この記事は Jij Advent Calendar 2024、Haskell Advent Calendar 2024、およびRust Advent Calendar 2024シリーズ2 の18日目の記事です。
TL; DR:Haskell にも Rustにもよいところがあるので、お互いいいとこ取りをしていきたいですね!
はじめに:転職しました
このたび諸般の事情[1]により転職しまして、2024年11月から株式会社JijというところでRustを書いております。
筆者はかれこれ17年くらいはHaskellを書きつづけており、前職でもほぼ全てのものをHaskellで書いていたくらいには生粋のHaskellerです。今回もできればHaskellを書く仕事をできると良かった[2]んですが、まあ日本(や日本からリモートワークできる海外)の企業でHaskellを書ける仕事はそこまで多くはないです。
なので、数年前ちょっと触って良い言語だな〜と思っていた Rust の職を今回はメインで探しました。
前職ではHaskellで微分方程式をそのまま書ける大規模数値計算ソルバの開発に従事していたところ、Jij では数理最適化用言語を Python の EDSL として Rust で実装する、という無茶苦茶なことをやっているということで、いい意味で無謀なことをしようとしていて面白そうだな、前職で楽しんでやっていた事と近そうだな、というところで Jij さんで働かせてもらうことにしたという感じです。
そういった次第で、本記事では生粋の Haskeller が業務で一ヶ月半ほど Rust を書いてみて感じた言語感の差異 についてお話をしたいと思います。ネタバレしておくと、ねこが死ぬシーンはありませんし、HaskellとRust互いが互いに学ぶところあるよね、という話が主です。つまみぐいして、「これたしかにあった方が便利だな」というのがあったら盗む、みたいな使い方をしてもらえればと思います。軸足はHaskellにあるので、最終的には全部Haskellに盗みたいなと思っています。
Rust のいいところを Haskellに、Haskell のいいところを Rust に盗みたい!あとついでに Haskell のわかってるひとは知ってるけどあまりはっきり(日本語で)発信されていない習慣の話も書きたい!といろいろ書いていたらなんか意識の流れみたいになって六万字を越えてしまいました。わりと「Haskell の良いところを Rustに〜」寄りになってしまった感もありますが、アンチでは全くなく、日々業務で苦しみつつ楽しく Rust を書いています(苦しみのないプログラミングは楽しくないですよね?)し、本当によい言語だと思います。Rust をより良くしたい!というラブコールだと思っていただければ(Haskellももっと更に良くするぞ!と意気込んでいますが)。
本稿の構成は次のようです。第一部「開発体験」では、言語機能からやや独立したエコシステムやツールチェインについて両言語の差異や一致点を議論します。
第二部の「言語機能」では、型システムやモジュールシステム、マクロなどについて両者を比較して、この機能ほしいな〜(両方向)という話をしていきます。
「まとめ」で本当に簡単に要点だけまとめたら、これは株式会社 Jij の Advent Calendar 記事なので、最後に「宣伝」で求人の宣伝をします。
開発体験
IDE/言語サーバ/開発環境について
Rustは最初からエコシステムへの意識があって設計されており、ツールチェインには大変素晴しいものがありますが、開発者がいちばん対面する機会が多いのは Rust の言語サーバ(IDEバックエンド)である Rust Analyzer(以下、RA) でしょう。Haskell にも Haskell Language Server(以下、HLS)があり、結構機能が充実しています(宣伝:私は HLS のContributorです。もう年単位でメンテに噛んでないですが……)が、以下の機能は2024年12月18日時点で Rust Analyzer にしかなく、かなりいいなと思った機能たちです:
-
(サブ)モジュールをQuickfix 経由で作れる
-
mod宣言のエラーから直に Quickfix を呼び出してモジュールファイルが作成できるのはとても便利ですね。 - ただし、Quickfix の Fuzzy Search がしたくて使っている Keyboard Quickfix 拡張から呼び出すとなぜか動かないので悲しい……
-
-
Inlay Hint で型を教えてくれる
- HLS にも次リリースで入るはずですが、(Inlay Hintとは関係のない)幾つかの不具合により次期バージョン 2.10.0.0 のリリースに一ヶ月ちかくかかっているみたいですね……
-
Cross-module rename がデフォルトでちゃんと動く
- HLS も cross-module renaming をサポートしていますが、デフォルトでは opt-out だったり、ロードしていないパッケージには効かなかったりします。ある程度動くのでデフォルトで有効化しちゃってよくない?という議論もあるので、将来はそこそこ動く状態になるんじゃないかと期待しています。
-
個別の単体テストを Code Lens から実行できる
- これはテストが言語機能に織り込まれているが故の Rust のアドバンテージかな、と思います。
- HLS も Eval Plugin を使えば doctest は実行&結果上書きできますが、他の単体テストについてはそもそもライブラリによって単位が違うなどの事情もあり、エディタから個別実行はできません。
-
Task が自動的に検出されてくれる
- 上と関連しますが、各テストが自動で検出されて、VSCode の Task として個別に実行可能なのはけっこう便利
-
cargo buildやcargo clippyなどの Task も自動で検出されるのはありがたい
-
Semantic TokenでMoveが起きている場所がわかる
- 私の彩色の設定だと、move が起きている引数・メソッド呼び出しが太字でハイライトされてくれるので、コードフローがかなりわかりやすくなり快適ですね
- HLS にも構文解析・型推論結果に基づいた Semantic Token のサポートがあり、けっこう助かります。一方で、多重度回りについては Semantic Tokens で区別されていないので、Linear Haskell 向けに linear な引数を区別する機能をそのうちつくってもいいかもしれませんね。
-
複数箇所に起因するエラーを親切に指摘してくれる
- 借用エラーやimplの重複が起きたときに、どこで借用や重複が起きているかなどをマーカで示してくれるので、エラーの原因がわかりやすくて本当にいい
- これも HLS に欲しいですね。実装したい。
一方で、これは言語サーバに限らない Rust への大きな不満点として、Rust には標準のREPL(対話環境)がないという点が挙げられます。
まあ、 evcxr をインストールすればよいのですが、rustc に標準でついてきてほしいですし、cargo で現在の crate の文脈などで簡単に実行できるようになってほしいです。
実装した関数がちゃんと正しく動くかを、テスト以前に手軽に確認したいと思うと、REPLがどうしてもほしくなりますし、他の crate の挙動をパッと確認したいなあと思ったときにも REPL は便利です。
HaskellではGHCが標準的に対話環境である GHCi を提供しており、実は Haskell Language Server も GHC の API を利用して魔改造強化された GHCi として実装されています。
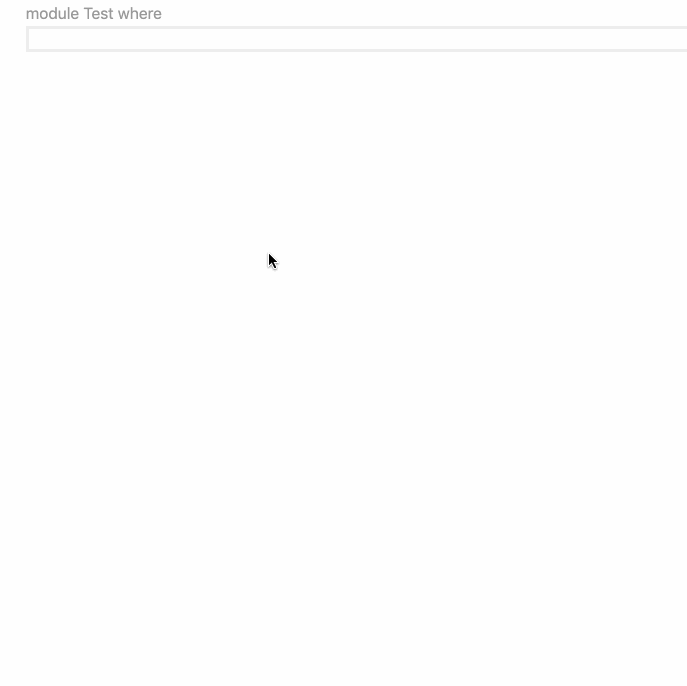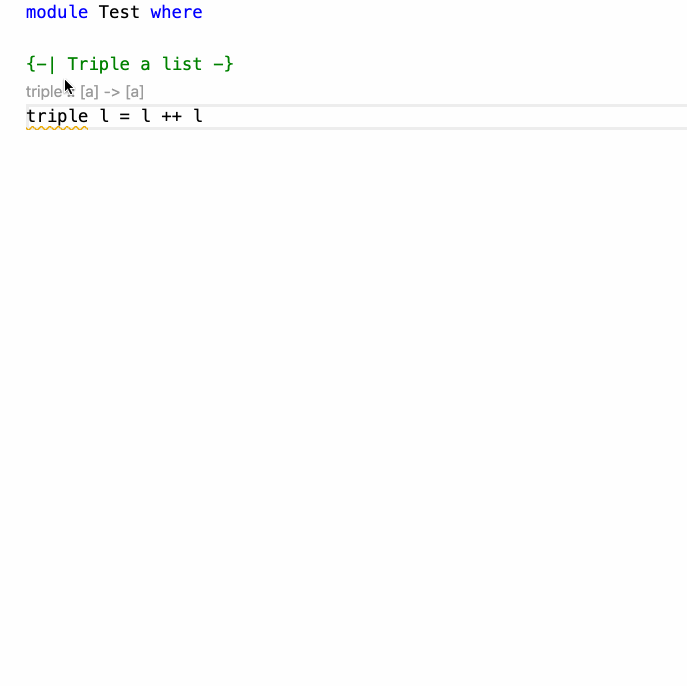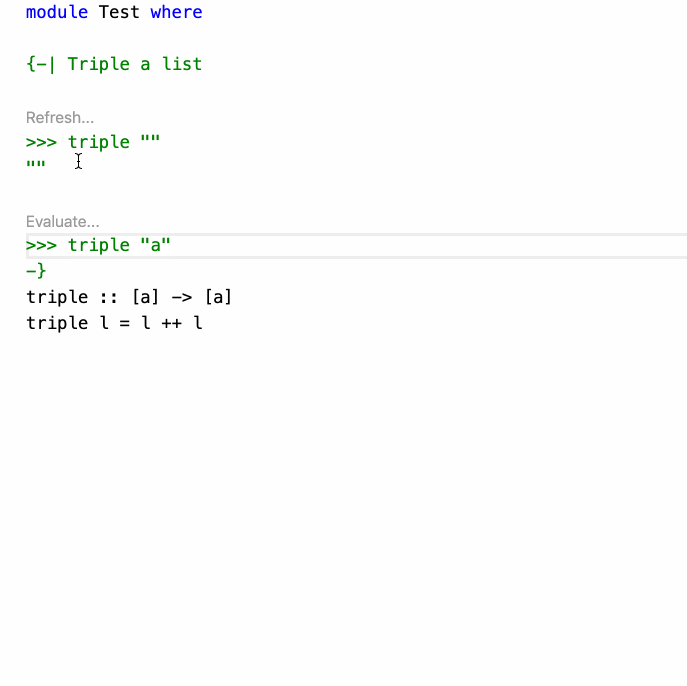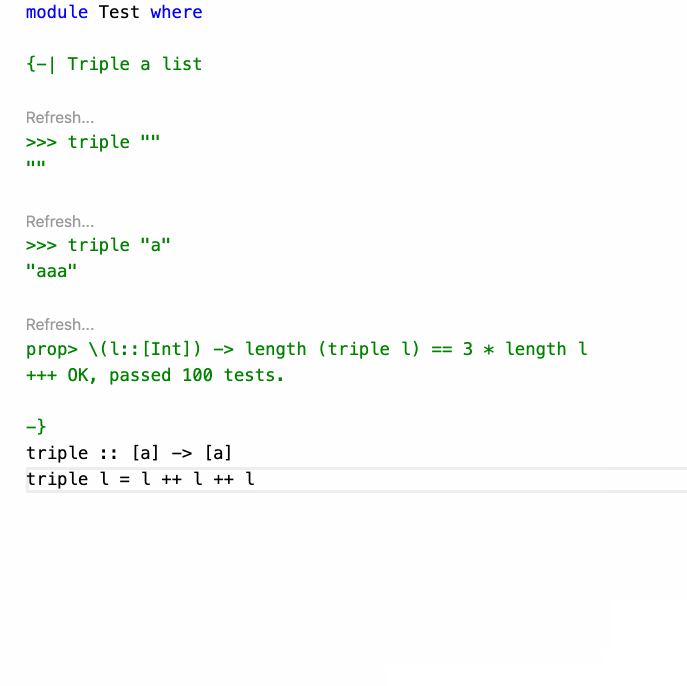
そのため、HLS には Eval プラグインというものが存在し、コードコメント中の >>> code の形の部分を実行して結果を確認できます。これがかなり便利です。
職場の Rustacean に訊いたところ、こういう用途では仕方がないので #[test] 関数を定義して実行するしかないということで、なんとかしてほしいところです。これはRustにも欲しい。
また、Rust Analyzerから Code Lens経由でテストを実行するには crateそのものがコンパイルが通る状態であることが前提になりますが、Haskell の Eval プラグインではそのモジュールが依存するモジュールのコンパイルが通れば動くのも手軽で嬉しい点です[3]。
おそらく、標準的なインタプリタの欠損は、言語サーバのレスポンス速度にも影響していると思います。現在、わたしは主に約3万行の Rust から成る JijModeling の開発に従事していますが、ソースコードを保存してから、Rust Analyzer が結果を報告してくれるまで最大5秒くらい待たされることがよくあり、開発体験としてはかなりしんどいものがあります。
HLSもそこそこ大きなコードベースの扱いに時間がかかるとはいえ、前職では15万行前後の Haskell コードを扱っていてもここまで流石に時間はかかっていなかったと思います(もう離れてしまったので、試せないですが……)。
また、Rust Analyzer は基本的に保存しないと状態が更新されないですが、(設定次第で)HLSは編集中であってもリアルタイムに状態が更新されるようにできるという点があり、この点は Haskell のアドバンテージだと思います。
こうしたパフォーマンス面については、HLSが本質的にはインタプリタ上に構築されたキャッシュつきビルドシステムであり、依存する外部ライブラリ以外はコンパイルせず reload してインタープリトするだけで済んでいることが結構効いているのではないかと思います。
また、HLS等での利用を念頭に、GHCには IDE 向けの情報が保存された .hie インターフェースファイルを出力する機能があったり、情報をオンメモリでキャッシュしていたりしています。こうした点が HLS のパフォーマンス面にも貢献していると思われます。このあたり、Rust Analyzerでも採り入れられる手法はあるのではないかと思います。
聞いた話では、Rust AnalyzerもIDEを念頭にした処理系を構築しようとしているという話もあるようで、このあたり改善していってほしいですね。
ビルドシステムと依存性地獄
まだまだ全然使いこなせていないですが、cargo はかなり色々な項目を設定でき、機能も充実しているようなのでこれから慣れていきたいですね。
build.rs で色々強化可能らしいですが、Haskell でも Cabal で Setup.hs を自由にカスタマイズできたので、この辺りそれぞれ出来ること・出来ないことは比べてみたいところです[4]。
Haskell の標準的なビルドシステムである cabal(と最近はメンテモードに移行している stack)のデフォルトの挙動は Nix-style と呼ばれるモードになっています。これは、プロジェクト毎に(推移的に)依存するパッケージのバージョンを固定した上で、隔離してビルドするものです。一方で、他のプロジェクトで使われた依存パッケージのキャッシュもフラグや最適化レベルなどに応じて自動的に再利用してくれ、極力ストレージやビルド時間が節約できるようになっています。
Cargo によるビルドも、各プロジェクト毎に隔離されてビルドされるのは同様なようで、デフォルトでこの挙動が提供されているのは素晴しいと思います。ただ、ビルドキャッシュ共有自体はsccacheなどを導入する必要があるのは、cabal に甘やかされて育った身からすると、ちょっと引っ掛かりポイントかな、と思いました。
Cabal に甘やかされて育った、といいましたが、実は cabal がマトモになったのはこの五、六年くらいです。詳しくは以前の記事にも書きましたが、かつて Haskell 界は Dependency Hell という地獄に悩まされていました。
掻い摘んでいえば、菱形継承問題の依存関係版です。開発中のパッケージ my-package の依存先に Package A, B があり、更に A も Package B に依存しているとしましょう。
ところが、最近パッケージ B が 1.0 から 2.0 にアップグレードし、A は 2.0 に対応したが my-package はまだ 1.0にしか対応していなかったとします。
my-package と A が B を使っている箇所が完全に内部で完結していて交わらない場合はこれでも動きます。しかし、A と my-package の間で B の提供するインタフェースを介してやりとりがある場合は違う型扱いになってしまいコンパイルに失敗します。これが Dependency Hell です。
かつての Haskell 界隈では同一パッケージの複数バージョンの併存を許しており、しかもライブラリをグローバルで共有していたためこうした問題によく遭遇していました。
これに音を上げた結果、プロジェクトごとにサンドボックス化(=隔離)された環境を用い、各パッケージは単一のバージョンに固定してビルドする手法が Haskell 界隈では定着しました。
前史的には cabal-sandbox などがサンドボックスビルドの先鞭をつけましたが、これらを実用の段階に押し上げたのが stack でした。
Stack を開発した FP Complete の人々は、サンドボックス化に加え、Stackage というものを投入しました。
Stackage には LTS と Nightly という二種類のスナップショットが日々更新されホストされています。ここでいうスナップショットとは、「全てのパッケージが両立してビルドに成功し、一部例外を除いてテストも成功することが保証されたパッケージバージョンおよびコンパイラバージョンのセット」です。
