【RAG】LangChainでHyDEを試す
RAGを構成する要素のうち、Retrieverの性能改善に資する方式として、HyDE(Hypothetical Document Embeddings)という手法があります。HyDEは入力されたクエリに対して、LLMで仮の回答を生成し、その仮の回答を元にナレッジを検索する方式です。この記事では、LangChainのRePhraseQueryを用いてHyDEを実装して、その効果を試してみます。
HyDE(Hypothetical Document Embeddings)とは?
HyDE(Hypothetical Document Embeddings)は、RAGのRetrieverの性能改善手法の一つです。
通常、ユーザーが入力したクエリをもとにナレッジ(ベクトルDB)を検索しますが、クエリとナレッジに含まれる文書、つまり、「質問」と「回答」の文書が類似しているとは限りません。
HyDEでは、ユーザーが入力したクエリから「仮の回答」(Hypothetical Document)を生成し、その仮の回答の埋め込み(Embeddings)を用いてベクトルDBを検索します。「仮の回答」はLLMの知識だけで生成するため、ハルシネーション等により間違っていることもありますが、それは気にしません。あくまで「仮の回答」とナレッジに格納されている文書の類似度が、元のクエリよりも高まることを狙う方式です。
具体的には、以下のような流れになります。
入力されたクエリ(Input Query)をいったんLLMに入れて、仮の回答(Hypothetical Documents)を生成します。その仮の回答を用いて、ナレッジ(Vector DB)から関連する文書を検索し、それをコンテキストとしてLLMに与えて最終的な回答を生成します。
LangChainによるHyDEの実装
いつものようにLangChainを利用してHyDEを実装してみます。LangCheinには、RePhraseQueryRetrieverという、与えられたクエリを言い換え(RePhrase)、その言い換えた内容でナレッジを検索する機能がありますので、これを利用します。
動作環境・準備
以下の環境で動作確認をしています。
- Windows10
- Python 3.11.6
- LangChain 0.2.11
- ChromaDB 0.5.5
ベクトルDBのEmbeddingにOpenAIの text-embedding-3-small を、LLMには OpenAI の GPT-4o-mini (gpt-4o-2024-05-13) を利用します。これらを利用するために、OpenAIのAPIキーを環境変数に設定しておいてください。
また、動作確認をするうえで、LangSmithを利用すると視覚的に分かりやすく動作を追うことができます。LangSmithを利用するには、LangChainのAPIキーを環境変数LANGCHAIN_API_KEYに設定してください。
OPENAI_API_KEY=<OpenAI API Key>
LANGCHAIN_API_KEY=<LangChain API Key>
ベクトルDBにはChromaを利用します。今回は、比較的多くのドキュメントを格納した状態で動作確認をしたかったので、自前のWordpressのブログ(青春18きっぷ関連の鉄道ブログ)の全記事をナレッジとして入れています。
この記事で掲載するコードを動作させるには、手元に適当なドキュメントを格納したChromaDBを用意して、以下の例のように環境変数にChromaDBのディレクトリとコレクション名を設定してください。
CHROMA_PERSIST_DIRECTORY="./chroma-db"
CHROMA_COLLECTION_NAME="wpchatbot"
あるいは、コードのChromaDBの部分を適当なベクトルDBなどに置き換えていただいても構いません。最終的に、LangChainのretrieverが用意できれば動作するはずです。
なお、コード全体は、以下のリポジトリに置いてあります。
HyDEの実装
# LLM
chat_model = ChatOpenAI(model="gpt-4o-2024-05-13", temperature=0.0)
# Vector Retriever
retriever = vector_retriever()
# HyDE Prompt
hyde_prompt = ChatPromptTemplate.from_template(hyde_prompt_template)
# HyDE retriever
rephrase_retriever = RePhraseQueryRetriever.from_llm(
retriever = retriever,
llm = chat_model,
prompt = hyde_prompt,
)
