Super Slurper を用いてAmazon S3 から R2 にデータを移行する
先日 Google などに続いて AWS の Amazon S3 もシステムを別基盤に移動させる際のデータ転送量を無償にするアナウンスを行いました。 この措置はシステム全体の移行に対して適応されるものであり、ハイブリッド環境や、引き続きオリジンは AWS を使いつつ配信は別 CDN などの場合には適応されないため、メリットを享受できるケースは多くはなさそうです。
一方、クラウドといえば過去の AWS 一強の時代から、データ分析や k8s モバイルアプリケーション開発はGoogle、OpenAI や MS 系ワークロードであればAzure 等複数クラウドを使い分ける企業が増えてきているように感じます。この際重要になるのはデータの置き場所です。3クラウドともシステム移行時のデータ取り出し料金は無償にすることをアナウンスしていますが、システムが稼働している場合は対象外になります。
対して、Cloudflare はすべてのサービスにおいてデータ転送量をゼロ円にしている関係上、ハイブリッド、もしくはマルチクラウド環境におけるデータの保管場所、データマートとしての問い合わせが増えています。
Super Slurper と R2
R2 は Cloudflare が提供しているオブジェクトストレージです。AWS S3 互換インターフェースを備え AWS CLI からそのまま操作できるのが一つの特徴です。データ保存料金は約半額、データ取り出し料金は無償であり大きいコスト削減が期待できます。
(余談ですが、私はCloudflare エバンジェリストではありますが、コスト削減[のみ]を目的としたS3 → R2 へのデータ移行は勧めていません。データは企業の将来を支える材料であり、安いだけで判断されるべきではなく、技術的必然性が求められると考えています。(怒られるかしら?))
S3からデータを取り出す一番良い方法は AWS Snowball なのですが残念ながら Cloudflare のデータセンターへ配送は行えず、なおかつ暗号鍵へのアクセスが AWS外部システムからは行えないため選択肢として使えません。このためオンラインデータ移行用に Cloudflare が提供しているのが Super Slurper になります。これは特定バケット+パスの組み合わせでデータを一気に移行させます。
現在Closed Beta で日時差分バッチ機能も提供しています。

やってみる
まずは移行元のS3バケットを作成します。この手順はこのブログでは割愛しますが、適当なバケットを作成しファイルをアップロードしておきます。
次にIAMポリシーを作成します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:Get*",
"s3:List*"
],
"Resource": [
"arn:aws:s3:::<BUCKET_NAME>",
"arn:aws:s3:::<BUCKET_NAME>/*"
]
}
]
}
当然ですが<BUCKET_NAME>は作成したバケットの名前に置き換えておきます。
作成されたIAMポリシーがアタッチされたIAMユーザー、ないしはロールを作成して、Access Key ID と Secret Access Key をメモっておきます。
以上で AWS 側の準備は完了ですので、次にCloudflare側の作業を行います。
まずR2で適当なバケットを作成します。