Stackageに一度パッケージを登録すると、毎日 CI/CD により新規パッケージのリリースが監視されるようになり、変更があれば毎夜ビルド&テストが試みられます。同一メジャーバージョンのスナップショットでは同じメジャーバージョン内での更新のみが取り入れられるようになっているので、一度スナップショットのある系列に入れば、Cabal の標準的なバージョニングポリシーである PVP (Rust でいうところの semvar に相当)に従っているかぎり、自動で更新されつつ十分新しいものが使えるようになります。
一方でバージョンアップによりビルドが壊れた場合は通知がパッケージ管理担当者に飛んできますので、常にコミュニティドリヴンで「安全なバージョン集合」が管理される状態が維持されています。
この Stackage の存在が Haskell のエコシステムでは本当に有り難く不可欠なものになっています。
現在、LTSには 3200 あまりのパッケージが登録されており、実用的な必須ライブラリはだいたい登録されているため、固定した snapshot を使っている限りはこれらの依存性の問題に頭を悩ませる必要がないのです。Stackage は stack の開発の過程で出て来ましたが、cabal からでも自由に利用することができます。近年では stack の開発から実質 FP Complete が手を引き有志によるメンテナンスモード状態になっており、一方で cabal は活発に新機能の開発が行われているため、モダンな Haskell プロジェクトは概ね cabal + Stackage 由来の freeze ファイルで依存関係を管理することが主流になっています[5][6]。もちろん、Stackage に登録されていないパッケージが必要になることもありますが、それは手動で freeze ファイルに追加すれば十分で、その結果バージョン制約が合わなくなるようなことは、まあ皆無ではありませんが、おおむね問題なく使えることが多いです。
こういった経緯からの教訓は、以下の記事によくまとまっていますので、気になった方は読んでみるといいでしょう:
さて、手短といいつつ長々と語ってしまいました。おそらく勘のいい人は言わんとすることがわかったと思いますが、こういった経緯を経てきた Haskeller からすると、Rust のビルドシステムまわりの現状はちょっとびっくりします。
というのも、Cargo では同一パッケージの異なるバージョンが推移的な依存先に登場することを許容しているからです。上述のように、これに起因する Dependency Hell または Cabal Hell にかつての Haskeller は散々苦しめられてきました。Rust でも同様の苦しみがありそうなのですが、そういった事象に対する対策は少なくとも Cargo の中では取られていないように見えます。
業務上では、マクロ回りで異なる syn に依存しているパッケージが併存している例を見たことがあります。これは内部で完結していたので問題なく併存できていましたが、共通パッケージを介してデータをやりとりするような例は、上で触れたような地獄が顕現しそうに思えます。
私じしんはまだ遭遇していませんが、事実依存関係の深いところにあるcrateのバージョンアップに伴い、依存関係内で対応ができているcrate・できていないcrateがでてきて、コンパイルに通らなくなってしまった[7]、という話を友人から聞いたことがあります。
それでも現状のまま、ということは、Haskellよりは Dependency Hell に苦しめられづらい何らかの事情があるのかもしれません(そういった背景事情があれば普通に知りたいです)が、まだ問題意識が広く流通していないだけのように思えます。
上のような経緯を踏まえれば、Stackage 相当のものが Rust にも存在していれば、こうした例に先んじて対処できるのではないかと思います。誰かやりませんか?
モノレポの扱い
一方で、Cargo が workspace という形でモノレポの管理機能を提供しているのはよいな、と思います。
Haskellでも、cabal の nix-style build が正にそのあたりを担っていますが、比較してみると以下のような違いがあると思われます:
-
Cargo には依存性の制約を workspace で強制できる機能があるらしい
- モノレポでは互いのパッケージ間に抽象化を破るような依存関係が生えないように腐心する必要があります。
- 前職でもこれが問題になり、依存関係の制約を強制するためのツールを作ったりしました
- Rust.Tokyo で聞いたところでは、Cargo のワークスペース機能では、このあたりを上手く分離する方法があるということで、これは素晴しいと思います。
-
Cargo Workspace では workspace の依存関係制約と個別の crate の依存関係制約が分散して存在している
- Cabal の場合、モノレポのルートにある
cabal.project.freezeファイルの制約が、モノレポ内の全てのパッケージに対して無条件に強制されます。- 各パッケージの定義ファイルでバージョン範囲の制約を記述しますが、これらが矛盾した場合はビルドができなくなります。
- Cargo ではどちらも個別に依存バージョンの制約を記述できるように見える
- workspace ルートの
Cargo.tomlやCargo.lockを優先してビルドするべきな気がするんですが、なんで Rust ではこういう設計になっているんでしょう? - 「workspace で用いるバージョン集合」に関する制約と、「個別の crate が要求するバージョン制約」がごっちゃになって記述される形になっているのが、実はあまりよくないのでは?という気がします。
- workspace ルートの
-
cargo addが workspace に対応していない- かなしい……。
- そもそも
cabalには標準ではcabal addは存在しておらず、コミュニティが開発した拡張コマンドとして存在しているので、cargo 自体は先を進んでいますね。
- Cabal の場合、モノレポのルートにある
モノレポの扱いについてはそれぞれに一長一短がありますが、いずれにせよ依存性まわりについては Rust よりも Haskell の方が整合的な扱いができているように思えます。
Rust の依存性管理がこうなっている経緯と理由をご存知の方がいらっしゃいましたら、ぜひ教えてください。
テスト駆動開発
テストコードと一般コードの混在
Haskellでもテスト駆動開発はメジャーな手法ですが、Rustはテスト環境が cfg アトリビュートとして標準で存在し、条件つきビルドができるというのが特徴的な部分だと思います。
Haskellの場合、ソース内に doctest の形で埋め込むテスト以外は、基本的に同一パッケージの test-suite 型の別コンポーネントとして指定することが一般的で、ビルド/パッケージングシステムのレベルでテストやベンチマークとそれ以外のライブラリ・実行ファイルの区別をします。それに対して、Rustではソースコードの中にテスト時だけコンパイルされる関数やモジュールを置いて渾然一体に管理するのが標準的です。
Rustの方法の利点は、実装とテストコードの位置が近く、プライベートな実装まで踏み込んで単体テストがしやすいというところかなと思います。Haskellの場合、外部利用が想定されない内部実装をテストする場合、doctestを使う以外では次のどちらかの手段を採ることが一般的です:
-
Internalモジュールから外部に露出させる。Haskellの世界では、言語仕様外の規約として、「Internalという名前のモジュールで提供されている物は実装の詳細で頻繁に変わるので依存してはいけないし、インタフェースの安定性は保証しない」という物があり、一般的に広く受け容れられています(HLSもInternalで終わるモジュールはインポート補完の候補から除外します)。 - 実装の詳細は、他パッケージから見えない internal-lib コンポーネントで定義する。internal-lib は stack だとまだちゃんと動かなかったりしますが、cabalでは普通に使えます。internal-lib はデフォルトでは同一パッケージの他コンポーネントからは依存できても、外部パッケージからは依存できません。なので、内部実装を internal-lib に置いておいてテストと公開用ライブラリコンポーネントはそちらを呼び出すようにする、というのは一つの手です。
これに比べれば、Rustはほぼ同一ファイル内でテストを配置できるので、物理的な位置と可視性が両立していてよいと思います。ただ、テスト用の derive が必要なときは、その derive マクロは #[cfg_atrr] ごしに呼び出してやる必要があったり、そのマクロも proptest::prelude::Arbitrary のようにフルにqualifyしてやるか、さもなくば use 宣言に #[cfg] が必要になったりするのがやや面倒くさいですし、Rust Analyzer が条件付き use の判定をわりと雑にやるのがややつらいところです。
また、同一ファイル内にテストを同居させると、ちゃんと考えないとテストコードとロジックが混在してしまって追いづらくなるところがやや気になります。まあ、ファイルを分割すればいいんですが。
性質ベーステスト
Rustの proptest は結構成熟しており手軽に使えるのでよいと思います。
ライブラリの設計としては Python の hypothesis に影響を受けたようで、Haskell世界の性質ベーステストライブラリでいえば QuickCheck よりもどちらかといえば falsify に近い使用感かなと思います。falsify はhypothesisに近いインタフェースを提供しつつ、乱数生成時の分岐を無限木からサンプルることで、より賢いshrinkを実現しているものです。
ただ、proptest に関しては一点不満があり、Haskellの主要な性質ベーステストライブラリでは、テストに用いられたデータの分布をユーザの指定した指標に従って確認する機能がありますが、proptestにはないようです。
この機能はHaskell Advent Calendar 2024 の7日目の takenobu-hs さんの記事でも採り上げられています:
QuickCheckでいえば、label関数やtabulate関数、collect関数、falsifyでいえばlabel関数やcollect関数がそれにあたります。
たとえば、素数判定を行う関数 isPrime があり、その挙動を検査したかったとします。素朴に書くと以下のようになるでしょう:
-- 非負整数 n について、 isPrime がちゃんと素数を判定しているか確認
prop_isPrime :: Word -> Property
prop_isPrime n =
disjoin
[ n <= 1 .&&. not (isPrime n)
, n === 2 .&&. isPrime n
, n > 2 .&&.
((isPrime n .&&. forAll (choose (2, n - 1)) (\k -> n `rem` k =/= 0))
.||.
(not (isPrime n) .&&. disjoin [n `rem` k === 0 | k <- [2..n-1]]))
]
非負整数なので 1 以下なら非素数、2なら素数、2 よりも大きければ「2以上 n - 1 以下の全ての自然数で割れない」かどうかと同値になることをテストしているわけです。
これを実行すれば、以下のようにテスト結果が得られます:
ghci> quickCheck prop_isPrime
+++ OK, passed 100 tests.
しかし、もしかしたら生成される自然数が何らかの理由によって 2 以下のみになっていて、実は三つめの一般の n に対する節が事実上無意味になっている可能性もあります[8]。
そこで、disjoin で場合分けされている三つの節についてどの枝にいるのかわかるようにしてみましょう。
prop_isPrime :: Word -> Property
prop_isPrime n =
disjoin
[ label "n <= 1" $ n <= 1 .&&. counterexample "expected non-prime, but prime!" (not (isPrime n))
, label "n == 2" $ n === 2 .&&. counterexample "Prime expected, non-prime!" (isPrime n)
, label "n > 2" $
n > 2 .&&.
((isPrime n .&&. forAll (choose (2, n - 1)) (\k -> n `rem` k =/= 0))
.||.
(not (isPrime n) .&&. disjoin [n `rem` k === 0 | k <- [2..n-1]]))
]
これを実行すると以下のような結果が得られます:
ghci> quickCheck prop_isPrime
+++ OK, passed 100 tests:
86% n > 2
11% n <= 1
3% n == 2
9割くらいは非自明な例をテストできているみたいですね!
更に、入力の偶奇の分布を知りたかったとします。この時は以下のように tabulate が使えます:
prop_isPrime :: Word -> Property
prop_isPrime n =
tabulate "parity" [if even n then "even" else "odd"] $
disjoin
[ label "n <= 1" $ n <= 1 .&&. counterexample "expected non-prime, but prime!" (not (isPrime n))
, label "n == 2" $ n === 2 .&&. counterexample "Prime expected, non-prime!" (isPrime n)
, label "n > 2" $
n > 2 .&&.
