polarsによるデータ前処理
本橋智光 著
前処理大全 (Law of Awsome Data Scientist)
2018-04-13 技術評論社
https://gihyo.jp/book/2018/978-4-7741-9647-3
polarsのエクササイズとして、前処理大全(LADS)の内容を動かしてみます。
polarsはpandasより高速でrustで書かれたデータフレームライブラリで、クエリをpython式で評価できたり鬱陶しい行indexが綺麗になっていたりと色々好みなのですが、pandasほど個別の処理を上手く書いた資料が見当たらないので、手に馴染むのが少し遅いところがあったりします。
SQL...はあまり仲良くなれていないのですが、データサイエンスに関わる人間なので書けるようにならないといけませんね......
以下使用するライブラリ
import numpy as np
import polars as pl
pl.Config(
tbl_cols=10,
tbl_rows=4,
tbl_hide_dtype_separator=True,
)
from matplotlib import pyplot as plt
import arviz
arviz.style.use("arviz-darkgrid")
データ抽出、選択
単純だが、無駄な処理を減らす方が良い。(今回SQLは扱わないが)クラウドの操作で誤ってテーブル選択してしまったことで処理一発で60万円が吹きとんだ人などもいた。SQLのアンチパターンなどはLADSに非常に詳しく具体例が載っているので読むのがおすすめ。
データ列を選択
データベースからの抽出を想定した場合、氏名などのデータはセキュリティの観点でマスキングされるべきで、また文字列はデータ量を圧迫するので消したい。
pandasにおいては行/列指定抽出ができるloc(行idx,列名)/iloc(行idx,列idx)/ix(任意)の3メソッドがあるが、行数を指定する方法はアンチパターンなのでだめ。また、等価な方法として、pandasのdropはaxis=0で行を、axis=1で列を削除する方法をつかうこともできる。dropは抽出には使うべきでないが、inplace(破壊的な変更)時のメモリ効率などから使用を検討することもある。
`pl.Dataframe`への簡単なアクセス方一覧
データフレームの作成
-
series = pl.Series("column", [values...]): シリーズ作成(列) -
df = pl.DataFrame([series1...]): データフレーム作成 -
df = pl.DataFrame({"column": [values...], ...}): 辞書からデータフレーム作成
データ列へアクセス
-
df.select("column"): 特定の列をデータフレームとして抽出(複数渡すことも可能) -
df.get_column("column"): 特定の列をシリーズとして抽出
データ行へアクセス
-
series[idx]: idx行目の値を抽出 -
df[idx]: idx行目のデータフレーム(スライスも可能)を抽出 -
df.filter(pl.col("column") == value): 特定の列の特定の値を持つ行のデータフレームを抽出
要素の抽出
-
df.item():df.shapeが(1,1)まで絞れているデータフレームから要素を抽出
シリーズの作成
pl.Seriesで列名と値を持ったシリーズを作れる。
引数は以下
-
name: ArrayLike | str | None = None -
values: ArrayLike | None = None -
dtype: PolarsDataType | None = None -
strict: bool = True ← オーバーフロー時にエラーを投げる -
nan_to_null: bool = False ← NaNをNullとして置き換え -
dtype_if_empty: PolarsDataType | None = None
nameがNoneだと列名が空文字になるので可能な限り名前をつける方が良い。
s = pl.Series("c1", [1,2,3,4,5])
print(s)
# shape: (5,)
# Series: 'c1' [i64]
# [
# 1
# 2
# 3
# 4
# 5
# ]
データフレームの作成
pl.DataFrameでシリーズを連結してデータフレームを作成する。
引数は以下
-
data: FrameInitTypes | None = None -
schema: SchemaDefinition | None = None ← 列毎のデータ型 -
schema_overrides: SchemaDict | None = None -
orient: Orientation | None = None -
infer_schema_length: int | None = N_INFER_DEFAULT -
nan_to_null: bool = False
s1 = pl.Series("c1", [1,2,3,4,5])
s2 = pl.Series("c2", [1.0,1.0,2.0,3.0,5.0])
s3 = pl.Series("c3", ["a","b","c","d","e"])
df = pl.DataFrame([s1,s2,s3])
print(df)
