こんにちは。IVRy のエンジニアの yuri ( @yuri_ivry ) です。
この記事は、「IVRyのSREの取り組み 2022夏」の後編です。前編に続き、7月にリリースした IVRy の SRE 的な取り組みの中からいくつかご紹介します。
※ 前編はこちらです。
お品書き
<前編>
- 重たいクエリを特定し、index を貼る
- 監視モニタリングの整備
<後編(この記事です)>
- DBのリードレプリカの導入
- キャパシティプランニング
- コア機能の分離
その3: DBのリードレプリカの導入
背景
特定のクライアントがログインすると IVRy 全体の負荷があがってしまう状態になっていました。
根本的には通話が多いクライアントにおいて「その1」で取り上げたクエリが悪さをしており、前述の対応で改善しました。
根本的な原因としてはシンプルで、検索で参照しているテーブルのカラムに index が貼られていませんでした
IVRyのSREの取り組み 2022夏(前編) より
ただ、特定の(参照)クエリのパフォーマンスにより IVRy の全ての機能が影響を受けてしまう構造が良くないため、その部分についても見直しを行うことにしました。
対応
RDS のリードレプリカを作成し、参照系のクエリはリードレプリカで処理するようにアプリケーションを修正しました。
従来からリードレプリカに関する議論は行われていましたが、単純にインフラコスト(のうち大きな割合を占める DB のコスト)が高くなるため、初期のうちは利用していませんでした。
ユーザが増えてきていよいよやる価値が高まってきたタイミングだね、と今回判断しました。
<余談>
あるお題に対して以前の結論とは異なる結論を出すことは、意思決定のための背景や条件が変化するスピードが速いスタートアップではよくあることだと思っています。
IVRy では、こういった制約条件の変化を適切に捉え、結論が変化することに対しても全員で共通認識を持ち続けていくことを大切にしています。
閑話休題。
Rails でのリードレプリカの利用は下記の記事を参考に行いました。なお、コネクションの切り替えについては検証環境でうまく切り替わらないケースがあったこともあり、現状は自動切り替えではなく controller 内で個別に指定する形にしています。
こちらのリリースについての懸念は、レプリケーションにかかる時間と、その間の master インスタンスのパフォーマンス劣化でした。
前者については検証環境で10分程度であることがわかっており、後者についてはメモリの使用量が高まることがあるとわかっていました。
