Vercel AI SDKでChrome拡張機能 + ローカルLLMを動かす
はじめに
CursorやClineといったコーディングにLLMを活用するツールが流行りだしていますが、皆さんそろそろ使うだけではなくて自分でLLMを使ったツールを作ってみたいと思うようになってきたのではないでしょうか?
従来、AIの開発はPythonエコシステムが中心でしたが、Webアプリケーションとしての開発効率を考えると、フロントエンドとバックエンドを同じ言語で統一したいケースも多いでしょう。そこで今回は、JavaScriptでAI機能を実装できるVercel AI SDKを紹介します。
Vercel AI SDKは、WebアプリケーションでLLM機能を簡単に利用できるようにするためのSDKです。クライアントとサーバー間の実装を簡略化し、チャットのようなUIを含めたAI機能の実装を容易にします。これにより、開発者は複雑なLLMモデルの統合を気にすることなく、アプリケーションのコア機能の開発に集中できます。
本記事では、Vercel AI SDKの基本的な使い方と、応用としてChrome拡張機能での活用方法について解説します。
AI SDKの基本的な使い方
2025-05-21 追記:GitHub Modelsのエンドポイント、モデルIDの指定方法が変更されたためサンプルコードを最新化。
バックエンド(Hono + GitHub Models)
まずはバックエンドでVercel AI SDKを使ってみましょう。LLMにはGitHub Modelsを利用してテキストを生成してみます。
GitHub Modelsは、GitHubが開発者向けに提供してくれている様々なLLMモデルを簡単にお試しできるサービスです。コンテキスト長などの制限があるためプロダクション用途には向かないですが、GitHubのトークンさえあれば無料で利用できるので今回のようなお試し用途には最適です。
Webサーバーは普段使い慣れているもので大丈夫ですが、今回はHonoを使います。AI SDKの generateText でLLMを呼び出してテキストを生成してもらうことが可能です。
// server.ts
import { Hono } from 'hono';
import { serve } from '@hono/node-server'
import { createOpenAI } from '@ai-sdk/openai';
import { generateText } from 'ai';
const app = new Hono();
// OpenAIモデルのインスタンスを作成
const model = createOpenAI({
baseURL: 'https://models.github.ai/inference',
apiKey: process.env.GITHUB_TOKEN
}).chat('openai/gpt-4o');
app.post('/generate', async (c) => {
// リクエストボディからプロンプトを取得
const { prompt } = await c.req.json<{ prompt: string }>();
// LLMを使用してテキストを生成
const { text } = await generateText({ model, prompt, });
return c.json({ text });
});
const PORT = 3000;
serve({
fetch: app.fetch,
port: PORT
})
console.log(`Server running at http://localhost:${PORT}/`);
利用しているLLMの提供元(プロバイダー)はGitHub Modelsなのに createOpenAI といういかにもOpenAI用のものを利用していますが、GitHub ModelsはOpenAIのAPIと互換性があるのでこれで問題ありません。GitHub Modelsが提供している全てのモデルが同様に利用可能かどうかまでは確認していないですが、少なくともGPT-4oに関してはGitHub Models上でGPT-4oを選択したときのjsのサンプルコードではOpenAIの公式SDKを利用しているので問題ないようです。
このように、AI SDKでは各LLMのプロバイダー用にそれぞれのAPIをラップした createXXX が提供されています。そしてテキストを生成する generateText や後述の streamText などに modelを渡すことで、ユーザーが各LLMサービスごとのAPIを意識することなくLLMの機能を利用可能にしてくれています。この特性の利便性は後ほど再び触れます。
