re:Invent 2024: AmazonのRufusとReview HighlightsにみるAI活用
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Generative AI for millions: Amazon's Rufus and review highlights (AMZ301)
この動画では、Amazon.comにおけるGenerative AIの実践的な活用事例として、Review HighlightsとAmazon Rufusという2つのプロジェクトが詳しく紹介されています。Review Highlightsは、毎年12億件寄せられる商品レビューを効率的に要約・分析するシステムで、AWS Inferentia 2チップを活用してコスト効率の高い処理を実現しています。一方のAmazon Rufusは、ショッピングに特化したLLMベースの会話型アシスタントで、User-Perceived Latencyの最適化やContinuous Batchingの導入により、Prime Dayなどの大規模イベントでも安定したパフォーマンスを実現しています。両プロジェクトを通じて、Generative AIの本番環境での運用における具体的な課題解決方法や、顧客体験を起点とした設計の重要性が示されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon.comにおけるGenerative AIの概要

re:Invent 124へようこそ。本日は、数百万人のためのGenerative AIについてお話しさせていただきます。Amazon RufusとProduct Review Highlightsについて詳しく見ていきましょう。私はBurak Gozlukluと申します。AWSのPrincipal AI/ML Specialist Solutions Architectとして、Amazonのカスタマーサポートを担当しています。本日は、Amazon RufusのPrincipal EngineerであるRJと、Review HighlightsのDirector of EngineeringであるVaughnをお迎えしています。大規模な学習と解決策について情報を共有させていただきます。なお、本セッションはサイレントセッションとなっておりますので、セッション中の質問は受け付けておりませんが、セッション終了後に質問にお答えさせていただきます。

それでは、アジェンダについてご説明させていただきます。まず、Amazon.comにおけるGenerative AIから始めて、今年本番環境にリリースされたいくつかの事例をご紹介します。その後、VaughnとともにReview Highlightsについて詳しく見ていき、続いてAmazon Rufusについて説明し、最後に重要なポイントをまとめさせていただきます。
Amazon.comの規模と2023年のGenerative AI活用事例

Amazon.comで何かを構築する際には、常に2つの大きな課題があります。1つ目は間違いなく速度で、2つ目は規模です。数字で見てみますと、現在Amazon.comには4億点以上の商品があり、2億人以上のPrimeカスタマーにサービスを提供しています。毎年70億点以上の商品を配送し、毎日1,200万件以上の新規注文を受けています。また、毎年12億件の新しいレビューがお客様から寄せられています。ほとんどの購入は3分以内で完了し、この時間はさらに短くなってきています。速度と規模は常に大きな課題であり、私たちはお客様のニーズもこの観点から対応しています。

今年のGenerative AIを活用したイノベーションの1つが、Product Listing Expertです。Amazon.comでは、50以上のカテゴリーにわたって商品リストがタイトルや説明とともに表示されています。この技術が導入される前は、これらのリストのほとんどは販売者が手作業で作成する必要がありました。この技術により、現在では販売者がGenerative AIを使用してリストの下書きを作成できるようサポートしています。販売者は商品情報のURLを提供し、商品の詳細を入力すると、Generative AIツールがベストプラクティスを適用して最適な形でリストを生成します。販売者はベストプラクティスに基づいたリストをすぐに改善することができます。現在、10万人以上の販売者がこの技術を使用しており、今年末までに数百万件のリストにこの技術を適用する予定です。

