ブログ記事の更新が必要な個所を指摘してくれるツールを作ってみた
しばらくRAGをいじっていましたが、今回はちょっと趣向を変えて、ブログ記事の更新が必要な個所を指摘してくれるツールを作ってみました。特に難しい技術を使っているわけではありませんが、生成AIの応用編ということで簡単に紹介します。
ブログ記事の情報最新化は面倒
鉄道関連のブログを個人で運営しているのですが、新たな記事を書くのはともかく、既存の記事の情報を最新化する作業にかなりの時間を取られています。
具体的には、割引きっぷやフリーパスのようなお得なきっぷの情報や、観光列車・臨時列車の運転情報などです。これらの情報は数か月もすると古くなってしまいます。例えば、フリーパスは定期的に鉄道会社から発売されるのですが、利用できる期間や価格、内容が更新されていることが多く、その都度、ブログ記事を手動で更新していました。鉄道会社のニュースリリースを常にウォッチしていて、既存の記事にあるきっぷや列車の新たな情報があれば、記事を手動で更新するといった具合です。
ブログを運営しているくらいですから、文章を書くことは嫌いではないのですが、この「情報を最新化する」というのは本当にただの「作業」にすぎません。
今回は、生成AIを利用して、この作業を効率化するツールを作ってみました。
ツールの概要
今回作成したのは、鉄道会社のニュースリリースのURL(PDFファイルのURL)を入力すると、関連するブログ記事(既存記事)を抽出し、その記事内で更新が必要な箇所を指摘してくれるツールです。
具体的には、以下の2段階で動作するようにしています。
- ニュースリリースのURLを入力し、関連するブログ記事を3つ抽出する
- 3つの記事のうち一つを選択して、変更が必要な箇所を解析する
このように2段階にしたのは、1.の段階で必ずしも最も関連のある記事を抽出できるとは限らないためです。後述するように、1.でニュースリリースの内容と関連の深い記事を抽出する手法として、RAGでも利用されているコサイン類似度によるベクトル検索を利用しています。それなりに関連のある記事を抽出することはできますが、最もコサイン類似度が高い記事が、更新したい記事とは限りません。
いろいろと試した結果、上位3つくらいの記事を抽出すると、その中に更新すべき記事が入っていることが多いとわかりましたので、上位3つを表示させて、人間(=私)がどれを解析するかを選択できるようにしました。
実装
ツールの実装について、簡単に紹介します。今回のツールは、極めて用途が限定されるものであるため、ソースコード全体は公開しませんが、ポイントとなる部分に絞って、本文中で紹介します。
ニュースリリースの内容に関連するブログ記事を抽出する
まず、ニュースリリースの内容に関連性の高いブログ記事を抽出するステップです。
ニュースリリースはPDFファイルで提供されているため、それをダウンロードし、テキストを抽出します。その部分は省略します。
その後、まずはニュースリリースのサマリーを作成します。具体的なコードは以下のとおりです。
from openai import OpenAI
GPT_MODEL = 'gpt-4o-mini'
system_prompt = '''
あなたはユーザが提示するニュースリリースの文章を要約して、ニュース記事風に回答するチャットボットです。
以下の指示どおりに、ニュースリリースのニュース記事を作成してください。
## 指示
* ニュースリリースの内容を元に300文字前後でニュース記事を作成して、summaryに回答してください
* summaryは「です・ます」調のニュース記事風の日本語としてください
* companyにはニュースリリースを発行した会社名を入れてください
* keywordには、このニュースリリースで最も重要なキーワードを3つ選んでください。固有名詞を優先的に選んでください。