((isPrime n .&&. forAll (choose (2, n - 1)) (\k -> n `rem` k =/= 0))
.||.
(not (isPrime n) .&&. disjoin [n `rem` k === 0 | k <- [2..n-1]]))
]
すると以下のような結果が得られます。
ghci> quickCheck prop_isPrime
+++ OK, passed 100 tests:
86% n > 2
7% n <= 1
7% n == 2
parity (100 in total):
58% even
42% odd
概ね偶奇等しくテストできているようですね。今回は入力ごとにラベルを貼りましたが、ラベルの生成は任意の式を渡すことができるので、たとえば何か二つの数を入力にとるテストについて、その大小関係の分布を確認する、というようなこともできます。
また、ドキュメント改めて見るまで気づいていなかったんですが、各分岐が何%出現することが望ましいかを指定するcover関数も存在しているみたいです。
今回は単なる整数の一様乱数生成器を使っているのであんまり怖いことは起きそうにないですが、複雑なデータを生成する自前のジェネレータを実装して使っていたりする場合は、このように適切なデータをテストできているか確認するのは非常に重要です。
この機能は、性質ベーステストの初出である QuickCheck の原論文で既に必要性が説かれているもので、テストの実効性を保証する上で大事なものなのです。いちおうhypothesisでも event 関数を使えば限定的ながら似たことは実現できそうなので、proptest でも出来てほしいなと思います。折角なので、余裕があればこれを実現するための proc_macro でもそのうち書こうかなと思います。
また、性質ベーステストの入力をランダム生成ではなくサイズについて小さい順に網羅的に列挙して、小さな反例を探そうとする SmallCheck のような亜種もあります。このように、性質データの生成をどういう戦略(proptest の strategy の意味ではなく、乱数vs列挙の意味)でするのかも選べると、道が開けそうな気がします。まあとはいえ、これはHaskell界隈でもあんまり実用されている印象がないので、そこまで必須ではないですが。
外部ファイルに依存したテストツリーの生成
ただ、Rustがモジュール&関数としてテストを表現することによる弊害として、外部ファイルに依存してテストツリーを生成することが難しいという点があります。
例として、たとえば重複も込めて素因数分解を行う関数 primeFactors がちゃんと動くかテストしたかったとします。ランダムなテストとは別に、過去に失敗したケースを外部ファイルに個別に保存してあって、そいつらに対するリグレッションテストも行いたかったとしましょう。
Haskellではあくまでもテストは関数として表現されることになるので、以下のように素直に書くことができます:
-- テストとして実行されるメイン関数
main :: IO ()
main = do
inputs <- getDirectoryFiles ("data" </> "tests") ["*.dat"]
defaultMain $ testPrimeFactors inputs
-- 重複を込めて素因数分解する関数
primeFactors :: Int -> [Int]
primeFactors = {- ... -}
-- 素数判定
isPrime :: Int -> Bool
-- | 何か数値を入力として取ってそれに関して
isPrimeFactorsValid :: Int -> Bool
isPrimeFactorsValid n = n ==
let ps = primeFactors n
in product ps && all isPrime ps
testPrimeFactors :: [FilePath] -> TestTree
testPrimeFactors inputs =
testGroup "Tests"
[ testProperty "random test" $ isPrimeFactorValid
, testGroup "regression test"
[ testCase fp do
n <- read <$> readFile fp
assertBool $ isPrimeFactorsValid n
| fp <- inputs
]
]
この例だとあんまり外部ファイルに保存する必要はなく、リストの形でコード内に埋め込めばよいですが、もうちょっと複雑かつ大量なケースになってくると、個別のファイルに分けたくなります。
こういう例としては、以前Haskellで書いたSATソルバをRust に移植した際の例があります。
このディレクトリには、SATソルバベンチマークライブラリSATLIBから持ってきたデータが1000セット保存されており、各データは20変数・100節ほどの充足可能な論理式です。さすがにこれ全部をコード内に埋め込むのはキツいと思ってもらえるのではないかと思います。
これら全てを入力としてSATソルバの挙動を独立にテストするHaskellコードが次です:
一方、Rustではしょうがないので現状では一つの関数の中でglobして片っ端からデータを取ってきて一つ一つ処理しています。
こうすると、失敗した時に残りのケースの結果をテストできないのが辛いところで、たぶんちゃんとやろうと思うとproc_macroを書くことになるんでしょう。まあ、書けばいいんですが、こういう割と手軽にできたいところでproc_macroなり、プリプロセッサでコード生成をしてやったりする必要があるのは、ちょっと隔靴掻痒の感があります。
テストに関してはこんなところです。
Hoogle がほしい
これは、後で触れる認知負荷の話にも関連してきますが、Haskell には Hoogle という定番のサービスがあり、名前からだけでなく、(多相な)型シグネチャから関数を探すことができます:
これはかなりなくてはならないもので、「こんな関数あるかな〜」と思ったらまず型で検索をする、ということを Haskeller は習慣的にやっています。
Rust だと「Result と Option の順番を交換したい……」とか思ってもドキュメントと首っぴきになるしかなく、悲しいところがあります。仕方がないのでガーッと探して transpose であることがわかるわけですが、なかなか厳しい
Rust ではMonadや Traversable などの統一的な抽象化がないので、「似てるやつは似てる名前をつける」というヒューリスティックな命名規則でふんわり対処しているところがあり、個別の関数を探す手間が Haskell よりも高いから、絶対この需要はある筈だと思うんですよね……。
言語機能
パッケージングシステム
パッケージングについてはツールチェインとも関わってきますし、Haskell の場合言語機能と呼ぶには外部化されているのでここに置いてよいのか迷いましたが、モジュールシステムと関連して言及したかったので、こちらの節で触れます。
Haskellでは標準的なパッケージ記述言語は Cabal と呼ばれる形式です[9]。Cabalでは、一つのパッケージは以下の複数のコンポーネントからなります:
-
libraryコンポーネント:他パッケージから参照可能なメインライブラリ。パッケージ毎に高々1つ。 -
名前つき
libraryコンポーネント:最近の Cabal から使えるようになった、メイン以外の付随的なライブラリコンポーネント。デフォルトでは外部パッケージから利用できないが、設定次第で外部から参照可能にもできる。任意個。 -
executableコンポーネント:ユーザが利用する実行ファイルに相当するもの。任意個指定可能。 -
benchmarkコンポーネント:ベンチマークスイート。任意個指定可能。 -
testコンポーネント:テストスイート。任意個持てる。
いずれのコンポーネントも、依存するパッケージ・他コンポーネントが公開しているインタフェースのみを使うことができます。
Cabalファイルでは、共通のメタデータ以外は基本的にコンポーネントごとに設定を行います。特に、コンポーネントごとにソースディレクトリやモジュールの一覧を宣言します。ライブラリのルートモジュールのようなものはありませんし、実行ファイルのMainに相当するファイルも陽に指定することになります。
また、コンパイラフラグや依存パッケージ制約もコンポーネント毎に指定します。全部個別に設定するのは大変なので、common スタンザと import 宣言を使うことで複数コンポーネント間で共通する設定項目を共有することもできます。
対して、Cargo では Cargo.toml でパッケージ(crate)の情報を記述します。Cabalファイルは完全に独自の構文を持つ設定言語ですが、Cargo.toml は TOML なので言語と無関係な標準的なツールチェインの支援を受けられることはかなりの利点です。
Cargo では各crateは以下の要素から成ります:
-
lib: メインライブラリ。高々一つ。デフォルトのルートモジュールはsrc/lib.rsで、lib節が存在しない場合もsrc/lib.rsが存在すればライブラリが存在しているものとして扱われます。もちろん、陽にlibを指定して、ルートモジュールを変更することもできます。 -
bin: 実行ファイル。任意個指定可能。src/main.rsが存在すれば、それが crate と同じ名称の実行ファイルの定義として扱われます。パブリックなインタフェースしか利用可能ではない。 -
example:examples以下に置かれたファイル群はライブラリの使用例を表すものとして扱われます。実行ファイルとしてインストールされることはありませんが、何も指定しない場合は特別な実行ファイルとして記述することになるようです。パブリックなインタフェースしか利用可能ではない。 -
test: テストスイート。任意個指定可能。単体テストは基本的にライブラリ内に併置するスタイルで、もっぱら結合テストがtests以下に配置されるようです。パブリックなインタフェースしか利用可能ではない。 -
bench: ベンチマークスイート。任意個指定可能。benches以下に通常置かれる。ベンチはライブラリのプライベートなインタフェースも利用可能。
こうして比較してみると、cabal では全てのコンポーネントを陽に指定するためパッケージの構成要素の情報は .cabal ファイルを見れば完全に決定できるところ、Cargoの場合はファイルシステムを見ないと確定しない要素があることになります。パッケージ記述者からすると記述をサボれるのは嬉しいですが、情報を処理する時にファイルシステムをクエリする必要があるのはちょっと面倒じゃないかな、という気もします。まあ良し悪しでしょうか。
また、Cargo ではコンポーネントの種類毎にメインライブラリの非公開インタフェースをどこまで使えるかが変わってくるのが面白いなと思いました。単体テストは内部で書かれているから test で非公開を触れる必要がない一方、ベンチは内部の細かい部品を計測したいので内部まで触れるほうがよい、ということなのでしょう。とはいえ、ちょっと ad-hoc に制限が決まっているように見えますし、この辺りも cabal のようにコンポーネント毎に visibility をいじって、実装者が制御できるようにしたほうが汎用的な気もします。
モジュールシステム
パッケージングの節でも見たように、Rust のモジュールシステムと Haskell のモジュールは結構毛色が違います。
Rust ではライブラリは単一のルートモジュールとして指定され、サブモジュールは各モジュール内で mod 宣言を与える形で宣言します。また、ファイルとモジュールは一対一に対応しているわけではなく、単一ファイル内でモジュール階層をネストして定義することができます[10]。これは、単体テストに tests モジュールを使うプラクティスでも頻繁に使われているものですね。
一方で、Haskellのモジュールは基本的にファイルと一対一に紐付いているものです[11]。Hoge/Fuga/Bar/Buz.hs はモジュール Hoge.Fuga.Bar.Buz に対応します。先述の通り、パッケージの各コンポーネントに所属するモジュールは Cabal ファイルで宣言する必要があるので、宣言された各モジュールに対応するファイルをソースディレクトリに配置するのはプログラマの責務になります。
また、Rust の場合はモジュール階層の途中に位置する全てのサブモジュールが存在する(hoge::fuga::bar というモジュールが存在するなら、hoge::fugaも hoge も必ず存在する)のに対して、Haskellはモジュール成分の途中までのものは存在するとは限らないのも特徴です。このように、Rustではプログラム内でモジュール階層を定義するのに対して、Haskellでは個別のモジュール自体は一個のファイルで定義するが階層はプログラム外・パッケージ側で定義する、という考え方の違いがあります。
特に、Rust ではモジュールのエントリポイントはその crate に一対一で紐付いており、違うcrateの提供するモジュール名が衝突することはありません。対して、Haskellではモジュール全体の名前空間はパッケージ毎には分離されておらず、異なるパッケージ間でモジュール名が衝突し得ます。Haskellではこうした状況に対処するために PackageImports という機能拡張を提供しており、import "package-a" Data.Module などと書くことでどのパッケージのモジュールかを明確化することができますが、後手感はあります。こうした点では crate ごとにモジュールの名前空間がわかれている Rust はスマートだなと感じます。
また、外部からモジュールが呼び出せるかどうかは、Rustの場合は mod 宣言に pub をつけるかどうかで決まりますが、Haskell の場合は当該モジュールが Cabal で exposed-modules と other-modules のどちらにリストされているかで決まります。
また、個別モジュールから何を外部に露出して、何を秘匿するのか、という点についても、両者では考え方に差があります。
Haskell ではモジュールの先頭に export リストを与えて、そこで露出する型・関数・構築子などを指定する形になっています(省略する場合はすべて露出)。対する Rust では型や関数、トレイトごとに(どこまで)露出するかを指定する流儀です。
こうしたモジュール階層や可視性の指定の仕方の違いは、Rustではマクロでモジュールを動的に生成できるという点に端的に現れていると思います。
Haskellの場合、マクロはあくまでも単一モジュール(のスプライスグループ)毎に実行されますが、モジュール内でモジュールを宣言することはできないので、動的にモジュールを生成しようと思うと、マクロでなくプリプロセッサなどを使うことになります。また、マクロによって生成された定義をモジュール外部に露出しようと思うと、Rustの場合は局所的に pubなどをつければよいのに対し、2024年現在の Haskell では export リストをマクロで制御する方法はありません。マクロとの相性を考えると、モジュール階層をあるていど自由に定義できる Rust に軍配が上がる気がします。
一方で、モジュールそのものの「変換」という観点では、RustよりもHaskellがやや進んでいる面もあります。Rust はファイル内で自由にモジュール階層を定義できてもモジュールそのものを対象として扱うようなことはできせんが、Haskell(というかGHC)には最近[12] Backpackという機能が入り、モジュールを(メタレベルで)対象として扱うことができるようになりました。
これは、OCamlなどではファンクタ[13]と呼ばれるモジュール間の関数をHaskellでも真似しようというものです(なので、実際には ML 族の言語のほうが Haskell よりも遥かに進んでいるといえます)。これは、概念的には、「適当な仕様を満たすモジュールを引数にとって新しいモジュールを返すような高階のモジュールを定義できる」というものです。具体的には以下のように使うものです:
- 「適当な仕様」を形式化したシグネチャファイル(
Hoge.hsig)を定義する- 実装を省いた関数の型シグネチャや型名だけを含むモジュールもどき
- Cabalファイル側で、シグネチャに対してそのインタフェースを実装した具体的なモジュールを指定する
- すると、依存するシグネチャが具体実装で置き換えられた残りのモジュール群が降ってくる
- 複数実装を与えることもでき、具体化したものごとに名前を変えて提供することもできる。
詳しい使い方は説明しませんが、百年くらい前に書いた手前味噌として、「有限列」を表すシグネチャを受け取って、それを使って型レベルの長さつき列を返すような例が以下にあります:
直接的には関数ではありませんが、実質的にシグネチャを介して、モジュールの変換関数のようなものが実現できているのがわかると思います[14]。せっかくモジュールがコード内で扱えるのであれば、Rust でも似たようなことが出来るとよいのにな、と思います。とはいえ、実は Haskell は純粋言語なので考えるべきことが少なくなっているところがあり、型レベルで副作用が分離されていない OCaml などの ML 族の言語でファンクタをしっかり定式化しようとすると、色々な種類の定式化を考える必要がある、ということが知られています。Rustに入れようと思うとまずはこのあたりをちゃんと考える必要がありそうです。
また、Rustではモジュールを循環的に use しあうことが出来る(モジュール A と B が互いに use しあえる)のも特徴的だと思います。Haskellでは基本的に相互 importはできず、どうしても必要になった場合は .hs-boot ファイルというものを用意し、相手への循環参照が必要ないものだけを置いておいて tie-breaking する、という手間が必要になります。正直17年書いてきて hs-boot を書いたことは一度もなく、これは「相互 import が必要な時点で抽象化が破れていて何かがおかしいのでは?」という思想でコードを書いてき、これを回避する方法を蓄積してきたのも影響していると思います。
Rust の場合、先日業務上相互 use をしたくなったことがありましたが、抽象化を見直して回避しました。実際のところ、Rustで循環的な use ってどのくらい許容されているんでしょうか?識者の意見が気になるところです。
マクロ
Haskell には Template Haskell というマクロシステムがあります。Haskellでコード生成というと広く括れば Template Haskell 以外にも Generic Deriving / DerivingVia、プリプロセッサやソースプラグインなど幾つかの選択肢がありますが、ここではマクロということで対象は Template Haskell に絞ります。これは自慢なんですが、私は Template Haskell に関する日本語のブログ記事を書いた最初期の人間で、有り難いことに未だに「Template Haskell は konn さんの記事で勉強しました!」といって頂くことがあります。といっても書いたのは 2011 年のようで、なんか移行にミスって記事自体は消滅しちゃってるみたいですね(ウケる)。2020年のはてなグループの消滅に巻き込まれたみたいなので、これを見て勉強した人はそこそこの古参と言えると思います。Web Archive には残っていたので以下にサルベージしましたが、さすがに13年前(13年前!?!?!)の記事ということで古くなっているところもあるので、全体的な雰囲気の話を把むにとどめておくのがよいと思います。
閑話休題。Template Haskellでは、各構文要素ごとに抽象構文木(AST)があり、それを関数・データ型の情報収集や外部との入出力ができる Q モナド 内で切り貼りする、という形式になっています。直接 AST を弄るのはバージョン間で壊れたりすることがあるので、[|let x = $(macro) in x + x|] のように通常の式の形で書いてその中に合成した文を埋め込むこともできます。また、近年は式のASTには型つきのものが登場し、限定的ながらも型安全性にある程度配慮したマクロが組めるようになっています。
とはいえ、同一ファイル内のマクロを呼び出すことができなかったり、多段階のマクロ展開が型レベルで区別できなかったりと、まだまだ発展途上です。
一方で、Rust には proc macro と declarative macro という二つのマクロ機構があるようです。
proc macro はまだ書いていないですが、declarative macroは現職の最初の週から早速つかいました。パターンマッチで書けるのでかなり手軽でいいと思います(ちょっとメンテナンスがしづらいですが……)。
また、derive やアトリビュートをマクロでガシガシ書いてコード生成をさせていくのが Rust のスタイルになっているのも面白いと思います。
一方で、二種類のマクロが存在する弊害として、Rustのマクロ展開時順が予測不能になる場合があるというのが挙げられると思います。
これは決して重箱の隅をつついているのではなくて、業務上書いていて実際に遭遇した問題です。以下、何が起きたのか説明します。先にいっておくと、実際に何が起きたのかは現在に至るまで判明しておらず、また苦労して追っても仕方ないだろうということで現在は別の方法を採っています。
前提として、弊社では Python 向けライブラリを PyO3 を使って Rust で開発しています。
PyO3 では proc_macro で実装された種々のアトリビュートを使って、Python での表現やメソッドなどを表現します。また、Pyright などで使われる型情報の stub ファイルは、弊社のてらモスさんが開発した pyo3-stub-gen を使って生成し、これもアトリビュートを使います。
たとえば、 mod_a と mod_b から、同名の hoge という名前の関数を提供したかったとします:
#[gen_stub_pyfunction(module = "mod_a")]
#[pyfunction(name="hoge")]
fn hoge_a() -> PyAny {
// ...