一部の商品については、AIベースのレコメンデーションを提供しています。最近、私が特定のブランドの靴を購入した際、他の購入者の経験や私の購入履歴に基づいて、1サイズ小さいものを購入するようAIが提案してきました。これも完全にGenerative AIというわけではありませんが、Generative AIの一部を活用して、購入の意思決定のためのレコメンデーションを提供しています。
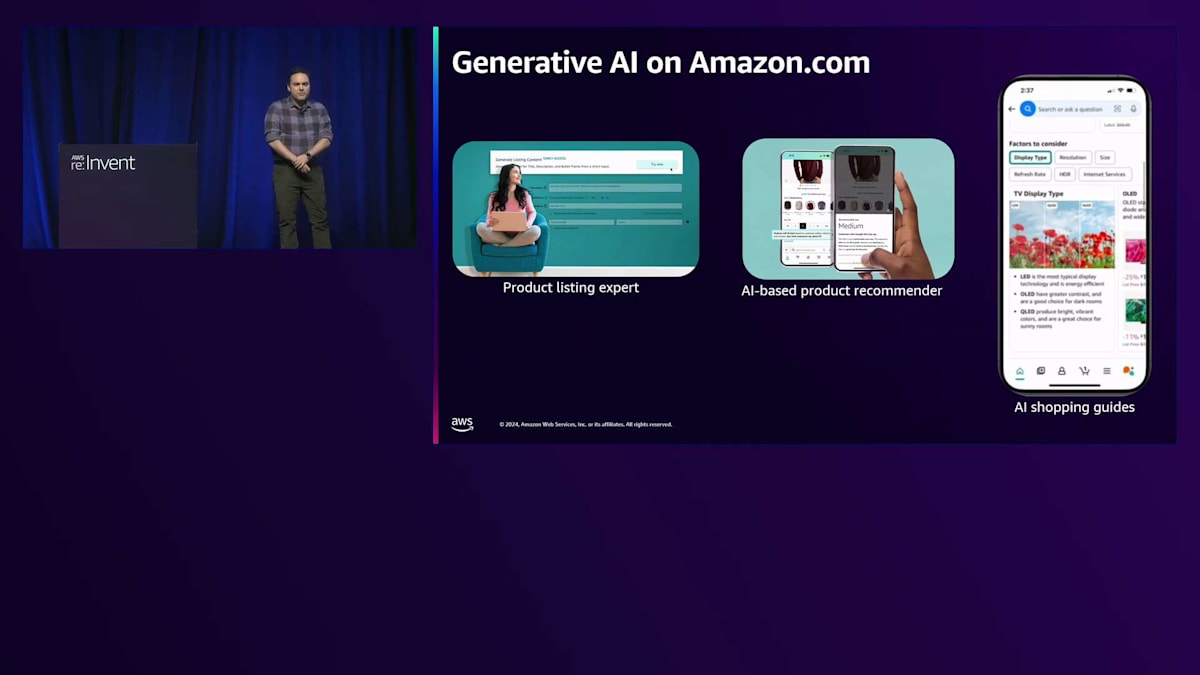
最近、AI Shopping Guidesを発表しました。これは決定木のような仕組みで動作します。例えば、モニターを購入したい場合、段階的に基本的な判断をサポートしながら、製品の推奨をフィルタリングしていきます。セッションの最後では、一部でGenerative AIを活用しています。完全なGenerative AIソリューションではありませんが、お客様により良い購買判断を提供するための重要な要素となっています。

販売者向けには、最近Ameliaを発表しました。Ameliaも会話型アシスタントですが、こちらは特にAmazonの出品者向けに特化しています。出品者は、ホリデーシーズンの準備や、商品リストの作成のベストプラクティス、ビジネスパフォーマンス、売上トレンド、サポートチケットの状況などについて質問することができます。Ameliaは、Generative AIを使用して24時間体制でこれらの質問に答え、出品者の課題解決を迅速にサポートします。現在、何千人もの出品者が利用しており、注目度は高まる一方です。Seller Universityの情報を活用し、バックエンドのすべてのデータベースを利用して出品者をサポートしています。

AmeliaはBedrockを使用していますが、会話型アシスタントではない別のアプリケーションとしてAmazon Adsから提供されているCreative Ads Generationがあります。Sponsored Products広告を出稿する私たちのお客様や出品者、広告主が直面する最大の課題の1つは、魅力的な商品画像や動画を作成することです。例えば、シャンプーの商品があり、出品者がビーチを背景にした素敵な画像を作成したい場合、背景のリクエストをプロンプトとして入力すると、Generative AIがさまざまなバージョンの背景を組み合わせて生成します。商品をクリックしてドラッグ&ドロップで配置し、商品リストに使用できる最適な位置を見つけることができます。最近では、プロンプトに基づいて短いクリップを生成する動画版も発表され、商品のカスタマーエクスペリエンスを向上させることができます。
Review HighlightsとAmazon Rufusの紹介


本日は、Amazon.comの2つのプロダクトについて詳しく見ていきます。1つ目はReview Highlights、そして2つ目は Amazon Rufusです。これらのプロダクトを使用したことがある方は手を挙げていただけますか?素晴らしいですね、多くの方が使用されているようです。Amazon.comアプリケーションで商品ページを下にスクロールすると、カスタマーレビューがありますが、それらのレビューのサマリーも表示されています。これは単なるサマリーではなく、パフォーマンスや評価などの側面がハイライトされており、その横にはセンチメントを示すカラーコーディングがあります。ポジティブな感情は緑色、ネガティブな感情はオレンジ色で表示されます。これについては今日詳しく説明します。

