



はじめに
今年もre:invent2024に行ってきましたー
参加レポートは一緒に行った同僚の@nakashimanの以下記事に任せ...
私はWorkshopのレポートと、JINSではそれをどうやっているかを軽く書きたいと思います。
セッションレポート
COP305:Using Observability for effective incident responseというワークショップ受けました。
内容としては、架空のUnicorn Petsというペットの写真を投稿しそこにいいねができるサイトで発生している色々なトラブルをo11yで解決しましょうというワークショップでした。
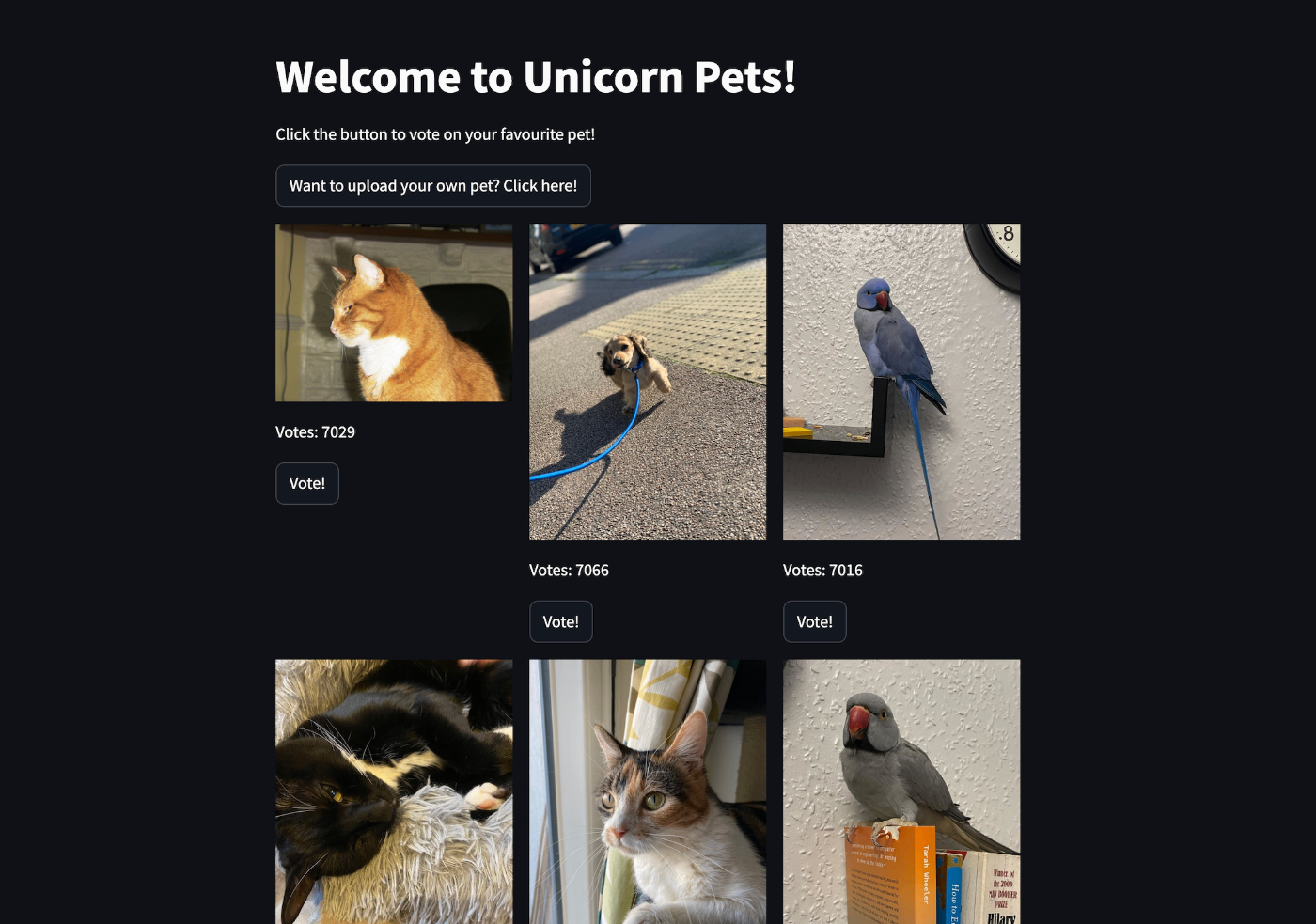
このサイト自体は以下のような構成で、
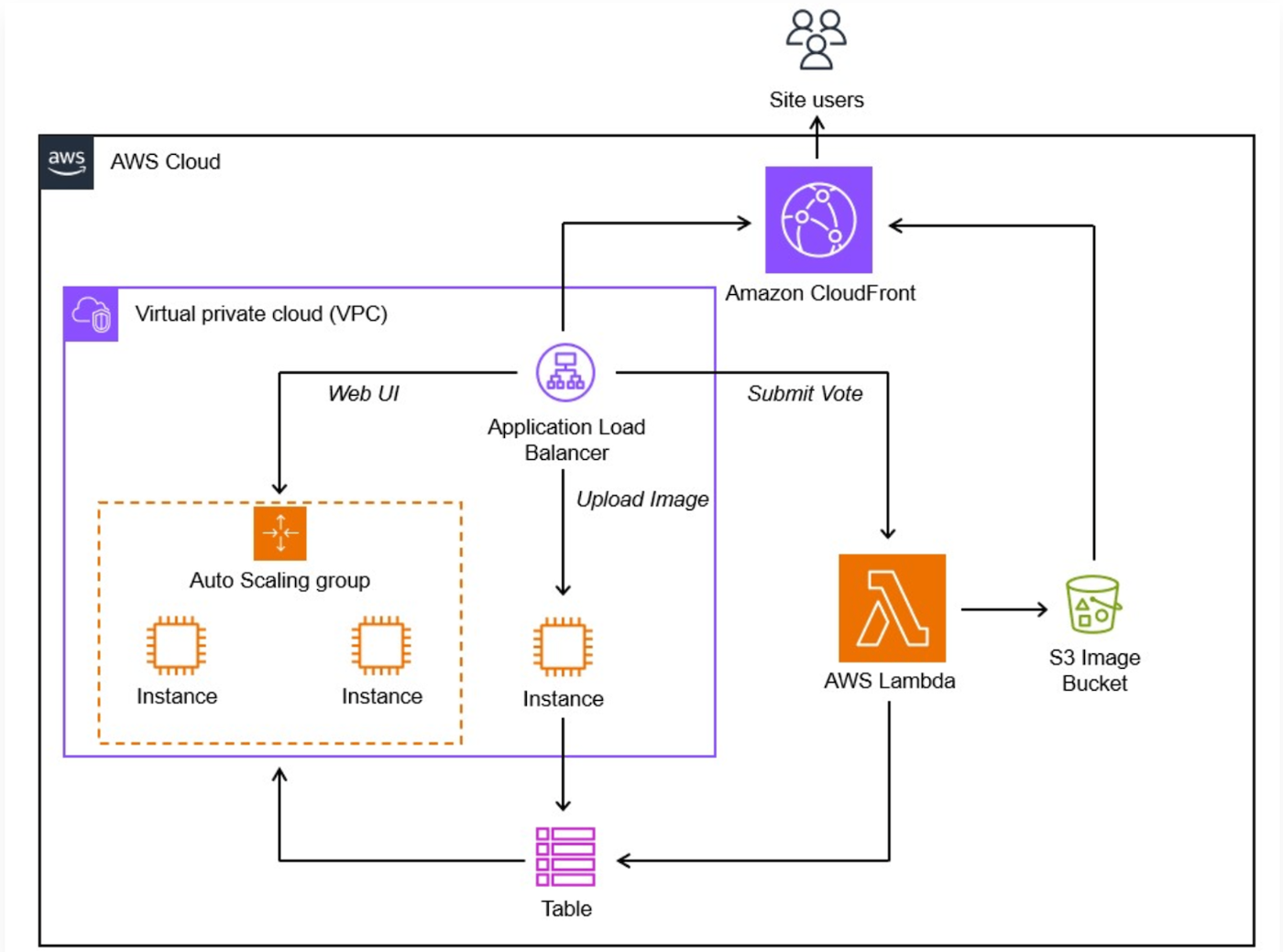
ここで発生している
- トラフィックが多い時間になるといいねができなくなる