}
#[gen_stub_pyfunction(module = "mod_b")]
#[pyfunction(name="hoge")]
fn hoge_b() -> PyAny {
// ...
}
// lib.rs で hoge_a, hoge_b を mod_a, mod_b に hoge という名前で追加するコードも書いておく
hoge だけならいいですが、さらに fuga, moke, piyo なども同様に mod_a, mod_b から提供したかったとします。
一々手で書くのは大変なので、それ用のマクロを定義しましょう。
use paste::paste;
macro_rules! define_funs {
($name:literal) => {paste!{ define_funs!{$name, [<$name _a>], [<$name _b>]}}},
($name:literal, $a_name:ident, $b_name:ident) => {
#[gen_stub_pyfunction(module = "mod_a")]
#[pyfunction(name=$name)]
fn $a_name() -> PyAny {
format!("{} from A", $name).into_py()
}
#[gen_stub_pyfunction(module = "mod_b")]
#[pyfunction(name=$name)]
fn $b_name() -> PyAny {
format!("{} from B", $name).into_py()
}
},
}
呼ぶと hoge from A や fuga from B などの Python 文字列が返る関数を定義したいつもりです(実際にはもっと複雑な型レベルや値の変換などが挟まるので単純化しています)。
ここでもちょっとかなしかったのは、与えた "hoge" などの文字列を切り貼りして関数名を創る機能がdecl macroに標準でなかったことです。今回は、paste crate に依存することで解決しました。
Template Haskell では、受け取った文字列を操作して識別子に変換することもできますし、逆に識別子からモジュール名や生の名前を取り出すこともできるので、標準でどうとでもできます。一方、Rust の declarative macro でこうした操作をする標準的な仕組みはないようで、paste のような外部クレートに依存しないといけないのが悲しいところです。
ともあれ、これを使ってこんな感じで定義してみましょう:
define_funs!("hoge");
define_funs!("fuga");
define_funs!("moke");
define_funs!("piyo");
これでコンパイルは通りましたが、生成された stub ファイルでは、関数名がどちらも hoge でないといけないところ、hoge_a や hoge_bのままになっている、という問題が発生しました。
どこかでマクロ書きまちがえたかな?と思い、試しに hoge のマクロをRust Analyzer でマクロを一段階ずつ展開させていくと、期待通りの結果が得られます:
#[gen_stub_pyfunction(module = "mod_a")]
#[pyfunction(name="hoge")]
fn hoge_a() -> PyAny {
format!("{} from A", "hoge").into_py()
}
#[gen_stub_pyfunction(module = "mod_b")]
#[pyfunction(name="hoge")]
fn hoge_b() -> PyAny {
format!("{} from B", "hoge").into_py()
}
そして、展開後の状態でコンパイルすると、Python側の関数名も期待通りのものになっていました。
一方で、cargo expand で全てのマクロを展開させた結果を見てみると、stub ファイルの生成に使いそうな部分の値が、確かに異なっていることが確認できたのです。
もうこの時点でこれは闇が深そうだな……という雰囲気がしてきたので、同じ名前空間に違う関数で生やすのを諦め、mod_a, mod_b に対応するモジュールを別々に生成させて、どちらも指定した hoge, fuga などの名前で直接定義することで回避しました。今回はこのように機能する回避策がみつかったのでよかったですが、マクロ同士が絡むマクロを書くと予想外の挙動を示すというのはなんとかなってほしいところです。変なことをしようとしたわけではなく、割と素直に書いてこういう挙動をされるとちょっとつらいものがあります。
Haskellではコンパイラに -ddump-splices というオプションがあり、マクロ展開の様子などを見ることができますし、そもそも一種類しかマクロがないのもあり、展開順に悩まされるということはありません(というか、derive や構文要素へのアノテーションはマクロとは別のレイヤで行われており、Haskellのマクロで多段階のマクロを書くような機会があまりない、というのが適切かもしれません)。
このような挙動を示したときに、簡単にデバッグできればいいのですが、 Rust Analyzer vs rustc/cargo-expand で挙動が違うとなるともうどうしていいのかわからないので、Rust のマクロの挙動をデバッグするもっと実践的な方法が欲しいなと思います。というか、もっと予測可能な挙動をしめしてくれればいいんですが……。誰か Rust に予測可能なマクロシステムを入れてください!
まあ、そもそも Haskell の型付 Template Haskell にしても、多段階計算を適切に扱うことができるような型システムを備えているわけでもなく、まだまだ発展途上です。多段階計算のリッチな型システムを備えた研究用言語はいくつか見当たりますが、Haskell や Rust のような既に実用されている言語にそうしたシステムを組み込んでいくような取り組みが、今後もっとされていくといいなと思います。LISP族なんかは構文木とソースコードが同型なので、多分 Racket とかが色々やってるんだろうと思う[要出典]ので、そのへんも参考にしていきたいですね。
enum, struct と 代数的データ型
既に多くの人がいっていることだと思いますが、struct と enum の組み合わせで代数的データ型(ADT)をエミュレートできるので、非常に書き味がよいです。Cの構造体と列挙型を睨みつつ、ADTに近づけた按配がかなりいいです。
再帰型の定義には Box や Arc などを噛ませる必要がありますが、これは Haskell でも(UnliftedDatatypes などを使わない限り)コンパイラが自動で裏側でやっていることで、Rust はそこを人間に書かせることで、「並行処理しないしここは Box でいいや」「並行処理するから Arc にしておこう」などと判断することができるので、これは見方によっては利点と言えるでしょう。
再帰節を Box に包むのも、.into() で変換するか、再帰を含む構築子向けのスマートコンストラクタを予め用意しておけばあまり煩雑ではありません。
上で書いたように、現職では数理最適化向けEDSLの開発をしているので、日常的に抽象構文木と戯れます。enum と struct と Box を組み合わせて ADT を再現できるので、このあたりの違和感はほとんどなく、これが C や C++ だったらもっと大変だったろうなと日々思っています。
また、Haskell を片目で見て設計されているので、enum の列挙子や struct のフィールドの名前空間もかなり良い感じです。私は Haskell は宇宙で最も理想的な言語だと考えているのですが、レコードのフィールドと直和型のコンストラクタの扱いについては完全に失敗していると思っています。特に、Haskellでは同一モジュール内で同名のフィールドや構築子を持つ別の型を気持ち良く扱えない点に忸怩たる思いを日々抱いています。
レコードフィールドの扱いについては、Lensという手法が発明されてくれたおかげで、最近色々な進展が見られます。重複を許すようにしたり、ドット記法でアクセスしたりする形を採ることで改善しつつありますが、それでもまだまだ道半ばです。特に、重複フィールドの曖昧性解消については、型情報から解決する機構を消そうという話もあったり、かなり混乱しています。最終的には HasField 型クラスを経由したドット記法でアクセスする形が支配的になるのかなと思いますが、フィールド更新については「多相レコードのフィールドを同時にアップデートする」をどう表現するかはまだ2024年時点で未解決で、混迷を極めているといってよいです。
直和型に至っては、Lensの双対とも言える Prism で大分扱いやすくなったとしても、同一モジュール内で同じ名前の構築子は共存できるようにはならないでしょう。
一方Rustでは、構造体のフィールドは型さえはっきりしていれば問題なくアクセス・更新できます。まあ、これは多相レコードアップデートがそもそもないからすっきりしている面もあるかもしれません。enum については、Rust では enum の型ごとに名前空間が区切られるので、そもそも同一モジュール内で構築子が被ることがなく、かなり気分がよいです。
Rust での型レベルプログラミング
Haskell で型レベルプログラミングをする上では、一般化代数的データ型(GADTs)と型族(Type Family)を縦横無尽に扱います。GADTs は、データ構築子によって型パラメータを変更できる機能で、たとえば、以下のような「型付き抽象構文木」を定義できます:
data Expr a where
IntC :: Int -> Expr Int
BoolC :: Bool -> Expr Bool
Var :: String -> Expr a
Neg :: Expr Int -> Expr Int
(:+:) :: Expr Int -> Expr Int -> Expr Int
(:*:) :: Expr Int -> Expr Int -> Expr Int
Not :: Expr Bool -> Expr Bool
(:&&:) :: Expr Bool -> Expr Bool -> Expr Bool
(:||:) :: Expr Bool -> Expr Bool -> Expr Bool
(:==:) :: Expr a -> Expr a -> Expr Bool
If :: Expr Bool -> Expr a -> Expr a -> Expr a
Expr a は、「a 型の式を表す抽象構文木」の気持ちです。特に、この言語では値は Int または Bool の値を取ることを想定しており、IntC や BoolC によって即値を定数として埋め込むことができます。Int と Bool どちらの値を取るかが型パラメータで区別されていることの嬉しさは、たとえば「(:+:) は Int 同士の式にしか使えない」「If 文の第1引数はBool値で、then と else 節は同じ型でなければならない」といった制約を型レベルで強制できることです。言い換えれば、型エラーになるような式を表現できないようにできることが嬉しいのです。また、GHCの網羅性検査はかなり賢く、マッチされている式の型に基づいて「ありえない」マッチ候補を除外してくれます。たとえば Expr Int 型の値にパターンマッチした場合、(:==:), (:||:), (:&&:), Not へのマッチは一切要求されなくなります。
Rust には現状、このような機能はありません。無理矢理実現するためのトリックはいくつかあるようで、ファントム型を持つ構築子を持たせておいてそのコンストラクタを秘匿し、スマートコンストラクタのみ提供するなどが考えられるようです。しかし、この手法では「不正な式を表現できなくする」は達成できても、「不要なマッチを網羅性検査から省く」は達成できないので、あくまでも部分的な解でしかありません。
他方、Haskell の型族は型レベルの関数のようなものです。いってしまえば、型に対するパターンマッチや再帰が出来るものになります。たとえば、次は型レベルで階乗を計算するものです:
type Factorial :: Nat -> Nat
type family Factorial n where
Factorial 0 = 1
Factorial n = n * Factorial (n - 1)
型族は上のように単体で宣言することもできれば、型クラスのメンバとして宣言することもでき、後者は関連型(Associated Type)と呼ばれます。
Rust には単純な型族はないようですが、trait に付随する Associated Type はまんまそのものですね。言語処理系を実装する上でこの機能が使えると何が嬉しいかというと、Trees That Grow という手法が使えるようになります。
これは GHC が内部実装でも使っているもので、一言でいうと、言語処理系の様々なフェーズで使われる抽象構文木の実装を拡張可能性を保ったまま共有できるものです。
たとえば、プログラムをパーズする段階では、各部分式には型註釈があるとは限らず、型を表すフィールドは Maybe Type などにしておきたいでしょう。一方で、パーズされた構文木を型検査した後の結果では、全ての部分式に型がついていてほしく、ここでは Type になっていてほしいです。また、パーズ前では生の文字列で識別子を表していても、名前解決フェーズ後には一意化された識別子を表す別の型で表現されていてほしいでしょう。脱糖したらなくなるような構文要素は、脱糖後にはコンストラクタの一覧から消えていてほしいです。
こうした状況を型族を使って解決するのが Trees That Grow です。フェーズを表すダミーの型をそれぞれ用意し、それをパラメータに持つ「部分式の型の情報を表す型」「識別子を表す型」の型族を定義しておいて、単一のAST定義ではそこで呼ぶようにするわけです。また、ASTの構築子に「各フェーズで追加的に必要になるフィールド」を入れるための拡張フィールドを用意しておけば、後から付加的な情報を増やしたりできますし、また脱糖で消える構文要素を消したい場合は、空の enum Void {} を言れておけば、脱糖後のフェーズには構築子が現れなくなります。Rust は never type 自体は安定化されていませんが、空 enum は自在に定義でき、網羅性判定も「空なのでマッチしなくてヨシ!」と判断してくれるので、期待通りの挙動が実現できます。
更に、少し前までは Rust の Associated Types は総称パラメータを持てなかったようですが、最近 GATs (Haskeller 向けの註:GADTs とは全然違います)が安定化され、事実上型パラメータを取れる型族を定義できるようになりました。
これの嬉しさとして、Haskell の Rank-1 多相を模倣できる、という点があります。周知の通り、Haskeller は Functor? とか Monad? とかいうよくわからない抽象化をフルに使ってコードを書きます。この定式化がそのまま使える、ということになるので、Haskeller としては今すごくテンションが上がっています(詳細はMonadの節で説明します)。
Functorに興味がなくても、言語処理系を書く上でも嬉しい点があります。それは、ADTに対する再帰スキームが Rust でも抽象化できることです[15]。これは、再帰的に定義されたデータ型を、一段階剥してやってボトムアップに値を畳み込んでいったり、逆に値を構築したりする方法です。流石に長くなりすぎたので詳細には触れませんが、たとえば、算術式の eval はこんな感じで実装できます:
再帰スキームをつかった eval の実装例
use std::ops::{Add, Mul};
pub trait Language: Sized {
type Layer<T>;
fn fmap<T, S, F>(f: F, layer: Self::Layer<T>) -> Self::Layer<S>
where
F: FnMut(T) -> S;
fn wrap(layer: Self::Layer<Self>) -> Self;
fn unwrap(self) -> Self::Layer<Self>;
fn fold<T, F>(self, f: &mut F) -> T
where
F: FnMut(Self::Layer<T>) -> T,
{
