Vimで日本語入力する思考記録
SKK的なものを作りたい
自分ならこうする、という感じで進めてみる
なお最初にlmapを使って途中まで作っていたのだが、それのリライトを兼ねて思考をまとめていく
Roadmap
- ひらがな入力
- 漢字変換
- 候補選択
- 変換マーカー表示
- カタカナモード
- 複数辞書
- コマンドライン
- ユーザー辞書登録
-
ユーザー関数 - mode indicator
- 変換キャンセル
- sticky key(変換マーカーを足したい)
-
自動補完(
<c-r>=の出力が残るのがカッコ悪いのでユーザー補完関数に変えたい&非同期化したい) - Google変換API
とりあえず以下の組を入力することを考えよう
{
"nya": "にゃ",
"ya": "や",
"a": "あ",
}
素朴な実装は以下だが…
inoremap nya にゃ
inoremap ya や
inoremap a あ
これはだめ なぜなら普通にimapすると入力が確定するまでバッファに出ない
つまりnyaを打ち終わるまで何も表示されない
実際はn→ny→にゃと見えてほしい
abbrevもだめ なぜなら登録単語の後にホワイトスペースが来ないと変換されない
つまりya<space>と入力して初めてやになる
ひらがな1字ずつ確定なんてやってられない
したがって、考えるべきは後ろの文字
aを入力したとき
- 直前に
nyがあればにゃにする - 直前に
yがあればやにする - いずれにも該当しなければ
あにする
この順番は重要で、yの判定を先に行うとnyの判定が行われなくなってしまう
したがって先行文字列の長いものから順に判定していく必要がある
幸い、これと似たことはすでにやっている
「現在のカーソルの直前の文字列」は以下で取得できる
let preceding_str = getline('.')->slice(0, charcol('.')-1)
したがって決め打ち入力は以下のようになる 先行入力を消すための<bs>が必要だ
なお適当にk.vimという名前のファイルで編集しているのでこういう関数名にしている
function! k#ins_a() abort
let preceding_str = getline('.')->slice(0, charcol('.')-1)
if slice(preceding_str, -2) ==# 'ny'
return "\<bs>\<bs>にゃ"
endif
if slice(preceding_str, -1) ==# 'y'
return "\<bs>や"
endif
return 'あ'
endfunction
inoremap <expr> a k#ins_a()

ちなみに、sliceの引数には文字列と開始インデックスを渡しているが、開始インデックスが文字列長を超えた場合は文字列全体が返されるので特に長さを比較する必要はない
echo slice('hoge', -10)
" -> hoge
これだけだと結構深刻な問題があって、すでにバッファに存在している文字列も変換素材になってしまう

したがって、先行入力で使うキーは「かな入力開始位置」を設定する
入力文字が削除されたり挿入モードで上下移動されたりした場合を考慮すると、入力開始位置を更新するタイミングは
- 既存の入力開始位置と現在行が異なるとき
- 既存の入力開始位置と現在行が同じだが、既存の開始位置が現在列より右側にあるとき
ということで以下の関数をつくる nについても同様
let s:kana_start_pos = [0, 0]
function! k#ins_y() abort
let current_pos = getcharpos('.')[1:2]
if s:kana_start_pos[0] != current_pos[0] || s:kana_start_pos[1] > current_pos[1]
let s:kana_start_pos = current_pos
endif
return 'y'
endfunction
inoremap <expr> y k#ins_y()
aの方をちょっと修正して、start_pos以降の文字しか見ないようにする
開始位置と行がズレている場合は先行かな入力がないので直接あを出力する
かなの出力を行うタイミングで「かな入力開始位置」をリセットする
function! k#ins_a() abort
+ if s:kana_start_pos[0] != line('.')
+ let s:kana_start_pos = [0, 0]
+ return 'あ'
+ endif
- let preceding_str = getline('.')->slice(0, charcol('.')-1)
+ let preceding_str = getline('.')->slice(s:kana_start_pos[1]-1, charcol('.')-1)
+ let s:kana_start_pos = [0, 0]
" 略
endfunction

続いて直接入力とかな入力をトグルできるようにする
is_enableは変数をユーザーが操作してしまうと良くないのでスクリプトローカル変数で持つ
let s:is_enable = v:false
function! k#is_enable() abort
return s:is_enable
endfunction
function! k#toggle() abort
return k#is_enable() ? k#disable() : k#enable()
endfunction
inoremap <expr> <c-j> k#toggle()
k#enable()の中でマッピングを行い、k#disable()の中でマッピングをもとに戻す
使うのは新しめの関数、maparg()とmapset()
まずはk#enable()
maparg()を使うと既存のマッピング情報の辞書を取り出すことができるので、これをs:keys_to_remapsリストに保存する
既存のマッピングが何もない状態の場合は空辞書が返ってくるので、こちらはs:keys_to_unmapsに保存する
let s:keys_to_remaps = []
let s:keys_to_unmaps = []
function! k#enable() abort
let s:keys_to_remaps = []
let s:keys_to_unmaps = []
for k in ['n', 'y', 'a']
let current_map = maparg(k, 'i', 0, 1)
if empty(current_map)
call add(s:keys_to_unmaps, k)
else
call add(s:keys_to_remaps, current_map)
endif
execute $'inoremap <expr> {k} k#ins_{k}()'
endfor
let s:is_enable = v:true
return ''
endfunction
つづいてk#disable()
保存していた情報をもとにマッピングの復元および削除を行う
function! k#disable() abort
for m in s:keys_to_remaps
call mapset('i', 0, m)
endfor
for k in s:keys_to_unmaps
execute 'iunmap' k
endfor
let s:keys_to_remaps = []
let s:keys_to_unmaps = []
let s:is_enable = v:false
return ''
endfunction

かな入力のトグルができた
とりあえずInsertLeaveで無効化するようにしておく
augroup k_augroup
autocmd!
autocmd InsertLeave * call k#disable()
augroup END
日本語変換ペアに'yy': 'っy'を追加する
ここまでnとyは開始文字、aは終了文字としていたが、これの追加によりyは開始にも終了にもなりうることになる
やることは既存のk#ins_y()に直前の文字を監視する部分を追加するだけ
上で書いたk#ins_a()ではポジションリセットを入れていたがこれは不要だった(aのほうからも除去)
function! k#ins_y() abort
let current_pos = getcharpos('.')[1:2]
if s:kana_start_pos[0] != current_pos[0] || s:kana_start_pos[1] > current_pos[1]
let s:kana_start_pos = current_pos
endif
+ let preceding_str = getline('.')->slice(s:kana_start_pos[1]-1, charcol('.')-1)
+ if slice(preceding_str, -1) ==# 'y'
+ return "\<bs>っy"
+ endif
return 'y'
endfunction

上記のk#ins_y()の構造を見るとリファクタリングができるようになる
- かな入力開始位置の更新(既存のバッファを変換元にしないため)
- 先行文字列を取得
- 先行文字列の後ろを長い順に取り出し、かな変換の実施
このリファクタリングを行うため、まず元のJSON辞書からかな入力で使う形の辞書に変換する
開始文字・終了文字になりうるものをs:start_keysとe:end_keysに入れていく
startのほうは配列でも良いのだが重複削除をするため辞書を使う
endのほうは終了文字をキー、先行文字列の辞書を値とした辞書
function! k#initialize() abort
let raw = {
\ "nya": "にゃ",
\ "ya": "や",
\ "yy": "っy",
\ "a": "あ",
\ }
let s:start_keys = {}
let s:end_keys = {}
for [key, val] in items(raw)
let preceding_keys = slice(key, 0, -1)
let start_key = slice(key, 0, 1)
let end_key = slice(key, -1)
let s:start_keys[start_key] = 1
if !has_key(s:end_keys, end_key)
let s:end_keys[end_key] = {}
endif
let s:end_keys[end_key][preceding_keys] = val
endfor
endfunction
call k#initialize()
echo s:start_keys
" -> {'a': 1, 'y': 1, 'n': 1}
echo s:end_keys
" -> {'a': {'': 'あ', 'y': 'や', 'ny': 'にゃ'}, 'y': {'y': 'っy'}}
単独のaは…まあ開始文字であるともいえるか
かな入力をまとめた関数の作成
function! k#ins(key) abort
" かな入力開始位置の更新
let current_pos = getcharpos('.')[1:2]
if s:kana_start_pos[0] != current_pos[0] || s:kana_start_pos[1] > current_pos[1]
let s:kana_start_pos = current_pos
endif
" かな変換辞書の取得
let kana_dict = get(s:end_keys, a:key, {})
if !empty(kana_dict)
" 先行入力の取得
let preceding_str = getline('.')->slice(s:kana_start_pos[1]-1, charcol('.')-1)
" 先行入力の末尾で変換を試みる
" 長いマッチから短いマッチへ順に調べていく
let i = len(preceding_str)
while i > 0
let tail_str = slice(preceding_str, -i)
if has_key(kana_dict, tail_str)
" マッチしたらその文字を返すが、マッチした文字はそのぶん<bs>して削除する
return repeat("\<bs>", i) .. kana_dict[tail_str]
endif
let i -= 1
endwhile
endif
" 空文字のキーがデフォルト値
return get(kana_dict, '', a:key)
endfunction
k#enable()のマッピング箇所も変更
- execute $"inoremap <expr> {k} k#ins_k()"
+ execute $"inoremap <expr> {k} k#ins('{k}')"
では本格的に50音がマッピングされた辞書を使ってみる
{
"a": "あ",
"i": "い",
"u": "う",
"e": "え",
"o": "お",
"ka": "か",
"ki": "き",
"ku": "く",
"ke": "け",
"ko": "こ",
"kk": "っk",
"sa": "さ",
"si": "し",
"su": "す",
"se": "せ",
"so": "そ",
"ss": "っs",
......
}
↑こういうのを用意して初期化関数で読み込む
function! k#initialize() abort
- let raw = {
- \ "nya": "にゃ",
- \ "ya": "や",
- \ "yy": "っy",
- \ "a": "あ",
- \ }
+ let raw = json_decode(join(readfile('./kana_table.json'), "\n"))
" 略
endfunction
起動関数でこれらをループする
マッピングするべきキーはs:start_keysとe:end_keysに入っているから、それらの辞書のキーを取り出してループする
(キーボードのキーと辞書のキーの名前が両方あって分かりづらいな)
function! k#enable() abort
let s:keys_to_remaps = []
let s:keys_to_unmaps = []
- for k in ['n', 'y', 'a']
+ for k in extendnew(s:start_keys, s:end_keys)->keys()
" 略
endfor
let s:is_enable = v:true
return ''
endfunction

