[Part2] TypeScript, PostgreSQL, Next.js, Prisma & GraphQLでApp作成
Part1はこちら

はじめに
このコースでは、ユーザーがキュレーションされたリンクのリストをブラウズして、お気に入りのリンクをブックマークできるフルスタックアプリ「awesome-links」の構築方法を学びます。
前回は、Prismaを使用してデータベース層をセットアップしました。このパートの最後では、GraphQLについて学びます。GraphQLとは何か、そしてNext.jsアプリでAPIを構築するためにどのように使用できるのかについて説明します。
開発環境
このチュートリアルに沿って進めるには、Node.js と GraphQL 拡張がインストールされている必要があります。また、PostgreSQLのインスタンスが動作している必要があります。
リポジトリのクローン
このコースの全ソースコードは、GitHubでご覧いただけます。
まず、任意のディレクトリに移動し、以下のコマンドを実行してリポジトリをクローンしてください。
git clone -b part-2 https://github.com/m-abdelwahab/awesome-links.git
クローンしたディレクトリに移動して、依存関係をインストールし、開発サーバーを起動することができます。
cd awesome-links
npm install
npm run dev
アプリは http://localhost:3000/ で実行され、4つの項目が表示されます。データはハードコードされており、/data/links.ts ファイルから取得されます。
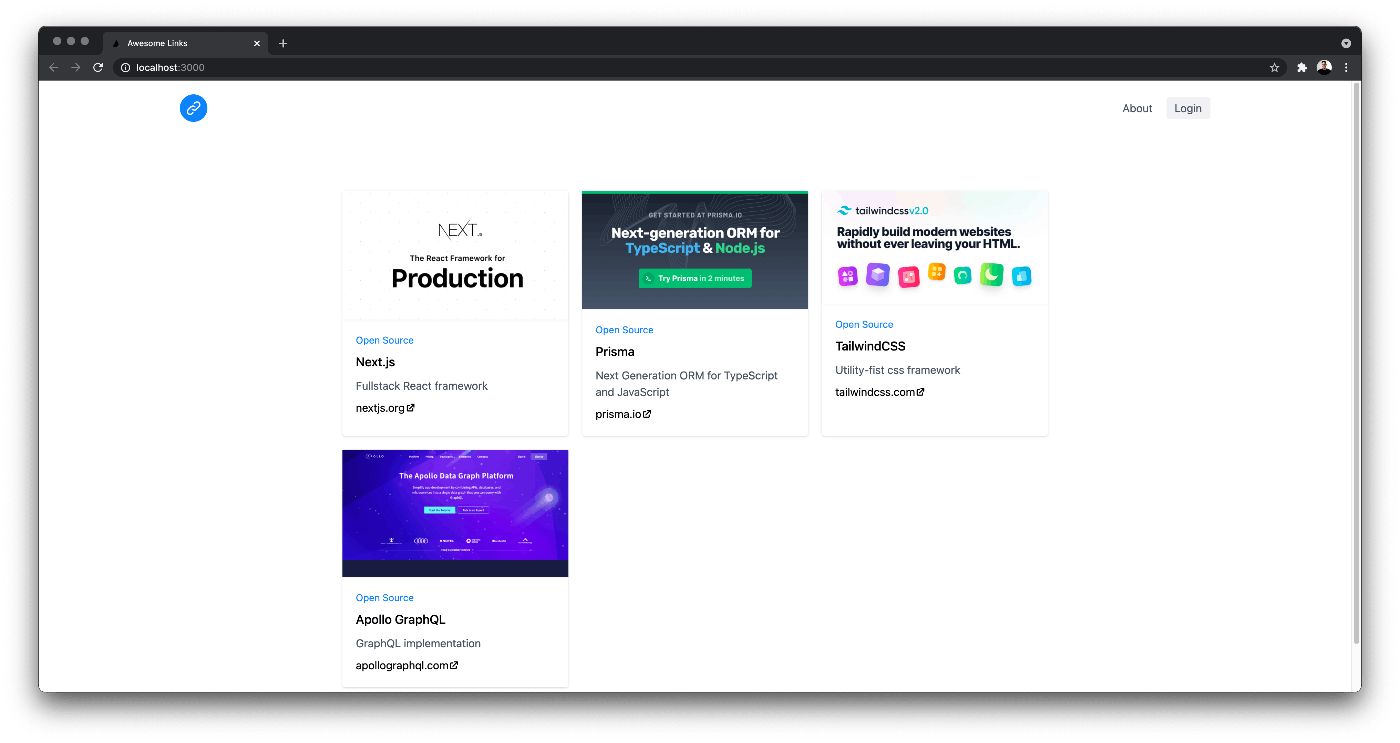
データベースのシード
PostgreSQLのデータベースを設定した後、env.exampleファイルを.envにリネームして、データベースの接続文字列を設定します。その後、以下のコマンドを実行し、データベースにテーブルを作成します。
npx prisma db push
次に、以下のコマンドを実行して、データベースのシードを作成します。
npx prisma db seed
このコマンドは、/prismaディレクトリにあるseed.tsスクリプトを実行します。このスクリプトは、Prisma Clientを使用して、4つのリンクと1人のユーザーをデータベースに追加します。
プロジェクトの構成と依存関係を見る
以下のようなフォルダ構成になります。
awesome-links/
┣ components/
┃ ┣ Layout/
┃ ┗ AwesomeLink.tsx
┣ data/
┃ ┗ links.ts
┣ pages/
┃ ┣ _app.tsx
┃ ┣ about.tsx
┃ ┗ index.tsx
┣ prisma/
┃ ┣ schema.prisma
┃ ┗ seed.ts
┣ public/
┣ styles/
┃ ┗ tailwind.css
┣ .env.example
┣ .gitignore
┣ README.md
┣ next-env.d.ts
┣ package-lock.json
┣ package.json
┣ postcss.config.js
┣ tailwind.config.js
┗ tsconfig.json
PrismaとともにTailwindCSSをセットアップしたNext.jsアプリケーションです。
pagesディレクトリの中に、3つのファイルがあります。
- _app.tsx: グローバルなAppコンポーネントで、ページ変更時に持続するナビゲーションバーの追加と、グローバルなCSSの追加に使用されます。
- about.tsx: このファイルは、http://localhost:3000/about に位置するページをレンダリングする React コンポーネントをエクスポートします。
- index.tsx: リンクのリストを含むトップページです。これらのリンクは、/data/links.ts ファイルにハードコードされています。
次に、prismaディレクトリがあり、次のファイルが含まれています。
- schema.prisma: PSL (Prisma Schema Language)で書かれたデータベースのスキーマ。このアプリのデータベースがどのようにモデル化されたかを知りたい場合は、コースの最後の部分をチェックしてください。
- seed.ts: データベースにダミーデータをシードするスクリプトです。
伝統的な方法でAPIを構築する。REST
コースの最後の部分では、Prismaを使用してデータベース層をセットアップしました。次のステップは、データモデルの上にAPI層を構築することで、クライアントからデータを要求したり送信したりできるようにします。
APIを構成する一般的なアプローチは、クライアントが異なるURLのエンドポイントにリクエストを送信することである。サーバーはリクエストの種類に応じてリソースを取得または変更し、レスポンスを送り返す。このアーキテクチャスタイルはRESTとして知られており、いくつかの利点がある。
- 柔軟性:エンドポイントでは、さまざまなタイプのリクエストを処理できる
- キャッシュ可能:特定のエンドポイントからのレスポンスをキャッシュするだけでよい。
- クライアントとサーバーの分離:異なるプラットフォーム(例えば、ウェブアプリ、モバイルアプリなど)がAPIを利用できる。
REST APIとその欠点
REST APIには利点がある反面、欠点もあります。ここでは、awesome-linksを例として説明します。
awesome-linksのREST APIを構成する一つの可能性を示します。
| RESOURCE | HTTP METHOD | ROUTE | DESCRIPTION |
|---|---|---|---|
| User | GET | /users | すべてのユーザーの情報を返す |
| User | GET | /users/:id | 1人のユーザーの情報を返す |
| Link | GET | /links | すべてのユーザーの情報を返す |
| Link | GET, PUT, DELETE | /links/:id | idで指定された1つのリンクの情報を返す、更新する、削除する |
| User | GET | /favorites | そのユーザーのお気に入りのリンクの一覧を返す |
| User | POST | /link/save | あるリンクをそのユーザーのお気に入りに追加する |
| Link | POST | /link/new | (アドミンによって)リンクを新たに作成する |
REST APIはそれぞれ異なる
REST APIは人によって異なる方法で構築しています。
この柔軟性には代償があり、すべてのAPIは異なるという状態を生み出してしまいます。
つまり、REST APIを扱うたびに、そのドキュメントに目を通し、以下のことを学ぶ必要があるのです。
- 異なるエンドポイントとそのHTTPメソッド。
- 各エンドポイントに対するリクエストパラメータ
- 各エンドポイントからどのようなデータとステータスコードが返されるか。
この柔軟性が高いがゆえに、初めてAPIを使う時に、開発者の生産性を低下させます。
そして、アプリが複雑化すると、APIも複雑化します。要件が増えれば、作成されるエンドポイントも増えます。
このエンドポイントの増加は、ほとんどの場合、2つの問題、すなわちデータのオーバーフェッチとアンダーフェッチを引き起こします。
オーバーフェッチとアンダーフェッチ
オーバーフェッチは、必要以上のデータをフェッチするときに発生します。これは、より多くの帯域幅を消費するため、パフォーマンスの低下を招きます。
一方、あるエンドポイントがUIに表示するために必要なデータをすべて返さないことがあり、その場合、別のエンドポイントに1回以上リクエストすることになります。この場合、ネットワークリクエストの滝が発生するため、パフォーマンスの低下にもつながります。
「awesome-links」アプリで、すべてのユーザーとそのリンクを表示するページを作りたい場合、/users/エンドポイントにAPIコールを行い、さらに/favoritesにリクエストを行い、お気に入りを取得する必要があります。
usersエンドポイントにユーザーとそのお気に入りを返させても、問題は解決しません。なぜなら、読み込みに長い時間がかかる重要なAPIレスポンスになってしまうからです。
REST APIは型付きでない
REST APIのもうひとつの欠点は、型付けされていないことです。エンドポイントから返されるデータのタイプも、送信するデータのタイプもわかりません。これは、APIについて仮定することにつながり、バグや予測不可能な動作につながる可能性があります。
例えば、リクエストを行う際にユーザーIDは文字列で渡すのか、それとも数字で渡すのか。どのリクエストパラメーターがオプションで、どのパラメーターが必須なのか?そのためにドキュメントを利用することになるのですが、しかし、APIが進化するにつれて、ドキュメントは古くなってしまうことがあります。これらの課題を解決するソリューションもありますが、本講座では取り上げません。
