Sparse Estimation with Python 勉強ノート 2.2 Lasso回帰の実装
鈴木讓 著
スパース推定100問 with Python
2021-01-29
https://www.kyoritsu-pub.co.jp/book/b10003298.html
Christopher M. Bishop 著, 元田浩 栗田多喜夫 樋口知之 松本裕治 村田昇 監訳
パターン認識と機械学習 ベイズ理論による統計的予測 (Pattern Recognition and Machine Learning)
2012-01-20
https://www.maruzen-publishing.co.jp/item/?book_no=294524
以前の記事をまとめて、Lasso回帰とLasso-Logistic回帰を実装します。
PRMLを読みながらスパース推定100問の行間を補完し、プログラムの見通しを良くしたいです。
以下はこの記事で使うパッケージ
import numpy as np
import polars as pl
from matplotlib import pyplot as plt
1. Lasso回帰
Lasso回帰の一般化表現の導出
入力データ
データが平均
この時、MAP推定により次の損失関数が導かれる。
中心化により
また、MAP推定に戻ると、事後分布を最大化する
より簡潔に軟閾値作用素(Soft Thresholding Operator)
この
Lasso回帰の実装
def linear_lasso(x_feat, y_target, lambda_=1.0):
N, D = x_feat.shape
w = np.zeros(D)
# 特徴を標準化
x_feat_mean = x_feat.mean(axis=0, keepdims=True)
x_feat_std = x_feat.std(axis=0, keepdims=True)
x_feat = (x_feat - x_feat_mean) / x_feat_std
# 座標降下法
eps = 0.000001 # 収束判定条件
w_old = np.ones_like(w)
while np.linalg.norm(w - w_old) > eps:
for d1 in range(D):
y_d1 = y_target
for d2 in range(D):
y_d1 = (y_d1 - x_feat[:, d2] * w[d2]) if d1 != d2 else y_d1
z = ((y_d1.T @ x_feat[:, d1:d1+1]) / N) / ((x_feat[:, d1:d1+1].T @ x_feat[:, d1:d1+1]) / N)
w[d1] = np.sign(z[0,0]) * np.maximum(np.abs(z[0,0]) - lambda_, 0) # L1 Norm部分の劣微分区間 [-λ, λ] → 0
# ↑ maximum(a, b) == where(a > b, a, b)
w_old = w
# スケールを戻す
w = w / x_feat_std
w_0 = y_target.mean() - (x_feat_mean.T @ w)
return w_0, w
def general_linear_lasso(x_feat, y_target, R=np.zeros(1), lambda_=1.0):
N, D = x_feat.shape
R = np.identity(N) if np.sum(R) == 0 else R
is_diagonal = lambda matrix: np.all(matrix == np.diag(np.diagonal(matrix)))
x_feat_mean = np.zeros((1, D))
for d in range(D):
x_feat_mean[:, d] = np.sum(R @ x_feat[:, d]) / np.sum(R)
x_feat[:, d] = x_feat[:, d] - x_feat_mean[:, d]
y_target_mean = np.sum(R @ y_target) / np.sum(R)
y_target = y_target - y_target_mean
R_ch = np.sqrt(R) if is_diagonal(R) else np.linalg.cholesky(R) # R が対角行列である場合 cholesky(R) は np.sqrt(R) と等価
_, w = linear_lasso(R_ch @ x_feat, R_ch @ y_target, lambda_=lambda_)
w_0 = y_target_mean - (x_feat_mean.T @ w)
return w_0, w
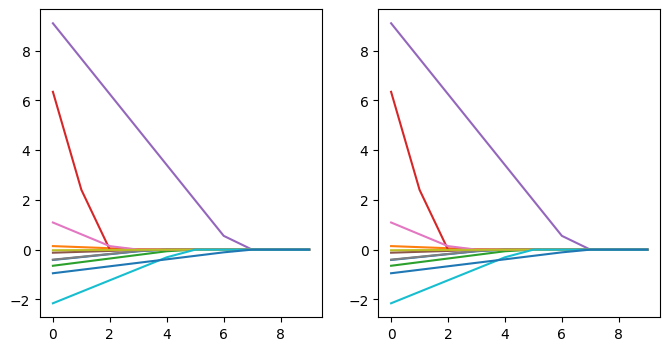
以下ではBOSTON Datasetによる住宅価格の予測問題を2つの実装で解いている。
# BOSTON Datasetをロード
data = pl.read_csv("boston.csv")
feat_name = ["crim", "zn", "indus", "chas", "rm", "age", "dis", "rad", "tax", "ptratio", "lstat"]
x_feat = data.select(feat_name).to_numpy()
y_target = data.select(["medv"]).to_numpy()
N, D = x_feat.shape
# λを変えながら回帰係数を計算
w_list_1 = []
w_list_2 = []
for l in range(10):
_, w = linear_lasso(x_feat, y_target, lambda_=l)
w_list_1.append(w)
_, w = general_linear_lasso(x_feat, y_target, lambda_=l)
w_list_2.append(w)
w_list_1 = np.concatenate(w_list_1)
w_list_2 = np.concatenate(w_list_2)
# グラフ描画
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
for f in range(len(feat_name)):
plt.plot(w_list_1[:, f])
plt.subplot(1, 2, 2)