実際にサーバーを動かして動作確認するにはこんな感じです。上記のコードはTypeScriptで書いていますが、Node.js v22からサポートされた --experimental-strip-types オプションを付けることでjsにトランスパイルしなくても直接実行可能です。
# ghのトークンをGITHUB_TOKENにセット
export GITHUB_TOKEN=$(gh auth token)
# サーバーを起動
node --experimental-strip-types server.ts
# 別のターミナルを開いてPOSTでJSONを送信
$ curl -X POST --json '{"prompt":"日本の首都はどこですか?"}' http://localhost:3000/generate
{"text":"日本の首都は **東京(とうきょう)** です。東京は日本の政治、経済、文化の中心地であり、世界的にも重要な都市の一つとされています。また、1868年の明治維新以降、京都から東京に首都機能が移されました。それ以来、東京が日本の首都としての役割を果たしています。"}
GITHUB_TOKEN だけでGitHub ModelsからGPT-4oのLLMを利用できている様子が確認できましたね。
フロントエンド(React + useChat)
ReactでAI SDKを使うと useChat hooksを利用することで、よく見るチャットUIを簡単に実装できます。useChat はメッセージの送受信、State管理、ローディング表示のためのStateなど、チャット型のUIに必要な機能を一通り提供してくれています。
まずは npm create vite@latest でViteを使うフロントエンドのプロジェクトを作成します。そして元のApp.tsxを完全に置き換えてAI SDKを使うチャットのUIを超簡易的に実装してみます。
// App.tsx
import { useChat } from '@ai-sdk/react';
export default function Chat() {
const { messages, input, handleInputChange, handleSubmit } = useChat({
// バックエンドのエンドポイントを指定
api: 'http://localhost:3000/api/chat',
});
return (
<div>
{messages.map(message => (
<div key={message.id}>
{message.role === 'user' ? 'User: ' : 'AI: '}
{message.content}
</div>
))}
<form onSubmit={handleSubmit}>
<input
name="prompt"
placeholder="質問を入力してください"
value={input}
onChange={handleInputChange}
/>
<button type="submit">送信</button>
</form>
</div>
);
}
なんとこれだけのコードで最低限のチャットUIが完成します。 useChat は api を省略するとフロントエンドが動いているサーバーの /api/chat にリクエストしますが、今の構成ではViteのdevサーバーを向いてしまうので、先ほど作成したHonoのバックエンドを向くように localhost:3000/api/chat を指定する必要があります。
useChat の接続先であるバックエンドはストリーミングでレスポンスを返す必要があります。これもAI SDKが用意してくれている streamText 関数を使うことで、LLMの結果をストリーミングで返すことが可能です。
// server.ts
import { Hono } from 'hono';
import { serve } from '@hono/node-server'
import { cors } from 'hono/cors'
import { createOpenAI } from '@ai-sdk/openai';
import { streamText } from 'ai';
const app = new Hono();
// クライアントはviteのサーバーでlocalhost:5173で動かしているためCORSを許可する必要がある
app.use('/api/*', cors())
// OpenAIモデルのインスタンスを作成
const model = createOpenAI({