let ft = Self::fmap(|me| me.fold(f), self.unwrap());
f(ft)
}
}
#[derive(Debug, Clone, PartialEq, Eq, PartialOrd, Ord)]
pub enum Expr {
Int(i64),
Var(String),
Add(Box<Expr>, Box<Expr>),
Mul(Box<Expr>, Box<Expr>),
}
#[derive(Debug, Clone, PartialEq, Eq, PartialOrd, Ord)]
pub enum ExprF<T> {
Int(i64),
Var(String),
Add(T, T),
Mul(T, T),
}
impl Add for Expr {
type Output = Self;
fn add(self, other: Self) -> Self {
Expr::Add(self.into(), other.into())
}
}
impl Mul for Expr {
type Output = Self;
fn mul(self, other: Self) -> Self {
Expr::Mul(self.into(), other.into())
}
}
impl From<&str> for Expr {
fn from(s: &str) -> Self {
Self::Var(s.to_string())
}
}
impl From<String> for Expr {
fn from(s: String) -> Self {
s.as_str().into()
}
}
impl From<i64> for Expr {
fn from(n: i64) -> Self {
Self::Int(n)
}
}
impl Language for Expr {
type Layer<T> = ExprF<T>;
fn fmap<T, S, F>(mut f: F, layer: Self::Layer<T>) -> Self::Layer<S>
where
F: FnMut(T) -> S,
{
match layer {
ExprF::Int(n) => ExprF::Int(n),
ExprF::Var(s) => ExprF::Var(s),
ExprF::Add(a, b) => ExprF::Add(f(a), f(b)),
ExprF::Mul(a, b) => ExprF::Mul(f(a), f(b)),
}
}
fn wrap(layer: Self::Layer<Self>) -> Self {
match layer {
ExprF::Int(n) => Expr::Int(n),
ExprF::Var(s) => Expr::Var(s),
ExprF::Add(a, b) => a + b,
ExprF::Mul(a, b) => a * b,
}
}
fn unwrap(self) -> Self::Layer<Self> {
match self {
Expr::Int(n) => ExprF::Int(n),
Expr::Var(s) => ExprF::Var(s),
Expr::Add(a, b) => ExprF::Add(*a, *b),
Expr::Mul(a, b) => ExprF::Mul(*a, *b),
}
}
}
impl Expr {
pub fn eval(self) -> Result<i64, Self> {
self.fold(&mut |layer| match layer {
ExprF::Int(n) => Ok(n),
ExprF::Var(s) => Err(Expr::Var(s)),
ExprF::Add(Ok(a), Ok(b)) => Ok(a + b),
ExprF::Add(a, b) => {
Err(a.map_or_else(|e| e, Expr::from) + b.map_or_else(|e| e, Expr::from))
}
ExprF::Mul(Ok(a), Ok(b)) => Ok(a * b),
ExprF::Mul(a, b) => {
Err(a.map_or_else(|e| e, Expr::from) * b.map_or_else(|e| e, Expr::from))
}
})
}
}
#[cfg(test)]
mod tests {
use super::*;
use test_case::test_case;
#[test_case(Expr::from(1) + 2.into(), 3; "1 + 2 = 3")]
fn test_closed(expr: Expr, result: i64) {
assert_eq!(expr.eval(), Ok(result));
}
#[test_case(Expr::from(1) + 2.into(), Ok(3); "1 + 2 = 3")]
#[test_case((Expr::from(1) + 2.into()) * "x".into(), Err(Expr::from(3) * "x".into()); "(1 + 2) x = 3x")]
fn test_any(expr: Expr, result: Result<i64, Expr>) {
assert_eq!(expr.eval(), result);
}
}
Monadください WOW WOW Monadください do:Rust の try_ とか ? とか、認知負荷高すぎないですか?
というわけで Rust における ? 記法と、モナド/do 式まわりの話をします。
周知の通り、Haskeller は Functor? とか Monad? とかいうよくわからない抽象化をフルに使ってコードを書きます。実はよくわからない抽象化ではない、という話をしていきます。
Functor, Applicative, Monad などはその代表例として存在くらいは有名でしょう。小難しく聞こえますが、それぞれ map, zip, and_then をサポートしているデータ構造・制御構造 に対応しています。Rust を書いているのであれば、イテレータやエラー処理でこうした関数を沢山チェインして書いたりすることがあると思います。モナド則などとよばれるのは、これらが「それっぽく」動くための前提条件を述べているもので、ライブラリを実装する人間が保証してくれるので、実は利用者は最初のうちはあんまり気にする必要はありません[16]。
Monad が何か、についてはあんまりここで説明するつもりはないですが、百年くらい前に「Monad は喩えだけで理解してはいけない」という記事を書いたので、良かったら読んでください。
ここでは、上のモナドの意味についての話はやめておいて、コードを書く認知負荷とモナドなどの定式化の話をしたいと思います。
Rust でコードを書く上でとても辛いのが、Result や Option に包まれた値の扱いです。私は Haskell の人間なので、これらが沢山使われていることの偉さは身に沁みてわかるのですが、これらの構文的な扱いは実のところかなり ad-hoc で場当たり的に感じ、「これやりたいんだけど……」と思い浮かんだ用途の関数を探したり覚えておくのに非常に苦労します。具体的には以下のような苦しみを感じます:
-
?が使えるかどうかがブロック全体の構造に依存しておりつらい- たとえば、「途中までは Option で値を処理するけど、最後は Result にする」とか、「Result で返ってきた値を適切に処理して Option にして返す」みたいな時に、最終的にブロックが返す値でないと
?が使えないのはかなり不便です。 -
?がどこのブロックに掛かっているのか次第で、Option で early return されると途中まで確保したリソースを確保する必要が出ないか不安になる
- たとえば、「途中までは Option で値を処理するけど、最後は Result にする」とか、「Result で返ってきた値を適切に処理して Option にして返す」みたいな時に、最終的にブロックが返す値でないと
- 全ての関数ごとに
try_の亜種があるか探さないといけないし、ない場合の対処がつらすぎる-
try_collectはitertoolsにしかないし、しかも Result にしか対応していない -
Optionにも使いたいし、TryでないEitherにも使いたくなる場面があります。
-
- メソッドチェーンで
.map().and_then().or_else().or_else().try_collect()?とかやってると何をしてるのかわからなくなる - 型クラスで十分な抽象化がなされていないので、型の組み合わせごとに関数を探す必要がある
- どういう名前かの候補が複数あるし、二つの型が絡むなら都合二箇所を調べる事になるので探すのが手間
- Hoogle のような型から関数を探せるのがあればまだマシなんですが……
- 最初のうちはマジでわからなくて目茶苦茶苦労したし、今でも苦労してます。
- 最初のうちはかなりえびちゃんに教えてもらいました、ありがとう🙏
- 一番最近は
Option<Result<T, E>>をResult<Option<T>, E>にしたくて、目を皿にして探し漸くtransposeを見付けるなどした
- パターンマッチと条件判定による early return がしづらい
Hoogle があれば見付かる系を除けば、以下の三点に集約されます:
- あらゆる型の組合せ毎に別々のよく似た、しかし時々違う振る舞いをする関数があり、認知負荷が高い
- 「条件つきの逐次実行」が書きづらい
- 構文に対する意味論が場当たり的に与えられているので、使いづらい言語機能がある
こうした痛し痒しは、実のところ Rust がパラメータ多相を欠き、したがって「逐次実行っぽい」「順番の入れ換えっぽい」などの共通の性質を抽出し損ねて場当たり的な構文や気合いで解決していることに起因していると考えています。
たとえば、 Applicative は「(条件分岐を含まない)逐次実行」(zip)、Monad は「前の値に依存した逐次実行」「条件分岐を含む逐次実行」(and_then)に相当するということです[17]。
これらの代表的な例として、IO や Maybe, Either などがあります。また、Maybe や Either などは「失敗・Fallbackをサポートする型」のクラスである Alternative のインスタンスでもあり、また IO と Maybeは「パターンマッチの失敗」による early return をサポートする MonadFail のインスタンスでもあります。
また、これらを「制御構造」のクラスだと見做したとき、Applicative と双対を成す「データ構造」のクラスとして Foldable と Traversable があります。前者は Rust でいえば into_iter() と try_fold() をサポートする型、後者は更に「int_iter().map(_).collect() および int_iter().map(_).try_collect()」をサポートしているような型です。たとえば、Set は Foldable ですし、リストや HashMap などが Traversable となるような代表的な例です。また、Maybe や Either もデータ構造として見ると「値を高々一個保持する」ものだと思えるので、Traversableのインスタンスになっています。
そして、Traversable は次のように定義されています:
class (Foldable t, Functor t) => Traversable t where
traverse :: Applicative f => (a -> f b) -> t a -> f (t b)
sequenceA :: Applicative f => t (f a) -> f (t a)
t が Traversable であるようなコンテナを表す型パラメータで、Vec<-> や HashMap<K, -> などが想定されます(- は「ここに何か入るよ」という気持ちです)。
traverse は歴史的経緯で mapM とも呼ばれていますが、この名前で見るとなるほどこれは「f という効果を伴いながら、map をすることができる」事を要求しています。Option にあたる Maybe には Applicative の構造が入り、ざっくり Vec に辺りリストは Traversable なので、これは .into_iter().collect() ないし into_iter().try_collect() に対応していそうです。
これを念頭に置いて今度は sequenceA の型を見てみると、これは「コンテナの中に入った副作用を外にくくりだす」と読めます。今度は Maybe が Traversable, Either が Applicative であったことを考えれば、これは私が見付けたくて仕方がなかった transpose 関数に相当しているではないですか[18]!また、into_iter().map() と try_collect() を切り離して考えて、 t = Vec, s = Result<-, E> だと思えば、sequenceA は try_collect() のようなものだとも思うことができます。
このように、現状の Rust では「これは失敗っぽいから try_ をつけて……えーっと Option<Result<-, E>> の Result を外に出すのは collect... じゃだめでえーと transpose か……」などと考えていたのが、Applicative / Traversable というレンズを通してみることで「ここは効果つきの map だから traverse だな。こっちは Result と Option を入れ換えてるから seuqnceA ね」と簡単に類推できるのです。また、 Traversable の親クラスである Foldable には foldrM :: Monad m => (a -> b -> m b) -> t a -> m b などもあり、これは try_fold の一般化になっています。
ここではよくでてくる try_ を例に出しましたが、これらは別段失敗しそうな計算である必要はなく、「大域的な設定を参照しながら計算をすすめる」Reader モナドなどに対しても問題なく使えるのです。また、これまで挙げた例以外では、たとえば proptest でサイズパラメータを減らしながら構文木のデータ生成を行いたい場合、BoxedStrategy をモナドのようだと思えば、prop_map や prop_flat_map も fmap や and_then だと思うことができるので、prop_compose マクロを使わずに do 式で対応できるようになるでしょう。
もちろん、関数の名前を覚えておかないといけないのは、これらの型クラスが使えた場合でも同様です。しかし、Rustでは「えーとこれ try_ つけた奴はあったっけな……」「collect……は高々一個だからちょっと違うか……?」などと一瞬考えてドキュメントを引く作業が挟まることになります。もちろん、慣れていく内に組み合わせは脳内にキャッシュされていくでしょう。しかし、Rust のこうした関数は Iterator かどうかとか、個別の実装ごとに微妙に挙動が違ったりしますし、新しいライブラリに依存するたびに「try_ っぽいのはあるか……?」とか探しにいく必要があります。パラメータ多相と型クラスによる実装があれば、「こいつは Traversable かな?」「Applicative ってことは動的な条件判定はできないんだな」などと一瞬確認するだけで欲しい情報が確定し、あとは最初に覚えた関数を使っていつも通りにプログラムを書くことができるわけです。これが、「モナドは実は認知負荷に効く」という主張です。勿論、「高度な抽象化はちょっと……」という面では認知負荷の心配はあるかもしれませんが、パターンを覚えるようなもので、使い方を覚えてしまえばあとはずっと使える、というのは嬉しいことだと思います[19]。また、厳密には Monad や Foldable にはならなくても、それに似た構造を持つ場合は似たような名前で関数を提供することで、使う側もイディオマティックに理解することができるでしょう。
「メソッドチェーンは便利だがつらい」「構文が場当たり的」という話も、Monad や Applicative があれば解決します。おそらく、Monad を使うための do 式というのがある、というのは Haskell の噂で聞いたことがある人もいるでしょう。実際、Rust にも do 式っぽいものを使えるようにする crate が幾つかあるようです。