Create bucketを押します。

適当な名前を付けます。
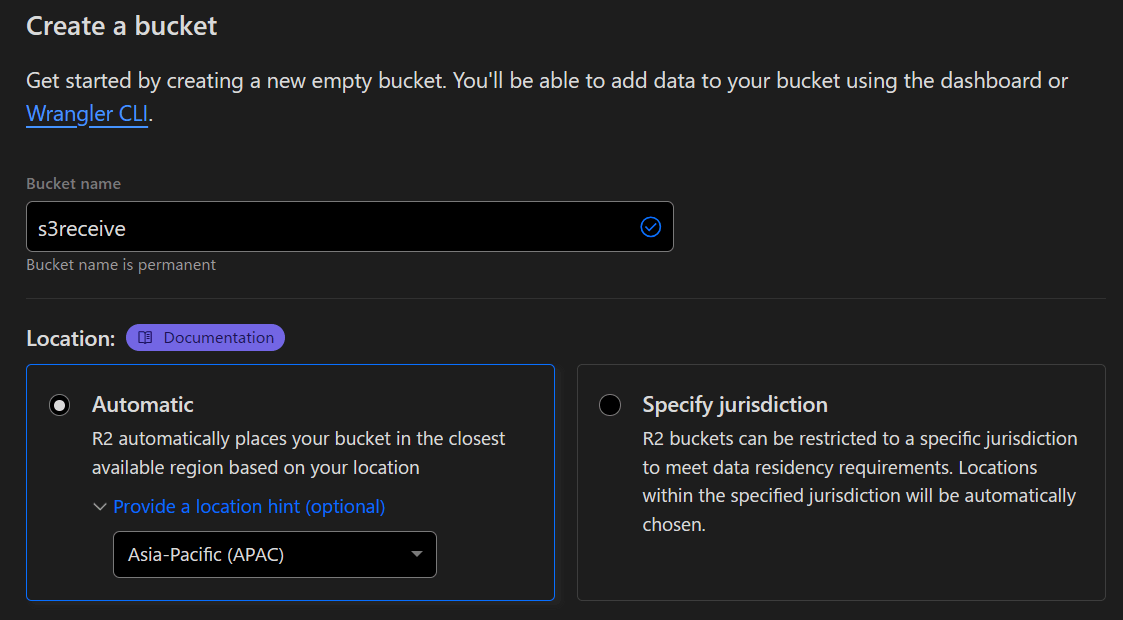
この際location hintをオンにして任意の地域をしています。
Cloudflareはリージョンレスサービスです。location hintを指定しない場合、世界のどこかにバケットが作成されます。(一応操作した管理者画面にログインしている管理者のIPアドレスで地域を特定し近場に作るよう努める仕様になっていますが、日本から作業してイタリアの作成されたケースなどがあります)このため、location hintでAPACを指定することで近場のデータセンターにバケットが作られます。
Create bucketをクリックします。

次に左ペインからData Migrationをクリックします。

Migrate filesをクリックします。
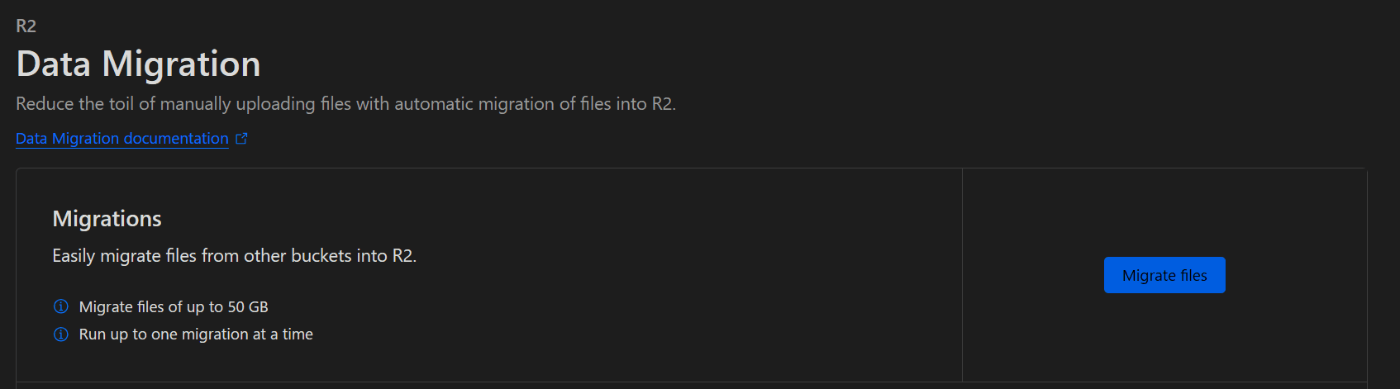
データソースはS3, Google Cloud Storage, R2から選択可能ですが今回はS3を指定します。