* categoryには記事のカテゴリを以下の分類から回答してください
- 分類: お知らせ きっぷ 観光列車 ダイヤ改正 旅行商品 臨時列車 イベント・キャンペーン 安全 経営 その他
* 全てJSON形式で、日本語で回答してください。
'''
assistant_prompt = '''
{"summary": "",
"company": "",
"category": "",
"keyword": []}
'''
def openai_api(text: str):
"""
OpenAI API
"""
client = OpenAI(
timeout=60.0,
max_retries=3,
)
res = client.chat.completions.create(
model=GPT_MODEL,
messages=[
{ 'role': 'system', 'content': system_prompt },
{ 'role': 'assistant', 'content': assistant_prompt },
{ 'role': 'user', 'content': text },
],
response_format={ 'type': 'json_object' },
)
return res
このコードでは、サマリー作成だけでなく、鉄道会社名やキーワードの抽出、カテゴリ分類なども行っているため、JSON形式での回答としています。サマリー作成だけであれば、もっとシンプルなプロンプトでもOKです。
次に、作成したサマリーをもとに、ブログの全記事が格納されているベクトルDBを検索します。ベクトルDBとしてはChromaDBを利用しています。
ブログ記事(HTMLファイル)を適切にチャンキングして、ChromaDBに格納する方法としては、以下の記事で紹介している<h2>タグでチャンク分割する方式を採用しています。
具体的なコードは以下のとおりです。
def retrieve_most_similar_docs(query: str) -> str:
"""Vectorstoreを検索し多くヒットしたブログ記事のタイトルとURLを返す
Args:
query (str): クエリ(ニュースリリースのサマリー)
Returns:
result (str): ブログ記事のタイトルとURL
"""
# ChromaDB
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
client = chromadb.PersistentClient(path="./chroma-db")
vectordb = Chroma(
collection_name="wpchatbot",
embedding_function=embeddings,
client=client,
)
# retrieve docs with score
sub_docs = vectordb.similarity_search_with_relevance_scores(query, k=10)
# cosine distance から最も関連性のありそうなドキュメントを探す
doc_scores = []
for doc in sub_docs:
did = [d for d in doc_scores if d['post_id']
== doc[0].metadata['post_id']]
if did == []:
doc_scores.append(
{'post_id': doc[0].metadata['post_id'],
'title': doc[0].metadata['title'],
'source': doc[0].metadata['source'],
'score': doc[1]}
)
else:
did[0]['score'] += doc[1]
# scoreでソートし上位3つのpost_idを取得
sorted_subdocs = sorted(doc_scores, key=lambda x: x['score'], reverse=True)
ids = [s['post_id'] for s in sorted_subdocs]
if sorted_subdocs:
return sorted_subdocs[:3]
else:
return None
ChromaDBに対して、ニュースリリースのサマリーを入力して、コサイン類似度によるベクトル検索を実施しています。ChromaDBに格納されているブログ記事のチャンクには、メタデータとしてURL(source)やWordpressのPostID(post_id)などが付与されています。
k=10で上位10個のチャンクを抜き出し、同一記事のチャンクが複数抽出された場合は、その記事を優先するため、スコアを加算するようにしています。このようにして、スコアの合計が上位3つの記事を返すようにしています。
ブログ記事の更新が必要な箇所を解析する
ニュースリリースとの関連性が深いと判断された3つのブログ記事のタイトルを表示し、その一つを選択して解析を実施します。
以下の手順で記事の更新が必要かを解析します。
- ブログ記事のURLから全文をダウンロード
- ブログ記事の全文(テキストのみ抽出)とニュースリリースの全文(テキストのみ抽出)をLLMに与え、ブログ記事の更新が必要な箇所を解析してもらう
ブログ記事の全文はChromaDBからも取得可能ですが、チャンクに分割されていて全文を取得するのが面倒なのと、ChromaDBに格納されているブログ記事が必ずしも最新の状態であるとは限らないためです。
前述のニュースリリースと関連性の深い記事を抽出する段階では、ブログ記事の情報が多少古くても、書いてある内容に大きな変更がなければ問題ありません。一方、更新が必要な箇所を指摘してもらう場合には、ブログ記事が最新である必要があります。
また、ニュースリリースの内容もサマリーではなく全文(テキストのみ)を与えます。
LLMに与えるプロンプトは以下のようになります。
prompt_template = """あたなは鉄道関連のブログ記事執筆のエキスパートです。
[新着情報]を読み、[ブログ記事]内で更新が必要な箇所があれば、その箇所を指摘してください。
特に、きっぷや列車の価格・料金、きっぷの有効期間、列車の運行期間、きっぷの効力などに大きな変更があれば、それを指摘してください。
大きな変更がない場合には「更新の必要はありません」と回答してください。
### 新着情報
{news_text}
### ブログ記事
{blog_article}
更新が必要な箇所:"""
新着情報(news_text)にニュースリリースの全文を、ブログ記事(blog_article)に改めて取得した最新のブログ記事の全文を入力します。
プロンプトはとてもシンプルですが、更新が必要な箇所として、特にブログ記事の更新で頻繁に実施する「きっぷや列車の価格・料金、きっぷの有効期間、列車の運行期間、きっぷの効力など」としています。
LLMを呼び出すところでは、以下のようにLangchainを利用しています。
def detect_outdated_content(news_text: str, blog_article: str) -> str:
"""生成AIを用いてニュースリリースの内容から更新が必要な箇所を抽出する
Args:
news_text (str): ニュースリリースの全文テキスト
blog_article (str): ブログ記事の全文テキスト
Returns:
str: 更新が必要な箇所(生成AIの回答)
"""
# モデル定義
model = ChatGoogleGenerativeAI(
