Open7
2025/3/6 AWS Innovate: Generative AI + Data(T4)
Contents
- T4-1: Amazon Q Developer を利用してソフトウェア開発ライフサイクル (SDLC) を加速させる
- T4-2: マルチエージェントを活用したスケーラブルな生成 AI アプリケーション
- T4-3: Amazon Bedrock を用いた生成 AI 活用時のコスト最適化
- T4-4: 生成 AI をビジネスに活かすファインチューニングの実践方法
- T4-5: Amazon SageMaker AI による基盤モデルや機械学習モデルの開発・運用効率化
T4-3: Amazon Bedrock を用いた生成 AI 活用時のコスト最適化
【L200】
- 大規模な本番活用でのコスト効率のよいモデルやアプローチ
- これまでの歴史
- 2023年はPoCの年
- 生成AIとは何?
- 安全か?
- 何から始める?
- モデル選択は?
- 2024年は本番稼働の年
- 何を優先するべきか
- コスト削減の方法は?
- 規模拡大するには?
- 独自モデルは?
- 2025年はビジネス価値の年
- Agent活用
- 活用を展開するには?
- ビジネス全体をどう変革するか
- 社員のAI活用は?
- 2023年はPoCの年
- Amazonにおける Review Highlightsの事例
- Accurate、Resoinsible、Customer delight、Cost-effectiveが大事
- コスト感の例①:1億件を解析・分類(ECサイト、人材紹介)
- Claude 3.5 Haiku →500万
- Claude 3.5 Sonnet→7000万
- コスト感の例②:200文字のコメントを1秒に1件レビューする(動画配信サイト、SNS)
- Claude 3.5 Haiku →15万/月
- Claude 3.5 Sonnet→200万/月
- Amazon Bedrock でコスト最適化のアプローチ

- モデル選定:Anthropic Claude、Amazon Nova、Amazon Bedrock Marketplace、Intelligent Prompt Routing...
- 価格と性能で最適なものを選択

- 推論方法:On-demand、Provisioned Throughput、Batch Inference
- リアルタイム処理が不要であれば、Batch Inferenceを選択するなど
- Fine-tuning:Fine-tuning、Model Distillation
- 軽量なタスク特化モデル
- Fine-tuningしたものは、Provisioned Throughputで独自の推論リソースを確保する必要がある
- 常時大規模なスループットが必要というユースケースで効果を発揮する点に注意
- キャッシュ:Prompt Caching
- 複数のAPIコール間での繰り返しのコンテキストをキャッシュ
- Amazon Bedrockのコストモニタリング
- Cost Exploreでも確認できるが、情報が粗い
- コスト配分タグ:APIを呼び出すタイミングで付与したタグ
- Langfuse:LLMOpsツール
- Amazon.comでのAI活用事例


T4-4: 生成 AI をビジネスに活かすファインチューニングの実践方法
【L300】
- なぜファインチューニングするのか?
- 基盤モデルでは汎用的なモデルを提供しているのでざまざまなタスクに対応できる
- しかし、以下の問題がある
- ハルシネーション
- 情報の鮮度(モデル作成時点の情報)
- 推論コスト
- 用途に特化したを作ることで、品質や性能向上、コスト最適化
- モデルの活用アプローチ:下にいくほど難易度やコストUP
- プロンプトエンジニアリング
- RAG
- モデルのカスタマイズ
- スクラッチ開発
- AWS上でのファインチューニングする方法
- 基盤モデルをラベル付きデータで追加の学習を行う
- 継続的事前トレーニング(Contiued pre-trainin)
- ドメイン特化のラベルなしデータで事前学習
- 蒸留(Distillation)
- 大きいモデルに匹敵する精度をもつ小さいモデルを作る
- Custom Model Import
- Amazon Bedrock 外で学習された基盤モデルをインポートする
- 既存モデルと同様のAPI呼び出しが可能
- Amazon SageMaker JumpStartでもファインチューニング可能
- 機械学習ハブにある400以上の事前学習済みモデルが利用可能
- VPCエンドポイントでセキュリティ◎
- ファインチューニング手順
- データセットの作成
- ファインチューニングジョブの作成、実行
- プロビジョンドスループットの購入
- ファインチューニングモデルの実行

T4-2: マルチエージェントを活用したスケーラブルな生成 AI アプリケーション
- 生成AIエージェント
- 自律的に実行計画を立ててタスクを実行するもの
- エージェントがユーザーの代わりに、基盤モデルに繰り返しプロンプトを実行