for f in range(len(feat_name)):
plt.plot(w_list_2[:, f])
2. Lassoロジスティック回帰
ロジスティック回帰の導出
入力変数
展開で出てくる
クラス内分布
まず2クラスの場合、
ロジスティック回帰にシグモイドが現れることが示された。
ロジスティック回帰の最適化
パラメータ
シグモイドを含むBinaryCrossEntropyは
故に、IRLSの正規方程式は以下である。
以上により、
ここで求められる
ロジスティック回帰の実装
def vdiag(m: np.ndarray):
return np.diag(m.squeeze())
def logistic_regression(x_feat, y_target):
N, D = x_feat.shape
x_feat_mean = x_feat.mean(axis=0, keepdims=True)
x_feat_std = x_feat.std(axis=0, keepdims=True)
x_feat = (x_feat - x_feat_mean) / x_feat_std
w_old = np.zeros((D, 1))
w_new = np.ones((D, 1))
eps = 0.001
while np.linalg.norm(w_old - w_new) > eps:
w_old = w_new
xw = x_feat @ w_old
fy = 1 / (1 + np.exp(-xw)) - y_target
R = vdiag((1 / (1 + np.exp(-xw))) * (1 - (1 / (1 + np.exp(-xw)))) + eps**4)
z = xw - np.linalg.inv(R) @ fy
w_new = np.linalg.inv(x_feat.T @ R @ x_feat) @ x_feat.T @ R @ z
w = w_new
print(w)
pred = 1 / (1 + np.exp(-(x_feat @ w)))
return pred
data = pl.read_csv("iris.csv")
x_feat = data[:100].select(["length0" ,"width0", "length1", "width1"]).to_numpy()
y_target = data[:100].select("variety").to_numpy()
pred = logistic_regression(x_feat, y_target)
print(np.where(pred > 0.5, 1, 0).reshape(-1)) # 予測ラベル
print(y_target.reshape(-1)) # クラスの正解ラベル
この結果
重み
[[-0.77190021]
[-9.40190388]
[20.14680524]
[29.36256095]]
予測ラベル
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
正解ラベル
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Lassoロジスティック回帰の導出
ただし、
これは対数尤度(クロスエントロピー)
ここで、ロジスティック回帰の対数尤度を最小化する
この最小化はロジスティック回帰と同様に、
Lassoロジスティック回帰の実装
def lasso_logistic_regression(x_feat, y_target, lambda_=1.0):
N, D = x_feat.shape
x_feat_mean = x_feat.mean(axis=0, keepdims=True)
x_feat_std = x_feat.std(axis=0, keepdims=True)
x_feat = (x_feat - x_feat_mean) / x_feat_std
w_old = np.zeros((D, 1))
w_new = np.ones((D, 1))
eps = 0.001
while np.linalg.norm(w_old - w_new) > eps:
w_old = w_new
xw = x_feat @ w_old
fy = 1 / (1 + np.exp(-xw)) - y_target
R = vdiag((1 / (1 + np.exp(-xw))) * (1 - (1 / (1 + np.exp(-xw)))) + eps**4)
z = xw - np.linalg.inv(R) @ fy
_, w_new = general_linear_lasso(x_feat, z, R, lambda_=lambda_)
w_new = w_new.reshape((D, 1))
w = w_new
print(w)
pred = 1 / (1 + np.exp(-(x_feat @ w)))
return pred
pred = lasso_logistic_regression(x_feat, y_target, lambda_=0.7)
print(np.where(pred > 0.5, 1, 0).reshape(-1)) # 予測ラベル
print(y_target.reshape(-1)) # クラスの正解ラベル
この結果
重み
[[ 0. ]
[-0. ]
[ 0.81276811]
[ 0.79554075]]
予測ラベル
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
正解ラベル
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
以上のように、Lassoによる変数選択効果が働き、通常のロジスティック回帰の重み係数が小さい次元は無視され、重要な次元のみによる表現が行われる。
感想
この記事では以下2つの記事を俯瞰しながら、SEwPの行間をPRMLを読んで埋めてみた。
次は1章の残りのElasticNetによる回帰と、2章のポアソン回帰、生存時間解析などを書き下していきたい。
SEwPはトピックの提案が詳細で、1つのテーマから複数の話題を接種することができるのだが、数式の見通しの悪さが凶悪なため、他の書籍で理論を理解してから読まないとよくわからない感じになってしまう。PRMLの知識があれば第二章まではなんとかなりそうなのでもう少し読み進めてみるが、GroupLassoからはどうするか...
この記事ではPRMLにおいてデータを基底関数
カーネルSVMなどでガウス関数などを
Discussion