MastraでDeep Researchクローン作成したい
Next.js × Amplify × MastraでDeep Researchクローン作成したい
やりたいこと
- MastraでDeep Researchクローンを作りたい
- Web検索ができる
- 多段でLLMを動かす
- 計画を立てて複数の検索ワードで検索する
- 段階的に、収集した情報が十分か、記載に誤りがないかを自省する
制約
- 諸事情によりGoogle検索やtavily等のweb検索APIが利用できない
- Azureは使えるが、bing searchが廃止になった
- 代替としてAzure AI Foundry > AI Agent Services > Grounding with Bing Searchの機能を使う
- web検索APIではなく「web検索機能をtoolとして保持しているgpt-4o」のAPIを提供するサービス
- OpenAIのresponses APIのbuilt-in toolsのWeb searchみたいなイメージ
- 検索結果の要約と検索結果のURLリストを取得できるので、代替として利用できる
- 35USD / 1,000検索なのでかなり高い
- web検索APIではなく「web検索機能をtoolとして保持しているgpt-4o」のAPIを提供するサービス
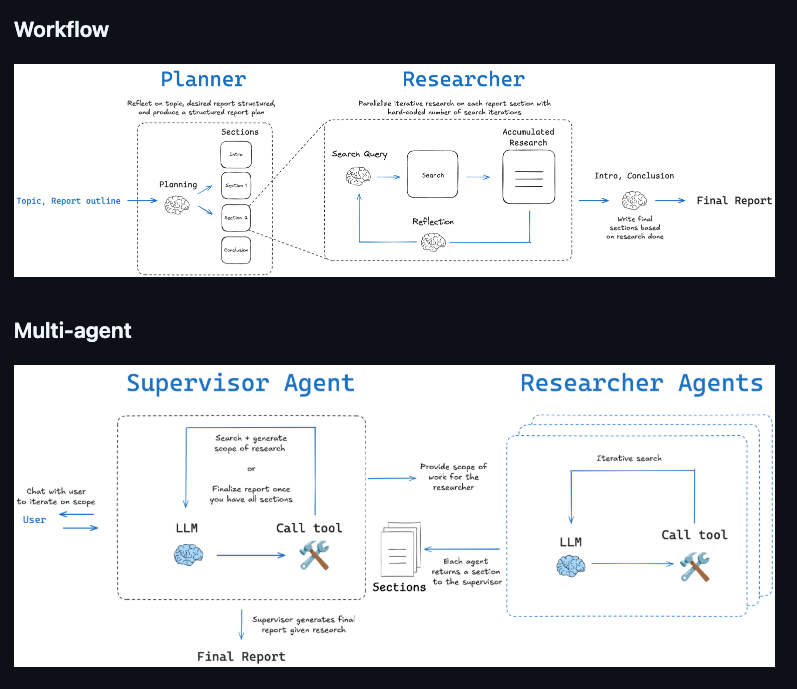
ワークフロー型とマルチエージェント型について
Open Deep Researchでは2つのアーキテクチャがあると紹介されている
直接関係ないが、ワークフローとエージェントの違いについてはこの記事も参考になる。
ワークフロー型
(雑理解)ステップごとの処理をコードとして定義しておき、順番にLLMを呼ぶ。
- コードとして定義されているので、毎回必ず同じ処理が実行される
- Mastraの場合、同じステップを可変の回数で繰り返し実行したい場合はワークフローの定義の中で、.dowhileや.foreachで定義する


