【RAG】LangChainのAgentでRAGチャットボットをつくる
ここしばらく、LangChainでRAGチャットボットを作って動かしています。これまで、RetrievalQA Chainを利用してきましたが、Agentを利用してRAGチャットボットを構築することもできます。今回は、LangChainのAgentを利用して、RAGチャットボットを作ってみます。
Agentを用いたRAGチャットボット
これまで実装してきたRAGチャットボットは、RetrievalQA Chain を利用したものです。RetrievalQA Chainは、ユーザーの入力(質問)に対して、ナレッジ(ベクトルDB)から関連情報を検索し、検索した情報をプロンプトに付与してLLMに回答を生成させるという一連の流れを実現します。
この流れに、会話履歴を含めたり、質問をこれまでの会話履歴から単独で理解可能なものに変換する「コンテキスト化」という手法も試してきました。それぞれの手法において、それなりの効果を確認できました。
それぞれの実装については、以下の記事をご覧ください。
RetrievalQA Chainでは、あらかじめ決められた流れでRAGを実現しますが、別の方法として、Agentを利用する方法があります。Agentでは、事前に定義したToolを利用してAIが問題を解決していきます。RAGにおいては、ナレッジを検索するretrieverをToolとして定義することで、 AIが必要と判断した時 に、ナレッジを検索してくれます。
具体的には、以下のフローチャートのような動作になります。
入力クエリ(Input query)に対して、Agentがtool(retriever)を利用すべきかを判断します。必要と判断したら、toolとして登録されているretrieverでナレッジ(Vector DB)を検索します。
その後、会話履歴(Chat hidtory)とあわせてQAプロンプトを作成して、LLMに最終的な回答を生成させます。
AgentによるRAGチャットボットの実装
それでは、Agentを利用したRAGチャットボットを実装していきます。
ベースとするのは、これまでに作成した会話履歴付きのRAGチャットボットです。このRAGチャットボットのChain部分をAgentに置き換えていくことにします。
LangChainのAgentは、最近ではLangGraphを利用して記述するようですが、この記事では従来のAgentExecutorを利用して実装します。なお、これまでのAgentから、LangGraphを利用したAgentへの移行については、LangChainのWebサイトにある以下の記事で解説されています。
また、この記事で紹介するコードは、以下のリポジトリで公開しています。
動作環境・準備
以下の環境で動作確認をしています。
- Windows10
- Python 3.11.6
- LangChain 0.2.10
- ChromaDB 0.5.5
ベクトルDBのEmbeddingにOpenAIの text-embedding-3-small を、LLMには OpenAI の GPT-4o-mini (gpt-4o-2024-05-13) を利用します。これらを利用するために、OpenAIのAPIキーを環境変数に設定しておいてください。
OPENAI_API_KEY=<OpenAI API Key>
ベクトルDBにはChromaを利用します。今回は、比較的多くのドキュメントを格納した状態で動作確認をしたかったので、自前のWordpressのブログの全記事をナレッジとして入れています。
この記事で掲載するコードを動作させるには、手元に適当なドキュメントを格納したChromaDBを用意して、以下の例のように環境変数にChromaDBのディレクトリとコレクション名を設定してください。
CHROMA_PERSIST_DIRECTORY="./chroma-db"
CHROMA_COLLECTION_NAME="wpchatbot"
あるいは、コードのChromaDBの部分を適当なベクトルDBなどに置き換えていただいても構いません。最終的に、LangChainのretrieverが用意できれば動作するはずです。
Agentの実装
それではAgentの実装について、コードを抜粋しながらポイントを解説していきます。
まず、プロンプトテンプレートです。
# プロンプトテンプレート
system_prompt = (
"あなたは青春18きっぷとその関連商品に関する有能なアシスタントです。"
"青春18きっぷの情報を取得するseishun18_retrieverを活用して、ユーザーの質問に答えてください。"
"青春18きっぷに関する質問に回答する場合には、必ずseishun18_retrieverを活用して取得した情報をもとに回答してください。"
"質問に回答するための情報が含まれない場合には、無理に質問に答えないでください。"
)
prompt_template = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
システムプロンプトでは、このあと定義するretrieverであるseishun18_retrieverを利用して質問に回答するように指示をしています。
テンプレートのほうでは、{chat_history}に会話履歴が、{input}にユーザーからの質問が入ります。また、{agent_scratchpad}は、Agentが一時的な情報や結果の記憶領域として利用されます。
次に、Agentで利用するToolの定義を見てみます。
# Vector Retriever
retriever = vector_retriever()