# ┌─────┬─────┬─────┐
# │ c1 ┆ c2 ┆ c3 │
# │ i64 ┆ f64 ┆ str │
# ╞═════╪═════╪═════╡
# │ 1 ┆ 1.0 ┆ a │
# │ 2 ┆ 1.0 ┆ b │
# │ 3 ┆ 2.0 ┆ c │
# │ 4 ┆ 3.0 ┆ d │
# │ 5 ┆ 5.0 ┆ e │
# └─────┴─────┴─────┘
また、series以外にもdictでデータを渡すこともできる。
df = pl.DataFrame(
{
"c1": [1,2,3,4,5],
"c2": [1.0,1.0,2.0,3.0,5.0],
"c3": ["a","b","c","d","e"]
})
print(df)
# ┌─────┬─────┬─────┐
# │ c1 ┆ c2 ┆ c3 │
# │ i64 ┆ f64 ┆ str │
# ╞═════╪═════╪═════╡
# │ 1 ┆ 1.0 ┆ a │
# │ 2 ┆ 1.0 ┆ b │
# │ 3 ┆ 2.0 ┆ c │
# │ 4 ┆ 3.0 ┆ d │
# │ 5 ┆ 5.0 ┆ e │
# └─────┴─────┴─────┘
データフレームの形状は次のように得られる。
print(df.columns)
# ['name', 'c1', 'c2']
print(df.dtypes)
# [Utf8, Float32, Float32]
print(df.schema)
# {'name': Utf8, 'c1': Float32, 'c2': Float32}
print(df.shape) # (df.height, df.width)と等価
# (4, 3)
行へのアクセス
df[idx]で行を選択してデータフレームを得られる。
print(df[2])
# ┌─────┬─────┬─────┐
# │ c1 ┆ c2 ┆ c3 │
# │ i64 ┆ f64 ┆ str │
# ╞═════╪═════╪═════╡
# │ 3 ┆ 2.0 ┆ c │
# └─────┴─────┴─────┘
print(df[2:4])
# ┌─────┬─────┬─────┐
# │ c1 ┆ c2 ┆ c3 │
# │ i64 ┆ f64 ┆ str │
# ╞═════╪═════╪═════╡
# │ 3 ┆ 2.0 ┆ c │
# │ 4 ┆ 3.0 ┆ d │
# └─────┴─────┴─────┘
print(df.head(3))
# ┌─────┬─────┬─────┐
# │ c1 ┆ c2 ┆ c3 │
# │ i64 ┆ f64 ┆ str │
# ╞═════╪═════╪═════╡
# │ 1 ┆ 1.0 ┆ a │
# │ 2 ┆ 1.0 ┆ b │
# │ 3 ┆ 2.0 ┆ c │
# └─────┴─────┴─────┘
print(df.tail(3))
# ┌─────┬─────┬─────┐
# │ c1 ┆ c2 ┆ c3 │
# │ i64 ┆ f64 ┆ str │
# ╞═════╪═════╪═════╡
# │ 3 ┆ 2.0 ┆ c │
# │ 4 ┆ 3.0 ┆ d │
# │ 5 ┆ 5.0 ┆ e │
# └─────┴─────┴─────┘
arrayからDataframeへの受け渡し
array = np.array(...)
df = pl.DataFrame(array, schema=['name', 'column1', 'column2', 'column3', 'column4', 'column5'])
print(df)
# ┌───────────┬─────────┬─────────┬─────────┬─────────┬─────────┐
# │ name ┆ column1 ┆ column2 ┆ column3 ┆ column4 ┆ column5 │ ← schemaにより列名がつく
# │ object ┆ object ┆ object ┆ object ┆ object ┆ object │ ← 文字列が含まれるnumpy.arrayはdtype=object
# ╞═══════════╪═════════╪═════════╪═════════╪═════════╪═════════╡
# │ natori ┆ 38.0 ┆ 0 ┆ 6147 ┆ nan ┆ 2471 │
# │ kenmochi ┆ nan ┆ 1 ┆ 3192 ┆ 5969.0 ┆ 5878 │
# │ ririmu ┆ 56.0 ┆ 0 ┆ 1594 ┆ 3632.0 ┆ 9449 │
# │ hoshikawa ┆ 34.0 ┆ 1 ┆ 8722 ┆ 5961.0 ┆ 8581 │
# └───────────┴─────────┴─────────┴─────────┴─────────┴─────────┘
以前記事で使ったダミーデータで遊ぶ。
data = pl.read_csv("datatable_use.csv")
# ┌─────────┬──────────┬─────┬────────────┬───────────┬───────────┬───────┬───────────┬───────────┐
# │ userid ┆ seibetsu ┆ age ┆ totalmoney ┆ name ┆ diligent ┆ shiwa ┆ bourgeois ┆ purchased │
# │ str ┆ str ┆ i64 ┆ i64 ┆ str ┆ f64 ┆ i64 ┆ i64 ┆ str │
# ╞═════════╪══════════╪═════╪════════════╪═══════════╪═══════════╪═══════╪═══════════╪═══════════╡
# │ WG78242 ┆ men ┆ 64 ┆ 63000 ┆ xHb3abbTf ┆ -5.843427 ┆ 120 ┆ 66 ┆ robots │
# │ RP38278 ┆ women ┆ 44 ┆ 75000 ┆ ZPPD0xV0 ┆ 0.629551 ┆ 82 ┆ 65 ┆ wallpaper │
# │ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
# │ EB65331 ┆ women ┆ 24 ┆ 83000 ┆ f2wtD ┆ -4.911862 ┆ 55 ┆ 70 ┆ mansions │
# │ AC71951 ┆ men ┆ 47 ┆ 97000 ┆ e4QX3Gw ┆ -4.831748 ┆ 70 ┆ 91 ┆ airplane │
# └─────────┴──────────┴─────┴────────────┴───────────┴───────────┴───────┴───────────┴───────────┘
# 文字列型以外のデータを選択する
data.select(["age", "totalmoney", "diligent", "shiwa", "bourgeois"])
# ┌─────┬────────────┬───────────┬───────┬───────────┐
# │ age ┆ totalmoney ┆ diligent ┆ shiwa ┆ bourgeois │
# │ i64 ┆ i64 ┆ f64 ┆ i64 ┆ i64 │
# ╞═════╪════════════╪═══════════╪═══════╪═══════════╡
# │ 64 ┆ 63000 ┆ -5.843427 ┆ 120 ┆ 66 │
# │ 44 ┆ 75000 ┆ 0.629551 ┆ 82 ┆ 65 │
# │ … ┆ … ┆ … ┆ … ┆ … │
# │ 24 ┆ 83000 ┆ -4.911862 ┆ 55 ┆ 70 │
# │ 47 ┆ 97000 ┆ -4.831748 ┆ 70 ┆ 91 │
# └─────┴────────────┴───────────┴───────┴───────────┘
data.drop(["userid", "seibetsu", "name", "purchased"])
# ┌─────┬────────────┬───────────┬───────┬───────────┐
# │ age ┆ totalmoney ┆ diligent ┆ shiwa ┆ bourgeois │
# │ i64 ┆ i64 ┆ f64 ┆ i64 ┆ i64 │
# ╞═════╪════════════╪═══════════╪═══════╪═══════════╡
# │ 64 ┆ 63000 ┆ -5.843427 ┆ 120 ┆ 66 │
# │ 44 ┆ 75000 ┆ 0.629551 ┆ 82 ┆ 65 │
# │ … ┆ … ┆ … ┆ … ┆ … │
# │ 24 ┆ 83000 ┆ -4.911862 ┆ 55 ┆ 70 │
# │ 47 ┆ 97000 ┆ -4.831748 ┆ 70 ┆ 91 │
# └─────┴────────────┴───────────┴───────┴───────────┘
pandasのinplaceについてはこの記事が非常に詳しい
条件指定による列選択
SQLなどではデータの中身を確認しなくても条件判別できるようにindexを使うと計算リソースの効率がいい。
(LADS内ではpandas.Dataframe.queryメソッドによる選択が変更にロバストとして推奨されているが、個人的には文字列として評価式を各のはエディタの支援を受けられないコードになるのであまり好ましく思わない。pandasではなくpolarsを使い始めたのもこの部分をexpressionでコードとして書けるからである)
# 購入金額を範囲選択する
data.filter((60000 < pl.col("totalmoney")) & (80000 > pl.col("totalmoney")))
# shape: (189, 9)
# ┌─────────┬──────────┬─────┬────────────┬───────────┬───────────┬───────┬───────────┬───────────┐
# │ userid ┆ seibetsu ┆ age ┆ totalmoney ┆ name ┆ diligent ┆ shiwa ┆ bourgeois ┆ purchased │
# │ str ┆ str ┆ i64 ┆ i64 ┆ str ┆ f64 ┆ i64 ┆ i64 ┆ str │
# ╞═════════╪══════════╪═════╪════════════╪═══════════╪═══════════╪═══════╪═══════════╪═══════════╡
# │ WG78242 ┆ men ┆ 64 ┆ 63000 ┆ xHb3abbTf ┆ -5.843427 ┆ 120 ┆ 66 ┆ robots │
# │ RP38278 ┆ women ┆ 44 ┆ 75000 ┆ ZPPD0xV0 ┆ 0.629551 ┆ 82 ┆ 65 ┆ wallpaper │
# │ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
# │ TI14229 ┆ women ┆ 33 ┆ 77000 ┆ E75H4njf0 ┆ -4.209395 ┆ 72 ┆ 67 ┆ robots │
# │ FL57622 ┆ women ┆ 49 ┆ 62000 ┆ GNVqARVT ┆ 4.1953835 ┆ 57 ┆ 49 ┆ carpets │
# └─────────┴──────────┴─────┴────────────┴───────────┴───────────┴───────┴───────────┴───────────┘
サンプリング