既存で紹介されているMastraでのDeep Researchクローンはワークフロー型
マルチエージェント型
(雑理解)処理を統括エージェントのプロンプトとして指示しておき、統括エージェントが自律的に判断しながら、専門エージェントを呼ぶ。
- 100%同じ処理になるとは限らない。(統括エージェントがどの程度プロンプトに従うかによる)
- Mastraの場合、Agentのtoolとして『専門エージェントをtoolとしてラップしたもの』を渡す
↓専門エージェント①
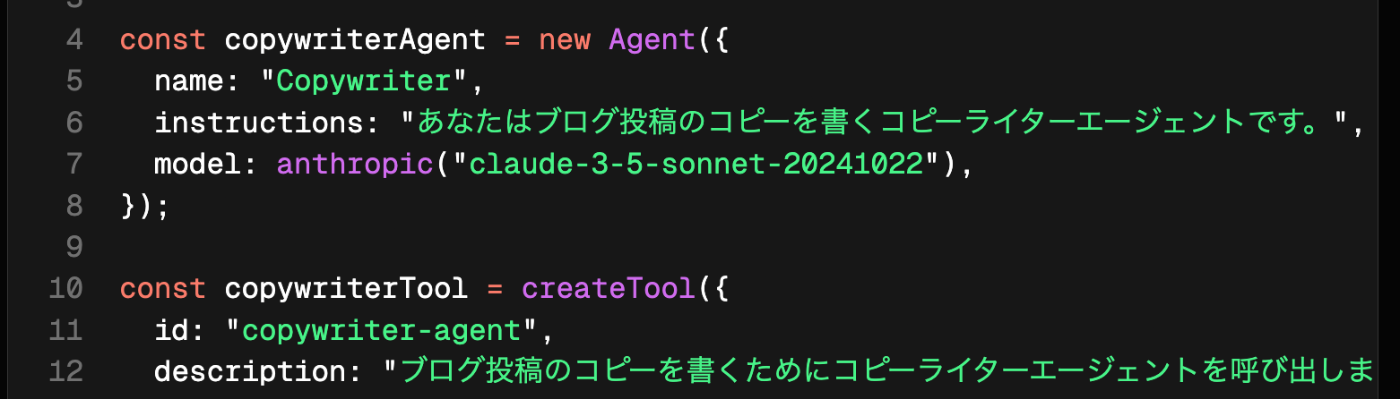
↓専門エージェント②

↓統括エージェント(2つの専門エージェントをtoolとして持っている)

言葉が混ざって使われる場合
ややこしいことに、以下のようにワークフローであっても、複数のLLMが連結しているという点から、マルチエージェントと言われる場合もある。
なので、処理手順が以下のどちらなのかで判断する。
①コードとして記載されている
myWorkflow.step(plannningStep).then(researchStep).then(writtingStep).then(reviewStep).commit();
②プロンプトとして記載されている
instructions: `
計画フェーズ → 情報収集 → 結果生成 → レビュー → 完了 というステップで進めてください。
`,
// ※ただし、究極的には、AIエージェントでは処理手順すら書かなくても良い可能性があるため、
厳密にいうと正確でないようにも思う。
instructions: `
あなたはユーザーの要望に応えるエージェントです。
`,
assistant-ui
assistant-uiというライブラリが便利そう。
mastra & Next.jsと公式にインテグレーションできるようだ。
メモ
最終的に参考になりそう
AzureのAPIを叩く際の認証について、ローカルの場合はAzure CLIからaz loginで良いが、実施にデプロイした後認証する際にはサービスプリンシパルの作成して、そこで発行した認証情報の環境変数への登録が必要。
const client = AIProjectsClient.fromConnectionString(
connectionString,
new DefaultAzureCredential()
);
AZURE_TENANT_ID=
AZURE_CLIENT_ID=
AZURE_CLIENT_SECRET=
流れ
以下はpythonだが認証情報の発行の内容は同じ。
- アプリの登録
- アプリケーションへのロールの割り当て(←忘れがちなので注意・ロールの割り当てには所有者権限が必要)
- デプロイ先に環境変数を登録する
https://learn.microsoft.com/ja-jp/azure/developer/python/sdk/authentication/local-development-service-principal?tabs=azure-portal#4---set-local-development-environment-variables
コード上は特に変更せずとも、DefaultAzureCredential()が自動で先ほどの環境変数を読み取ってくれる。

以下のようにMemoryとしてローカルDBを渡していると、当然ながらデプロイした際にエラーが出るので注意。
Memoryを消すか、なんらかのDBに置き換える必要がある。
// 統括エージェント
export const superviserAgent = new Agent({
name: "superviserAgent",
instructions: prompt_mastra_enhanced,
// instructions: prompt_gptO3_enhanced,
model: azure("gpt-4.1"),
tools: { azureWebSearchTool, readWebPageTool },
memory: new Memory({
storage: new LibSQLStore({
url: "file:../mastra.db",
}),
}),
});