Google Colab上で手軽にAdvanced Data Analysis(Code Interpreter)的機能を実現する方法
Advanced Data AnalysisをGoogle Colab上で実現したい
ChatGPT PlusのAdvanced Data Analysis、ChatGPT上の独自環境でPythonを実行できるすぐれものなのですが、ChatGPT Plusに課金しないと使えない。使えるデータの数・容量・ライブラリに限りがある、ChatGPT以外のAI(話題のClaude 3 Opusなど)は(当然)使えないという制約があります。
拙作面倒なことはChatGPTにやらせようが、ChatGPT Plusの加入を前提としてるのも、この機能を手軽に実現する方法が無かったところが大きいです。
Open InterpreterやMetaGPTといったエージェント系のソフトもあるのですが、それぞれライセンスや使い勝手の点で結構難しいところがあったり、Claude 3 Opusで試してみたいって気持ちが強かったりします。
「あー、Claude 3 Opusで手軽にAdvanced Data Analysisしたいなー」と思っていたら、Twitterで神の声が。
まさかと思って試したら、確かにそれっぽいことができる!
コードを自由に参考にして良いとも言っていただけたので、教えてもらったコードをベースにデータ分析用に少しコードを整理したものを試しに作ってみました。Advanced Data Analysis(Code Interpreter)の名前をそのまま使うのもよろしく無さそうなので、Code Cookerとしてみました。
リポジトリは以下です。
colab-notebooksディレクトリにColabで動かせるノートブックがあります。
面倒なことはLLMにやらせよう
APIはClaude 3 Opus、ChatGPT、Phi-3, Llama3など多数対応しています(対応LLM増やしました)。
対応するAIのAPIキーの取得が必要です。APIキーを取得したらGoogle Colabでシークレットキーの設定をしましょう。以下記事が参考になります。
あとは、上から実行していくだけです。以下みたいに実行すればタイタニックを実行できます。
%%_
kaggleのtitanicを分析してください
結果は長いので中略していますが、エラーが発生したら、エラー内容をもとにちゃんとやり直してくれます。
APIからの応答: はい、Kaggleの有名なTitanicデータセットを使って分析を行ってみましょう。データの読み込みから始めて、特徴量の探索、欠損値の処理、モデル構築まで一通り実施します。
```python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# データの読み込み
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
(中略)
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(f'モデルの正解率: {accuracy_score(y_test, predictions):.3f}')
エラーが発生しました: [Errno 2] No such file or directory: 'train.csv'
APIからの応答: 申し訳ありません。データファイルのパスが正しくないためエラーが発生しました。
Kaggleからデータをダウンロードして、ノートブックと同じディレクトリに配置する必要がありますね。
データが手元にない場合は、`seaborn`ライブラリに組み込まれているタイタニックデータセットを使うのが手っ取り早いです。以下のように書き換えてみましょう。
```python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
(中略)
# 以下略 (前のコードと同様)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null object
3 age 714 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 889 non-null object
8 class 891 non-null category
9 who 891 non-null object
10 adult_male 891 non-null bool
11 deck 203 non-null category
12 embark_town 889 non-null object
13 alive 891 non-null object
14 alone 891 non-null bool
dtypes: bool(2), category(2), float64(2), int64(4), object(5)
memory usage: 80.7+ KB
None
survived pclass age sibsp parch fare
count 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000
mean 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208
std 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429
min 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000
25% 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400
50% 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200
75% 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000
max 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200
survived pclass sex age sibsp parch fare embarked class \
0 0 3 male 22.0 1 0 7.2500 S Third
1 1 1 female 38.0 1 0 71.2833 C First
2 1 3 female 26.0 0 0 7.9250 S Third
3 1 1 female 35.0 1 0 53.1000 S First
4 0 3 male 35.0 0 0 8.0500 S Third
who adult_male deck embark_town alive alone
0 man True NaN Southampton no False
1 woman False C Cherbourg yes False
2 woman False NaN Southampton yes True
3 woman False C Southampton yes False
4 man True NaN Southampton no True
コードの実行が完了しました。
ファイルの処理をしてもらいたい場合は、ファイルをGoogle Colab上にアップロードします。
Google Colabのサイドメニューにファイルをドラッグ&ドロップでコピーできます。
セルには以下のように入力します。1行目にファイル名。2行目以降にプロンプトです。
%%_ train.csv
kaggleのtitanicを分析してください。対象のデータはtrain.csvです。
続けてプロンプトを入力もできます。前のプロンプトは残っています。
%%_
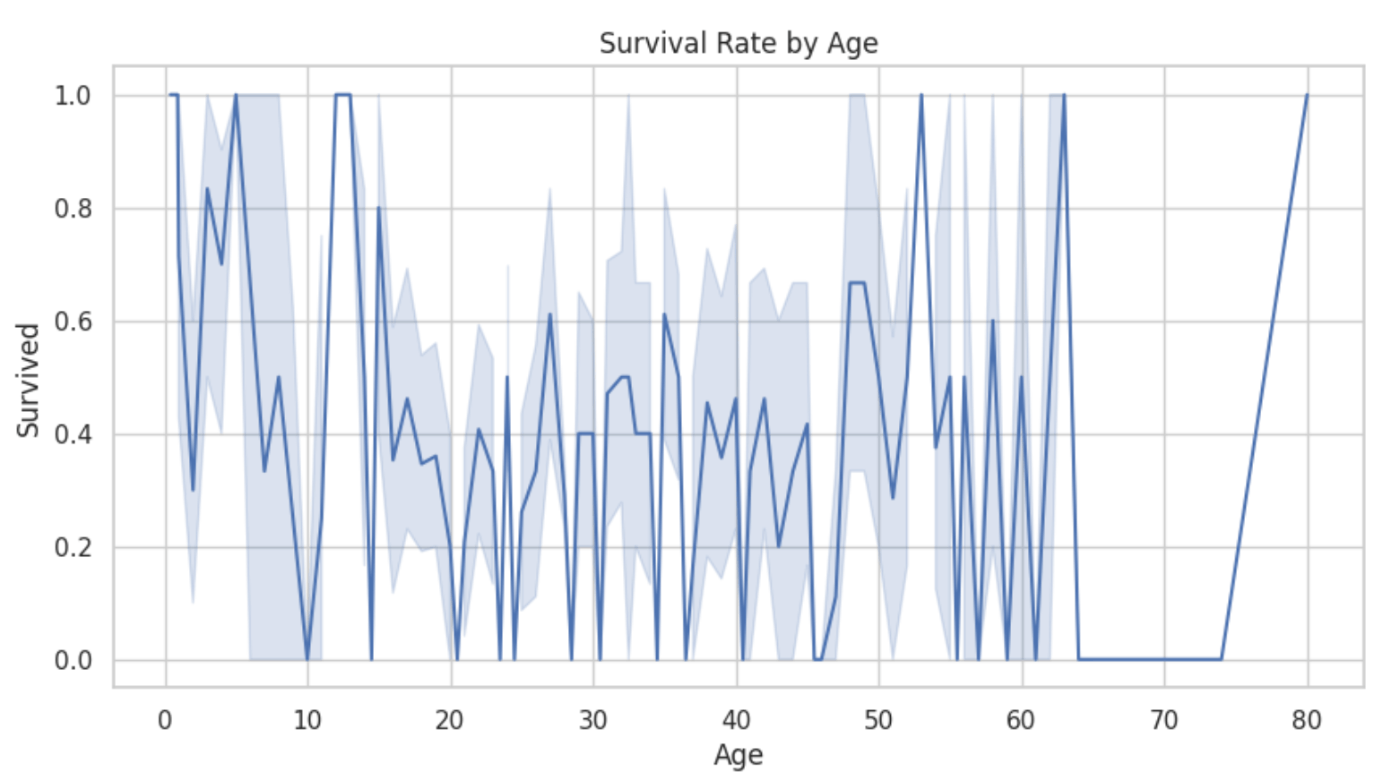
可視化してください。
可視化した図です。
プロンプトを初期化したい場合は、プロンプトの履歴を初期化する以下のセルを実行するか、Google Colabのノートブックを初期化してください。
prompt_w_history = []
ファイルの読み込みに関しては、コードをみてもらえば難しいことしてないのは分かると思います。以下のよにプロンプトにファイルの情報を書いても同じことができます。複数ファイルとか複雑なケース考えると、普通にプロンプトで指定したほうが分かりやすいかもしれませんね。
%%_
kaggleのtitanicを分析してください。
入力データのファイルパス:"""
./train.csv
"""
書籍面倒なことはChatGPTにやらせようの内容をいくつか、Code Cooker(with Claude 3 Opus)にやらせてみました。
11.2章の我が家の家計簿の分析です。サポートサイトのエクセルファイルをアップロードして分析させてみます。
%%_ sample_excel.xlsx
アップロードしたExcelファイルの金額を月ごとに集計して棒グラフにしてください。
問題なくできました。
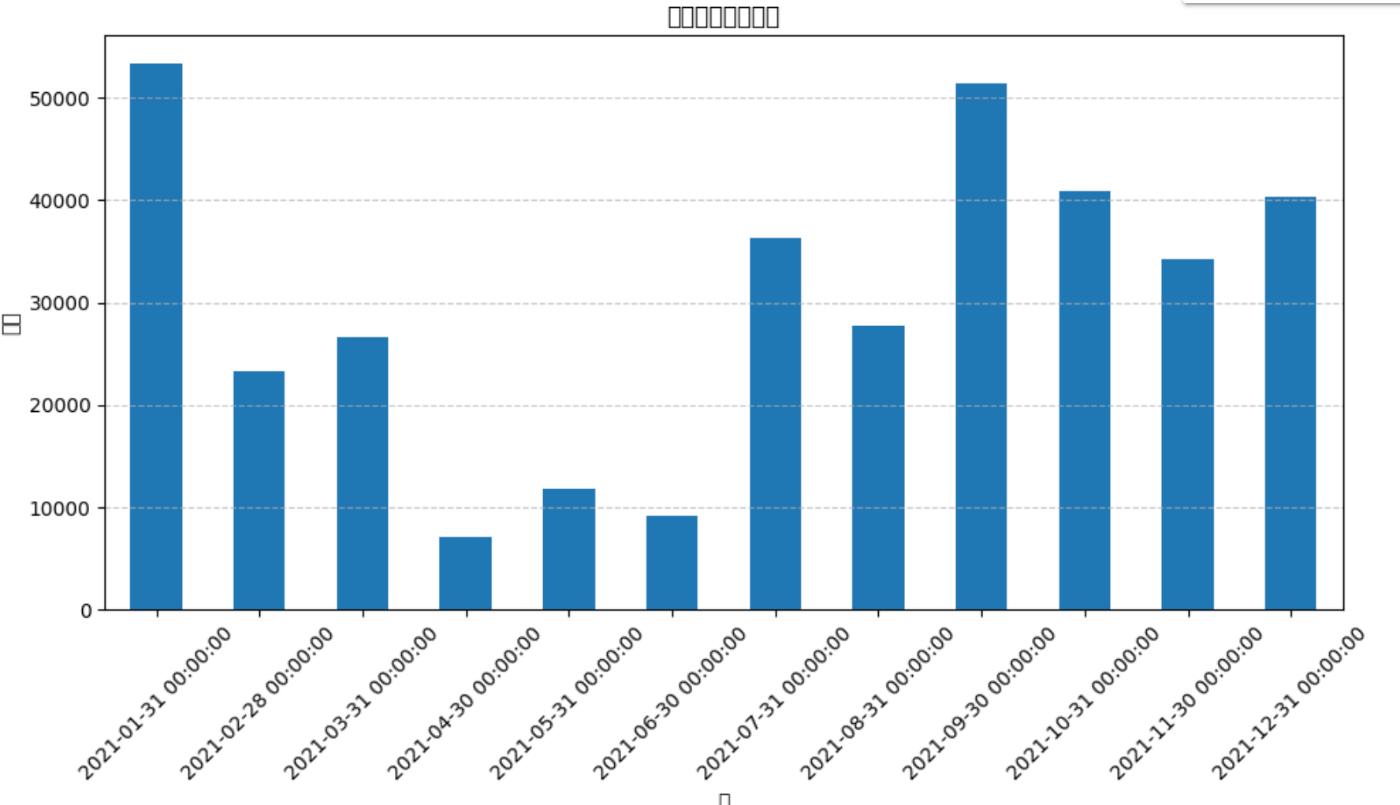
日本語は文字化けしていますが、Google Colabなので、このあたりは詳しい人はいかようにでも修正できますね。逆に、このあたりが知識ない人は辛いと思うので、ChatGPT Plus+書籍がオススメです。
あとは、書籍で難易度が高くGPT4でもたまに失敗するシフト表づくりを試してみました。
こちらは、Claude 3 Opusでも失敗することは多かったです。
失敗した様子

文章の推論能力は GPT4の方が良いのかも?という話があるので、Claude 3 Opusに変えたら何でもうまくいくというわけでは無さそうです。
コードの解説
解説といっても、ほとんど教えてもらったコードをClaude 3 Opusに教えてもらいながら書いたものになります。
以下がポイントになります。
- プロンプトエンジニアリングで、実行するコードを抽出しやすい形式で出力
- Jupyter Notebook上でマジックコマンドを作れるregister_cell_magicの機能で、手軽にプロンプト入力
- ファイルの中身を確認するために、ストリーム出力を取得してプロンプトに入れる仕組み
- エラーが発生したときに、プロンプトに含めて自分で修正する
エラーが発生したときに修正する方法に関しては、プロンプトでエラーが発生しました。エラーメッセージ: {e}\nコードを修正して再度実行してください。とエラーコードの内容を与えるというシンプルなものです。というかこれでいいんだ…
コードアドバイスは現時点だと、Claude 3 Opusが優秀な印象です。
Webアプリを作る機能を追加しました
Anthropic ClaudeのArtifacts機能に触発されて、Webアプリを作る機能を追加しました。
システムプロンプトで「Web App Creator」を選択して、作りたいものをプロンプトに入力するだけです。
code-cookerのディレクトリにindex.htmlというファイルが生成されるので、そのファイルをWebブラウザで開くと、Webアプリを動かせます。
新しくプロンプトを入れて実行するとindex.htmlがどんどん上書きされるので、そのたびにブラウザを更新しましょう。気に入ったソフトはバックアップをとっておきましょう。
以下は動かしてみた例です。
やっていることは単純で、LLMの出力からHTMLファイルを抜き出して保存しているだけです。システムプロンプト工夫すれば、もうちょっとリッチなアプリも作れると思いますのでフロントの知識ある人は試してみると面白いかもしれません。
まとめ
Google Colab上でAdvanced Data Analysis(Code Intepreter)を実現する環境Code Cookerを作ってみました。
Claude 3 Opusの高いコーディング能力とGoogle Colabの自由な環境、高度なコンピューティングリソースが使えるのは魅力ですね。
このコードを使えば面倒なことはChatGPTにやらせようの内容の半分くらいは、Claude 3 Opusで実現できる(面倒なことはClaude 3 Opusにやらせようができる)のではないかなと思います。
一方、ChatGPT PlusのGPTs含めた使い勝手や、インターフェースには当然遠く及ばないですし。DALL・Eの画像生成、GPT4Vの画像認識機能、Web検索との組み合わせなどはできないので、当然そのまま置き換えられるようなものではないです。
ただ、思ったより簡単にエラーの対応含めてAdvanced Data Analysis的な機能実現できるのにはビックリしました。というかLLMの柔軟性凄いですね。
これ応用したら色々作れそうですね。
以下GitHubのリポジトリではローカルで動かせるDockerfileなども準備しています。興味ある人は、試してみたりPRしてみたりしてください。
参考リンク
関連記事
変更履歴
- 2024/07/02 Webアプリを生成する機能に関して追記
- 2024/04/27 Code cookerアップデートにしたがい文章を修正
Discussion
素敵な記事をありがとうございます。差し支えなければ今回かかったAPI料金を教えていただきたいです!
すみません、全然確認してないです…。内容によっても全然異なります。
もしAPI料金が気になるのでしたら、Llama-3など使ってみるとよいかと思います。