まずは、ふつうにChatモデルのLLMとVector Retrieverを用意します。vector_retriever()は、永続化したChromaDBを読み込んで、そのretrieverを返す関数です。hyde_promptは、仮の回答をLLMに生成させるためのプロンプトですが、後ほど説明します。
HyDEに利用するretrieverを、LangChainのRePhraseQueryRetrieverを利用して作成します。RePhraseQueryRetrieverは、HyDE専用というわけではなく、与えられたクエリをLLMを利用して言い換える(RePhrase)ためのRetrieverです。
llmにはクエリを言い換えるために利用するLLMを、promptにはLLMに指示をするためのプロンプトを、retrieverには、言い換えたあとのクエリでナレッジを検索するためのretrieverを渡します。
プロンプトを指定しないと、デフォルトでは以下のプロンプトが利用されるようです。
You are an assistant tasked with taking a natural language query from a user and converting it into a query for a vectorstore. In this process, you strip out information that is not relevant for the retrieval task. Here is the user query: {question}
これをHyDE用に修正します。HyDEでは、元のクエリから仮の回答を生成しますので、単純にLLMに回答してもらうようなシンプルなプロンプトにします。
プロンプトhyde_promptは以下のように設定してあります。
# HyDEプロンプトテンプレート
hyde_prompt_template = """ \
以下の質問の回答を書いてください。
質問: {question}
回答: """
RAGチェイン
HyDEを実現するrephrase_retrieverを組み込んだRAGチェインを作成します。
# RAG Chain
rag_chain = (
{"context": rephrase_retriever | doc_to_str, "question": RunnablePassthrough()}
| prompt
| chat_model
| StrOutputParser()
)
LCELでRAGチェインを設定しますが、retrieverがrephrase_retrieverになっている以外は、通常のRAGのチェインと変わりありません。
rephrase_retrieverによって検索されたドキュメントをcontextに、ユーザーが入力したクエリquestionはRunnablePassthroughでそのまま次のpromptに渡します。promptは通常のRAG用のQAプロンプトです。それをLLMchat_modelに渡し、結果をStrOutputParserで文字列に変換して出力します。
なお、doc_to_strは、ChromaDBから取得した複数のドキュメントを文字列に整形するだけの関数です。
# Documentsを整形する関数
def doc_to_str(docs):
return "\n---\n".join(doc.page_content for doc in docs)
このRAGチェインを以下のように実行します。
response = rag_chain.invoke(input_message)
input_messageにはユーザーが入力したクエリが入っています。これで、HyDEによるナレッジの検索を実施した後、LLMが最終的な回答を生成します。
HyDEの動作検証
それでは動作の検証をしてみます。HyDEを利用しない基本的なRAGと、HyDEを実装したRAGで、取得されるドキュメントや回答の違いを検証していきます。
HyDEで取得されるドキュメントの検証
まず、HyDEの効果を確認するために、単にクエリをもとにベクトル検索だけを実施するRAG (rag_basic.py) と、HyDEを実装したRAG (rag_hyde.py) で、ナレッジから取得されるドキュメントを比較してみます。比較しやすいように取得するドキュメントは5個とします。
- 質問: 青春18きっぷの旅で東北地方を移動するときにおすすめの列車は?
この質問に対する回答は、以下のとおりです。
# 基本的なRAG
$ python .\rag_basic.py 青春18きっぷの旅で東北地方を移動するときにおすすめの列車は?
AI: 青春18きっぷの旅で東北地方を移動するときにおすすめの列車は、中央本線の長距離普通列車「441M」です。この列車は大月から長野まで約210kmを4時間5分で走り、東京駅や新宿駅から1回の乗り換えで甲府・松本・長野へ到達できます。長距離移動に便利な列車です。
# HyDE
$ python .\rag_hyde.py 青春18きっぷの旅で東北地方を移動するときにおすすめの列車は?
