日本語入力Vimプラグインを作ったので自慢します
SKKライク日本語入力プラグインを公開しました。
その名も tuskk (tˈʌsk)です。
VimおよびNeovimで動作します。
基本の使い方
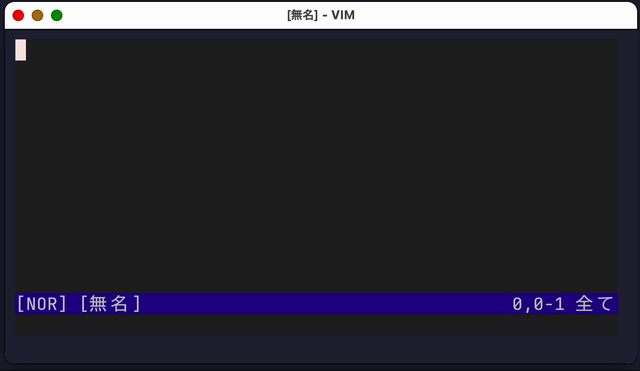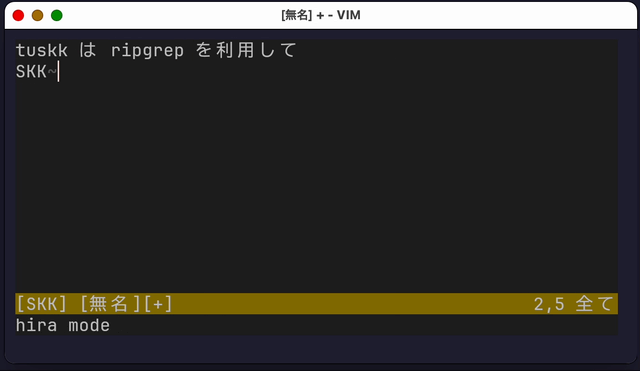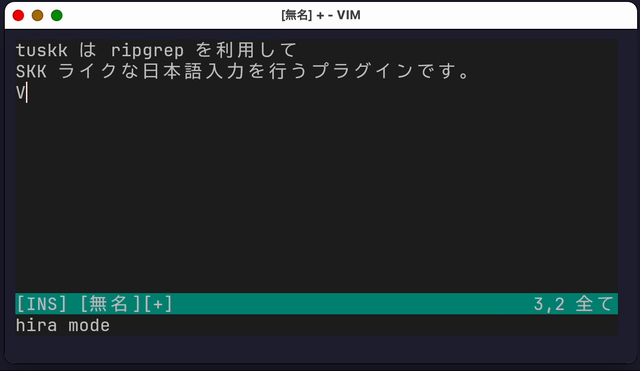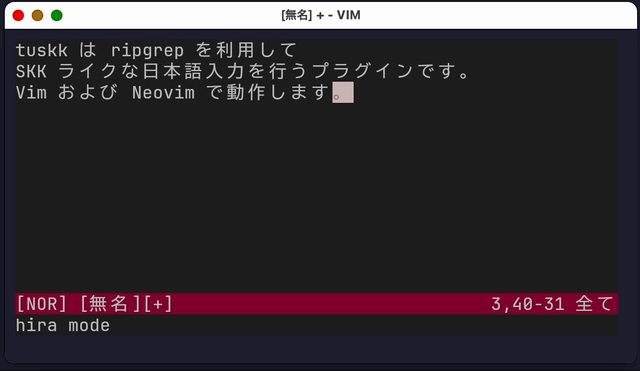
tuskkを起動すると、一般的なIMEのように、ローマ字で日本語を入力できるようになります。一般的なIMEと異なるのは、このとき入力されるひらがなは確定された状態になっていることです。
この際、Shiftキーを押しながら入力することで、変換待機状態になります。この状態で変換開始にマッピングされたキーを押すことで、漢字変換を行うことができます。
また、変換待機状態で再度Shiftキーを押しながら入力すると、送りあり変換を開始します。
これにより、変換範囲をユーザーの意図通りに調整できます。
kannji → かんじ
Kannji → 漢字
KannJi → 感じ
また、Shiftキーを押しながらのキー入力が負担になることの対策として、stickyという仕組みも用意されています。
このキーを押すと、次のキーがShiftされた扱いになります。以下は;をstickyとした例です。
;kannji → 漢字
;kann;ji → 感じ
コンセプト
上でSKKライクと書いていますが、tuskkはあくまで日本語入力補助プラグインを指向しており、SKK実装を作ることを目的としていません。
他のSKK実装でできることを諦めている部分があるため、既存のSKKに慣れ親しんでいるひとは違和感を覚える点があるかもしれません。
以下のような点が特徴的だと思います。
辞書の読み込み
tuskkは SKK辞書ファイルの読み込みを行いません 。
変換を呼び出したときにripgrepを利用して辞書を検索し、それをパースして候補リストに表示します。
入力中文字の表示
SKKといえば変換開始位置を▽で表示しているイメージですが、tuskkではこれを表示しません。
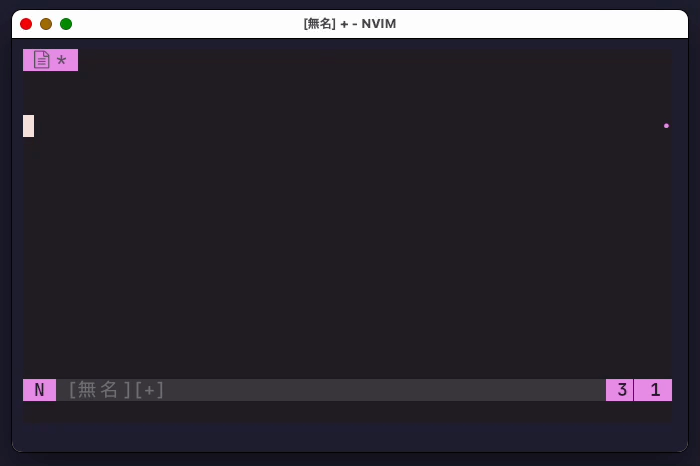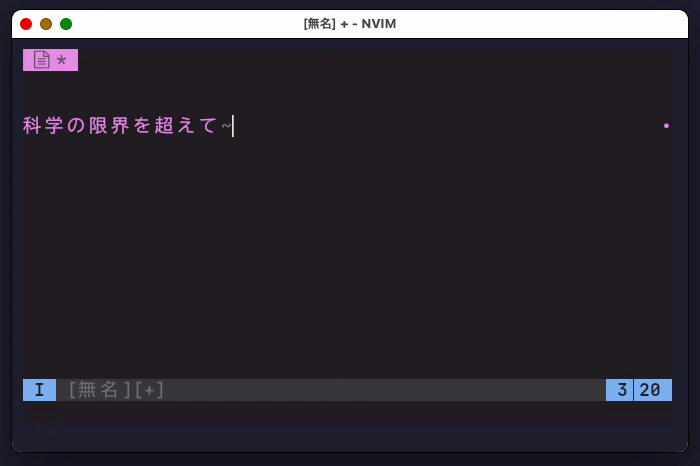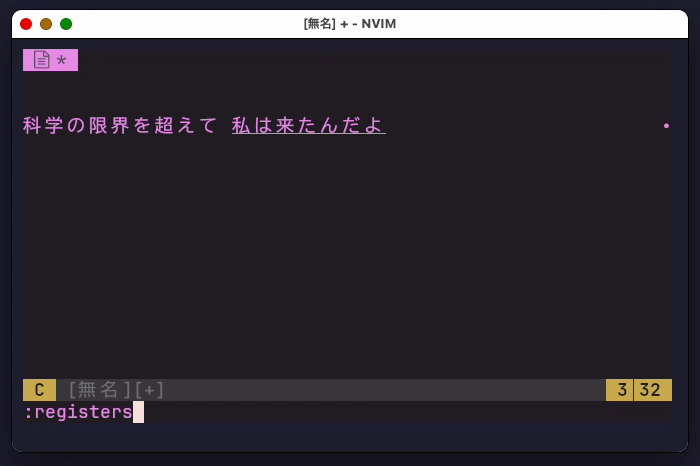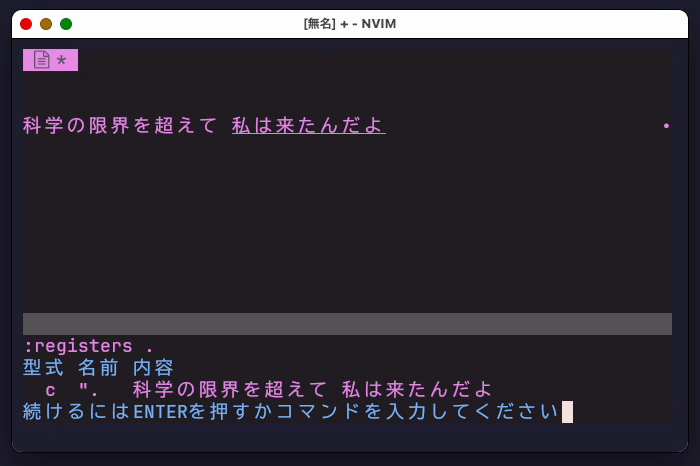
入力中の文字はvirtual textを、変換範囲の表示はハイライトを用いて表示します。したがって、バッファに反映される文字列は確定されたもののみです。
これはドットレジスタで確認できます。
自動補完
tuskkでは変換キーを押さなくても自動で候補を表示する機能があります。
内部的には、キー入力のたびにripgrepで辞書検索を行っています。処理が遅くなることを防ぐため、自動補完開始までの遅延時間を設定できます。
コマンドラインでの動作
tuskkはコマンドラインでは動作しません。コマンドラインモードは挿入モードとは全くAPIが異なるため、対応は諦めました。
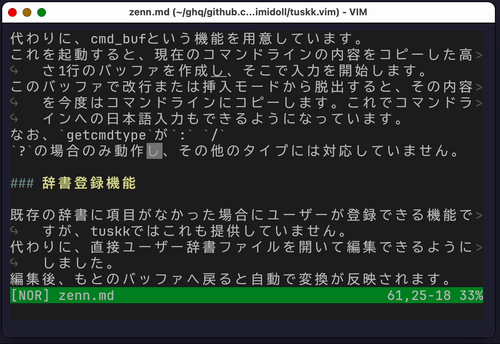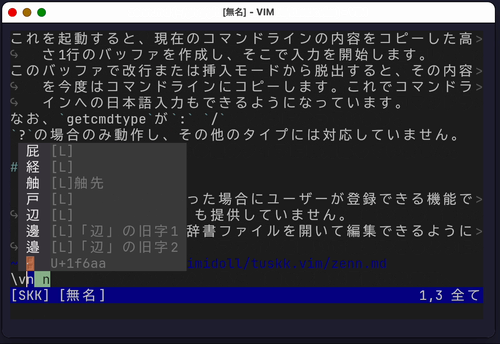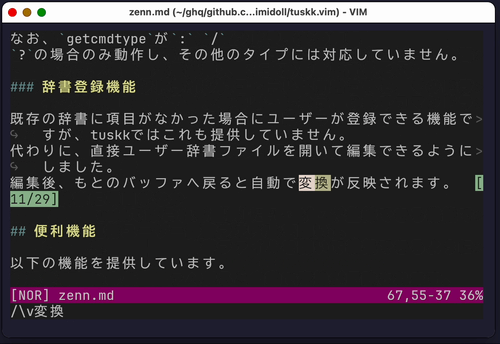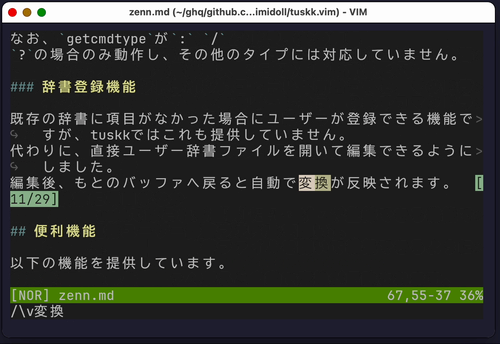
代わりに、cmd_bufという機能を用意しています。
これを起動すると、現在のコマンドラインの内容をコピーした高さ1行のバッファを作成し、そこで入力を開始します。
このバッファで改行または挿入モードから脱出すると、その内容を今度はコマンドラインにコピーします。これでコマンドラインへの日本語入力もできるようになっています。
なお、getcmdtypeが: / ?の場合のみ動作し、その他のタイプには対応していません。
辞書登録機能
既存の辞書に項目がなかった場合にユーザーが登録できる機能ですが、tuskkではこれも提供していません。
代わりに、直接ユーザー辞書ファイルを開いて編集できるようにしました。
編集後、もとのバッファへ戻ると自動で変換が反映されます。
便利機能
以下の機能を提供しています。
かなテーブル設定
一般的なローマ字テーブルはtuskkの関数として提供していますが、これはあくまでもVimの辞書を返すだけの関数です。
アルファベットと日本語の対応は、ユーザーが自由に調整できます。
例えば、「kt」を「こと」に、「ms」を「ます」にするといった独自設定も自由自在です。
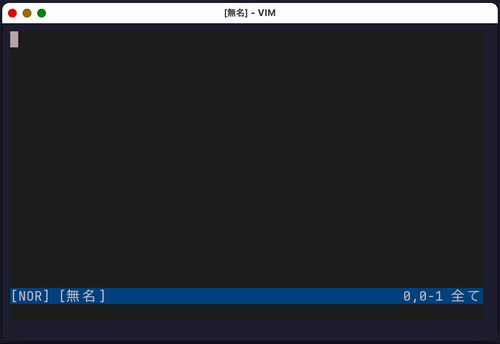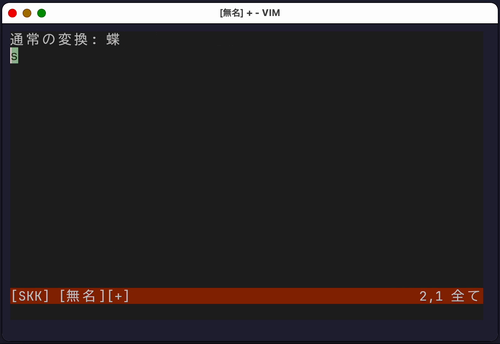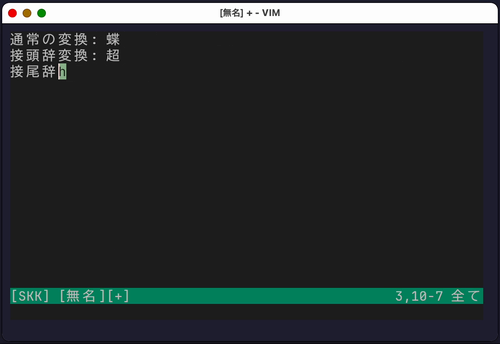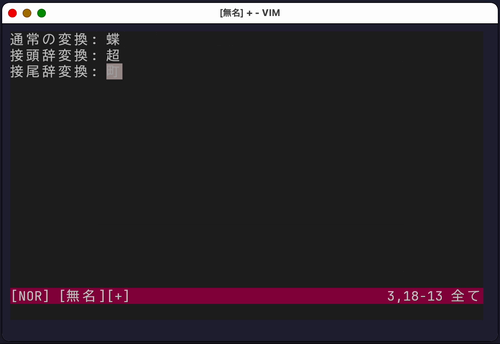
接頭辞・接尾辞変換
他の熟語の前後につく語を入力する場合、普通に変換すると無関係な候補が大量に出てしまうことがあります。
例えば、「ちょう」という読みに対応する漢字は多くありますが、「ちょう○○」という場合や、「○○ちょう」という場合に使える漢字は限られます。
zengo という内部関数を実行することで、変換候補を接頭辞・接尾辞に適したものに限定できます(辞書に登録されている必要があります)。
ビルトイン設定では>にマッピングされています。
自動変換開始
変換待機状態で特定の文字を入力すると、自動で変換を開始できます。
ビルトイン設定にはを 。などが登録されていますが、ユーザーが自由に設定可能です。
変換開始位置調整
extend / shrink という内部関数を実行することで、変換開始位置を移動できます。変換開始を忘れても安心です。ビルトイン設定では<left> <right>にマッピングされています。

数値変換
数値を変換範囲に含んでいた場合、全角数字、漢数字などに変換できます。
数字キーはShiftキーと同時に入力できない(記号になってしまう)ため、stickyの利用が必要です。
対応している変換形式は以下の記事で紹介したものです。
その他
以下の機能も使用できます。設定方法はhelpファイルに記載しています。
- 連続した「っ」を1つとみなす(例:「けっっか」を「結果」に変換できる)
- 変換候補が1つの場合、候補一覧を表示せず自動で確定
- Google日本語入力APIを利用した変換
- などなど
設定例
筆者はこんな感じで設定して使用しています。
call tuskk#initialize({
\ 'user_jisyo_path': '~/.cache/vim/SKK-JISYO.user',
\ 'jisyo_list': [
\ { 'path': '~/.cache/vim/SKK-JISYO.L', 'encoding': 'euc-jp', 'mark': '[L]' },
\ { 'path': '~/.cache/vim/SKK-JISYO.geo', 'encoding': 'euc-jp', 'mark': '[G]' },
\ { 'path': '~/.cache/vim/SKK-JISYO.station', 'encoding': 'euc-jp', 'mark': '[S]' },
\ { 'path': '~/.cache/vim/SKK-JISYO.jawiki', 'encoding': 'utf-8', 'mark': '[W]' },
\ { 'path': '~/.cache/vim/SKK-JISYO.emoji', 'encoding': 'utf-8' },
\ { 'path': '~/.cache/vim/SKK-JISYO.nicoime', 'encoding': 'utf-8', 'mark': '[N]' },
\ ],
\ 'kana_table': tuskk#opts#builtin_kana_table(),
\ 'suggest_wait_ms': 200,
\ 'suggest_prefix_match_minimum': 5,
\ 'suggest_sort_by': 'length',
\ 'use_google_cgi': v:true,
\ 'merge_tsu': v:true,
\ 'trailing_n': v:true,
\ 'abbrev_ignore_case': v:true,
\ })
inoremap <c-j> <cmd>call tuskk#toggle()<cr>
cnoremap <c-j> <cmd>call tuskk#cmd_buf()<cr>
「変換のたびに検索しなおすのは動作が遅くなるのでは?」と思われるかもしれませんが、以下の辞書を設定していても、手元ではストレスない速度で動作させることができています。
- skk-dev/dictのL辞書(17万行)、geo辞書(11万行)、station辞書(2万行)、emoji辞書(4千行)
- jawiki辞書(58万行)
- nicoime辞書(25万行)
ちなみに、neologd辞書(103万行)を追加したら、さすがに重たくて使用に堪えませんでした。
既知の問題
Vimでのみ、suggestを有効にすると表示が乱れることがあります。

texprop関連の問題ではないかと考えているのですが、以下の通り再現が難しく、現状は原因不明です。
- ゆっくり入力すると発生しない→常に表示が乱れるわけではない
- 空のバッファでも発生する→近くの文字が入っているわけではない
- 出てくる文字が一定ではない→文字コードが露出しているわけではない
Vimの内部構造に詳しい方、助けてください🙏。
なお、まだ開発してから日が浅いので、他にも未発見のバグが含まれている可能性があります。
裏話など
仕様変更の過程
VimConf直前ごろから作っていたのですが、何度か仕様変更を行ったので1ヶ月ほどかかってしまいました。
途中まではこのscrapに記録を残していたのですが…最終的には大幅に仕様が変わっています。
- lmapでのマッピング
- maparg / mapset方式に変更
- ローマ字部分にvirtual textを使用
- 全てvirtual textを使う方式を採用
開発中にVimをクラッシュさせる方法を発見
開発中にtextprop関連のバグを発見しました。特定の操作をするとE340が発生しVimがクラッシュするバグです。
こちらは、以下のissueで修正してもらいました。
この修正を必要とするため、Vimではパッチ9.0.2146を要求します。開発開始時点(VimConf当時)のVimでは動きません。
complete-itemの仕様
Vimの標準の機能では日本語の候補を上手く絞り込むことができないため、complete-itemは以下のような内容にして、自前で絞り込みを行っています。
wordを空文字にするというのは滅多にされない手法なのではと思います。
{
'word': '',
'abbr': '変換',
'dup': 1,
'empty': 1,
'user_data': { 'yomi': 'へんかん', 'len': 4 }
}
結び
まだ荒削りな部分があるとは思いますが、けっこう気持ち良く動くようになっていると思います。
この記事とプラグイン同梱の日本語ヘルプは全てtuskkを使って書きました。このくらいの文章を書けるポテンシャルはあります。
試していただけると嬉しいです。
Discussion