baseURL: 'https://models.github.ai/inference',
apiKey: process.env.GITHUB_TOKEN
}).chat('openai/gpt-4o');
// /api/chatエンドポイントを追加
app.post('/api/chat', async (c) => {
const { messages } = await c.req.json();
const result = streamText({
model,
system: 'You are a helpful assistant.',
messages,
});
return result.toDataStreamResponse();
});
const PORT = 3000;
serve({
fetch: app.fetch,
port: PORT
})
console.log(`Server running at http://localhost:${PORT}/`);
実際にフロントエンドとバックエンドを起動して動作確認してみましょう。
# ghのトークンをGITHUB_TOKENにセット
export GITHUB_TOKEN=$(gh auth token)
# バックエンドのHonoサーバーを3000ポートで起動
node --experimental-strip-types server.ts
# フロントエンドのViteサーバーを5173ポートで起動
npx vite
CSSを一切当てていないのでこれ以上ないくらい簡素なUIですが、ちゃんとチャットでLLMに質問できてストリーミングで返答をちょっとずつ表示できていることが確認できます。
このデモでは基本的なチャット機能のみを実装しましたが、AI SDKを使えば最小限のコードでチャットUIの土台を作れることが確認できました。実用的なUIにするにはMarkdownのレンダリングなど、追加の実装が必要です。
ローカルマシンで動かすLLMに切り替える(Hono + Ollama)
ここまではGitHub Modelsを使っていましたが、ローカルマシンで動かすLLM(以後ローカルLLMと書きます)に切り替えてみましょう。先ほどまでのバックエンドのコードで @ai-sdk/openai を使っていましたが、これを ollama-ai-provider に変更します。
AI SDKはLLMに呼び出す部分をProvidersという形で別パッケージにしており、公式がサポートしている有名どころのLLMサービスに加えてコミュニティが作成したProviderも存在します。ローカルLLMを動かすためのツールは色々ありますが、今回は手軽なOllamaを使っているという前提で説明します。
まずはOllamaを起動し、何かしらのモデルをダウンロードしておいてください。今回は執筆時点で出たばかりのgemma3を ollama pull gemma3 でダウンロードしておきます。次にバックエンドのコードを少し変更し @ai-sdk/openai の代わりにollama-ai-provider を使います。
// server.ts
import { Hono } from 'hono';
import { serve } from '@hono/node-server'
import { cors } from 'hono/cors'
// import { createOpenAI } from '@ai-sdk/openai';
import { createOllama } from 'ollama-ai-provider';
import { generateText, streamText } from 'ai';
const app = new Hono();
// クライアントはviteのサーバーでlocalhost:5173で動かしているためCORSを許可する必要がある
app.use('/api/*', cors())
// OpenAIモデルのインスタンスを作成
// const model = createOpenAI({
// baseURL: 'https://models.github.ai/inference',
// apiKey: process.env.GITHUB_TOKEN
// }).chat('openai/gpt-4o');
// Ollamaモデルのインスタンスを作成
const model = createOllama({
baseURL: 'http://localhost:11434/api'
}).chat('gemma3')
// /api/chatエンドポイントを追加
app.post('/api/chat', async (c) => {