AI: 東北地方を移動する際におすすめの列車は、五能線の観光列車「リゾートしらかみ」です。この列車は秋田~青森・弘前間を結び、日本海沿いの美しい景色を楽しむことができます。特に夏の夕陽を楽しむために「リゾートしらかみ6号」(弘前発秋田行き)がおすすめです。
回答が異なります。「東北地方を移動するときのおすすめ列車」を聞いていますが、基本的なRAGでの回答は中央本線の列車を挙げています。一方、HyDEを利用したRAGでは、東北地方を走る観光列車「リゾートしらかみ」を答えています。回答としてはHyDEのほうが望ましいです。
それでは、どうしてこのような回答の違いになったのかを見ていきます。LangSmithを用いて、取得されたドキュメントを見てみます。まず、HyDEを実装していないシンプルなRAGの場合です。
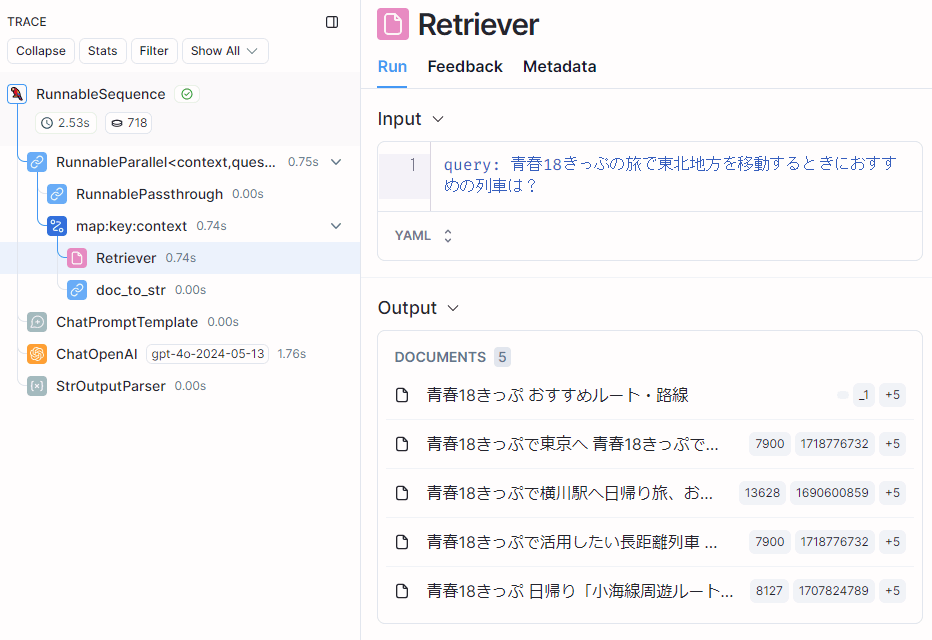
基本的なRAGのトレース
5つの文書の中身は長くなりますので、以下をクリックしてご覧ください。
基本的なRAGで取得された文書
青春18きっぷ おすすめルート・路線
青春18きっぷで東京へ
青春18きっぷで、日本各地から東京を目指すときのおすすめルートを、方面別に紹介する記事です。各路線の特徴、おすすめの路線や列車も紹介しています。青春18きっぷ初心者の方は、ぜひご覧ください。
青春18きっぷで横川駅へ日帰り旅、おすすめの列車・観光スポットを紹介!
