AWS Glueに入門してみた
以下の本を参考にAWS Glueに入門させていただきました。
ただ2020年7月とかに出ている本だったためAWS ConsoleのCrawler作成画面やJob作成画面が結構変わっている部分があったのでその辺りを補完しつつまとめようと思います。
AWS Glue Crawler、DataCatalog、Athena
AWS Glue CrawlerからDataCatalogを作成、Athenaで分析まで試してみた。
その際、AWS Glue Clawlerの作成画面は以下のように更新されており少し戸惑ったのでメモ。
-
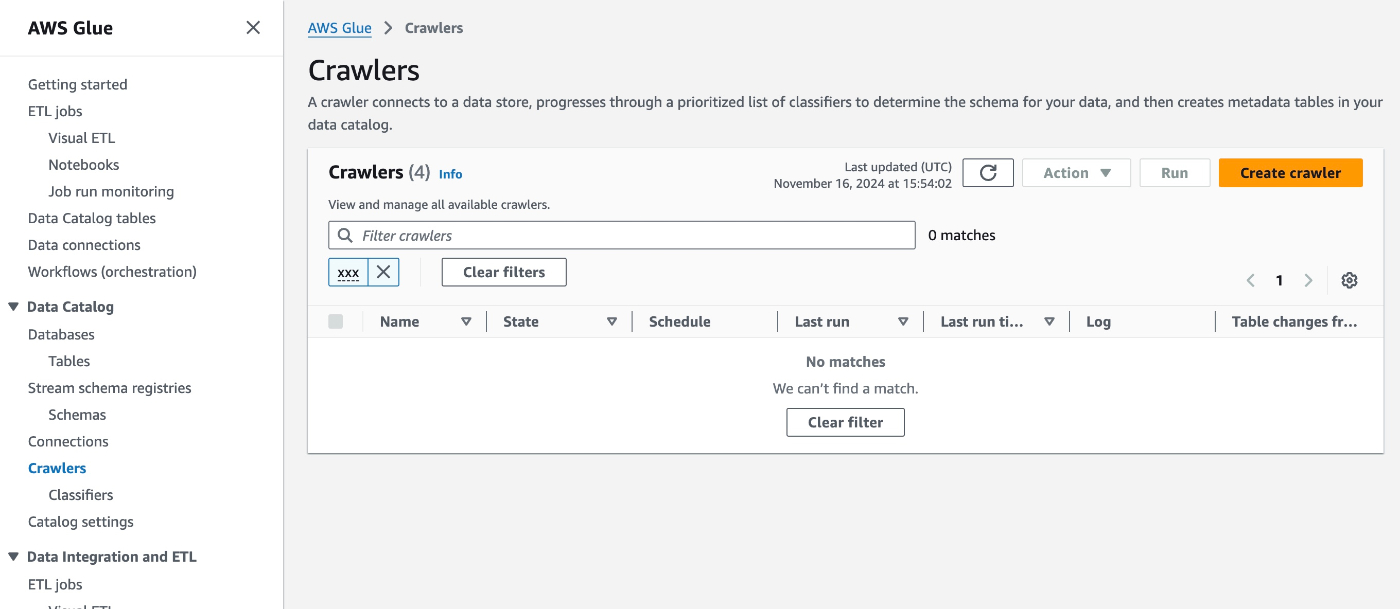
Create Clawlerから作成画面へ
-
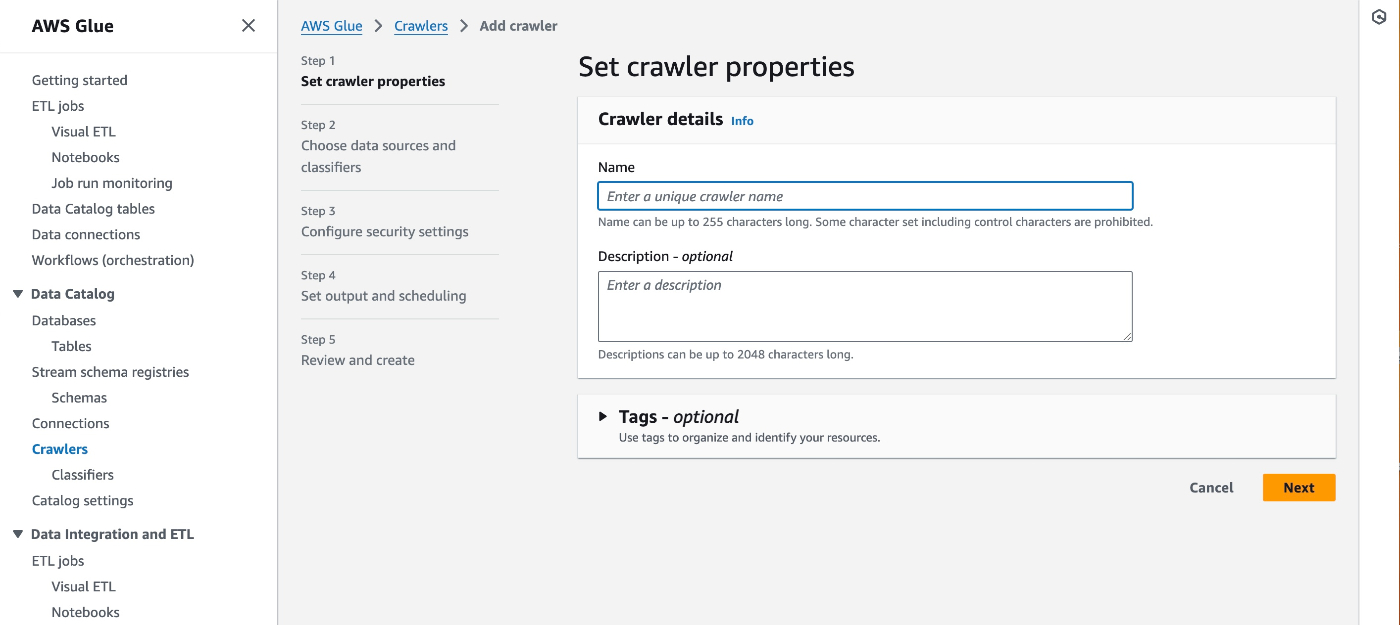
5ステップで作成するような画面に変わっていた。ここではクローラ名だけ設定。
-
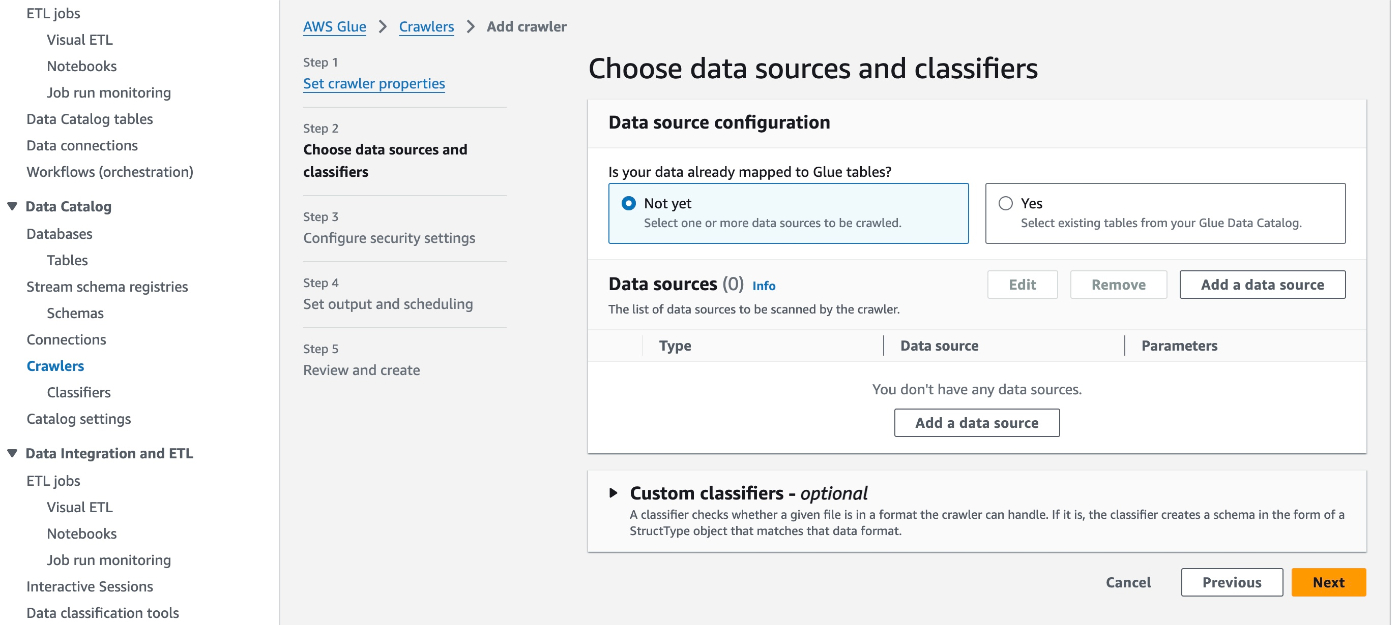
データソースを設定する。
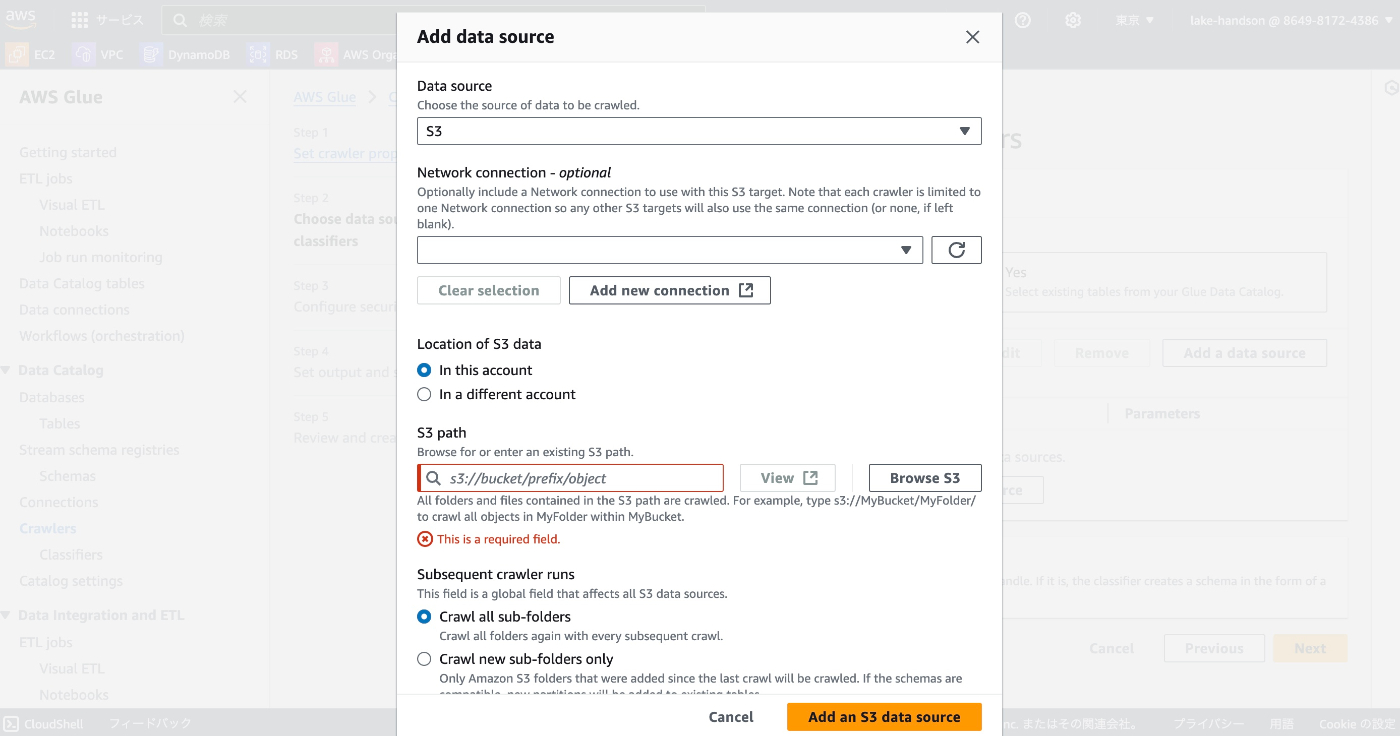
S3を設定する場合は、S3 URIを設定する。(それ以外の場合はおそらくConnectionsを設定する)
-
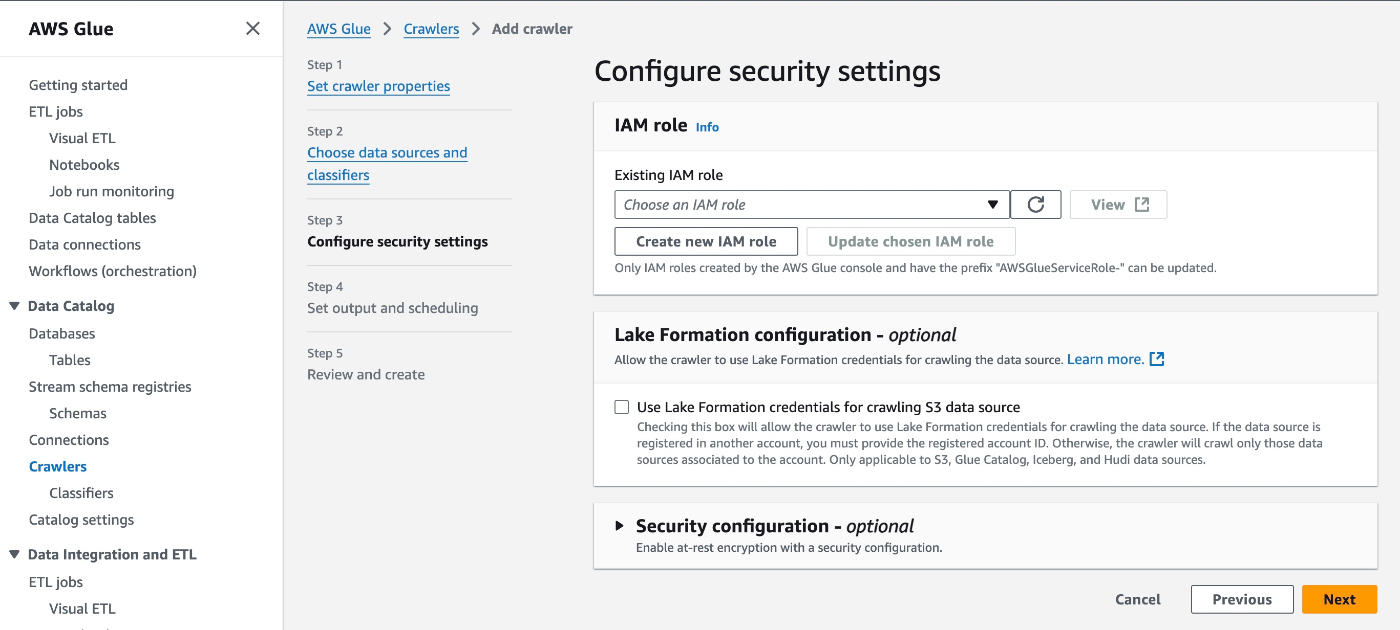
実行Roleを作成する。
