FastViT YOLO 実装と解説(調整中)
調整中記事 ディスカッション求む!
[1] Pavan Kumar Anasosalu Vasu, James Gabriel, Jeff Zhu, Oncel Tuzel, Anurag Ranjan
"FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization"
ICCV 2023, 2023-08-13
https://arxiv.org/abs/2303.14189
https://github.com/apple/ml-fastvit
[2] Jocher, Glenn and Chaurasia, Ayush and Qiu, Jing
"YOLO by Ultralytics"
https://github.com/ultralytics/ultralytics
この記事ではApple MLチームの発表した高速なCNN FastViTを用いて、YOLO v8のアーキテクチャを真似した自作モデルを作り、各種モデルの設計を簡単に解説していきます。
特にBBox Anchor周りの理解にあたって以下の記事がとても参考になりましたので読むべき。
概要
ReparameterizeなNNモジュールをメインに持つモダンなYOLOを実際に作ってみる。
これにより速度性能の高いモデルが作れるかどうか、データの学習まで行って評価する。
FastViT
以前解説したMobileOneと同様に、reparameterizeを用いて高速化した高効率モデルである。
次の図の通り、他モデルと比べEfficientNetv2やConvNeXtなどの競争力のあるモデルと比べても高速で高精度な推論ができている。
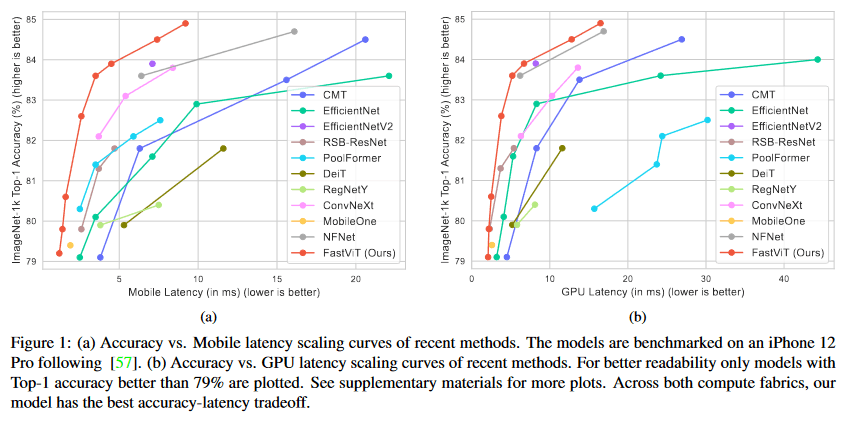 [1]より、iPhone12上でのベチマークとGPU上でのベンチマーク
[1]より、iPhone12上でのベチマークとGPU上でのベンチマーク
この速度を可能にするのが学習時と推論時のマイクロアーキテクチャの変更で、学習に有効だがメモリ効率の悪いConvの分岐などの計算を、推論モードでは順方向の線形構造に再設計することで推論速度を効率化した。
 [1]より、各ブロックの設計とreparameterize後の設計
[1]より、各ブロックの設計とreparameterize後の設計
details
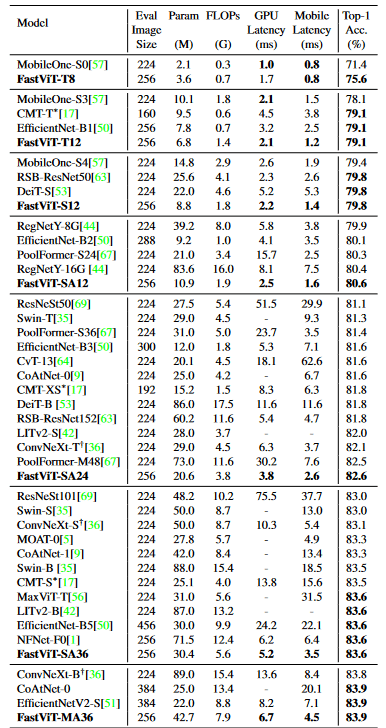 [1]より、ImageNetベンチマークの比較
[1]より、ImageNetベンチマークの比較
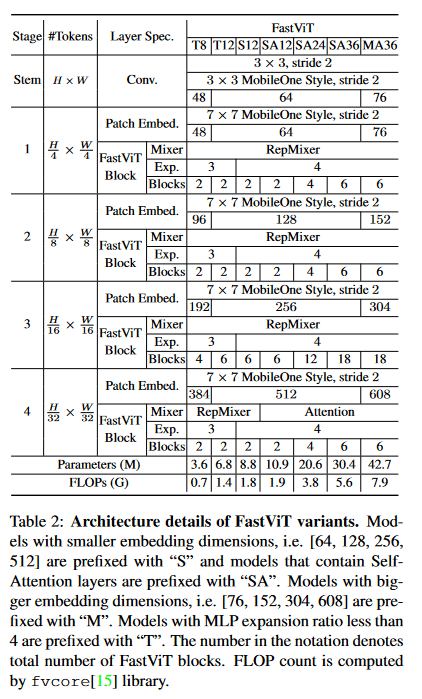 [1]より、モデルのスケーリング
[1]より、モデルのスケーリング
たとえば、SA-24スケールは次の構成になっている。
timm FastViT SA24
===============================================================================================
Layer (type (var_name)) Input Shape
===============================================================================================
FastVit (FastVit) [1, 3, 256, 256]
├─Sequential (stem) [1, 3, 256, 256]
│ └─MobileOneBlock (0) [1, 3, 256, 256]
│ │ └─ConvNormAct (conv_scale) [1, 3, 256, 256]
│ │ │ └─Conv2d (conv) [1, 3, 256, 256]
│ │ │ └─BatchNormAct2d (bn) [1, 64, 128, 128]
│ │ └─ModuleList (conv_kxk) --
│ │ │ └─ConvNormAct (0) [1, 3, 256, 256]
│ │ │ │ └─Conv2d (conv) [1, 3, 256, 256]
│ │ │ │ └─BatchNormAct2d (bn) [1, 64, 128, 128]
│ │ └─GELU (act) [1, 64, 128, 128]
│ └─MobileOneBlock (1) [1, 64, 128, 128]
│ │ └─ConvNormAct (conv_scale) [1, 64, 128, 128]
│ │ │ └─Conv2d (conv) [1, 64, 128, 128]
│ │ │ └─BatchNormAct2d (bn) [1, 64, 64, 64]
│ │ └─ModuleList (conv_kxk) --
│ │ │ └─ConvNormAct (0) [1, 64, 128, 128]
│ │ │ │ └─Conv2d (conv) [1, 64, 128, 128]
│ │ │ │ └─BatchNormAct2d (bn) [1, 64, 64, 64]
│ │ └─GELU (act) [1, 64, 64, 64]
│ └─MobileOneBlock (2) [1, 64, 64, 64]
│ │ └─BatchNorm2d (identity) [1, 64, 64, 64]
│ │ └─ModuleList (conv_kxk) --
│ │ │ └─ConvNormAct (0) [1, 64, 64, 64]
│ │ │ │ └─Conv2d (conv) [1, 64, 64, 64]
│ │ │ │ └─BatchNormAct2d (bn) [1, 64, 64, 64]
│ │ └─GELU (act) [1, 64, 64, 64]
├─Sequential (stages) --
│ └─FastVitStage (0) [1, 64, 64, 64]
│ │ └─Sequential (blocks) [1, 64, 64, 64]
│ │ │ └─RepMixerBlock (0) [1, 64, 64, 64]
│ │ │ │ └─RepMixer (token_mixer) [1, 64, 64, 64]
│ │ │ │ │ └─MobileOneBlock (mixer) [1, 64, 64, 64]
│ │ │ │ │ │ └─BatchNorm2d (identity) [1, 64, 64, 64]
│ │ │ │ │ │ └─ConvNormAct (conv_scale) [1, 64, 64, 64]
│ │ │ │ │ │ │ └─Conv2d (conv) [1, 64, 64, 64]
│ │ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 64, 64, 64]
│ │ │ │ │ │ └─ModuleList (conv_kxk) --
│ │ │ │ │ │ │ └─ConvNormAct (0) [1, 64, 64, 64]
│ │ │ │ │ └─MobileOneBlock (norm) [1, 64, 64, 64]
│ │ │ │ │ │ └─BatchNorm2d (identity) [1, 64, 64, 64]
│ │ │ │ │ └─LayerScale2d (layer_scale) [1, 64, 64, 64]
│ │ │ │ └─ConvMlp (mlp) [1, 64, 64, 64]
│ │ │ │ │ └─ConvNormAct (conv) [1, 64, 64, 64]
│ │ │ │ │ │ └─Conv2d (conv) [1, 64, 64, 64]
│ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 64, 64, 64]
│ │ │ │ │ └─Conv2d (fc1) [1, 64, 64, 64]
│ │ │ │ │ └─GELU (act) [1, 256, 64, 64]
│ │ │ │ │ └─Dropout (drop) [1, 256, 64, 64]
│ │ │ │ │ └─Conv2d (fc2) [1, 256, 64, 64]
│ │ │ │ │ └─Dropout (drop) [1, 64, 64, 64]
│ │ │ │ └─LayerScale2d (layer_scale) [1, 64, 64, 64]
│ │ │ └─RepMixerBlock (1) [1, 64, 64, 64]
│ │ │ │ └─RepMixer (token_mixer) [1, 64, 64, 64]
...