do はいってしまえば「逐次実行っぽいものを、and_then() と let のチェーンに書き換える」構文糖衣です。
一個の式の中では一つのモナドを使うことになりますが、意味論は do の中で完結するので、「Either を返すけど途中に Option に ? を使いたい」みたいな局面でも問題なく共存できます。GHC の ApplicativeDo 拡張を使えば、モナドだけではなく Applicative、つまり「and_then を使わず map と zip だけで書ける」処理に対しても do を使うことができます。また、GHC 9 系ではQualifiedDo という言語拡張をつかうと、「Applicative または モナドっぽい構造」に対しても do-式を使うことができるので、なんなら途中で型がかわるようなものも書けます。
時間がないのでかなり人工的な例ですが、次のような処理を考えます[20]:
- 変数から値への割り当てマップと、変数を表す文字列の列が与えられる。
- 変数が不正だったり、割り当てられていなけばその旨エラーを返して終わり
- 値が全て奇数であれば、和を取って返す。
- 偶数かそもそも整数でない値が一つでもあれば、処理自体は成功するが
None(をOkに包んで)返す
Rust で書くと、たとえば以下のようになるでしょう:
fn sum_odds_with(adds: HashMap<Var, Value>, exprs: Vec<String>) -> Result<Option<i64>, String>{
let vals = exprs.into_iter().map(|var|
Ok(assignments.get(&expr.parse::<Var>()?).ok_or(format!("Unbound variable: {:?}", var)))
).try_collect::<_, _, anyhow::Err>()?;
let odds = vals.into_iter().flat_map(|v|
if let Int(i) = v if i % 2 == 1 {
Some(i)
} else {
None
}
).collect::<Option<Vec<i64>>();
Ok(odds.into_iter().sum())
}
たぶんがんばれば iter 一回だけで行けるとは思いますが、そうなるとどこで try_ を呼ぶとか ? をつけるとかワケがわからなくなるので、ここでは何回かに分けています。
見通しは悪くはないですが、良くはないですね……。Haskell ならこのように書きます。
sumOddsWith :: HashMap Var Value -> [String] -> Either String (Maybe Int)
sumOddsWith assign exprs = do
-- 熟達した Haskeller なら、ここは `(<=<)`を使って一行で書くでしょう。
vals <- forM exprs \e -> do
v <- parse e
fromMaybe (Left $ "Unbound variable: " <> v) $ lookup v assign
let odds = forM vals \v -> do
Int i <- pure v
guard (i `rem` 2 == 1)
pure i
pure (fmap sum odds)
forM は mapM ないし traverse の引数を入れ換えたものです。慣れないと目がすべるかもしれませんが、ほとんど同じ流れで失敗しうる計算を複数混ぜているのがわかると思います。また、pure は Some(-) や Ok(-) などに当るものです。
oddsのところの do は Maybe について、残りは Either についての do 式です。
<- が Rust の .and_then に当るものになっています。普通の変数束縛と <- を混ぜてつかうことで、.and_then をチェインせずにあたかも普通のプログラムのように書けているのがわかると思います。束縛時にパターンマッチがつかえるのは、 Maybe が MondFail だからです。
guard は、「与えられた式が真なら Some(()) そうでなければ None」というようなものです。ここでは条件式は一つだけですが、この先さらにパターンマッチと if 文が積み重なっていったとき、途中で分岐が挟まってしまうと Rust では結構つらくなりますが、Haskell では MonadFail の構造と guard、そして適宜 Alternative の構造を使ってやることでかなり(少なくとも私には)見通しよく書けます。
こうした do 式は、.and_then() っぽい演算が生えていれば基本的に使えるものになります。上の do クレートは何とか(ランク1の)trait の範囲で頑張ってやろうとしているようです。Rust での型レベルプログラミングに書いたように、GATs を使えば Rust でもパラメトリックな Monad などの定式化を真似ることができそうです。以下のレポジトリでその実験をしています:
たとえば、Functor の例を採り上げてみましょう。Haskell での Functor の定義は以下のようになっています:
class Functor f where
fmap :: (a -> b) -> f a -> f b
ここで大事なのは、インスタンス実装対象である型 f は関数定義で引数 a をとっていること、つまり単なる型ではなく、「型引数を一つとって型を返す」ようなものになっていることです。このような型に対する多相性をパラメトリック多相とかRank-1 多相とかいいます。
Rust で型クラスに対応するのは trait ですが、残念ながら、総称パラメータが完全適用された単一の型しかトレイトを実装できません。しかし、GATs では関連型が総称引数を取れるので、以下のような形で定義ができます:
pub trait Functor {
type Container<T>;
fn fmap<T, S, F>(f: F, carrier: Self::Container<T>) -> Self::Container<S>
where
F: Fn(T) -> S;
}
enum OptionFunctor {}
impl Functor for OptionFunctor {
type Container<T> = Option<T>;
fn fmap<T, S, F>(f: F, carrier: Option<T>) -> Option<S>
where
F: Fn(T) -> S,
{
match carrier {
Some(x) => Some(f(x)),
None => None,
}
}
}
enum VecFunctor {}
impl Functor for VecFunctor {
type Container<T> = Vec<T>;
fn fmap<T, S, F>(f: F, carrier: Vec<T>) -> Vec<S>
where
F: Fn(T) -> S,
{
carrier.into_iter().map(f).collect()
}
}
つまり、Option や Vec などに対して直接 Functor trait を実装するのではなく、実装を表すダミーの型 OptionFunctor や VecFunctor などを用意して、その GAT として本丸のコンテナを与えて各制御構造を実装すればいいのです!
ダミー型を使うことの利点は、Haskell の場合 Functor のインスタンスは最後の型パラメータについて多相的である必要があります。
たとえば、Either e a (Rustでいう Result<A, E>)を考えてみましょう。Either は(実際には双函手なので)二通りの Functor の構造が入り得ます。一つは e の方をマップするもの、もういっこは a の方をマップするものです。Haskellでは Functor のインスタンスは「型を受け取って型を返す」ものである必要があるため、Functor インスタンスは a についてのものしか実装できません。一方、このダミー型の方法では、ResultFunctor と ResultErrorFunctor の二つを用意して、前者は A を後者は E をマップする(それぞれ Result::map と Option::map_err に対応)ものを共存させることができます。
ところで、実は Functor の階層はHaskellの線型型の文脈では Data Functor と Control Functor という二つの Functor 概念に分裂することがしられています。これは map などに渡す関数が Fn なのか FnOnce なのかの違いで、データ構造らしく振る舞うものと制御構造らしく振る舞うのかがかわってくる、という知見です。Haskell では、前述の QualifiedDo 拡張を使うことで、こうした Linear なモナドに対しても do 式を使えるようになっいます。
そして、色々いじっている内に、このあたりの Linear Haskell の知見を Rust にフィードバックすることで、Rust に do 式を入れる上でかなりよい指標になってくるのでは!?という事に気付き、今いろいろと実験しています。
簡単にいうと、Linear Haskell では消費回数が「きっかり一回」でなくてはならないため、Maybe や Either は Linear Control Monad にはなりません。一方で、Rust の場合は「高々一回」消費されればよいので、対応する Option や Result は Affine Control Monad になります。どういうことかといえば、ここでスケッチしたような Control Monad に基づいた do 式を Rust で使うことができれば、上の Haskell のような形で Option や Result の処理を do で書けるようになるということです。このあたりのことを実証するために、さしあたりは QualifiedDo の Rust 版マクロを実装しようとたくらんでいるところです。
所有権とライフタイム、線型型(アファイン型)関連
なんでこいつへの言及がこんなに後なんだ、という感じですが、なんといっても Rust の偉いところは線型型に由来する所有権の概念を、ライフタイムやムーブセマンティクスと組み合わせることで、安全かつ効率的で何により実用的ななプログラムを書ける、という事を実証した点です。これは本当に偉すぎると思います。
論理学者の Girard が1980年代に線型論理を提唱し、それを見た計算機科学者が「リソース管理に敏感な型システムの構築に使えるのでは!?」と気付いて以来、線型型システムの研究は永年続けられてきましたが、それを産業的な要求に応える形で実用的に解決したのが本当に偉いです。
余りにも偉いので、はっきりと Rust からの影響を受けて最近 Haskell にも線型型が入りました。これについては、以下の二つの記事でけっこうしっかりと採り上げたので、そっちを読んでください。
上の記事でも触れましたが、Rust の所有権システムは、リソースは「高々一回」消費されればよい「アファイン型」であるのに対して、Haskellでは「きっかり一回」消費されることを要求される「線型型」のシステムが入っているという点が異なります。この「消費回数」制限のことを多重度(multiplicity)といいますが、Rust では多重度は所有権という形で値そのものの制約として管理されている一方、Haskellでは関数の型の矢印 -> に関する制約として導入されている点で、両者は双対のような形になっています。
いずれにせよ、このあたりは本当に Rust から盗むべきことが沢山あるなあという感じです。さしあたりは、参照カウントを使って GC されないメモリ管理を Haskell で自由に使えるようにしたり、FFIで渡ってきた他言語のリソース(Cライブラリや、WASM/JSバックエンドにおけるJSのオブジェクトなど)を管理するのに使ったりしていきたいですね。
特に、Haskell と Rust の間の FFI をやっている人達はぼちぼちいますが、線型型を使っているひとは(前見た時は)みつけられなかったので、ここにこそ使ってきたいという気持ちもあります。
上の記事で予告したように、Haskell も Linear Constraintsが入ることで Rust の所有権システムをさらに柔軟化したようなものが、型制約を介してエミュレートできるようになる予定です(2024年12月18日時点で最後のレビューが行われています)。このあたり、お互いの成功・失敗をみつつ、Haskell と Rust の間でよいフィードバック・ループが回るといいなと思います。
卑近な例だと、Rust でブロックごとの lifetime 変数を束縛する方法ってないと思うんですが、このあたりできるようになると、色々 lifetime を明示できていいのなあと思ったりします。
また、所有権と密接に関連する事項として、Rust では不変・可変参照が型レベルで & vs &mut という形で区別されているという点があります。
これはかなり偉い分離で、Rust の成功の一端を担っている重要な事項だと思いますが、このために get と get_mut、iter と iter_mut など、一部属性を取得するような関数に全て不変版と可変版が別々に定義されているのが、ちょっと面倒です。
でもじゃあどうやって区別するの?という気持ちになりますが、Haskell ではこういった場合多相性を使って対処するのが常套手段です。
Rustにも(総称性だけではない)多相性はあり、たとえばlifetime変数が挙げられます。
たとえば、lifetime 変数 'a を真似てこんどは ''a みたいな「可変性変数」を導入し、こんな風に書けたらいいのになという気持ちです:
struct Hoge { field1: usize, field2: String }
impl Hoge {
fn get_field1<''mode>(&<''mode> self) -> &'_ <''mode> usize {
self.field1
}
fn get_field2<''mode>(&<''mode> self) -> &'_ <''mode> String {
self.field2
}
}
記法はかなり苦しいので考える必要がありますが、 ''mode が可変性変数で、 mut または readonly (現状ではそんなものはない)などを渡り、&'a <''mode> はそれぞれ ''mode = mut のときは &'a mut を、 ''mode = readonly のときは &'a を指すようにしてほしい、という感じです。
Haskell では可変性の多相性についてはこれから Linear Constraints が入ってから(ライブラリレベルで)定式化が色々考えらる事になると思いますが、線型型に絡むところだと、関数の多重度に関する多相性があります。先述の通り、Linear Haskell では線型性は関数の性質なので、関数の型として a -> b と a %1-> b の二種類があり、後者が「a をきっかり一回消費する[21]」線型な関数の型になります。これらは別々の型ではなく、次のように定義されています:
type a %m-> b
type a -> b = a %Many-> b
type a %1-> b = a %One-> b
つまり、関数矢印が多重度 m を多相的に取るようになっていて、m が Many なら普通の関数、Oneなら線型な関数を指すという定式化になっています。このため、たとえば、Haskell で頻出な ($) や (.) の「多重度多相版」が次のように定義できたりします[22]:
($$) :: (a %m -> b) %1 -> a %m -> b
f $$ x = f x
(.:) :: (b %m -> c) %1 -> (a %m -> b) %m -> a %m -> c
(f .: g) x = f (g x)
この他にも、多重度について多相な IOモナドなども定義でき、色々な実装を共有することができます。こうした線型性の「使い勝手」を向上させる多相性が、もっと Rust にも入ってほしいなと思います。
インスタンス導出と newtype