"Create new IAM Role"から作成すると、S3の場合設定したS3 URIへのアクセスを許可するIAM Roleが自動で作成される。
-
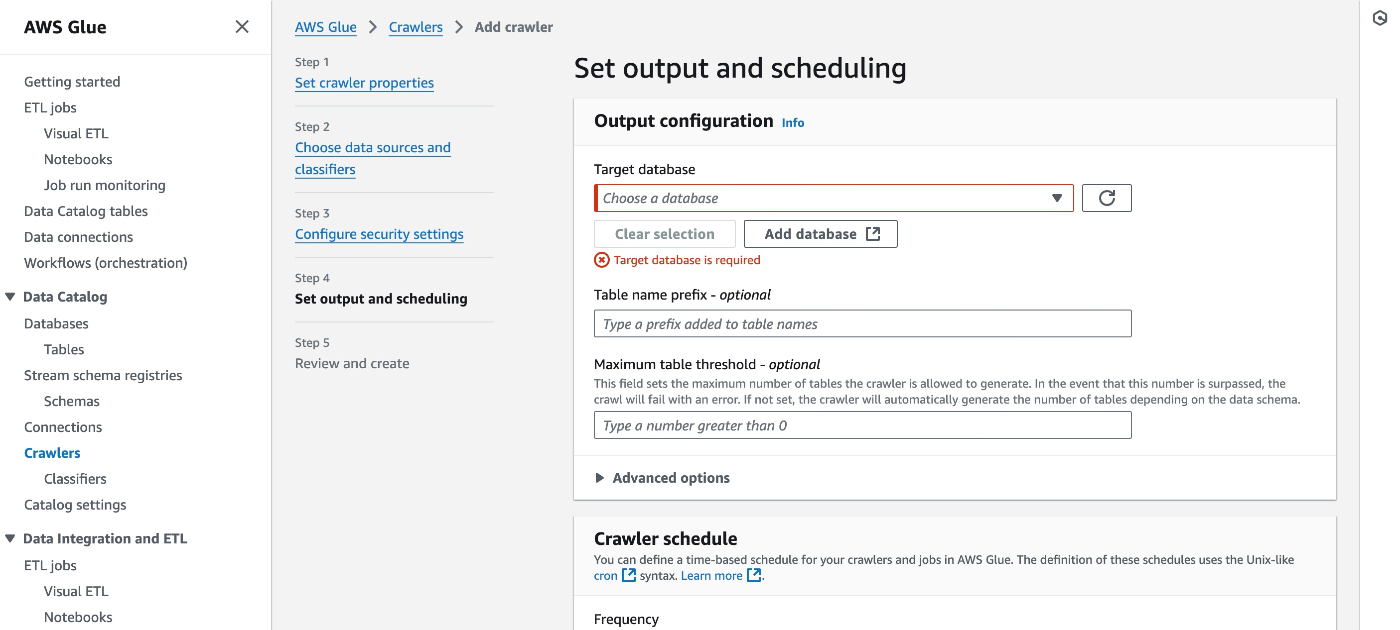
データベースの作成、紐付けを行う。
データベースが未作成なら、Add databaseから作成できる。ここでいうデータベースとは、AWS Glue DataCatalogで管理されるテーブル(メタ情報)をまとめる論理的なグループという感じ。prefixは"projectA_"としておくとS3なら"projectA_<S3 URIの最後のディレクトリ名>"のような命名でテーブルが作成される。
以上で、DataCatalogにてテーブルが作成されるが、テーブルの確認画面やAthenaからの分析画面は大きく変化はなかった。
Visual ETLの使い方
AWS Glue Jobの作成に移っていくが、ここもUIが変わっていて簡易的なジョブを作るにはVisual ETLを触ってみるしかなかったため手順を記載する。
-
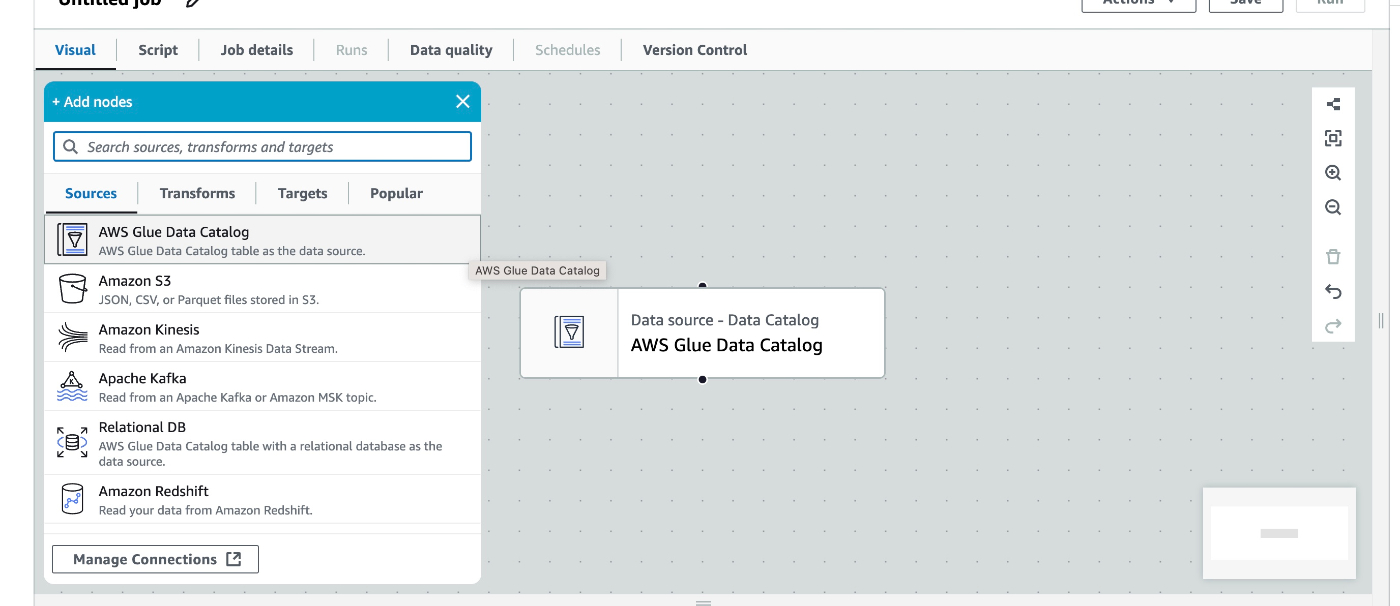
sourceをData Catalogとする。
これは一つ前の手順でS3をデータソースにしたテーブルを作成していたためデータカタログをソースとすることができる。
-
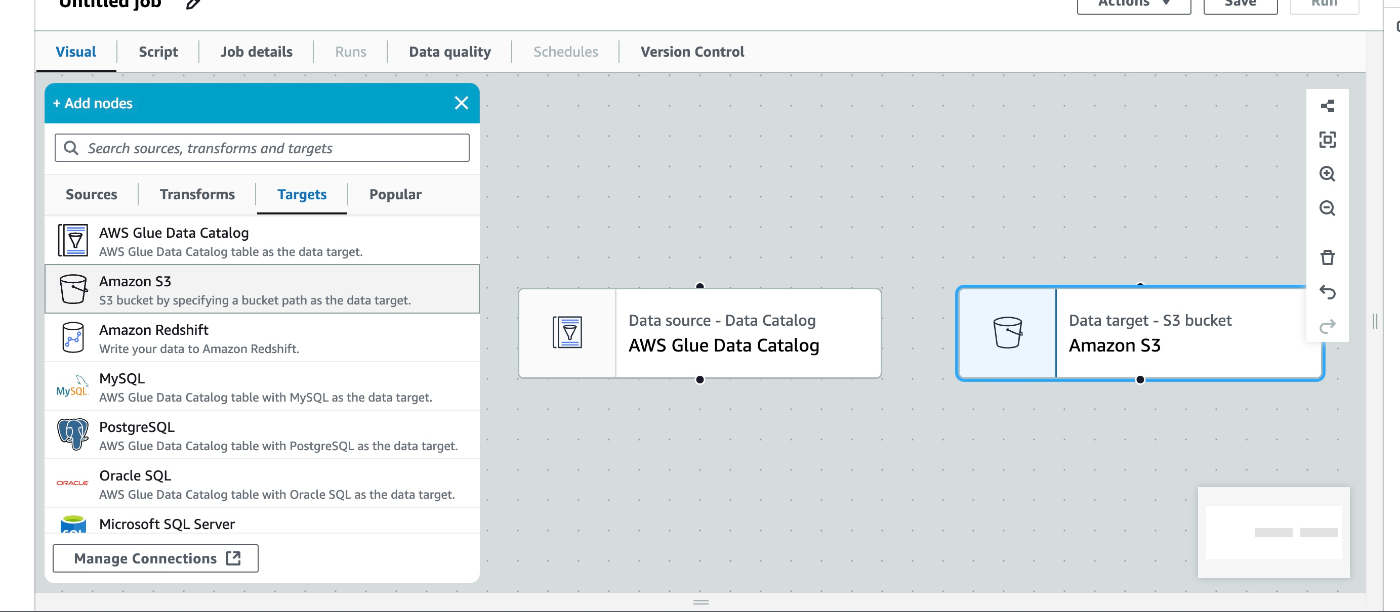
