こんにちは。IVRy のエンジニアの yuri ( @yuri_ivry ) です。
IVRy では目に見える機能開発の他にも、サービスレベルを高めクライアントに提供するシステムが安定稼働し続けることを目指して、様々なシステム改善(Site Reliability Engineering, SRE)を日々実施しています。
今回は、2022年7月に IVRy の開発チームがリリースした SRE 的な取り組みの中から5つほど、前後編にわけてご紹介します。
※ 本記事の想定読者はパブリッククラウド上で Web サービスを提供するエンジニアです。
(追記: 後編も公開しました)
背景
IVRy の導入クライアント数が継続的に増えていることや、クリニックなどいくつかの業種における着信数の急増加に伴い、IVRy のシステム負荷が増大し設定画面のログインや表示等に時間がかかるケースが増えていました。
IVRy の成長はとても嬉しいものですが、それによるシステム負荷によってクライアントにご迷惑をおかけしてしまうシーンを極力減らせるよう、いくつかのシステム改善を実施しました。
<余談>
日本における新型コロナウィルスの第7波の拡大と連動する形で着信数が爆発しているクライアントも多数見受けられ、IVRy の中の人として改めて、電話というコミュニケーションツールの社会インフラとしての存在感の大きさを感じています。
閑話休題。
お品書き
<前編(この記事です)>
- 重たいクエリを特定し、index を貼る
- 監視モニタリングの整備
<後編>
- DBのリードレプリカの導入
- キャパシティプランニング
- コア機能の分離
その1: 重たいクエリを特定し、 index を貼る
まずは超基礎的な対応から手を付けました。
背景
特定のページの表示が重たくなっていることに関して、クライアントからお問い合わせいただくことがありました。

クライアントからいただいたお問い合わせを社内で共有した様子
調査と原因
該当のページで呼び出している API の処理内で発行している SQL のパフォーマンスが悪くなっていました。
根本的な原因としてはシンプルで、検索で参照しているテーブルのカラムに index が貼られていませんでしたw
IVRy のほとんどの機能ではクエリのパフォーマンスにも気をつけた実装がされていますが、この箇所においては少し複雑なクエリになっていたこともあり、データ量が一定を超えたタイミングからパフォーマンス課題が顕在化しました。