データフレームからランダムに行レコードをドローすることで、データを抽出する。
SQLにおいては、ORDER BY RANDOM()として先頭をとってくる方法はORDER処理の効率が悪いので、WHERE RANDOM() < pのようにして行idxを使って持ってくる。
pandasではsampleで簡単に持ってこれる。
# データから100件のレコードをランダムに抽出
data.sample(n=100)
# shape: (100, 9)
# ┌─────────┬──────────┬─────┬────────────┬──────────┬───────────┬───────┬───────────┬───────────┐
# │ userid ┆ seibetsu ┆ age ┆ totalmoney ┆ name ┆ diligent ┆ shiwa ┆ bourgeois ┆ purchased │
# │ str ┆ str ┆ i64 ┆ i64 ┆ str ┆ f64 ┆ i64 ┆ i64 ┆ str │
# ╞═════════╪══════════╪═════╪════════════╪══════════╪═══════════╪═══════╪═══════════╪═══════════╡
# │ KM97399 ┆ women ┆ 77 ┆ 67000 ┆ ZmmznfZq ┆ -0.368318 ┆ null ┆ 60 ┆ cosmetics │
# │ IN34867 ┆ men ┆ 73 ┆ 35000 ┆ E0K7M ┆ 4.2167583 ┆ 94 ┆ 36 ┆ shelves │
# │ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
# │ RC51034 ┆ women ┆ 50 ┆ 92000 ┆ gY9Kw ┆ -0.831305 ┆ 96 ┆ 86 ┆ mansions │
# │ EF74296 ┆ men ┆ 51 ┆ 46000 ┆ 6yMuV ┆ 5.1154947 ┆ 78 ┆ 51 ┆ wallpaper │
# └─────────┴──────────┴─────┴────────────┴──────────┴───────────┴───────┴───────────┴───────────┘
条件つきのサンプリングについても実行する。
まずある列(例えばpurchased)からサンプリングした値のレコードを抽出する、一部にランダム要素がある選択は次のようにする。
LADS内では主にSQLでの無駄な処理が発生しないような書き方を解説しているが、pandasやpolarsでは簡単にかける。
# 購入品目のうち、**重複しない**品目についてランダムに3割抽出し、その購入品目を持つレコードを選択する
target = data.select("purchased").unique().sample(fraction=0.3)
# ┌───────────┐
# │ purchased │
# │ str │
# ╞═══════════╡
# │ shelves │
# │ wallpaper │
# │ cosmetics │
# └───────────┘
data.filter(pl.col("purchased").is_in(target))
# shape: (377, 9)
# ┌─────────┬──────────┬─────┬────────────┬───────────┬───────────┬───────┬───────────┬───────────┐
# │ userid ┆ seibetsu ┆ age ┆ totalmoney ┆ name ┆ diligent ┆ shiwa ┆ bourgeois ┆ purchased │
# │ str ┆ str ┆ i64 ┆ i64 ┆ str ┆ f64 ┆ i64 ┆ i64 ┆ str │
# ╞═════════╪══════════╪═════╪════════════╪═══════════╪═══════════╪═══════╪═══════════╪═══════════╡
# │ RP38278 ┆ women ┆ 44 ┆ 75000 ┆ ZPPD0xV0 ┆ 0.629551 ┆ 82 ┆ 65 ┆ wallpaper │
# │ EV55298 ┆ women ┆ 28 ┆ 54000 ┆ ae7vQb ┆ 0.217086 ┆ 28 ┆ 43 ┆ shelves │
# │ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
# │ QD20371 ┆ men ┆ 30 ┆ 12000 ┆ RoTaNUxI ┆ 4.2189426 ┆ null ┆ 35 ┆ shelves │
# │ CU60828 ┆ men ┆ 51 ┆ 34000 ┆ TPf7eOOS1 ┆ -2.753193 ┆ 81 ┆ 44 ┆ shelves │
# └─────────┴──────────┴─────┴────────────┴───────────┴───────────┴───────┴───────────┴───────────┘
統計量の集計
無駄な処理を行わないように書くほうがAwesomeだとされる。前述の通り、SQLではミスにより非効率な計算機リソースを食ったり、お金がかかる事があるので、結合などの重い処理を回避するように書くべき。