この事前情報を元に、なるべく通話量の少ない時間帯にリリースを実施することとし、サービスインしながら影響を極小化させました。
その4: キャパシティプランニング
背景
IVRy のピークタイムは通話が増える AM 9時~10時頃なのですが、このピークタイム前後で ECS のメモリや CPU のアラートが通知されることが連日続いていました。
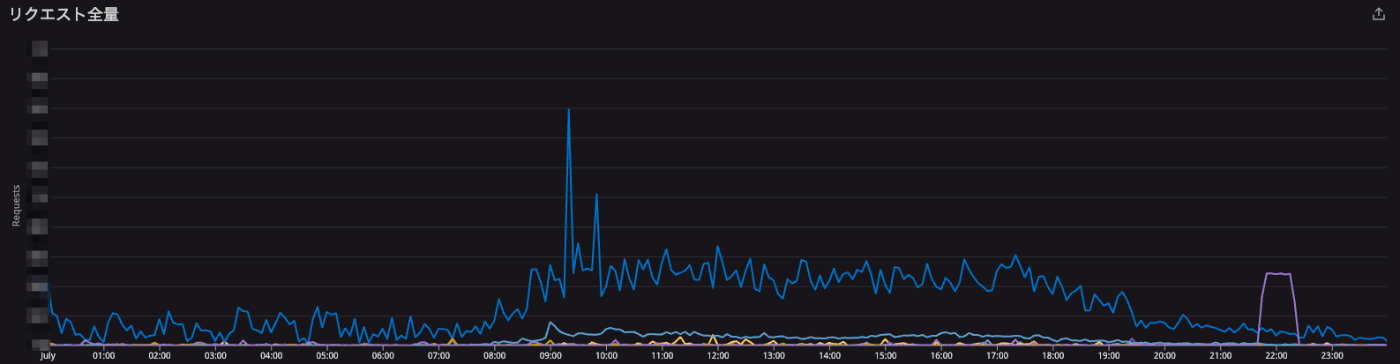
とある1日の IVRy への各システムへのリクエスト数のトレンド
調査と原因
スタートアップ初期あるあるかとは思うのですが、下記のような状態になっていました。
- Rails の Web サーバとして利用している Puma の設定値がデフォルトのママ
- ECS タスクのサイズや数が初期に設定したもののママ
- RDS のインスタンスタイプが初期に設定したママ
いつかは見直さなきゃという思いはあったものの、問題なくサービスが動いている状態が長らく続いていたため、新しい機能追加など他の対応を優先して実施してきていました。
対応
現状のメトリクスをもとに、愚直に見直しをかけていきました。
-
Puma の設定の見直し
- 弊社と似た構成でかつパラメータをどのように考えるかが丁寧に記載されていた下記の記事を参考させていただきました。
- Amazon ECS+FargateでRailsを動かす際の最適なパラメーターを考えてみる - ユニファ開発者ブログ https://tech.unifa-e.com/entry/2020/08/28/161733
- 下記と合わせて DB のコネクション数の調整なども実施しています
- 弊社と似た構成でかつパラメータをどのように考えるかが丁寧に記載されていた下記の記事を参考させていただきました。
-
ECS スケールアウト・スケールアップ
- Puma の設定と合わせてですが、基本的には1タスクを利用しきる + スケールアウトによるキャパシティアップという路線にしました
-
RDS のスケールアップ
- 大きな声では言えないのですが、本番でも T 系インスタンスを利用していたのを止めました…
- 前編でも触れた通り、DB の再起動がかかる処理のため実施タイミングやコミュニケーションについては留意して進めました
負荷テスト等を実施することでより中長期的なキャパシティプランニングを行ったり、オートスケーリングの設定を行ったりするところまでは至っておらず、まだまだ対応の余地がありそうです。
その5: コア機能の分離
背景
様々な要因によりシステム負荷があがった際、IVRy の通話を含む全ての機能に影響が出てしまうことがありました。