それでは、ルートに沿って、おすすめの列車や観光スポットを紹介しましょう。掲載してある列車とダイヤは2023年3月改正の土休日ダイヤです。信越本線で「EL/SLぐんまよこかわ」に乗車するための乗り継ぎダイヤです。
青春18きっぷで活用したい長距離列車
青春18きっぷの旅で利用したい長距離普通列車(北海道~東日本エリア)をまとめた記事です。主要な列車のダイヤも紹介しています。青春18きっぷでの長距離旅行の際には参考にしてみてください。中央本線の長距離普通列車「441M」の紹介記事です。大月から長野まで約210kmを4時間5分で走る長距離列車です。東京駅や新宿駅から、たった1回の乗り換えで、甲府・松本・長野へ到達できる、貴重な列車です。
青春18きっぷ 日帰り「小海線周遊ルート」
まず、ルートをざっと紹介します。東京(首都圏)から甲信地方の東部を経由して戻ってくる周遊ルートです。しなの鉄道とJRバス関東には、青春18きっぷでは乗車できませんので、別途運賃を支払う必要がありますが、それでも青春18きっぷ1日分+1,020円でおさまります。何度か実践していますが、日帰りルートにしてはかなり距離がありますので、朝は早めに出発しましょう。山間部の車窓が美しいルートなので、景色を楽しみたいのなら、雲が湧く前の午前中が狙い目です。
元のクエリにある「東北地方」というキーワードがあまり考慮されていません。ナレッジに含まれる文書に、「東北地方」というワードと、「青春18きっぷ」「おすすめの列車」というワードの全てが含まれる文章がないためだと思われます。
次にHyDEの動作をLangSmithで見ていきます。
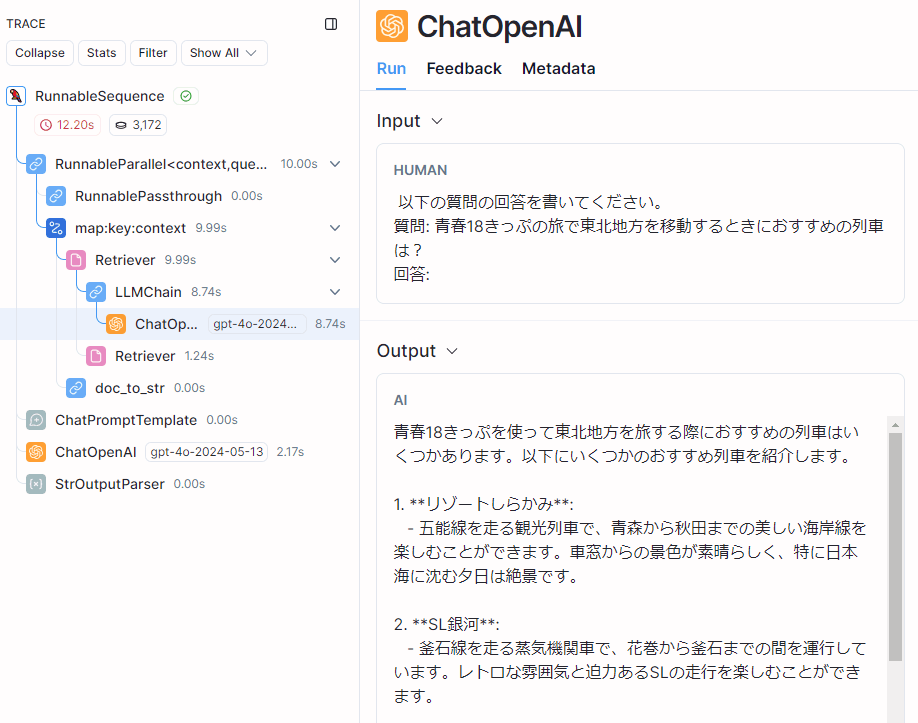
HyDEにおいて仮の回答を生成する部分のトレース
HyDEでは、ナレッジを検索する前に、LLMに「仮の回答」を生成させるステップがあります。LLMが生成した「仮の回答」は以下のとおりです。
青春18きっぷを使って東北地方を旅する際におすすめの列車はいくつかあります。以下にいくつかのおすすめ列車を紹介します。
1. **リゾートしらかみ**:
- 五能線を走る観光列車で、青森から秋田までの美しい海岸線を楽しむことができます。車窓からの景色が素晴らしく、特に日本海に沈む夕日は絶景です。
2. **SL銀河**:
- 釜石線を走る蒸気機関車で、花巻から釜石までの間を運行しています。レトロな雰囲気と迫力あるSLの走行を楽しむことができます。
3. **快速「海里」**:
- 新潟から酒田までを結ぶ観光列車で、日本海沿いの美しい景色を楽しむことができます。車内では地元の食材を使った食事も楽しめます。
4. **快速「はまなす」**:
- 青森から八戸までを結ぶ列車で、三陸海岸の美しい景色を楽しむことができます。特に夏の時期には、海水浴や釣りなどのアクティビティも楽しめます。
5. **仙山線**:
- 仙台から山形までを結ぶ路線で、山間部の美しい景色を楽しむことができます。特に秋の紅葉シーズンには絶景が広がります。
6. **磐越西線**:
- 郡山から新潟までを結ぶ路線で、阿賀野川沿いの美しい景色を楽しむことができます。特に冬の雪景色は一見の価値があります。
青春18きっぷを使ってこれらの列車に乗ることで、東北地方の自然や文化を存分に楽しむことができます。事前に運行スケジュールを確認し、計画を立てて旅を楽しんでください。
ナレッジを利用していない、純粋にLLM(OpenAI GPT-4o-mini)の知識のみでの回答ですので、古い情報や間違った回答も少し含まれています。ただ、これはあくまで「仮の回答」ですので、正確性はそれほど気にする必要はありません。
次に、この「仮の回答」と類似する文書をナレッジから取得します。
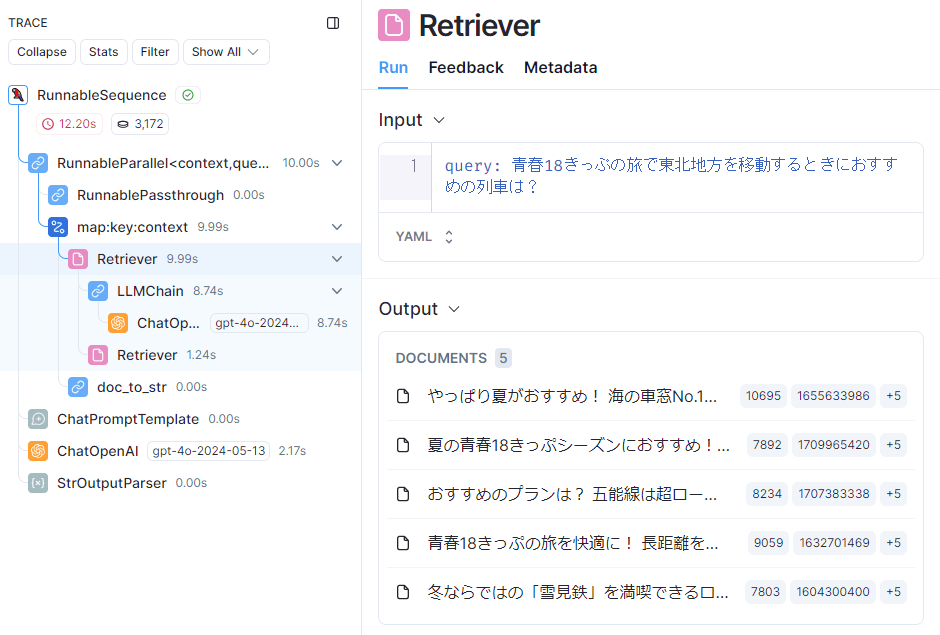
HyDEにおいて仮の回答でナレッジを検索して得られたドキュメントのトレース
DOCUMENTSの欄に表示されている4桁~5桁の数字は、ナレッジの元となっているWordpressの記事IDです。ChromaDBに入れるときにmetadataとして保存しています。先ほどの基本的なRAGとはまったく違う記事IDの文書が選ばれていることがわかります。
取得された文章の全体は、以下をクリックしてご覧ください。
HyDEを用いたRAGで取得された文書
やっぱり夏がおすすめ! 海の車窓No.1! 五能線「リゾートしらかみ」