const { messages } = await c.req.json();
const result = streamText({
model,
system: 'You are a helpful assistant.',
messages,
});
return result.toDataStreamResponse();
});
const PORT = 3000;
serve({
fetch: app.fetch,
port: PORT
})
console.log(`Server running at http://localhost:${PORT}/`);
修正が必要だったのは createOpenAI の部分だけですね。このようにAI SDKではProviderのパッケージを切り替えるだけでLLMを変更可能です。
これで先ほどと同様にバックエンドとフロントエンドのサーバーを起動すると、Ollamaによって動いているgemma3がチャットに返答してくれるはずです。ローカルLLMは自分のPCで動いているので、GitHubに通信が必要であったGitHub Modelsとは異なりネットワークを切断したオフラインの環境でも動作します。
Chrome拡張機能でAI SDKを使う
さて、実はここまでが前振りでここからが本題です。
ここまで読んでくれたみなさんはきっとAI SDKを作ってLLMを使う何かのアプリを作りたくなってきたはずです。単にチャットUIのアプリを再実装するだけではつまらないので普段の業務を効率化する何かを作りたいと思いませんか?例えば、社内ドキュメントの検索や議事録の作成など、普段の業務で地味に時間がかかっていることをLLMにサクッと投げられると面白そうです。
しかし、普段の業務で使っているのは何らかのSaaSであることが多いでしょうから、そこに独自の機能を組み込むことは基本的にはできないです。社内で独自に開発しているシステムであれば拡張可能ですが、業務データをLLMを提供している外部に渡すことが許可されるかは業種やデータの性質だと思われます[1]。
この2つの問題を同時に解決できるのがChrome拡張機能です。Chrome拡張機能ならばSaaSのサービスでもUIやAPIを外部から拡張でき、さらにLLMをローカルマシン上で実行させれば業務データを外部に渡さずLLMの機能を利用できます。AI SDKを利用すればLLMの活用は簡単で、jsですのでChrome拡張との相性もバッチリです。
Chrome拡張機能での制約
さて、では実際にChrome拡張を作成してみましょう。UIをどうするかも考えどころですが、今回はシンプルにChromeのサイドバーに先ほどの useChat を使うフロントエンドのコードを流用してチャットUIを表示してみます。
<!-- sidebar.html -->
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>AI Chat</title>
</head>
<body>
<div id="root"></div>
<script type="module" src="sidebar.js"></script>
</body>
</html>
// sidebar.tsx
import React from 'react'
import ReactDOM from 'react-dom/client'
import { useChat } from '@ai-sdk/react'
const Sidebar = () => {
const { messages, input, handleInputChange, handleSubmit } = useChat({
// バックエンドではなくローカルを向くようにしてみる
api: '/api/chat',
});
return (
<div className="sidebar">
<h1>AI Chat</h1>
<div className="chat-container">
{messages.map(message => (
<div key={message.id} className="message">
<strong>{message.role === 'user' ? 'あなた: ' : 'AI: '}</strong>
<div>{message.content}</div>
</div>
))}
</div>
<form onSubmit={handleSubmit} className="input-form">
<input
name="prompt"
placeholder="質問を入力してください"
value={input}