- 新規画像の投稿がそもそも壊れていてできない
という課題をCloudWatchやSystem Manegerで原因の特定と改善を進めました。
トラフィックが多い時間になるといいねができなくなる
ここはCloudWatch logsを見て原因を特定しましょうパートでした。
Live Tailを使ってリアルタイムでログを見たり、

ログのインサイトからクエリを走らせてログを分析したりみたいなことを実施しました。
エラーの原因としてはDynamoDBのCapacityが足りなくなっているので、
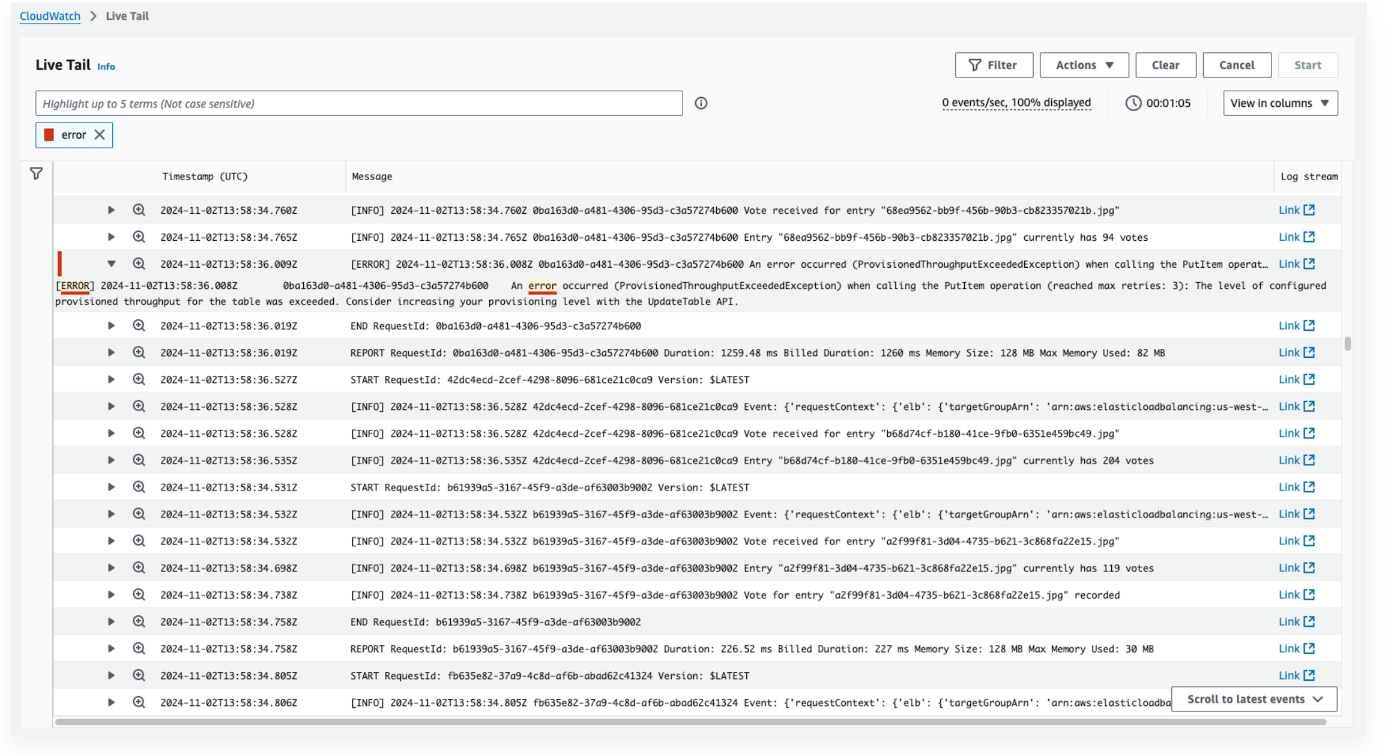
DynamoDBのRead CapacityとWrite CapacityのAuto Scalingを有効化してあげようって感じでした。
新規画像の投稿がそもそも壊れていてできない
ここは、EC2インスタンスにCloudWatch Agentをインストールしてより詳細なメトリクスを見る。そしてそこで特定した課題をAWS SSM Automationで改善しようパートでした。