RESTの代替となるGraphQL
GraphQLは、Facebookが開発しオープンソース化した新しいAPI規格です。RESTに代わる、より効率的で柔軟なAPIを提供し、クライアントは必要なデータを正確に受け取ることができます。
1つまたは複数のエンドポイントにリクエストを送信してレスポンスをつなぎ合わせるのではなく、単一のエンドポイントにのみリクエストを送信します。
以下は、「awesome-links」アプリ内のすべてのリンクを返すGraphQLクエリの一例です。このクエリは、後でAPIを構築する際に定義することになります。
query {
links {
id
title
}
}

リンクにはもっと多くのフィールドがあるにもかかわらず、APIはidとtitleしか返しません。
これで、GraphQL APIの構築をどのように始められるか、おわかりいただけたと思います。
スキーマの定義
APIが実行できるすべての操作を定義する、GraphQLスキーマからすべてが始まります。また、操作の入力引数やレスポンスタイプも指定します。
このスキーマはクライアントとサーバーの間の契約として機能します。また、GraphQL APIを消費する開発者のためのドキュメントとしても機能します。スキーマの定義は、GraphQLのSDL(Schema Definition Langauge)を使って行います。
「awesome-links」アプリのGraphQLスキーマをどのように定義するか見てみましょう。
オブジェクトの型とフィールドの定義
最初に行う必要があるのは、Objectタイプの定義です。Objectタイプは、APIから取得できるオブジェクトの種類を表します。
各オブジェクトタイプは、1つまたは複数のフィールドを持つことができます。アプリにユーザーを登場させたいので、Userオブジェクトタイプを定義する必要があります。
type User {
id: String
name: String
email: String
image: String
role: Role
bookmarks: [Link]
}
enum Role {
ADMIN
USER
}
User 型は、以下のフィールドを持ちます。
- email: String型
- id:String型
- name :String型
- image:String型
- role:Role型のenumであり、ユーザーのロールはUSERまたはADMINの2つの値のいずれかを取ることができます
- bookmarks:Link型の配列。こユーザーが多くのリンクを持つことができることを意味します。次に、Linkオブジェクトを定義します。
これは、Linkオブジェクトの型の定義です。
type Link {
id: String
category: String
description: String
imageUrl: String
title: String
url: String
users: [User]
}
リンクとユーザーオブジェクトタイプは多対多の関係です。これは、Prismaを使用してデータベースでモデル化されています。
クエリーの定義
GrahQL APIからデータを取得するためには、Query Object型を定義する必要があります。これは、すべてのGraphQLクエリのエントリポイントを定義する型です。各エントリポイントでは、その引数と戻り値の型を定義します。
以下は、すべてのリンクを返すクエリです。
type Query {
links: [Link]!
}
リンククエリは、Link 型の配列を返します。!は、このフィールドが non-nullable であることを示すために使用されます。つまり、このフィールドがクエリされたときに API は常に値を返すということです。
構築したいAPIの種類に応じて、さらにクエリーを追加することができる。「awesome-links」アプリの場合、単一のリンクを返すクエリ、単一のユーザーを返すクエリ、そしてすべてのユーザーを返すクエリを追加できる。
type Query {
links: [Link]!
link(id: String!): Link!
user(id: String!): User!
users: [User]!
}
- linkクエリは、String 型の id を引数として取り、Link を返します。id は必須であり、null は不可です。
- userクエリは String 型の id を引数にとり、User を返します。id は必須であり、Null 値でないものを返します。
- usersクエリは,User 型の配列を返す。id は必須です。レスポンスは Null 値ではありません。
ミューテーションの定義
データの作成、更新、削除を行うには、Mutation Object タイプを定義する必要があります。書き込みを行う操作はすべてミューテーションを経由して明示的に送信することが慣例となっています。同様に、データを変更するためにGETリクエストを使用するべきではありません。
「awesome-links」アプリでは、リンクの作成、更新、削除のために異なるミューテーションが必要になります。
type Mutation {
createLink(category: String!, description: String!, imageUrl: String!, title: String!, url: String!): Link!
deleteLink(id: String!): Link!
updateLink(category: String, description: String, id: String, imageUrl: String, title: String, url: String): Link!
}
- createLinkミューテーションは、カテゴリ、説明、タイトル、url、imageUrlを引数として取ります。これらのフィールドはすべて String 型であり、必須です。このミューテーションはLinkオブジェクト型を返します。
- deleteLinkミューテーションは、String 型の ID を必須の引数としてとります。これは、必須のLinkを返します。
- updateLinkミューテーションは、createLinkミューテーションと同じ引数を取ります。ただし、引数はオプションです。この方法では、リンクを更新するときに、更新したいフィールドのみを渡します。このミューテーションは必須リンクを返します。
クエリやミューテーションの実装を定義
ここまでは、GraphQL APIのスキーマを定義しただけで、クエリーやミューテーションが実行されたときにどうなるかは指定していません。クエリーやミューテーションの実装の実行を担う関数をリゾルバと呼びます。リゾルバの内部では、データベースへのクエリやサードパーティAPIへのリクエストを送信することができます。
このチュートリアルでは、PostgreSQLデータベースにクエリを送信するために、リゾルバの内部でPrismaを使用することにします。
GraphQL APIの構築
GraphQL APIを構築するには、単一のエンドポイントにサービスを提供するGraphQLサーバーが必要です。
このサーバーには、リゾルバと一緒にGraphQLスキーマが含まれます。このプロジェクトでは、Apollo Serverを使用します。
はじめに、冒頭でクローンしたスターターレポで、ターミナルから以下のコマンドを実行します。
npm install graphql apollo-server-micro micro-cors
Graphqlパッケージは、GraphQLのJavaScriptリファレンス実装です。Apollo Server用のMicro統合であるapollo-server-microの相互依存関係です。このインテグレーションは、Next.jsに最適化されています。最後に、Apollo Studioを使えるようにするために、micro-corsを使用しています。
アプリのスキーマを定義する
次に、GraphQLスキーマを定義する必要があります。プロジェクトのルートフォルダに新しいgraphqlディレクトリを作成し、その中に新しいschema.tsファイルを作成します。すべてのリンクを返すクエリとともに、リンクオブジェクトを定義します。
// graphql/schema.ts
import { gql } from 'apollo-server-micro'
export const typeDefs = gql`
type Link {
id: String
title: String
description: String
url: String
category: String
imageUrl: String
users: [String]
}
type Query {
links: [Link]!