EXPLAIN ANALYZE による当時の実行計画
IVRy では RDB として Amazon RDS for PostgreSQL を利用しています。
筆者個人としてはプロダクションレベルで PostgreSQL を利用した経験が乏しく、PostgreSQL のクエリパフォーマンスの分析について下記の記事を大いに参考にさせていただきました。
対応
対応としてはシンプルに index を追加したのですが、2点ほど気をつけたことがあります。
1点目は、どこにどのような index を貼るか、です。
上記の実行計画の画像の中にも含まれていますが、該当のクエリは NOT 条件やカラムを跨いだ OR 条件を含むものであり、単純に該当カラムに index を貼れば良い、という話ではありませんでした。
-- 特定の通話履歴について、「この通話相手との他の通話履歴」を抽出する
SELECT "calls".id FROM "calls"
WHERE "calls"."client_id" = 'クライアントID'
AND ("calls"."caller_number" = '+電話番号' OR "calls"."call_to" = '+電話番号')
AND "calls"."calllog_id" != '通話履歴ID'
ORDER BY "calls"."timestamp" DESC LIMIT 100;
OR 部分について UNION 句を利用する形でクエリをリライトするなどの手段も候補に入れて検討しました。
最終的には、OR と並列の検索条件になっているカラムと、OR の各条件の複合 index をそれぞれ貼るというアプローチを取りました。
(具体的には、client_id and caller_number, client_id and call_to の2つ)
最初は一部メンバ(私を筆頭にw)は「この index で速くなるのか…?」と疑心暗鬼になっていましたが、本番環境に近いデータでの実行計画を見て検証していく中で、現状妥当な打ち手でありそうなことが明らかになりました。
※ この index により、 a AND (b OR c) を (a AND b) OR (a AND c) のように分配法則のような形で最適化して実行する場面が増えそうであり、それで十分なパフォーマンスが見込めそうだ、と判断した形です。
2点目は、RDS でスロークエリログを出せていなかったので出すようにしたことです。
これにより、クライアントからお問い合わせをいただくだけでなく自分たちで重いクエリを検知することを狙いました。
IVRy では RDS のパラメータグループをデフォルトのものを利用してしまっていたので、まずはパラメータグループの変更が必要でした。
これには RDS の再起動を伴うため、実施する時間帯やクライアントへのコミュニケーションに注意して実施しました。
どの Web サービスでも類似の議論はあると思いますが、IVRy は電話 SaaS というプロダクト特性上、クライアントの業務時間外も含めて高いサービスレベルを保つことを目指しています。
そのため DB 再起動を伴う処理は実施タイミングは慎重に検討する必要がありました。
今回は、後編で触れる RDS のスケールアップと合わせての対応とすることで、DB 再起動に伴うサービスメンテウィンドウの回数を極小化しました。
その2: 監視モニタリングの整備
背景
アプリケーションのエラーログや、ECS の CPU 使用率などについてはアラート通知の設定ができていましたが、IVRy のシステム負荷があがっているときにそれらの通知がないことがありました。
また、高負荷状態における調査の際にも、リクエスト数のトレンドや偏りなどがわかる状態になっておらず、いちいち CloudWatch Logs のクエリ + シェル芸で調べるような状態になっていました。
監視ちゃんとやりたいねーという話は昔から定期的に出ていたものの、実コストや運用装着コスト、知見のある開発者がいないといった点からなかなか導入まで至っていませんでした。
今回、知見のあるエンジニアがジョインしたことに加えて上記のような課題も顕在化したことを推進力として、導入まで進めることとしました。
対応
Datadog を導入し、一通りのメトリクスについてのモニタリングを設定しました。また、ダッシュボードを作成し日々のトレンドなどを一覧でみられるようにしました。
導入については、副業メンバで本業でDatadogを利用している人など知見を持っているメンバが中心となって一気に進める形で行いました。
検証環境での素振りからはじめ、数日のうちに本番の主要なメトリクスのダッシュボードを作ってしまいました。
その後、これまで Datadog に触れてきていなかったメンバがキャッチアップする形で利用を進めています。
障害対応時にメトリクスを見ようと手癖で AWS のマネコンを開くエンジニアもいましたが、最近はまず Datadog を見ることが多くなってきたように思います。
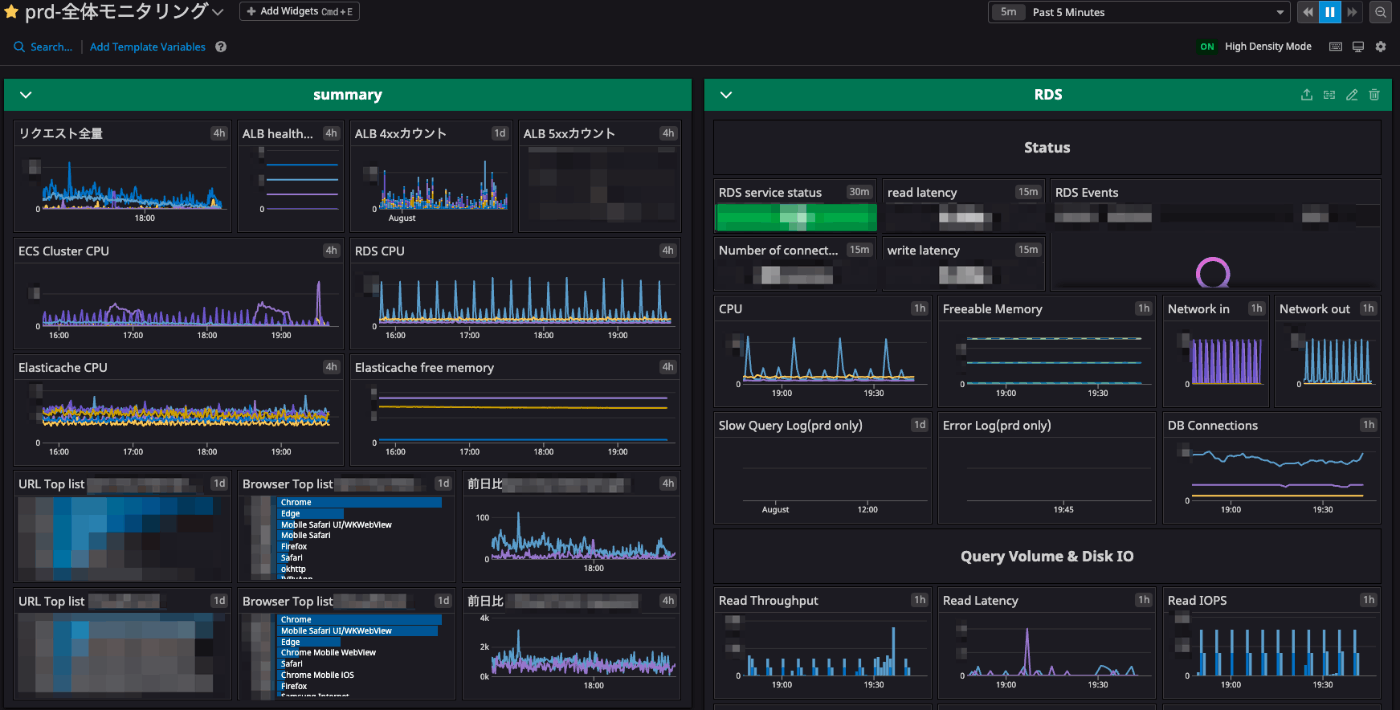
Datadog ダッシュボードの一部
この事例は同時に、IVRy は副業で関わっているメンバがすぐに大きな価値貢献をしてくれている事例でもあります。
これまで十分に手が回っていなかった部分ややりたくてもやれていなかった部分でも、優秀な副業メンバが自身の経験やノウハウ、スキルによってサクッと解決まで持っていってくれるなど、様々な場所で良いコラボレーションが起きていると思います。
ここまでのまとめ
IVRy のサービスレベルを向上させるために、2022年7月にリリースした内容について、2点ご紹介しました。残りの3点については、後編でご紹介します。
(追記: 後編も公開しました)
この時点で少しでも IVRy に興味を持っていただいた方、下記もご覧ください!IVRy は副業からでも大歓迎です。

Discussion