データ数、水準数
ある列(例えばpurchased)の各水準に属するユニークな値を取ってくる。
単純にこれを行うならgroup_byの集約メソッドsize, nuniqueを使うが、Awesomeな実装ではaggを使う方が高効率。
# 購入品目ごとにユーザIDと名前を集約
data.group_by("purchased").agg(["userid", "name"])
# shape: (12, 3)
# ┌───────────┬───────────────────────────────────┬───────────────────────────────────┐
# │ purchased ┆ userid ┆ name │
# │ str ┆ list[str] ┆ list[str] │
# ╞═══════════╪═══════════════════════════════════╪═══════════════════════════════════╡
# │ robots ┆ ["WG78242", "KY50919", … "LV1519… ┆ ["xHb3abbTf", "eI1CBE8", … "2vHJ… │
# │ mansions ┆ ["WT95574", "QX16563", … "EB6533… ┆ ["eq0HNV", "Fu2DENe", … "f2wtD"] │
# │ … ┆ … ┆ … │
# │ sushi ┆ ["AV23759", "LX83727", … "KG9127… ┆ ["J2ajE2", "DHq0Sajq", … "2OgUat… │
# │ steak ┆ ["WY70836", "NF99178", … "BW7110… ┆ ["RX9EzX", "Q04LInkvc", … "hvCZ5… │
# └───────────┴───────────────────────────────────┴───────────────────────────────────┘
代表的な統計量
ある列の合計や平均、最大、最小などを取ってくる。列の選択などが絡む場合には、計算量を抑えた方法で計算するのが良い。
本を読んでいるとpandasのreset_indexが非常に鬱陶しく感じてしまう。polarsなら煩わされることなくコードが書けて嬉しい。
# 購入された商品ごとに合計売上を計算
data.group_by("purchased").sum().select(["purchased", "totalmoney"])
# shape: (12, 2)
# ┌───────────┬────────────┐
# │ purchased ┆ totalmoney │
# │ str ┆ i64 │
# ╞═══════════╪════════════╡ 欠損値Nullは無視される
# │ mansions ┆ 6577000 │
# │ jewelry ┆ 4688000 │
# │ … ┆ … │
# │ potatoes ┆ 35000 │
# │ peace ┆ 178000 │
# └───────────┴────────────┘
集計関数の詳細
列ごとの集計
-
DataFrame.max(): 最大値 -
DataFrame.min(): 最小値 -
DataFrame.sum(): 和 -
ataFrame.product(): 積 -
DataFrame.mean(): 平均 -
DataFrame.median(): 中央値 -
DataFrame.quantile(q, interpolation="nearest"): 分位(q%点の値) -
DataFrame.var(d=1): 分散(dは自由度 N-d) -
DataFrame.std(d=1): 標準偏差(dは自由度 N-d)
全体の要約を見る場合は以下
df.describe()
列を集計
次のデータフレームを各メソッドで集計する。
df = pl.DataFrame({
"name": ["a","b","c","d","e"],
"c1": [1,2,3,4,5],
"c2": [6,7,8,9,0]
})
df.min()
# ┌──────┬─────┬─────┐
# │ name ┆ c1 ┆ c2 │
# │ str ┆ i64 ┆ i64 │
# ╞══════╪═════╪═════╡
# │ a ┆ 1 ┆ 0 │
# └──────┴─────┴─────┘
df.max()
# ┌──────┬─────┬─────┐
# │ name ┆ c1 ┆ c2 │
# │ str ┆ i64 ┆ i64 │
# ╞══════╪═════╪═════╡
# │ e ┆ 5 ┆ 9 │
# └──────┴─────┴─────┘
df.sum()
# ┌──────┬─────┬─────┐ boolは論理和を取る
# │ name ┆ c1 ┆ c2 │
# │ str ┆ i64 ┆ i64 │
# ╞══════╪═════╪═════╡
# │ null ┆ 15 ┆ 30 │
# └──────┴─────┴─────┘
df.mean()
# shape: (1, 3)
# ┌──────┬─────┬─────┐
# │ name ┆ c1 ┆ c2 │
# │ str ┆ f64 ┆ f64 │
# ╞══════╪═════╪═════╡
# │ null ┆ 3.0 ┆ 6.0 │
# └──────┴─────┴─────┘
df.product()
