Cloudflare Vectorize ベクトルデータの操作

CloudflareにはWorkersと連携するデータソースが風数存在していますが、昨今生成AIの発達に伴い自然言語や非構造化データの取り扱いに用いられるベクトルデータの保存と検索に特化したVectorizeというデータベースがあります。
VectorizeはWorkersのPaidプランでご利用いただけます。
ベクトルデータについて
非構造化データの取り扱いにはベクトル化という手法が用いられます。これはデータの意味とコンテキストを理解するという原則に基づいて動作します。テキスト、画像、音声などの複雑なデータを数値ベクトル埋め込みに変換します。これにより、データベースは従来の文字列やバイナリーblobの一致ではなく、意味の理解に基づいて検索を実行できるようになります。
つまり、1)様々なデータをベクトルというデータに変換する、2)ベクトルデータをデータベースに保存し検索可能とする、という2つのテクノロジーにより構成されます。
コサイン類似度について
試してみる前に、コサイン類似度についての解説です。
前述の通りベクトル検索は以下の2ステップで稼働します。
1)様々なデータをベクトルというデータに変換する、2)ベクトルデータをデータベースに保存し検索可能とする
まずは様々なデータ(文字列、音声、画像等)を外部ツールを使ってベクトルデータ化します。Langchianなどが有名ですがいろいろなツールが存在しています。このデータをベクトルデータベースに保存し検索を行います。その際コサイン類似度というものが一般的には使われます。
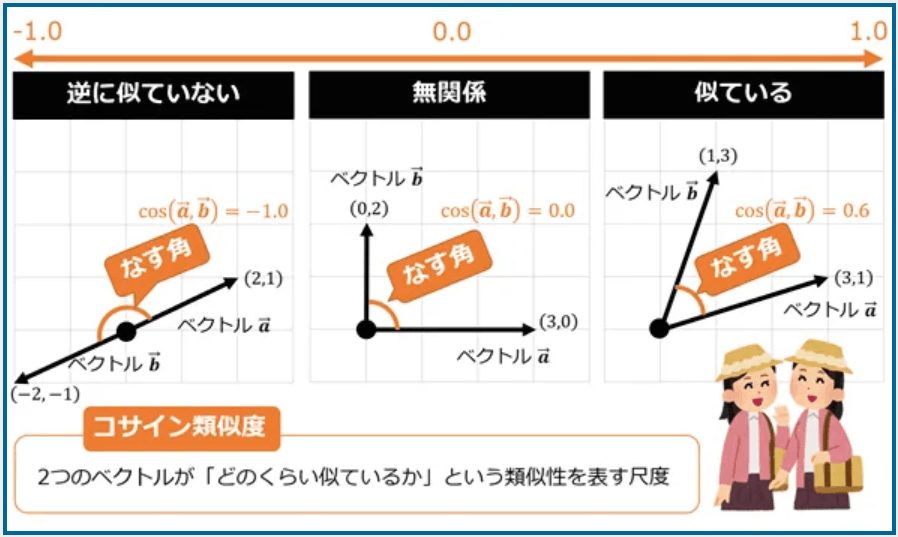 が非常にわかりやすいので図を拝借します。
が非常にわかりやすいので図を拝借します。
この図では2次元ですが、実際はより複雑な多階層次元によりデータが構成されます。
やってみる
Vectorizeインスタンスの作成
では早速VectorizeをWorkerから触ってみます。
以下のコマンドでVectorizeインスタンスを作成します。
create vectorizeで指定するDBインスタンス名は皆さんの名前に変えてください。
npx wrangler vectorize create vectorize --dimensions=3 --metric=cosine --deprecated-v1
🚧 Creating index: 'vectorize'
✅ Successfully created a new Vectorize index: 'vectorize'
📋 To start querying from a Worker, add the following binding configuration
into 'wrangler.toml':
[[vectorize]]
binding = "VECTORIZE_INDEX" # available within your Worker on
env.VECTORIZE_INDEX
index_name = "vectorize"
dimensionsは何次元のベクトルに対応するか?です。数字が大きければ大きいほど精度が向上しますが、当然計算は遅くなります。この例では10を指定していますが、実際の世界はもっと複雑です。例えばWorkersAIがデフォルトで埋め込み文字列を扱う際は768が推奨値です。この例では一度シンプルにして基礎を理解して行くためにも小さい数字にします。
metricは検索アルゴリズムです。Vectorizeは上記のほかにも、ユークリッド距離や負のスカラー値にも対応しています。違いに興味がある方は
等を参考にしてみて下さい。Vectorizeはインスタンス単位でこの値が固定であり、クエリ単位で変更はでいないので注意してください。
マネージメントコンソール上でDBインスタンスが一つできています。
[[vectorize]]
binding = "VECTORIZE_INDEX" # available within your Worker on
index_name = "vectorize"
は設定ファイルであるwrangler.tomlに記載すべき値なのでどこかにコピーしておきます。
Worker Projectのイニシャライズ
ではいつも通りHello Worldを起動します。
mkdir vectorize
cd .\vectorize\
wrangler init vectorize
Delegating to locally-installed wrangler@3.10.0 over global wrangler@2.14.0...
