LambdaからGlueJobにパラメーターを渡してみた
はじめに
S3トリガーを使用してLambda関数を呼び出し、LambdaからGlueJobを実行しようと試みましたが、どうやって引数をGlueに渡して受け取れば良いか分からず苦労しました...。
そこで、今回はGlueJobへのジョブパラメーターの設定方法とLambdaからGlueJobへの引数の渡し方についてまとめます。
まずはGlueJob ジョブパラメータについて理解しよう
ジョブパラメーターって?
ジョブパラメーターとは、Lambdaの環境変数と同じようなもので、実行するスクリプトの中で設定した変数を受け取ることが可能となります。
ちなみにジョブパラメーターは50個まで設定可能なようです。
ジョブパラメーターの設定方法
AWSコンソールからは、GlueJob設定画面のJob detailsのタブから設定可能です。

ここでKeyに書いている -- は好きでつけているわけではありません。
-- を先頭につけてあげないと、ジョブパラメーターとして認識せずにエラーになります。
では -- を付けなかった場合はどうなるか気になりますよね。
やってみましょう。
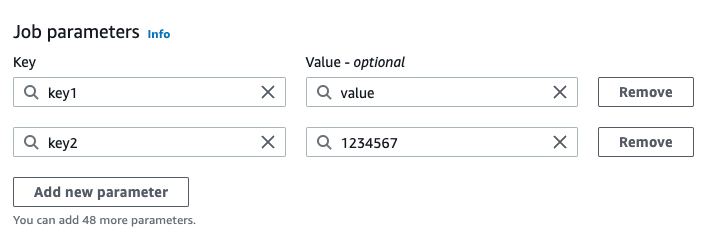
この設定でジョブを実行した場合、下記のように引数を認識せずにエラーが発生します。

よって、ジョブパラメーターを設定する場合は忘れずに -- を先頭につけてあげましょう。
ジョブパラメーターの取得方法
設定したジョブパラメーターを取得したい場合は getResolvedOptions の第二引数の部分に設定したジョブパラメーター名を入力してあげると連想配列で取得することができます。
あとはその配列のKeyに取得したいものを指定してあげると、値を取得することができます。
参考:getResolvedOptions を使用して、パラメータにアクセスする
import sys
from awsglue.utils import getResolvedOptions
# ジョブパラメーターを受け取る
args = getResolvedOptions(sys.argv, ['key1', 'key2'])
key1_value = args['key1']
key2_value = args['key2']
以降、実際の処理...
ここでの注意点なのですが、受け取るパラメーターは全てString型となります。
int型などで扱いたい場合はキャストしてあげましょう。
また取得時は -- をつける必要はありません。
LambdaからGlueに引数を渡して実行できる環境を作成しよう
ジョブパラメーターについて少し理解できたと思いますので、実際にLambdaから引数をGlueJobに渡す環境を作成してみましょう。
S3にオブジェクトが作成されたときに、Lambdaを介してGlueJobにS3の情報 (バケット名、オブジェクト名) を渡すような形で作成してみます。
Lambdaの作成
S3イベントJSONから、バケット名とオブジェクト名を取得してGlueJobに渡して実行するコードです。
Pythonで環境を作成し、コードを貼り付けてください。
今回はLambdaのs3-putのテストアクションを使って実行するので、トリガーは設定しません。
(ですが、Glueを実行するためのロールは設定必要となるので、設定しておきましょう。)
import json
import boto3
def lambda_handler(event, context):
# イベントJSONからバケット名とオブジェクトキーを取得
bucket_name = event['Records'][0]['s3']['bucket']['name']
object_key = event['Records'][0]['s3']['object']['key']
# GlueJobの呼び出し
job_name = '実行するジョブ名を入力する'
client = boto3.client('glue')
response = client.start_job_run(
JobName=job_name,
# 引数をArgumentsで指定する
Arguments={
'--bucket_name': bucket_name,
'--object_key' : object_key
}
)
GlueJobの作成
ジョブパラメーターを受け取り、プリントするだけのコードです。
Python Shell script editorでジョブを作成し、コードを貼り付けてください。
(CloudWatch Logsで確認する用にプリントしていますが、見るにあたってGlueJobにポリシーのアタッチが必要となります。)
import sys
from awsglue.utils import getResolvedOptions
# ジョブパラメーターを受け取る
args = getResolvedOptions(sys.argv, ['bucket_name', 'object_key'])
bucket_name = args['bucket_name']
object_key = args['object_key']
print(f"バケット名:{bucket_name}")
print(f"オブジェクト名:{object_key}")
あとは作成したGlueJob名をLambdaのコード内にあるjob_nameに入力すると実行できます。
ここで気になった方はいると思いますが、コードを記述しただけで、コンソール側でジョブパラメーターを設定していませんね。
Lambdaから渡すジョブパラメーターの設定はどうしたらいいの?
初期値のないジョブパラメーターは設定不要です。
しかし、設定を行ったからと言って、エラーが発生するわけではありません。
初期値を持たせておきたいジョブパラメーターがある場合、コンソール側で設定しておき、Lambdaから値を渡すことでその値が上書きされるように設定されます。
そのため、Lambdaから渡されるジョブパラメーターに応じてGlueJobの処理を変更したい場合などには、事前にコンソール側で設定しておきましょう。
作成した環境を実行してみよう
それでは実行してみましょう。
Lambdaでs3-putのテストイベントを実行してください。

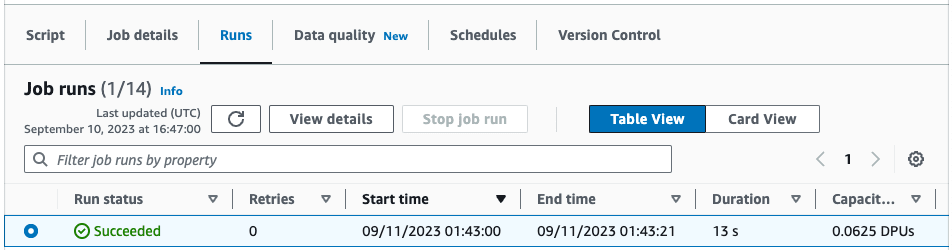
実行後、GlueJob設定画面のRunsの画面を見てみましょう。
正常に完了していると、下図と同様にSucceededとなります。
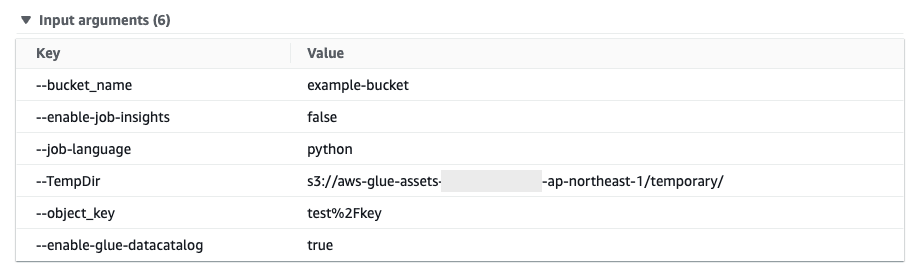
ポリシーをアタッチ済みの方は実行ログを確認してみましょう。
下図の様にS3の情報が出力されているかと思います。

まとめ
というわけで、今回はここまでとなります。
教訓は下記2点ですね。
・ ジョブパラメーターの命名は -- を先頭につける
・ Lambdaから値を渡すとき、初期値が不要であればコンソール画面でジョブパラメーターの設定は不要
-- が省略できないのはなんででしょうね・・・。
最後までご覧いただき、ありがとうございました!
Discussion