# shape: (1, 2)
# ┌─────┬─────┐ 積はutf8型が含まれるとエラー
# │ c1 ┆ c2 │ boolは論理積を取る
# │ i64 ┆ i64 │
# ╞═════╪═════╡
# │ 120 ┆ 0 │
# └─────┴─────┘
df.median()
# shape: (1, 3)
# ┌──────┬─────┬─────┐ これはdf.quantile(0.5)と等価
# │ name ┆ c1 ┆ c2 │
# │ str ┆ f64 ┆ f64 │
# ╞══════╪═════╪═════╡
# │ null ┆ 3.0 ┆ 7.0 │
# └──────┴─────┴─────┘
df.quantile(0.25)
# shape: (1, 3)
# ┌──────┬─────┬─────┐ 4分位範囲などを計算できる
# │ name ┆ c1 ┆ c2 │ 補完方法は"nearest", "higher", "lower", "midpoint", "linear"から選べる
# │ str ┆ f64 ┆ f64 │
# ╞══════╪═════╪═════╡
# │ null ┆ 2.0 ┆ 6.0 │
# └──────┴─────┴─────┘
df.var()
# shape: (1, 3)
# ┌──────┬─────┬──────┐ デフォルトで不偏分散
# │ name ┆ c1 ┆ c2 │ ddof=0 にすると標本分散が計算できる
# │ str ┆ f64 ┆ f64 │
# ╞══════╪═════╪══════╡
# │ null ┆ 2.5 ┆ 12.5 │
# └──────┴─────┴──────┘
df.std()
# shape: (1, 3)
# ┌──────┬──────────┬──────────┐
# │ name ┆ c1 ┆ c2 │
# │ str ┆ f64 ┆ f64 │
# ╞══════╪══════════╪══════════╡
# │ null ┆ 1.581139 ┆ 3.535534 │
# └──────┴──────────┴──────────┘
要約
df.describe()
# ┌────────────┬──────┬──────────┬──────────┐
# │ describe ┆ name ┆ c1 ┆ c2 │
# │ str ┆ str ┆ f64 ┆ f64 │
# ╞════════════╪══════╪══════════╪══════════╡
# │ count ┆ 5 ┆ 5.0 ┆ 5.0 │
# │ null_count ┆ 0 ┆ 0.0 ┆ 0.0 │
# │ mean ┆ null ┆ 3.0 ┆ 6.0 │
# │ std ┆ null ┆ 1.581139 ┆ 3.535534 │
# │ min ┆ a ┆ 1.0 ┆ 0.0 │
# │ 25% ┆ null ┆ 2.0 ┆ 6.0 │
# │ 50% ┆ null ┆ 3.0 ┆ 7.0 │
# │ 75% ┆ null ┆ 4.0 ┆ 8.0 │
# │ max ┆ e ┆ 5.0 ┆ 9.0 │
# └────────────┴──────┴──────────┴──────────┘
行(レコード)方向への演算
行の集計
-
df.fold(funcion): functionを行に適用し、seriesを返す
例えば以下のような操作ができる
-
df.fold(lambda s1, s2: s1 + s2): 行方向の和 -
df.fold(lambda s1, s2: s1.zip_with(s1 < s2, s2): 行方向の最小値
functionは2つのseries間の計算である必要があり、列ごとにfoldされて計算される。
行の集計
foldで行方向に適用する関数を作用させ、1列のデータ(series)を返す。
df = pl.DataFrame({
"c1": [1,2,3,4,5],
"c2": [6,7,8,9,0],
"c3": [2,4,6,8,10]
})
df.fold(lambda s1, s2: s1 + s2)
# shape: (5,)
# Series: 'c1' [i64] 各行の和
# [
# 9
# 13
# 17
# 21
# 15
# ]
df.fold(lambda s1, s2: s1.zip_with(s1 < s2, s2))
# shape: (5,)
# Series: 'c1' [i64] 各行の最小値
# [
# 1
# 2
# 3
# 4
# 0
# ]
df.fold(lambda s1, s2: s1 + s2)
# shape: (5,)
# Series: 'c1' [str] utf8やbool型も定義された演算なら計算可能
# [
# "aejr"
# "bfer"
# "cgyr"
# "dhur"
# "eilr"
# ]
順位
機械学習などのコンペで前処理としてRank-Gaussなどの処理がある。また、時系列データに対して前後関係を保つためのランクを振るために使うこともある。
SQLでは計算コストが非常にシビアで、全体の値へアクセスする処理を何も考えずに使うと計算リソースを圧迫する書き方になる。WINDOW()などを利用して順位付けを小分けにすることで効率化するなど工夫が必要。
# 購入品目ごとに購入金額でランク付けして選択
df = (
data
.with_columns(pl.col("totalmoney").rank("max").over("purchased").alias("rank"))
.select(["purchased", "totalmoney", "rank"])
)