Run `npx wrangler init vectorize` to use the local version directly.
⛅️ wrangler 3.10.0 (update available 3.57.0)
-------------------------------------------------------
Using npm as package manager.
▲ [WARNING] The `init` command is no longer supported. Please use `npm create cloudflare@2 -- vectorize` instead.
The `init` command will be removed in a future version.
Running `npm create cloudflare@2 -- vectorize`...
using create-cloudflare version 2.0.9
╭ Create an application with Cloudflare Step 1 of 3
│
├ Where do you want to create your application?
│ dir vectorize
│
├ What type of application do you want to create?
│ type "Hello World" script
│
├ Do you want to use TypeScript?
│ typescript yes
│
├ Copying files from "simple" template
│
├ Do you want to use git?
│ git no
│
╰ Application created
╭ Installing dependencies Step 2 of 3
│
├ Installing dependencies
│ installed via `npm install`
│
╰ Dependencies Installed
╭ Deploy with Cloudflare Step 3 of 3
│
├ Do you want to deploy your application?
│ no deploying via `npm run deploy`
│
├ APPLICATION CREATED Deploy your application with npm run deploy
│
│ Run the development server npm run start
│ Deploy your application npm run deploy
│ Read the documentation https://developers.cloudflare.com/workers
│ Stuck? Join us at https://discord.gg/cloudflaredev
│
╰ See you again soon!
cd vectorize
workers関数のデプロイとテスト
普段私はTypeScriptをなるべく使わずブログを書いていますが、Vectorizeは公式ドキュメントでも明示的にTypeScriptを指定しているため、プロジェクトはTypeScriptでイニシャライズしました。
作成されたらwrangler.tomlを以下に修正します。先ほどのものを追記しただけです。
#:schema node_modules/wrangler/config-schema.json
name = "vectorize"
main = "src/index.ts"
compatibility_date = "2024-08-15"
compatibility_flags = ["nodejs_compat"]
[[vectorize]]
binding = "VECTORIZE_INDEX" # available within your Worker on env.VECTORIZE_INDEX
index_name = "vectorize"
vectorizeの部分は皆さんの名前毎に変えてください。
次にindex.tsをいかに置き換えます。
export interface Env {
VECTORIZE_INDEX: VectorizeIndex;
}
const sampleVectors: Array<VectorizeVector> = [
{ id: '1', values: [32.4, 74.1, 3.2], metadata: { url: '/products/sku/13913913' } },
{ id: '2', values: [15.1, 19.2, 15.8], metadata: { url: '/products/sku/10148191' } },
{ id: '3', values: [0.16, 1.2, 3.8], metadata: { url: '/products/sku/97913813' } },
{ id: '4', values: [75.1, 67.1, 29.9], metadata: { url: '/products/sku/418313' } },
{ id: '5', values: [58.8, 6.7, 3.4], metadata: { url: '/products/sku/55519183' } },
];
export default {
async fetch(request, env, ctx): Promise<Response> {
let path = new URL(request.url).pathname;
if (path.startsWith("/favicon")) {
return new Response('', { status: 404 });
}
if (path.startsWith("/insert")) {
let inserted = await env.VECTORIZE_INDEX.insert(sampleVectors);
return Response.json(inserted);
}
const queryVector: Array<number> = [54.8, 5.5, 3.1];
const matches = await env.VECTORIZE_INDEX.query(queryVector, { topK: 3, returnValues: true, returnMetadata: true });
return Response.json({
matches: matches,
});
},
} satisfies ExportedHandler<Env>;
一度Deployしてみます。
wrangler deploy
Delegating to locally-installed wrangler@3.57.0 over global wrangler@2.14.0...
Run `npx wrangler publish` to use the local version directly.
⛅️ wrangler 3.57.0
-------------------
▲ [WARNING] `wrangler publish` is deprecated and will be removed in the next major version.
Please use `wrangler deploy` instead, which accepts exactly the same
arguments.