現時点でのk.vimはこんな感じ
100行でかな入力ができた
ではSKKの要、漢字入力を作っていく
「日本語を書ける」を入力することを考える
まずは送りなし変換
Nihongo<space>と入力するとにほんごがエコーバックされるようにする
とりあえず文字を大文字にするユーティリティ関数を追加
function! s:capital(char) abort
return substitute(a:char, '.', '\U\0', '')
endfunction
処理はk#ins()に引数を追加することにして、k#enable()のマッピング箇所に大文字のマッピングを追加
for k in extendnew(s:start_keys, s:end_keys)->keys()
" 略
execute $"inoremap <expr> {k} k#ins('{k}')"
+ if k =~ '\l'
+ execute $"inoremap <expr> {s:capital(k)} k#ins('{k}',1)"
+ endif
endfor
k#ins()に第二引数を追加して変換開始位置を保存
+let s:henkan_start_pos = [0, 0]
-function! k#ins(key) abort
+function! k#ins(key, henkan = v:false) abort
let current_pos = getcharpos('.')[1:2]
if s:kana_start_pos[0] != current_pos[0] || s:kana_start_pos[1] > current_pos[1]
let s:kana_start_pos = current_pos
endif
+ if a:henkan
+ let s:henkan_start_pos = current_pos
+ endif
" 略
endfunction
k#henkan()とk#kakutei()を追加
かな入力スタートのときと似ている
変換が完了したら変換スタート位置をリセットする
kakuteiは変換なしで位置をリセットするだけ
function! k#henkan(fallback_key) abort
let current_pos = getcharpos('.')[1:2]
if s:henkan_start_pos[0] != current_pos[0] || s:henkan_start_pos[1] > current_pos[1]
return a:fallback_key
endif
let preceding_str = getline('.')->slice(s:henkan_start_pos[1]-1, charcol('.')-1)
echomsg preceding_str
let s:henkan_start_pos = [0, 0]
return ''
endfunction
function! k#kakutei(fallback_key) abort
let current_pos = getcharpos('.')[1:2]
if s:henkan_start_pos[0] != current_pos[0] || s:henkan_start_pos[1] > current_pos[1]
return a:fallback_key
endif
let s:henkan_start_pos = [0, 0]
return ''
endfunction
k#enable()でマッピング 現段階では<space>と<cr>に決め打ちする
function! k#enable() abort
" 略
+ inoremap <expr> <space> k#henkan(" ")
+ call add(s:keys_to_unmaps, "<space>")
+ inoremap <expr> <cr> k#kakutei("\n")
+ call add(s:keys_to_unmaps, "<cr>")
let s:is_enable = v:true
return ''
endfunction
これで、Nihongo<space>と入力するとにほんごがエコーバックされるようになった
また、Nihongo<cr>では改行されないはず
つぎに送りあり変換
KaKと入力するとかkがエコーバックされるようにする
k#ins()で変換スタートを操作していた場所を変更
function! k#ins(key, henkan = v:false) abort
" 略
if a:henkan
- let s:henkan_start_pos = current_pos
+ if s:henkan_start_pos[0] != current_pos[0] || s:henkan_start_pos[1] > current_pos[1]
+ let s:henkan_start_pos = current_pos
+ else
+ let preceding_str = getline('.')->slice(s:henkan_start_pos[1]-1, charcol('.')-1)
+ echomsg preceding_str .. a:key
+ endif
endif
" 略
endfunction
これで送りありのエコーバックもOK
では漢字変換作業
まずはL辞書をダウンロード
こういう構造になっている
かわり /代わり;replacement.「-の品」/変わり;change.「-ない」/変り/代り/替わり/替り/
正規表現っぽく書くとこう
^yomi /(kanji(;description)?/)+$
これをパースして辞書として持てば良さそうだが…VimConfではこのように言われていた
- ありすえ氏 「V8は速い!…まあ比較対象がVim scriptなのでなんでも速いんですが」
- kuu氏 「V8は速い!数十万行の辞書でも一瞬で読み込める」
まあVim scriptはこういうのを処理する作りではない 読み込むのは難儀であろう
ということで 辞書は読み込まない という方針で行く
使うのはripgrep
こんな感じで都度grepする作戦
❯ rg --no-filename --no-line-number --encoding euc-jp '^かわりみ ' ~/.cache/vim/SKK-JISYO.L
かわりみ /変わり身/変り身/
grep結果はsystemlist()で取り出せる
複数あったときの選択UIはおいおい考えるとして、今回は最初の変換候補を決め打ちで使用することにする
let s:jisyo = {
\ 'path': expand('~/.cache/vim/SKK-JISYO.L'),
\ 'encoding': 'euc-jp'
\ }
function! s:to_kanji(str) abort
let cmd = $"rg --no-filename --no-line-number --encoding {s:jisyo.encoding} '^{a:str} ' {s:jisyo.path}"
let results = systemlist(cmd)
if len(results) == 0
echomsg 'No Kanji'
return ''
endif
let kanji_list = []
for r in results
let tmp = split(r, '/')
" splitしたときの最初の要素は「読み」なので不要
call extend(kanji_list, tmp[1:])
endfor
" TODO: 候補複数の場合の選択UIは後で作る
let selected = kanji_list[0]
" ;以降は説明なので消す
return substitute(selected, ';.*', '', '')
endfunction
echomsg s:to_kanji('にほんご')
" -> 日本語
echomsg s:to_kanji('かk')
" -> 書
k#henkan()に送りなし変換反映処理を追記
変換リセットの位置が微妙だが、変換結果がなければ確定されないとした
function! k#henkan(fallback_key) abort
let current_pos = getcharpos('.')[1:2]
if s:henkan_start_pos[0] != current_pos[0] || s:henkan_start_pos[1] > current_pos[1]
return a:fallback_key
endif
let preceding_str = getline('.')->slice(s:henkan_start_pos[1]-1, charcol('.')-1)
echomsg preceding_str
+ let converted = s:to_kanji(preceding_str)
+ if converted ==# ''
+ return ''
+ endif
let s:henkan_start_pos = [0, 0]
- return ''
+ return repeat("\<bs>", strcharlen(preceding_str)) .. converted
endfunction
k#ins()に送りあり変換反映処理を追記
kana_dictが必要になるので定義位置をif a:henkanの前へ移動した
+ let kana_dict = get(s:end_keys, a:key, {})
if a:henkan
if s:henkan_start_pos[0] != current_pos[0] || s:henkan_start_pos[1] > current_pos[1]
let s:henkan_start_pos = current_pos
else
let preceding_str = getline('.')->slice(s:henkan_start_pos[1]-1, charcol('.')-1)
echomsg preceding_str .. a:key
+ let converted = s:to_kanji(preceding_str .. a:key)
+ if converted ==# ''
+ return get(kana_dict, '', a:key)
+ endif
+ let s:henkan_start_pos = [0, 0]
+ return repeat("\<bs>", strcharlen(preceding_str)) .. converted .. get(kana_dict, '', a:key)
endif
endif
- let kana_dict = get(s:end_keys, a:key, {})
これで(候補を選択できないが)最低限のSKK入力はできるようになった

ここからはUIの話になりそう
おっと…大文字のマッピングを戻すのを忘れていた
では変換の複数選択を作る
これは素直にcomplete-functionsを使おう
まずは変換候補を直接適用するのではなく取得するだけの関数を作成
function! k#get_henkan_list(str) abort
let cmd = $"rg --no-filename --no-line-number --encoding {s:jisyo.encoding} '^{a:str} ' {s:jisyo.path}"
let results = systemlist(cmd)
let kanji_list = []
for r in results
let tmp = split(r, '/')
call extend(kanji_list, tmp[1:])
endfor
return kanji_list
endfunction
続いて補完候補リストを出す関数を作成
最初はユーザー定義completefunc(E840のヘルプの部分にサンプルがあるやつ)を使おうと思ったがoptionを汚染したくないのでcomplete()を使う形式にした
forループで使っているs:latest_kanji_listは最新のk#get_henkan_list()の返り値で、このあとのk#henkan()の改造で追加する
function! k#completefunc()
" 補完の始点のcol
let preceding_str = getline('.')->slice(0, s:henkan_start_pos[1]-1)
echomsg 'completefunc preceding_str' preceding_str
let start_col = strlen(preceding_str)+1
let comp_list = []
for k in s:latest_kanji_list
" ;があってもなくても良いよう_restを使う
let [word, info; _rest] = split(k, ';') + ['']
" :h complete-items
call add(comp_list, {
\ 'word': word,
\ 'menu': info,
\ 'info': info
\ })
endfor
call complete(start_col, comp_list)
return ''
endfunction
次はk#henkan()の改造
s:latest_kanji_listを設定しつつ、k#completefunc()を呼び出す
補完メニューが表示されていたら変換ではなく次の候補を選択する
ついでにpreceding_strの末尾がnならんと認識する優しさをプラス
function! k#henkan(fallback_key) abort
+ if pumvisible()
+ return "\<c-n>"
+ endif
" 略
let preceding_str = getline('.')->slice(s:henkan_start_pos[1]-1, charcol('.')-1)
+ \->substitute("n$", "ん", "")
echomsg preceding_str
- let converted = s:to_kanji(preceding_str)
- if converted ==# ''
+ let s:latest_kanji_list = k#get_henkan_list(preceding_str)
+ if empty(s:latest_kanji_list)
+ echomsg 'No Kanji'
return ''
endif
- let s:henkan_start_pos = [0, 0]
- return repeat("\<bs>", strcharlen(preceding_str)) .. converted
+ return "\<c-r>=k#completefunc()\<cr>\<c-n>"
endfunction
補完完了時に変換スタート位置をリセットする
最初CompleteDonePreではなくCompleteDoneを使っていたので全くリセットされず慌てた…
augroup k_augroup
autocmd!
autocmd InsertLeave * call k#disable()
+ autocmd CompleteDonePre * if get(complete_info(), 'selected', -1) >= 0
+ \ | let s:henkan_start_pos = [0, 0]
+ \ | endif
augroup END
HACKコメント部の説明
漢字リストの文字列は漢字の場合と漢字;説明の場合がある
説明があってもなくてもエラーにならないよう、余分な部分を_restに吸収させている
echo split('漢字', ';')
" -> ['漢字']
" -> [word, info] にマッピングしようとすると要素数不整合でエラー
" -> let [word, info] = split(k, ';') + [''] を使う
echo split('漢字;説明', ';') + ['']
" -> ['漢字', '説明', '']
" -> [word, info] にマッピングしようとすると要素数不整合でエラー
" -> let [word, info; _rest] = split(k, ';') + [''] を使う
追記:このコメントを書いたときには気づかなかったがkakuteiもpumvisibleで動作を変える必要があった↓
completeを送りありにも反映しよう
方針は先程と同じだが、送りありの場合、辞書内にある変換結果と見出し語が違う(例:よみが「かk」、変換結果が「書」→ kが消えている)ので、送り仮名のアルファベットを補う必要がある
まずk#ins()を先程のk#henkan()と同じように変更
このとき、k#completefunc()に引数を渡す
function! k#ins(key, henkan = v:false) abort
" 略
let kana_dict = get(s:end_keys, a:key, {})
if a:henkan
if s:henkan_start_pos[0] != current_pos[0] || s:henkan_start_pos[1] > current_pos[1]
let s:henkan_start_pos = current_pos
else
let preceding_str = getline('.')->slice(s:henkan_start_pos[1]-1, charcol('.')-1)
echomsg 'okuri-ari:' preceding_str .. a:key
- let converted = s:to_kanji(preceding_str .. a:key)
- if converted ==# ''
+ let s:latest_kanji_list = k#get_henkan_list(preceding_str .. a:key)
+ if empty(s:latest_kanji_list)
+ echomsg 'okuri-ari: No Kanji'
return get(kana_dict, '', a:key)
endif
- let s:henkan_start_pos = [0, 0]
- return repeat("\<bs>", strcharlen(preceding_str)) .. converted .. get(kana_dict, '', a:key)
+ return $"\<c-r>=k#completefunc('{a:key}')\<cr>\<c-n>"
endif
endif
completefuncのほうに引数を追加し、補完候補リストを作るときに末尾に付け足す
-function! k#completefunc()
+function! k#completefunc(suffix_key = '')
" 略
- \ 'word': word,
+ \ 'word': word .. a:suffix_key,
" 略

追記
フォールバックはkeyそのままの値ではなくデフォルト値にする必要がある
どこを変換しているのかわからないので、マーカー▽を表示する
これはバッファに書き込むのではなくvirtual markを使おう
このAPIはVimとNeovimで差があるけど、幸い互換レイヤーを以前作っていたことがある
dotfiles/.vim/autoload/mi/virt_mark.vim
これを簡略化して、inline marker専用のスクリプトを作る
" " sample
" nnoremap sm <cmd>call inline_mark#display(line('.'), col('.'), '▽')<cr>
" nnoremap sn <cmd>call inline_mark#clear()<cr>
" namespaceのキーまたはproptypeにファイルパスを使い、
" 名前が他のプラグインとぶつかるのを防ぐ
let s:file_name = expand('%:p')
let s:hl = 'Normal'
if has('nvim')
let s:ns_id = -1
function! inline_mark#clear() abort
if s:ns_id < 0
return
endif
call nvim_buf_clear_namespace(0, s:ns_id, 0, -1)
let s:ns_id = -1
endfunction
function! inline_mark#display(lnum, col, text) abort
if s:ns_id < 0
let s:ns_id = nvim_create_namespace(s:file_name)
endif
" nvim_buf_set_extmarkは0-basedなので、1を引く
call nvim_buf_set_extmark(0, s:ns_id, a:lnum - 1, a:col - 1, {
\ 'virt_text': [[a:text, s:hl]],
\ 'virt_text_pos': 'inline',
\ })
endfunction
else
function! inline_mark#clear() abort
call prop_type_delete(s:file_name, {})
endfunction
function! inline_mark#display(lnum, col, text) abort
if empty(prop_type_get(s:file_name))
call prop_type_add(s:file_name, {'highlight': s:hl})
endif
call prop_add(a:lnum, a:col, {
\ 'type': s:file_name,
\ 'text': a:text,
\ })
endfunction
endif
最初はプロパティを置いただけだったので入力していくと1列目に打ち込むとプロパティの位置が文字より後ろになってしまう状態だった
vimではstart_inclを、neovimではright_gravityを設定したら入力文字より先に出せた

