S3からのデータ移行その2 Cloudflare Sippy

前回、以下の記事では Super Slurper というツールを用いて S3 からの一括データ移行を行いました。(差分移行は Closed Beta なのでまた機会があればご紹介します)
Cloudflare にはもう一つデータを順次移行させる Sippy というツールが提供されています。これはデータをまとめて移行させるものではなくGetリクエストがあったオブジェクトのみを順次リクエスト単位で S3 からダウンロードし R2 へ保存するという動作をします。CDNでいうと、S3 がオリジン、R2がエッジのような関係性になりますが、CDN のキャッシュと異なり最新版を S3 へチェックしに行くという動作は行わず<bucket名>+<オブジェクト名>で合致したファイルが R2 へ存在すればレスポンスでそのオブジェクトを戻す。存在しない場合、S3 からダウンロードを行い、オブジェクトを R2 へ保存しオブジェクトをレスポンスで戻す、という動作をします。
大量のファイルを一気に移行させる場合、通信帯域にもよりますがかなりの時間がかかります。このため運用途中のシステムでは計画停止による移行が行えず、オンライン状態のままデータ移行を行うことを検討する必要がありますが、sippyではそれをサポートします。
さっそくやってみる
まずはデータの置き場所である S3 及びCloudflare からの接続に使用する IAM クレデンシャルが必要ですが、これは前回の記事のものを再利用するため、以下の手順を終わらせておきます。
前回同様新規で R2 バケットをテスト用に作成しSettingsタブへ移動します。

画面下部のIncremental migrationのEnableボタンを押します。

以下にS3の情報を入力します。
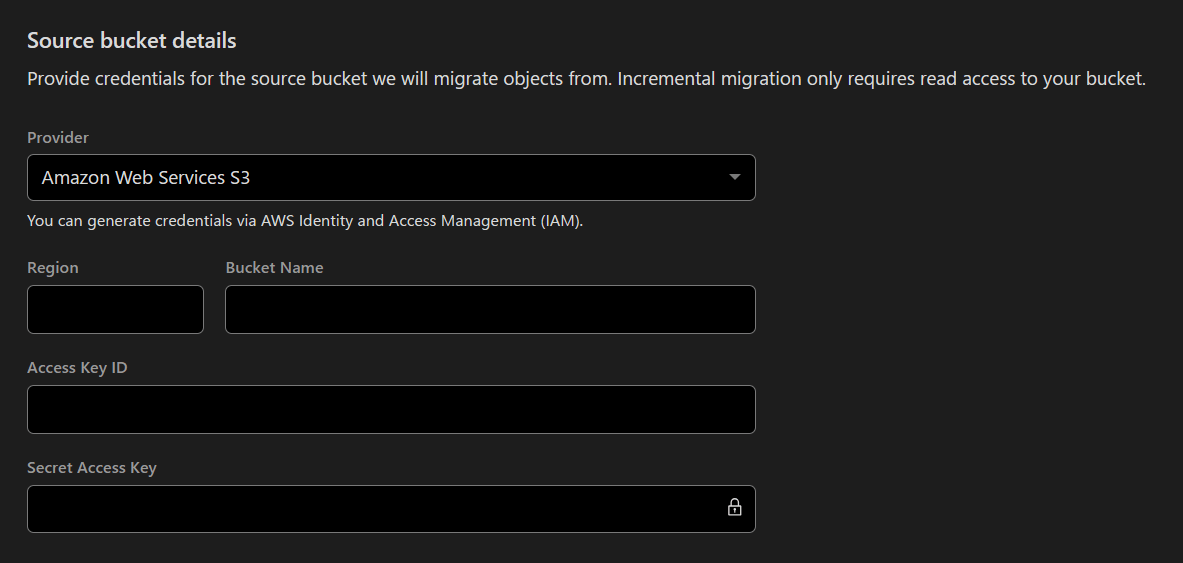
尚RegionはAWSの正式リージョンコードである必要があります。東京リージョンだとap-northeast-1になります。
必要な情報を入力してEnableをクリックすると設定が完了です。