# Retriever Tool
tool = create_retriever_tool(
retriever,
"seishun18_retriever",
"Searches and returns excerpts from the Autonomous Agents seishun18 knowledge",
)
tools = [tool]
vector_retriever()は、永続化されたChromaDBを読み込み、retrieverとして返す関数です。通常のRAGで利用するベクトル検索のretrieverと同じものです。
次に、create_retriever_toolを利用して、Retriever Toolを作成します。create_retriever_toolは、retriever、ツール名(name)、ツールの説明(description)などを受け取って、ナレッジを検索するretrieverをAgentが利用するToolとして返します。
ツール名やツールの説明は重要です。Agentは、このツール名やツールの説明を見て、ツールを利用するかを判断するためです。
次に、先ほど作成したToolを利用してAgentを作成します。
# Agent
agent = create_tool_calling_agent(chat_model, tools, prompt_template)
agent_executor = AgentExecutor(agent=agent, tools=tools)
create_tool_calling_agentにchat_model(LLMモデル)、先ほど作成したretriever tool、プロンプトテンプレートを渡して、agentを作成します。
create_tool_calling_agentは、Toolを利用するAgentを作成する関数です。
作成したAgentをAgentExecutorでラップします。agentがAgentの実行インスタンスであるのに対して、AgentExecutorはagentの実行を管理します。具体的には、Agentがどのツールを利用するか、どのようにユーザーと対話するかなどの制御を実施します。
最後に、会話履歴付きチャットボットを作成するために、agent_executorをRunnableWithMessageHistoryでラップします。
# 会話履歴付きAgentExecutor
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
get_session_history=get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
)
RunnableWithMessageHistoryは、通常のRAGなどのRunnableなChainに対して、会話履歴を付与するためのラッパーです。LCEL記法などで書いたChainに対して、ラップするだけで会話履歴を付けることができるので、とても便利です。詳しくは以下の記事で紹介しています。
あとは、agent_with_chat_historyをinvokeすればOKです。
# Agentを実行
response = agent_with_chat_history.invoke(
{"input": input_message},
config={"configurable": {"session_id": session_id}}
)
動作確認
それでは動かしてみましょう。今回も、私が運営する青春18きっぷ(鉄道関連)のブログの記事を入れたベクトルDBを利用します。
動作確認ではLangSmithを利用します。LangSmithを利用するには、LangChainのAPIキーを環境変数LANGCHAIN_API_KEYに設定したうえで、コードに以下を追加します。
# Langchain LangSmith
unique_id = uuid.uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing RAG agent - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
この状態でコードを実行すると、LangSmithのWebサイトにあるダッシュボードでLangChainの動作を確認することができます。
基本的な質問での動作
まずはコンソールでAIの回答を確認してみましょう。
$ python .\rag_chatbot_agent.py
---
[0]あなた: こんにちは。
AI: こんにちは!青春18きっぷやその関連商品について何か質問がありますか?どんな情報でもお手伝いしますので
、お気軽にどうぞ。
---
[1]あなた: 2024年春の青春18きっぷはいつ使えますか?
AI: 2024年春の青春18きっぷの利用期間は以下の通りです:
- **利用期間**:2024年3月1日(金)~4月10日(水)
- **発売期間**:2024年2月20日(火)~3月31日(日)
この期間中に青春18きっぷを利用して、JRの普通列車や快速列車での旅を楽しむことができます。
---
[2]あなた: 夏は?
AI: 2024年夏の青春18きっぷの利用期間は以下の通りです:
- **利用期間**:2024年7月20日(土)~9月10日(火)
- **発売期間**:2024年7月10日(水)~8月31日(土)
この期間中に青春18きっぷを利用して、JRの普通列車や快速列車での旅を楽しむことができます。
---
[3]あなた: 価格は?