}
`
gqlタグは、スキーマ定義などのGraphQL文字列をラッピングするためのテンプレートリテラルのタグです。シンタックスハイライトを有効にし、Apolloライブラリが操作やスキーマを扱う際に期待する形式にGraphQL文字列を変換します。
リゾルバの定義
次に必要なことは、リンククエリ用のリゾルバ関数を作成することです。そのために、/graphql/resolvers.tsファイルを作成し、以下のコードを追加します。
export const resolvers = {
Query: {
links: () => {
return [
{
category: 'Open Source',
description: 'Fullstack React framework',
id: '8a9020b2-363b-4a4f-ad26-d6d55b51bqes',
imageUrl: 'https://nextjs.org/static/twitter-cards/home.jpg',
title: 'Next.js',
url: 'https://nextjs.org',
},
{
category: 'Open Source',
description: 'Next Generation ORM for TypeScript and JavaScript',
id: '2a3121b2-363b-4a4f-ad26-d6c35b41bade',
imageUrl: 'https://www.prisma.io/images/og-image.png',
title: 'Prisma',
url: 'https://prisma.io',
},
{
category: 'Open Source',
description: 'GraphQL implementation',
id: '2ea8cfb0-44a3-4c07-bdc2-31ffa135ea78',
imageUrl: 'https://www.apollographql.com/apollo-home.jpg',
title: 'Apollo GraphQL',
url: 'https://apollographql.com',
},
]
},
},
}
resolvers は、各クエリやミューテーションの実装を定義するためのオブジェクトです。クエリオブジェクトの中の関数は、スキーマで定義されたクエリの名前と一致しなければなりません。同じことがミューテーションについても言えます。ここでは、リンクリゾルバ関数はオブジェクトの配列を返し、各オブジェクトの型はリンクです。
GraphQLエンドポイントの作成
GraphQLエンドポイントを作成するために、Next.jsのAPIルートを活用します。pages/apiフォルダ内のファイルは、/api/*エンドポイントにマッピングされ、APIエンドポイントとして扱われます。
先に/pages/api/graphql.tsファイルを作成し、以下のコードを追加します。
import { ApolloServer } from 'apollo-server-micro'
import { typeDefs } from '../../graphql/schema'
import { resolvers } from '../../graphql/resolvers'
import Cors from 'micro-cors'
const cors = Cors()
const apolloServer = new ApolloServer({ typeDefs, resolvers })
const startServer = apolloServer.start()
export default cors(async function handler(req, res) {
if (req.method === 'OPTIONS') {
res.end()
return false
}
await startServer
await apolloServer.createHandler({
path: '/api/graphql',
})(req, res)
})
export const config = {
api: {
bodyParser: false,
},
}
先ほど作成したスキーマとリゾルバをパラメータとして、新しいapolloServerインスタンスを作成しました。そして、startServerという関数を作成し、apolloServer.start();を呼び出します。これはApolloServer 3での要求事項です。
次に、handlerと呼ばれる非同期関数を定義し、リクエストとレスポンスオブジェクトを受け取ります。この関数の本体内部では、まずstartServer関数を呼び出し、次にcreateHandler関数を呼び出して、パスを/api/graphqlに設定しています。これはGraphQL APIのエンドポイントです。
最後に、すべてのAPIルートは、デフォルトの設定を変更するためにconfigオブジェクトをエクスポートすることができます。Bodyの解析はGraphQLで処理されるため、ここでは無効にしています。
GraphQLプレイグラウンドを用いたクエリの送信
これまでの手順が完了したら、以下のコマンドを実行して、サーバーを起動します。
npm run dev
http://localhost:3000/api/graphql/ に移動すると、以下のページが表示されるはずです。
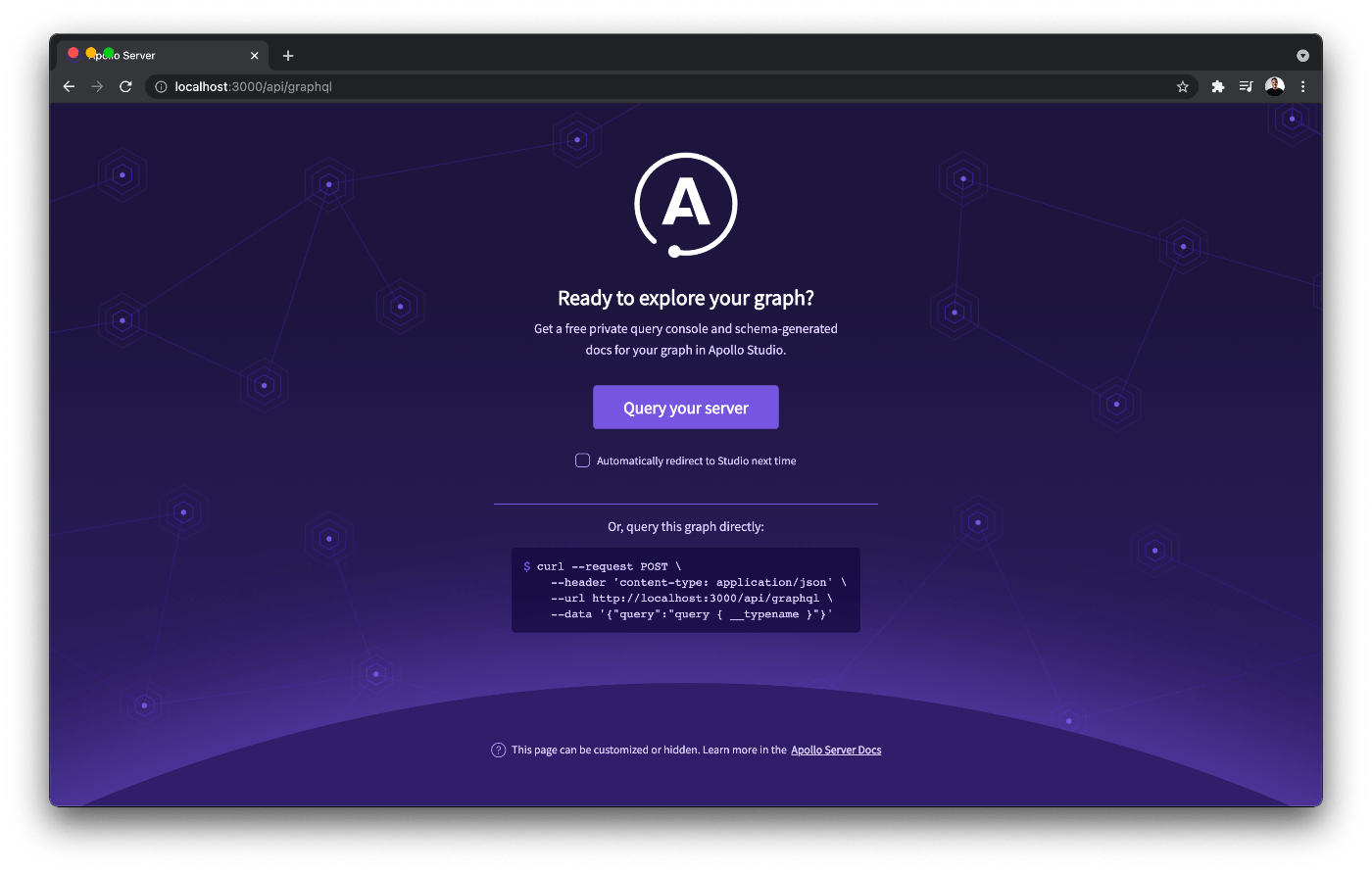
Query your server "をクリックすると、Apollo Studio Explorerにリダイレクトされます。
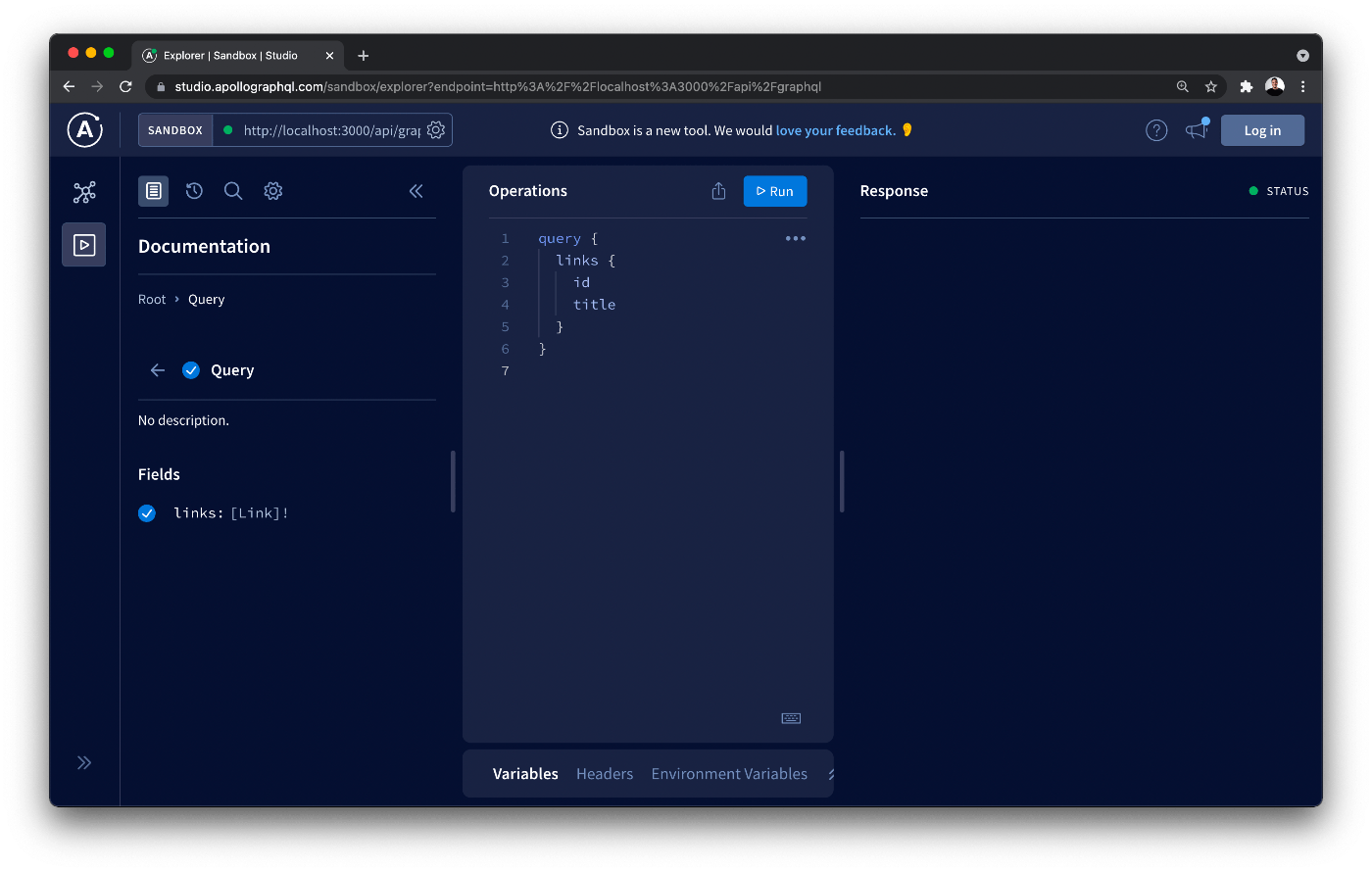
GraphQL Playgroundは、エンドポイントを指定することでGraphQL APIを探索することができます。ローカルで作業しているため、エンドポイントはhttp://localhost:3000/api/graphql/。
左側にあるスキーマタブ(apolloロゴの下にある最初のアイコン)では、GraphQLスキーマ全体を見ることができます。また、各クエリ/ミューテーションを個別に探索し、必要な引数とその型を確認することができます。
すべてが期待通りに実行されることを確認するために、リンククエリを書き、返したい異なるフィールドを指定して、「クエリ」ボタンをクリックします。右側のレスポンス・セクションに、先ほどリンク・リゾルバに書いたハードコードされたデータが表示されるはずです。
Prismaクライアントの初期化
これまで、GraphQL APIはリゾルバ関数でハードコードされたデータを返していました。これらの関数でPrisma Clientを使用して、データベースにクエリを送信することになります。
Prisma Clientは自動生成されるタイプセーフのクエリビルダーです。プロジェクトで使用できるようにするには、一度インスタンス化して、プロジェクト全体で再利用する必要があります。プロジェクトのルート・フォルダに /lib フォルダを作成し、その中に prisma.ts ファイルを作成します。次に、そこに次のコードを追加してください。
// /lib/prisma.ts
import { PrismaClient } from '@prisma/client'
// PrismaClient is attached to the `global` object in development to prevent
// exhausting your database connection limit.
// Learn more: https://pris.ly/d/help/next-js-best-practices
let prisma: PrismaClient
if (process.env.NODE_ENV === 'production') {
prisma = new PrismaClient()
} else {
if (!global.prisma) {
global.prisma = new PrismaClient()
}
prisma = global.prisma
}
export default prisma