# ┌───────────┬────────────┬──────┐
# │ purchased ┆ totalmoney ┆ rank │
# │ str ┆ i64 ┆ u32 │
# ╞═══════════╪════════════╪══════╡
# │ robots ┆ 63000 ┆ 21 │
# │ wallpaper ┆ 75000 ┆ 89 │
# │ … ┆ … ┆ … │
# │ mansions ┆ 83000 ┆ 42 │
# │ airplane ┆ 97000 ┆ 18 │
# └───────────┴────────────┴──────┘
データテーブルの結合
PythonやRだとデータをメモリに上げなければならないので、大規模なデータを使うのはSQLが良い。
df_user = data.select(["userid", "seibetsu", "age", "name"])
df_alt = data.select(["userid", "shiwa", "diligent", "bourgeois"])
df_buy = data.select(["userid", "totalmoney", "purchased"])
# "userid"を一致させながら列方向に結合
df = df_user.join(df_alt, on="userid")
df = df.join(df_buy, on="userid")
# ┌─────────┬──────────┬─────┬───────────┬───────┬───────────┬───────────┬────────────┬───────────┐
# │ userid ┆ seibetsu ┆ age ┆ name ┆ shiwa ┆ diligent ┆ bourgeois ┆ totalmoney ┆ purchased │
# │ str ┆ str ┆ i64 ┆ str ┆ i64 ┆ f64 ┆ i64 ┆ i64 ┆ str │
# ╞═════════╪══════════╪═════╪═══════════╪═══════╪═══════════╪═══════════╪════════════╪═══════════╡
# │ WG78242 ┆ men ┆ 64 ┆ xHb3abbTf ┆ 120 ┆ -5.843427 ┆ 66 ┆ 63000 ┆ robots │
# │ RP38278 ┆ women ┆ 44 ┆ ZPPD0xV0 ┆ 82 ┆ 0.629551 ┆ 65 ┆ 75000 ┆ wallpaper │
# │ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
# │ EB65331 ┆ women ┆ 24 ┆ f2wtD ┆ 55 ┆ -4.911862 ┆ 70 ┆ 83000 ┆ mansions │
# │ AC71951 ┆ men ┆ 47 ┆ e4QX3Gw ┆ 70 ┆ -4.831748 ┆ 91 ┆ 97000 ┆ airplane │
# └─────────┴──────────┴─────┴───────────┴───────┴───────────┴───────────┴────────────┴───────────┘
オーバーサンプリングとオーバーサンプリング
不均衡データにより大き過ぎるデータを消すアンダーサンプリングと、小さいデータを増やすオーバーサンプリングはよく機械学習の枠組みで使われる。
アンダーサンプリングは分割と結合により簡単に実装できるが、オーバーサンプリングはSMOTEによって行うのがAwsome。
SMOTE(Synthetic Minority Over-Sampling Techniqu): データにガウスノイズを付加して新しいデータを生成することでデータ数を水増しする。単純なコピーより多様なデータを作れる。
これはsklearnと互換なインターフェイスを持つimblearn (imbalanced-learn)を使える。
# 不均衡なダミーデータを作成してそれを使ってSMOTEを行ってみる
# 多くのデータを持つ{x_1, xx_1}のクラスと小さな{x_2, xx_2}のクラスを作る
x_1 = np.random.normal(0, 1, 512)
xx_1 = 4 * x_1 + np.random.normal(0, 4, 512)
t_1 = np.zeros(512, dtype=np.uint8)
x_2 = np.random.normal(-1, 1, 32)
xx_2 = 2 * x_2 + np.random.normal(8, 5, 32)
t_2 = np.ones(32, dtype=np.uint8)
df = pl.DataFrame({
"x": np.concatenate([x_1, x_2]),
"xx": np.concatenate([xx_1, xx_2]),
"t": np.concatenate([t_1, t_2])
})
# SMOTEで{x_2, xx_2}クラスをオーバーサンプリングする
from imblearn.over_sampling import SMOTE
smote = SMOTE()
x_blanced, t_blanced = smote.fit_resample(
df.select(["x", "xx"]).to_numpy(),
df.select("t").to_numpy()
)
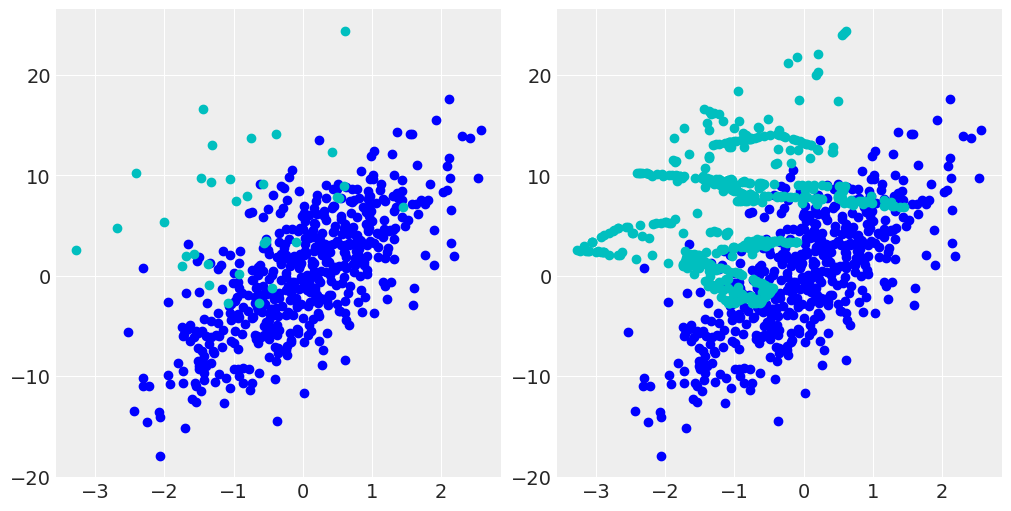
print(x_blanced.shape, t_blanced.shape) # 大きいデータ512個に合わせて小さいデータが増えた
x_2_blanced = x_blanced[-512:, 0]