でもこれだと「変換ポイントを消す」ができないな…virtualだから
まあ変換ポイントの除去は後から考えるか
autoloadとかを考えていないのでとりあえずk.vimの冒頭でinline_mark.vimをロード
source ./inline_mark.vim
文字インデックスをバイトインデックスに変換するヘルパー関数を作成
function! s:char_col_to_byte_col(lnum, char_col) abort
return getline(a:lnum)->slice(0, a:char_col-1)->strlen()+1
endfunction
ヘルパーを使って変換マーカーと変換中マーカーを設定する関数を作成
let s:henkan_marker = "▽"
let s:select_marker = "▼"
function! s:set_henkan_start_pos(pos) abort
let s:henkan_start_pos = a:pos
let [lnum, char_col] = s:henkan_start_pos
let byte_col = s:char_col_to_byte_col(lnum, char_col)
call inline_mark#display(lnum, byte_col, s:henkan_marker)
endfunction
function! s:set_henkan_select_mark() abort
call inline_mark#clear()
let [lnum, char_col] = s:henkan_start_pos
let byte_col = s:char_col_to_byte_col(lnum, char_col)
call inline_mark#display(lnum, byte_col, s:select_marker)
endfunction
function! s:clear_henkan_start_pos() abort
let s:henkan_start_pos = [0, 0]
call inline_mark#clear()
endfunction
これを使って変換ポイントのセットをしていたところを書き換え
- let s:henkan_start_pos = a:pos
+ call s:set_henkan_start_pos(current_pos)
- let s:henkan_start_pos = [0, 0]
+ call s:clear_henkan_start_pos()
completefuncに入ったときにマーカーを変換中に変更
function! k#completefunc(suffix_key = '')
+ call s:set_henkan_select_mark()
" 略
endfunction

カタカナモードを作る
ひらがなをカタカナに変換する関数はこちらの記事に書いた
入力文字をコンバートするため、k#ins()の名前を変更して入力文字列を取得する関数にする
-function! k#ins(key, henkan = v:false) abort
+function! s:get_insert_char(key, henkan = v:false) abort
" 略
k#ins()を作り直し、↑の関数を呼び出して入力文字を出力する
ここで内部モードがzen_kataならカタカナに変換して出力する(ほかのモードは後でやる)
" hira / zen_kata / han_kata / abbrev
let s:inner_mode = 'hira'
function! k#ins(key, henkan = v:false) abort
let char = s:get_insert_char(a:key, a:henkan)
if s:inner_mode == 'zen_kata'
return s:hira_to_kata(char)
endif
" TODO: implement other modes
return char
endfunction
モードを扱う関数も追加
セット関数だけあれば動きはするが、ひらがなとトグルする関数があると便利そうなので追加
function! s:set_inner_mode(mode) abort
let s:inner_mode = a:mode
endfunction
function! s:toggle_inner_mode(mode) abort
call s:set_inner_mode(s:inner_mode == 'hira' ? a:mode : 'hira')
endfunction
全角カナを扱う関数を追加
前半は変換中ではない場合 これはモードをトグルする
後半は変換中の場合 これはカタカナに変換する
function! k#zen_kata(...) abort
let current_pos = getcharpos('.')[1:2]
if s:henkan_start_pos[0] != current_pos[0] || s:henkan_start_pos[1] > current_pos[1]
call s:toggle_inner_mode('zen_kata')
return ''
endif
let preceding_str = getline('.')->slice(s:henkan_start_pos[1]-1, charcol('.')-1)
\->substitute("n$", "ん", "")
call s:clear_henkan_start_pos()
return repeat("\<bs>", strcharlen(preceding_str)) .. s:hira_to_kata(preceding_str)
endfunction
定義した関数をk#enable()の中で呼び出す
とりあえず決め打ちでqにマッピング
function! k#enable() abort
" 略
+ inoremap <expr> q k#zen_kata('q')
+ call add(s:keys_to_unmaps, 'q')
+ call s:set_inner_mode('hira')
let s:is_enable = v:true
return ''
endfunction
ここまで関数系のキーは決め打ちにしていたがこれらもjsonに持ちたい
文字列ではなくオブジェクトを渡したときに関数と認識するようにしましょうか
↓ こんな感じで設定したい
{
"a": "あ",
略......
"z<space>": " ",
"q": { "func": "zen_kata" },
"<cr>": { "func": "kakutei" },
"<space>": { "func": "henkan" },
"<c-q>": { "func": "han_kata" },
}
特殊文字をどうやってハンドリングしようかしら
jsonのキー文字列をVim内部マッピング文字列へ変換するヘルパーを作成
ベタ書きじゃい!!
" c-cはキャンセルなので含めていない
function! s:trans_special_key(str) abort
return a:str->substitute('<space>', "\<space>", 'g')
\ ->substitute('<s-space>', "\<s-space>", 'g')
\ ->substitute('<cr>', "\<cr>", 'g')
\ ->substitute('<bs>', "\<bs>", 'g')
\ ->substitute('<c-a>', "\<c-a>", 'g')
\ ->substitute('<c-b>', "\<c-b>", 'g')
\ ->substitute('<c-d>', "\<c-d>", 'g')
\ ->substitute('<c-e>', "\<c-e>", 'g')
\ ->substitute('<c-f>', "\<c-f>", 'g')
\ ->substitute('<c-g>', "\<c-g>", 'g')
\ ->substitute('<c-h>', "\<c-h>", 'g')
\ ->substitute('<c-i>', "\<c-i>", 'g')
\ ->substitute('<c-j>', "\<c-j>", 'g')
\ ->substitute('<c-k>', "\<c-k>", 'g')
\ ->substitute('<c-l>', "\<c-l>", 'g')
\ ->substitute('<c-m>', "\<c-m>", 'g')
\ ->substitute('<c-n>', "\<c-n>", 'g')
\ ->substitute('<c-o>', "\<c-o>", 'g')
\ ->substitute('<c-p>', "\<c-p>", 'g')
\ ->substitute('<c-q>', "\<c-q>", 'g')
\ ->substitute('<c-r>', "\<c-r>", 'g')
\ ->substitute('<c-s>', "\<c-s>", 'g')
\ ->substitute('<c-t>', "\<c-t>", 'g')
\ ->substitute('<c-u>', "\<c-u>", 'g')
\ ->substitute('<c-v>', "\<c-v>", 'g')
\ ->substitute('<c-w>', "\<c-w>", 'g')
\ ->substitute('<c-x>', "\<c-x>", 'g')
\ ->substitute('<c-y>', "\<c-y>", 'g')
\ ->substitute('<c-z>', "\<c-z>", 'g')
endfunction
読み込み時にこれを使ってJSONキー文字列を変換
これにより<cr>などが一字とみなされてうまくsplitできるようになる
function! k#initialize() abort
" 略
- for [key, val] in items(raw)
+ for [k, val] in items(raw)
+ let key = s:trans_special_key(k)
" 略
enable時にはマッピング用にもとに戻す
function! k#enable() abort
" 略
- for k in extendnew(s:start_keys, s:end_keys)->keys()
+ for key in extendnew(s:start_keys, s:end_keys)->keys()
+ let k = keytrans(key)
" 略
- execute $"inoremap <expr> {k} k#ins('{k}')"
- if k =~ '\l'
+ execute $"inoremap <expr> {k} k#ins('{key}')"
+ if key =~ '^\l$'
" 略
これでs:get_insert_charの返り値が文字列とは限らなくなったのでs:get_insert_specに名前を変更
-function! s:get_insert_char(key, henkan = v:false) abort
+function! s:get_insert_spec(key, henkan = v:false) abort
k#insでs:get_insert_specの戻り値に応じて挙動を変える
function! k#ins(key, henkan = v:false) abort
- let char = s:get_insert_char(a:key, a:henkan)
+ let spec = s:get_insert_spec(a:key, a:henkan)
+ if type(spec) == v:t_dict
+ return call($'k#{out.spec}', [a:key])
+ endif
+ let char = spec
if s:inner_mode == 'zen_kata'
return s:hira_to_kata(char)
endif
" TODO: implement other modes
return char
endfunction
これでinoremap <expr> q k#zen_kata('q')のように直接定義していたものをjsonに出すことができた
vim-jpのやり取りでtrans_special_keyの短縮版を作れたので更新
kuuさんのdotvimより
" e.g. <space> -> \<space>
function! s:trans_special_key(str) abort
return substitute(a:str, '<[^>]*>', {m -> eval($'"\{m[0]}"')}, 'g')
endfunction
半角カナモードも作るが…全角かなと良い感じの対応は無理そう
↓このページのサイドバーの下のほう、「半角・全角形」に半角カナのキーコード定義があるが、濁点・半濁点が文字と独立している関係で、全角カナと並びが異なる
ということは、全角カナと同じ並びをしたマッピングテーブルを自分で作ればOK
それで対応できない記号などは個別にマッピング
半角カナのsplitはこちらを参考にさせていただく
(というかこの並び順がすでに揃っている、ちゃんとコードを見ていないけどうつぼさんも同じ発想に至っているのかもな)
何度か試した結果、こんな感じに
" たまにsplit文字列の描画がおかしくなるので注意
let s:hankana_list = ('ァアィイゥウェエォオカガキギクグケゲコゴ'
\ .. 'サザシジスズセゼソゾタダチヂッツヅテデトド'
\ .. 'ナニヌネノハバパヒビピフブプヘベペホボポ'
\ .. 'マミムメモャヤュユョヨラリルレロワワイエヲンヴーカケ')
\ ->split('.[゙゚]\?\zs')
let s:zen_kata_origin = char2nr('ァ', v:true)
let s:griph_map = { 'ー': '-', '〜': '~', '、': '、', '。': '。', '「': '「', '」': '」', '・': '・' }
function! s:zen_kata_to_han_kata(str) abort
return a:str->substitute('.', {m->get(s:griph_map,m[0],m[0])}, 'g')
\ ->substitute('[ァ-ヶ]', {m->get(s:hankana_list, char2nr(m[0], v:true) - s:zen_kata_origin, m[0])}, 'g')
\ ->substitute('[!-~]', {m->nr2char(char2nr(m[0], v:true) - 65248, v:true)}, 'g')
endfunction
これらを利用して半角カナモードと濁点モードを追加
起動関数は全角カナモードをコピペして書き換えただけなのでここには書かない(詳細はgithubのdiffで)
weztermで<c-q>が効かないことがあるようなので起動キーはzqにした
これにより、func実行でも先行入力を除去する必要が出てきたため、s:get_insert_specを修正
辞書にprefixというキーを追加して、ここに<bs>を流し込む
function! s:get_insert_spec(key, henkan = v:false) abort
" 略
if has_key(kana_dict, tail_str)
- return repeat("\<bs>", i) .. kana_dict[tail_str]
+ if type(kana_dict[tail_str]) == v:t_dict
+ let result = { 'prefix': repeat("\<bs>", i) }
+ call extend(result, kana_dict[tail_str])
+ return result
+ else
+ return repeat("\<bs>", i) .. kana_dict[tail_str]
+ endif
endif
" 略
endfunction
これをk#insのほうで認識して実行する
if type(spec) == v:t_dict
- return call($'k#{spec.func}', [a:key])
+ return get(spec, 'prefix', '') .. call($'k#{spec.func}', [a:key])
endif

kanji_listだった部分をhenkan_listに修正
L辞書決め打ちだったが複数辞書に対応させる
上ほど優先度が高いとする
-let s:jisyo = {
- \ 'path': expand('~/.cache/vim/SKK-JISYO.L'),
- \ 'encoding': 'euc-jp'
- \ },
+let s:jisyo_list = [
+ \ { 'path': expand('~/.cache/vim/SKK-JISYO.L'), 'encoding': 'euc-jp' },
+ \ { 'path': expand('~/.cache/vim/SKK-JISYO.geo'), 'encoding': 'euc-jp' },
+ \ { 'path': expand('~/.cache/vim/SKK-JISYO.emoji'), 'encoding': 'utf-8' },
+ \ ]
k#get_henkan_listで辞書リストをループして検索を繰り返す
function! k#get_henkan_list(str) abort
- let cmd = $"rg --no-filename --no-line-number --encoding {s:jisyo.encoding} '^{a:str} ' {s:jisyo.path}"
- let results = systemlist(cmd)
let henkan_list = []
- for r in results
- let tmp = split(r, '/')
- call extend(henkan_list, tmp[1:])
+ for jisyo in s:jisyo_list
+ let cmd = $"rg --no-filename --no-line-number --encoding {jisyo.encoding} '^{a:str} ' {s:jisyo.path}"
+ let results = systemlist(cmd)
+ for r in results
+ let tmp = split(r, '/')
+ call extend(henkan_list, tmp[1:])
+ endfor
endfor
return henkan_list
endfunction