秋田~青森間を五能線経由で結ぶ観光列車「リゾートしらかみ」は、途中、2時間近くにも渡って、日本海のすぐ近くを通ります。日本海の大海原に加えて、奇岩が続く海岸線や、点在する小さな漁村など、日本海の車窓の魅力をたっぷりと味わうことができる列車です。「リゾートしらかみ」のもう一つの魅力が、日本海に沈む夕陽です。夏休みの期間は、「リゾートしらかみ6号」(弘前発秋田行き)に乗ると、ちょうど日本海沿いに走る区間で日没を迎えます。「リゾートしらかみ」は、夏の青春18きっぷシーズン中は毎日運転されます。日によって運転される列車の本数が異なりますが、夏の青春18きっぷが利用できる期間中は、ごく一部の日を除いて、3往復6本の「リゾートしらかみ」が運転されます。途中駅で下車して、観光を楽しみ、後続の「リゾートしらかみ」に乗車するといったこともできますね。「リゾートしらかみ」については、運転日・ダイヤ、おすすめの座席、指定席の予約方法など、以下の記事で紹介していますので、ぜひご覧ください。また、「リゾートしらかみ」の車窓や、車内での食事情などについては、以下の記事もご覧ください。以上、「2022年夏の青春18きっぷで乗りたいおすすめの路線・列車6選!」でした。夏休みは青春18きっぷで遠征される方も多いと思いますが、今シーズンだからこそ乗っておきたい列車・路線をうまく組み込んで旅を楽しみたいですね。
夏の青春18きっぷシーズンにおすすめ! 小海線日帰り旅!
山梨県の小淵沢駅と、長野県の小諸駅を結ぶ小海線に乗車するルートです。首都圏からは、中央本線~小海線~しなの鉄道~JRバス関東~信越本線~高崎線という一周ルートになりますので、飽きることなく旅ができます。個人的には一番のおすすめルートです。おすすめのシーズンは何と言っても夏! 日本全国のJR線で最も標高の高いところ走る小海線は、まさに高原鉄道。八ヶ岳の麓の清里や野辺山は、夏になると大勢の観光客で賑わいます。また、週末を中心に運転される観光列車「HIGH RAIL 1375」に乗るのもおすすめです。青春18きっぷ+指定席券(840円)で乗車することができます。筆者の大好きな小海線についてまとめた目次ページです。小海線の車窓や沿線の観光スポット、観光列車「HIGH RAIL 1375」などの記事を掲載しています。小海線の観光列車「HIGH RAIL 1375」については、以下の記事をご覧ください。運転日やダイヤ、指定席の予約方法などの基本的な情報に加え、車内の様子などの乗車記も公開しています。
おすすめのプランは?