xx_2_blanced = x_blanced[-512:, 1]
fig, axes = plt.subplots(1, 2, figsize=(10,5))
axes[0].scatter(x_1, xx_1, c="b")
axes[0].scatter(x_2, xx_2, c="c")
axes[1].scatter(x_1, xx_1, c="b")
axes[1].scatter(x_2_blanced, xx_2_blanced, c="c")
Label-Encodeの疎行列化
カテゴリ変数などのような水準を記録した行(レコード)を持つデータから、カテゴリごとのカウントを計算して列方向に置き直す。
単純な同水準を持つレコード数のカウントはgroup_byで出せるが、水準数が莫大なサイズの場合、Label-Encodeなどを行うとone-hotなデータが巨大な疎行列になる可能性がある。この場合、データを正式に疎行列として扱うことでメモリ効率を高められる。
# Label-Encodeしたデータを疎行列にする
df = data.select(["seibetsu", "age", "purchased"]).to_dummies()
# shape: (999, 77)
# ┌─────────┬─────────┬─────────┬────────┬────────┬───┬─────────┬─────────┬────────┬────────┬────────┐
# │ seibets ┆ seibets ┆ seibets ┆ age_21 ┆ age_22 ┆ … ┆ purchas ┆ purchas ┆ purcha ┆ purcha ┆ purcha │
# │ u_NaN ┆ u_men ┆ u_women ┆ u8 ┆ u8 ┆ ┆ ed_robo ┆ ed_shel ┆ sed_st ┆ sed_su ┆ sed_wa │
# │ u8 ┆ u8 ┆ u8 ┆ ┆ ┆ ┆ ts ┆ ves ┆ eak ┆ shi ┆ llpape │
# │ ┆ ┆ ┆ ┆ ┆ ┆ u8 ┆ u8 ┆ u8 ┆ u8 ┆ r │
# │ ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ u8 │
# ╞═════════╪═════════╪═════════╪════════╪════════╪═══╪═════════╪═════════╪════════╪════════╪════════╡
# │ 0 ┆ 1 ┆ 0 ┆ 0 ┆ 0 ┆ … ┆ 1 ┆ 0 ┆ 0 ┆ 0 ┆ 0 │
# │ 0 ┆ 0 ┆ 1 ┆ 0 ┆ 0 ┆ … ┆ 0 ┆ 0 ┆ 0 ┆ 0 ┆ 1 │
# │ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
# │ 0 ┆ 0 ┆ 1 ┆ 0 ┆ 0 ┆ … ┆ 0 ┆ 0 ┆ 0 ┆ 0 ┆ 0 │
# │ 0 ┆ 1 ┆ 0 ┆ 0 ┆ 0 ┆ … ┆ 0 ┆ 0 ┆ 0 ┆ 0 ┆ 0 │
# └─────────┴─────────┴─────────┴────────┴────────┴───┴─────────┴─────────┴────────┴────────┴────────┘
print(df.to_numpy().__sizeof__()) # -> 128 B
from scipy import sparse
# COO疎行列: 非ゼロ要素の座標と値のリストを扱う
# 一般的に用いられ、他形式への変換も高速
df_coo = sparse.coo_matrix(df.to_numpy())
print(df_coo.__sizeof__()) # -> 16 B
# (0, 1) 1
# (0, 46) 1
# (0, 72) 1
# (1, 2) 1
# (1, 26) 1
# (1, 76) 1
# (2, 2) 1
# (2, 41) 1
# ...
# (998, 1) 1
# (998, 29) 1
# (998, 65) 1
# CSR疎行列: 行(レコード)方向に対する処理、特にベクトルとの積が高速
df_csr = sparse.csr_matrix(df.to_numpy())
print(df_csr.__sizeof__()) # -> 16 B
# CSC疎行列: CSRの列方向版
df_csc = sparse.csc_matrix(df.to_numpy())
print(df_csc.__sizeof__()) # -> 16 B
データのサイズが小さくなったことがわかる。
感想
一通りのデータフレームの使い方は試せた。
本の内容としては、SQLの勉強とPythonにおけるデータフレームの扱いの基本中の基本に関してはとても良書に思える。しかしRについても書いてあるので(R使いには良いことではあるが)ページの1/4ほどは読み飛ばす形になったのですぐに読み終わってしまった。欲を言えばPython/Rのデータフレームライブラリについてもう少しメモリ効率など踏み込んでほしい気もする。AAMLPの方でも触れられていたが、Label-Encodeを疎行列化することは読むまで思いつかなかったので、この本を読んで最も良かった点だったかもしれない。
最近CUDAによるデータフレームcudfを試す流れがあったのだが、正直なところ並列演算が要るほどの大きなテーブルデータに巡り合ったことがないので、今はpolarsの高速さで間に合ってる感がある。
実際英語の辞書CSVをpandasで扱ったときは遅くて困難を感じたが、polarsなら許容できる速さが出たので、さすがRustの力というところかもしれない。
Discussion