変換候補が辞書内になかった場合にユーザーが登録できる仕組みを作りたい
このためにはコマンドラインで動作させる必要がありそう
しかしコマンドライン内はバッファ内とAPIが異なる
座標の取得も補完の表示も別関数になるしvirtual markの設定もできない
したがってコマンドライン用にまた新しくSKKシステムを作り直す
…というのはさすがにきついので「高さ1行のバッファを開いてそこに入力された値をコマンド文字列とする」方針で行く
- cmdlineで
<c-j>押下、関数起動 - コマンドラインの既存の内容とカーソル位置を取得
- 高さ1行の一時バッファを展開
- 2で取得したコマンドラインの内容とカーソル位置を一時バッファに反映、インサートモードに遷移
- 改行またはモードチェンジに反応して一時バッファの内容を取得、バッファを破棄
- 5で取得した一時バッファの内容をコマンドラインに展開
function! k#cmd_buf() abort
" とりあえずコマンドと検索のみ対応
let cmdtype = getcmdtype()
if ':/?' !~# cmdtype
return
endif
" コンテキストを保存
let s:cb_ctx = {
\ 'type': cmdtype,
\ 'text': getcmdline(),
\ 'col': getcmdpos(),
\ 'view': winsaveview(),
\ 'winid': win_getid(),
\ }
" 1行のバッファを作成
botright 1new
setlocal buftype=nowrite bufhidden=wipe noswapfile
" コマンドモードから脱出
call feedkeys("\<c-c>", 'n')
" 入力済みの内容とカーソル位置をバッファに反映
call setline(1, s:cb_ctx.text)
call cursor(1, s:cb_ctx.col)
" インサートモード開始
if strlen(s:cb_ctx.text) < s:cb_ctx.col
startinsert!
else
startinsert
endif
call k#enable()
" 改行されたとき(行数が1を超えたとき)またはインサートモードを抜けたときに
" 入力された内容をcmdlineへ反映
augroup k_cmd_buf
autocmd!
autocmd InsertEnter <buffer> ++once
\ autocmd TextChanged,TextChangedI,TextChangedP,InsertLeave <buffer> ++nested
\ if line('$') > 1 || mode() !=# 'i'
\ | stopinsert
\ | let s:cb_ctx.line = s:cb_ctx.type .. getline(1, '$')->join('')
\ | quit!
\ | call win_gotoid(s:cb_ctx.winid)
\ | call winrestview(s:cb_ctx.view)
\ | call timer_start(1, {->feedkeys(s:cb_ctx.line, 'nt')})
\ | endif
augroup END
endfunction
cnoremap <c-j> <cmd>call k#cmd_buf()<cr>
autocmdの内容を解説
脱出時のコマンドを生で書くと即TextChangedが発火して終了してしまったので
InsertEnterでラップ
autocmd InsertEnter <buffer> ++once
脱出時のイベントを定義
なおwindow移動時のイベントは発火してほしいのでnestedをつけておく
\ autocmd TextChanged,TextChangedI,TextChangedP,InsertLeave <buffer> ++nested
\ if line('$') > 1 || mode() !=# 'i'
インサート終了
\ | stopinsert
入力内容から改行を削除してコマンド文字列を抽出
\ | let s:cb_ctx.line = s:cb_ctx.type .. getline(1, '$')->join('')
ウィンドウを脱出
bufhidden=wipeとかを設定しているのでバッファは削除される
\ | quit!
もとのウィンドウへ移動、カーソル位置などを復帰
\ | call win_gotoid(s:cb_ctx.winid)
\ | call winrestview(s:cb_ctx.view)
コマンド文字列を入力
\ | call timer_start(1, {->feedkeys(s:cb_ctx.line, 'nt')})
\ | endif
ラストのコマンド文字列入力はtimer_startを使って非同期っぽく行っている
このアイデアは以前記事に書いたものを利用した

debug出力が露出してるけど気にしないでほしい
ついでにk#toggleの呼び出しを<expr>にしてる意味ないなと思ったので<cmd>形式に切り替え
これまで入力を担当するk#ins()は<expr>マッピングにしていたが、<expr>はバッファを編集したりカーソルを移動したりできず、成約が重い
これは<cmd>に変えたほうがよいかな?と思い念のためskkeletonのマッピングを見てみたが…やはり<cmd>を使っているようだ

