【RAG】LangChainでつくるRAGチャットボット ~質問のコンテキスト化を試す~
前回の記事で、会話履歴付きのRAGチャットボットを試してみました。ユーザーの質問とLLMの回答を履歴として保持し、それを2回目以降の質問の際にプロンプトに含めるだけで、それなりに文脈を意識した回答をLLMが生成してくれるようになりました。
今回は、さらにRAGチャットボットの性能向上を目指して、LangChainのWebサイトにも載っている「質問のコンテキスト化」(Contextualizing the question)を試してみます。
RAGチャットボットにおける質問のコンテキスト化とは?
RAGチャットボットにおける「質問のコンテキスト化」は、2回目以降のユーザーの質問(クエリ)を、会話履歴を参照して単独で成立する質問に補完する技術のことです。
LangChainのWebサイトに掲載されている例を挙げてみます。
Human: "What is Task Decomposition?"
AI: "Task decomposition involves breaking down complex tasks into smaller and simpler steps to make them more manageable for an agent or model."
Human: "What are common ways of doing it?"
「Task Decompositionって何?」という質問にAIが答えていますが、その次に「それを行う一般的な方法は?」と質問しています。
文脈を理解していれば「それ」(it)が Task Decomposition であることがわかります。質問のコンテキスト化とは、以下のように、文脈(会話履歴)を考慮して、単独でRAGに入力して回答を得られるようにすることです。
- ユーザの質問: それを行う一般的な方法は?
- コンテキスト化された質問: Task Decomposition を行う一般的な方法は?
このように、RAGのチェインを実行する前に、ユーザーの質問を会話履歴を用いて補完することで、2回目以降でも単独で成立する質問にしているわけです。
全体のフローは、LangChainのWebサイトにある以下の図がわかりやすいです。
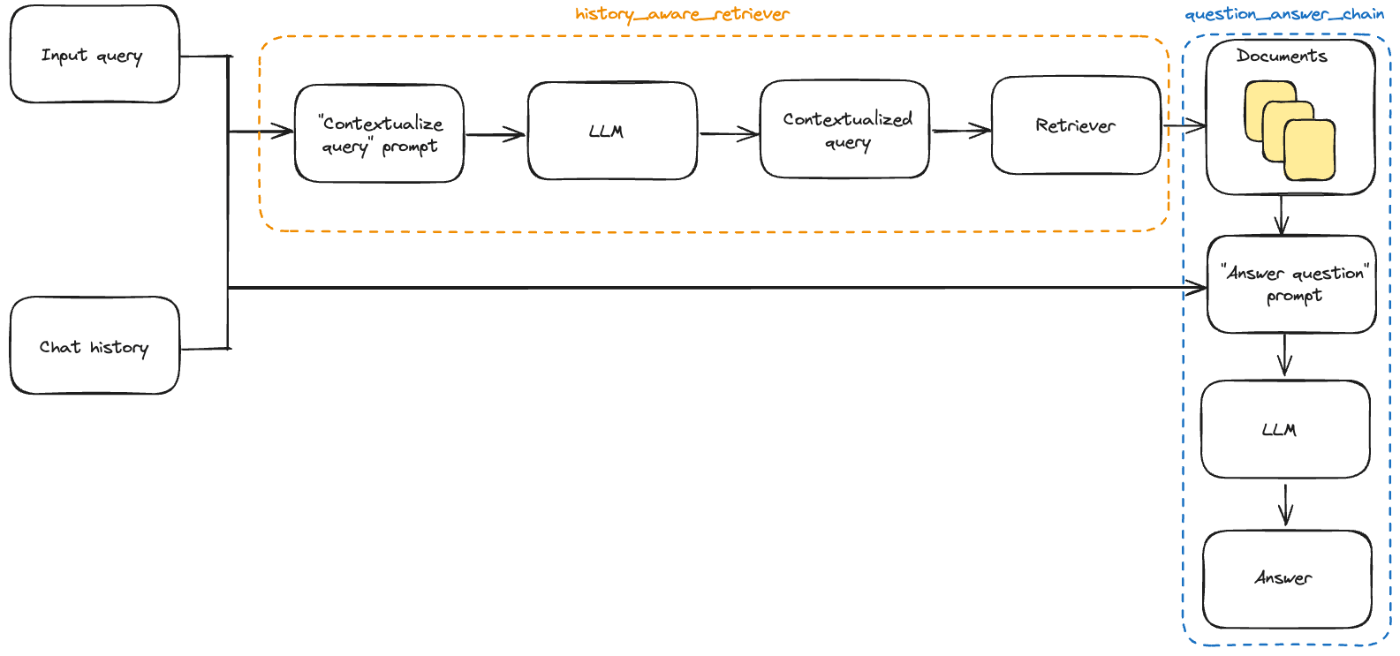
質問のコンテキスト化を含めたRAGチャットボットのフロー(LangChain Webサイトより)
右側が通常のRAGのチェインで、真ん中にあるhistory_aware_retrieverとあるところが、ここまでで説明した質問のコンテキスト化を実現する部分です。会話履歴とユーザーの質問(クエリ)を入力してLLMに渡し、コンテキスト化された質問(図中の"")
質問のコンテキスト化を実現するRAGチャットボットの実装