derive マクロは直接 Haskell の deriving 機構に影響を受けていて、かなり便利です。
Haskell (というか GHC)のインスタンス導出機構は(Template Haskell やコンパイラプラグインによる物を除くと)以下の三つの「戦略」があります:
-
ストック: Haskell言語標準やGHCがデフォルトで提供している導出可能なインスタンスの導出(
Eq,Ord,Show,Read,Generic,Functor,Foldable,Traversableなど)。 -
DeriveAnyClass:InstanceSigsつきのデフォルト実装を持つ任意の型クラスのインスタンスを導出できる機能。 -
GeneralisedNewtypeDeriving(GND) /DerivingVia: 後述する、zero-cost type-safe coercion を使って既存の実装を安全に共有して新たなインスタンスを導出する方法。
大昔はストックとGNDしかなかったため、「stock でないものは全部 newtype と解釈する」という方針でしたが、後に DeriveAnyClass が入ったときに newtype が優先される仕様だったため混乱が起き、現在では DerivingStrategies 言語拡張を指定して、次のように陽に[23]戦略を指定させるのがベストプラクティスになっています(ストック以外の戦略を使うと警告が出るようになったはずです):
data MyGreatType = MyGreatType [Int] (Maybe String)
deriving stock (Show, Eq, Ord) -- ストック導出
deriving anyclass (ToJSON, FromJSON) -- DeriveAnyClass
deriving (Semigroup, Monoid) via Generically MyGreatType -- DerivingVia
newtype MyGreateNewtype = MyGreatNewtype Int
deriving stock (Show, Eq, Ord) -- ストック導出
deriving newtype (ToJSON, FromJSON) -- GND
deriving (Semigroup, Monoid) via Sum Int -- DerivingVia
あるいは、StandaloneDeriving を使って次のようにすることができます:
deriving stock instance Show MyGreatNewtype
deriving anyclass instance ToJSON MyGreatType
deriving via Sum Int instance Semigroup (Sum Int)
Stock deriving については、言語標準仕様で定められているものだけでなく、先述の GADTs に対しても適切に文脈を補完してインスタンスの導出ができるようになっています。ただ、システマティックに仕様が決まっている関係上、型族が絡んでくると次のように StandaloneDeriving で親制約を陽に指定してやる必要がでてきて、ちょっと面倒です:
type family ConstExt phase
type family AddExt phase
type family ExprExt phase
data Expr phase = ConstInt Int (ConstExt phase)
| Add (Expr phase) (Expr phase) (AddExt phase)
| ExprExt phase
-- このようには書けない:
-- deriving Show
deriving stock instance
( Show (ConstExt phase)
, Show (AddExt phase)
, Show (ExprExt phase)
) => Show (Expr phase)
一方で、Rust のビルトインの derive マクロでは、Associated Types が絡んできてもこうした親クラス制約(Rust の場合はトレイト境界)を書かなくて済むので楽な場合が多いですね。一方で、時々本来 phantom で必要のない型にまで制約を要求してきた例に遭遇した事もあります(ちょっとすぐ実例は思い出せないですが、Default まわりで業務上遭遇した記憶があります……)。あと、あくまでも derive に渡すのはマクロの名前であり、渡した名前と実装されるトレイトが一対一に対応する訳ではない、というのも、ちょっとマクロの中で何が定義されているのか勘違いしやすいので、極力は分けてほしいなあ、という気持ちがあります。
次の項目に移りましょう。Haskell の DeriveAnyClass は、上で書いた通りデフォルト型註釈つき実装を持つ任意の型クラスの実装を導出できるものです。
概ね Rust の derive インスタンスと実現したい方向は似ていますが、derive マクロはあくまでもマクロがコードを生成するのに対して、DeriveAnyClass では、型クラスが「どういう時に導出できるか」を表すデフォルトの型制約と共に実装を持っているという違いがあります。
このデフォルト制約・実装は自由ですが、多くの場合は GHC の Generics 機能を使って実装されることが多いです。
これに対して、GeneralisedNewtypeDeriving と DerivingVia は、Rust でもよくつかわれている newtype を介して、インスタンス実装の共有をするという機能です。
これについては、以下の五年以上前のスライドで詳しく説明しているので、気になったら是非読んでやってください:
簡単に言えば、直接 newtype で包まれた関係になくても内部表現が同じ型の間のインスタンス実装を共有できるのが DerivingVia で、GeneralisedNewtypeDeriving はそれを直接の newtype に制限したものです[24]。GHC には type-safe coercion という概念があり、簡単に言えば、内部表現が同じ型同士を安全にゼロコストで一気に coerce できるというものです[25]。この機能はかなり便利で、例えば単純な型だけではなく、関数や任意の代数的データ型まで一気に coerce することができます:
{-# LANGUAGE TypeApplications #-}
import Data.Coerce
newtype Id = Id Int
newtype IdList = IdList [Id]
shiftIds :: Int -> IdList -> IdList
shiftIds n = coerce @([Int] -> [Int]) (map (+ n))
DerivingVia は同じ表現が与えられた時に、この coercion を通じて自動的にインスタンスを導出してくれる機構です。
上の例とはまた違った例では、Haskell の DerivingVia は「あるトレイト/型クラスの実装から別のトレイトの実装を導出する」という用途にも使えます。いま、整数と真偽値に関する簡単な式の型 Expr と、その評価結果の値を表す型 Value があって、種々の型を Expr などに変換したかったとします。
このとき、A: Into<Value> (これは Rust では Value: From<A> から自動的に導出されます)から Expr: From<A> を実装するのが次の(実際には動かない)例です[26]:
/// 評価後の値を表す型
enum Value {
Int(i64),
Bool(bool),
}
/// 種々の型の [`Value`] への変換を先に実装する
impl From<bool> for Value {
fn from(b: bool) -> Self {
Value::Bool(b)
}
}
impl From<i64> for Value {
fn from(i: i64) -> Self {
Value::Int(i)
}
}
impl From<i32> for Value {
fn from(i: i64) -> Self {
Value::Int(i as i64)
}
}
impl From<u32> for Value {
fn from(i: i64) -> Self {
Value::Int(i as i64)
}
}
/// 簡単な算術式の型
enum Expr {
Int(i64),
Bool(bool),
Add(Box<Expr>, Box<Expr>),
Sub(Box<Expr>, Box<Expr>),
Mul(Box<Expr>, Box<Expr>),
IsZero(Box<Expr>),
And(Box<Expr>, Box<Expr>),
Not(Box<Expr>),
If(Box<Expr>, Box<Expr>, Box<Expr>),
}
/// Value は Expr にそのまま変換できる
impl From<Value> for Expr {
fn from(value: Value) -> Self {
match value {
Value::Int(i) => Expr::Int(i),
Value::Bool(b) => Expr::Bool(b),
}
}
}
/// Into<Value> インスタンスを Into<Expr> に変換するための newtype ラッパ
struct WrapIntoValue<T>(T);
impl<T: Into<Value>> From<WrapIntoValue<T>> for Expr {
fn from(v: T) -> Self {
<T as Into<Value>>::into(v).into()
}
}
/// 存在しない、「架空の」 DerivingVia宣言
impl From<bool> for Expr via WrapIntoValue<bool>;
impl From<i64> for Expr via WrapIntoValue<i64>;
impl From<i32> for Expr via WrapIntoValue<i32>;
impl From<u32> for Expr via WrapIntoValue<u32>;
Rust では newtype パターンはよく使われていても、このようにnewtype 元の実装を共有する標準機能はないので、ちょっと何とかなってほしいところです。DerivingViaを部分的に模倣する crate を書いてくださっている方がいらしたので、業務ではこちらをところどころ使っています。
Deref の制約解消の機能などを使って頑張っているようです(詳細は追えていません)。ホワイトリスト形式で内部表現との From, Into を導出できたり、IntoIterator や二項演算を導出できるようになっており、有り難く使わせて頂いております。とはいえ、Haskell の DerivingVia を知っていると、やはりホワイトリスト形式ではなく、任意の trait を DerivingVia できるようになってほしいところです。
とはいえ、「表現が同じなら実装を共有する」とだけ言うと簡単に聞こえますが、実は型パラメータが phantom なのか、表現だけ気にしているのか、それとも完全に同じ型でないとだめか、という点に気をつけないと任意の型を別の型に変換できて不健全になってしまうので、GHC では role という概念を導入することで健全性を保っています。真面目にやろうと思うと Rust 向けの role システムを考えることなりそうですし、誰かそういう論文を書いてほしいところです(他力本願)。
型システム、他の雑感
もう十分長くなってしまったので、かなり大事だと思いつつも項を立てるほどでもない型まわりの雑感を以下に書いておきます。
- 部分式に型註釈を書きたい
- 主に
into()の結果が曖昧なときなどに「注釈書いて!」といわれますが、into自体はジェネリックパラメータを取らないので、<usize as Into<Expr>>::into(12) + Expr::Var("x")とかExpr::from(12) + Expr::Var("x")とか書かないといけないのがつらいです - Haskell みたいに
(12.into() : Expr) + "x".into(): Exprとか書けたらいいんですが……
- 主に
-
#[non_exhaustive]便利なのかそうでないのかよくわからない……- Rust では将来フィールドや enum の列挙子が増える可能性があるとき、
#[non_exhaustive]をつけることでパターンマッチのデフォルトフィールドを強制したり、直接コンストラクタを呼べなくしたりすることができる - 将来の拡張性を考えると妥当ですが、そうすると値の構築やパターンマッチがかなり煩雑になってしまう
- Haskell ではこういう場合、フィールドへの
Lensや、列挙子のPrism(まとめて Optics という)を提供するのがプラクティスになっている-
Lens: フィールドアクセサと更新関数の組 -
Prism: 構築子へのパターンマッチ関数(成功すれば Ok、そうでなければ Err)と、引数をとって構築子を適用する関数の組
-
- これらは適切に畳み込みに使えたりもするので、Rust でも似たようなものがほしいですね……
- optics 系のライブラリはあるようですが、なんか最近更新されているものはなさそう……
-
PrismはFoldやTraveresalと組み合わせてコンポーザブルにパーザを書くのに使えたりするので、言語処理の観点でもあったらうれしい- 最低限、
matches!マクロで、パターン中の変数を Option に包んで返してくれるものがあればあるていど十分かも(そのうちやるか)
- 最低限、
- Haskell ではこういう場合、フィールドへの
- Rust では将来フィールドや enum の列挙子が増える可能性があるとき、
- Beautiful Folding がほしい
-
Iterator は便利ですが、畳み込みつつ map もするとか、複数の指標を畳み込む、みたいなことをしたいと、結局
for-ループになってしまう -
Haskell には beautiful folding というパターンがあって、複数の畳み込みを一個にまとめることができる道具がある
-
これの Rust 版がほしいですね
-
Itertools::teeとかを適宜呼べばいいが、あんまり考えずにやりたい - Clone とかも適宜必要になると思うので、そこは考えていく必要がある
-
-
まとめ
いちゃもんではなくちゃんと気持ちをわかってもらおうと思ってあれもこれもと書いているうちに、完全に取り留めのない書き散らしになってしまいました。
斜め読みして、どこか持ち帰ってもらえたらいいなと思います。
いいとこどりしよう、以上に特にメインの主張があるわけではないですが、切実に感じているのは以下です(理由は上や過去記事を読んでね)
- Rust のツールチェーンはかなりいい
- 機能面の充実がすごい。モジュールの作成や Semantic Token による move の図示など
- パフォーマンスが改善されてくれたら言うことなし
- 所有権とライフタイムすばらしい
- Linear Haskell に盗みたい
- proptest に生成データの統計機能がほしい
- Rust は型で名前空間がわかれているので、Haskell の名前衝突の悲しみがなく大変よい
- Hoogle くれ
- Stackage くれ。同一パッケージの異なるバージョンを共存させないで……
- DerivingVia くれ。
- マクロは強力。でももうちょっと予測可能になってほしい。
- 認知負荷を減らすためにMonadをください。Rust でもやる方法はあるので……。
どうしても Haskell に肩入れした記事になってしまいましたが、どちらにもどちらの良さがあり、双方どんどん盗んでいきたいですね。
先日はRust.Tokyoにも参加させて頂きましたが、2トラックで熱気があり盛り上がっているな、という感じでした。Haskellも負けじとまた盛り上がっていきたいところです。
モナドやFoldableまわりについては、Haskellの側でも記事か本を書こうと思っていますし、Monad in Rust についてもそのうち別の記事を書こうと思います。乞うご期待。
宣伝
Jijでは各ポジションを絶賛採用中です!