│ │ │ └─RepMixerBlock (3) [1, 64, 64, 64]
│ │ │ │ └─RepMixer (token_mixer) [1, 64, 64, 64]
│ │ │ │ │ └─MobileOneBlock (mixer) [1, 64, 64, 64]
│ │ │ │ │ │ └─BatchNorm2d (identity) [1, 64, 64, 64]
│ │ │ │ │ │ └─ConvNormAct (conv_scale) [1, 64, 64, 64]
│ │ │ │ │ │ │ └─Conv2d (conv) [1, 64, 64, 64]
│ │ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 64, 64, 64]
│ │ │ │ │ │ └─ModuleList (conv_kxk) --
│ │ │ │ │ │ │ └─ConvNormAct (0) [1, 64, 64, 64]
│ │ │ │ │ └─MobileOneBlock (norm) [1, 64, 64, 64]
│ │ │ │ │ │ └─BatchNorm2d (identity) [1, 64, 64, 64]
│ │ │ │ │ └─LayerScale2d (layer_scale) [1, 64, 64, 64]
│ │ │ │ └─ConvMlp (mlp) [1, 64, 64, 64]
│ │ │ │ │ └─ConvNormAct (conv) [1, 64, 64, 64]
│ │ │ │ │ │ └─Conv2d (conv) [1, 64, 64, 64]
│ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 64, 64, 64]
│ │ │ │ │ └─Conv2d (fc1) [1, 64, 64, 64]
│ │ │ │ │ └─GELU (act) [1, 256, 64, 64]
│ │ │ │ │ └─Dropout (drop) [1, 256, 64, 64]
│ │ │ │ │ └─Conv2d (fc2) [1, 256, 64, 64]
│ │ │ │ │ └─Dropout (drop) [1, 64, 64, 64]
│ │ │ │ └─LayerScale2d (layer_scale) [1, 64, 64, 64]
│ └─FastVitStage (1) [1, 64, 64, 64]
│ │ └─PatchEmbed (downsample) [1, 64, 64, 64]
│ │ │ └─Sequential (proj) [1, 64, 64, 64]
│ │ │ │ └─ReparamLargeKernelConv (0) [1, 64, 64, 64]
│ │ │ │ │ └─ConvNormAct (large_conv) [1, 64, 64, 64]
│ │ │ │ │ │ └─Conv2d (conv) [1, 64, 64, 64]
│ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 128, 32, 32]
│ │ │ │ │ └─ConvNormAct (small_conv) [1, 64, 64, 64]
│ │ │ │ │ │ └─Conv2d (conv) [1, 64, 64, 64]
│ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 128, 32, 32]
│ │ │ │ └─MobileOneBlock (1) [1, 128, 32, 32]
│ │ │ │ │ └─BatchNorm2d (identity) [1, 128, 32, 32]
│ │ │ │ │ └─ModuleList (conv_kxk) --
│ │ │ │ │ │ └─ConvNormAct (0) [1, 128, 32, 32]
│ │ │ │ │ │ │ └─Conv2d (conv) [1, 128, 32, 32]
│ │ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 128, 32, 32]
│ │ │ │ │ └─GELU (act) [1, 128, 32, 32]
│ │ └─Sequential (blocks) [1, 128, 32, 32]
│ │ │ └─RepMixerBlock (0) [1, 128, 32, 32]
│ │ │ │ └─RepMixer (token_mixer) [1, 128, 32, 32]
│ │ │ │ │ └─MobileOneBlock (mixer) [1, 128, 32, 32]
│ │ │ │ │ │ └─BatchNorm2d (identity) [1, 128, 32, 32]
│ │ │ │ │ │ └─ConvNormAct (conv_scale) [1, 128, 32, 32]
│ │ │ │ │ │ │ └─Conv2d (conv) [1, 128, 32, 32]
│ │ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 128, 32, 32]
│ │ │ │ │ │ └─ModuleList (conv_kxk) --
│ │ │ │ │ │ │ └─ConvNormAct (0) [1, 128, 32, 32]
│ │ │ │ │ └─MobileOneBlock (norm) [1, 128, 32, 32]
│ │ │ │ │ │ └─BatchNorm2d (identity) [1, 128, 32, 32]
│ │ │ │ │ └─LayerScale2d (layer_scale) [1, 128, 32, 32]
│ │ │ │ └─ConvMlp (mlp) [1, 128, 32, 32]
│ │ │ │ │ └─ConvNormAct (conv) [1, 128, 32, 32]
│ │ │ │ │ │ └─Conv2d (conv) [1, 128, 32, 32]
│ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 128, 32, 32]
│ │ │ │ │ └─Conv2d (fc1) [1, 128, 32, 32]
│ │ │ │ │ └─GELU (act) [1, 512, 32, 32]
│ │ │ │ │ └─Dropout (drop) [1, 512, 32, 32]
│ │ │ │ │ └─Conv2d (fc2) [1, 512, 32, 32]
│ │ │ │ │ └─Dropout (drop) [1, 128, 32, 32]
│ │ │ │ └─LayerScale2d (layer_scale) [1, 128, 32, 32]
│ │ │ └─RepMixerBlock (1) [1, 128, 32, 32]
...
│ │ │ └─RepMixerBlock (11) [1, 256, 16, 16]
│ │ │ │ └─RepMixer (token_mixer) [1, 256, 16, 16]
│ │ │ │ │ └─MobileOneBlock (mixer) [1, 256, 16, 16]
│ │ │ │ │ │ └─BatchNorm2d (identity) [1, 256, 16, 16]
│ │ │ │ │ │ └─ConvNormAct (conv_scale) [1, 256, 16, 16]
│ │ │ │ │ │ │ └─Conv2d (conv) [1, 256, 16, 16]
│ │ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 256, 16, 16]
│ │ │ │ │ │ └─ModuleList (conv_kxk) --
│ │ │ │ │ │ │ └─ConvNormAct (0) [1, 256, 16, 16]
│ │ │ │ │ └─MobileOneBlock (norm) [1, 256, 16, 16]
│ │ │ │ │ │ └─BatchNorm2d (identity) [1, 256, 16, 16]
│ │ │ │ │ └─LayerScale2d (layer_scale) [1, 256, 16, 16]
│ │ │ │ └─ConvMlp (mlp) [1, 256, 16, 16]
│ │ │ │ │ └─ConvNormAct (conv) [1, 256, 16, 16]
│ │ │ │ │ │ └─Conv2d (conv) [1, 256, 16, 16]
│ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 256, 16, 16]
│ │ │ │ │ └─Conv2d (fc1) [1, 256, 16, 16]
│ │ │ │ │ └─GELU (act) [1, 1024, 16, 16]
│ │ │ │ │ └─Dropout (drop) [1, 1024, 16, 16]
│ │ │ │ │ └─Conv2d (fc2) [1, 1024, 16, 16]
│ │ │ │ │ └─Dropout (drop) [1, 256, 16, 16]
│ │ │ │ └─LayerScale2d (layer_scale) [1, 256, 16, 16]
│ └─FastVitStage (3) [1, 256, 16, 16]
│ │ └─PatchEmbed (downsample) [1, 256, 16, 16]
│ │ │ └─Sequential (proj) [1, 256, 16, 16]
│ │ │ │ └─ReparamLargeKernelConv (0) [1, 256, 16, 16]
│ │ │ │ │ └─ConvNormAct (large_conv) [1, 256, 16, 16]
│ │ │ │ │ │ └─Conv2d (conv) [1, 256, 16, 16]
│ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 512, 8, 8]
│ │ │ │ │ └─ConvNormAct (small_conv) [1, 256, 16, 16]
│ │ │ │ │ │ └─Conv2d (conv) [1, 256, 16, 16]
│ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 512, 8, 8]
│ │ │ │ └─MobileOneBlock (1) [1, 512, 8, 8]
│ │ │ │ │ └─BatchNorm2d (identity) [1, 512, 8, 8]
│ │ │ │ │ └─ModuleList (conv_kxk) --
│ │ │ │ │ │ └─ConvNormAct (0) [1, 512, 8, 8]
│ │ │ │ │ │ │ └─Conv2d (conv) [1, 512, 8, 8]
│ │ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 512, 8, 8]
│ │ │ │ │ └─GELU (act) [1, 512, 8, 8]
│ │ └─RepConditionalPosEnc (pos_emb) [1, 512, 8, 8]
│ │ │ └─Conv2d (pos_enc) [1, 512, 8, 8]
│ │ └─Sequential (blocks) [1, 512, 8, 8]
│ │ │ └─AttentionBlock (0) [1, 512, 8, 8]
│ │ │ │ └─BatchNorm2d (norm) [1, 512, 8, 8]
│ │ │ │ └─Attention (token_mixer) [1, 512, 8, 8]
│ │ │ │ │ └─Linear (qkv) [1, 64, 512]
│ │ │ │ │ └─Linear (proj) [1, 64, 512]
│ │ │ │ │ └─Dropout (proj_drop) [1, 64, 512]
│ │ │ │ └─LayerScale2d (layer_scale_1) [1, 512, 8, 8]
│ │ │ │ └─ConvMlp (mlp) [1, 512, 8, 8]
│ │ │ │ │ └─ConvNormAct (conv) [1, 512, 8, 8]
│ │ │ │ │ │ └─Conv2d (conv) [1, 512, 8, 8]
│ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 512, 8, 8]
│ │ │ │ │ └─Conv2d (fc1) [1, 512, 8, 8]
│ │ │ │ │ └─GELU (act) [1, 2048, 8, 8]
│ │ │ │ │ └─Dropout (drop) [1, 2048, 8, 8]
│ │ │ │ │ └─Conv2d (fc2) [1, 2048, 8, 8]
│ │ │ │ │ └─Dropout (drop) [1, 512, 8, 8]
│ │ │ │ └─LayerScale2d (layer_scale_2) [1, 512, 8, 8]
│ │ │ └─AttentionBlock (1) [1, 512, 8, 8]
...