Bucket nameはS3のバケット名を指定します。
以下にIAMのクレデンシャルをセットしNextをクリックします。

データを受け取るR2のバケットを指定します。
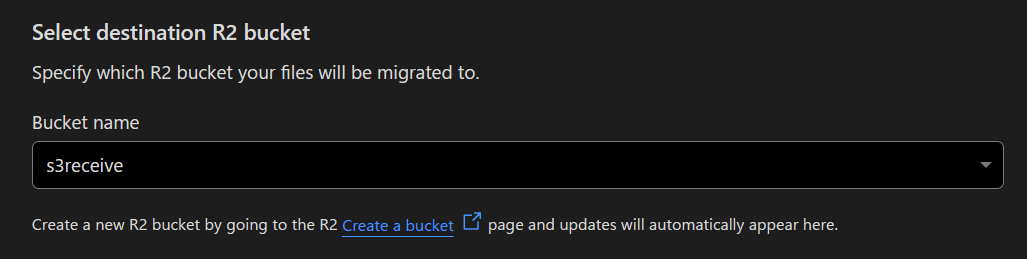
R2 API Tokensをクリックするとブラウザの別タブでCloudflare上でR2用API Tokenを作成する画面が表示されます。

Create API TokenをクリックしAPI Tokenを作成します。

この際以下のようにRead-onlyではなく書き込み権限を付与しておきます。
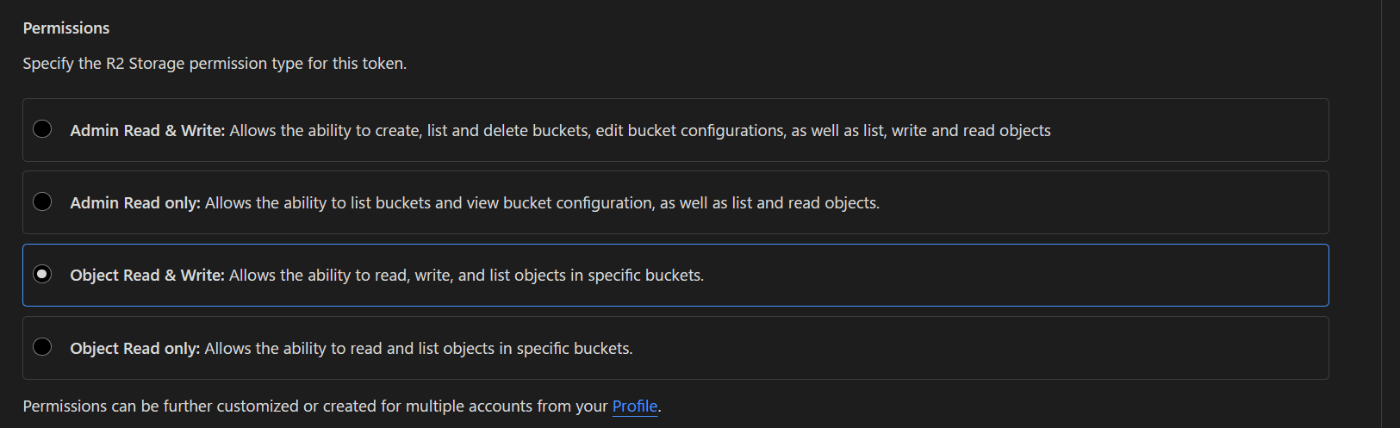
作成されるとAccess Key IDとSecret Access Keyが表示されますのでコピーしてメモっておきます。
先ほどのタブに戻って生成された値を入力します。
ファイルの上書きを行うかどうかを指定します。

現在差分移行機能は Closed Beta ですので複数回ジョブを実行させる場合は、上書きを禁止しておきます。
Nextを押すとS3、R2 それぞれのクレデンシャルチェックが行われます。

Migrate filesをクリックするとjobが実行されます。



この通りデータが移行されました。
以下の通りログをダウンロードすることが出来ます。
[
{
"logType":"migrationComplete",
"msg":"the migration has been completed",
"createdAt":"2024-05-02T06:06:52.082299Z"
},
{
"logType":"migrationStart",
"msg":"the migration started",
"createdAt":"2024-05-02T06:06:39.292159Z"
}
]
注意点
S3からのデータ取り出しにおいてデータ転送量を免除させるためには、事前にAWSサポートへの連絡が必要です
1オブジェクトサイズは50GBまでです。それ以上のオブジェクトが存在する場合rcloneなどのツールが必要になります。
その他
Super Slurper は一気にデータを移行しますが、クライアントからリクエストされたオブジェクトだけを順次移行させるSippyというサービスが別に存在します。機会があればまた別のブログにまとめたいと思います。
Discussion