AI: 2024年の青春18きっぷの価格は以下の通りです:
- **価格**:12,050円(税込)
- 5回分(5日分)セットでの価格です。
- 1回分(1日分)あたり2,410円となります。
おとな用、こども用の区別はなく、こども(小学生以下)でもおとなと同額になります。
[1]で2024年春の青春18きっぷの利用期間を聞いていますが、正しく回答できています。[2]の「夏は?」や、[3]の「価格は?」の質問に関しては、それぞれ「青春18きっぷの」という前提できちんと回答できています。会話履歴の効果がきちんと出ているようです。
蛇足ですが、GPT-4o-miniではMarkdown形式で回答が返ってくるようですね。
次に、LangSmithで詳細な動作を確認してみます。以下は、最初の[0]の「こんにちは」というユーザーの入力に対するLangSmithのトレースです。
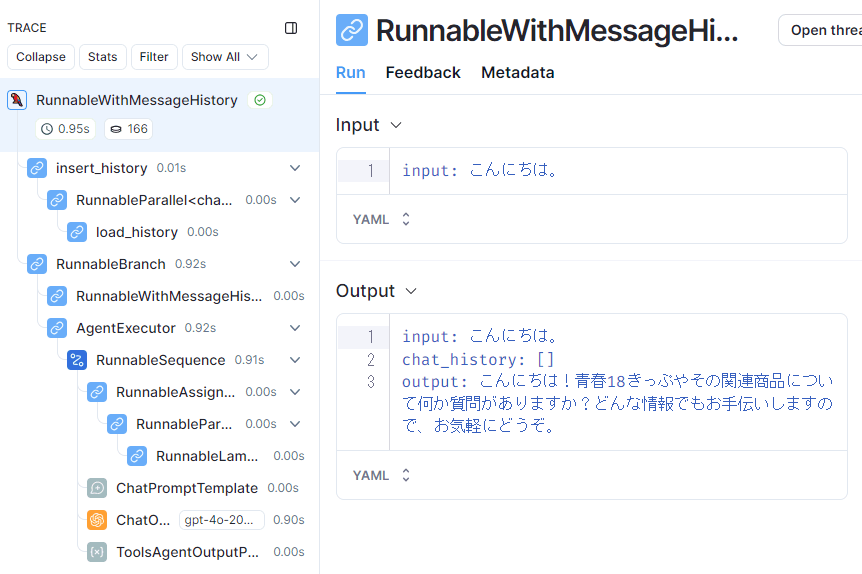
Retrieverは動作していない
左側のトレースを見てみると、retrieverが動作していません。つまり、Agentは、「こんにちは」という入力に回答するためには、retrieverは不要と判断しているわけです。
次に、[1]の「2024年春の青春18きっぷはいつ使えますか?」という質問に対するトレースを見てみます。
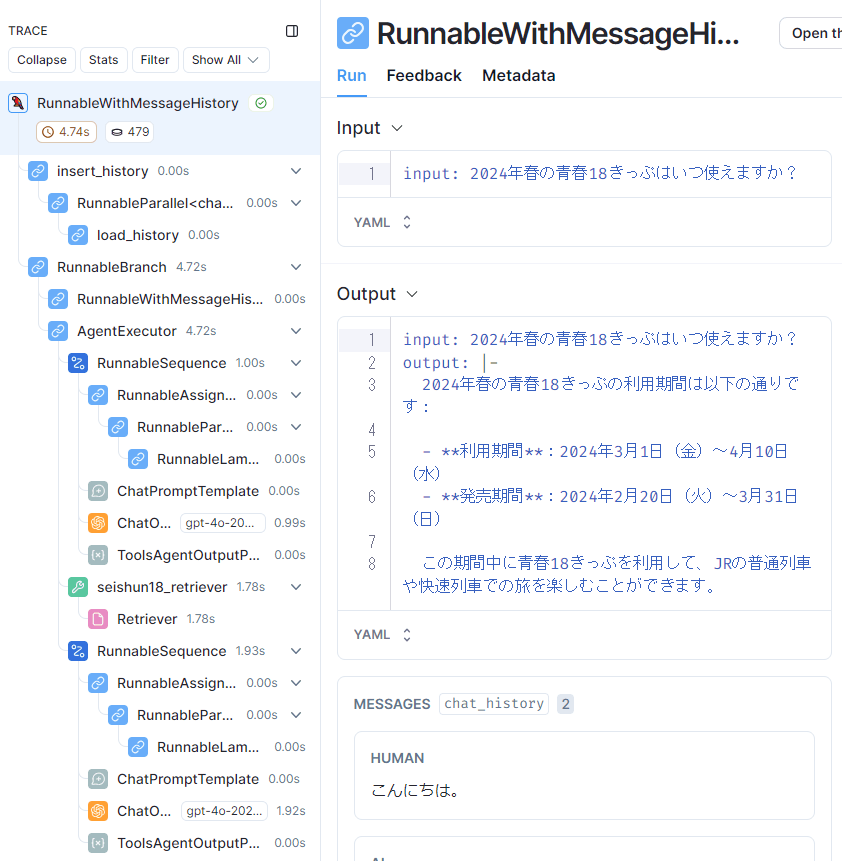
今度はRetrieverが動作している
先ほどのトレースと比べると、ぐっと処理のステップが増えました。左側のトレースを見ると、seishun18_retrieverやRetrieverがあり、ナレッジを検索していることがわかります。つまり、Agentは、「2024年春の青春18きっぷはいつ使えますか?」という質問に答えるためには、retrieverを使う必要があると判断しているわけです。
以下の出力は、トレースにあるToolsAgentOutputParserのものです。
{
"output": [
{
"tool": "seishun18_retriever",
"tool_input": {
"query": "2024年春 青春18きっぷ 期間"
},
"log": "\nInvoking: `seishun18_retriever` with `{'query': '2024年春 青春18きっぷ 期間'}`\n\n\n",
"type": "AgentActionMessageLog",
"message_log": [
{
"content": "",
"additional_kwargs": {
"tool_calls": [
{
"index": 0,
"id": "call_xxxxxxxxxxxxxxxxxxxxxxxx",
"function": {