│ │ │ └─AttentionBlock (3) [1, 512, 8, 8]
│ │ │ │ └─BatchNorm2d (norm) [1, 512, 8, 8]
│ │ │ │ └─Attention (token_mixer) [1, 512, 8, 8]
│ │ │ │ │ └─Linear (qkv) [1, 64, 512]
│ │ │ │ │ └─Linear (proj) [1, 64, 512]
│ │ │ │ │ └─Dropout (proj_drop) [1, 64, 512]
│ │ │ │ └─LayerScale2d (layer_scale_1) [1, 512, 8, 8]
│ │ │ │ └─ConvMlp (mlp) [1, 512, 8, 8]
│ │ │ │ │ └─ConvNormAct (conv) [1, 512, 8, 8]
│ │ │ │ │ │ └─Conv2d (conv) [1, 512, 8, 8]
│ │ │ │ │ │ └─BatchNormAct2d (bn) [1, 512, 8, 8]
│ │ │ │ │ └─Conv2d (fc1) [1, 512, 8, 8]
│ │ │ │ │ └─GELU (act) [1, 2048, 8, 8]
│ │ │ │ │ └─Dropout (drop) [1, 2048, 8, 8]
│ │ │ │ │ └─Conv2d (fc2) [1, 2048, 8, 8]
│ │ │ │ │ └─Dropout (drop) [1, 512, 8, 8]
│ │ │ │ └─LayerScale2d (layer_scale_2) [1, 512, 8, 8]
(以下MobileOne + Classification Head)
YOLOv8
基礎的なCSPブロックを用いたPAFPN構造で、アンカーフリーなBBox HeadとClassification Headを持つ。この実装を参考にしながらモデルを作っていく。
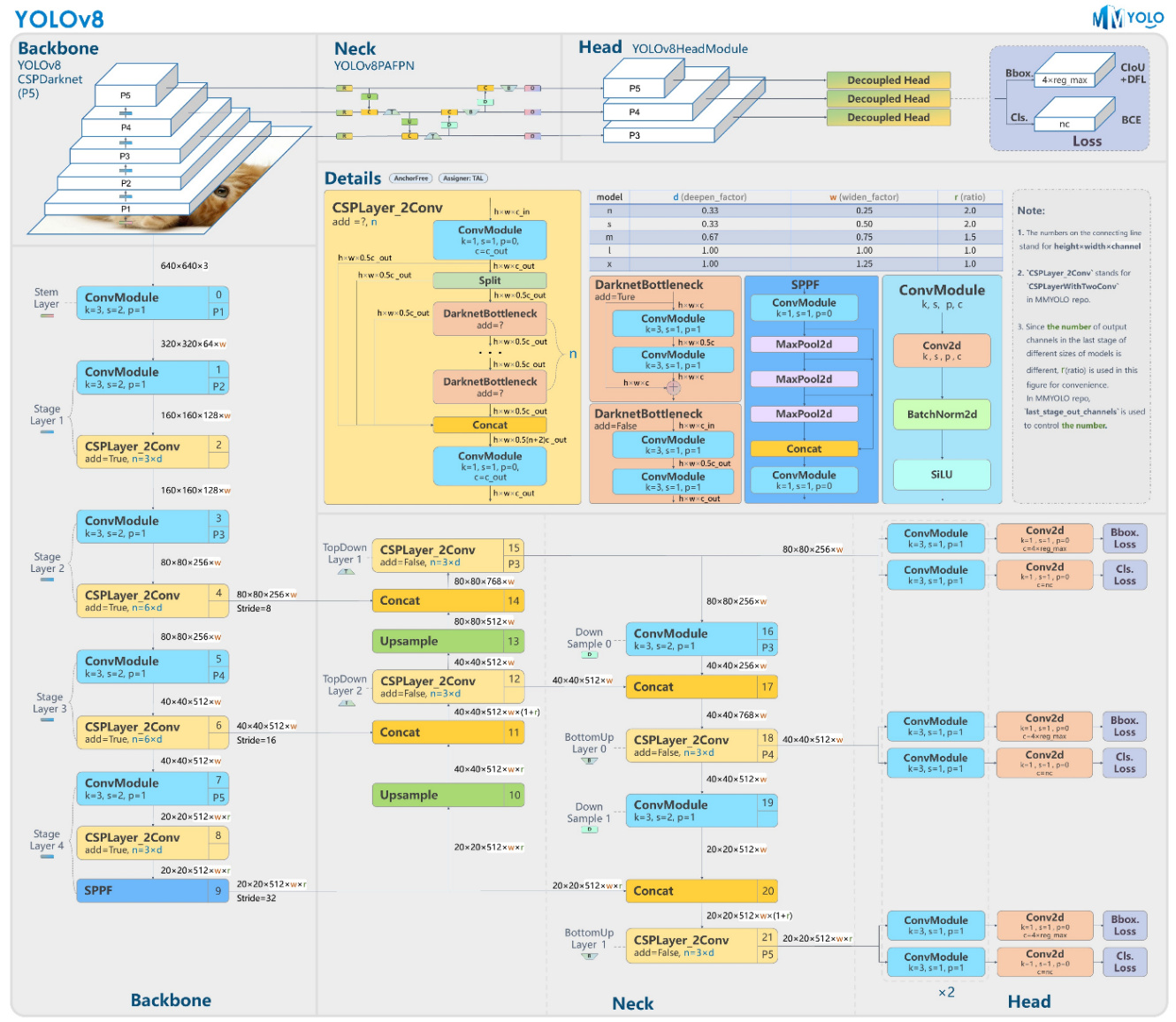 [3]より、YOLOv8の構造
[3]より、YOLOv8の構造
性能的にはトップだが、License的に実用上はRTMDetを使うほうがいいと思う。精度もそこまで変わらない。(というかYOLOv6.2以上はデータセットによって勝ったり負けたりしそう...)

実際にUltralyticsのモデルYOLOv8nのインスタンスを確認してみた。特にNeckとHeadについて詳しく見てみると次のようになる。
[3] MMYOLO
https://mmyolo.readthedocs.io/en/dev/
https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov8
Ultralytics YOLOv8 nano
========================================================================================================================
Layer (type (var_name)) Input Shape Output Shape Mult-Adds
========================================================================================================================
DetectionModel (DetectionModel) [1, 3, 256, 256] [1, 84, 1344] --
BACKBONE
├─Sequential (model) -- -- --
│ └─Conv (0) [1, 3, 256, 256] [1, 16, 128, 128] --
│ │ └─Conv2d (conv) [1, 3, 256, 256] [1, 16, 128, 128] 7,340,032
│ └─Detect (22) -- -- --
│ └─Conv (1) [1, 16, 128, 128] [1, 32, 64, 64] --
│ │ └─Conv2d (conv) [1, 16, 128, 128] [1, 32, 64, 64] 19,005,440
│ └─Detect (22) -- -- --
│ └─C2f (2) [1, 32, 64, 64] [1, 32, 64, 64] --
│ │ └─Conv (cv1) [1, 32, 64, 64] [1, 32, 64, 64] --
│ │ │ └─Conv2d (conv) [1, 32, 64, 64] [1, 32, 64, 64] 4,325,376
│ └─Detect (22) -- -- --
│ └─C2f (2) -- -- --
│ │ └─ModuleList (m) -- -- --
│ │ │ └─Bottleneck (0) [1, 16, 64, 64] [1, 16, 64, 64] --
│ │ │ │ └─Conv (cv1) [1, 16, 64, 64] [1, 16, 64, 64] 9,502,720
│ └─Detect (22) -- -- --
│ └─C2f (2)
..
│ └─Detect (22) -- -- --
│ └─SPPF (9) -- -- --
│ │ └─MaxPool2d (m) [1, 128, 8, 8] [1, 128, 8, 8] --
│ │ └─MaxPool2d (m) [1, 128, 8, 8] [1, 128, 8, 8] --
│ │ └─MaxPool2d (m) [1, 128, 8, 8] [1, 128, 8, 8] --
│ │ └─Conv (cv2) [1, 512, 8, 8] [1, 256, 8, 8] --
│ │ │ └─Conv2d (conv) [1, 512, 8, 8] [1, 256, 8, 8] 8,404,992
│ └─Detect (22) -- -- --
NECK
│ └─Upsample (10) [1, 256, 8, 8] [1, 256, 16, 16] --
│ └─Concat (11) [1, 256, 16, 16] [1, 384, 16, 16] --
│ └─C2f (12) [1, 384, 16, 16] [1, 128, 16, 16] --
│ │ └─Conv (cv1) [1, 384, 16, 16] [1, 128, 16, 16] --
│ │ │ └─Conv2d (conv) [1, 384, 16, 16] [1, 128, 16, 16] 12,615,680
│ └─Detect (22) -- -- --
│ └─C2f (12) -- -- --
│ │ └─ModuleList (m) -- -- --
│ │ │ └─Bottleneck (0) [1, 64, 16, 16] [1, 64, 16, 16] --
│ │ │ │ └─Conv (cv1) [1, 64, 16, 16] [1, 64, 16, 16] 9,453,568
│ └─Detect (22) -- -- --
│ └─C2f (12) -- -- --
│ │ └─ModuleList (m) -- -- --
│ │ │ └─Bottleneck (0) -- -- --
│ │ │ │ └─Conv (cv2) [1, 64, 16, 16] [1, 64, 16, 16] 9,453,568
│ └─Detect (22) -- -- --
│ └─C2f (12) -- -- --
│ │ └─Conv (cv2) [1, 192, 16, 16] [1, 128, 16, 16] --
│ │ │ └─Conv2d (conv) [1, 192, 16, 16] [1, 128, 16, 16] 6,324,224
│ └─Detect (22) -- -- --
│ └─Upsample (13) [1, 128, 16, 16] [1, 128, 32, 32] --
│ └─Concat (14) [1, 128, 32, 32] [1, 192, 32, 32] --
│ └─C2f (15) [1, 192, 32, 32] [1, 64, 32, 32] --
│ │ └─Conv (cv1) [1, 192, 32, 32] [1, 64, 32, 32] --
│ │ │ └─Conv2d (conv) [1, 192, 32, 32] [1, 64, 32, 32] 12,648,448
│ └─Detect (22) -- -- --
│ └─C2f (15) -- -- --
│ │ └─ModuleList (m) -- -- --
│ │ │ └─Bottleneck (0) [1, 32, 32, 32] [1, 32, 32, 32] --
│ │ │ │ └─Conv (cv1) [1, 32, 32, 32] [1, 32, 32, 32] 9,469,952
│ └─Detect (22) -- -- --
│ └─C2f (15) -- -- --
│ │ └─ModuleList (m) -- -- --
│ │ │ └─Bottleneck (0) -- -- --
│ │ │ │ └─Conv (cv2) [1, 32, 32, 32] [1, 32, 32, 32] 9,469,952
│ └─Detect (22) -- -- --
│ └─C2f (15) -- -- --
│ │ └─Conv (cv2) [1, 96, 32, 32] [1, 64, 32, 32] --
│ │ │ └─Conv2d (conv) [1, 96, 32, 32] [1, 64, 32, 32] 6,356,992
│ └─Detect (22) -- -- --
│ └─Conv (16) [1, 64, 32, 32] [1, 64, 16, 16] --
│ │ └─Conv2d (conv) [1, 64, 32, 32] [1, 64, 16, 16] 9,453,568
│ └─Detect (22) -- -- --
│ └─Concat (17) [1, 64, 16, 16] [1, 192, 16, 16] --
│ └─C2f (18) [1, 192, 16, 16] [1, 128, 16, 16] --
│ │ └─Conv (cv1) [1, 192, 16, 16] [1, 128, 16, 16] --
│ │ │ └─Conv2d (conv) [1, 192, 16, 16] [1, 128, 16, 16] 6,324,224
│ └─Detect (22) -- -- --
│ └─C2f (18) -- -- --
│ │ └─ModuleList (m) -- -- --
│ │ │ └─Bottleneck (0) [1, 64, 16, 16] [1, 64, 16, 16] --
│ │ │ │ └─Conv (cv1) [1, 64, 16, 16] [1, 64, 16, 16] 9,453,568
│ └─Detect (22) -- -- --
│ └─C2f (18) -- -- --
│ │ └─ModuleList (m) -- -- --
│ │ │ └─Bottleneck (0) -- -- --
│ │ │ │ └─Conv (cv2) [1, 64, 16, 16] [1, 64, 16, 16] 9,453,568
│ └─Detect (22) -- -- --
│ └─C2f (18) -- -- --
│ │ └─Conv (cv2) [1, 192, 16, 16] [1, 128, 16, 16] --
│ │ │ └─Conv2d (conv) [1, 192, 16, 16] [1, 128, 16, 16] 6,324,224
│ └─Detect (22) -- -- --
│ └─Conv (19) [1, 128, 16, 16] [1, 128, 8, 8] --
│ │ └─Conv2d (conv) [1, 128, 16, 16] [1, 128, 8, 8] 9,445,376
│ └─Detect (22) -- -- --
│ └─Concat (20) [1, 128, 8, 8] [1, 384, 8, 8] --
│ └─C2f (21) [1, 384, 8, 8] [1, 256, 8, 8] --
│ │ └─Conv (cv1) [1, 384, 8, 8] [1, 256, 8, 8] --
│ │ │ └─Conv2d (conv) [1, 384, 8, 8] [1, 256, 8, 8] 6,307,840
│ └─Detect (22) -- -- --
│ └─C2f (21) -- -- --
│ │ └─ModuleList (m) -- -- --
│ │ │ └─Bottleneck (0) [1, 128, 8, 8] [1, 128, 8, 8] --
│ │ │ │ └─Conv (cv1) [1, 128, 8, 8] [1, 128, 8, 8] 9,445,376
│ └─Detect (22) -- -- --
│ └─C2f (21) -- -- --
│ │ └─ModuleList (m) -- -- --
│ │ │ └─Bottleneck (0) -- -- --
│ │ │ │ └─Conv (cv2) [1, 128, 8, 8] [1, 128, 8, 8] 9,445,376
│ └─Detect (22) -- -- --
│ └─C2f (21) -- -- --
│ │ └─Conv (cv2) [1, 384, 8, 8] [1, 256, 8, 8] --
│ │ │ └─Conv2d (conv) [1, 384, 8, 8] [1, 256, 8, 8] 6,307,840
│ └─Detect (22) -- -- --
-> [1, 256, 8, 8], [1, 128, 16, 16], [1, 64, 32, 32]
│ └─Detect (22) [1, 144, 32, 32] [1, 84, 1344] --
│ │ └─ModuleList (cv2) -- -- --
│ │ │ └─Sequential (0) [1, 64, 32, 32] [1, 64, 32, 32] --
│ │ │ │ └─Conv (0) [1, 64, 32, 32] [1, 64, 32, 32] 37,814,272
│ │ └─ModuleList (cv2) -- -- --
│ │ │ └─Sequential (0) -- -- --
│ │ │ │ └─Conv (1) [1, 64, 32, 32] [1, 64, 32, 32] 37,814,272
│ │ └─ModuleList (cv2) -- -- --
│ │ │ └─Sequential (0) -- -- --
│ │ │ │ └─Conv2d (2) [1, 64, 32, 32] [1, 64, 32, 32] 4,259,840
│ │ └─ModuleList (cv3) -- -- --
│ │ │ └─Sequential (0) [1, 64, 32, 32] [1, 80, 32, 32] --
│ │ │ │ └─Conv (0) [1, 64, 32, 32] [1, 80, 32, 32] 47,267,840
│ │ │ │ └─Conv (1) -- -- --
│ │ │ └─Sequential (0) -- -- --
│ │ │ │ └─Conv (1) [1, 80, 32, 32] [1, 80, 32, 32] 59,064,320
│ │ │ │ └─Conv (1) -- -- --
│ │ │ └─Sequential (0) -- -- --
│ │ │ │ └─Conv2d (2) [1, 80, 32, 32] [1, 80, 32, 32] 6,635,520
-> [1, 64, 32, 32], [1, 80, 32, 32]
│ │ └─ModuleList (cv2) -- -- --
│ │ │ └─Sequential (1) [1, 128, 16, 16] [1, 64, 16, 16] --
│ │ │ │ └─Conv (0) [1, 128, 16, 16] [1, 64, 16, 16] 18,890,752
│ │ └─ModuleList (cv2) -- -- --
│ │ │ └─Sequential (1) -- -- --
│ │ │ │ └─Conv (1) [1, 64, 16, 16] [1, 64, 16, 16] 9,453,568
│ │ └─ModuleList (cv2) -- -- --
│ │ │ └─Sequential (1) -- -- --
│ │ │ │ └─Conv2d (2) [1, 64, 16, 16] [1, 64, 16, 16] 1,064,960
│ │ └─ModuleList (cv3) -- -- --
│ │ │ └─Sequential (1) [1, 128, 16, 16] [1, 80, 16, 16] --
│ │ │ │ └─Conv (0) [1, 128, 16, 16] [1, 80, 16, 16] 23,613,440
│ │ │ │ └─Conv (1) -- -- --
│ │ │ └─Sequential (1) -- -- --
│ │ │ │ └─Conv (1) [1, 80, 16, 16] [1, 80, 16, 16] 14,766,080
│ │ │ │ └─Conv (1) -- -- --
│ │ │ └─Sequential (1) -- -- --
│ │ │ │ └─Conv2d (2) [1, 80, 16, 16] [1, 80, 16, 16] 1,658,880
-> [1, 64, 16, 16], [1, 80, 16, 16]
│ │ └─ModuleList (cv2) -- -- --
│ │ │ └─Sequential (2) [1, 256, 8, 8] [1, 64, 8, 8] --
│ │ │ │ └─Conv (0) [1, 256, 8, 8] [1, 64, 8, 8] 9,441,280
│ │ └─ModuleList (cv2) -- -- --
│ │ │ │ └─Conv (1) [1, 64, 8, 8] [1, 64, 8, 8] 2,363,392
│ │ └─ModuleList (cv2) -- -- --
│ │ │ │ └─Conv2d (2) [1, 64, 8, 8] [1, 64, 8, 8] 266,240
│ │ └─ModuleList (cv3) -- -- --
│ │ │ └─Sequential (2) [1, 256, 8, 8] [1, 80, 8, 8] --
│ │ │ │ └─Conv (0) [1, 256, 8, 8] [1, 80, 8, 8] 11,801,600
│ │ │ │ └─Conv (1) -- -- --
│ │ │ │ └─Conv (1) [1, 80, 8, 8] [1, 80, 8, 8] 3,691,520
│ │ │ │ └─Conv2d (2) [1, 80, 8, 8] [1, 80, 8, 8] 414,720
-> [1, 64, 8, 8], [1, 80, 8, 8]
│ │ └─DFL (dfl) [1, 64, 1344] [1, 4, 1344] --
│ │ │ └─Conv2d (conv) [1, 16, 4, 1344] [1, 1, 4, 1344] 86,016
BBox Regression Head(cv2)とClassification Head(cv3)について詳しく見ると以下のようになっている。
(22): Detect(
(cv2): ModuleList(
(0): Sequential(
(0): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(1): Sequential(
(0): Conv(
(conv): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(2): Sequential(
(0): Conv(
(conv): Conv2d(256, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
)
(cv3): ModuleList(
(0): Sequential(
(0): Conv(
(conv): Conv2d(64, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(80, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(80, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(2): Conv2d(80, 80, kernel_size=(1, 1), stride=(1, 1))
)
(1): Sequential(
(0): Conv(
(conv): Conv2d(128, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(80, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(80, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(2): Conv2d(80, 80, kernel_size=(1, 1), stride=(1, 1))
)
(2): Sequential(
(0): Conv(
(conv): Conv2d(256, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(80, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(80, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(2): Conv2d(80, 80, kernel_size=(1, 1), stride=(1, 1))
)
)
(dfl): DFL(
(conv): Conv2d(16, 1, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
入出力として試してみると、[B,3,512,512]の入力画像に対し、[B, 84, 5376], list([B,144,64,64], [B,144,32,32], [B,144,16,16])のように、それぞれBBox Proposalと各スケールの処理前テンソル(?)が返された。BBoxのdim=1の84は、おそらくデフォルトのクラス数80とxywhの4の和だと思う。(Objectnessスコアが含まれていないのはなぜ...?)
モデルグラフからHeadへの入力を推定してみると、おそらく[1,64,H/8,W/8], [1,128,H/16,W/16], [1,256,H/32,W/32]が特徴ピラミッドとして使われている。Detection Headではこれらの空間方向の大きさを保存しながらクラス数80のChannelを持つテンソルに変換されている。
以下の回答は正確だと思う。
最後のDFLはGeneralized Focal Lossを計算する際に使うもので、[4]が参考になっていた。おそらく損失計算時のなにかだと思うがよく分からなかった。
[4] X. Li, C. Lv, W. Wang, G. Li, L. Yang and J. Yang,
"Generalized Focal Loss: Towards Efficient Representation Learning for Dense Object Detection, in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3139-3153, 1 March 2023, doi: 10.1109/TPAMI.2022.3180392.
https://ieeexplore.ieee.org/document/9792391
Ultralytics YOLO v8 Head
コードはAGPL Licenseなので注意
from ultralytics.utils.tal import dist2bbox, make_anchors
class DFL(nn.Module):
"""
Integral module of Distribution Focal Loss (DFL).
Proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
"""
def __init__(self, c1=16):
"""Initialize a convolutional layer with a given number of input channels."""
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
"""Applies a transformer layer on input tensor 'x' and returns a tensor."""
b, c, a = x.shape # batch, channels, anchors
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
class Detect(nn.Module):
dynamic = False # force grid reconstruction
export = False # export mode
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, num_class=80, feature_layer=(128,256,512)):
"""Initializes the YOLOv8 detection layer with specified number of classes and channels."""
super().__init__()
self.num_class = num_class # number of classes
self.num_featpyramid = len(feature_layer) # number of detection layers
self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)
self.num_anchor = num_class + self.reg_max * 4 # number of outputs per anchor
self.stride = torch.zeros(self.num_featpyramid) # strides computed during build
c2 = max((16, feature_layer[0] // 4, self.reg_max * 4))
c3 = max(feature_layer[0], min(self.num_class, 100)) # channels
self.cv2 = nn.ModuleList(
nn.Sequential(
nn.Conv2d(x, c2, 3, padding=1),
nn.Conv2d(c2, c2, 3, padding=1),
nn.Conv2d(c2, 4 * self.reg_max, 1)
) for x in feature_layer)
self.cv3 = nn.ModuleList(
nn.Sequential(
nn.Conv2d(x, c3, 3, padding=1),
nn.Conv2d(c3, c3, 3, padding=1),
nn.Conv2d(c3, self.num_class, 1)
) for x in feature_layer)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
def forward(self, x):
shape = x[0].shape # BCHW
for i in range(self.num_featpyramid):
x[i] = torch.cat([self.cv2[i](x[i]), self.cv3[i](x[i])], dim=1)
if self.training:
return x
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
x_cat = torch.cat([xi.view(shape[0], self.num_anchor, -1) for xi in x], 2)
if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV ops
box = x_cat[:, :self.reg_max * 4]
cls = x_cat[:, self.reg_max * 4:]
else:
box, cls = x_cat.split((self.reg_max * 4, self.num_class), 1)
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
if self.export and self.format in ('tflite', 'edgetpu'):
img_h = shape[2] * self.stride[0]
img_w = shape[3] * self.stride[0]
img_size = torch.tensor([img_w, img_h, img_w, img_h], device=dbox.device).reshape(1, 4, 1)
dbox /= img_size
y = torch.cat((dbox, cls.sigmoid()), 1)
return y if self.export else (y, x)
def bias_init(self):
"""Initialize Detect() biases, WARNING: requires stride availability."""
m = self # self.model[-1] # Detect() module
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1
# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequency
for a, b, s in zip(m.cv2, m.cv3, m.stride): # from
a[-1].bias.data[:] = 1.0 # box
b[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
余談: 最近はYOLO MS(Multi-Scale)というモデルが速いらしい。
自作モデルを作る
本題。YOLO v8の構造のうち、順方向の特徴抽出ステージと・各スケールの特徴マップを用いるステージ、スケール別の特徴マップからBBoxを計算するステージの3つに分けて作っていく。できるだけ実装を追ったが、DFLなど実装がよく分からなかった部分は自前で考えた。
学習パラメータを含むモデル本体は以下の設計で作る。基本的にはYOLOなど最近のリアルタイム検出可能な手法はこのような雰囲気で作られていると考えて良い。
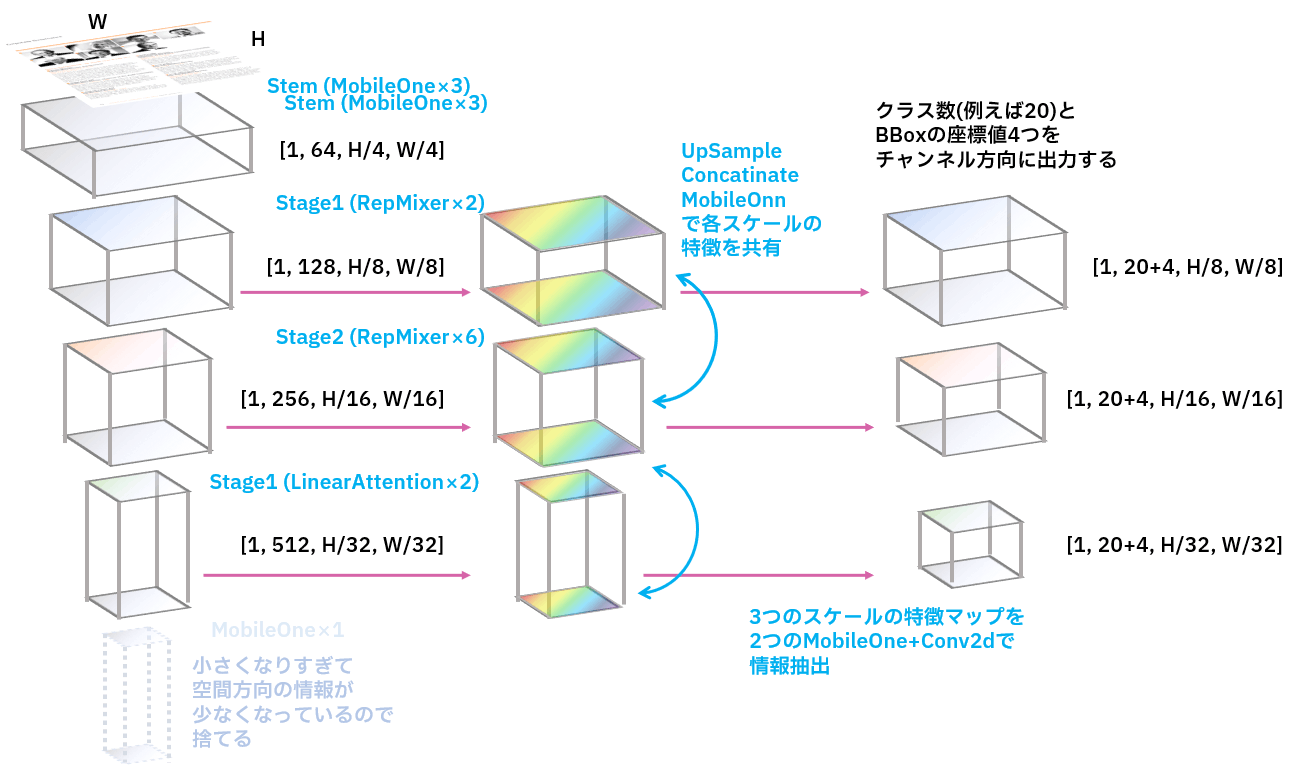 学習パラメータを含むモデルからの特徴マップの大きさ
学習パラメータを含むモデルからの特徴マップの大きさ
Backbone Network
まず特徴抽出を行うバックボーンNNを作る。といっても、ここは一般画像認識モデルをステージごとに分割して特徴マップをひっぱってくるだけ。
工夫としては、今回使用するFastViTはreparameterizeを行うモジュールが含まれているため、一括で推論モードを起動できるように全依存先のモジュールにreparameterizeメソッドを組んでおくことにした。これによりモジュール上層からでも一括でreparameterize可能になって便利。
使用するスケールはSA12。
Spatial Pyramid PoolingはYOLOv5のものを参考にした。この部分は画像のスケールに関する帰納バイアスをモデルに持たせることに役立っているらしい。
まず、画像[B,3,H,W]の入力に対し、バックボーンから[B,128,H/8,W/8], [B,256,H/16,W/16], [B,512,H/32,W/32]の特徴マップを得る。
import torch
from torch import nn
import torchvision
from torchvision.ops import box_convert
from torchvision.transforms import v2 as transforms
from torchvision import tv_tensors
import torchinfo
import timm
from timm.models.fastvit import MobileOneBlock
import datasets
import lightning as pl
class FastVitBackbone(nn.Module):
def __init__(self):
super().__init__()
self.inference_mode = False
base = timm.create_model(
"fastvit_sa12.apple_dist_in1k",
pretrained=True,
)
self.stem = base.stem # -> [ 64, HW/4]
self.block0 = base.stages[0] # -> [ 64, HW/4]
self.block1 = base.stages[1] # -> [128, HW/8]
self.block2 = base.stages[2] # -> [256, HW/16]
self.block3 = base.stages[3] # -> [512 ,HW/32]
self.spp = SpatialPyramidPooling(512, 512)
return None
def forward(self, x):
x = self.stem(x)
x = self.block0(x)
p0 = self.block1(x)
p1 = self.block2(p0)
p2 = self.block3(p1)
p2 = self.spp(p2)
return p0, p1, p2
def reparameterize(self):
self.inference_mode = True if self.inference_mode == False else print("already inference mode.")
# MobileOneBlock, ReparamLargeKernelConv, RepConditionalPosEnc is reparameterizable
for i in range(3):
self.stem[i].reparameterize()
for i in range(2):
self.block0.blocks[i].token_mixer.reparameterize() # RepMixer
self.block1.downsample.proj[0].reparameterize() # ReparamLargeKernelConv
self.block1.downsample.proj[1].reparameterize() # MobileOneBlock
for i in range(2):
self.block1.blocks[i].token_mixer.reparameterize() # RepMixer
self.block2.downsample.proj[0].reparameterize() # ReparamLargeKernelConv
self.block2.downsample.proj[1].reparameterize() # MobileOneBlock
for i in range(6):
self.block2.blocks[i].token_mixer.reparameterize() # RepMixer
self.block3.downsample.proj[0].reparameterize() # ReparamLargeKernelConv
self.block3.downsample.proj[1].reparameterize() # MobileOneBlock
self.block3.pos_emb.reparameterize() # RepConditionalPosEnc
return None
後付になるが、SpatialPyramidPoolingの定義は以下。
class ConvNormAct(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=1,
stride=1,
groups=1,
bias=False,
apply_act=True,
):
super().__init__()
self.conv = nn.Conv2d(
in_channels, out_channels, kernel_size, padding=kernel_size//2,
stride=stride, groups=groups, bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU(inplace=True) if apply_act else nn.Identity()
return None
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
class SpatialPyramidPooling(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
poolk = [5, 9, 13]
self.conv1 = ConvNormAct(in_channels, in_channels//2, 1)
self.conv2 = ConvNormAct(in_channels//2 * 4, out_channels, 1)
self.m1 = nn.MaxPool2d(kernel_size=poolk[0], stride=1, padding=poolk[0]//2)
self.m2 = nn.MaxPool2d(kernel_size=poolk[1], stride=1, padding=poolk[1]//2)
self.m3 = nn.MaxPool2d(kernel_size=poolk[2], stride=1, padding=poolk[2]//2)
return None
def forward(self, x):
x = self.conv1(x)
return self.conv2(torch.cat((x, self.m1(x), self.m2(x), self.m3(x)), dim=1))
Feature Pyramid Network
次にPAFPNを作る。YOLOv8の図でいうNeckで、自作モデルではCross Stage Pyramid LayerのかわりにMobileOneのブロックを使う方針でいく。PAFPNでは特徴抽出してdown sampleされた特徴マップを空間方向を合わせながら結合していき、もう一度特抽出を行う。これにより色々なスケールでの特徴に関して処理することができて、スケールが大きな出力にも大域的な情報が含まれるようになる。
FPNに渡される特徴マップは[B,128,H/8,W/8], [B,256,H/16,W/16], [B,512,H/32,W/32]のサイズの3つで、これらをRepMixerとLinerAttetionをもつFastViT Stageで折り込んでいき、[B,128,H/8,W/8], [B,256,H/16,W/16], [B,512,H/32,W/32]の出力を得る。
class MobileOneFpn(nn.Module):
def __init__(self, inc=[128, 256, 512]):
super().__init__()
self.inference_mode = False
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear')
self.block0 = MobileOneBlock(inc[2]+inc[1], inc[1], 3, use_se=True, num_conv_branches=4)
self.block1 = MobileOneBlock(inc[1]+inc[0], inc[0], 3, use_se=True, num_conv_branches=4)
self.conv0 = MobileOneBlock(inc[0], inc[0], 7, stride=2, use_se=False, num_conv_branches=4)
self.block2 = MobileOneBlock(inc[1]+inc[0], inc[1], 3, use_se=True, num_conv_branches=4)
self.conv1 = MobileOneBlock(inc[1], inc[1], 7, stride=2, use_se=False, num_conv_branches=4)
self.block3 = MobileOneBlock(inc[2]+inc[1], inc[2], 3, use_se=True, num_conv_branches=4)
return None
def forward(self, p0, p1, p2):
h1 = self.block0(torch.concat([self.upsample(p2), p1], dim=1))
o0 = self.block1(torch.concat([self.upsample(h1), p0], dim=1))
o1 = self.block2(torch.concat([self.conv0(o0), h1], dim=1))
o2 = self.block3(torch.concat([self.conv1(o1), p2], dim=1))
return o0, o1, o2
def reparameterize(self):
self.inference_mode = True if self.inference_mode == False else print("already inference mode.")
# self.block0[0].blocks[0].token_mixer.reparameterize()
# self.block1[0].blocks[0].token_mixer.reparameterize()
# self.block2[0].blocks[0].token_mixer.reparameterize()
# self.block3[0].blocks[0].token_mixer.reparameterize()
self.block0.reparameterize()
self.block1.reparameterize()
self.block2.reparameterize()
self.block3.reparameterize()
self.conv0.reparameterize()
self.conv1.reparameterize()
return None
動作確認
実際に出力を確かめてみよう。
backbone = FastVitBackbone()
neck = MobileOneFpn()
img = torch.ones(8,3,256,256)
p0, p1, p2 = backbone(img)
print(p0.shape, p1.shape, p2.shape)
o0, o1, o2 = neck(p0, p1, p2)
print(o0.shape, o1.shape, o2.shape)
torch.Size([8, 128, 32, 32]) torch.Size([8, 256, 16, 16]) torch.Size([8, 512, 8, 8])
torch.Size([8, 128, 32, 32]) torch.Size([8, 256, 16, 16]) torch.Size([8, 512, 8, 8])
さらにreparameterizeも動くか試してみる。
backbone = FastVitBackbone()
neck = MobileOneFpn()
backbone.reparameterize()
neck.reparameterize()
img = torch.ones(8,3,256,256)
p0, p1, p2 = backbone(img)
print(p0.shape, p1.shape, p2.shape)
o0, o1, o2 = neck(p0, p1, p2)
print(o0.shape, o1.shape, o2.shape)
torch.Size([8, 128, 32, 32]) torch.Size([8, 256, 16, 16]) torch.Size([8, 512, 8, 8])
torch.Size([8, 128, 32, 32]) torch.Size([8, 256, 16, 16]) torch.Size([8, 512, 8, 8])
ここで、実際に学習可能なNNになっているか確かめてみる。
FastVitBackboneとFastVitFpnを結合してGAPでChannel方向に平坦化し、線形層で分類タスクを解くタスクで学習させる。データセットはKvasirとGastroVisionで、内視鏡画像の28クラス分類で学習した所、検証スコアF1精度0.278から8epochで0.424まで向上し、大体EfficientNetくらいの上昇をみれたので、正常に動作すると判断した。
BBox & Class Regression Head
特徴マップごとにBBox回帰とクラス分類を行う畳み込み層を作る。
出力はYOLO v8の頁で示した通り[B, CLASS, H/s, W/s], [B, REG_MAX*4, H/s, W/s]となる。
少し自信がないのだが、一旦は以下の図のように設計して行くことにする。以下の例ではBBox提案数3,クラス数20の例を示した。
 出力テンソルと損失計算の設計
出力テンソルと損失計算の設計
class MobileOneDetHead(nn.Module):
def __init__(self, in_channels, num_classes, scale: int, reg_max=16):
super().__init__()
self.inference_mode = False
self.num_classes = num_classes
self.reg_max = reg_max
self.scale = scale # input [B, in_channel, H/scale, W/scale]
self.anchors = torch.empty(0) # init
self.strides = torch.empty(0) # init
self.shape = None
h_channels1 = max((16, in_channels//4, reg_max*4))
h_channels2 = max(in_channels, num_classes)
self.bbox_head = nn.Sequential(
MobileOneBlock(in_channels, h_channels1, 3, use_se=True, num_conv_branches=4),
nn.Conv2d(h_channels1, 4*reg_max, 1),
nn.Sigmoid(),
)
self.class_head = nn.Sequential(
MobileOneBlock(in_channels, h_channels2, 3, use_se=True, num_conv_branches=4),
nn.Conv2d(h_channels2, num_classes, 1),
nn.Sigmoid(), # class probabirity
)
return None
def reparameterize(self):
self.inference_mode = True if self.inference_mode == False else print("already inference mode.")
self.bbox_head[0].reparameterize()
self.class_head[0].reparameterize()
return None
def forward(self, x):
b, _, h, w = x.shape
classes = self.class_head(x).view(b,self.num_classes,h*w) # [B, N_CLASSES, H*W] (e.g. [1,100,128*128])
bbox = self.bbox_head(x) # [B, 4, H*W] (e.g. [1,4,128*128])
bbox = torch.concat([
torch.mean(bbox[:, :1*self.reg_max]-0.5, dim=1).view(b,1,h*w),
torch.mean(bbox[:, 1*self.reg_max:2*self.reg_max]-0.5, dim=1).view(b,1,h*w),
torch.mean(bbox[:, 2*self.reg_max:3*self.reg_max]*self.scale, dim=1).view(b,1,h*w),
torch.mean(bbox[:, 3*self.reg_max: ]*self.scale, dim=1).view(b,1,h*w),
torch.max(classes, dim=1)[0].view(b,1,h*w) # objectness
], dim=1)
if self.shape != bbox.shape:
self.shape = bbox.shape
self.anchors = make_anchors(x, self.scale, grid_offset=0.5)
self.anchors = self.anchors.transpose(0, 1)
bbox[:,0] = (bbox[:,0] + self.anchors[0]) * self.scale
bbox[:,1] = (bbox[:,1] + self.anchors[1]) * self.scale
return torch.concat([bbox.view(b,5,h,w), classes.view(b,self.num_classes,h,w)], dim=1)
anchor boxの座標は次のmeshgridで与える。
def make_anchors(feat, stride, grid_offset=0.5):
dtype, device = feat.dtype, feat.device
_, _, h, w = feat.shape
sx = torch.arange(end=w, device=device, dtype=dtype) + grid_offset # shift x
sy = torch.arange(end=h, device=device, dtype=dtype) + grid_offset # shift y
sy, sx = torch.meshgrid(sy, sx, indexing='ij')
anchor_point = torch.stack([sx, sy], -1).view(-1, 2)
return anchor_point
動作確認
全体を一旦結合してFLOPsを計測した所、[1,3,512,512]の入力で46.32 GFLOPs、reparametarize後は16.91 GFLOPsで、YOLOv5のmスケール相当のFLOPsとなり、パラメータ数に関しては40%削減できているモデルになった。計測結果は以下。
# FastVitDet
Total params: 70,713,094
Total mult-adds (G): 46.32
# FastVitDet reparametrized
Total params: 25,730,630
Total mult-adds (G): 16.91
# YOLOv5m
Total params: 43,692,861
Total mult-adds (G): 15.64
使用したYOLOv5実装はUltralyticsのtorch hub実装。
モデル全体
以上のモジュールを結合し、学習モードでは損失計算用の出力を、推論モードでは提案BBoxを出力するモデルを作る。
class FastVitDet(nn.Module):
def __init__(self, inc=[128, 256, 512], num_classes=10, reg_max=16):
super().__init__()
self.inference_mode = False
self.num_classes = num_classes
self.reg_max = reg_max
self.num_anchor = num_classes + reg_max * 4
self.backbone = FastVitBackbone()
self.neck = MobileOneFpn(inc=inc)
self.head0 = MobileOneDetHead(inc[0], num_classes, scale= 8, reg_max=reg_max)
self.head1 = MobileOneDetHead(inc[1], num_classes, scale=16, reg_max=reg_max)
self.head2 = MobileOneDetHead(inc[2], num_classes, scale=32, reg_max=reg_max)
self.nms = Det3NMS(num_classes)
return None
def reparameterize(self):
self.inference_mode = True if self.inference_mode == False else print("already inference mode.")
self.backbone.reparameterize()
self.neck.reparameterize()
self.head0.reparameterize()
self.head1.reparameterize()
self.head2.reparameterize()
return None
def forward(self, x):
p0, p1, p2 = self.backbone(x)
p0, p1, p2 = self.neck(p0, p1, p2)
bbox0 = self.head0(p0)
bbox1 = self.head1(p1)
bbox2 = self.head2(p2)
if self.training:
return bbox0, bbox1, bbox2
else:
outputs = self.nms([bbox0, bbox1, bbox2])
return outputs
NMSは次の構成で行った。
class Det3NMS(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.num_classes = num_classes
return None
@torch.no_grad
def forward(self, bbox_list):
# input [B, ↓, H/s, W/s]
# dim=1: [dx, dy, w, h, objctness, class...]
bbox = torch.concat([
box_convert(bbox_i[:,:4].reshape(-1,4), "cxcywh", "xyxy")
for bbox_i in bbox_list
], dim=0)
objectness = torch.concat([
bbox_i[:,4:5].reshape(-1)
for bbox_i in bbox_list
], dim=0)
classes = torch.concat([
torch.argmax(bbox_i[:,5:].reshape(-1, self.num_classes), dim=1)
for bbox_i in bbox_list
], dim=0)
outputs = torchvision.ops.batched_nms(bbox, objectness, classes, iou_threshold=0.95)
return outputs
学習と性能評価
データセットを作ってLightingを用いた学習ループを構築する。
今回は文書画像データセットDocLayNetの一部を使って動作を確認し、推論の様子を見る。
損失設計
損失関数は以下のように設定する。
- classification loss: クラス分類に対してFocal Lossを用いる。YOLOv8ではDFL(distance Focal Loss) というものが使われていた。詳しくは[4]を参照のこと。本来は正解bboxのみをマスクするとのことだが、実装力の都合上すべてのアンカーに対して計算を行う。
- confidence loss: BBoxのobjectnessスコアに対して正解Anchorが1に近づくようにする。Anchor Boxすべてに関して計算する。Focal Lossを用いる。
- bbox regression loss: bboxの各値を正解へ近づける。GIoUやCIoUが用いられる。
[5] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár
"Focal Loss for Dense Object Detection"
ICCV2017, 2018-02-07
https://arxiv.org/abs/1708.02002
[6] Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, Dongwei Ren
"Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression"
AAAI 2020, 2019-11-19
https://arxiv.org/abs/1911.08287
https://github.com/Zzh-tju/DIoU
class Det3Loss(nn.Module):
def __init__(self):
super().__init__()
self.classification = FocalLoss()
self.localization = CIoULoss()
self.confidance = FocalLoss()
return None
def forward(self, bbox_list, target_list):
# input [B, ↓, H/s, W/s]
# dim=1: [dx, dy, w, h, objctness, class...]
bbox_loss = 0
obj_loss = 0
cls_loss = 0
for bbox, target in zip(bbox_list, target_list):
b, c, _, _ = bbox.shape
bbox, target = bbox.view(b, c, -1), target.view(b, c, -1)
bbox_box = box_convert(bbox[:,:4].reshape(-1,4), "cxcywh", "xyxy")
target_box = box_convert(target[:,:4].reshape(-1,4), "cxcywh", "xyxy")
bbox_loss += self.localization(bbox_box, target_box)
obj_loss += self.confidance(bbox[:,4:5].reshape(b,-1), target[:,4:5].reshape(b,-1))
cls_loss += self.classification(bbox[:,5:].reshape(b,-1), target[:,5:].reshape(b,-1))
return bbox_loss, obj_loss, cls_loss
FocalLossとCIoULossは以下のように定義してある。
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=1.5):
super().__init__()
self.alpha = alpha
self.gamma = gamma
return None
def forward(self, inputs, targets):
inputs = inputs.reshape(-1)
targets = targets.reshape(-1)
bec = F.binary_cross_entropy(inputs, targets, reduction='mean')
becexp = torch.exp(-bec)
return self.alpha * (1-becexp)**self.gamma * bec
class CIoULoss(nn.Module):
def __init__(self, ):
super().__init__()
return None
def forward(self, bbox, target):
# input:
# bbox: [N,4] xyxy
# target: [N,4] xyxy
return torchvision.ops.complete_box_iou_loss(bbox, target, reduction="mean")
教師データ整形
データセットとデータモジュールを作成する。
class DoclaynetDataset(torch.utils.data.Dataset):
def __init__(self, dataset, img_size=(512,512)):
self.contents = dataset
self.transforms = transforms.Compose([
transforms.Resize(img_size),
transforms.RandomVerticalFlip(),
transforms.RandomHorizontalFlip(),
transforms.ToImage(),
transforms.ToDtype(torch.float32, scale=True),
])
self.transforms_img = transforms.Compose([
transforms.RandomGrayscale(p=0.20),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
self.totarget = BboxTargeter(num_classes=11, img_size=img_size)
return None
def __len__(self):
return len(self.contents)
def __getitem__(self, idx):
data = self.contents[idx]
img = data["image"]
bbox = tv_tensors.BoundingBoxes(
data["bboxes_block"],
format="xywh",
canvas_size=(data["coco_height"], data["coco_width"])
)
if bbox.shape == torch.Size([1, 0]):
bbox = tv_tensors.BoundingBoxes(
[[0,0,0,0],],
format="xywh",
canvas_size=(data["coco_height"], data["coco_width"])
)
img, bbox = self.transforms(img, bbox)
img = self.transforms_img(img)
label = torch.tensor(data["categories"])
return img, self.totarget(bbox, label)
class DoclaynetDataModule(pl.LightningDataModule):
def __init__(self, img_size=(512,512), batch_size=8, num_workers=4):
super().__init__()
self.batch_size = batch_size
self.num_workers = num_workers
self.img_size = img_size
self.dataset_origin = datasets.load_dataset("pierreguillou/DocLayNet-small")
return None
def prepare_data(self):
return None
def setup(self, stage=None):
self.train_dataset = DoclaynetDataset(self.dataset_origin["train"], img_size=self.img_size)
self.test_dataset = DoclaynetDataset(self.dataset_origin["validation"], img_size=self.img_size)
return None
def train_dataloader(self):
train_dataloader = torch.utils.data.DataLoader(
self.train_dataset,
batch_size=self.batch_size,
shuffle=True,
num_workers=self.num_workers,
)
return train_dataloader
def val_dataloader(self):
test_dataloader = torch.utils.data.DataLoader(
self.test_dataset,
batch_size=self.batch_size,
shuffle=True,
num_workers=self.num_workers,
)
return test_dataloader
前述の設計図通り、教師データであるBBoxとクラスラベルからアンカーボックス出力と同じフォーマットのものを作成する。
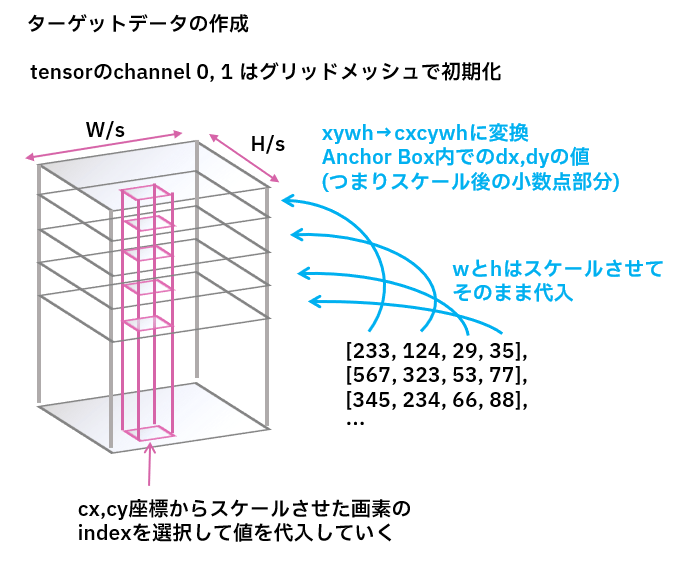 教師データ作成
教師データ作成
class BboxTargeter(nn.Module):
def __init__(self, num_classes=10, img_size=(512,512), scale=[8, 16, 32], grid_offset=0.5):
super().__init__()
self.img_size = img_size
self.scale = scale
self.num_classes = num_classes
anchor_point = []
for s in scale:
sx = torch.arange(end=img_size[0]//s) + grid_offset # shift x
sy = torch.arange(end=img_size[1]//s) + grid_offset # shift y
sy, sx = torch.meshgrid(sy, sx, indexing='ij')
anchor_point += [torch.stack([sx*s, sy*s], -1).view(2, img_size[0]//s, img_size[1]//s)]
self.anchors = anchor_point
return None
def forward(self, bbox, label):
# input:
# img: [3,H,W]
# bbox: [N,4] [topx, topy, w, h]
# label: [C]
# output:
# target : list([↓, H/s, W/s])
# dim=1 [dx, dy, w, h, gt, class...]
target = []
label = label.to(torch.int)
bbox = box_convert(bbox, in_fmt="xywh", out_fmt="cxcywh")
for i, s in enumerate(self.scale):
init_target = torch.concat([
self.anchors[i],
torch.zeros(2, self.img_size[0]//s, self.img_size[1]//s)+0.001, # put offet to escape NaN
torch.zeros(self.num_classes+1, self.img_size[0]//s, self.img_size[1]//s),
], dim=0)
for b, l in zip(bbox, label):
idxx, idxy = (b[0]//s).to(torch.int), (b[1]//s).to(torch.int)
init_target[0, idxx, idxy] += torch.clamp(b[0]/s, 0, 1) # cx + dx
init_target[1, idxx, idxy] += torch.clamp(b[1]/s, 0, 1) # cy + dy
init_target[2, idxx, idxy] = b[2] # bbox w
init_target[3, idxx, idxy] = b[3] # bbox h
init_target[4, idxx, idxy] = 1 # gt mask(objectness)
init_target[5+l, idxx, idxy] = 1 # classes onehot
target += [init_target]
return target[0], target[1], target[2]
出力の確認をしてみると次のようになった。
model = FastVitDet(num_classes=11)
model.reparameterize()
datamodule = DoclaynetDataModule(img_size=(384,384))
datamodule.setup()
dataloader = datamodule.train_dataloader()
criteria = Det3Loss()
# データローダ
img, target = next(iter(dataloader))
print(target[0].shape, target[1].shape, target[2].shape)
# 推論
outputs = model(img)
print(outputs[0].shape, outputs[1].shape, outputs[2].shape)
# 損失計算
bbox_loss, obj_loss, cls_loss = criteria(outputs, target)
print(bbox_loss + obj_loss + cls_loss)
torch.Size([8, 16, 48, 48]) torch.Size([8, 16, 24, 24]) torch.Size([8, 16, 12, 12])
torch.Size([8, 16, 48, 48]) torch.Size([8, 16, 24, 24]) torch.Size([8, 16, 12, 12])
tensor(4.0993, grad_fn=<AddBackward0>)
学習
lightingを用いて学習ループを作る。
class FastVitDetModule(pl.LightningModule):
def __init__(self):
super().__init__()
self.model = FastVitDet(num_classes=11)
self.criteria = Det3Loss()
return None
def forward(self, img):
bbox0, bbox1, bbox2 = self.model(img)
return bbox0, bbox1, bbox2
def training_step(self, batch, batch_idx):
img, target = batch
outputs = self.forward(img)
bbox_loss, obj_loss, cls_loss = self.criteria(outputs, target)
acc_dict = {
"train_iou": bbox_loss,
"train_obj": obj_loss,
"train_cls": cls_loss,
}
self.log_dict(acc_dict, logger=True, prog_bar=True)
return {"loss": bbox_loss + obj_loss + cls_loss}
def validation_step(self, batch, batch_idx):
img, target = batch
outputs = self.forward(img)
bbox_loss, obj_loss, cls_loss = self.criteria(outputs, target)
acc_dict = {
"test_iou": bbox_loss,
"test_obj": obj_loss,
"test_cls": cls_loss,
}
self.log_dict(acc_dict, logger=True, on_epoch=True, prog_bar=False)
return {"metrics": bbox_loss + obj_loss + cls_loss}
def configure_optimizers(self):
optimizer = torch.optim.AdamW(
self.parameters(),
lr=0.001,
weight_decay=0.005)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer,
16,
eta_min=0.00001)
return {"optimizer": optimizer, "lr_scheduler": lr_scheduler}
実行
if __name__ == "__main__":
model = FastVitDetModule()
datamodule = DoclaynetDataModule(img_size=(384,384))
pllogger_csv = pl.pytorch.loggers.CSVLogger("./trainlog_detectionmodel/", name="fastvitdet")
trainer = pl.Trainer(
logger=pllogger_csv,
enable_checkpointing=True, # 学習した重みを保存する
check_val_every_n_epoch=1, # 検証を行うインターバル
accelerator="gpu",
devices=1,
max_epochs=16,
)
trainer.fit(
model,
datamodule=datamodule
)
可視化
// TODO 調整中
objectnessを見る限り、学習は問題なく完了しているものの、おそらくグリッドメッシュあたりのスケール変換がおかしくなっているか。
また、予想はしていたが1/8スケールの特徴量は畳み込みの回数が少ないせいで低レベルな特徴の影が残っている。PAFPNを調節して特徴抽出部分を増やすなどが必要だろう。
 NNはターゲットを回帰できているが、明らかに正解データが想定していない値になっており、1/8スケール特徴量は特徴を分離できていない
NNはターゲットを回帰できているが、明らかに正解データが想定していない値になっており、1/8スケール特徴量は特徴を分離できていない
感想
これまでなんとなく理解したと思い込んでいた部分も、いざ実装してみると謎なことが多く、理解の粒度を確認できていい体験になっている。正常に動くまで調整方法を募集しているので、もし読んだ人がいたらディスカッション欄で指摘して頂きたい。
また、教師データ整形部分や損失関数の計算部分については素朴な実装にとどまっており、2020年代っぽい組み方ではないので、特に次の点で改善の余地が大きい。
- 教師データ整形について、この記事の実装では殆ど同じ情報を持つ高次元なtensorを3つ保持しなければならないため、メモリ効率の面で非効率な実装になっている。
- 損失計算について、YOLOv8の頁で述べた通りモダンな実装では正解Anchor boxでマスクしてその部分のクラスとIoUを計算するが、このマスクを行いながら座標値などを抜き出す処理をGPU上で行う方法が分からなかった。
- DFLに謎の畳み込みが入っていて、何をしている部分なのか読み取れなかったが、本家の実装ではアンカーフリーのbbox headでObjectnessを含めず、さらにSimOTAなどを使わずに精度を上げている要因として損失設計が大きそうなので、本質的なYOLOv8の良さに触れることはできていないかもしれない。
これらはMMDetectionなどのモダンなフレームワークを解剖して、実際に挙動を見てみる必要があるだろう。
モデル以外の学びとしては、単純にviewやreshapeを大量に使ったので頭の中でtensorのメモリ空間をエミュレートできるようになってきた感じがすること(?)かもしれない。
順方向の画像系タスクはClassfication, Detectioin, Segmentaionと触ってきたので、来年はUNetとVAEを作って自作Diffusion Modelあたりを作れるようになりたい。
Discussion