五能線は超ローカル線であることには変わりありませんので、普通列車の本数が極めて少ないです。特に、岩館~鯵ヶ沢は本数が少なく、日中は数時間列車がやってこない時間帯もあります。おすすめは
観光列車「リゾートしらかみ」
に乗車することです。リゾートしらかみは、秋田~青森・弘前間を結ぶ全席指定の快速列車です。秋田、青森、弘前といった拠点駅を結んでいますので利用しやすいですし、快速列車ですので指定席券(530円)さえ確保できれば、青春18きっぷで乗車可能です。それに、何といっても特急列車並みのリクライニングシートに乗って旅ができる乗り得列車でもあります。リゾートしらかみに乗車するのであれば、
日没の時間帯に日本海に面した区間を走る列車
を選ぶのがおすすめです。2024年のダイヤでは、以下の列車がおすすめです。夏季: 6号(弘前→秋田)
冬季: 4号(青森→秋田) または 5号(秋田→青森)なお、リゾートしらかみは臨時列車ですので毎日運転ではありません。また、日によって運転される列車も異なりますので、事前に運転日、運転時刻等を確認しておきましょう。リゾートしらかみの指定席を確保する場合は、
「A席」がおすすめ
です。日本海に沿って走る区間で海側になります。指定席が売り切れになると乗車できませんので、予定が決まったら早めに手配することをおすすめします。「リゾートしらかみ」の運転日・ダイヤ、予約方法、車窓のポイント、沿線の観光スポット等については、以下の記事でまとめて紹介していますので、「リゾートしらかみ」の乗車を考えてい列車る方は、ぜひご覧ください。「リゾートしらかみ」の乗車記も公開しています。2021年3月に「リゾートしらかみ1号」(くまげら編成)に乗車した際の乗車記です。写真多め、動画入りで、日本海の絶景車窓を紹介していますので、ぜひご覧ください。冬の五能線の車窓を眺めに、2022年12月、「リゾートしらかみ5号」に乗車してきました。夏の穏やかな日本海とは対照的に、鈍色のどんよりとした空の下、白波が立つほど荒れている日本海を眺めながらの旅です。
青春18きっぷの旅を快適に! 長距離を快適に移動できる列車として活用しよう!
観光列車の中には、特急列車並みの長距離を走る列車も少なくありません。それに、単に長距離であるだけでなく、普通列車では乗り換えが必要な区間を、乗り換えなしで移動することもできるのです。このような観光列車の特徴をいかして、乗り鉄のような鉄道旅行に活用してみることをおすすめします。車窓や食を楽しむだけでなく、鉄道本来の目的である「移動手段」としても活用してしまおうということです。特に、普通列車・快速列車にしか乗車できない青春18きっぷの旅に活用することをおすすめします。JR各社のSL列車やトロッコ列車、それに、JR東日本の観光列車「乗ってたのしい列車」は、全車指定席の快速列車として運転されているものが多くあります。快速列車ですので、乗車券としては「青春18きっぷ」を使うことができます。あとは、指定席券(530円~840円くらいが多い)をプラスすれば、青春18きっぷの旅でも観光列車に乗ることができます。青春18きっぷ+指定席券で乗車できる観光列車については、以下の記事にまとめていますので、ぜひご覧ください。
冬ならではの「雪見鉄」を満喫できるローカル線(只見線、飯山線、大糸線)
冬の青春18きっぷの旅でぜひおすすめしたいのが、暖かい車内から雪景色を眺める「雪見鉄」です。雪が降る路線であればどこでもいいのですが、見るからに静寂に包まれるローカル線をおすすめします。首都圏から比較的近い「雪見鉄」を楽しめる路線としては、まずは只見線をおすすめします。2022年10月に全線で運転を再開してから1年。まだまだ運転再開特需が続く只見線です。只見線の沿線、特に福島・新潟県境付近は豪雪地帯。冬の青春18きっぷシーズンでは、まだ積雪はそれほど多くはないかもしれませんが、十分に「雪見鉄」を楽しめると思います。以下の記事では、以前、筆者が冬の青春18きっぷシーズンに只見線に乗車した時の様子を紹介していますので、ぜひご覧ください。(全線運転再開前に乗車しましたので、一部区間は代行バスとなっています)もう一つ、「雪見鉄」におすすめしたい路線は飯山線です。JR東日本エリアでは屈指の豪雪路線で、大雪が降ると、日中の列車を運休して除雪作業を行うほどです。飯山線は千曲川~信濃川に沿って走る路線です。白と黒のモノトーンの世界が車窓を包み込み、いかにも雪国の冬を感じさせる路線でもあります。飯山線の冬の車窓については、以下の乗車記をご覧ください。こちらも冬の青春18きっぷで乗車した時のものです。飯山線に乗車するのであれば、観光列車「おいこっと」もおすすめです。長野~十日町間をのんびりと走る観光列車です。観光列車「おいこっと」については、以下の記事で紹介しています。車内の様子や乗車記に加え、おすすめの座席や指定席の予約方法などについても紹介していますので、ぜひご覧ください。また、大糸線も含めた「雪見鉄」のおすすめ路線や乗車プランを以下の記事にまとめています。ぜひご覧ください。