ご興味ございましたらカジュアル面談からでもぜひ!ご連絡お待ちしております。
-
生きていると様々な諸般の事情がありますね?それです。 ↩︎
-
長期的には全然諦めてないです。世界をHaskellで一杯にしたいですね。 ↩︎
-
一方で、HLSも漸く最近になって Multiple Components サポートがはいったのもあり、Eval プラグインが依存関係を load できずに不安定になったり、重複していないインスタンス宣言が重複していると判断されてしまったりと、まだまだ課題はあります。おそらくこのあたりはこれから改善していくものと思われます。 ↩︎
-
とはいえ、17年Haskell書いていてカスタムの
Setup.hs書いたことないので、その機会が来るのかはわからないところですが……。 ↩︎ -
完全な余談ですが、cabal は後述の Backpack に最初から対応していたり、適切なリビルドや言語サーバの運用に必要な Multi-component build にも対応しているのに対し、Stack は後手に回っていたりします。また、stack のリビルド規則は厳しく、CI上でキャッシュつきビルドをしようと思うと工夫が必要になってしまう、という落とし穴もあります。こうした背景からも、今後は cabal が再び開発の主流を占めていくことになるでしょう。 ↩︎
-
Stackage の運営自体はHaskell Foundation に移管されて今でも維持されており、つい最近も無事 LTS が GHC 9.8 系へと移行したところです。 ↩︎
-
聞いた話だと
ndarrayとndarray-linalgまわりでこういった状態が起きていると聞きました。 ↩︎ -
これを直接 quickCheck に食わせれば十分な範囲の自然数が生成されるはずなので、これは心配しすぎな訳ですが、ここでは説明のために一旦一緒に不安になってください。 ↩︎
-
hpack (
package.yaml) というYAML表現も存在し、stack などではデフォルトで採用されています。一方、stack 以外のビルドシステムでは hpack から Cabal ファイルを生成してからコミット/ビルドする必要があり、またCabalファイルの仕様が進化したり、Cabal のフォーマッタが自動でモジュールリストを生成出来るようになったりしたため、近年では hpack を使わず Cabal ファイルを直接編集しフォーマットするのが一般的になりはじめています。 ↩︎ -
このシステムは、Agda のモジュールシステムと結構似ていると思います。Agda はモジュールとレコードをほぼ交換可能なものとして扱うことができ、モジュールをネストしたり、あるいは引数をとるようなパラメトリックなモジュールも定義出来たりします。 ↩︎
-
モジュール間で相互依存するのに
.hs-bootファイルを使って記述を分割できたり、後述の Backpack 機能などの存在により、一対一でない場合もあります。 ↩︎ -
と思ったらもう7年前でした。まじ……? ↩︎
-
Haskell における自己函手の抽象化
Functorとは無関係です。 ↩︎ -
型クラスとなにがちがうんだ?と思うかもしれません。例えば上の長さつき有限列の例では、「有限列っぽい型」の型クラスを定義して、「有限列の型」を引数にとる多相的な型として長さつき列を定義できそうです。しかし、例えば、Map-likeな型を抽象化したいと思った場合、通常の
Mapなら鍵にはOrdが要求されますが、HashMapではHashableが必要になります。Backpackでは、このような制約じたいもシグネチャ内でパラメータ化することができます。もっとも、型族とConstarintKindsを使えば型クラスでも同じことは抽象化できはします。このように、実のところ多くの局面では(本来は Backpack を使うのが素直な文脈でも)Backpackは型クラスで代用できてしまい、また stack が未だに backpack をサポートしていないのもあって、実のところ Backpack は Haskell 界隈で広くつかわれているとはいいがたいです(torch の Haskell バインディング Hasktorch では確か使われていた筈ですが)。それでも、Backpack には Backpack の利点があります。たとえば、Backpack を使って定義された型は単純な多相型ではなく、実装ごとに個別の型が生成されるという違いがあります。最適化の面からすると、多相型の場合はフィールドの値を UNPACK することはできませんが、Backpack を使うと個別実装は多相性のない具体的な型のみになるので、UNPACKが使えるという利点があり、この点に着目したunpacked-containersパッケージなどがあります。また、特定のモジュールの API をテストしたいような場合、Backpack を使ってシグネチャを一般化しておき、テストコードではシグネチャを使って書いて実装ごとにそれをインスタンシエートする、というような形で書くと綺麗になるのではないかと思います。 ↩︎ -
実のところ、上の GATs を使ったトリックを考えたのは、この再帰スキームを実現する方策としてでした。思い付いた後に、この方法使ってる人いるのかな?と crate を探したところ recursion-schemes crate が見付かり、そこで Functor が類似の方法で定式化されていたので、「あっそうかこれ Monad, Applicative にも使えるじゃん!」と気付いた、というのが流れです。 ↩︎
-
もちろん、これらの知識があれば規則に従って式変形をして同値だがより効率的なプログラムを導出できたりなど、知っていればいたで恩恵があります。 ↩︎
-
見方を変えれば、Applicative は「コールグラフが実行前に静的に決まっている」計算、Monadは「グラフが実行時に動的に決まる」計算ということになります。並列計算やビルドシステムの場合は、Applicative は各命令間の情報は限定的にしかやりとりできない代わりに、実行前にグラフを分析して適宜並列化・順序変更ができる、という利点があります。 ↩︎
-
実際、
f = ZipList,t = []とすると、これは正に二重リストの転置(transpose)演算になることがわかります。 ↩︎ -
プログラミングにおける抽象化って、ぜんぶ使ってる内に覚えるものだよね、というのが先に挙げた私の「モナドチュートリアル」の主張であもあります。 ↩︎
-
マトモな人なら
Vec<String>ではなく最初からVec<Var>を取るようにしてロジックを分離すると思いますが、ここでの主題は関係ないので、いったんマトモな人もマトモでなくなってください。あびゃ〜 ↩︎ -
厳密には、「関数全体がきっかり一回消費されるなら、
aもきっかり一回消費される」というべきですが、簡単のためこう書いています。 ↩︎ -
実際には他の Levity polymorphism などとの兼ね合いもあり、
baseでの($)や(.)はこのような形にはなっていません。それでも、十分新しい GHC であれば、上の定義は問題なく通すことができます。 ↩︎ -
YO YO ↩︎
-
このような関係にあるのは、GeneralisedNewtypeDeriving が DerivingVia の(そしてもっといえばGADTsや型族の)遥か昔に入った拡張であるためです。 ↩︎
-
もちろん、順序関係に基づく(BTree)Mapのような構造を考えると、
Map Int aと、その鍵の順序を逆転させたMap (Down Int) aを自由に coerce できてしまうと、不変条件が破れるので困ります。Haskell の role システムはこのような場合にライブラリ設計者が「表現が合っているだけではだめで、ちゃんと同じ型でないとだめだよ」と指定できる機能もついています。 ↩︎ -
実はこれは若干嘘で、Haskell では「型クラス(トレイト)を実装している型と
viaの引数の型の表現が一致する」ことを要求するので、最後の部分はFrom<T> for ExprではなくInto<Expr> for Tの方が適切です。とはいえ、Rust ではFromを実装してIntoを消費するのが推奨されているので、このような実装にしました。 ↩︎

Discussion
"外部ファイルに依存したテストツリーの生成" ですが、
build.rsでglobしてテストファイル毎に対応する関数を書いたテストコードを生成し、それをinclude!で取り込む、というのをよくやります。例えば以下のような感じです。
あーなるほど、build.rsに手を入れてやってしまう感じなんですね……!この辺はマクロの中でファイルシステム見るしかないのかなあ、と思っていましたが、ビルドの前処理でも同じことができると言うのは目から鱗でした(とはいえ、メタ的な手法を使わずに出来るといいなあという気持ちもやっぱりありますね……)。ありがとうございます!
konnさん、素晴らしい記事をありがとうございます!
Rust向けのHoogleとしてRoogleというものがあるようです。
あまり使ったことがないので使い心地はわからないですが…
https://roogle.hkmatsumoto.com/
ご参考になれば…
長々と書いてしまいましたがそう言っていただけて何よりです……!
Roogle 存じ上げませんでした……!ちょっと明日から使ってみようと思います 👍
Result<Option>をOption<Result>にする話。
公式APIドキュメント(https://doc.rust-lang.org/std) の検索欄で
Result<Option> -> Option<Result>のように引数 -> 戻り値を入力するとtransposeを候補に出してはくれますね。Haskell使ってないのでHoogleクラスの便利さに達しているかはわかりませんが。
EDIT:
-> 戻り値で、特定の戻り値の型を返す関数を列挙する検索もサポートしてたはず。ありがとうございます!確かに検索してくれますね……!そういえば、
Option::transposeもなんか適当に入力していて見付かったような気がします。その時は全文検索に引っ掛かったのかな、と思ったんですが、標準である昨日だったんですね。ただ、ジェネリックパラメータを手で与えてしまうとヒットしなくなったりするようなので、そのあたりはもうちょっと自由にできるといいのかなと思いました。Hoogle はある程度のパッケージを横断的に検索してくれるので、これで横断的に検索できるとよりよさそうですね(Roogleがそうなのかしら)そういった問題が発生することはあって、「依存ライブラリの型を露出させるときは、そのライブラリをre-exportしておく」というプラクティスが一応あります。
複雑なケースだと、これだけじゃ困ることはありそうですが。
なるほど、「これを使いますよ」というのを export しておくわけですね。とりあえず何とかはなりそうですが、複数の crates がそれぞれ違うバージョンの同一crateに依存していたりすると結局解決にならなさそうですね……。
StackageとRustの比較については以下が参考になるかもしれません。
ざっくりいうとRustは依存関係解決がちゃんとしていてSemVerを遵守する文化があり、Cargo.lockによるバージョン固定もできるので、大規模なStackageを保守するコストが正当化できない、という意見のようでした。
SemVerについては互換性を機械的にチェックできる cargo-semver-checks をCargo本体に取り込もうという動きもあり、そちらの方向に開発コストをかけているように見えます。
おぉ、正に Stackage を作った Snoyman の記事がありましたか……!ありがとうございます。軽く拝読しました。
たしかに Stackage が作られた当時はSnoymanのいうような問題があり、Stackage がそれに対する解として機能していたと思います。しかし、こうした問題は4年を経て現在の Haskell では概ね解消しており、それでもなお Stackage は Haskell のエコシステムのかなり重要な位置を占めていますので、不要という事はないと思います。
Snoyman の記事にもあるように、一応 Haskell にも PVP というしっかりとしたバージョニングポリシーがあり、たしかに Stackage が作られた当初はこれを遵守しているパッケージは少なかったですが、Stackage の存在によって寧ろ遵守する文化が根付いてきているように思います(そうしないと Stackage がちゃんと機能しないので)。
cargo-semver-checks はかなり良さそうなツールですね……!PVP は複雑ではありますが、実用上そこまで判断に困ることは少ないという体感で、Semvar でも利用者が増えて守らない人が増えそうな気もするので、こうしたツールがあるのは素晴しいことだと思います。まだ広く用いられていないですが、Haskell でも
policemanやcheck-pvpといった PVP をチェックしてくれるツールがある程度存在しています。どちらもあまり最近はメンテされていないようですが……。ロックファイルについてですが、Cargo.lock に対応するものとして、現代の cabal では
freezeファイルがあります。Cabal と共に使う場合そのfreezeファイルが降ってくるというのが Stackageの現代の在り方なので、両者は必ずしも排他ではないと思います。4年前に Snoyman が記事を書いた当時はたしかにまだ cabal も発展途上でしたが、今はかなり成熟して freeze ファイルの生成や制約ソルバも問題なく動くようになっています。その上でもやはり最初の叩き台として Stackage から freeze ファイル持ってきて、後で追加で足して……という使い方はかなり安心感と安定性を齎してくれると感じています。Snoyman の記事で触れられていない重要な点としては、やっぱり記事で触れたような菱形依存関係の問題があると思います。これを引き起こさないように Stackage (snapshot) とサンドボックス化が必要だったという歴史がある訳で、こうした問題に対処しようと思うと Stackage 的なものが必要になる気がします。もちろん、これが問題になりにくい可能性もあって、それならばなくても機能はするんだと思います。
まとめると、整合性のある lockfile が天から降ってくる仕組みとしてのStackage はあればあったで便利じゃないかなあという結論になるかなと思います。ぎゃくに言えば、現状で問題なければなくても回るんだろうな、と思います。菱形依存関係が問題になってきたら検討するとよいような気がしますね。
菱形依存関係については上のコメントにもありますが、re-exportしておくことでmy_packageから直接参照しているBとAからre-exportされているBはぞれぞれ別のクレートとして参照可能です。
なのでmy_package内でそこの受け渡しが必要であれば(バージョンXのBの型からバージョンYのBの型への)変換コードを自分で書くことで面倒ではありますが対応は可能です。
最悪re-exportされていなくても、Aが参照しているバージョンのBを別途依存関係に書けば多分いけますね。その場合はAが参照しているBのバージョンが変わるごとにmy_packageが壊れることになるのでかなり体験が悪いですが。
いずれにしても本質的に回避不能というケースはあまり思いつかないです。
ndarrayの件は知らないのですが、大規模なエコシステムで上記のようなことを手作業するのが面倒すぎるとかはあるかもしれません。
うーん、結局そこで re-export して対応する、というのが本質的な解決になっていない気がするんですよね……。Haskell でも re-export はできますが、結局その変換をしようと思うと場当たり的・一時的な対応になり、バージョンがそろったら結局元に戻す必要がありますし。型の間の変換であればなんとかなりそうですが、
traitの実装を共有しようと思うと大変そうな気がします(あ、だから型の変換で頑張ることになるわけですね)。どこで export しているかは「依存しているバージョンの型がとりあえずすぐ手に入る」以外、あんまり本質的ではないような気がしていて、どちらにしてもどちらかの依存バージョンが再び変わったらもう一方の変換ロジックは変えるなりしないといけないのは変わらない気がします。
本質的に回避不能でないのはどの言語でもそう(Haskell でも別の型として扱われるだけですし)という気がしますが、回避不能でないからといって、複数バージョンの間の変換関数を書くのは本質的な解決になっていないような気もします。プロダクトなら問題ないですが、ライブラリだったりすると結局複数のバージョンの組み合わせを考えないといけない気がしますし。
……というところまで書いて、もしかして Rust は依存ライブラリ全般に対して実装するのではなくて、lockfile に書いた特定のバージョンで動けばよい、というカルチャーなのかな、という気がしてきました。ライブラリでこの方針だと制限がかかってしまう気がしますが、実行ファイルだとそれで問題ないのかもしれないですね。
Haskellがちょっと触ったくらいしか知らないのでそちらの問題意識が分かってない部分があるかもしれませんが、機能的にRustと大差ないとすると単にRustのエコシステムが若くてそういう問題がまだ出にくい、というだけかもしれませんね。
将来的に「tokioのv1, v2, v3で相互運用しないといけない」みたいな事態になるとStackage的なものが欲しくなるのかもしれません。
たとえば
super::なども、他言語のモジュールシステムではあまり考えられない存在でしょうか?そうなると、Rust のモジュールには他言語と異なる利用法がありそうです。たとえばテストを書くとき、「テスト駆動開発」の節で仰っている通り、同一ファイル(
foo.rsとします)内にテストを同居させればプライベートな実装まで踏み込めますが、テストコードとロジックが混在してしまいます。そこでファイルをfoo.rsとfoo/test.rsに分割しますが、このときfoo/test.rsの先頭にuse super::*;と書くことで、foo.rs内と同じ可視性が得られます。確かにモジュールという言語機能を使っているのですが、どうも他言語のモジュールとはモチベーションが違っている気がします。他には、
foo.rs内で定義した構造体Fooにトレイトstd::fmt::Debugを impl する(derive を使わずに自分で書く)ような場合、記述が煩雑になるとfoo/debug.rsに分けるといった使い方も考えられます(そういう書き方をしている人が自分の他にどのくらいいるかは分かりませんが……)。自分は、このように「見やすさのために一部の記述を別ファイルに切り分ける」という目的でモジュールを利用する場合に限り、循環的な
useを書いています。もしかするとこの目的自体が Rust 特有なのかもしれません。たしかに、モジュールの親を指すような指定子ってあまり他の言語では見たことがない気がします。
use super::*は分けない場合でも確かによく使いますし、こうしたテストなどや実装の分割上での簡便性を念頭にモジュールが設計されているというのはそうなのかもしれません。他言語でも、実装を複数モジュールに分割することはありますが、単一モジュールで最終的な結果を露出したいとなったら hide と reexport を手動でやったり、相互依存的なモジュール分割を行おうと思うと記事中で触れたような hs-boot ファイルが必要になってしまいます。こう思ってみてみると、確かにご指摘のように、Rust はむしろモジュール間の分離はそこまで厳密せずに、ほどよい粒度で分割できるようにしたいという要求を第一に設計されていそうですね。このあたり、 pub use など
適切に呼ばないとスコープに入らないものがあったりする事とトレードオフになっている感じはしますが、その選択も含めて面白いなと感じます。