2つ目のAmazon Rufusは、ショッピングアシスタント、会話型アシスタント、そしてAmazonのエキスパートです。商品について質問したり、Rufusを使って検索を開始したりすることができます。私が典型的に使用する例としては、ある商品について見つけにくい具体的な質問がある場合、「この商品はこれができますか?」と尋ねます。Rufusをショッピングコンパニオンとして活用できます。 この2つのプロジェクトを選んだ理由があります。Review HighlightsとRufusは、実はお客様に一貫したカスタマーエクスペリエンスを提供しています。一方は会話型で、もう一方はよりインタラクティブな静的情報を提供するもので、これらの2つのアプリケーションはスペクトラムの両端に位置しています。
Review Highlightsは対話的な静的機能であるのに対し、Rufusは会話型です。モードの観点では、Review HighlightsはオフラインモードでのLarge Language Modelの利用です。例えば、商品をクリックした時に、レビューサマリーを計算するためにエンドポイントを待つ必要はありません。そのレビューサマリーは既に計算され、作成され、キャッシュされているのです。そのため、クリックするとすぐに、実際のレビューと同様にサマリーも見ることができます。これはLarge Language Modelのプロダクション環境におけるオフライン処理とオフラインアプリケーションであり、一方Rufusはリアルタイムです。チャットボットとリアルタイムで会話を行い、バッチ処理の非同期とストリーミングという2つの異なる例を示しています。

規模の観点では、Review Highlightsは何百万ものレビューを処理する必要があります。一部の商品では、1つの商品に対して何万件ものレビューがあります。一方Rufusは、何百万人ものお客様が低レイテンシーで利用できるようにすることが重要です。これら2つの例は、静的でオフラインな場合とリアルタイムストリーミングアプリケーションの場合における、Large Language Modelアプリケーションの幅広い適用例を示していると考えています。 今日は、私のチームが開発し構築したReview Highlightsについてお話ししたいと思います。Burakが話していたように、私たちがお客様を起点に考え、お客様とそのニーズに基づいて使用する技術や構築方法を決定したという点が、とても興味深く素晴らしいと思います。
私たちが構築したものは、おそらく少し意外に感じられるかもしれません。Generative AIについて考えるとき、想像していたよりもシンプルだったり、より制御されていたりするかもしれません。しかし一方で、私たちには解決すべき具体的なお客様のユースケースがあり、そのユースケースのために構築しました。私たちは実現したことと、その方法について非常に満足しています。そして、ガードレールやセーフティーをはじめとする、とても興味深い学びがあったと思います。
Human in the loopやコスト管理、無駄を省くことも、ここでは非常に重要で興味深い側面です。
Review Highlightsの開発と実装

私はAmazonで、この7年以上にわたって何らかの形でCustomer Reviewsに関わってきました。Amazonでは様々なことを行ってきましたが、かなり長い間Customer Reviewsに携わっています。Customer Reviewsは、ショッピング体験における最も古く、最も信頼される要素の1つです。Amazon.comで今日見つけることができる最も古くてアクティブなレビューが何年前のものだと思うか、皆さんに聞いてみたいところです。残念ながら聞くことはできませんが、お伝えしましょう - 来年で30周年を迎えます。「The Hot Zone」という本があります。そのレビューを見ると、29年前のレビューが今でも関連性を持って残っているのを見つけることができます。
これは長年提供されている機能ですが、私たちのお客様にとって非常に重要なものです。大多数のお客様がレビューを読んでおり、その多くが購入時に1ヶ月の間に複数のレビューを読んでいます。お客様からは一貫して、カスタマーレビュー、特に信頼できる正直なカスタマーレビューの存在が、ストアでの購入を決める際の重要な判断材料の一つだと伺っています。

カスタマーレビューに関する最大の課題の一つは、レビューの数が非常に多いということです。一見それは良いことのように思えます。確かに、信頼性を高めるユーザー生成コンテンツが豊富にあるわけですから。しかし、ある商品に10件のレビューがあれば全部読めるかもしれませんが、100件になると少し大変です。1,000件、10,000件、あるいは100,000件となると...実際、サイトには評価とレビューを合わせて100万件以上のユーザー生成コンテンツが投稿されている商品もあります。そうなると、それらを全て読んで理解することは事実上不可能です。
私たちに求められているのは、「群衆の知恵」の全体像をお客様に理解していただく方法を提供することです。Review Highlightsは、そのために開発した一つの仕組みです。レビューセクションを見ると、全体的なサマリーのセクションがあります。これはコーパス内の全レビューをLLMで生成した要約です。実際には、他の従来型のMLモデルとその出力を活用して要約を生成しています。全てのレビューを分析し、そのコンテンツに対して意味理解と言語モデルを適用して異なるバケットに分類し、それらのバケットにラベルを付け、各バケットにポジティブ、ニュートラル、ネガティブといった感情分析を適用しています。