"arguments": "{\"query\":\"2024年春 青春18きっぷ 期間\"}",
"name": "seishun18_retriever"
},
"type": "function"
}
]
},
"response_metadata": {
"finish_reason": "tool_calls",
"model_name": "gpt-4o-2024-05-13",
"system_fingerprint": "fp_xxxxxxx"
},
"type": "AIMessageChunk",
"id": "run-da35eaa0-fbd1-4628-92ba-xxxxxxxxxx",
"example": false,
"tool_calls": [
{
"name": "seishun18_retriever",
"args": {
"query": "2024年春 青春18きっぷ 期間"
},
"id": "call_xxxxxxxxxxxxxxxxxxxxxxxx",
"type": "tool_call"
}
],
"invalid_tool_calls": [],
"tool_call_chunks": [
{
"name": "seishun18_retriever",
"args": "{\"query\":\"2024年春 青春18きっぷ 期間\"}",
"id": "call_xxxxxxxxxxxxxxxxxxxxxxxx",
"index": 0,
"type": "tool_call_chunk"
}
]
}
],
"tool_call_id": "call_xxxxxxxxxxxxxxxxxxxxxxxx"
}
]
}
AgentExecutorがtoolの要否を判断した結果が出力されていますが、seishun18_retrieverを用いて、2024年春 青春18きっぷ 期間を検索するようにという結果になっています。
これを受けて、実際にRetrieverでナレッジを検索し、取得できた文書とともに、最終的にLLMに回答を生成させているわけです。
Agentが、質問内容に応じて、Toolとしてseishun18_retrieverを利用する必要があるかを的確に判断できていることがわかります。
少し複雑な質問での動作
Agentが適切にretrieverの要否を判断していることはわかりました。
ただ、RAGチャットボットにおいては、「こんにちは」のようなナレッジに関係のない会話は通常はまれであり、たいていはナレッジに関する質問になります。そうであれば、常にナレッジを検索するRetrievalQA Chainとあまり変わらないのでは? と思ったので、少し複雑な質問で動作を確認してみました。
$ python .\rag_chatbot_agent.py
---
[0]あなた: 北海道&東日本パスとはどんなきっぷですか?