- 生成AIエージェントを構築する上での課題
- エージェントへの機能を増やしていくと・・
- プロンプトの実装が煩雑化、メンテナンスが困難に
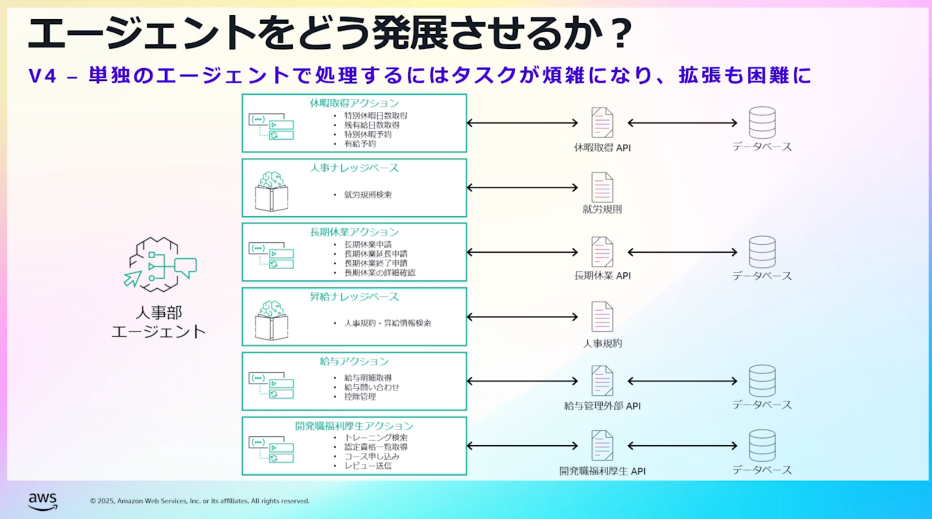
- エージェントが煩雑な処理に対応できずに混乱、誤ったタスクを実行し、回答が不安定に
- 長い指示を処理するため推論回数増加、レイテンシ、コストも増加
- エージェントを分割して、ユーザーに用途にあったエージェントを利用してもらう?
- ユーザーがどこに問い合わせるか理解して使い分ける必要があるので、容易ではない
- 解決策:マルチエージェント
- 複数のエージェントを連携して統合する。
- 統合の方法は階層型、メッシュ型がある。

- Amazon Bedrock Agents multi-agent collaborationでは階層型を採用
- エージェントへの機能を増やしていくと・・
- エージェントのユースケース

- ユーザーのリクエストに対して柔軟に対応させたい場合
- 生成AIエージェントの検討
- 課題の解決策としてエージェントが最適か?
- 単純な書き起こしであればエージェントではない実装も選択肢として検討する
- AWS Step Functions
- Amazon Bedrock Flows
- 単純な書き起こしであればエージェントではない実装も選択肢として検討する
- 単独エージェントから小さく開始→複数エージェントと発展させていく
- 課題の解決策としてエージェントが最適か?
- おすすめ>GenU
- Amazon Bedrock Agents multi-agent collaboration
- 複数のエージェントを束ねて、より複雑な処理を実行できる

T4-1: Amazon Q Developer を利用してソフトウェア開発ライフサイクル (SDLC) を加速させる
- 開発者は、ソフトウェア開発ライフサイクルのどこに時間を費やしているか?

- 当初は、「作成(Create)」の部分を補っていた。
- しかし、実際はほかのタスクでも時間を費やしている
- Amazon Q
- Developer:開発者、IT専門家
- AWS機能に関するガイダンス
- 機能開発を加速
- コードのデバッグ、テスト、最適化
- アプリケーションコード変換

- Business:従業員、ビジネスアナリスト
- Developer:開発者、IT専門家
- Amazon Q Developer エージェント
- コード生成(/dev)
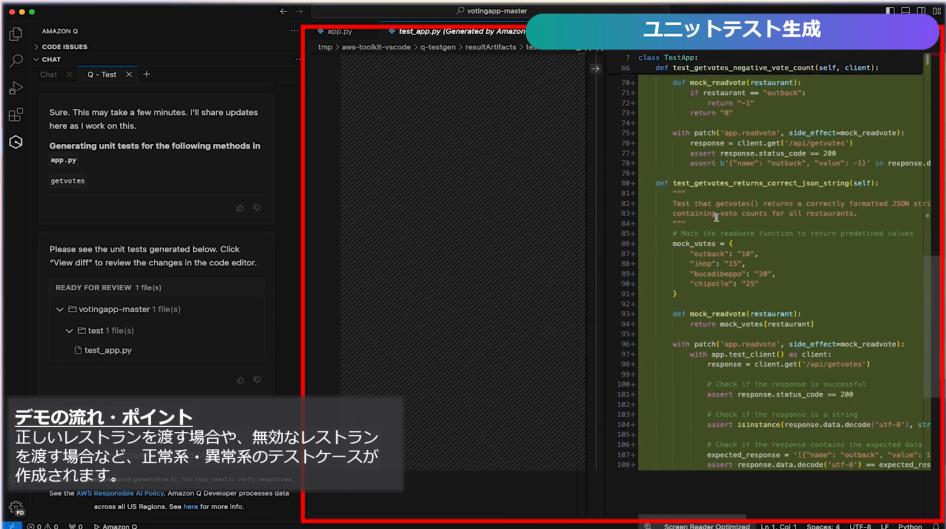
- テスト生成(/test)
- コードレビュー(/review)
- ドキュメント生成(/doc)
- コード生成(/dev)
- ハンズオン