このシステムを構築する際、私たちはお客様がAIやLLMの言葉をそのまま信じるのではなく、実際のレビューを確認できる証拠を提供することが重要だと考えました。そのため、それぞれの要約に対してレビューのスニペットも提供しており、お客様は「群衆の知恵」が商品について何を語っているのかを、必要に応じて深く掘り下げたり、概要だけを把握したりすることができます。
2022年11月にOpenAIがChatGPTを公開した時、その衝撃は至る所に広がりました。私たちはこの時、このような技術を活用して、カスタマーレビューを通じてお客様の信頼できる購買判断をサポートできるのではないかと考えました。私たちの考え方はこうです - カスタマーレビューを通じて、お客様が返品することなく、満足のいく購買判断ができるようにサポートしたい。お客様に「はい、レビューを読んで、他の人々の意見を理解した上で、購入するかしないかを決めました。その判断に非常に満足しています」と言っていただけることを目指しています。
この新製品を構築するにあたり、お客様にとって有用で、かつ信頼を維持できるものにするために必要な要件について検討しました。まず正確性が不可欠です - レビュー、レビュアー、事実について誤った情報を生成してはいけません。正確性とデータドリブンであることを確保するには、優れたHuman-in-the-loopプロセスとモニタリングが必要でしょう。また、お客様が私たちの作業を確認できるよう、責任を持って対応する必要があります。透明性とセキュリティも重要です。さらに、プロセスに時間や摩擦を加えることなく、ほぼ遅延なくお客様に提供できる必要があります。要約は素晴らしいものですが、要約だけでは不十分なので、お客様に根拠となる情報も提供しています。
最後に、そして決して重要度が低くないのが、コスト効率の良さです。22の異なるマーケットプレイス、28の言語、そして長年にわたってお客様から投稿された65億件以上のコンテンツに対応するために、迅速かつコスト効率の良い方法が必要でした。そこで、オフラインのバッチ処理を採用することにしました。

数枚前のスライドで触れたように、私たちは最終的に複数の異なるモデルを組み合わせてこの出力を提供することにしました。コストを抑え、精度を向上させ、さまざまな場所でエクスポートして使用できる有用なアーティファクトを作成するため、従来のNLPとLarge Language Models(LLMs)は必要な場合にのみ使用しています。新しい魅力的なツールを単にそれが存在するという理由で使用するのではなく、永続的な顧客の問題を解決することに焦点を当てたアプローチを取りました。特定のソリューションにこだわることなく、自然言語処理における長年の取り組みとLLMsを組み合わせることで、両者の利点を活かすことができました。

お客様のレビュー(私たちの生データ)を取り、さまざまな従来型MLとLLMsを使用します。また、AWS Inferentia 2チップを活用することで、お客様が必要とする時にキャッシュして提供できるコンテンツと情報を生成できます。キャッシュされている間も、新しいコンテンツが到着するたびに要約やレビューを更新するため、常に最新の状態を保っています。新しい本が出版され、多くのレビューが寄せられた場合、私たちは新しいコンテンツを常にモニタリングし、これらのプロセスを再実行して新しいアスペクトを生成するかどうかを判断します。新しいアスペクトを開発し、十分な情報がある場合は、新しい要約を作成するワークフローがトリガーされます。

カスタマーレビューはショッピングページだけでなく、検索から広告まで、Amazonのさまざまなシステムで使用されているため、データが正規であり、配信可能であることが重要です。私たちはBurakやAWSの他の同僚と協力して、新しい機能を追加しました。現在、すべてのSageMakerユーザーが利用できるAmazon SageMakerのBatch Transformを実現しました。これにより、レビューのオフラインバッチ処理が可能になります。競合と比べて40%優れた価格性能比を持つInferentia 2チップセットを使用しています。この作業を事前に行うことで、アスペクトデータやその他の情報を処理した後、一部のタスクにより小規模なLLMsを使用することができ、幻覚を抑制し、適切なガードレールを備えた質の高い結果をお客様に提供することができました。