それでは、質問のコンテキスト化を追加したRAGチャットボットを実装していきます。コード全体は、以下のリポジトリのrag_chatbot3.pyとして置いてあります。
rag_chatbot3.pyは、前回の記事で実装した会話履歴付きRAGチャットボット(上記リポジトリにあるrag_chatbot2.py)をベースに実装します。以下では、質問のコンテキスト化の機能を追加した部分を中心にポイントを絞って解説していきます。
RAGの基本的な部分と、会話履歴付きのRAGチャットボットについては、前回の記事で詳しく解説しています。
動作環境・準備
以下の環境で動作確認をしています。
- Windows10
- Python 3.11.6
- LangChain 0.2.8
- ChromaDB 0.5.4
今回も、前回同様、ベクトルDBのEmbeddingにOpenAIの text-embedding-3-smallを、LLMに Google Gemini 1.5 Flash を利用しています。これらを利用するために、APIキーを環境変数に設定しておいてください。
OPENAI_API_KEY=<OpenAI API Key>
GOOGLE_API_KEY=<Google Gemini API Key>
ベクトルDBにはChromaを利用します。今回は、比較的多くのドキュメントを格納した状態で動作確認をしたかったので、自前のWordpressのブログの全記事をナレッジとして入れています。
この記事で掲載するコードを動作させるには、手元に適当なドキュメントを格納したChromaDBを用意して、以下の例のように環境変数にChromaDBのディレクトリとコレクション名を設定してください。
CHROMA_PERSIST_DIRECTORY="./chroma-db"
CHROMA_COLLECTION_NAME="wpchatbot"
あるいは、コードのChromaDBの部分を適当なベクトルDBなどに置き換えていただいても構いません。最終的に、LangChainのretrieverが用意できれば動作するはずです。
実装
会話履歴とユーザーの新たな質問から、コンテキスト化された質問を生成するには、LLMを利用します。まずLLMに渡すためのプロンプトを準備します。
# コンテキスト化プロンプト
contextualize_q_system_prompt = """Using the chat history and the user's question, create a standalone question that can be understood without the chat history.
formulate the question if necessary; otherwise, return it as is.