T4-5: Amazon SageMaker AI による基盤モデルや機械学習モデルの開発・運用効率化
- MLOps:機械学習の開発や運用を自動化及び簡素化する一連のプラクティス
- プラットフォーム管理:インフラ構築、アクセス提供
- データ:データの取り込み、準備、結合、カタログ化、可視化
- 実験:MKがビジネス課題を解決できるか?(PoC)
- モデル構築:モデル構築・学習の自動化
- モデルテスト:モデルテストとガードレール
- モデルデプロイ:モデルの提供と監視
- MLガバナンス:バージョン管理、監査
- FMOps:基盤モデル特有の事情を加味したMLOps、ファインチューナーと呼ばれる基盤モデルに深い知識を持つ人が追加される
- プロンプトを使用した基盤モデルの選択・評価・動作制御
- モデルの堅牢性やバイアス
- プロンプトを使用したモデルの動作変更と管理
- コスト最適化
- GenAIOps:生成AIアプリケーションの構築に特化した運用フレームワーク
- RAG
- エージェント構築と評価
- 生成AIトレーサビリティの確保
- ガードレール実装
- プロンプトマネジメント

-
Amazon SageMaker AIによるFMOps
- 自動ビルドパイプライン
- SageMaker Pipeline
- データ準備
- SageMaker Ground Truth
- SageMaker processing job
- モデル学習
- SageMaker training job
- モデル評価
- SageMaker with MLflow
- SageMaker Clarify
- モデルレジストリ
- SageMaker with MLflow
- SageMaker Model Registry
- モデルデプロイ
- SageMaker Modep Deloyment
- モデル監視
- SageMaker Model Monitor
- ドキュメント
- SageMaker Model Card
- モデルパフォーマンス
- SageMaker Model Dashboard
- 自動ビルドパイプライン
- マルチアダプタ推論
- LoRA:モデルを迅速かつコスト効率よくファインチューニングするための技術。大規模な基盤モデルの一部のみ更新
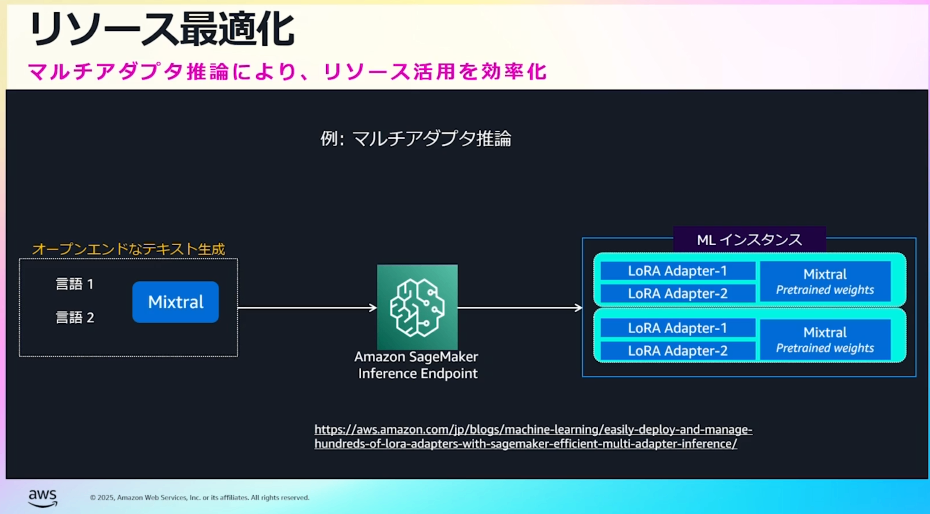
- ベースとなるモデルを固定、少数のアダプタ層を更新することで高いパフォーマンスかつ安価にファインチューニングできる特徴がある