LLMやAIに興味のある方なら誰でもご存知の通り、私たちが学んできたことの一つは、人間からのフィードバックとその質が非常に重要だということです。私たちが構築したすべてのシステムに加えて、Amazonがクロスリンガルモデルでサポートしているすべての言語をカバーする人間のアノテーターチームがいます。彼らはタイムリーで一貫性のあるフィードバックを提供し、それによって私たちは常に出力を監査し、更新し、改善することができています。私たちは、顧客の期待に応え、適切な情報を提供できるよう、モデルに関する様々なガードレールを確立しています。
私たちは人間のアノテーターと共に常に改善を重ね、より良いフィードバックを得るためのモニタリングを行っています。また、エスカレーションを通じて顧客から直接提供される情報や、彼らが提供するデータ、ショッピング行動、消費パターンにも注意を払っています。アノテーションを提供するために直接私たちと協力してくれる人々の存在は、継続的な成功の重要な要素となっています。
この機能は1年前に最小規模の形で最初にローンチしました。この1年間を通じて、毎月少なくとも2~3の異なる実験をローンチし、機能のほぼすべての側面を改善しながら、顧客価値を高めてきました。これも重要なポイントです - 私たちはシステムを構築してローンチしましたが、それで終わりではありませんでした。成功を測定すると同時に、失敗も測定し、言葉が不自然な箇所や、人々にとって興味深くない側面、適切な購買判断の支援ができていない部分を特定し、顧客のために製品を磨き上げるロードマップを持って常に改善を重ねています。

最終的に、私たちはこの一つの機能を構築しました。これは、RJがこれから皆さんにお話しする、よりオープンエンドな会話型LLMアプリケーションとは対照的な例です。この場合、私たちはLLMを会話支援を超えて大規模に活用しましたが、それは非常に制約された使用事例でした。なぜなら、顧客体験と期待から逆算して、コスト削減と効率向上のために従来型の機械学習とLLMを組み合わせたからです。この証拠として - 正確な数字は共有できませんが、もし共有できたら、そのコストの低さに驚かれることでしょう。LLMはエネルギーと計算時間の両面で非常に贅沢だという評判がありますが、私たちの構築方法によって、非常にコスト効率が高くて効率的なAIソリューションを実現できることを、このプロジェクトは証明しています。
さらに、開発過程で作成したアーティファクトは、Webサイト上の他の多くのアプリケーションでも活用可能で販売可能なものとなっています。顧客の反応は非常に良好で、Rufusなど、Amazonの他のチームとも連携しながら改善を続けています。それでは、RJに引き継ぎたいと思います。彼は、オープンエンドな会話型ショッピングアシスタントとAIという、もう一つの側面についてお話しします。
Amazon Rufusの開発と技術的課題

私はAmazonのエンジニアで、この1年間Rufusの開発に携わってきました。先ほどの方は30年のプロジェクトについて話されましたが、私たちのプロジェクトはまだ1周年を迎えていない若いものです。数ヶ月前にリリースし、現在は米国の全顧客向けにデスクトップとモバイルで利用可能となっています。RufusはAIを活用したショッピングアシスタントです。私たちが目指しているのは、お客様が十分な情報を得た上で判断できるよう支援することで、そのために顧客からの幅広い質問に答えています。この課題に取り組む中で、最新のGenerative AI技術を活用できることに気づきました。技術を検討する際、コストだけでなく、お客様が何分も待たされることなく、良好なショッピング体験を得られることを重視しました。そのため、より対話的なアプローチを実現するために、戦略、製品、インフラの面でも革新を行う必要がありました。

課題解決にあたり、私たちが学んだのは、ショッピング専用にカスタマイズされたLLMが必要だということでした。なぜなら、ショッピングに関するデータセットは非常に特殊だからです。他のモデルを使用することは避けたいと考えました。独自のLLMを使用することで、推論に重点を置いたパラメータの学習と調整が可能となり、コストを削減できるメリットがありました。LLMだけでなく、ショッピングセッションには最新のデータセットや購買行程に関する検索ソースも必要です。例えば、レザーシューズを探している顧客をアシストする際、その人のショッピング履歴を参照して検索ストアを取得します。そのため、私たちは多くのエビデンスリソースを活用したRetrieval Augmented Generationというアプローチを採用しています。ここでいうエビデンスとは、推論を通じてより良い出力を得るためのモデルへの入力のことです。
実際のトレーニングと予測の過程では、Reinforcement Learningを通じて応答の品質を向上させています。RufusがどのようにしてこのAIアプリケーションを処理しているかについての科学的なアプローチは、下部に記載されているブログで詳しく説明しています。