設定画面に障害が発生した場合でも、IVRy のコア機能である通話が利用できる状態をなるべく担保できないか、と考えました。
IVRy はリリース以降、継続的に機能追加を実施してきました。
いま時点で IVRy が持つ機能の中には、クライアントの業務オペレーションの観点からみてサービスレベルが明確に違うものもできてきています。
具体的には、「通話」と「設定」ではサービスレベルが大きく違いますし、「設定」の中でも電話履歴の確認とルールの設定では違いがあります。
第一優先で守るべき機能は「通話」 ですが、「設定」の機能追加が進んできたこともあり、システム的に「設定」が倒れることによって「通話」も共倒れしうる構造になっていました。
対応
API サーバにおいて通話に関連する API とそうでない API を別々の ECS で処理するようにしました。
いわゆる Bulkhead Pattern になるかと思います。
具体的には、 ECS のターゲットグループを通話関連とそれ以外の2つに分割し、ALB から path ベースで処理するターゲットグループを指定するようにしました。
また、フロント側の処理も見直し、通話に必須ではない処理が着信や発信といった通話機能をブロックすることがないようにしました。
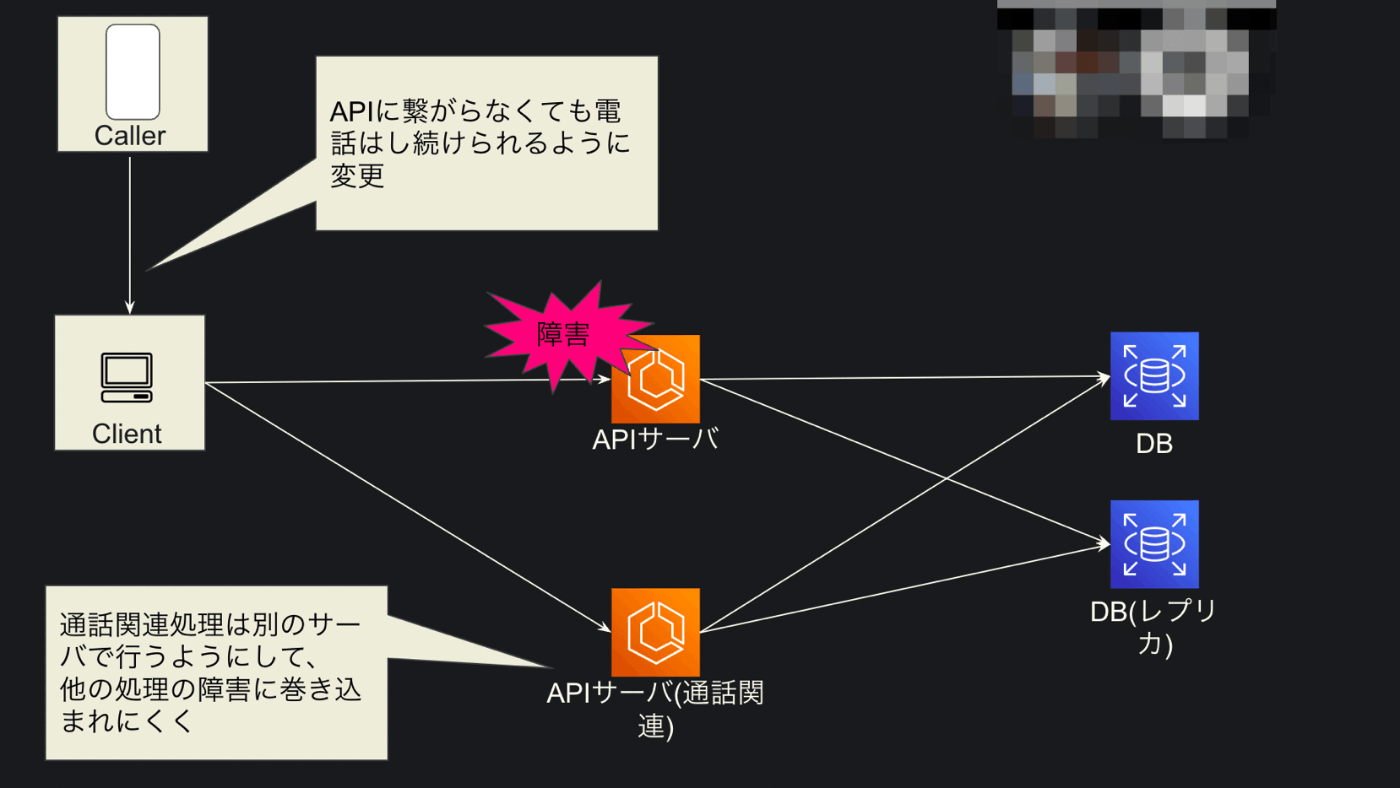
社内の LT 会でこれらの取組を共有したときに使った、超簡略化した図解
これにより、例えば設定画面でアプリケーションレベルの負荷が高まった際にも、通話機能部分は影響を受けにくい状態を作ることができました。
もちろんデータベースは1つなので、負荷の内容次第では完全ではありませんが、一定の効果が見込めると見込んでいます。
まとめ
IVRy は電話自動応答の SaaS であり、時間帯や曜日等の緩急無くサービスレベルを高く保ち続けることが求められます。
サービスレベルの向上というのは簡単ではなく、やらなすぎるのは当然として、やりすぎてしまうこともまたサービス成長を妨げてしまうものです。
適切なサービスレベルを目指していくためには、自分たちのサービスの現状や将来の様子、サービス特性やクライアントの業務理解を深めることが必要不可欠だと思っています。
まだまだ基本的な対応から始めているところではありますが、今後もこれらの理解をみんなで深めながら、継続的にサービスレベルの改善に繋がる開発を行っていきます。
そんな IVRy の開発に興味を持っていただけた方、ぜひ一度お話しましょう!
IVRy は副業からでも大歓迎です。
前編はこちら:

Discussion