model="gemini-1.5-flash",
temperature=0,
)
# prompt
prompt = PromptTemplate(
template=prompt_template,
input_variables=["news_text", "blog_article"],
)
# output parser
output_parser = StrOutputParser()
# chain
chain = prompt | model | output_parser
# invoke
answer = chain.invoke({
"news_text": news_text,
"blog_article": blog_article,
})
return answer
プロンプトとLLMモデル、Output Parserを定義して、それらをChainでつなげるだけのシンプルなものです。
LLMにgemini-1.5-flashを利用していますが、特にこだわりはありません。シンプルなタスクですので、コスパが良く回答が早いモデルを選んだだけです。
動作確認
さっそく動作確認をしてみます。UIはコマンドラインでもよかったのですが、使いやすいようにGradioにしてみました。
まず、JR東日本が発売している「大人の休日倶楽部パス」というきっぷのニュースリリースを入れてみます。
結果は以下のようになりました。
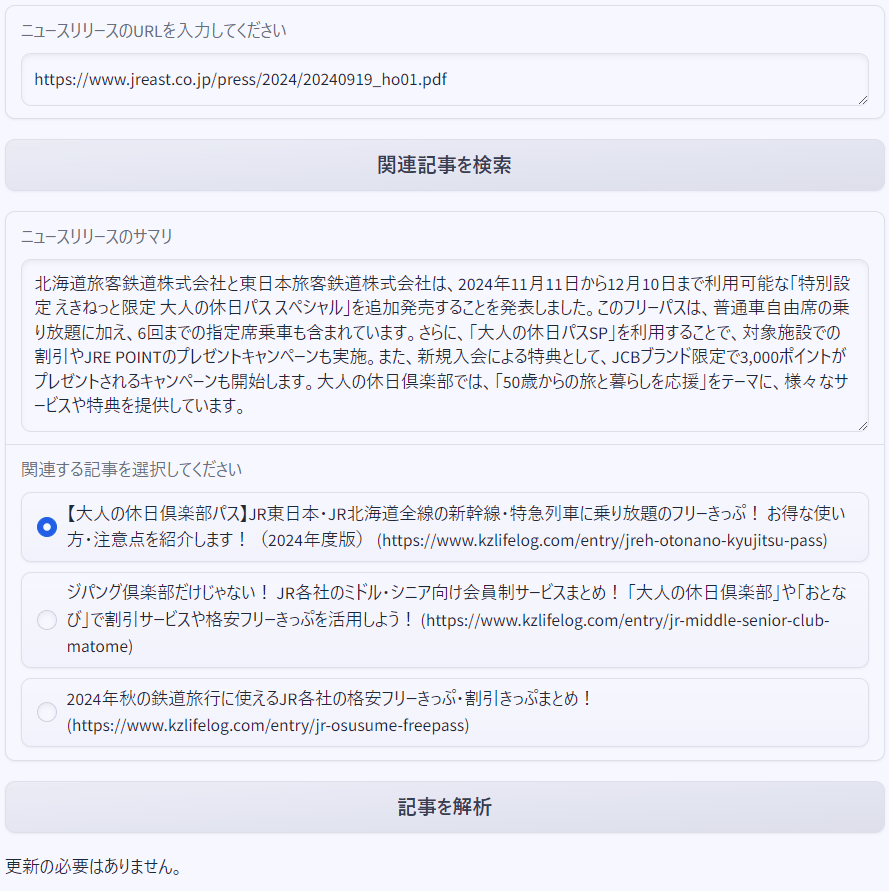
一番上にニュースリリースのURLを入力して「関連記事を検索」を押すと、ニュースリリースのサマリーと関連記事が3つ表示されます。このニュースリリースに関して更新したい記事は、一番上に表示されている 「【大人の休日倶楽部パス】JR東日本・JR北海道全線の新幹線・特急列車に乗り放題のフリーきっぷ! お得な使い方・注意点を紹介します!(2024年度版)」 の記事ですので、これを選択して「記事を解析」を押します。すると、結果として「更新の必要はありません」と出力されました。
今回入力したニュースリリースの内容は、すでに記事に反映済みでしたので、「更新の必要はありません」という回答は正しいものです。ちなみに、ブログ記事は以下のものになります。
次に、同じくJR東日本が発売している「あきたホリデーパス」というフリーきっぷのニュースリリースを入れてみます。
結果は以下のとおりとなりました。
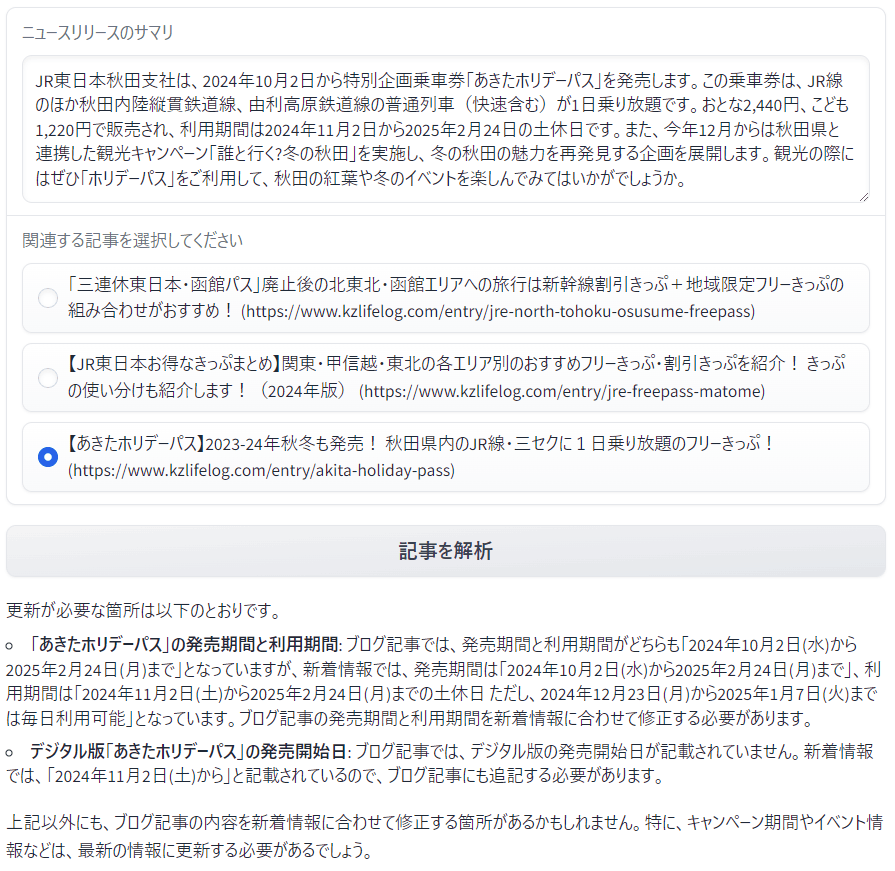
この記事は更新したつもりでいたのですが、発売期間の記述を誤っていたようです。また、デジタル版の発売開始日など他の箇所も指摘されています。
ブログ記事に古い情報が残っていて、それを更新すべきか? だけでなく、記事の元ネタとなっている公式の情報と照らし合わせて、記述に間違いがないかを確認してくれるツールとしても役に立ちそうです。
まとめ
生成AIの(すごく個人的な)活用事例の一つとして、ブログ記事内の更新が必要な箇所を指摘してくれるツールを作ってみました。上で紹介したように、それなりに動作してくれています。
次の目標は、記事の更新まで含めての完全自動化なんですが、ネックになりそうなのは、更新すべき記事を抽出するためのステップです。ベクトル検索を利用していることもあり、数百ある記事の中から、もっとも関連性の高い記事をぴたりと当てるのは難しいですね。今回は、ベクトル検索した結果、関連性の高い3つの記事のから、更新すべき記事を人間(=私)が選ぶようにして、ベクトル検索のあいまい性を回避しました。
いわゆるRAGであれば、多少関係のない内容が抽出されたとしても、LLMが質問回答に必要な情報をピックアップしてくれるのですが、今回のようなツールではそうもいきません。もう少し別の方法を考えないといけないようです。
Discussion