解決策は見つかりましたが、Amazonならではの課題もありました。お客様が最も重視することの1つは、ユーザー体験です。回答を得るまでに長時間待たせるようなモデルで、ユーザー体験を損なうことは避けたいと考えました。私たちが注目した課題の1つは、LLMモデルのUser-Perceived Latencyです。User-Perceived Latencyとは、Amazonのアプリやデスクトップで最初のトークンが表示されるまでの時間を指します。私たちはこのUser-Perceived Latencyを最適化し、ソースと推論ハードウェアを微調整して非常に低く抑えています。これは、本番環境への展開を始めた時に理解した最初の課題でした。
Amazonには何百万ものお客様がいて、Amazonの多くのタッチポイントと統合しようとしたとき、コストが大幅に増加することに気づきました。コストだけでなく、その支出に見合うだけのハードウェアも十分に確保できていませんでした。そこで2つ目の最適化指標として、入力トークンではなく生成されたトークン100万件あたりのコストに着目しました。本番環境では、生成されたトークン100万件あたりのコストに注目する必要があります。なぜなら、モデルの入力として大きなコンテキスト長を持ちながら、「はい」や「いいえ」のような単一トークンの回答を生成する場合もあれば、少ない入力トークンから要約を生成する場合もあるからです。モデルのトレーニング時は品質に重点を置きますが、本番環境では生成されたトークン100万件あたりのコストにより重点を置く必要があります。
3番目の柱はハードウェアの希少性です。私たちは利用可能なハードウェアを最大限に活用し、その効率性を高め、キャパシティのプロビジョニング時に最大限のスループットを確保する必要があります。これら3つの柱は、モデルを本番環境に展開する際の重要なポイントであり、これらが主要な技術的課題でした。

ここで、顧客のクエリを処理する際のRufusのアーキテクチャについて詳しくご説明したいと思います。顧客が「トレイルシューズを買うべき?」といったクエリを入力すると、先ほど説明したRAGアーキテクチャを使用します。Wikipediaやショッピング履歴、詳細な商品情報など、さまざまな情報源からデータを取得します。これらの入力をクエリと共にLLM推論に渡します。従来のLLM推論では単にテキストを出力して表示するだけですが、Amazonでは応答に意味を持たせるためにハイドレーションを行う必要があります。ハイドレーションとは、何かにタグを付け、そのタグをアプリケーション内で画像を表示するために埋め込む方法です。この例では、Amazon検索と連携してSalomon's Men Extra Ultraハイキングシューズを表示しています。モデルは単に検索用のタグを付けるだけで、その後で画像を表示できるようになります。
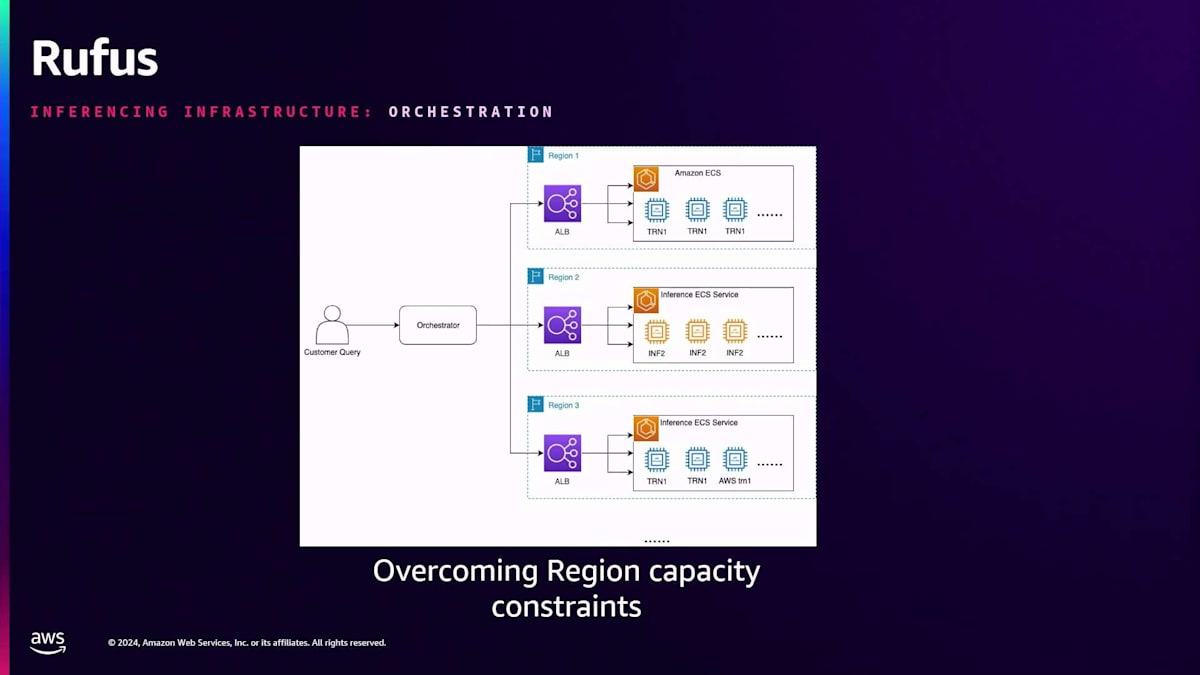
オーケストレーションのインフラ面での課題について見てみると、前述の通り、1つのAWS Regionでキャパシティが不足しています。従来は1つのAWS Regionを使用するのが一般的でしたが、キャパシティの制約により、複数のAWS Regionを利用して応答をストリーミングで返す必要がありました。ストリーミングアーキテクチャを採用しているため、UPLのレイテンシーを克服することができます。この例では、顧客のクエリが情報源を通じてオーケストレーターに届くと、そのRegionのスループットとキャパシティに基づいてトラフィックをルーティングします。そのため、クロスリージョンのキャパシティに投資する必要があり、これによってRegionの制約を実際に克服することができました。