CloudWatch Agentをインストールするところとそこからメトリクスを見るところはあまり興味なかったこともありスキップしてしまったのですが、メトリクスをみてimg-tmpディレクトリのディスク容量が足りなくなっていてこれが原因だよねと特定をしました。
その上で、ディスク拡張はいろいろな方法でできるけれど、ここをSSM Automation使いましょうで進みました。
SSM AutomationではすでにAWS側で用意されているRunbookがあり、その中から今回はAWS-ExtendEbsVolumeというその名の通りRunbookが用意されているので、ここに必要なパラメータを入れて実行しました。

これによってディスクが拡張され、ちゃんと画像をアップロードできるようになったね!🎉を確認しこのパートは完了でした。
Runbookの改修
上記のRunbookを更に使いやすいものにするため、このRunbookをベースにオリジナルのRunbookを実装しました。
追加した機能は以下となります。
- Runbookが実行された際に通知を行う
- 本番環境のワークロードに対しては(ここはタグで判断)実行前に承認プロセスを追加する
既存のRunbookに通知機能を追加して、
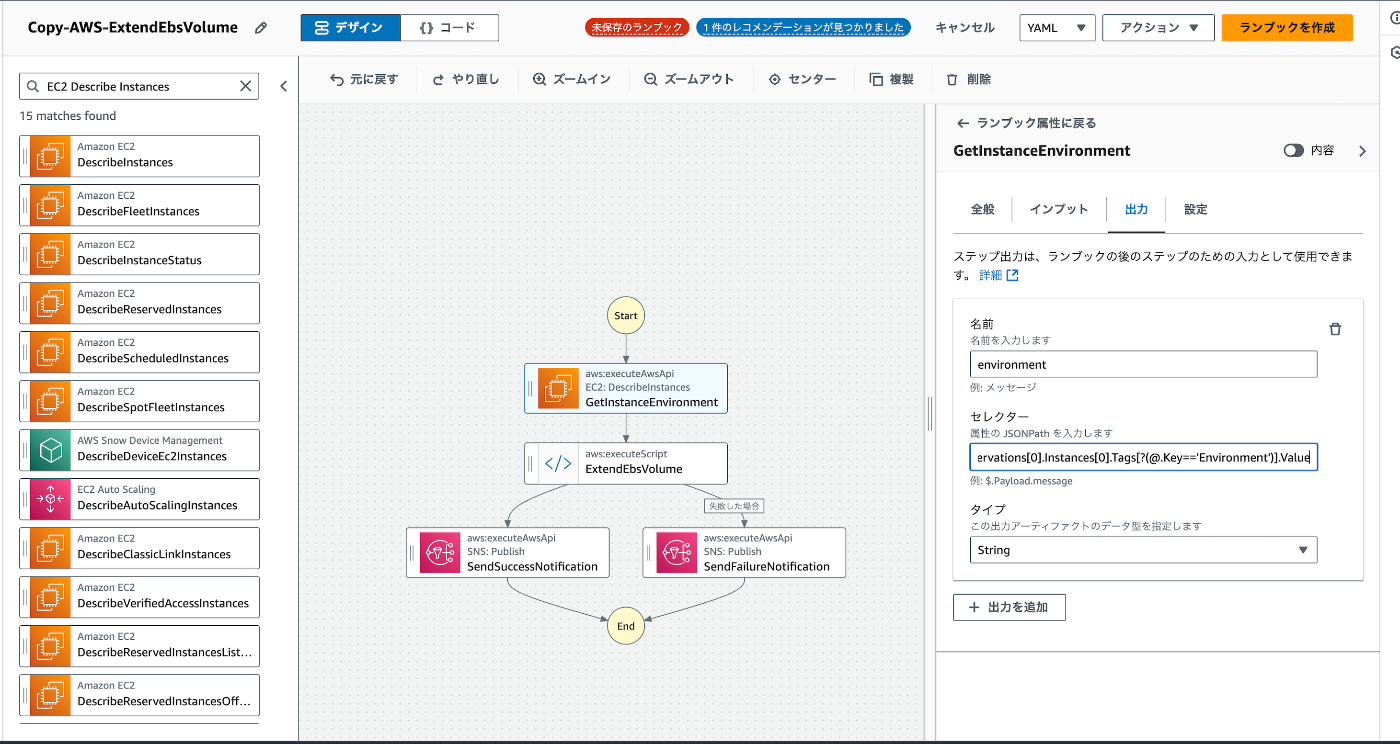
タグをベースにした条件分岐を追加して、
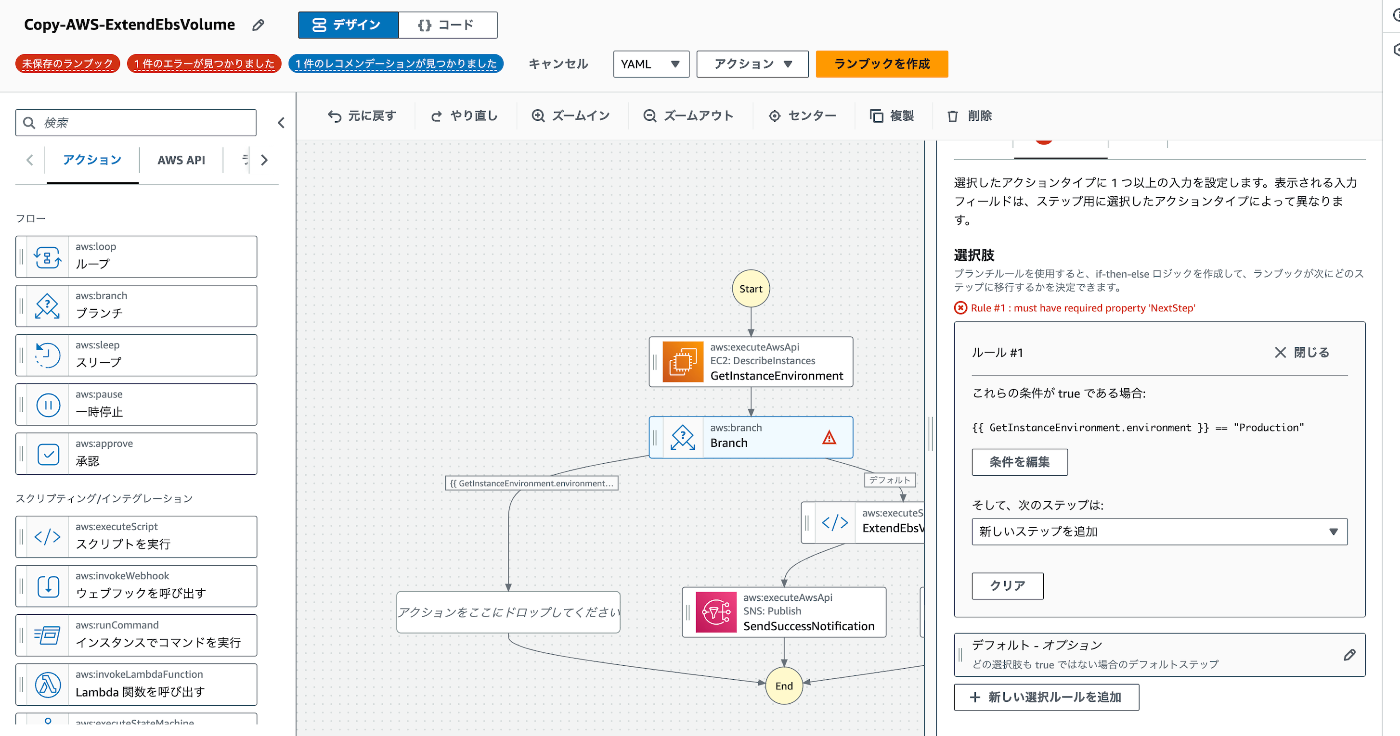
承認プロセスを追加して、
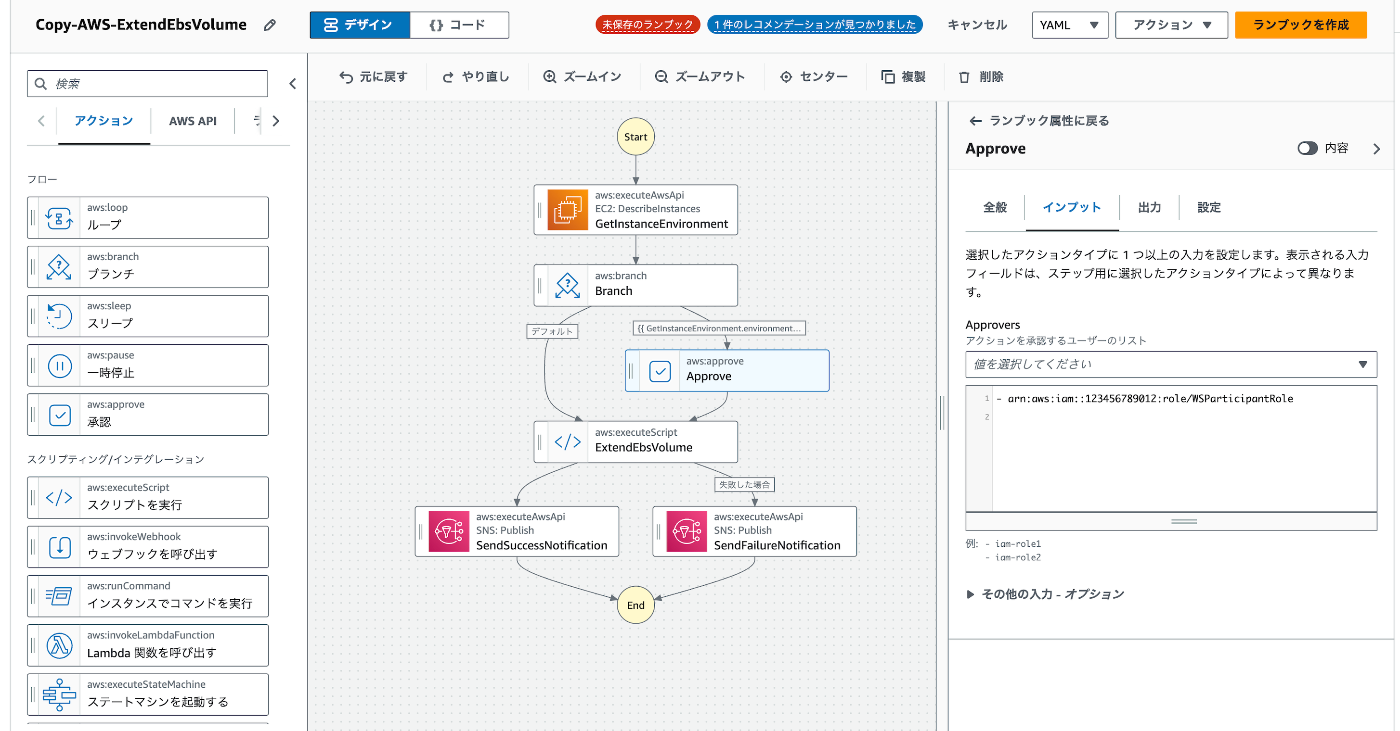
みたいに機能の追加をワークショップの中では進めました。
コードベースで作成することもできるようです。

ここまで作成し、実際に作成したRunbookを実行まで実施しました。
感想と学び
o11yのところは、普段は私はDatadogを利用しており、CloudWatchでメトリクス見たり、ダッシュボード作ったり、ログ漁ったりは滅多にないのでいい学習になりました。