LLMが生成した「仮の回答」に含まれる「リゾートしらかみ」の文書などが取得できています。これをもとに、最終的な回答として「リゾートしらかみ」を回答しています。
つまり、元のクエリからLLMによって生成された「仮の回答」には、LLMの知識が含まれ、その LLMの知識をヒントにナレッジを検索 していることになります。
処理時間
HyDEでは、以下の2回のLLMへの問い合わせが発生します。
- ユーザーが入力したクエリから「仮の回答」を生成する
- ナレッジから取得したコンテキストとユーザーのクエリから最終的な回答を生成する
基本的なRAGでは2.の1回だけですので、2回のLLMへの問い合わせが発生することによる処理時間が気になります。そこで、いくつかの質問で処理時間を比較してみました。
| 質問No. | 基本RAG | HyDE |
|---|---|---|
| No.1 | 2.53 | 8.74 |
| No.2 | 3.14 | 6.03 |
| No.3 | 3.00 | 6.03 |
| No.4 | 3.25 | 12.41 |
※単位[秒]
ざっくりいうと、基本的なRAGに比べて、HyDEでは2~3倍の処理時間を要します。LLMのモデルによって違うのかもしれませんが、今回利用したGPT-4o-miniでは、「仮の回答」がかなり長い場合があり、その生成に時間を取られているようです。最終的な回答を生成する2.のステップの処理時間は、基本的なRAGとHyDEではほとんど変わりません。そのため、基本的なRAGとHyDEの処理時間の差は、主に1.の「仮の回答」を生成するのに要している時間とみてよいと思います。
最終的な回答を生成する場合には、プロンプトに「コンテキストを使って回答すること」としているため、コンテキストの内容以上のことは回答しません。それに対して、「仮の回答」の生成では、特に制限なくLLMに回答させているため、全般的に回答が長くなる傾向があります。
「仮の回答」を生成する際のプロンプトに「簡潔に」とか「〇〇文字以内で」などと指示をすれば短くなりますが、ナレッジを検索するときにヒントとなる情報も少なくなるため、処理時間と精度のトレードオフということになりそうです。
まとめ
RAGの改善手法の一つであるHyDE(Hypothetical Document Embeddings)を実装して、動作を検証してみました。
上の検証で紹介した例以外にも多くのクエリで試していますが、基本的なRAGだけでも十分に適切な文書を取得できることが多いです。ただ、ユーザーが入力したクエリに含まれる重要なキーワードがすべて含まれる文書がないこともあり、そのような場合には、LLMの知識を借りて「仮の回答」を生成することで、適切な文書を取得できる確率が上がる可能性がありそうだと感じました。
一方で、「仮の回答」を生成する際には、LLMの知識だけを頼りにするため、ハルシネーションを起こす可能性もあります。多少の間違いであれば大きな影響はなさそうですが、重要なキーワードで間違えていると、そのキーワードのせいで、ナレッジから適切ではない文書を取得してしまうこともありそうです。
これを改善するには、取得する文書の数を多めにして、元のクエリとの類似度でRerankする方法がありそうです。さらにLLMへの問い合わせが増えてしまうので、処理時間との兼ね合いもありますが、検索性能の向上が見込めると思います。別途、実装して検証してみたいと思います。
関連記事
CohereのRerankerを利用したRAGの実装と検証の記事です。
ユーザーが入力したクエリと類似のクエリを複数作成し、それぞれのクエリをもとにナレッジを検索する RAG Fusion という手法の実装と動作検証の記事です。
Discussion