**Important!** Do not directly answer the user's question."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
contextualize_q_promptとして、LLMに質問のコンテキスト化を実施してもらうプロンプトを作成します。MessagePlaceholderにはchat_historyとしてこれまでの会話履歴が、{input}にはユーザの新たな質問が入ります。
なお、コードは、前述のLangChainのWebサイトにサンプルとして掲載されているものを借用していますが、システムプロンプトcontextualize_q_system_promptは修正しています。LangChainに掲載されていたもので実行してみたら、単純に質問に答えてしまうことが多かったので、質問に直接答えないようにと強調しています。(これでも完ぺきではないですが、頻度は減りました。)
次に、このプロンプトを利用して、history_aware_retrieverを作成します。
# LLM
chat_model = ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0.0)
# Vector Retriever
retriever = vector_retriever()
# History aware retriever
history_aware_retriever = create_history_aware_retriever(
chat_model,
retriever,
contextualize_q_prompt
)
LLMchat_modelとベクトル検索のretrieverを用意して、create_history_aware_retrieverに渡します。
create_history_aware_retrieverは、会話履歴をもとに質問のコンテキスト化をするチェインを作成する関数です。具体的には、以下のようにチェインを作成します。
- 指定したプロンプト(上の例では
contextualize_q_prompt)に会話履歴chat_historyが含まれれば、そのプロンプトとLLM(上の例ではchat_model)を用いて、コンテキスト化された質問を作成する - 指定したプロンプトに会話履歴が含まれなければ、何もせずにそのままユーザーの入力を出力する
create_history_aware_retrieverについては、LangChainのAPIドキュメントをご確認ください。
# RAG Chain
basic_qa_chain = create_stuff_documents_chain(
llm = chat_model,
prompt = qa_prompt,
)
次に、ユーザーの質問に回答するbasic_qa_chainを作成します。LLMとプロンプトをcreate_stuff_documents_chain関数に渡すと、通常のQAチェインが作成されます。
create_stuff_documents_chainは、promptに指定したプロンプトに含まれるcontext(Documentのリスト)をLLMに渡すチェインを作成する関数です。RAGを実装するときに便利ですね。
最後に、history_aware_retrieverとbasic_qa_chainを連結して、最終的なチェインを作成します。
rag_chain = create_retrieval_chain(history_aware_retriever, basic_qa_chain)
create_retrieval_chainは、retrieverとQAチェインを受け取り、それらを連結してRerieverl QAチェインを作成する関数です。前述のhistory_aware_retrieverは、質問のコンテキスト化だけでなく、コンテキスト化された質問をもとにベクトルDBを検索するretrieverとして動作するところまでを含みますので、ここではretrieverとしてcreate_retrieval_chain関数に与えています。
最後に、rag_chainに会話履歴を付与します。
# Runnable chain を RunnableWithMessageHistory でラップ
runnable_with_history = RunnableWithMessageHistory(
runnable=rag_chain,
get_session_history=get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)
先ほど作成したrag_chainチェインを、RunnableWithMessageHistoryでラップすることで、自動的に会話履歴を付与することができます。
RunnableWithMessageHistoryの引数や動作に関しては、前回の記事で紹介していますので、詳しく知りたい方は以下の記事をご覧ください。
最終的に、ここで作成したrunnable_with_historyに、ユーザーの新たな入力を与えてinvokeすることで、質問のコンテキスト化を実現したRAGチャットボットを実行できます。
質問のコンテキスト化を実現するRAGチャットボットの動作確認
それでは、さっそく動作させてみます。
利用するナレッジとLangSmithの準備
今回も、ナレッジとしては、私が運営する鉄道関連(青春18きっぷ関連)のブログで公開している全記事です。記事のHTMLを<h2>と<h3>でチャンク分割していて、チャック当たりの文字数は平均500文字程度です。
また、動作確認をするうえで、LangSmithを利用すると視覚的に分かりやすく動作を追うことができます。LangSmithを利用するには、LangChainのAPIキーを環境変数LANGCHAIN_API_KEYに設定したうえで、コードに以下を追加します。
# Langchain LangSmith
unique_id = uuid.uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
この状態でコードを実行すると、LangSmithのWebサイトにあるダッシュボードでLangChainの動作を確認することができます。
動作確認
まずはコンソールで動作確認をしてみます。
$ python ./rag_chatbot3.py
---
[0]あなた: 2024年春の青春18きっぷはいつ利用できますか?
AI: 2024年春の青春18きっぷは、2024年3月1日(金)から4月10日(水)まで利用できます。
---
[1]あなた: 夏は?