もう1つ興味深い点として、推論ストリーミングスタックについてお話ししたいと思います。私たちはネイティブサービスとTriton Inference ServerのNvidia Python Backendを使用しました。本番環境へのローンチ時には、推論サービスのスループットを向上させるVLLMを使用しました。スケールアップに伴い、AWS Neuron SDKとハードウェアを実装しました。このアーキテクチャの利点は、異なる種類のハードウェアを置き換えて実験を行うことができ、特定のハードウェアのキャパシティが増えた場合でも、スタックの上位層に大きな変更を加えることなく置き換えられることです。このアーキテクチャにより、そのRegionでアクセス可能なインスタンスでキャパシティが利用可能になった時点で、バランスを取ることができました。

これがストリーミングスタックです。私たちが理解したのは、大規模な環境でのこれらのインスタンスのスループットが、インスタンスあたり1トランザクション未満だということです。これは、応答が遅延し顧客が適時に応答を受け取れないため、ロードバランサーや応答の遅延をファインチューニングできないことを意味します。そこで、静的バッチ処理の代わりにContinuous Batchingを導入しました。この例で示すように、Dynamic Batchingでは、リクエストが来た時に応答が返ってくるまで待つ必要があります。しかしContinuous Batchingでは、最初の応答が完了すると、その応答を終了し、次の応答が処理キューに入ることができます。Continuous Batchingにより、制約のあるハードウェアでより大きなスループットを実現し、顧客がリクエストのためにキューで待つ必要がないためレイテンシーが低減され、ハードウェアからより高い同時実行性のサポートを得ることができました。

Rufusを本番環境に導入する際に得た重要な学びがありました。通常、Amazonスケールのウェブアプリケーションを提供する場合、各インスタンスは自然と数千または数百のリクエストのスループットを処理します。しかし、LLMベースのアプリケーションの構築を始めたとき、スループットは非常に低く、一桁かそれ以下でした。各ホストが処理できる同時リクエスト(実際にはシステムに入ってくるユーザークエリ)の数は非常に限られていました。直面した2つ目の課題は、キャパシティの制約により、全リージョンやサブリージョンで統一されたキャパシティを確保できないことでした。負荷が均一に分散されないことがわかっている状況で、また仮に均一に分散されたとしても各マシンのスループットを事前に決定できない状況で、このLoad Balancerの問題に対処する必要がありました。

このセッションから得られた最初の重要な学びは、推論ハードウェアに合わせてLLMを最適化することです。私たちは、推論を実行するハードウェアに基づいてパラメータとモデルサイズを調整しました。アーキテクチャのパラメータを2の倍数になるように微調整しました。トレーニングでは32ビットと16ビットを使用してモデルの品質を損なわないようにしましたが、推論については、精度を下げても品質を維持できるかどうかを検証しました。8-bit Quantizationを実装することで、お客様への結果をほぼ同等に保ちながら、メモリと計算のフットプリントを削減できることがわかりました。
これにより、特定のインスタンスに制限されることなく、より多くのハードウェアをプールに追加できるようになり、モデルサイズを妥協することなく拡大できました。より高性能なインスタンスでスケールアップする代わりに、ハードウェアプールを拡充することでモデルサイズを増やすことができました。Neuron SDKを使用して、推論ハードウェアの重要なプロファイリングポイントを最適化しました。レイテンシーを検証する際は、KV Cachingやさまざまな最適化テクニックに焦点を当てました。Neuron SDKのデバッグおよびプロファイリング機能への投資により、ボトルネックを特定し、コンパイラーチームやNeuron SDKチームと協力してパフォーマンスを向上させることができました。
Prime DayやCyber Mondayのような大規模イベントにおいて、キャパシティパフォーマンスの月次改善が非常に重要であることが証明されました。これらの最適化とスループットの20-30%の一貫した改善により、AWSプールから無限のキャパシティを必要とすることなく、Prime Dayを成功裏に運営することができました。このスタック上でPrime Dayを完全に展開した方法についてのブログを公開しました。