skkeleton状態でimapを表示した結果
なんでこんなことを考えているかというと辞書登録のためにはinsertを途切れさせないといけないのだがそれがexprの中だと面倒 タイマーテクニックを使えばできるのだけど黒魔術感は否めない
ということでk#ins()を書き換える
具体的には、これまで「先行入力の数だけ<bs>で消し、変換後の文字を足す」というやり方を取ってきたが、直接現在行をgetline()とsetline()で書き換えよう
…と思ったけどやっぱりむずくない?文字列だったら書き換えられるけど改行とかバックスペースは対応がむずそうである
skkeletonで辞書登録やってみたけどundoポイントは途切れているようなのでここを気にしなくてよさそうかも
いったんinsert modeを脱出して辞書登録モード(別バッファ編集)に入り、もとの位置に戻って入力文字を置き換えてstartinsertしてやればよいか
では辞書登録機能を作っていこう
まず、SKK入力中に別バッファを開いて再度SKK入力をする可能性が出てきたので、start_posを複数持てるようにしたい
バッファ変数でもウィンドウ変数でもどっちでも良いな…ウィンドウにしておくか
-let s:kana_start_pos = [0, 0]
-let s:henkan_start_pos = [0, 0]
+let w:kana_start_pos = [0, 0]
+let w:henkan_start_pos = [0, 0]
さらに「開始位置から現在位置までの先行入力」「現在位置が開始位置の同じ行で右側かどうかの真偽値」を取得する処理もいくつかあるので関数にまとめよう
" 変数名を文字列連結で作ってしまうと後からgrepしづらくなるので
" 行数が嵩むが直接記述する
function! s:is_same_line_right_col(target) abort
let target_name = ''
if a:target ==# 'kana'
let target_name = 'kana_start_pos'
elseif a:target ==# 'henkan'
let target_name = 'henkan_start_pos'
else
throw 'wrong target name'
endif
let target = get(w:, target_name, [0, 0])
let current_pos = getcharpos('.')[1:2]
return target[0] ==# current_pos[0] && target[1] < current_pos[1]
endfunction
function! s:get_preceding_str(target, trim_trail_n = v:true) abort
let target_name = ''
if a:target ==# 'kana'
let target_name = 'kana_start_pos'
elseif a:target ==# 'henkan'
let target_name = 'henkan_start_pos'
else
throw 'wrong target name'
endif
let start_col = get(w:, target_name, [0, 0])[1]
let preceding_str = getline('.')->slice(start_col-1, charcol('.')-1)
if a:trim_trail_n
return preceding_str->substitute("n$", "ん", "")
endif
return preceding_str
endfunction
濁点関数を追加(これいる?)
function! s:hira_to_dakuten(str) abort
return a:str->substitute('[^[:alnum:][:graph:][:space:]]', {m->m[0] .. '゛'}, 'g')
endfunction
k#insを三項演算子を使って記述を短縮
動作は変わらないのでZennは書かなくて良いや 気になったらcommit diffを見に行く運用
prettierの新フォーマット、まじで「最初は奇妙だがしばらくすると止められなくなる」感覚でとても気に入っている
<expr>マッピングを止めて<cmd>...<cr>に切り替える
すこし上のコメントで「現在行をgetline()とsetline()で書き換えよう」と書いていたが、実のところ直接returnしていた文字列をfeedkeysで入力するかたちに切り替えれば良いことに気づいた
具体的には以下
function! k#ins(key, henkan = v:false) abort
let spec = s:get_insert_spec(key, a:henkan)
let result = type(spec) == v:t_dict ? get(spec, 'prefix', '') .. call($'k#{spec.func}', [a:key])
" 各モードは略
\ : spec
- return result
+ call feedkeys(result, 'n')
endfunction
で、マッピング箇所を書き換えればOK
- execute $"inoremap <expr> {k} k#ins('{key}')"
+ execute $"inoremap {k} <cmd>call k#ins('{key}')<cr>"
…と思ったのだが、<cr>のマッピングでのみ問題が発生
「<cmd>...<cr>がコマンド文字列として解釈される」という仕様上、k#insの引数に<cr>をわたしているつもりが、そこがコマンドの終端として解釈されてしまう 困った
これはマッピングの内部では<lt>を使い、関数の内部でそれをもとに戻す処理を挟むことで解決した
マッピング箇所は以下のようになり、
" in k#enable()
for key in extendnew(s:start_keys, s:end_keys)->keys()
let k = keytrans(key)
+ let k_lt = substitute(k, '<', '<lt>', 'g')
let current_map = maparg(k, 'i', 0, 1)
if empty(current_map)
call add(s:keys_to_unmaps, k)
else
call add(s:keys_to_remaps, current_map)
endif
- execute $"inoremap <expr> {k} k#ins('{key}')"
+ execute $"inoremap {k} <cmd>call k#ins('{k_lt}')<cr>"
k#insはこうなる
function! k#ins(key, henkan = v:false) abort
- let spec = s:get_insert_spec(a:key, a:henkan)
+ let key = s:trans_special_key(a:key)
+ let spec = s:get_insert_spec(key, a:henkan)
- let result = type(spec) == v:t_dict ? get(spec, 'prefix', '') .. call($'k#{spec.func}', [a:key])
+ let result = type(spec) == v:t_dict ? get(spec, 'prefix', '') .. call($'k#{spec.func}', [key])
" 略
\ : spec
- return result
+ call feedkeys(result, 'n')
endfunction
これで<expr>の制約から解き放たれたぞ!
とりあえずユーザー辞書の定義をしよう
辞書パスの変数を定義
変換時の順序を良い塩梅に決めるのは難しい気がするので、ちょっと冗長だけどs:jisyo_listにも同じパスを手動で入れ込む
+let s:user_jisyo_path = expand('~/.cache/vim/SKK-JISYO.user')
let s:jisyo_list = [
\ { 'path': expand('~/.cache/vim/SKK-JISYO.L'), 'encoding': 'euc-jp' },
+ \ { 'path': s:user_jisyo_path, 'encoding': 'utf-8' },
\ { 'path': expand('~/.cache/vim/SKK-JISYO.geo'), 'encoding': 'euc-jp' },
\ { 'path': expand('~/.cache/vim/SKK-JISYO.emoji'), 'encoding': 'utf-8' },
\ ]
ファイルが存在しないとよろしくないので、initialize関数内で初期化しよう
glob()の結果が空だった場合にディレクトリを作成して初期データを保存
" k#initialize()内部に追加
if glob(s:user_jisyo_path)->empty()
call fnamemodify(s:user_jisyo_path, ':p:h')
\ ->iconv(&encoding, &termencoding)
\ ->mkdir('p')
let user_jisyo_lines = [
\ ';; フォーマット',
\ ';; yomi /(henkan(;setsumei)?/)+',
\ ';;',
\ ';; okuri-ari entries.',
\ ';; okuri-nasi entries.',
\ ]
call writefile(user_jisyo_lines, s:user_jisyo_path)
endif
これで起動と同時にファイルが作られた
;; フォーマット
;; yomi /(henkan(;setsumei)?/)+
;;
;; okuri-ari entries.
;; okuri-nasi entries.
適当に編集して、ファイルがある場合は勝手に更新されないことを確認
辞書を走査する部分にちょっと追加して読みを保存するように変更 内容はgithubに
ユーザー辞書を準備したので、登録機能を作っていく
k#completefuncで、候補リストの末尾に「辞書登録」のアイテムを追加する
wordを先行入力、abbrを[辞書登録]にすることで、リストには「辞書登録」と表示させつつ、バッファの文字はそのままにしておく
function! k#completefunc(suffix_key = '')
" comp_listに変換候補を詰めるところまで略
+ let preceding_str = s:get_preceding_str('henkan') .. a:suffix_key
+ call add(comp_list, {
+ \ 'word': preceding_str,
+ \ 'abbr': '[辞書登録]',
+ \ 'menu': preceding_str,
+ \ 'info': preceding_str,
+ \ 'user_data': { 'yomi': preceding_str, 'func': 'jisyo_touroku' }
+ \ })
call complete(start_col, comp_list)
return ''
endfunction
これで、変換先が辞書になくても候補リストが最低1要素存在することになったので、リスト要素数をチェックしていた部分が削除できる
番兵法というやつである
- if empty(s:latest_henkan_list)
- echomsg 'No Kanji'
- return ''
- endif
autocmd CompleteDonePreでv:completed_itemを認識して処理を行う
いったん表示させてみよう
augroup k_augroup
autocmd!
" 略
+ autocmd CompleteDonePre * echomsg 'completed' v:completed_item
augroup END
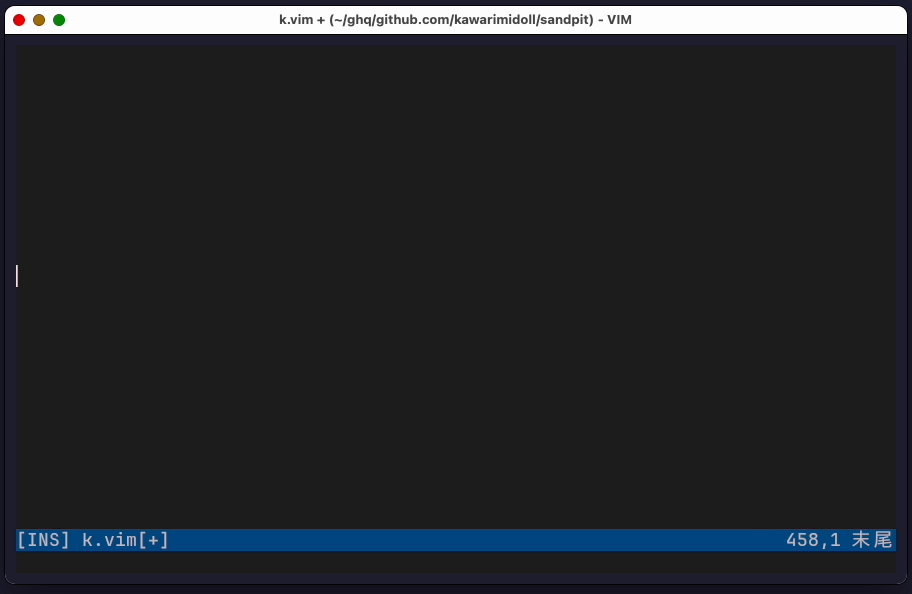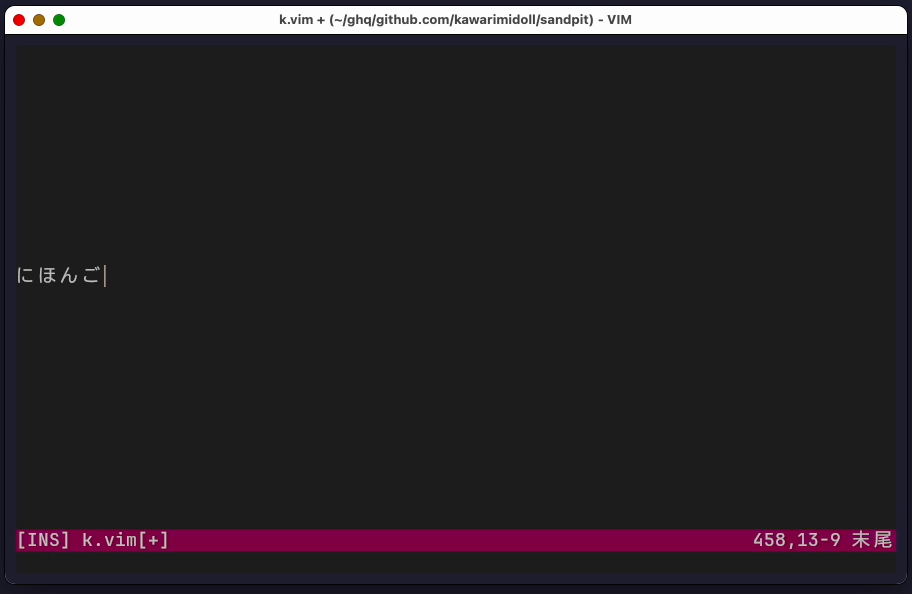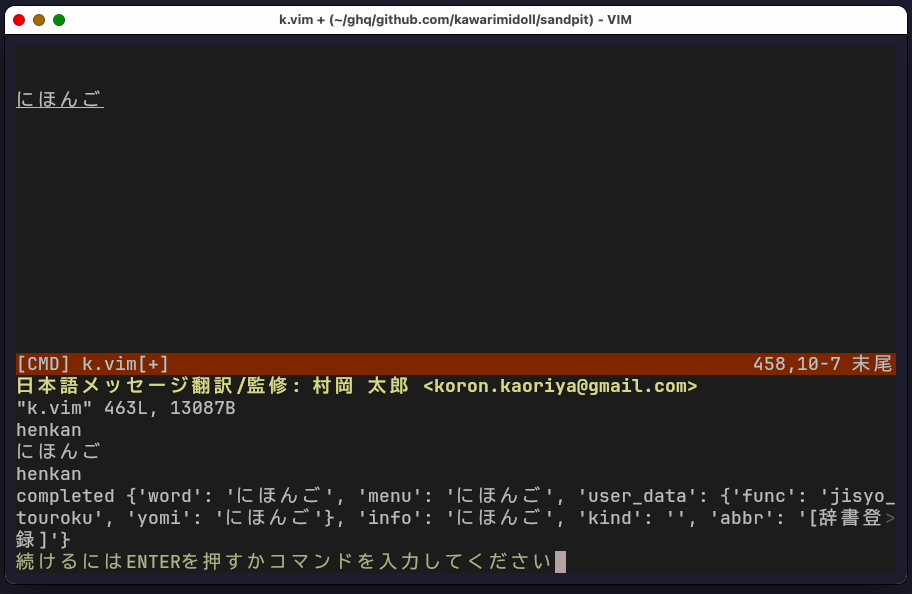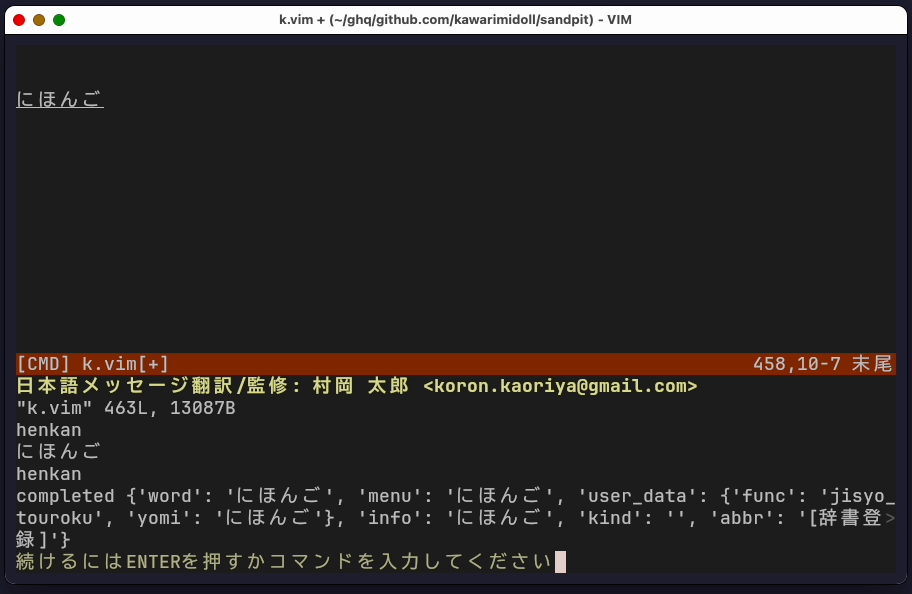
:messages で選択されたアイテムの内容を表示
v:completed_item.user_data.funcのデータを使って辞書登録を起動できそうだ!
いくつかこのスクラップに細かく書くほどでもない修正を加えたのでcommitだけ説明
メニューから変換先を選んだあとにkakuteiを実行せずそのまま次の入力を続けようとすると変換ポイントが置けない問題があったので修正
かなテーブルに「うぃ」「うぇ」を追加
start_point変数をウィンドウ変数からバッファ変数へ変更
さて、ユーザー辞書に関してだが、「ユーザー辞書登録機能」は実用上必須だが、「ユーザー辞書登録モード」はなくてもよいということに思い至った
つまり、辞書を登録する場合はコマンドラインなどで入力するのではなく直接辞書を別バッファで開いてしまえば良い
「辞書を読み込むのが大変なのでrgに任せる」「コマンドラインモードを作るのが大変なのでインサートモードで書いたものをコマンドラインへコピペする」に続く第3の諦めである
方針はこうだ
- 候補メニューから
[辞書登録]が選択される - その時点でのカーソル位置などのコンテキストを保存する
- 別バッファでユーザー辞書を開く
- 適切な位置にカーソルが移動していてすぐに編集できる状態になっているとよい
- ユーザー辞書を編集して保存する
- もとのバッファに戻ってくると登録した内容が反映される
- 反映した部分から編集できる状態になっているとよい
- 登録をキャンセルしたらもとの状態に戻るとする
まずcomp_list末尾に追加する要素にコンテキストを保存するよう変更
+ let current_pos = getcharpos('.')[1:2]
+ let is_trailing = getline('.')->strcharlen() < current_pos[1]
call add(comp_list, {
\ 'word': preceding_str,
\ 'abbr': '[辞書登録]',
\ 'menu': preceding_str,
\ 'info': preceding_str,
- \ 'user_data': { 'yomi': preceding_str, 'func': 'jisyo_touroku' }
+ \ 'user_data': {
+ \ 'yomi': preceding_str,
+ \ 'jisyo_touroku': {
+ \ 'yomi': preceding_str,
+ \ 'start_pos': b:henkan_start_pos,
+ \ 'cursor_pos': getcharpos('.')[1:2],
+ \ 'is_trailing': is_trailing,
+ \ 'suffix_key': a:suffix_key,
+ \ }
+ \ }
\ })
そしてs:complete_done_pre()内部で上記のuser_data.jisyo_tourokuがあったときに処理を起動
順番に:
-
BufEnter <buffer> ++onceで現在のバッファに戻ってきたときに発動する処理を予約 -
execute 'botright 5new' okuri s:user_jisyo_pathで画面をsplitしつつ辞書を開く- okuri変数には
+/okuri-nasiか+/okuri-ariが入り、該当行まで直接飛ぶ:h +cmd参照
- okuri変数には
- feedkeysで黒魔術を使う
-
i_ctrl-oでoを使って次の行にカーソルを移す - 保存されていた読み、スペース、スラッシュ2個を入力する
-
i_ctrl-gUで<left>を使って左へ移動(直前に入力した2つのスラッシュの間に入る) -
<cmd>call k#enable()<cr>を呼び出してSKK開始
-
let user_data = get(a:completed_item, 'user_data', {})
- if type(user_data) == v:t_dict
- let func = get(user_data, 'func', '')
+ if type(user_data) != v:t_dict
+ return
+ endif
- if func !=# ''
- echomsg 'jisyo touroku'
- endif
+ if has_key(user_data, 'jisyo_touroku')
+ let jt = user_data.jisyo_touroku
+ let b:jisyo_touroku_ctx = jt
+
+ autocmd BufEnter <buffer> ++once call s:buf_enter_try_user_henkan()
+
+ let okuri = '+/okuri-' .. (jt.suffix_key ==# '' ? 'nasi' : 'ari')
+ execute 'botright 5new' okuri s:user_jisyo_path
+
+ call feedkeys($"\<c-o>o{jt.yomi} //\<c-g>U\<left>\<cmd>call k#enable()\<cr>", 'n')
+ endif
+endfunction
なお、ユーザー辞書バッファ内で再度辞書登録が呼ばれる可能性があるのでその対処が必要 これは本質ではないので後ほど行う
で、BufEnterで予約する処理は以下
- 保存していた座標へ移動
- インサートモード開始
- SKK開始
- 変換候補リストを取得
- ユーザーが編集してリスト候補ができているはず
- もし1件も取得できなければここで終了
- リストの先頭を結果として使用(よみがなの数だけ
<bs>を連打し、変換後の文字列を挿入) - 送りありの場合、ここにstart_posを設定して送り仮名を入力
- henkan_startに変換結果の文字数を足せば送り仮名開始位置が算出できる
function! s:buf_enter_try_user_henkan() abort
call setcursorcharpos(b:jisyo_touroku_ctx.cursor_pos)
if b:jisyo_touroku_ctx.is_trailing
startinsert!
else
startinsert
endif
call k#enable()
let s:latest_henkan_list = k#get_henkan_list(b:jisyo_touroku_ctx.yomi)
if empty(s:latest_henkan_list)
return
endif
let henkan_result = substitute(s:latest_henkan_list[0].henkan, ';.*', '', '')
call feedkeys(repeat("\<bs>", strcharlen(b:jisyo_touroku_ctx.yomi)) .. henkan_result, 'n')
" 送り仮名の補完
if b:jisyo_touroku_ctx.suffix_key !=# ''
let tmp_pos = b:jisyo_touroku_ctx.start_pos
let tmp_pos[1] += strcharlen(henkan_result)
let b:kana_start_pos = tmp_pos
call feedkeys(b:jisyo_touroku_ctx.suffix_key, 'n')
endif
endfunction
待ってたぜェ!!この瞬間をよォ!!
本質ではない軽めの変更を複数追加
変換候補がどの辞書によるものか視認できるよう、辞書定義にmark(任意)を追加

L辞書をL、地名辞書をGで登録した例

説明がある単語の場合は末尾にマークがつく
autocmdをトップレベルに置いていたので、enable関数でautocmdを定義し、disable関数で削除するよう修正
k#get_henkan_listは必ず返り値を変数に保存する運用になっていたので、k#update_henkan_listに改名し、内部で保存までするように変更
Vimと関係なくSKKについて解説している記事を発見
どうやらGoogle変換APIに問い合わせる機能があるようだ
便利そうなので追加しよう
たしかuga-rosaさんが作ってたなと思い立ち検索
lua/jam/cgi.luaにコードあり
どうやらhttp://www.google.com/transliterate?langpair=ja-Hira|ja&text=[変換対象文字列]で変換できるもよう
これを作る
まずは日本語文字列をURLエンコードするユーティリティの作成
この辺を参考にした
ポイントはバイト区切りで変換する必要があるのでsplit(str, '\zs')ではうまくいかないこと
function! s:url_encode(str)
return range(0, strlen(a:str)-1)
\ ->map({i -> a:str[i] =~ '[-.~]\|\w' ? a:str[i] : printf("%%%02x", char2nr(a:str[i]))})
\ ->join('')
endfunction
curlしてテストしてみると文節(?)ごとに区切られた配列で返ってくる
JSONとして解釈できそうだ
❯ curl -s 'http://www.google.com/transliterate?langpair=ja-Hira|ja&text=%E3%81%8B%E3%82%8F%E3%82%8A%E3%81%BF%E3%81%AB%E3%82%93%E3%81%8E%E3%82%87%E3%81%86'
[["かわりみ",["変わり身","カワリミ","変り身","変わりみ","代わりみ"]],["にんぎょう",["人形","ニンギョウ","人業","人行","にんぎょう"]]]
区切られた候補を選択をするUIを提供するのはむずい気がするので、とりあえず最初の各候補を採用して接続して返すようにする
function! k#google_henkan(str) abort
let url_base = 'http://www.google.com/transliterate?langpair=ja-Hira|ja&text='
let encoded = s:url_encode(a:str)
let result = system($"curl -s '{url_base}{encoded}'")
try
return json_decode(result)->map({_,v->v[1][0]})->join('')
catch
echomsg v:exception
return ''
endtry
endfunction
次はこれを呼び出すトリガーを候補メニューに追加する
ユーザー辞書登録のときのように、コンテキストをまとめてuser_dataに突っ込むことにしよう
また、Google変換に同じ文字列を渡しても結果は変わらないので、ループ部分でGoogle変換結果を確認できたら候補にはトリガー要素を追加しないことにする
function! k#completefunc(suffix_key = '')
" 略
+ let google_exists = v:false
let comp_list = []
for k in s:latest_henkan_list
" 略
+ let google_exists = google_exists || has_key(k, 'by_google')
endfor
let current_pos = getcharpos('.')[1:2]
let is_trailing = getline('.')->strcharlen() < current_pos[1]
+ let context = {
+ \ 'yomi': preceding_str,
+ \ 'start_pos': b:henkan_start_pos,
+ \ 'cursor_pos': getcharpos('.')[1:2],
+ \ 'is_trailing': is_trailing,
+ \ 'suffix_key': a:suffix_key,
+ \ }
+
+ if !google_exists
+ call add(comp_list, {
+ \ 'word': preceding_str,
+ \ 'abbr': '[Google変換]',
+ \ 'dup': 1,
+ \ 'user_data': { 'yomi': preceding_str, 'google_trans': context }
+ \ })
+ endif
" 略
endfunction
トリガーに反応する部分をs:complete_done_preに追加
読みの文字列を上述のk#google_henkanに渡し、結果をs:latest_henkan_listに追加、feedkeysを介してk#completefuncを呼び出す
if has_key(user_data, 'google_trans')
let gt = user_data.google_trans
let henkan_result = k#google_henkan(gt.yomi)
if henkan_result ==# ''
echomsg 'Google変換で結果が得られませんでした。'
return
endif
call insert(s:latest_henkan_list, {
\ 'henkan': henkan_result,
\ 'mark': '[Google]',
\ 'yomi': gt.yomi,
\ 'by_google': v:true
\ })
let b:henkan_start_pos = gt.start_pos
call feedkeys("\<c-r>=k#completefunc()\<cr>\<c-n>", 'n')
return
endif

愛をとりもどせ
追記:コミット漏れ↓
自動補完を作る
とはいえ全く新しい処理を作るわけではない
今まで「変換キーを押したタイミングで」「よみがな完全一致で」変換候補を表示していたのを、「かなを入力するたびに」「よみがな前方一致で」変換候補を表示する仕組みを作れば良い
まずテキスト入力で発動する関数を準備
k#enableのautocmd定義箇所に関数コールを置く
function! k#enable() abort
" 略
+ autocmd TextChangedI * call s:auto_complete()
" 略
endfunction
s:auto_completeは以下
- 先行入力はこれまでに作った
get_preceding_strが使えるが、入力末尾のアルファベット部分(▽かわりmとか)は候補絞り込みでノイズになるのでsubstituteで削除する - 最小文字数(ここでは2字)を下回っていたら補完は行わない
- 最小文字数の部分が更新されていた場合、henkan_listを更新する
- 末尾で
<c-r>=k#autocompleteを呼んで補完リストを更新する- 通常の補完とは異なりここで
<c-n>を入力しない
- 通常の補完とは異なりここで
「辞書を毎回検索するよりは、いったん2字以上でざっくりと検索して、それ移行はVim内部で絞り込んでいったほうが処理が軽いだろう」という仮説のもと、このような設計にしている
let s:latest_auto_complete_str = ''
let s:min_auto_complete_length = 2
function! s:auto_complete() abort
let preceding_str = s:get_preceding_str('henkan', v:false)
\ ->substitute('\a*$', '', '')
if strcharlen(preceding_str) < s:min_auto_complete_length
return
endif
echomsg 'auto_complete' preceding_str
" 冒頭のmin_lengthぶんの文字が異なった場合はhenkan_listを更新
if slice(preceding_str, 0, s:min_auto_complete_length) !=# slice(s:latest_auto_complete_str, 0, s:min_auto_complete_length)
call k#update_henkan_list(preceding_str, 0)
endif
let s:latest_auto_complete_str = preceding_str
call feedkeys("\<c-r>=k#autocompletefunc()\<cr>", 'n')
endfunction
k#update_henkan_listは既存の関数だが、これまで完全一致でしか検索していなかったので、前方一致できるように引数を追加して調整する
-function! k#update_henkan_list(str) abort
+function! k#update_henkan_list(str, exact_match = v:true) abort
+ let str = a:exact_match ? $'{a:str} ' : a:str
let henkan_list = []
for jisyo in s:jisyo_list
let mark = get(jisyo, 'mark', '') ==# '' ? '' : $'[{jisyo.mark}]'
- let cmd = $"rg --no-filename --no-line-number --encoding {jisyo.encoding} '^{a:str} ' {jisyo.path}"
+ let cmd = $"rg --no-filename --no-line-number --encoding {jisyo.encoding} '^{str}' {jisyo.path}"
let results = systemlist(cmd)
for r in results
let tmp = split(r, '/')
call extend(henkan_list, tmp[1:]->map({_,v->{
\ 'henkan': v,
- \ 'yomi': a:str,
+ \ 'yomi': tmp[0]->substitute(' *$', '', ''),
\ 'mark': mark
\ }}))
endfor
endfor
let s:latest_henkan_list = henkan_list
endfunction
k#autocompletefuncは以下の通り
既存のk#completefuncと似ているが、送り仮名の引数は不要
いったんGoogle検索や辞書登録もオミット
キャッシュした候補リストをcomp_listに変換するところで、s:latest_auto_complete_strと前方一致しているかどうかでフィルタしている
function! k#autocompletefunc()
let [lnum, char_col] = b:henkan_start_pos
let start_col = s:char_col_to_byte_col(lnum, char_col)
let comp_list = []
for k in s:latest_henkan_list
" 前方一致で絞り込む
if k.yomi !~# $'^{s:latest_auto_complete_str}'
continue
endif
" ;があってもなくても良いよう_restを使う
let [word, info; _rest] = split(k.henkan, ';') + ['']
" :h complete-items
call add(comp_list, {
\ 'word': word,
\ 'menu': info .. k.mark,
\ 'info': info .. k.mark,
\ 'user_data': { 'yomi': k.yomi }
\ })
endfor
call complete(start_col, comp_list)
return ''
endfunction
s:complete_done_preをちょっと修正
冒頭の条件を変えて早期リターンする
function! s:complete_done_pre(complete_info, completed_item) abort
echomsg a:complete_info a:completed_item
- if get(a:complete_info, 'selected', -1) >= 0 && s:is_same_line_right_col('henkan')
+
+ if get(a:complete_info, 'selected', -1) < 0
+ " not selected
+ return
+ endif
+
+ if s:is_same_line_right_col('henkan')
これで https://github.com/tokuhirom/jawiki-kana-kanji-dict のような長大な読みがなを持つ辞書も使いやすくなる

自動で入力してやんよ

こんなのいちいち入力してられませんわ
小さな調整をいくつか
デバッグ用に出していたechomsgを整理
前方一致検索で送りあり候補がヒットしないよう正規表現を調整
変換時にselect_start_posを追加
enable時に各start_posを初期化
rgのエラー出力を無視
- let cmd = $"rg --no-filename --no-line-number --encoding {jisyo.encoding} '^{str}' {jisyo.path}"
+ let cmd = $"rg --no-filename --no-line-number --encoding {jisyo.encoding} '^{str}' {jisyo.path} 2>/dev/null"
sticky keyを作る
まずはほかのキーと同様にキーマップを定義
+ ";": { "func": "sticky" },
つづいてk#stickyを定義
;を入力すると何も文字を入力せずに変換ポイントを設定すれば良いだけ…なのだが、すでに変換ポイントを置いている場合は次の入力で送りあり変換をスタートさせる必要がある
ちょっとアドホックだがs:next_okuriという変数をtrueにする
" 変換中→送りあり変換を予約
" それ以外→現在位置に変換ポイントを設定
function! k#sticky(...) abort
if s:is_same_line_right_col('henkan')
let s:next_okuri = v:true
else
let current_pos = getcharpos('.')[1:2]
call s:set_henkan_start_pos(current_pos)
endif
return ''
endfunction
s:get_insert_specで変換を行うとき、henkan引数を直接指定されていなくても、next_okuriがtrueなら送りあり変換を発動するよう変更
function! s:get_insert_spec(key, henkan = v:false) abort
" 略
let kana_dict = get(s:end_keys, a:key, {})
- if a:henkan
+ let next_okuri = get(s:, 'next_okuri', v:false)
+ if a:henkan || next_okuri
- if !s:is_same_line_right_col('henkan') || pumvisible()
+ if !next_okuri && (!s:is_same_line_right_col('henkan') || pumvisible())
call s:set_henkan_start_pos(current_pos)
else
let preceding_str = s:get_preceding_str('henkan', v:false)
call k#update_henkan_list(preceding_str .. a:key)
+ let s:next_okuri = v:false
+
return $"\<c-r>=k#completefunc('{get(kana_dict,'',a:key)}')\<cr>\<c-n>"
endif
" 略
endfunction
endif
skkeletonと違って送りあり変換スタート位置にマーカーを置いていないから分かりづらいかもしれないなぁ…*を表示させるようにしようか

ちょっとだけ「子音入力」というのを試してみた
たとえばhnknと入力すると(は|ひ|ふ|へ|ほ)ん(か|き|く|け|こ)んという正規表現で辞書を検索する
結果はこう

ただでさえ同音異義語が多いのに子音一致まで範囲を広げると候補が出すぎて実用的ではないという印象
一覧から選択する部分は一つ一つ上下移動しないといけないので、それをするよりはhenkanと入力して候補リストの時点で絞り込んだほうが確定が早い この機能は導入見送り
いくつか細かな調整を追加
ユーザー辞書登録時、すでに辞書がウィンドウで開いている場合はそこへジャンプするよう修正
Google候補確定時、確定した変換結果をユーザー辞書末尾に追加
辞書のマークを説明より先に表示させるよう修正
600行を超えてきたので可能な範囲でファイルを分割
とはいえこの程度では管理は楽にはならないか
モード処理はもっと共通化できそうなのだが…
インターフェースを整理しよう
ユーザーが設定できそうな部分はすべてinitialize関数に渡して設定させる
いままでinitializeの中に入れてたkana_tableの読み込みを関数として独立させる
function! k#default_kana_table() abort
return json_decode(join(readfile('./kana_table.json'), "\n"))
endfunction
initializeで引数を読むように改造
okuri_markerは現状使っていないのだが今後のためにコメントで予約
テーブルのデフォルト値には上のk#default_kana_table()を利用
ユーザー辞書は安全のためフルパスかどうか(/で始まるかどうか)を検査
-function! k#initialize() abort
+function! k#initialize(opts = {}) abort
+ " マーカー
+ let s:henkan_marker = get(a:opts, 'henkan_marker', '▽')
+ let s:select_marker = get(a:opts, 'select_marker', '▼')
+ " let s:okuri_marker = get(a:opts, 'okuri_marker', '*')
+ " ユーザー辞書
+ let s:user_jisyo_path = get(a:opts, 'user_jisyo_path', expand('~/.cache/vim/SKK-JISYO.user'))
+ if s:user_jisyo_path !~ '^/'
+ echoerr '[k#initialize] user_jisyo_path must be start with /'
+ return
+ endif
+ " 指定されたパスにファイルがなければ作成する
if glob(s:user_jisyo_path)->empty()
" 略
endif
+ " 変換辞書
+ let s:jisyo_list = get(a:opts, 'jisyo_list', [])
+
+ " かなテーブル
+ let kana_table = get(a:opts, 'kana_table', k#default_kana_table())
- for [k, val] in items(raw)
+ for [k, val] in items(kana_table)
" 以下略
こんな感じで呼び出す
call k#initialize({
\ 'user_jisyo_path': '/path/to/SKK-JISYO.user',
\ 'jisyo_list': [
\ { 'path': expand('~/.cache/vim/SKK-JISYO.L'), 'encoding': 'euc-jp', 'mark': 'L' },
\ { 'path': expand('~/.cache/vim/SKK-JISYO.geo'), 'encoding': 'euc-jp', 'mark': 'G' },
\ { 'path': expand('~/.cache/vim/SKK-JISYO.jawiki'), 'encoding': 'utf-8', 'mark': 'W' },
\ { 'path': expand('~/.cache/vim/SKK-JISYO.emoji'), 'encoding': 'utf-8' },
\ ]
\ })
自動補完最小文字数もオプションに追加
候補リストの出力高速化を試みる
複数辞書に対してはforループでsystemlist('rg {yomi} {jisyo_path}')を何度も実行している
何度もシステムコールを発行するのは処理が重そうなのでコマンド文字列を;で繋いで一発で実行できるようにする(systemlist('rg yomi jisyo_1 ; rg yomi jisyo_2 ; ...'))
k#update_henkan_listを修正(diffにしようと思ったけど関数名以外ほぼすべて変わっていたので通常表示)
一括で表示するだけだとどの辞書の項目かわからなくなってしまうので、--with-filenameをつけてファイル名も出力する
辞書名をもとにmarkをつける(後述)
function! k#update_henkan_list(str, exact_match = v:true) abort
let str = a:exact_match ? $'{a:str} ' : $'{a:str}[^ -~]* '
" コマンド文字列生成
let cmd = ''
for jisyo in s:jisyo_list
let cmd ..= 'rg --no-heading --with-filename --no-line-number'
\ .. $" --encoding {jisyo.encoding} '^{str}' {jisyo.path} 2>/dev/null; "
endfor
let results = systemlist(cmd)
let henkan_list = []
for r in results
" /path/to/jisyo:よみ /変換1/変換2/.../
" 変換部分にcolonが含まれる可能性があるためsplitは不適
let colon_idx = stridx(r, ':')
let path = strpart(r, 0, colon_idx)
let content = strpart(r, colon_idx+1)
let space_idx = stridx(content, ' /')
let yomi = strpart(content, 0, space_idx)
let henkan_str = strpart(content, space_idx+1)
call extend(henkan_list, split(henkan_str, '/')->map({_,v->{
\ 'henkan': v,
\ 'yomi': trim(yomi),
\ 'mark': s:jisyo_mark_pair[path]
\ }}))
endfor
let s:latest_henkan_list = henkan_list
endfunction
pathとyomiとhenkansのパースは関数として切り出してもよいかも
辞書名とmarkのペアはinitialize関数の変換辞書を取り出すところで作成
rgの出力でパスと内容が:で区切られているので、これをパスに指定することは禁止する(とおもったけどそもそもファイルパスに使えないらしいので無意味かも)
ついでにencodingも初期化する
" 変換辞書
let s:jisyo_list = get(a:opts, 'jisyo_list', [])
let s:jisyo_mark_pair = {}
for jisyo in s:jisyo_list
if jisyo.path =~ ':'
echoerr "[k#initialize] jisyo.path must NOT includes ':'"
return
endif
let s:jisyo_mark_pair[jisyo.path] = get(jisyo, 'mark', '') ==# '' ? '' : $'[{jisyo.mark}] '
let encoding = get(jisyo, 'encoding', '')
if encoding ==# ''
let jisyo.encoding = 'auto'
endif
endfor
とはいえコマンド実行を1回にまとめたところで辞書が大きければ本質的には問題解決しないか…
いくつか調整
k#update_henkan_list内で元のリストを作り、k#completefuncとk#autocompletefuncのそれぞれでVim用に整形していたのを、k#update_henkan_listで整形までするようリファクタリング
自動補完の条件を修正
ユーザー辞書が辞書リストに無かった場合は自動的に追加するよう設定
結局辞書リストではなくgrep文字列だけ保存しておけば良いのでは?と思ったので対応
変換ヒット件数をエコーバック これで<c-r>=の表示をかき消すことができた
っが連続したときに合成する機能を追加
google日本語入力でたまに助かっている