AI: 2024年夏の青春18きっぷは、2024年7月20日(土)から9月10日(火)まで利用できます。
---
[2]あなた: 価格は?
AI: 2024-25年シーズンの青春18きっぷの価格は、12,050円です。これは大人も子供も同じ価格です。
最初の会話[0]で2024年春の青春18きっぷがいつ利用できるかを聞いています。これに対してRAGチャットボットが正確に答えています。
さらに、[1]では「夏は?」と聞いていますが、これはもちろん「2024年の夏の青春18きっぷはいつ利用できますか?」という意図の質問ですが、これに対しても、そのように質問を解釈して、正確に答えています。
[2]でも同様に、「価格は?」という質問に対して、「青春18きっぷの価格は?」と解釈して、正確に答えています。
LangSmithのダッシュボードで、もう少し詳細なトレースを確認してみます。
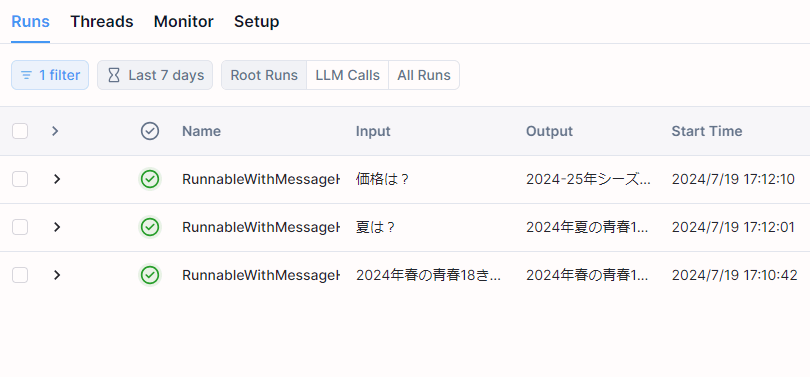
質問のコンテキスト化を追加したRAGチャットボットのトレース
LangSmithを表示させると、上記の3往復分の会話がそれぞれ1行ずつ表示されます。このうち、2番目の「夏は?」の質問について、詳しく見ていきましょう。
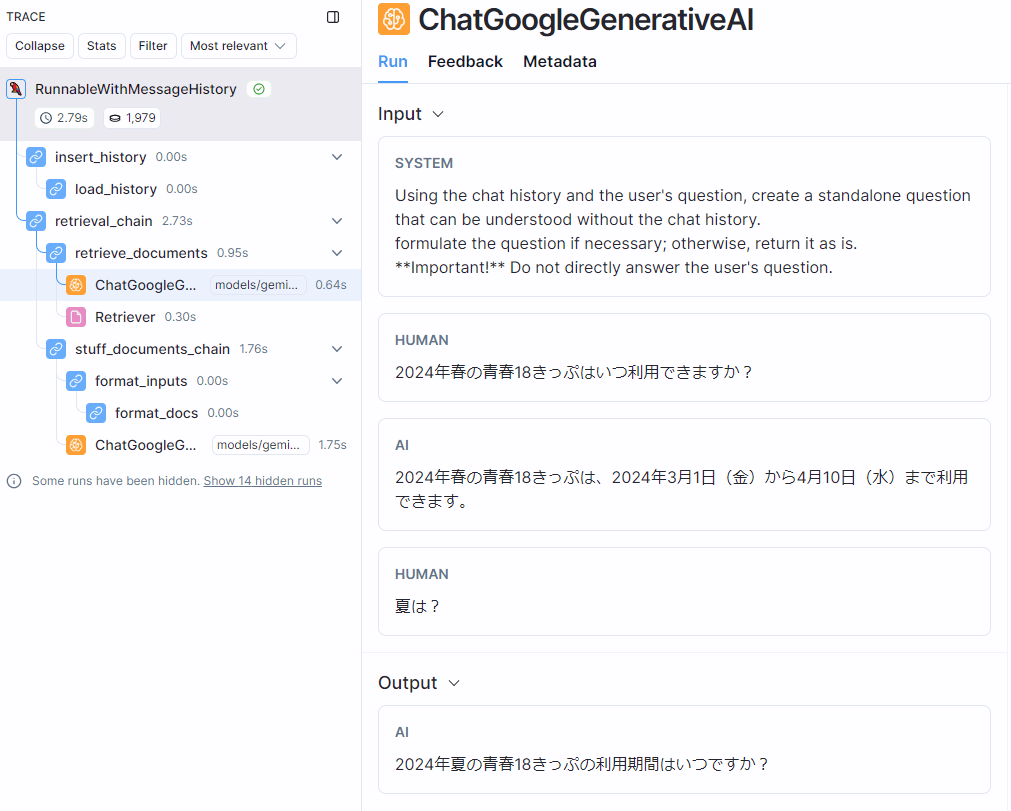
質問のコンテキスト化部分の詳細
左側のフローを見ると、LLMへのクエリが2回発生していることがわかります。1回目が、いわゆる「質問のコンテキスト化」を実施するもので、2回目が最終的にRAGとしてユーザーの質問に回答するためのものです。
図の右側に表示されているのが、1回目の「質問のコンテキスト化」の内容です。システムプロンプトの下にあるのが、これまでの会話履歴と、新たな質問の内容(「夏は?」の部分)です。
これを受け取ったLLMの回答がOutputに示されています。回答は 「2024年夏の青春18きっぷの利用期間はいつですか?」 となっていて、元の「夏は?」という質問が、これまでの会話履歴をもとに、単独で成立する質問に修正されていることがわかります。

最終的なQAクエリの詳細
2回目のLLMのクエリでは、元のユーザーの質問(「夏は?」)ではなく、コンテキスト化された質問「2024年夏の青春18きっぷの利用期間はいつですか?」がクエリとして渡されていて、それに対して、正確に「2024年夏の青春18きっぷは、2024年7月20日(土)から9月10日(火)まで利用できます。」と回答しています。
このように、まず最初に会話履歴を用いて質問をコンテキスト化したあとで、2回目のQAチェインが動作していることがわかります。
他にもいろいろと試してみましたが、1回目の「質問のコンテキスト化」の部分で、LLMが質問を修正するのではなく、質問に答えてしまうことが何度かありました。その場合でも会話履歴をもとに質問に回答しているので、正しい回答になっていることが多いです。
もっとも、これは意図した動作ではないですし、これで回答が正確に得られるのであれば、前回の記事で実装した「単純な会話履歴付きのRAGチャットボット」で十分なわけです。そういう意味では、質問のコンテキスト化のプロンプトを改良する余地はありそうです。
まとめ
会話履歴付きのRAGチャットボットにおいて、会話履歴を考慮した「質問のコンテキスト化」を実現するコードを実装して、動作を確認してみました。
前述のように、完璧な動作ではないものの、意図した動作を確認することができました。最初の質問・回答に対して、ユーザーからより詳細な説明を求める質問や、関連事項に関する質問を受ける可能性が高いチャットボットにおいては、「質問のコンテキスト化」は有利に働くと思われます。「質問のコンテキスト化」により、ナレッジを検索する際に必要な情報量が増えるためです。
一方、「質問のコンテキスト化」のためのLLMへのクエリが発生するため、1ターンの会話につき2回のLLMへのクエリが発生します。当然、トークン数が増えるのでコストはかかりますし、回答に要する時間も長くなります。
ただ、今回、Google Gemini 1.5 Flash で試した限りにおいては、それほど気になるほどの遅延は発生しませんでした。トークン数は確かに増えますが、「質問のコンテキスト化」では会話履歴と新たな質問だけをLLMに渡しているので、トークン数はわずかです。ナレッジから検索したコンテキストが占める割合のほうが圧倒的に大きいので、あまり気にしなくてもよさそうです。
関連記事
会話履歴付きのRAGチャットボットの実装・動作確認を試してみた記事です。本記事の前提となる記事です。
Discussion