Your worker has access to the following bindings:
- Vectorize Indexes:
- VECTORIZE_INDEX: vectorize
Total Upload: 1.09 KiB / gzip: 0.51 KiB
Uploaded vectorize (1.54 sec)
Published vectorize (4.13 sec)
https://vectorize.harunobukameda.workers.dev
Current Deployment ID: 0bf2f9f3-3224-4aea-84e6-12570ffb4c5f
Current Version ID: 0bf2f9f3-3224-4aea-84e6-12570ffb4c5f
Note: Deployment ID has been renamed to Version ID. Deployment ID is present to maintain compatibility with the previous behavior of this command. This output will change in a future version of Wrangler. To learn more visit:
この状態で生成されたURLにアクセスと表示されるはずです。
{"matches":{"count":0,"matches":[]}}
少し中身を見ていきます。
export interface Env {
VECTORIZE_INDEX: VectorizeIndex;
}
はWorkersお約束の書式です。wrangler.tomlの中で設定したVectorizeインスタンスをバインディングして、環境変数でWorkersコードから呼び出せるようになります。これだけでenvという環境変数を指定するとVectorizeインスタンスが呼び出せるのはWorkersの特徴です。
if (path.startsWith("/insert")) {
let inserted = await env.VECTORIZE_INDEX.insert(sampleVectors);
return Response.json(inserted);
}
デプロイされたURL+/insertにアクセスするとデータのinsertが行われます。
{"count":5,"ids":["1","4","3","5","2"]}
以下の5つのベクトルデータがinsertされたという意味です。
const sampleVectors: Array<VectorizeVector> = [
{ id: '1', values: [32.4, 74.1, 3.2], metadata: { url: '/products/sku/13913913' } },
{ id: '2', values: [15.1, 19.2, 15.8], metadata: { url: '/products/sku/10148191' } },
{ id: '3', values: [0.16, 1.2, 3.8], metadata: { url: '/products/sku/97913813' } },
{ id: '4', values: [75.1, 67.1, 29.9], metadata: { url: '/products/sku/418313' } },
{ id: '5', values: [58.8, 6.7, 3.4], metadata: { url: '/products/sku/55519183' } },
];
尚insertは数回読み込むと2回目からは重複データの場合以下の通り処理がスキップされていることがわかります。
{"count":0,"ids":[]}
以下の通りupsertに変更することで何度も上書きを行います。
let inserted = await env.VECTORIZE_INDEX.upsert(sampleVectors);
この状態でもう一度ルートにアクセスを行うと以下のようなJSONが出力されます。(以下はJSON Formatterという神サイトで成形しました。
{
"matches":{
"count":3,
"matches":[
{
"id":"5",
"values":[
58.79999923706055,
6.699999809265137,
3.4000000953674316
],
"metadata":{
"url":"/products/sku/55519183"
},
"score":0.999909486
},
{
"id":"4",
"values":[
75.0999984741211,
67.0999984741211,
29.899999618530273
],
"metadata":{
"url":"/products/sku/418313"
},
"score":0.789848214
},
{
"id":"2",
"values":[
15.100000381469727,
19.200000762939453,
15.800000190734863
],
"metadata":{
"url":"/products/sku/10148191"
},
"score":0.611976262
}
]
}
}
これは以下の検索結果が出ています。
const queryVector: Array<number> = [54.8, 5.5, 3.1];
const matches = await env.VECTORIZE_INDEX.query(queryVector, { topK: 3, returnValues: true, returnMetadata: true });
return Response.json({
matches: matches,
});
[54.8, 5.5, 3.1]のベクトルは以下の投入済5ベクトルとどれが一番コサイン類似度か高いか?という意味です。
[32.4, 74.1, 3.2]
[15.1, 19.2, 15.8]
[0.16, 1.2, 3.8]
[75.1, 67.1, 29.9]
[58.8, 6.7, 3.4]
returnValues: true, returnMetadata: true を削除して再度wrangler deployを行い結果をシンプルにします。以下のようにtopK: 3で指示されたTop3が結果として出力されます。コサイン類似度では-1から1の間で類似度が出力され1に近ければ近いほど似ている、ということになります。
{
"matches":{
"count":3,
"matches":[
{
"id":"5",
"score":0.999909486
},
{
"id":"4",
"score":0.789848214
},
{
"id":"2",
"score":0.611976262
}
]
}
}
つまり[54.8, 5.5, 3.1]に一番近いのはid=5の[58.8, 6.7, 3.4]です。これはなんとなく計算しなくても想像がつくと思います。
次の記事ではLangChainを使って連携させてみたいと思います。
Discussion