ただ、Datadogでのダッシュボード作成やログクエリにだいぶ慣れてきてしまっているので、2時間のワークショップでは使い方は雰囲気を掴むまでだったかな...が正直なところです。
ただ、AWSに閉じてこれだけo11yができるのは改めて多機能だよなーを感じました。
そしてWernerのKeynoteでCloudWatchはだいぶ複雑と言っていたのもなんか納得。。。
SSM Automationについては以前書いた記事で使っている旨は少し書いたのですがそれ以外では使えていませんでした。
Automationを改修できることは知っていたのですが、このワークショップで実施したような条件分岐や承認プロセスなどがわりとサクッと使えるのは結構便利と感じ、細々した運用業務の改善に使えそうだなと感じました。
直近もJINS内でPatch Managerの検証を開始していたり含めSystem Managerでもう少し運用を改善・自動化できないかは検討しているので、使い倒していければと思います💪
JINSではどうか
JINSではCloudWatchとDatadogを目的や利用者によって使い分けており、ここで簡単にDatadog側の利用状況を紹介します。
現時点InfrastructureとLog、RUMをメインで使っており、APMも少しずつ使い始めておりこれからどんどん使っていこうステータスです。
主にInfra/Log周りで現在こんな取り組みしていますをご紹介します。
ダッシュボード
ダッシュボードをサービスごとにダッシュボードを作成しています。
インフラメトリクスメインのダッシュボード

APIの状況見れるダッシュボードだったり
数は少ないですがビジネス的な指標を出すものだったり(そしてほどんど見せられない)
今回のワークショップでやった内容は、Datadogのダッシュボードをみて「この挙動はおかしいよね」とやり取りしたり、Log Explorerで詳細のログ調査を実施したりしています。
また、サービスごとに作ったダッシュボードを見ながら、リソースの仕様状況や定期的なスパイクの原因の認識合わせ、直近の改修がどう反映されているかを定期的に実施しています。
モニター
リソースやエラーログ監視などはもちろん、最近はSynthetics監視系もしかけ始めました。
ブラウザ監視をやったり

証明書監視をやったり
また、直近でアラート疲れであったり、CPUが何%になったからといったアラートでなくもっとユーザに近い監視に切り替えようと言った課題が上がってきているので、こういった対応を年始から始めていこうかと思っています。
そのためにも最近「入門 監視」をもう一度読み直したりし始めました。
さいごに
セッションで体験したCloudWatchによるo11yとJINSでの取り組みを書いてみました。
APMをもっと使っていこう、監視改善を行わないとなど課題がたくさんあるので、今後このあたり取り組んでいきます!
余談
(全然不十分な内容感あるのですが)やっとこのフラグを多少回収できました・・・😇


Discussion