autocmdにinline_mark#clearを追加
現時点では特に効果なし
調整
グーグル検索をオプションフラグ化
辞書のパスが重複できないよう制限
有効な変換候補がないときに自動選択しないよう調整
自動補完を同期的に行っていたが、辞書を増やしてみたら処理が追いつかなくなり次の文字の入力が落ちるようになってしまったので非同期化を試みる
job実行はvirtual markと同じくVimとNeovimでAPIが違う…が、こちらも以前dotfilesに互換レイヤーを作っていたのでこれを持ってくる
dotfiles/.vim/autoload/mi/job.vim
dotfilesではこんな感じで ripgrepをquickfixに入れるのに使っている
call job#start('rg --vimgrep ' .. query, {
\ 'out': {data->execute('caddexpr filter(data, ''!empty(v:val)'')')},
\ 'exit': {_->execute('copen')} })
これを使って非同期実行をしよう
なお元々はvim-jetpackのこのあたりを参考にしたものである
辞書のパスと辞書の数を保存 これ結局コマンドを一つに統合しないほうが良かったか…まあ後で整理しよう
このあとのためにコマンド文字列のクォートを変更(シングルクォートは内部にスペースがあると区切られてしまう)
このあとのために`k#update_henkan_list()を分割
では自動補完を作る まずはjobモジュールをインポート
+source ./job.vim
s:auto_complete()内の変換リスト作成関数呼び出しを変更
- call k#update_henkan_list(preceding_str, 0)
+ call k#async_update_henkan_list(preceding_str)
k#async_update_henkan_list()はこう 既存のk#update_henkan_list()では引数で完全一致と前方一致を切り替えていたけど、自動補完用なので前方一致に専念することができる(逆に通常の変換も完全一致オンリーにできるはずだ)
最初にスクリプト変数を初期化しているが、s:latest_henkan_listはここまででも使ってきた実際の変換リストが入る変数、s:latest_async_henkan_listは今回初出、非同期の変換リストが入る変数
各辞書ごとにコマンドを分割してjobでgrepを実行している
結局実行コマンドを分割してる、あとで始めから結合しないように直そう
" 自動補完用なので前方一致のみ
function! k#async_update_henkan_list(str) abort
let s:latest_henkan_list = []
let s:latest_async_henkan_list = []
let grep_cmd_list = split(s:grep_cmd, '2>/dev/null; ')
for cmd in grep_cmd_list
let run_cmd = substitute(cmd, ':query:', $'{a:str}[^!-~]* ', 'g')
call job#start(run_cmd, {
\ 'exit': {data->s:populate_async_henkan_list(data)} })
endfor
endfunction
jobのexitで呼ばれるs:populate_async_henkan_list()はこちら
最初にgrep結果をs:latest_async_henkan_list変数に蓄積し、その数が辞書リストの数に満たなければ終了
辞書リストの数に達していたら、それを辞書の優先度順に並び替え、各要素(つまり各辞書の出力の配列)をextendしてhenkan_list化
function! s:populate_async_henkan_list(data) abort
" 変換リストの蓄積が辞書リストの数に満たなければ早期脱出
call add(s:latest_async_henkan_list, a:data)
if len(s:latest_async_henkan_list) != s:jisyo_list_len
return
endif
" 蓄積リストを辞書リストの順に並び替える
let henkan_list = []
for path in s:jisyo_path_list
let result_of_current_dict_index = indexof(s:latest_async_henkan_list, {
\ _,v -> !empty(v) && substitute(v[0], ':.*', '', '') ==# path
\ })
if result_of_current_dict_index < 0
continue
endif
call extend(henkan_list, s:latest_async_henkan_list[result_of_current_dict_index])
endfor
call s:save_henkan_list(henkan_list, "\<c-r>=k#autocompletefunc()\<cr>")
endfunction
s:save_henkan_listに引数を追加して、末尾でfeedkeysで補完ポップアップを表示
-function! s:save_henkan_list(source_list) abort
+function! s:save_henkan_list(source_list, after_feedkeys = '') abort
" 中略
+ if a:after_feedkeys != ''
+ call feedkeys(a:after_feedkeys, 'n')
+ endif
endfunction
まだ整理が必要だが大枠はできた
必要な挙動を整理しよう
aやt(通常の文字)を入力した場合:
- かなスタート位置から現在位置までの間が「登録されたキー」に一致するなら
<bs>をそのキーの数だけ繰り返して登録された値を返す-
nyなら<bs><bs>にゃをfeedkeysする - これ分割して良いな、つまり
[2, 'にゃ']を返す
-
- どのキーとも一致しなければデフォルト値を返す
- デフォルト値は先行入力なしの値またはその文字になる たとえば
aならあ、tならt - ここも先行入力を消す必要があるからそれぞれ
[1, 'あ'][]かな
- デフォルト値は先行入力なしの値またはその文字になる たとえば
- まてまて、
tはかなスタート位置を設定する必要がある- それは既存の仕様で良いのか
- かなスタート位置よりも同行右列ならそのまま それ以外なら現在位置にセット
- 確定やモードチェンジは決め打ちで現在位置(の右)にかなスタートを設定して良さそうだな いや、
[0, 0]にリセットでも良いのか - 変換スタート設定もかなスタートを区切る 変換エンドは区切らない
A(シフト入力)の場合:
- 実はstickyの応用版と捉えたほうが良さそうなので分析は劣後
;(sticky)の場合:
- 通常入力と同じように考えようinsert_specの返り値は
[1, { 'func': 'sticky' }]かな - 変換スタート位置を設定する inputからhenkanステートへ移行
- 「変換スタート位置の同列右にいるか」で判断はできる…けど状態変数を持ったほうが良さそう?
- henkanステートで変換キーが押された場合は変換を実行 selectステートへ移行
- 確定時にはステートをdirectへ復帰 すなわち変換スタート位置をリセット
- 確定されなかった場合はhenkanステートへ復帰
- とおもったけどIMEもそういう動きはしない 一度変換を試みられた時点で常に確定で良さそうだ
- selectステートはhenkan & pumvisibleで判断できそうだな
- やっぱ無理では?自動補完と手動変換を区別できない
- したがって変換キーを押したところで状態変数をselectに移行する
- henkanステートでstickyが押された場合は変換エンド位置を設定 okuriステートへ移行
- okuriステートは変換エンド位置の比較で判断可能
- この状態で通常入力が来たら送りあり変換を行う
aやtなど通常入力 okuriステートの場合
- 入力を行い、それを利用して変換に入る
- ひとまずローマ字以外の入力は考えない ほかの入力形式に対応するとなると逆変換テーブルが要る
A(シフト入力)の場合:
- こうなるとわかりやすい
- 内部的に
;aとしているだけである - 共通化すると
[1, { 'func': 'sticky', 'post_func_str': 'あ' }]かな…pre_func_stringはあり得るか?まあ拡張性があっても良いか- abbrevのところの検討を反映すると
[1, { 'func': sticky }, 'あ']かな?{ 'str': 'あ' }でも良い
- abbrevのところの検討を反映すると
- もしかして
imap ;aでよいのでは
q(カタカナモードチェンジ)の場合:
- jsonには`"q": { "mode": "mode#katakana", "name": "カタカナ" },'みたいに指定しようか
- ユーザーに自由に設定させられたら面白いと思ったけどこれ無理あるか…この拡張性は不要だ
- とくにabbrevモードのことを考えるとしんどいね
- inputステートで実行された場合はモードをkatakanaに変更 これはステートとは別に持つ
[1, { 'mode': 'katakana' }]
- henkanステートで実行された場合はその場でカタカナに変更して確定 モード変更はしない
- これはokuriモードでもそれでよさそう
- カタカナモードで変換を実行されたときも変換できるようにする必要がある
- クエリを投げるときにひらがなに戻す
/(abbrevモード)の場合:
- stickyを設定し、変換・確定・削除以外のキーをキーそのまま入力にさせる
- 変換・確定・変換ポイントの削除で解除される
- 共通化すると
[1, { 'func': 'sticky' }, { 'mode': 'abbrev' }]みたいになるか
込み入った実装をリファクタリング
まずはjisyo_list関連のコードを整理しよう
引数のjisyo_listにユーザー辞書が含まれているかをフラグを使って検査していたがビルトインのindexofを使うように修正
rgを一回で実行できるようにコマンドをまとめていた部分を修正
s:jisyo_listも保存するようにし、それぞれの辞書に対するコマンドもちゃんと保存するようにした
ユーザー辞書登録時のエラーメッセージを整理
同期・非同期の関数を分離したことでk#update_henkan_listの第二引数が無意味になったので削除
かなテーブルの処理を見直し
いままでk#initialize()でs:start_keysとs:end_keysのオブジェクトを作っていた
これが複数あったのは開始キーでかなスタートを設定したかったからだが、end_keysに空オブジェクトを埋め込めばstart_keysは不要になる
日本語だと説明しづらいのでコード↓
" かなテーブル
let kana_table = get(a:opts, 'kana_table', k#default_kana_table())
- let s:start_keys = {}
let s:end_keys = {}
for [k, val] in items(kana_table)
let key = s:trans_special_key(k)
let preceding_keys = slice(key, 0, -1)
let start_key = slice(key, 0, 1)
let end_key = slice(key, -1)
- let s:start_keys[start_key] = 1
if !has_key(s:end_keys, end_key)
let s:end_keys[end_key] = {}
endif
let s:end_keys[end_key][preceding_keys] = val
+
+ " start_keyもend_keysに登録する(入力開始位置の指定のため)
+ if !has_key(s:end_keys, start_key)
+ let s:end_keys[start_key] = {}
+ endif
endfor
これでk#enable()でs:start_keysとs:end_keysを接続していた箇所を圧縮できる
- for key in extendnew(s:start_keys, s:end_keys)->keys()
+ for key in s:end_keys->keys()
で、もうend_keysという名前が相応しくないのでkeymap_dictに改名
大文字にするs:capital()関数を作っていたがビルトインのtoupper()で良いことに気づいたので変更
s:keys_to_remapsとs:keys_to_unmapsを両方保持していたが片方で良いことに気づいたので調整
以下はエッセンス、全体はgit commitに
" マッピング部
- if empty(current_map)
- call add(s:keys_to_unmaps, k)
- else
- call add(s:keys_to_remaps, current_map)
- endif
+ call add(s:keys_to_remaps, empty(current_map) ? k : current_map)
" マッピング解除部
- for m in s:keys_to_remaps
- call mapset('i', 0, m)
- endfor
- for k in s:keys_to_unmaps
- execute 'iunmap' k
+ for k in s:keys_to_remaps
+ if type(k) == v:t_string
+ execute 'iunmap' k
+ else
+ call mapset('i', 0, k)
+ endif
endfor
k#enable()内でマッピングするキーを算出していたが、かなテーブルが変わらなければ不変なので、これもマッピングコマンド文字列をk#initialize()で計算して保持する方式にする
まずs:keymap_dictを作っていた部分の末尾にshift_key_listを作る処理を追加
+ let shift_key_list = []
let s:keymap_dict = {}
for [k, val] in items(kana_table)
" 中略
+ " 文字入力を開始するアルファベットのキーは変換開始キーとして使用する
+ if type(val) == v:t_string && start_key =~# '^\l$'
+ call s:uniq_add(shift_key_list, toupper(start_key))
+ endif
+ endfor
ちなみにs:uniq_add()はこう 配列にその要素がなければ追加する
function! s:uniq_add(list, item) abort
if index(a:list, a:item) < 0
call add(a:list, a:item)
endif
endfunction
さらにs:keymap_dictを作り終わったあとにs:map_cmdsの作成処理を追加
keytrans()する部分などはk#enable()から持ってきた
" 入力テーブルに既に含まれている大文字は変換開始に使わない
call filter(shift_key_list, '!has_key(s:keymap_dict, v:val)')
let s:map_cmds = []
for key in s:keymap_dict->keys()
let k = keytrans(key)
let k_lt = substitute(k, '<', '<lt>', 'g')
call add(s:map_cmds, [k, $"inoremap {k} <cmd>call k#ins('{k_lt}')<cr>"])
endfor
for k in shift_key_list
call add(s:map_cmds, [k, $"inoremap {k} <cmd>call k#ins('{tolower(k)}',1)<cr>"])
endfor
これによりk#enable()のループの方は大幅に簡略化できる
let s:keys_to_remaps = []
- for key in s:keymap_dict->keys()
- let k = keytrans(key)
- let k_lt = substitute(k, '<', '<lt>', 'g')
- let current_map = maparg(k, 'i', 0, 1)
- call add(s:keys_to_remaps, empty(current_map) ? k : current_map)
- execute $"inoremap {k} <cmd>call k#ins('{k_lt}')<cr>"
-
- if key =~ '^\l$'
- let ck = toupper(k)
- let current_map = maparg(ck, 'i', 0, 1)
- call add(s:keys_to_remaps, empty(current_map) ? ck : current_map)
- execute $"inoremap {ck} <cmd>call k#ins('{k}',1)<cr>"
- endif
+ for [key, map_cmd] in s:map_cmds
+ let current_map = maparg(key, 'i', 0, 1)
+ call add(s:keys_to_remaps, empty(current_map) ? key : current_map)
+ execute map_cmd
endfor
ここまできて気づいたが全角英数モードを作ることを考えるとキーボードで入力できる英数字は全部k#ins()を通さないとだめやん…
let s:keyboard_key_list = ('abcdefghijklmnopqrstuvwxyz'
\ .. 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
\ .. '0123456789!@#$%^&*()'
\ .. "`-=[]|;',./"
\ .. '~_+{}\:"<>?')->split('\zs')
これで初期化すればstart_keyを気にする必要はなくなりそうだ
→と思ったけど大文字の判定を潰してしまうのでだめ
いくつか細かい調整
辞書によってはゔをう゛で登録しているようなのでこれに対応
substituteしていたところをkeytransに変更
かなスタート座標設定用関数を追加
オプションのパース関数をつくりopts.vimにファイルごと切り出し
ユーティリティ関数をutils.vimに切り出し
initialize前にenable/disableしようとしたときに失敗するよう修正
オプション利用位置でopts#get()を直接使用するよう修正 https://github.com/kawarimidoll/sandpit/commit/88d221efe831ce8f40a132f5abf6c75d0fde5b27
内部関数の引数を調整 https://github.com/kawarimidoll/sandpit/commit/26cf960e6032146f0ce577fd09e171ea9e7800da
絶対パス判定用のisabsolutepath()というビルトインがあったので利用(名前が長い) https://github.com/kawarimidoll/sandpit/commit/9279740a2da70fa02cdf6cb9f4937e2fcf5242be
オプション引数のmarkをそのまま使うよう変更 https://github.com/kawarimidoll/sandpit/commit/b09fe5b42ea0743b316073cce5cfaa2507ee2eea
確認用に辞書を追加 https://github.com/kawarimidoll/sandpit/commit/0d5807ee715e90081ae2811831ba34542ff78cd1
henkan_posをセットするときに一度マークを消去 https://github.com/kawarimidoll/sandpit/commit/5cc1356e09d2ac3718d55cb4103c46e3c22dee70
内部関数の実装を単純化 https://github.com/kawarimidoll/sandpit/commit/fd9f0b5c3125821160d904657cee10372f6ac9c2 https://github.com/kawarimidoll/sandpit/commit/7099d4d0653393c2b7f6aa1e5a8c782853c85cad https://github.com/kawarimidoll/sandpit/commit/e3094ea1bd507f25ad09d43175cad7aeab7688af
非同期辞書検索を改善する方法を思いついたので対応
まずjobのコールバックでjob_idを受け取れるよう改造(もともと受け取れるのだが互換レイヤーでは潰していた)
ripgrepの実行で--with-filenameを使って出力と同じ行に辞書名を出すようにしていたが、これは辞書のパスをコールバックに受け渡すのが難しいため
lambdaはクロージャとして動いてしまうので、以下のようなコードを書いたとき、s:on_exit1()に渡されるpathの値は、(forが回り切ってから各コマンドが終了すると考えると)全てforの最後のpathの値になってしまう
for path in path_list
call job#start(cmd, { 'exit': {_ -> s:on_exit1(path) }})
endfor
このためgrep結果と辞書を結びつけることが難しいと考え、ripgrepの出力に辞書パスを表示するようにしていた
しかし、jobのコールバックに渡されるjob_idは実行時に取得することができることに気づいた
以下の実装のアイデアを使えば、s:job_listに保存した値を通して、job_idと辞書パスの紐づけを行うことができる
let s:job_list = []
for path in path_list
" letで得られるjob_idとs:on_exit2に渡されるjob_idは同じ
let job_id = job#start(cmd, { 'exit': {data, job_id -> s:on_exit2(data, job_id) }})
call add(s:job_list, [job_id, path])
endfor
ということで作ったのが以下
k#async_update_list()はコマンドを呼び出しつつ、そのときのjob idと辞書オブジェクトのペアをs:run_job_listに保存していく
on_exitはdataとjob_idの2引数を取るのでlumbdaを介さずfuncrefを直接渡している
let s:async_result_dict = {}
function! k#async_update_list(str) abort
let s:latest_henkan_list = []
let s:run_job_list = []
for jisyo in opts#get('jisyo_list')
" 既存のコマンド定義を使うために一時的に置換で対応
let cmd = substitute(jisyo.grep_cmd, 'heading --with-', '', '')
\ ->substitute(':query:', $'{a:str}[^!-~]* /', '')
let job = job#start(cmd, { 'exit': funcref('s:on_exit') })
call add(s:run_job_list, [job, jisyo])
endfor
endfunction
s:on_exit()の実装は以下
呼び出されるとs:async_result_dictにjob idとdataの組を保存する
その後、上記のk#async_update_listで作られたs:run_job_listをループして、そこに保存されているjob idをもとに候補リストを作っていく
function! s:on_exit(data, job_id) abort
let s:async_result_dict[a:job_id] = a:data
" 手動変換がスタートしていたら自動補完はキャンセルする
if s:is_same_line_right_col('select')
call utils#debug_log('manual select is started')
return
endif
" 蓄積された候補を辞書リストの順に並び替える
let henkan_list = []
let is_finished = v:true
for [job_id, jisyo] in s:run_job_list
if !has_key(s:async_result_dict, job_id)
" 検索が終わっていない辞書がある場合は早期終了
let is_finished = v:false
continue
endif
for r in s:async_result_dict[job_id]
if empty(r)
continue
endif
" ここに既存のcomplete-items生成処理が入る
endfor
endfor
if is_finished
" すべての辞書の検索が終わったら蓄積変数をクリア
let s:async_result_dict = {}
endif
if empty(henkan_list)
return
endif
let s:latest_henkan_list = henkan_list
call feedkeys("\<c-r>=k#autocompletefunc()\<cr>", 'n')
endfunction
s:async_result_dictをただのリストではなく辞書にしているのは直前の検索が終わる前に新しい検索が始まったときに対応するため
これを対応しないと(実用上ほぼ起こらないとは思うが)連続で検索された場合に候補リストが混ざってしまうことがあった ループに使われるs:run_job_list自体は同期的に作られるため、別の候補を参照してしまう危険は避けられる
(ここには結論だけ書いてるけど何を返したら非同期が思い通りの順序になるかめっちゃ実験した)
変換リストのパース処理を s:async_update_listから外に切り出し https://github.com/kawarimidoll/sandpit/commit/a2f3c2fe1e3b36f966f8d4952c8d66978141e4e1
手動変換も↑を使うように変更 https://github.com/kawarimidoll/sandpit/commit/05a897b212202cde3dc8ec5a66bd573ee076f7f3
使わなくなった記述の削除 https://github.com/kawarimidoll/sandpit/commit/741bbaa82d8735382933d28cfa86f56b8c709198
変換の処理をhenkan_list.vimに独立 https://github.com/kawarimidoll/sandpit/commit/f3d161d0bd1ec5d919f60fec7778df2719aa2883
自動補完を辞書の設定順ではなく読みの文字数順にソートする設定を追加(オプトイン) https://github.com/kawarimidoll/sandpit/commit/e4bf5b3f1928476b1d5347b9e9348bff1c159884