AI: 「北海道&東日本パス」は、JR北海道とJR東日本の普通列車・快速列車に連続する7日間乗り放題となるフリーきっぷです。以下はその詳細です:
### 利用期間と発売期間
- **春季**: 2024年3月1日~4月22日(発売期間: 2024年2月20日~4月16日)
- **夏季**: 2024年7月1日~9月30日(発売期間: 2024年6月20日~9月24日)
- **冬季**: 2024年12月10日~2025年1月10日
### 価格
- **大人**: 11,330円
- **小児**: 5,660円
### 乗車可能な列車・路線
- JR北海道・JR東日本・青い森鉄道・IGRいわて銀河鉄道・北越急行の普通・快速列車の普通車自由席
- BRT(バス高速輸送システム)
(省略)
「北海道&東日本パス」は、特に東北地方~北海道を中心に旅行する場合や、本州~北海道を鉄道で行き来する場合 に非常に便利です。
---
[1]あなた: 青春18きっぷとどちらがおすすめですか?
AI: 青春18きっぷと北海道&東日本パスのどちらがおすすめかは、旅行の目的や行き先、日程によって異なります。
以下にそれぞれの特徴をまとめましたので、参考にしてください。
### 青春18きっぷの特徴
- **利用可能期間**: 春季、夏季、冬季の特定期間
- **価格**: 12,050円(5回分)
- **有効期間**: 5回分(5日分)で、1回分は1日有効
- **利用可能エリア**: 全国のJR線の普通・快速列車の普通車自由席
- **メリット**:
- 全国のJR線に乗り放題
- 1回分を複数人でシェア可能
- **デメリット**:
- 新幹線や特急列車には基本的に乗れない(特定区間を除く)
- 連続した日でなくても利用可能だが、5回分を使い切る必要がある
### 北海道&東日本パスの特徴
- **利用可能期間**: 春季、夏季、冬季の特定期間
- **価格**: 大人 11,330円、小児 5,660円
- **有効期間**: 連続する7日間
- **利用可能エリア**: JR北海道、JR東日本、青い森鉄道、IGRいわて銀河鉄道、北越急行の普通・快速列車の普通車
自由席
- **メリット**:
- 東北地方の三セク路線にも乗車可能
- 特定特急券を購入すれば北海道新幹線に乗車可能
- 連続する7日間有効で、長期旅行に適している
- **デメリット**:
- 利用エリアがJR北海道・JR東日本エリアに限定される
- 連続する7日間での利用が必要
### おすすめの選び方
- **全国を旅行したい場合**: 青春18きっぷ
- **東北地方や北海道を中心に旅行する場合**: 北海道&東日本パス
- **連続した日程で長期旅行を計画している場合**: 北海道&東日本パス
- **複数人でシェアして使いたい場合**: 青春18きっぷ
旅行の目的や行き先に応じて、どちらのきっぷが適しているかを検討してみてください。
---
[2]あなた: 価格はどちらが安いですか?