onChange={handleInputChange}
className="chat-input"
/>
<button type="submit" className="submit-button">送信</button>
</form>
</div>
)
}
ReactDOM.createRoot(document.getElementById('root')!).render(
<React.StrictMode>
<Sidebar />
</React.StrictMode>
)
このコードをViteでビルドしてChrome拡張としてパッケージして実行してみると、チャットのリクエストがエラーになっています。
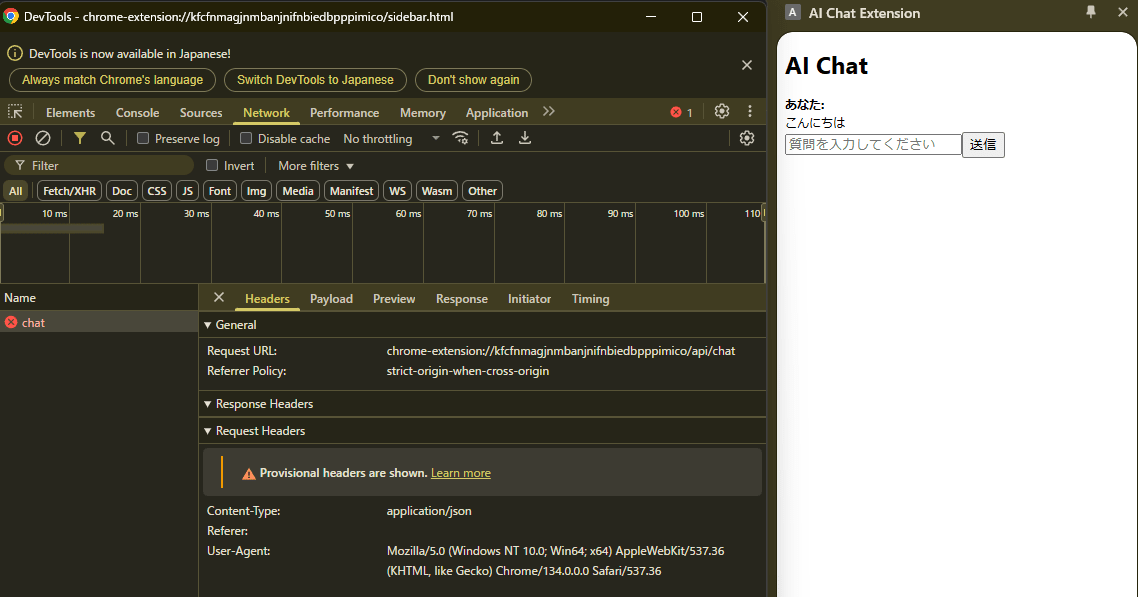
バックエンドサーバーを用意せずにChrome拡張機能だけで完結させたいためuseChat()のapiをローカルパスに変更したことで、リクエストはChrome拡張機能のURL(chrome-extension://...)に向けて送信されるようになりました。しかし、そのリクエストを処理するコードが存在しないためエラーになったようです。
useChatは、クライアント(ブラウザ)からサーバーサイドのAPIエンドポイントにリクエストを送信し、そのレスポンスを処理するという前提で設計されています。そのため、サーバーを立てられないChrome拡張機能では、そのままでは利用できません。
Service Workerによるfetch横取りによる実現
この問題を解決するために、Service Workerを活用する方法を思いつきました。Chrome拡張機能ではService Workerを利用できるので、これを使ってfetchリクエストを横取りする仕組みを実装します。具体的には、Service Workerでfetchイベントを監視し、useChat からの /api/chat へのリクエストに対してAI SDKのstreamText のレスポンスを返すようにします。これによりuseChatからはstreamTextを実行するバックエンドサーバーからレスポンスが返ってくるのと同じように見えるので、問題なく動作するはずです。
// background.ts
import { createOllama } from 'ollama-ai-provider';
import { streamText } from 'ai';
// Ollamaモデルのインスタンスを作成
const model = createOllama({
baseURL: 'http://localhost:11434/api'
}).chat('gemma3');
// Service Workerのイベントリスナーを設定
// @ts-ignore
self.addEventListener('fetch', (event: FetchEvent) => {
// useChatのリクエストを横取り
if (event.request.url.endsWith('/api/chat')) {
event.respondWith(handleChat(event.request));
}
});
async function handleChat(request: Request) {
try {
const { messages } = await request.json();
const result = streamText({
model,
system: 'You are a helpful assistant.',
messages,
});
return result.toDataStreamResponse();
} catch (error) {
console.error('Chat error:', error);
return new Response(JSON.stringify({ error: String(error) }), {
status: 500,
headers: { 'Content-Type': 'application/json' }
});
}
}
このService Workerを先ほどのサイドバーだけであったChrome拡張機能のコードに追加して実行してみます。
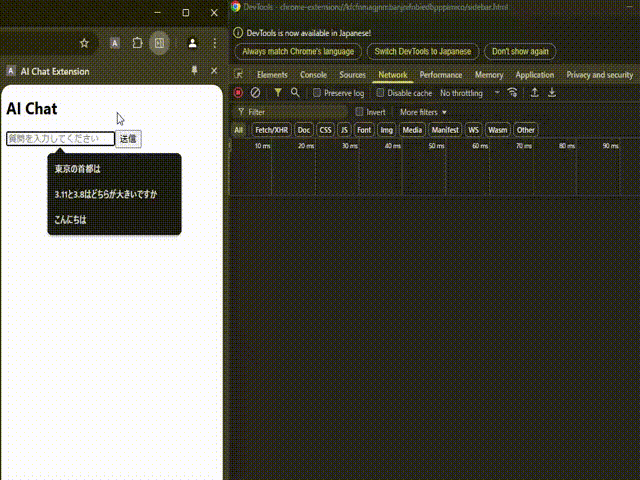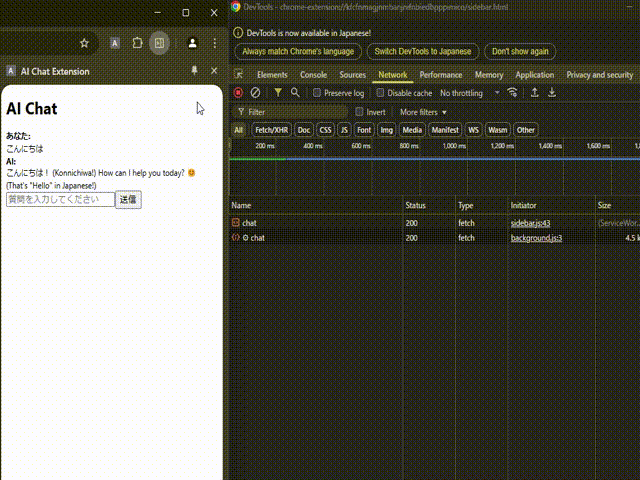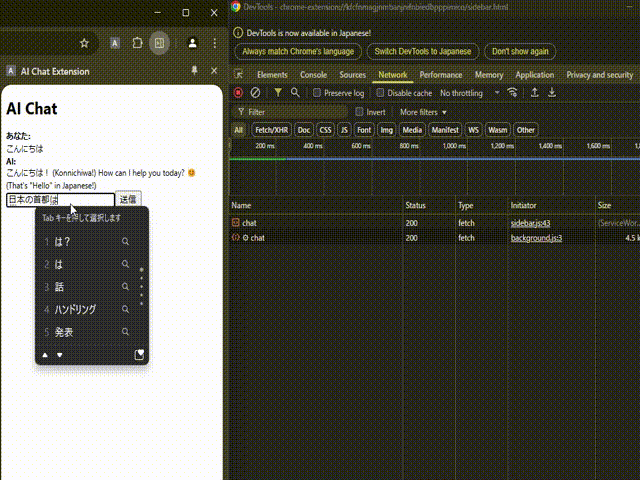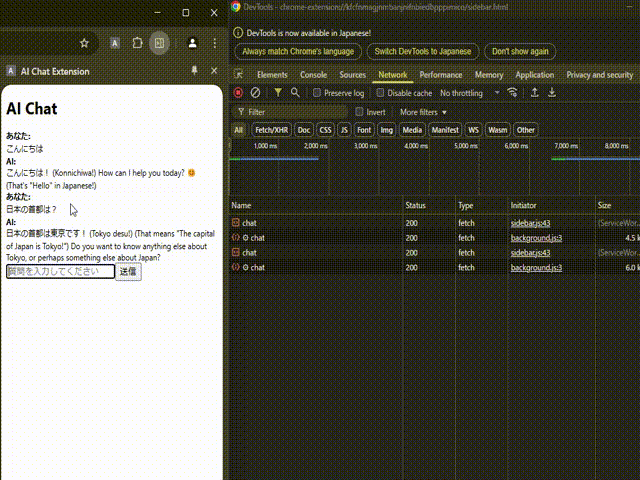