targetはS3とする。
-
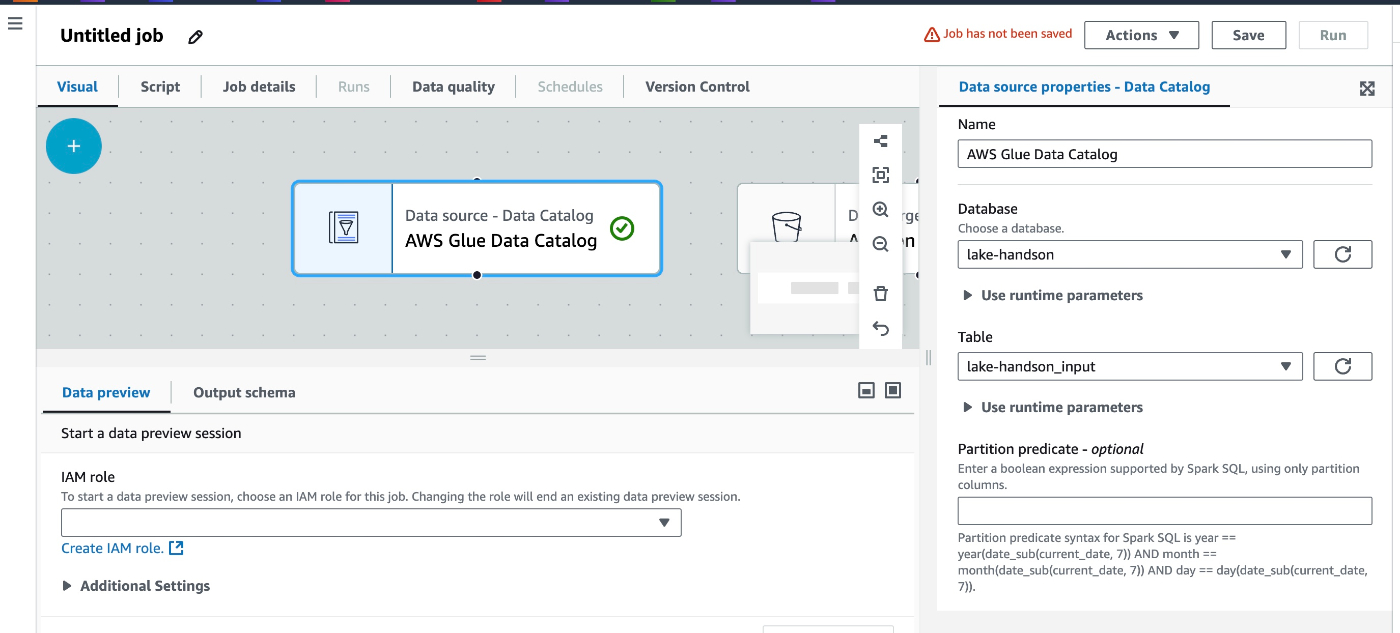
sourceのData Catalog設定
Name, Database, Tableについては、Crawlerで生成したテーブルを選択すれば良い。
IAM RoleにはGlue Jobの実行Roleが必要。ここではGlueServiceRoleとS3の権限があれば良い。
-
targetのS3設定
Node ParentsをData Catalogとすることで、紐付けが自動で行われる。ここではformatはParquet(パーケト)という列指向データ形式を選択し、Snappyによる圧縮を行っている。
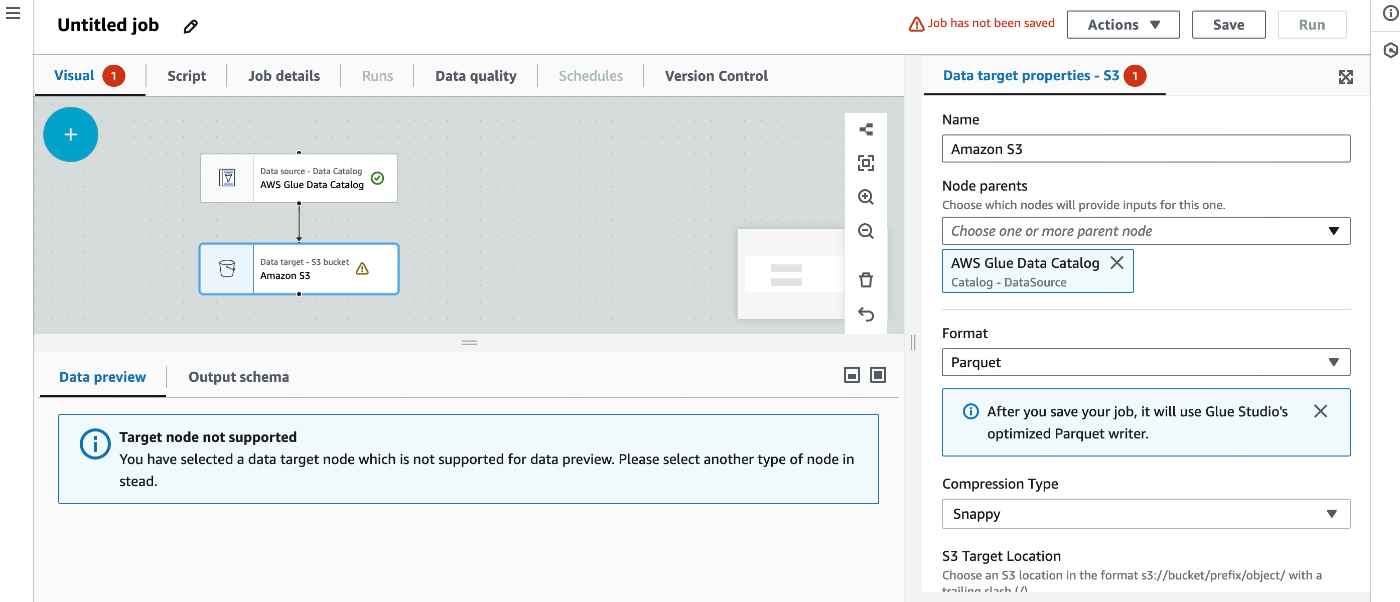
あとはtargetの出力先を指定するだけ。
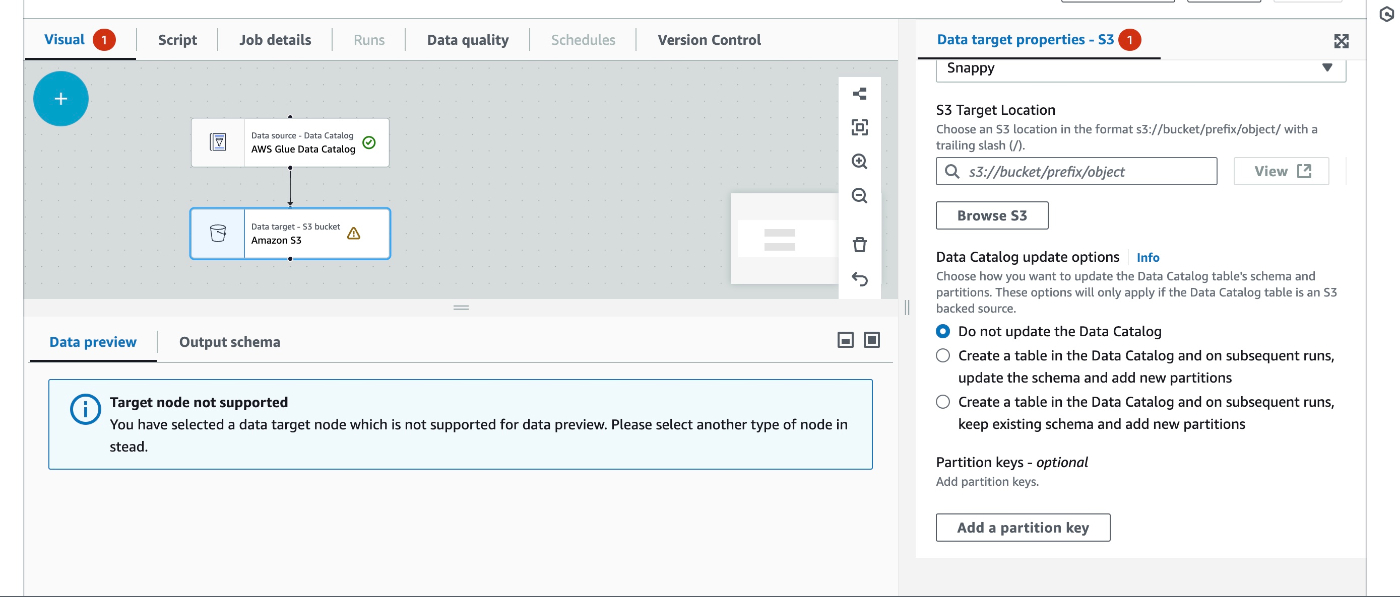
-
Job detailsの設定
今回は言語=Python3, Type=SparkとしているためPySparkでScriptが生成される。
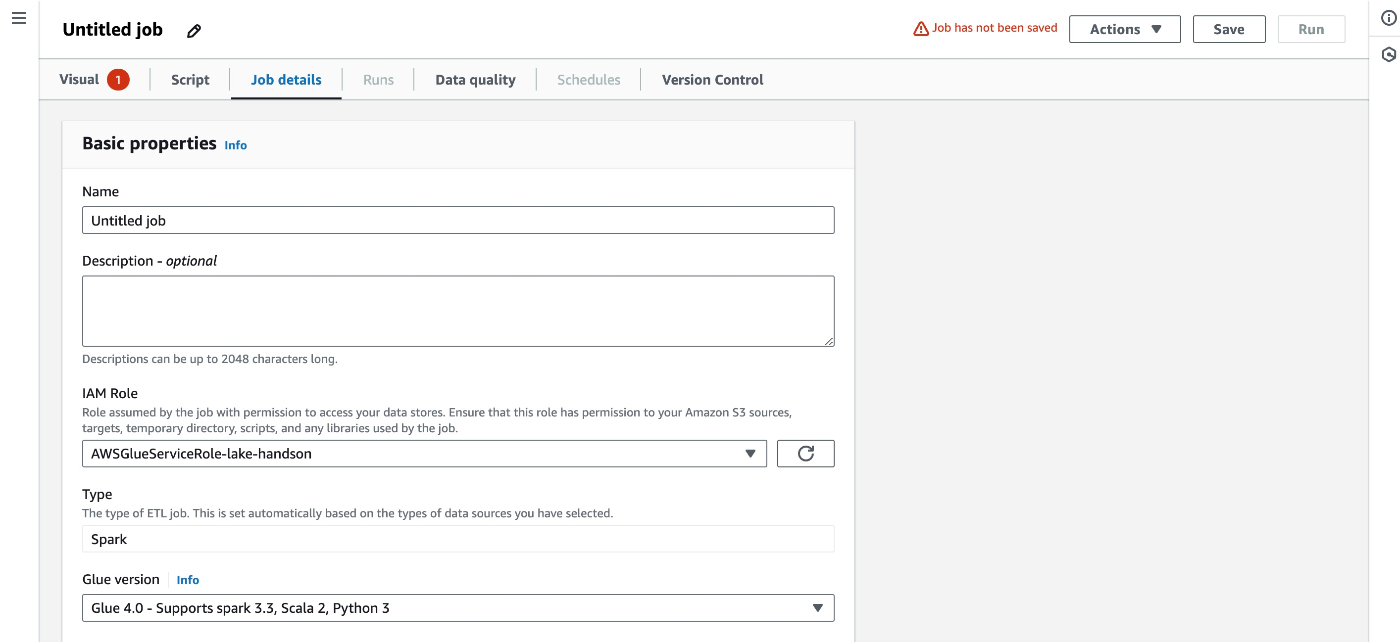
Requested number of workersはDPU値になる。
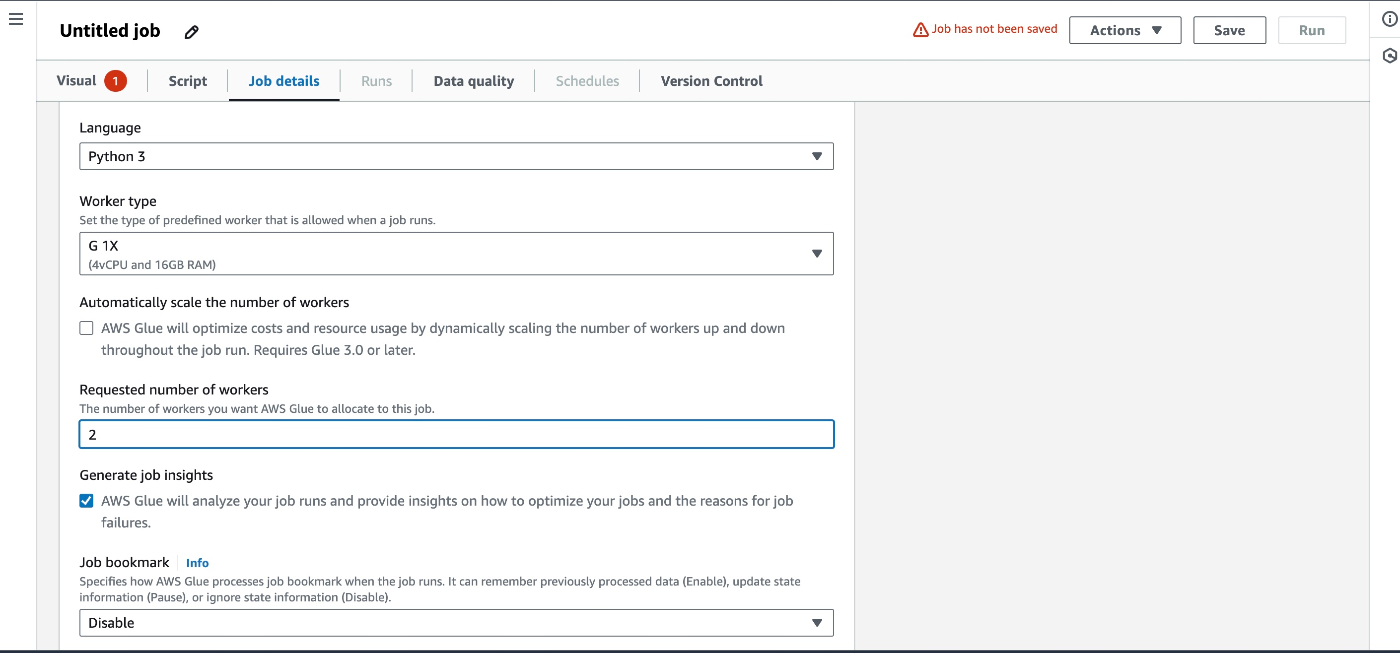
ここまで設定すればジョブ作成を完了できる。
パーティション化とマスキング処理(PySpark)
上記で作成したJobのScriptタブに移動するとpython scriptが自動生成されている。
これを元に少し修正してマスキングとパーティションを行った。(その際のコードは以下)
生成されたコード
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_nodexxxxxxxxxxx = glueContext.create_dynamic_frame.from_catalog(
database="lake-handson",
table_name="lake-handson_input_xxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
transformation_ctx="AWSGlueDataCatalog_nodexxxxxxxxxxx"
)
# Script generated for node Amazon S3
AmazonS3_nodexxxxxxxxxxxxxx = glueContext.getSink(
path="s3://lake-handson/output",
connection_type="s3",
updateBehavior="UPDATE_IN_DATABASE",
partitionKeys=[],
enableUpdateCatalog=True,
transformation_ctx="AmazonS3_nodexxxxxxxxxx")
AmazonS3_nodexxxxxxxxxxxxxx.setCatalogInfo(
catalogDatabase="lake-handson",
catalogTableName="lake-handson-output")
AmazonS3_nodexxxxxxxxxxxxxx.setFormat("glueparquet", compression="snappy")
AmazonS3_nodexxxxxxxxxxxxxx.writeFrame(masked_dyfr)
job.commit()
マスキングとパーティションを行ったコード
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
### Add Function Chap8
def mask(dynamicRecord):
dynamicRecord['secret_id'] = '*******'
return dynamicRecord
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_nodexxxxxxxxxxx = glueContext.create_dynamic_frame.from_catalog(
database="lake-handson",
table_name="lake-handson_input_xxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
transformation_ctx="AWSGlueDataCatalog_nodexxxxxxxxxxx"
)
# apply mask
masked_dyfr = Map.apply(frame=AWSGlueDataCatalog_nodexxxxxxxxxxx, f=mask)
# Script generated for node Amazon S3
AmazonS3_nodexxxxxxxxxxxxxx = glueContext.getSink(
path="s3://lake-handson/output",
connection_type="s3",
updateBehavior="UPDATE_IN_DATABASE",
partitionKeys=["column1"],
enableUpdateCatalog=True,
transformation_ctx="AmazonS3_nodexxxxxxxxxx")
AmazonS3_nodexxxxxxxxxxxxxx.setCatalogInfo(
catalogDatabase="lake-handson",
catalogTableName="lake-handson-output")
AmazonS3_nodexxxxxxxxxxxxxx.setFormat("glueparquet", compression="snappy")
AmazonS3_nodexxxxxxxxxxxxxx.writeFrame(masked_dyfr)
job.commit()
以下変更しか行っていないがこれで十分だった。
・mask関数の追加と適用
・glueContext.getSink()のpartitionKeysにパーティション用のカラム名を指定
AWS Glue PySparkの独自クラス
上記パーティション化とマスキング処理のために調べたAWS Glue PySpark独自クラスについて
DynamicFrameとDataFrame
PySparkにはDataFrameというクラスがあるが、AWS GlueではData Catalogをうまく扱うためにDynamicFrameというクラスが用意されている。
CatalogからDynamicFrameを生成する方法
dyFrame = glueContext.create_dynamic_frame.from_catalog(database="glue", table_name="data")
ResolveChoiceクラス
DynamicFrameは列に複数の型が見つかった場合、Choice型という型で複数の型を持つように保持する。これをどれかの型に確定させるためにResolveChoiceクラスが使用される。
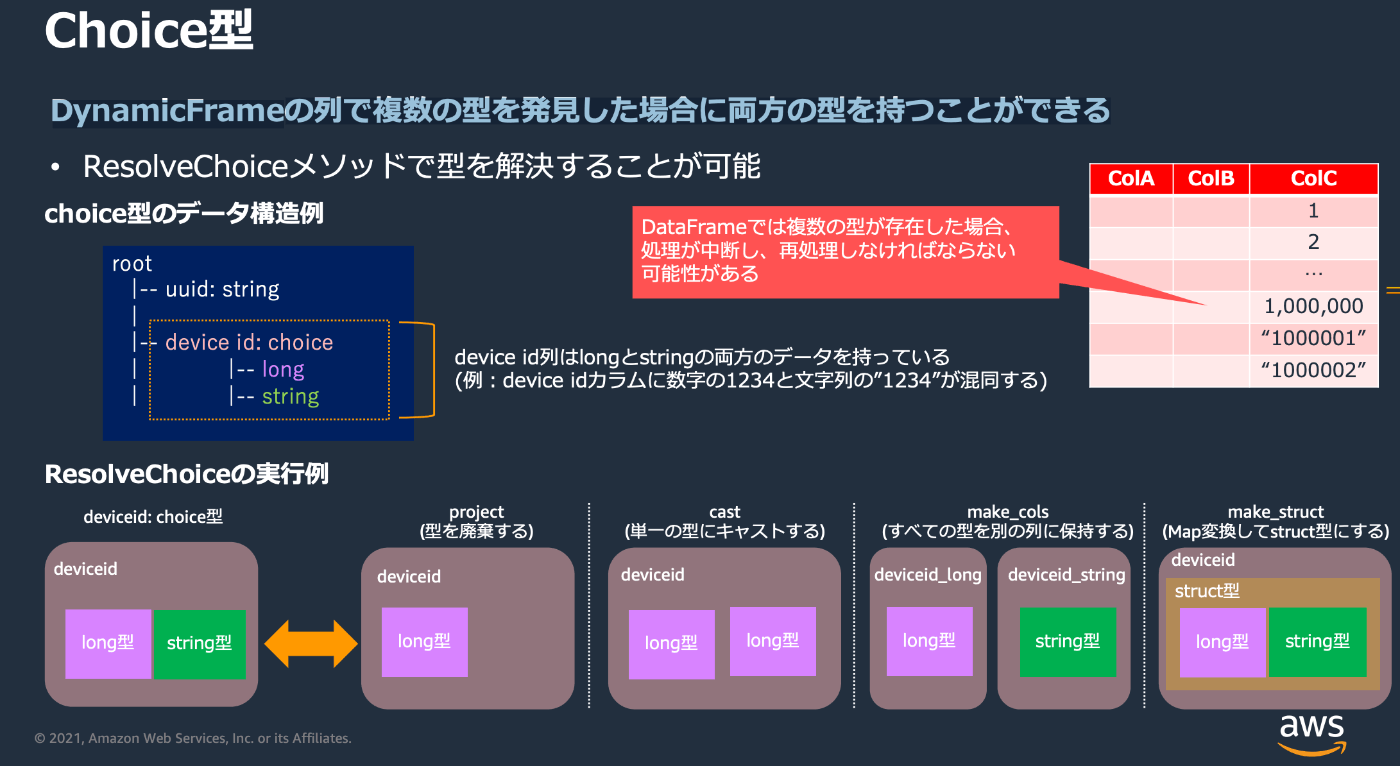
DynamicFrame全体のChoice型を一気に変換する例
resolved_dynamic_frame = dynamic_frame.resolveChoice(choice="make_struct")
DynamicFrameの特定項目のChoice型をのみを変換する例
resolved_dynamic_frame = dynamic_frame.resolveChoice(
specs=[("target_column", "make_struct")]
)
Mapクラス
DynamicFrame内の全てのレコードに対して関数を適用したりできる。
全てのレコードに対する共通処理などをしたいときに便利。
全てのpasswordカラムをマスキングする例
def mask(dynamicRecord):
dynamicRecord['password'] = '****************'
return dynamicRecord
# DynamicFrameにマスク用の関数を適用
masked_dynamicframe = Map.apply(frame=dynamicframe, f=mask)
Discussion