重要なポイントは、これらの機能がAWS Inferentia 2スタック上で実現可能だということです。USやUKで体験されるRufusの推論は、完全にAWS Inferentia 2スタック上で動作しています。この過程では、広範なプロファイリング、デバッグ、他のアクセラレーターとのパフォーマンス比較が必要でした。AWS Inferentia 2が市場に投入されたことで、ハードウェアの多様化に成功し、効果的にスケールアップすることができ、IMRコストの管理に役立つコスト構造を導入することができました。

私たちの成果は結果に表れています。First Tokenのレンダリングにかかる遅延を1秒未満に削減しました。LLMを使用して数百万人のお客様にPrime Dayのサービスを、何の問題もなく提供することができました。Annapurnaチップを使用してRufusをPrime Dayで完全にローンチし、お客様の厳しい遅延要件を満たすことができました。私たちは、要求の厳しいお客様の期待に常に応え続けることを信念としています。

重要な結論として、優れたFoundation Modelは不可欠ですが、本番環境での運用コストと実装は、お客様とのフィードバックループを完結させることが重要です。機能面だけでなく、お客様とのエンゲージメントについても革新を続ける必要があります。さらに、お客様の体験に焦点を当て、必要に応じてシステムのアーキテクチャを再設計する準備が必要です。LLMプロジェクト以前、Amazonアプリ内のほとんどの呼び出しは同期的でしたが、お客様のニーズに応えるためにスタック全体でストリーミングサポートを実装しました。最後に、複数のアクセラレーターへの投資が、お客様へのリーチとフットプリントを拡大する上で重要です。スケーリングが成功の鍵となる場合、単一のアクセラレーターに依存して制限されるべきではありません。
Generative AIプロジェクトからの重要な学び

RJ、ありがとうございます。JuanとRJから、彼らの学びと解決策について聞かせていただきました。 このセッションの最後に、いくつかの重要な学びを共有させていただきたいと思います。お客様体験を起点とした考え方について聞いていただきました。課題に直面したとき、私たちが達成しようとしていることと、お客様が求めているものについて、一歩下がって考える必要があります。例えば、Wangのケースでは、お客様に代わって要約を計算し、情報を抽出することを決定しました。
これは、お客様がスピードと利便性を求めているからこそ実施されました。ルーファーズのケースでは、推論の最適化に焦点を当て、スケールを考慮し、最高のお客様体験のための推論の最適化に取り組みました。常にお客様体験に立ち返り、必要に応じて設計を見直す必要があります。
本番環境への移行は、おそらく最も重要な学びの一つです。私たちのグループは、多くのAmazonグループのGenerative AIプロジェクトを支援していますが、Proof of Conceptは非常にうまくいくものの、Generative AIを本番環境に移行しようとすると問題が発生するケースを多く見てきました。Jupyterでは動作し、POCは成功したものの、本番環境でスケールすると、スケーラビリティや精度などの問題が見えてきます。本番環境を常に意識することは、すべてのケースにおいて非常に重要な学びです。なぜなら、設計からやり直す必要が出てくる可能性があるからです。Rufusのケースでは、目指すスケールに対応するため、異なるリージョンについて検討する必要がありました。

AWSのInferentiaとTrainiumについて多くのお話をさせていただきました。これらはAmazonが開発したAnnapurnaチップセットです。これらのチップセットは、競合他社と比べて最大40%のコスト削減を実現します。最終的に私たちが目指しているのは、単なる成功ではなく、InferentiaやTrainiumに移行することで、コスト、レイテンシー、そしてサステナビリティの面での向上によってROIを高めることです。実際、TrainiumとInferentiaはさらに優れたサステナビリティを実現できることが分かっています。これで本日のプレゼンテーションを終わらせていただきます。先ほど申し上げた通り、質疑応答は承れませんが、これから
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion