MobileNet for 2023 "MobileOne" 実装と解説
TL;DR
MobileOneは学習時のアーキテクチャでSEModuleなどの処理を行い、デプロイ時はVGGのように限界までシンプルなアーキテクチャに変更することで、推論時の速度を高速化した。
Pavan Kumar Anasosalu Vasu, James Gabriel, Jeff Zhu, Oncel Tuzel, Anurag Ranjan
"MobileOne: An Improved One millisecond Mobile Backbone"
CVPR 2023, 2023-03-28
https://arxiv.org/abs/2206.04040
2017年ごろから現れたMobileNet系の端末向けNNがありますが、MobileNetは精度の犠牲がかなり大きく、簡単なタスクのBackbone Networkがやっとのイメージがあります。
この記事で解説する、Appleから提案されたMobileOneは、iPhone上での推論速度で良い精度効率を達成しており、ImageNetベンチマークの精度的にも実用に悪くないレベルに達していると感じました。
この記事ではMobileOneがなぜ高効率なのかについて論文を読んで、実際にプログラム上の実装を読んで、依存関係を排したシンプルなモデルを作ってみます。
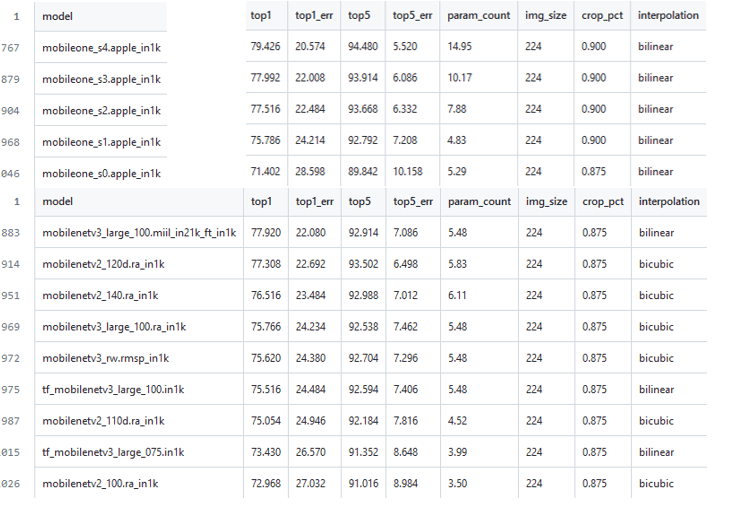 timmのImageNetベンチマークcsv
timmのImageNetベンチマークcsv
この記事では扱いませんが、より精度が高くなったFastViT (←といいつつViTっぽくはない)はMobileOneのブロックを使いながらさらに複雑なAttention部分もreparametarizeして高性能化しているらしいです。自前実装はしませんが、timmから使えます。
この記事の図表は特に断りが無い限り上記論文からの引用です。
問題と方針
NNの評価にFLOPsやパラメータカウントなどを使うことは一般的になっているが、推論速度は必ずしもこれに比例しない。例えばパラメータを共有する構造のNNはパラメータカウントは小さくなるが速度は落ちる。パラメータを持たないスキップコネクションや分岐処理はメモリアクセスコストの面からすると良くない。
このために、NNのPyTorch実装をONNX経由でCoreML上に展開し、実用デバイス(iPhone12)上のボトルネックを解析することで、latencyを最小化するアーキテクチャを考えることで高速なモデルを作りたい。この論文では学習時と推論時のアーキテクチャを切り離して、線形構造をreparameterizeすることで、メモリアクセス性も高い高速なモデルを作ることにしている。
また、小規模なモデルを過剰に正則化してしまわないように、学習中に動的に正則化を緩和する方法を使う。
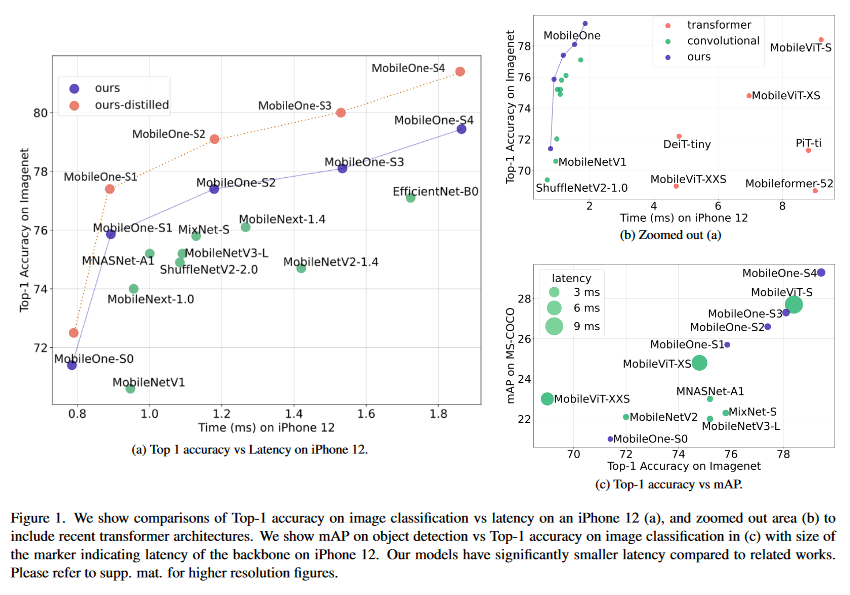 ベンチマーク結果
ベンチマーク結果
図の通り、同パラメータカウント帯のMobileNetより高精度で、MobileViTより圧倒的に早い。画像分類タスクだけでなくObject Detectionなどのタスクでもパレート最適な速度性能が出ている。
解析
FLOPsとパラメータの速度
デバイス上での動作にはFLOPsと相関が高い。パラメータ数はそこそこ相関がある。
また、CPUではパラメータカウントとの相関は低くなる。
つまり、実用上私達がNNを使うときはFLOPsを見るようにすればいいらしい。(あんまりFLOPsで統一された指標表を見かけないのが悲しい)
活性化関数の速度
最近導入されたDynamic Shift-MaxやDynamicReLUsのような手法はFLOPsの小さいモデルの精度上昇には向いているが、latencyの面で言えばあまり良くない。
MobileOneではReLUのみを使った。
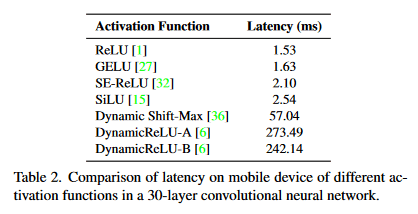 活性化関数の速度比較
活性化関数の速度比較
SiLUよりGELUのほうが早いのは不思議...
計算グラフ構造の速度
ランタイム性能に影響を与える要因はメモリアクセスコストと並列度が特に大きい。
計算グラフ内に分岐があるとテンソルの保存が必要になるのでメモリアクセスが発生して遅くなる。
また、Squeeze-Exciteで使用されるGAP演算のような同期が必要なアーキテクチャも、同期コストにより全体の実行時間に悪影響である。
モデルの構成
以上の問題を解決するために、MobileOneではRep-VGGのように学習時のアーキテクチャと推論時のアーキテクチャを分離する方針を取った。
(この方法はYOLO v7などでも使われた高速化手法で、他の論文でもよく話題に上がるので間違いないと思う。)
アーキテクチャ
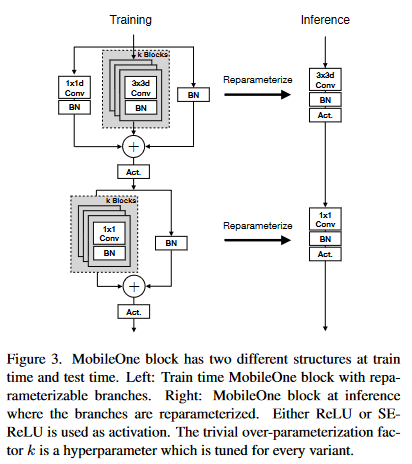
図の通り、1つの畳み込みを設計するのではなく、MobileNet v1の3×3→1×1のdepthwise separable convをベースに、reparameterize可能なスキップコネクションとBatchNorm層をもつようにする。図中のkはkernel sizeで、論文中table.6に示されている通り、1~5で精度に対して最適化する。例えばMobileOne-S1ではk=1が最も精度が良かったとされている。
スケーリング
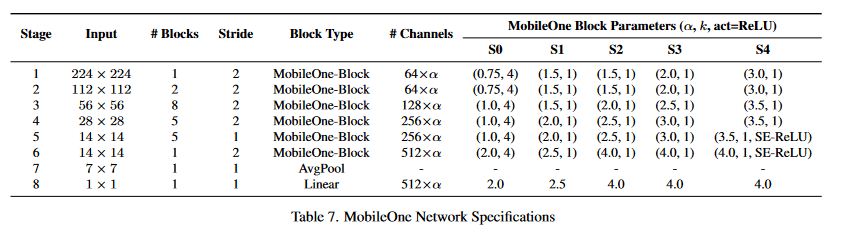
モデルのスケーリングは表の通り。EfficientNetなどでは入力解像度に対するスケーリングが行われているが、メモリアクセス面で良くないので考慮していない。
(正直CNN系は入力解像度が可変で使用用途に応じて変えるので、実用上比較時のノイズになる解像度方向のスケーリングはあまりベンチマークに示してほしくないと思う...)
Reparameterize
このモデルの肝になる部分で、推論時にスキップ接続とBatchNormを引きちぎって学習で用いたConv Kernelを変形する。ブロック内のパラメータについて考えると、
-
k -
C_{in} -
C_{out} -
M -
W_{\text{train}} \in \mathbb{R}^{C_{out}×C_{in}×k×k} -
b_{\text{train}} \in \mathbb{R}^{D} -
μ, σ, γ, β
が存在していて、これを推論時に線形構造に変形する。
スキップ接続ではBatchNormはkernel size 1x1のConvに折り込まれて、
学習
小さなモデルは大規模なモデルよりも過学習に対抗するための正則化が小さくてすむ。また、先行研究が示すように学習の初期段階でWeight Decayを行い、この正則化効果によって生じるlossをCosine Annealingすることが重要になる。また、学習にはEfficientNet v2で使われたちょっとずつAugmentation強度を変化させる学習方法を適用する。
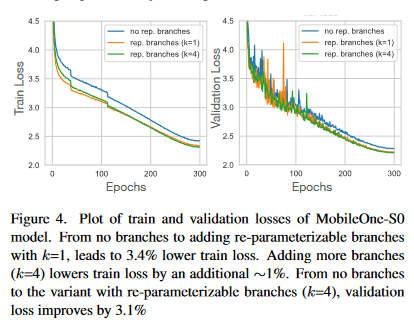
図のように、最初から変形後のアーキテクチャで学習した結果よりも、学習用のスキップ接続をつけて分岐をk=4に追加することで損失を下げることができる。
実装
timmの実装を読んで、モデルのスケーリングやオプションに関わる一般性を排して単純化したものを載せる。
import torch
import torch.nn as nn
class SqueezEexcite(nn.Module):
def __init__(self, channels):
super().__init__()
self.fc1 = nn.Conv2d(channels, channels//16, kernel_size=1)
self.act = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(channels//16, channels, kernel_size=1)
self.gate = nn.Sigmoid()
return None
def forward(self, x):
x_se = x.mean((2, 3), keepdim=True)
x_se = self.fc1(x_se)
x_se = self.act(x_se)
x_se = self.fc2(x_se)
return x * self.gate(x_se)
class ConvNormAct(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=1,
stride=1,
groups=1,
bias=False,
apply_act=True,
):
super().__init__()
self.conv = nn.Conv2d(
in_channels, out_channels, kernel_size, padding=kernel_size//2,
stride=stride, groups=groups, bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU(inplace=True) if apply_act else nn.Identity()
return None
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
class MobileOneBlock(nn.Module):
def __init__(
self,
in_chs: int,
out_chs: int,
kernel_size: int,
stride: int = 1,
groups: int = 1,
num_conv_branches: int = 4,
use_scale_branch: bool = True,
):
super(MobileOneBlock, self).__init__()
self.in_chs = in_chs
self.out_chs = out_chs
self.stride = stride
self.kernel_size = kernel_size
self.groups = groups
self.num_conv_branches = num_conv_branches
self.inference_mode = False # init train mode
self.se = SqueezEexcite(out_chs)
if self.inference_mode:
self.reparam_conv = nn.Conv2d(
in_chs,
out_chs,
kernel_size=kernel_size,
padding=kernel_size//2,
stride=stride,
groups=groups,
bias=True,
)
else:
# Re-parameterizable skip connection
self.reparam_conv = None
self.identity = (
nn.BatchNorm2d(num_features=in_chs)
if (out_chs == in_chs) and (stride == 1)
else None
)
# Re-parameterizable conv branches
self.conv_kxk = nn.ModuleList([
ConvNormAct(
in_chs,
out_chs,
kernel_size=kernel_size,
stride=stride,
groups=groups,
apply_act=False,
) for _ in range(num_conv_branches)
])
# Re-parameterizable scale branch
self.conv_scale = None
if kernel_size > 1 and use_scale_branch:
self.conv_scale = ConvNormAct(
self.in_chs,
self.out_chs,
kernel_size=1,
stride=self.stride,
groups=self.groups,
apply_act=False
)
self.act = nn.ReLU()
return None
def forward(self, x):
# Inference mode forward pass.
if self.inference_mode:
return self.act(self.se(self.reparam_conv(x)))
# Multi-branched train-time forward pass.
# Identity branch output
identity_out = self.identity(x) if (self.identity is not None) else 0
# Scale branch output
scale_out = self.conv_scale(x) if (self.conv_scale is not None) else 0
# Other kxk conv branches
out = scale_out + identity_out
if self.conv_kxk is not None:
for rc in self.conv_kxk:
out += rc(x)
return self.act(self.se(out))
def reparameterize(self):
if self.reparam_conv is not None:
return None
kernel, bias = self._get_kernel_bias()
self.reparam_conv = nn.Conv2d(
self.in_chs,
self.out_chs,
self.kernel_size,
padding=self.kernel_size//2,
stride=self.stride,
groups=self.groups,
bias=True,
)
self.reparam_conv.weight.data = kernel
self.reparam_conv.bias.data = bias
# Delete un-used branches
for name, para in self.named_parameters():
if 'reparam_conv' in name:
continue
para.detach_()
self.__delattr__("conv_kxk")
self.__delattr__("conv_scale")
if hasattr(self, "identity"):
self.__delattr__("identity")
self.inference_mode = True
return None
def _get_kernel_bias(self):
# get weights and bias of scale branch
kernel_scale = 0
bias_scale = 0
if self.conv_scale is not None:
kernel_scale, bias_scale = self._fuse_bn_tensor(self.conv_scale)
# Pad scale branch kernel to match conv branch kernel size.
pad = self.kernel_size // 2
kernel_scale = torch.nn.functional.pad(kernel_scale, [pad, pad, pad, pad])
# get weights and bias of skip branch
kernel_identity = 0
bias_identity = 0
if self.identity is not None:
kernel_identity, bias_identity = self._fuse_bn_tensor(self.identity)
# get weights and bias of conv branches
kernel_conv = 0
bias_conv = 0
if self.conv_kxk is not None:
for ix in range(self.num_conv_branches):
_kernel, _bias = self._fuse_bn_tensor(self.conv_kxk[ix])
kernel_conv += _kernel
bias_conv += _bias
kernel_final = kernel_conv + kernel_scale + kernel_identity
bias_final = bias_conv + bias_scale + bias_identity
return kernel_final, bias_final
def _fuse_bn_tensor(self, branch):
if isinstance(branch, ConvNormAct):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, "id_tensor"):
input_dim = self.in_chs // self.groups
kernel_value = torch.zeros(
(self.in_chs, input_dim, self.kernel_size, self.kernel_size),
dtype=branch.weight.dtype,
device=branch.weight.device,
)
for i in range(self.in_chs):
kernel_value[
i, i % input_dim, self.kernel_size // 2, self.kernel_size // 2
] = 1
self.id_tensor = kernel_value
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
これをインスタンス化すると次のようになる。
model = MobileOneBlock(64, 128, 3, group=64)
MobileOneBlock(
(se): SqueezEexcite(
(fc1): Conv2d(128, 8, kernel_size=(1, 1), stride=(1, 1))
(act): ReLU(inplace=True)
(fc2): Conv2d(8, 128, kernel_size=(1, 1), stride=(1, 1))
(gate): Sigmoid()
)
(conv_kxk): ModuleList(
(0-3): 4 x ConvNormAct(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(conv_scale): ConvNormAct(
(conv): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(act): ReLU()
)
そして、これをreparameterizeすることで、inferance_mode = Trueに変更され、以下のようになる。
model.reparameterize()
MobileOneBlock(
(se): SqueezEexcite(
(fc1): Conv2d(128, 8, kernel_size=(1, 1), stride=(1, 1))
(act): ReLU(inplace=True)
(fc2): Conv2d(8, 128, kernel_size=(1, 1), stride=(1, 1))
(gate): Sigmoid()
)
(act): ReLU()
(reparam_conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64)
)
実用上の問題としては、reparameterizeメソッドにアクセスする手段を考えてモデル設計しなければならない点がある。すこし煩わしいがデプロイ前にnn.Mudule.childを再帰的に呼ぶメソッドを用意してラップして使うことになるのだろうか。
具体的なモデルの全貌としては以下の構成になる。
timmのmobileone_s1.apple_1kモデルの構成例
==================================================================================================
Layer (type (var_name)) Input Shape Output Shape Param #
==================================================================================================
ByobNet (ByobNet) [1, 3, 256, 256] [1, 1000] --
├─MobileOneBlock (stem) [1, 3, 256, 256] [1, 64, 128, 128] --
│ └─ConvNormAct (conv_scale) [1, 3, 256, 256] [1, 64, 128, 128] --
│ │ └─Conv2d (conv) [1, 3, 256, 256] [1, 64, 128, 128] 192
│ │ └─BatchNormAct2d (bn) [1, 64, 128, 128] [1, 64, 128, 128] 128
│ └─ModuleList (conv_kxk)
│ │ └─ConvNormAct (0) [1, 3, 256, 256] [1, 64, 128, 128] 1,856
│ └─Identity (drop_path) [1, 64, 128, 128] [1, 64, 128, 128] --
│ └─Identity (attn) [1, 64, 128, 128] [1, 64, 128, 128] --
│ └─ReLU (act) [1, 64, 128, 128] [1, 64, 128, 128] --
├─Sequential (stages) [1, 64, 128, 128] [1, 1280, 8, 8] --
│ └─Sequential (0) [1, 64, 128, 128] [1, 96, 64, 64] --
│ │ └─MobileOneBlock (0) [1, 64, 128, 128] [1, 64, 64, 64] 896
│ │ └─MobileOneBlock (1) [1, 64, 64, 64] [1, 96, 64, 64] 6,336
│ │ └─MobileOneBlock (2) [1, 96, 64, 64] [1, 96, 64, 64] 1,536
│ │ └─MobileOneBlock (3) [1, 96, 64, 64] [1, 96, 64, 64] 9,600
│ └─Sequential (1) [1, 96, 64, 64] [1, 192, 32, 32] --
│ │ └─MobileOneBlock (0) [1, 96, 64, 64] [1, 96, 32, 32] 1,344
│ │ └─MobileOneBlock (1) [1, 96, 32, 32] [1, 192, 32, 32] 18,816
...
│ │ └─MobileOneBlock (14) [1, 192, 32, 32] [1, 192, 32, 32] 3,072
│ │ └─MobileOneBlock (15) [1, 192, 32, 32] [1, 192, 32, 32] 37,632
│ └─Sequential (2) [1, 192, 32, 32] [1, 512, 16, 16] --
│ │ └─MobileOneBlock (0) [1, 192, 32, 32] [1, 192, 16, 16] 2,688
│ │ └─MobileOneBlock (1) [1, 192, 16, 16] [1, 512, 16, 16] 99,328
...
│ │ └─MobileOneBlock (18) [1, 512, 16, 16] [1, 512, 16, 16] 8,192
│ │ └─MobileOneBlock (19) [1, 512, 16, 16] [1, 512, 16, 16] 264,192
│ └─Sequential (3) [1, 512, 16, 16] [1, 1280, 8, 8] --
│ │ └─MobileOneBlock (0) [1, 512, 16, 16] [1, 512, 8, 8] 7,168
│ │ └─MobileOneBlock (1) [1, 512, 8, 8] [1, 1280, 8, 8] 657,920
├─Identity (final_conv) [1, 1280, 8, 8] [1, 1280, 8, 8] --
├─ClassifierHead (head) [1, 1280, 8, 8] [1, 1000] --
│ └─SelectAdaptivePool2d [1, 1280, 8, 8] [1, 1280] --
│ │ └─AdaptiveAvgPool2d [1, 1280, 8, 8] [1, 1280, 1, 1] --
│ │ └─Flatten (flatten) [1, 1280, 1, 1] [1, 1280] --
│ └─Dropout (drop) [1, 1280] [1, 1280] --
│ └─Linear (fc) [1, 1280] [1, 1000] 1,281,000
│ └─Identity (flatten) [1, 1000] [1, 1000] --
================================================================================================
Total params: 4,825,192
Trainable params: 4,825,192
Non-trainable params: 0
Total mult-adds (G): 1.08
================================================================================================
Input size (MB): 0.79
Forward/backward pass size (MB): 101.06
Params size (MB): 19.03
Estimated Total Size (MB): 120.88
================================================================================================
感想
Rep-VGGが最初に出てきたときはだいぶ色物モデルだなあと思っていたが、最近実用される定番モデル群にもreparameterizeが採用されることが多く、そんなこともあるんだ...と思っている。
不思議に思っていることとしては、計算方法の変形を行ったモデルでも同じ精度の推論ができる点は謎めいているように感じる。reparameterize後に極小学習率でfine tuningして使うことになるのだろうか?
MobileNet(とEfficientNet b0)以降、この手の定番があまり更新されていなかったので、新しい定番としてMobileOneを見かけることが増えてきて良いことだと思う。また、同じ雰囲気でかなり精度面も強いFastViTも注目している。これらにより最近の大規模モデルの精度を徐々に軽量モデルでもできるようになると、実運用を考えたときに嬉しい研究成果になると思った。
追加実験
データセットとしてKvasirデータセット[1]とGastroVisionデータセット[2]を結合したものを使い、内視鏡画像28クラス分類タスクで学習させた。
[1] Pogorelov, Konstantin and Randel, Kristin Ranheim and Griwodz, Carsten and Eskeland, Sigrun Losada and de Lange, Thomas and Johansen, Dag and Spampinato, Concetto and Dang-Nguyen, Duc-Tien and Lux, Mathias and Schmidt, Peter Thelin and Riegler, Michael and Halvorsen
KVASIR: A Multi-Class Image Dataset for Computer Aided Gastrointestinal Disease Detection
https://datasets.simula.no/kvasir/
[2] Debesh Jha*, Vanshali Sharma*, Neethi Dasu, Nikhil Kumar Tomar, Steven Hicks, M.K. Bhuyan, Pradip K. Das, Michael A. Riegler, P{\aa}l Halvorsen, Thomas de Lange, Ulas Bagci
GastroVision: A Multi-class Endoscopy Image Dataset for Computer Aided Gastrointestinal Disease Detection
https://github.com/DebeshJha/GastroVision
https://arxiv.org/abs/2307.08140
このモデルを用いて推論を行う。
まず学習モードのアーキテクチャを保存して推論モードにせずに検証を行った。
MobileOneBlock(
(se): Identity()
(conv_kxk): ModuleList(
(0): ConvNormAct(
(conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNormAct2d(
64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
)
)
(conv_scale): ConvNormAct(
(conv): Conv2d(3, 64, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNormAct2d(
64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
)
(act): GELU(approximate='none')
)
MobileOneBlock(
(se): Identity()
(conv_kxk): ModuleList(
(0): ConvNormAct(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64, bias=False)
(bn): BatchNormAct2d(
64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
)
)
(conv_scale): ConvNormAct(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(2, 2), groups=64, bias=False)
(bn): BatchNormAct2d(
64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
)
(act): GELU(approximate='none')
)
MobileOneBlock(
(se): Identity()
(identity): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_kxk): ModuleList(
(0): ConvNormAct(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNormAct2d(
64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
)
)
(act): GELU(approximate='none')
)
この状態でF1精度0.941。
次にreparameterizeを行ったアーキテクチャで検証を行った。
MobileOneBlock(
(se): Identity()
(act): GELU(approximate='none')
(reparam_conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
MobileOneBlock(
(se): Identity()
(act): GELU(approximate='none')
(reparam_conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64)
)
MobileOneBlock(
(se): Identity()
(act): GELU(approximate='none')
(reparam_conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
identityとconvk×kがreparam_convに置き換わっている。
F1精度0.9041で変化しなかった。
以上の結果から、学習アーキテクチャを変更しても、実際の計算処理自体は変わらない(または最終層のロバストネスで吸収している)ので、安心して使える。
Discussion
論文をもとにコード書く場合って今回の場合どこを見ればわかるのでしょうか?