まず、新しいPrisma Clientインスタンスを作成します。次に、本番環境でない場合は、データベース接続の制限を使い切らないように、Prismaはグローバルオブジェクトにアタッチされます。詳しくは、Next.jsのドキュメントとPrisma CLientのベストプラクティスをご覧ください。
GraphQLコンテキストの作成
次のステップでは、リゾルバがPrisma Clientにアクセスし、データベースにクエリを送信できるようにするために、コンテキストを作成します。
先に進み、/graphqlフォルダ内にcontext.tsファイルを作成し、以下のコードをそこに追加します。
// /graphql/context.ts
import { PrismaClient } from '@prisma/client'
import prisma from '../lib/prisma'
export type Context = {
prisma: PrismaClient
}
export async function createContext({ req, res }): Promise<Context> {
return {
prisma,
}
}
Context型を作成し、PrismaClient型をそれにアタッチしています。次に、createContext()という非同期関数をエクスポートして、libディレクトリに作成されたprismaインスタンスを返します。
次に、コンテキストを含めるために/pages/api/graphql.tsファイルを更新します。
// /pages/api/graphql.ts
import { ApolloServer } from 'apollo-server-micro';
import { typeDefs } from '../../graphql/schema';
import { resolvers } from '../../graphql/resolvers';
+ import { createContext } from '../../graphql/context';
const apolloServer = new ApolloServer({
typeDefs,
resolvers,
+ context: createContext,
});
const startServer = apolloServer.start();
export default cors(async function handler(req, res) {
if (req.method === 'OPTIONS') {
res.end();
return false;
}
await startServer;
await apolloServer.createHandler({
path: '/api/graphql',
})(req, res);
});
export const config = {
api: {
bodyParser: false,
},
};
これで、データベースからデータを返すようにリゾルバを更新することができます。/graphql/resolvers.tsファイルの中で、`links'関数を以下のコードに更新してください。
// /graphql/resolvers.ts
export const resolvers = {
Query: {
links: (_parent, _args, ctx) => {
return ctx.prisma.link.findMany()
},
},
}
リゾルバは現在、3つのオプションの引数を持つ。
- _parent: このフィールドの親に対するリゾルバの返り値。リゾルバでは使用されないので、アンダースコアをプレフィックスとする。
- _args: フィールドに提供されたすべてのGraphQL引数を含むオブジェクト。例えば、クエリ { link(id: "4") } を実行する場合、ユーザーリゾルバに渡されるargsオブジェクトは{ "id": "4" }. リゾルバでは使われないので、アンダースコアで接頭辞を付けていることになります。
- context引数は、認証スコープ、データベース接続、カスタムフェッチ関数など、どのリゾルバも必要とするようなものを渡すのに便利である。ここでは、Prisma Clientにアクセスするためにこの引数を使用しています。
すべてが正しく設定されていれば、http://localhost:3000/api/graphql、Apollo Studio Explorerでリンククエリを実行すると、返されるデータはデータベースから取得されたものになります。
現在の GraphQL セットアップの欠点
GraphQL APIが複雑化すると、スキーマとリゾルバを手動で作成する現在のワークフローでは、開発者の生産性が低下する可能性があります。
- リゾルバはスキーマと同じ構造に一致させる必要があり、その逆も同様です。リゾルバはスキーマと同じ構造でなければならず、その逆も同様です。そうでなければ、バグの多い、予測不可能な動作をすることになります。スキーマが進化したり、リゾルバの実装が変わったりすると、これら2つのコンポーネントが偶然に同期しなくなることがあります。
- GraphQL スキーマは文字列として定義されているため、SDL コードの自動補完やビルド時のエラーチェックは行われません。
これらの問題を解決するには、GraphQL code-generatorのようなツールを組み合わせて使用することができます。あるいは、スキーマをそのリゾルバで構築する際に、コードファーストのアプローチを使用することもできる。
Nexusを使ったコードファーストなGraphQL API
NexusはGraphQLスキーマ構築ライブラリで、コードを使用してGraphQLスキーマを定義することができます。このアプローチの価値提案は、プログラミング言語を使用してAPIを構築することであり、複数の利点がある。
-
SDLとビジネスロジックの構築に使用するプログラミング言語を切り替える必要がない。
-
テキストエディタからの自動補完
-
型安全性(TypeScriptを使用している場合)
-
これらの利点は、摩擦の少ない、より良い開発体験に貢献します。
まずは、以下のコマンドを実行して、Nexusをインストールしてください。
npm install nexus
次に、/graphql/schema.tsファイルのtypeDefsを以下のコードに置き換えることで、空のgraphqlスキーマが作成されます。
// /graphql/schema.ts
import { makeSchema } from 'nexus'
import { join } from 'path'
export const schema = makeSchema({
types: [],
outputs: {
typegen: join(process.cwd(), 'node_modules', '@types', 'nexus-typegen', 'index.d.ts'),
schema: join(process.cwd(), 'graphql', 'schema.graphql'),
},
contextType: {
export: 'Context',
module: join(process.cwd(), 'graphql', 'context.ts'),
},
})
Nexusからオブジェクトを引数として受け取るmakeSchema()関数をインポートしています。このオブジェクトの内部には、以下のフィールドが含まれています。
- types: すべての異なるオブジェクトタイプを含む配列。
- outputs: オブジェクト。生成された GraphQL API の型と SDL で記述されたスキーマの場所を指定します。ここでは、タイプは node_modules ディレクトリにあるファイルに、スキーマは /graphql ディレクトリに生成されます。
- contextType: コンテキストタイプを含めるためのオブジェクト。/graphql/context.tsファイルで定義されている、エクスポートされたContextタイプをインポートします。
最後に、/pages/api/graphql.tsファイル内のimportを更新します。
// /pages/api/graphql.ts
import { ApolloServer } from 'apollo-server-micro';
+ import { schema } from '../../graphql/schema';
import { resolvers } from '../../graphql/resolvers';
import { createContext } from '../../graphql/context';
const apolloServer = new ApolloServer({
+ schema,
resolvers,
context: createContext,
});
// code below unchanged
サーバーが起動していることを確認し、http://localhost:3000/api/graphql に移動します。okフィールドを持つクエリを送信すると、trueが返されます。
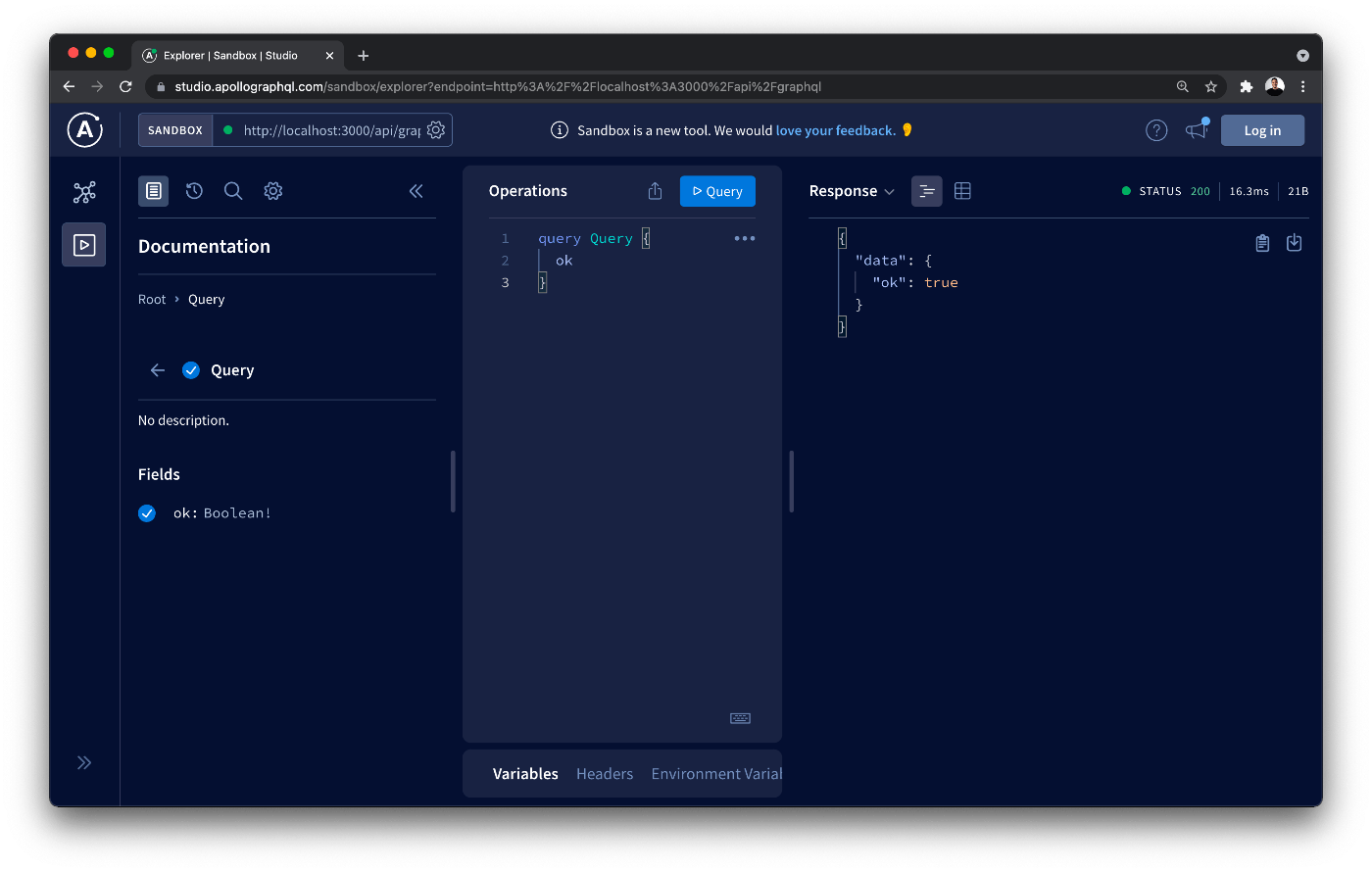
Nexusを使ったクエリの定義
最初のステップは、Nexusを使用してLinkオブジェクトタイプを定義することです。まず、/graphql/types/Link.ts ファイルを作成し、以下のコードを追加します。
// /graphql/types/Link.ts
import { objectType, extendType } from 'nexus'
import { User } from './User'
export const Link = objectType({
name: 'Link',
definition(t) {
t.string('id')
t.string('title')
t.string('url')
t.string('description')
t.string('imageUrl')
t.string('category')
t.list.field('users', {
type: User,
async resolve(_parent, _args, ctx) {
return await ctx.prisma.link
.findUnique({
where: {
id: _parent.id,
},
})
.users()
},
})
},
})
Linkのオブジェクトタイプは、NexusのobjectType()関数を使用して作成されます。この関数はオブジェクトを引数として取り、そこでオブジェクトタイプの名前と異なるフィールドを指定します。また、各フィールドのタイプも指定します。id、title、url、description、imageUrl、categoryはstring型です。フィールドについては、typeUser`の配列であることを指定しています。
では、新規に/graphql/types/User.tsファイルを作成し、Userタイプを作成するためのコードに以下を追加します。
// /graphql/types/User.ts
import { enumType, objectType } from 'nexus'
import { Link } from './Link'
export const User = objectType({
name: 'User',
definition(t) {
t.string('id')
t.string('name')
t.string('email')
t.string('image')
t.field('role', { type: Role })
t.list.field('bookmarks', {
type: Link,
async resolve(_parent, _args, ctx) {
return await ctx.prisma.user
.findUnique({
where: {
id: _parent.id,
},
})
.bookmarks()
},
})
},
})
const Role = enumType({
name: 'Role',
members: ['USER', 'ADMIN'],
})
型を追加する際にインポートをより管理しやすくするために、 graphql/types/index.ts ファイルを作成し、スキーマから全ての型を再エクスポートするためのインデックスとして使用します。このようにして、すべての型を一度にインポートすることができます。
// graphql/types/index.ts
export * from './Link'
export * from './User'
graphql/schema.tsでimportを更新し、先ほど作成した型を含めるようにします。
// graphql/schema.ts
import { makeSchema } from 'nexus'
import { join } from 'path'
+ import * as types from './types'
export const schema = makeSchema({
+ types,
outputs: {
typegen: join(process.cwd(), 'node_modules', '@types', 'nexus-typegen', 'index.d.ts'),
schema: join(process.cwd(), 'graphql', 'schema.graphql'),
},
contextType: {
export: 'Context',
module: join(process.cwd(), 'graphql', 'context.ts'),
},
})
graphql/types/Link.ts ファイルで、Link オブジェクトのタイプ定義の下に、以下のコードを追加します。
// graphql/types/Link.ts
// code above unchanged
export const LinksQuery = extendType({
type: 'Query',
definition(t) {
t.nonNull.list.field('links', {
type: 'Link',
resolve(_parent, _args, ctx) {
return ctx.prisma.link.findMany()
},
})
},
})
Nexus の extendType() 関数を使って、クエリを作成しているところです。
- .nonNull は、クライアントが常にこのフィールドの値を取得することを指定します。Nexus では、すべての「出力タイプ」(フィールドが返すタイプ)は、デフォルトで NULL 可能です。
- .listは、このクエリがリストを返すことを指定します。
- field() は、2 つの引数を取る関数です。
- フィールドの名前。この場合、最初に作成したスキーマと同様、クエリの名前は "links" となります。
- リゾルバ関数と一緒に、クエリの返される型を指定するオブジェクト。リゾルバ関数では、コンテキストからプリズマにアクセスし、findMany()関数を使ってデータベースのLinkテーブルのすべてのリンクを返しています。
これで、Apollo Studio Explorerに戻ると、データベースからすべてのリンクを返すクエリを送信できるようになります。

クライアントサイドのGraphQLクエリ
このプロジェクトでは、Apollo Client を使用します。構築したばかりのGraphQL APIと対話するために、通常のHTTP POSTリクエストを送信することができます。しかし、代わりにGrapQL Clientを使用すると、多くの利点を得ることができます。
Apollo Clientは、データのリクエストやキャッシュ、UIの更新を行います。また、クエリのバッチ処理、クエリの重複排除、ページネーションなどの機能も備えています。
Next.jsでApolloクライアントをセットアップする
Apollo Clientを使い始めるには、以下のコマンドを実行してプロジェクトに追加します。
npm install @apollo/client
次に、/libディレクトリにapollo.tsというファイルを新規に作成し、以下のコードを追加してください。
// /lib/apollo.ts
import { ApolloClient, InMemoryCache } from '@apollo/client'
const apolloClient = new ApolloClient({
uri: 'http://localhost:3000/api/graphql',
cache: new InMemoryCache(),
})
export default apolloClient
新しいApolloClientのインスタンスを作成し、uriとcacheフィールドを持つ設定オブジェクトを渡します。
- uriフィールドは、対話するGraphQLエンドポイントを指定します。これは、アプリをデプロイする際に本番用URLに変更されます。
- cacheフィールドはInMemoryCacheのインスタンスで、Apollo Clientはクエリ結果を取得した後にキャッシュするためにこれを使用します。
次に、/pages/_app.tsxファイルに以下のコードを追加し、Apollo Clientをセットアップします。
// /pages/_app.tsx
import '../styles/tailwind.css'
import Layout from '../components/Layout'
import { ApolloProvider } from '@apollo/client'
import apolloClient from '../lib/apollo'
function MyApp({ Component, pageProps }) {
return (
<ApolloProvider client={apolloClient}>
<Layout>
<Component {...pageProps} />
</Layout>
</ApolloProvider>
)
}
export default MyApp
プロジェクトのすべてのコンポーネントがGraphQLクエリーを送信できるように、グローバルなAppコンポーネントをApollo Providerでラッピングしています。
useQueryを使ったリクエストの送信
Apolloクライアントを使用してフロントエンドにデータを読み込むには、/pages/index.tsxファイルを更新して以下のコードを使用します。
// /pages/index.tsx
import Head from 'next/head'
import { gql, useQuery } from '@apollo/client'
const AllLinksQuery = gql`
query {
links {
id
title
url
description
imageUrl
category
}
}
`
export default function Home() {
const { data, loading, error } = useQuery(AllLinksQuery)
if (loading) return <p>Loading...</p>
if (error) return <p>Oh no... {error.message}</p>
return (
<div>
<Head>
<title>Awesome Links</title>
<link rel="icon" href="/favicon.ico" />
</Head>
<div className="container mx-auto max-w-5xl my-20">
<ul className="grid grid-cols-1 md:grid-cols-2 lg:grid-cols-3 gap-5">
{data.links.map(link => (
<li key={link.id} className="shadow max-w-md rounded">
<img className="shadow-sm" src={link.imageUrl} />
<div className="p-5 flex flex-col space-y-2">
<p className="text-sm text-blue-500">{link.category}</p>
<p className="text-lg font-medium">{link.title}</p>
<p className="text-gray-600">{link.description}</p>
<a href={link.url} className="flex hover:text-blue-500">
{link.url.replace(/(^\w+:|^)\/\//, '')}
<svg
className="w-4 h-4 my-1"
fill="currentColor"
viewBox="0 0 20 20"
xmlns="http://www.w3.org/2000/svg"
>
<path d="M11 3a1 1 0 100 2h2.586l-6.293 6.293a1 1 0 101.414 1.414L15 6.414V9a1 1 0 102 0V4a1 1 0 00-1-1h-5z" />
<path d="M5 5a2 2 0 00-2 2v8a2 2 0 002 2h8a2 2 0 002-2v-3a1 1 0 10-2 0v3H5V7h3a1 1 0 000-2H5z" />
</svg>
</a>
</div>
</li>
))}
</ul>
</div>
</div>
)
}
useQueryフックを使って、GraphQLエンドポイントにクエリを送信していますね。このフックには、GraphQL クエリ文字列の必須パラメータがあります。コンポーネントがレンダリングされるとき、useQueryは3つの値を含むオブジェクトを返します。
-
loading: データが返されたかどうかを判断するブール値。
-
error: クエリ送信後にエラーが発生した場合のエラーメッセージを含むオブジェクト。
-
data: APIエンドポイントから返されたデータを含む。
-
ファイルを保存した後、http://loclahost:3000 に移動すると、データベースから取得されたリンクのリストが表示されます。
ページネーション
AllLinksQueryは、データベースに登録されているすべてのリンクを返します。アプリが大きくなってリンクを追加すると、APIレスポンスが大きくなり、ロードに時間がかかるようになります。また、prisma.link.findMany()関数を使用してデータベース内のリンクを返しているため、リゾルバが送信するデータベースクエリの速度も低下します。
パフォーマンスを向上させるための一般的なアプローチは、ページ分割のサポートを追加することです。これは、大きなデータセットを小さなチャンクに分割し、必要に応じて要求できるようにするものです。
ページ送りを行うには、さまざまな方法があります。たとえば Google の検索結果のようにページ番号を振ることもできますし、 Twitter のフィードのように無限スクロールさせることもできます。

データベースレベルでのページネーション
さて、データベースレベルでは、オフセットベースのページネーションとカーソルベースのページネーションという2つの手法があります。
- オフセットベース: ある程度の数の結果をスキップして、限られた範囲を選択します。たとえば、最初の200件の結果をスキップして、その後の10件だけを取り上げることができます。この方法の欠点は、データベースレベルではスケールしないことです。たとえば、最初の200,000レコードをスキップする場合、データベースはまだすべてのレコードをトラバースする必要があり、パフォーマンスに影響します。
オフセットベースのページ送りを使用する理由についての詳細は、 ドキュメントを参照ください。
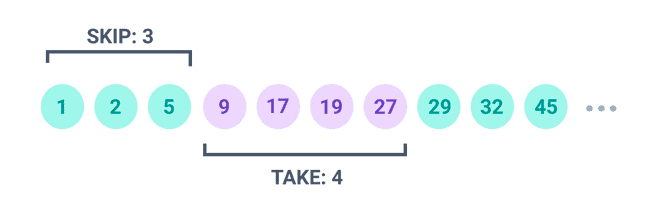
- カーソルベースのページネーション: カーソルを使って、結果セットのある場所をブックマークすることができます。その後のリクエストで、その保存した場所に直接ジャンプすることができます。配列にインデックスでアクセスするのと似ています。
カーソルは、IDやタイムスタンプのような、一意で連続したカラムである必要があります。この方法は、オフセットベースのページネーションよりも効率的であり、このチュートリアルで使用する方法です。
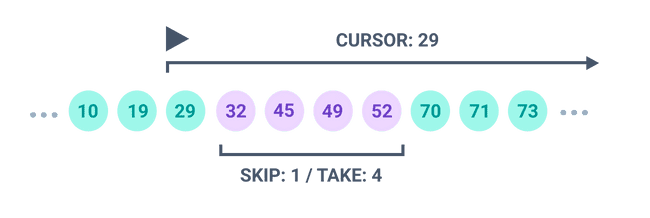
GraphQLにおけるパジネーション
GraphQL APIをページネーションに対応させるためには、Relay Cursor Connections SpecificationをGraphQLスキーマに導入する必要があります。これは、GraphQLサーバーがページネーションされたデータをどのように公開すべきかの仕様です。
以下は、allLinksQueryのページネーションクエリがどのようなものになるかを示しています。
query allLinksQuery($first: Int, $after: String) {
links(first: $first, after: $after) {
pageInfo {
endCursor
hasNextPage
}
edges {
cursor
node {
id
imageUrl
title
description
url
category
}
}
}
}
クエリーは、first と after の2つの引数を取ります。
- first: API に返させたい項目の数を指定する Int。
- after: 結果セットの最後の項目をブックマークする String 引数で、これがカーソルとなります。
このクエリは、pageInfoとedgeという2つのフィールドを含むオブジェクトを返す。
- pageInfo:クライアントが、さらに取得すべきデータがあるかどうかを判断するのに役立つオブジェクト。このオブジェクトは、endCursorとhasNextPageという2つのフィールドを含んでいる。
- endCursor: 結果セット内の最後のアイテムのカーソル。このカーソルのタイプはStringである。
- hasNextPage: APIが返すブール値で、フェッチできるページがまだあるかどうかをクライアントに知らせます。
- edgesはオブジェクトの配列であり、各オブジェクトはカーソルフィールドとノードフィールドを持つ。ここでのノードフィールドは、Linkオブジェクトタイプを返します。
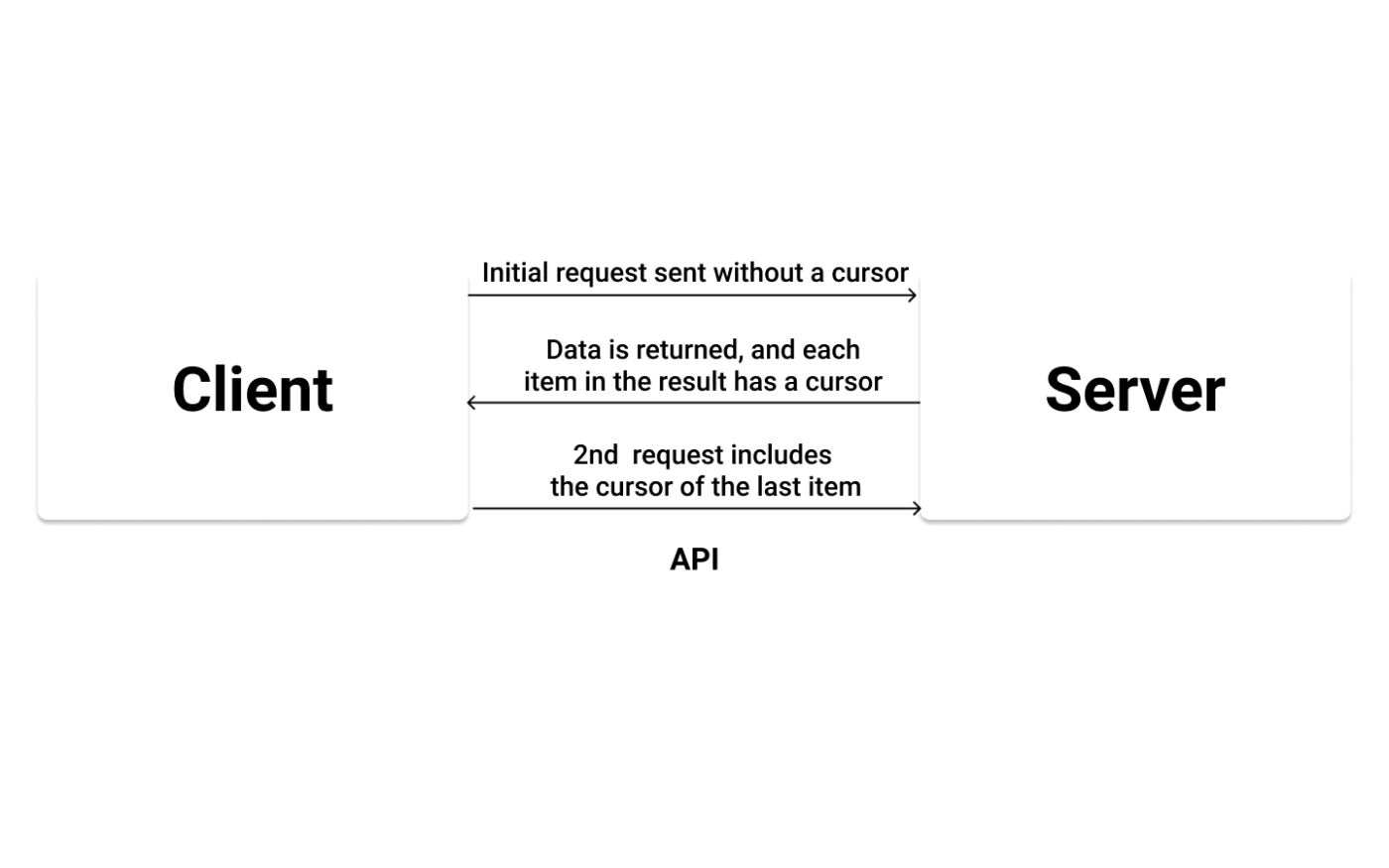
ページが最初にロードされたときにいくつかのリンクが要求され、その後、ユーザがボタンをクリックすることでさらに多くのリンクを取得できる、一方向のページ送りを実装することになります。
あるいは、ユーザーがスクロールしてページの最後に到達したときに、このリクエストを行うこともできます。
この方法は、ページが最初にロードされるときにデータを取得する。次にボタンをクリックした後、APIに2回目のリクエストを送信する。このリクエストには、返したいアイテムの数とカーソルが含まれる。すると、データが返され、クライアントに表示される。
GraphQLスキーマの修正
Nexusを使って再現するには、/graphql/types/Link.ts ファイルに移動して、以下のコードを追加します。
// /graphql/types/Link.ts
// code above unchanged
export const Edge = objectType({
name: 'Edge',
definition(t) {
t.string('cursor')
t.field('node', {
type: Link,
})
},
})
export const PageInfo = objectType({
name: 'PageInfo',
definition(t) {
t.string('endCursor')
t.boolean('hasNextPage')
},
})
export const Response = objectType({
name: 'Response',
definition(t) {
t.field('pageInfo', { type: PageInfo })
t.list.field('edges', {
type: Edge,
})
},
})
以下のオブジェクトタイプを定義しました。
- Egdes: string 型のカーソルフィールドと、Link オブジェクトを返すノードフィールドを含む。
- PageInfo: string 型の endCursor フィールドと hasNextPage boolean を含む。
- Response: LinksQueryから返されるオブジェクトタイプである。これはpageInfoオブジェクト・タイプとEdgeタイプのarrayであるedgesを含んでいる。
ここで、LinksQueryを以下のコードに更新する。
export const LinksQuery = extendType({
type: 'Query',
definition(t) {
t.field('links', {
type: 'Response',
args: {
first: intArg(),
after: stringArg(),
},
async resolve(_, args, ctx) {
return {
edges: [
{
cursor: '',
node: {
title: '',
category: '',
imageUrl: '',
url: '',
description: '',
},
},
],
}
},
})
},
})
次に、/graphql/types/Link.tsのLinksQueryを以下のコードに更新します。
// /graphql/types/Link.ts
// get ALl Links
export const LinksQuery = extendType({
type: 'Query',
definition(t) {
t.field('links', {
type: 'Response',
args: {
first: intArg(),
after: stringArg(),
},
async resolve(_, args, ctx) {
let queryResults = null
if (args.after) {
// check if there is a cursor as the argument
queryResults = await ctx.prisma.link.findMany({
take: args.first, // the number of items to return from the database
skip: 1, // skip the cursor
cursor: {
id: args.after, // the cursor
},
})
} else {
// if no cursor, this means that this is the first request
// and we will return the first items in the database
queryResults = await ctx.prisma.link.findMany({
take: args.first,
})
}
// if the initial request returns links
if (queryResults.length > 0) {
// get last element in previous result set
const lastLinkInResults = queryResults[queryResults.length - 1]
// cursor we'll return in subsequent requests
const myCursor = lastLinkInResults.id
// query after the cursor to check if we have nextPage
const secondQueryResults = await ctx.prisma.link.findMany({
take: args.first,
cursor: {
id: myCursor,
},
orderBy: {
id: 'asc',
},
})
// return response
const result = {