AI: ### 青春18きっぷの価格
- **価格**: 12,050円(5回分)
- **1回分の価格**: 約2,410円
### 北海道&東日本パスの価格
- **価格**: 大人 11,330円、小児 5,660円
- **1日あたりの価格**: 約1,618円(7日間有効)
### 価格の比較
- **青春18きっぷ**: 1回分(1日分)の価格は約2,410円
- **北海道&東日本パス**: 1日あたりの価格は約1,618円
### 結論
価格だけで比較すると、1日あたりの利用料金は「北海道&東日本パス」の方が安いです。ただし、利用エリアや有効期間などの条件も考慮する必要があります。旅行の目的や行き先に応じて、どちらのきっぷが適しているかを検討し てください。
[0]で、青春18きっぷの姉妹きっぷである「北海道&東日本パス」について質問していますが、[1]では「青春18きっぷとどちらがおすすめですか?」、[2]で「価格はどちらが安いですか?」と聞いています。
この[1]や[2]の質問は、それぞれのきっぷの情報をナレッジから取得して、比較したうえで回答する必要がある点で、やや複雑な質問になっていますが、それでも正確に答えられています。
LangSmithでこの[1]の質問回答のトレースを見てみます。

seishun18_retrieverが2回動作している
左側のトレースを見てみると、seishun18_retrieverが2つあるのがわかるでしょうか? その前のAgentExecutorの最終的な出力であるToolsAgentOutputParserを見てみると、以下のようになっています。とても長いので、途中のtool_callsのところだけ抜粋しています。
(...省略)
"tool_calls": [
{
"name": "seishun18_retriever",
"args": {
"query": "青春18きっぷの特徴"
},
"id": "call_qJKNz1IgAsJuJoiX9FdBZuYk",
"type": "tool_call"
},
{
"name": "seishun18_retriever",
"args": {
"query": "北海道&東日本パスの特徴"
},
"id": "call_KdXTVkFcuQ6D8lhyPEwIQSZL",
"type": "tool_call"
}
],
(省略...)
これを見ると、Agentは2回のseishun18_retrieverの実行が必要であると判断しています。
- 1回目: "青春18きっぷの特徴"
- 2回目: "北海道&東日本パスの特徴"
「青春18きっぷとどちらがおすすめですか?」という質問を、「青春18きっぷと北海道&東日本パスのどちらがおすすめですか?」と解釈し、これに回答するには、青春18きっぷと北海道&東日本パスのそれぞれのナレッジが必要であると判断しているわけです。
長くなるのでここでは示しませんが、このあとのLLMへのQAクエリでは、2回のナレッジの検索で取得した情報が渡されていることが確認できています。
[2]の価格に関する質問でも同様に、「青春18きっぷ 価格」と「北海道&東日本パス 価格」の2回のナレッジ検索が行われています。
この動作は、RetrievalQA Chainでは難しいので、Agentならではと言えそうです。
処理時間
気になる処理時間ですが、やはり少し時間がかかります。
回答が比較的短い最初の会話では、以下のようになりました。
- [0]こんにちは: 0.95s
- [1]2024年春の青春18きっぷはいつ使えますか?: 4.74s
- [2]夏は?: 3.97s
- [3]価格は?: 3.22s
retrieverを利用しない[0]ではすぐに回答が返ってきますが、retrieverを利用する[1]~[3]では4秒前後の処理時間がかかります。処理時間の大部分はLLMでの回答生成に要する時間ですが、[1]~[3]ではAgentの判断にもLLMを利用しているため、その分、処理時間が長くなっています。
一方、2回のナレッジ検索に加えて、LLMからの回答が長めの2回目の会話では、かなり処理時間がかかっています。
- [0]北海道&東日本パスとはどんなきっぷですか?: 11.46s
- [1]青春18きっぷとどちらがおすすめですか?: 12.42s
- [2]価格はどちらが安いですか?: 8.17s
こちらは、retrieverを2回使うことに加えて、回答が長いこともあって、10秒を超える時間を要しました。ただ、やはりLLMの回答生成に要する時間がほとんどですので、ストリーミングで回答を表示させるようにすれば、体感的にはそこまで長くないと思われます。
まとめ
LangChainのAgentを利用して、RAGチャットボットを実装してみました。
retrieverを使うか使わないかの判断だけをAgentがするのであれば、毎回retrieverを強制的に使わせるRetrievalQA Chainと大差ないかなと思っていました。が、実際に試してみると、1回の質問について、必要であればretrieverを複数使ってくれますし、それぞれ適切なクエリでの検索をしてくれます。
これはあらかじめ処理内容が決まっているRetrievalQA Chainでは難しい動作です。今回はToolが一つだけでしたので、Agentにする意味はあまりないかもしれないと思っていましたが、その一つのToolであるretrieverをどのように使いこなしていくかもAgentが考えてくれるということですね。
Toolとして、retrieverだけでなく、ネットを検索するToolなどを組み合わせれば、より賢いRAGチャットボットを作ることもできそうです。
Discussion