今度はちゃんとLLMからのレスポンスが返ってきていますね!ネットワークリクエストを見てみるとService Workerであるbackground.jsからちゃんとレスポンスが返ってきていることも確認できます。
このようにして、ちょっとだけ工夫が必要ですがChrome拡張機能でも通常のAI SDKの使い方とほぼ同様にLLMの機能を組み込むことができました。後はChrome拡張のAPIを駆使して拡張したいサービスのUIを拡張したり、DOMからテキストを抽出してLLMに処理させるなどアイディア次第で色々なことができると思います。
まとめ
本記事では、Vercel AI SDKの基本的な使い方と、Chrome拡張機能での活用方法について解説しました。AI SDKを使うことで、JavaScriptでもAIアプリケーションを比較的簡単に開発できます。また、Chrome拡張機能として実装すれば社内システムに手を加えることなくLLMの機能を活用できますし、独立して開発できるため社内システムに実際にLLMの機能を追加する前のPoC作成としても有用でしょう。
今後は、ローカルで実行できるモデル(DeepSeek-R1やgemma3など)の性能向上とNPUや大容量のVRAMを搭載するノートPCの普及により、OpenAIやAnthropicなどのLLMサービスを利用せずとも実用的なAIアプリケーションを開発できるようになるとも思われます[2]。
付録
最後のChrome拡張のサンプルコード全体を載せておきます。
sidebar.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>AI Chat</title>
</head>
<body>
<div id="root"></div>
<script type="module" src="sidebar.js"></script>
</body>
</html>
sidebar.tsx
import React from 'react'
import ReactDOM from 'react-dom/client'
import { useChat } from '@ai-sdk/react'
const Sidebar = () => {
const { messages, input, handleInputChange, handleSubmit } = useChat({
api: '/api/chat',
});
return (
<div className="sidebar">
<h1>AI Chat</h1>
<div className="chat-container">
{messages.map(message => (
<div key={message.id} className="message">
<strong>{message.role === 'user' ? 'あなた: ' : 'AI: '}</strong>
<div>{message.content}</div>
</div>
))}
</div>
<form onSubmit={handleSubmit} className="input-form">
<input
name="prompt"
placeholder="質問を入力してください"
value={input}
onChange={handleInputChange}
className="chat-input"
/>
<button type="submit" className="submit-button">送信</button>
</form>
</div>
)
}
ReactDOM.createRoot(document.getElementById('root')!).render(
<React.StrictMode>
<Sidebar />
</React.StrictMode>
)
background.ts
import { createOllama } from 'ollama-ai-provider';
import { streamText } from 'ai';
// Ollamaモデルのインスタンスを作成
const model = createOllama({
baseURL: 'http://localhost:11434/api'
}).chat('gemma3');
// Service Workerのイベントリスナーを設定
// @ts-ignore
self.addEventListener('fetch', (event: FetchEvent) => {
// useChatのリクエストを横取り
if (event.request.url.endsWith('/api/chat')) {