pageInfo: {
endCursor: myCursor,
hasNextPage: secondQueryResults.length >= args.first, //if the number of items requested is greater than the response of the second query, we have another page
},
edges: queryResults.map(link => ({
cursor: link.id,
node: link,
})),
}
return result
}
//
return {
pageInfo: {
endCursor: null,
hasNextPage: false,
},
edges: [],
}
},
})
},
})
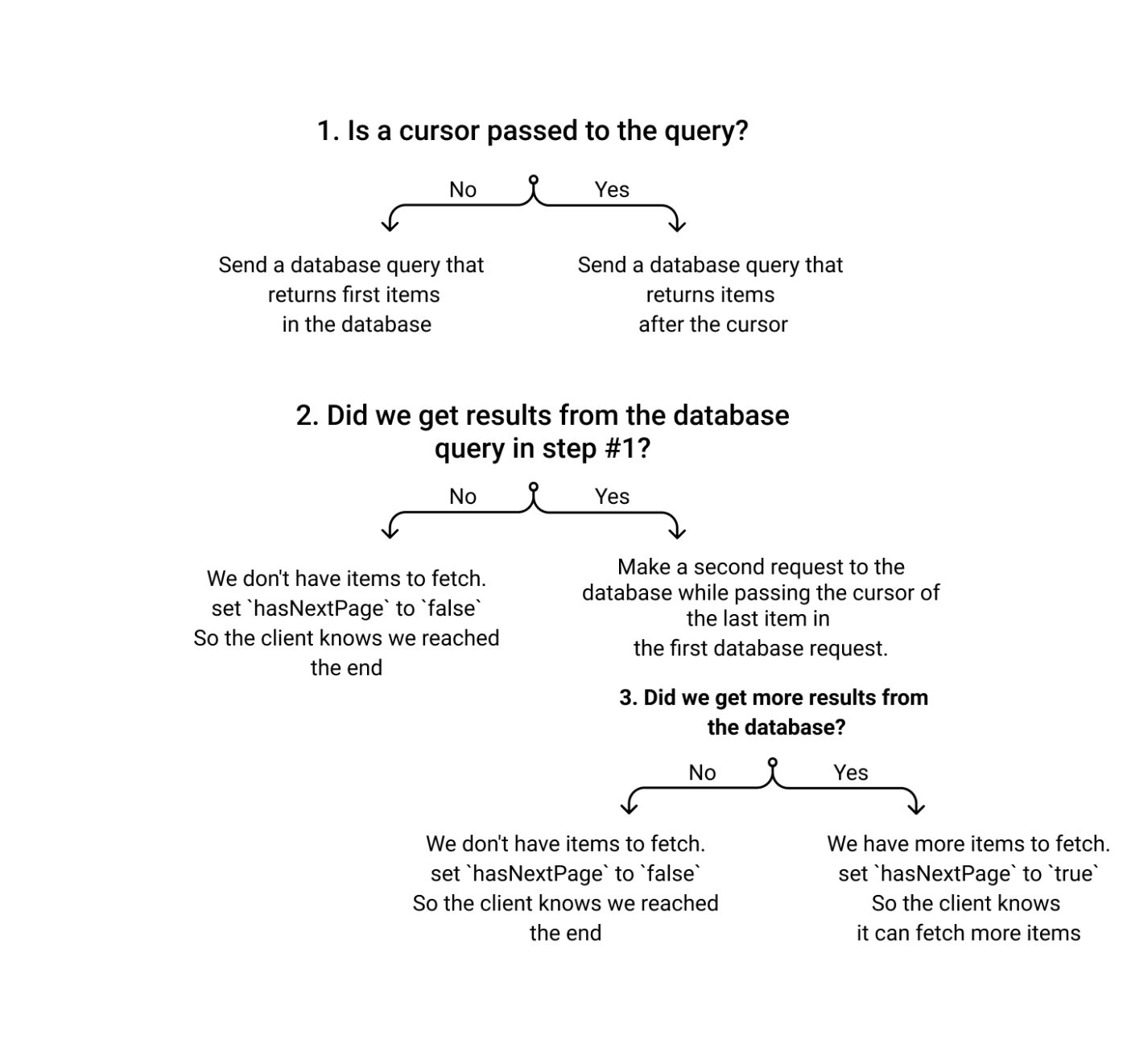
このリゾルバが最初に行うことは、クライアントからのクエリの引数としてカーソルが渡されているかどうかを確認することである。カーソルがない場合、これは初期リクエストとなります。
この初期リクエストが空の配列を返した場合、データベース内にリンクがないことを示すResponseオブジェクトが返されます。
最初のリクエストがリンクを返す場合、最初の結果セットから最後の要素の id を取得し、それをカーソルとして 2 番目のクエリで渡します。
そして、カーソルを含むResponseオブジェクトを返します。このカーソルは、クライアントからのクエリの引数として渡すことができます。
ページネーションがサーバー上でどのように動作するかをまとめた図を以下に示します。
fetchMore()を使用したクライアントでのページネーション
APIがページネーションに対応したことで、Apollo Clientを使用してクライアント上でページネーションされたデータを取得することができます。
useQueryフックは、データ、ローディング、エラーを含むオブジェクトを返します。しかし、useQueryはfetchMore()関数も返し、これはページネーションと結果が返されたときのUI更新を処理するために使用されます。
/pages/index.tsx ファイルに移動して、次のコードを使用するように更新し、ページ送りのサポートを追加してください。
// /pages/index.tsx
import Head from "next/head";
import { gql, useQuery, useMutation } from "@apollo/client";
import Link from "next/link";
import { AwesomeLink } from "components/AwesomeLink";
const AllLinksQuery = gql`
query allLinksQuery($first: Int, $after: String) {
links(first: $first, after: $after) {
pageInfo {
endCursor
hasNextPage
}
edges {
cursor
node {
id
imageUrl
url
title
category
description
id
}
}
}
}
`;
function Home() {
const { data, loading, error, fetchMore } = useQuery(AllLinksQuery, {
variables: { first: 2 },
});
if (loading) return <p>Loading...</p>;
if (error) return <p>Oh no... {error.message}</p>;
const { endCursor, hasNextPage } = data.links.pageInfo;
return (
<div>
<Head>
<title>Awesome Links</title>
<link rel="icon" href="/favicon.ico" />
</Head>
<div className="container mx-auto max-w-5xl my-20">
<div className="grid grid-cols-1 md:grid-cols-2 lg:grid-cols-3 gap-5">
{data?.links.edges.map(({ node }) => (
<AwesomeLink
title={node.title}
category={node.category}
url={node.url}
id={node.id}
description={node.description}
imageUrl={node.imageUrl}
/>
))}
</div>
{hasNextPage ? (
<button
className="px-4 py-2 bg-blue-500 text-white rounded my-10"
onClick={() => {
fetchMore({
variables: { after: endCursor },
updateQuery: (prevResult, { fetchMoreResult }) => {
fetchMoreResult.links.edges = [
...prevResult.links.edges,
...fetchMoreResult.links.edges,
];
return fetchMoreResult;
},
});
}}
>
more
</button>
) : (
<p className="my-10 text-center font-medium">
You've reached the end!{" "}
</p>
)}
</div>
</div>
);
}
export default Home;
まず、useQueryフックに変数オブジェクトを渡す。この変数にはfirstというキーがあり、値は2である。 これは、2つのリンクを取得することを意味する。この値は好きな数に設定することができる。
data変数には、APIへの最初のリクエストから返されたデータが格納される。
そして、pageInfoオブジェクトからendCursorとhasNextPageの値を再構築します。
hasNextPageがtrueの場合、onClickハンドラを持つボタンを表示します。このハンドラは、fetchMore()関数を呼び出す関数を返し、その関数は次のフィールドを持つオブジェクトを受け取ります。
- 初期データから返された endCursor を取得する Avariables オブジェクト。
- updateQuery 関数。これは、前の結果と 2 番目のクエリから返された結果を組み合わせて UI を更新する役割を担います。
hasNextPageがfalseの場合、取得できるリンクがもうないことを意味します。
保存してアプリを実行すると、データベースからページングされたデータをフェッチできるようになるはずです。
まとめと次のステップ
おめでとうございます。あなたはコースの第2部を無事終了しました。もし何か問題が発生したり、質問がある場合は、Slackのコミュニティでお気軽にお問い合わせください。
このパートで、あなたは以下のことを学びました。
- RESTよりもGraphQLを使用する利点
- SDLを使用してGraphQL APIを構築する方法
- Nexusを使用してGraphQL APIを構築する方法とその利点
- API にページネーションサポートを追加する方法と、クライアントからページネーション付きのクエリを送信する方法
このコースの次のパートでは、次のことを行います。
- APIエンドポイントを保護するためにAuth0を使用して認証を追加し、ログインしたユーザーのみがリンクを表示できるようにします。
- ログインしたユーザがリンクをブックマークできるように、ミューテーションを作成します。
- リンクを作成するための管理者専用のルートを作成します。
- ファイルアップロードを処理するためにAWS S3をセットアップします。
- 管理者としてリンクを作成するためのミューテーションを追加する
Discussion