テスト
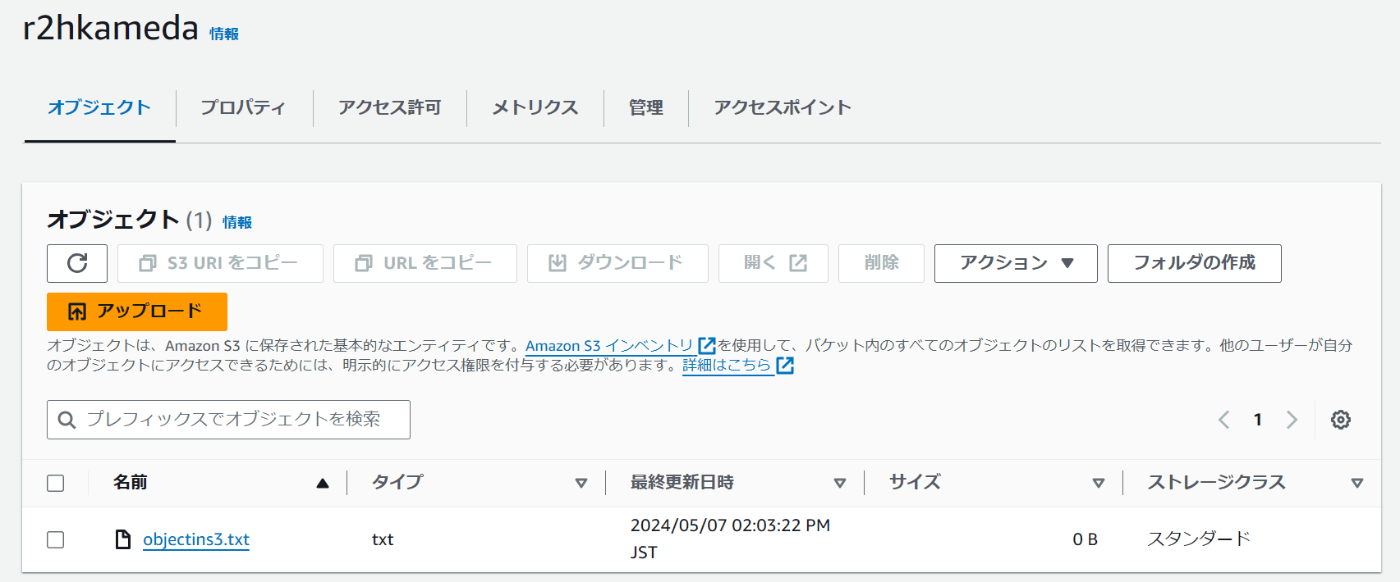
テスト用に2つのテキストファイルを準備しておきます。objectinr2.txtとobjectins3.txtとしておきます。objectinr2.txtをR2、objectins3.txtをS3に保存しておきます。
[r2]

[s3]
適当なツールでR2に対してGetObjectを投げます。AWS CLIも使えますが一番便利なのはWorkersの開発で使うWranglerでしょうか。手順が不明な方は以下を参考にやってみて下さい。
まず以下を実行します。
wrangler r2 object get sippy/objectinr2.txt
当たり前ですがファイルは問題なくダウンロードされます。
次に以下を実行します。
wrangler r2 object get sippy/objectins3.txt
objectins3.txtはR2には存在しませんが問題なく成功します。
Delegating to locally-installed wrangler@3.10.0 over global wrangler@2.14.0...
Run `npx wrangler r2 object get sippy/objectins3.txt` to use the local version directly.
⛅️ wrangler 3.10.0 (update available 3.53.1)
-------------------------------------------------------
Downloading "objectins3.txt" from "sippy".
Download complete.
R2バケットを見てみるとファイルが問題なく移行しています。

詳しいドキュメントはこちらです。
Discussion