event.respondWith(handleChat(event.request));
}
});
async function handleChat(request: Request) {
try {
const { messages } = await request.json();
const result = streamText({
model,
system: 'You are a helpful assistant.',
messages,
});
return result.toDataStreamResponse();
} catch (error) {
console.error('Chat error:', error);
return new Response(JSON.stringify({ error: String(error) }), {
status: 500,
headers: { 'Content-Type': 'application/json' }
});
}
}
manifest.json
{
"manifest_version": 3,
"name": "AI Chat Extension",
"version": "1.0",
"description": "Chrome拡張でLLMとチャットができます",
"permissions": [
"sidePanel"
],
"background": {
"service_worker": "background.js",
"type": "module"
},
"action": {
"default_title": "AI Chat"
},
"side_panel": {
"default_path": "sidebar.html"
}
}
vite.config.ts
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react'
import { resolve } from 'path'
import { copyFileSync } from 'fs'
export default defineConfig({
plugins: [
react(),
{
name: 'copy-files',
writeBundle() {
copyFileSync(
resolve(__dirname, 'src/manifest.json'),
resolve(__dirname, 'dist/manifest.json')
)
copyFileSync(
resolve(__dirname, 'src/sidebar.html'),
resolve(__dirname, 'dist/sidebar.html')
)
}
}
],
build: {
rollupOptions: {
input: {
sidebar: resolve(__dirname, 'src/sidebar.tsx'),
background: resolve(__dirname, 'src/background.ts'),
},
output: {
entryFileNames: '[name].js',
chunkFileNames: 'vendor-[hash].js',
assetFileNames: '[name].[ext]'
}
},
outDir: 'dist',
emptyOutDir: true
}
})
Discussion
こんにちは!
service workerの知見とてもためになりました!ありがとうございます。
一点気になったことがあったので質問させていただきます!
Chromeに組み込まれているGemini Nanoは使ってみましたでしょうか?
こちらだと通信が必要ないためもしかしたら簡単かもしれません。
やはりモデルサイズが小さいため十分な精度が得られなかったでしょうか?
Gemini Nanoは存在は知っていましたが使ったことはなかったです。
というのもここ半年の間だけでもgemma3のようなオープンモデルは数ヶ月ごとにより賢いモデルが公開され続けているので、自分はそれらをずっと試していたからです。
この機会に試してみようと思ってやってみたのですが、flagsで必要なものをオンにしてもchrome://componentsの方でOptimization Guide On Device Modelという必要な設定がなぜか表示されなくて自分は試すことができませんでした・・・
おそらくこのChromeのGemini nano用と思われるAI SDKのproviderもコミュニティで作成されているようなので、将来Stable版に降りてきて誰でも使えるようになったらまた面白いことになるかもしれないですね。