動的transfomerの実験
論文を読んで気になったのでAttention層の位置による影響を比較する簡単な実験をします。
その1はこっち
以下の論文では、学習済みLLama2をベースに、Attention+Dense層を1つの層とし、層をスキップする数を増減させ性能の違いを比較しています。結果は、少数のスキップであれば大きな性能低下は起きず、一方で多数をスキップした場合は大きな性能低下が見られたことが報告されています。さらに、層の順番を入れ替える実験も行っており、スキップした場合と同様に少数の入れ替えであれば大きな性能低下は起きないそうです。
層のスキップや順番もデータに応じて可変にすれば良いのでは????
データの種類によっては不要な層をスキップしたり、適切な順序を選択したりすることで、各層に知識が詰まった状態で学習されるのでは?と予想できます
構成
Phi3をベースに可変式のtransformerを作成/学習し、最終的なLossをベースモデルと提案モデルで比較します。いずれもlayerは4層で、学習データ(日本語wikipediaの一部)、ハイパーパラメタなどは同じものを利用します。
図のベースモデルのように4層のレイヤーを持つとします。レイヤーごとに4つのレイヤーのいずれかもしくはスキップを選択する判定を持ち、これを4回繰り返します。
例として以下のようなパターンが存在します。
- パターン1: 1, 4層目がスキップされるパターン
- パターン2: 1層目にlayer3が選ばれるパターン
- パターン3: layer2が繰り返されるパターン

5つのレイヤー(1つは何もしない)のうち1つを選択する、これを4回行う、というイメージのほうがわかりやすいかもしれません。
図にはないですが、レイヤーの選択を行うrouter layerを持ちます。router layerはdense+softmaxで実装されます。また、層はseqence毎に切り替わるとします。
すなわち、簡単なsequenceの場合1つのレイヤーのみで処理し、複雑なsequenceの場合は4つのレイヤーで処理のようなレイヤーの使い分けが想定されます。
結果
学習の設定は以下
1800step
learning-rateのwarmupは300step
モデルのパラメタ数はいずれのパターンも約12million
学習データは日本語wikipediaの一部
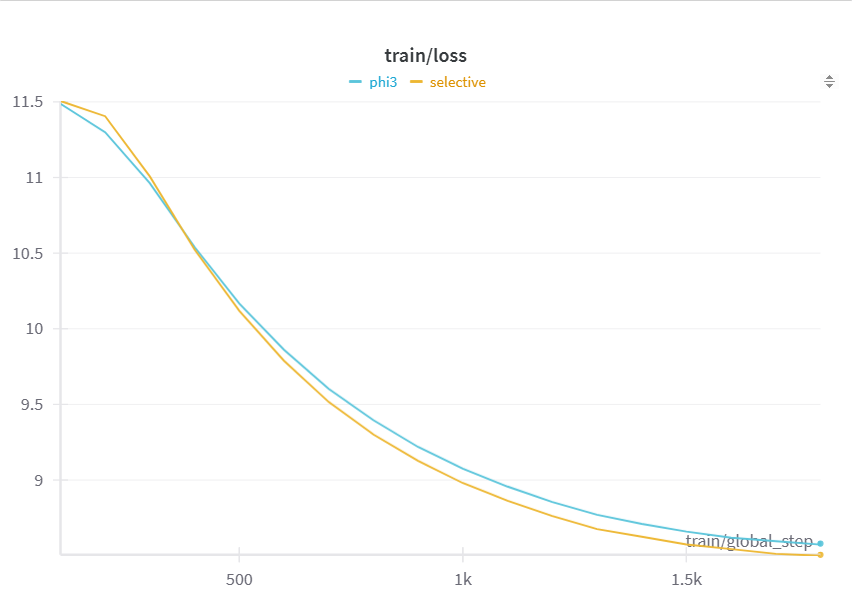
1800stepでのlossは以下のようになります。僅かですが提案モデルのlossが小さくなっています。
| パターン | Loss |
|---|---|
| 動的モデル | 8.5061 |
| phi3 | 8.5797 |
学習時間に関しては、ベースモデルであるphi3のほうが早くなっています。
おそらく、router layer分の時間がかかったものだと考えられます。
| パターン | train_runtime |
|---|---|
| 動的モデル | 799.3307 |
| phi3 | 670.4039 |
動的モデルではrouter layer分パラメタ数が多くなるので、fropで考えるとphi3側をもう少し学習step行うのがより同じ比較になるはずです。
layerの選択回数
提案モデルにwiki-newsを入力した場合の、レイヤーの選択回数は以下のようになりました。
選択回数はlayer1が一番多く選択され、layer3が少なくなっていますが、大幅に偏った選択はなくバランスよく選択されています。Moeのようにlossを追加したほうが良いかと予想していましたが、偏りは見えませんでした。ただし、学習させるデータセットの種類によっては偏りが出てくるかもしれません。
| レイヤーid | 選択回数 |
|---|---|
| Layer 0 | 7 |
| Layer 1 | 8 |
| Layer 2 | 6 |
| Layer 3 | 3 |
| Residual | 6 |
文章とlayerの順序
文章ごとに、layerの順序が変わることを確認します。
例1
カナダ・トロント市のジョン・トーリー氏が今年2月に市長を辞職したことを受け、今月26日に実施された選挙では、犬や高校生など102人が立候補する異例の選挙戦となった。
市選挙当局は、同月28日に開票結果を公表し、香港出身の女性政治家オリビア・チョウ氏の当選が確定した。次点は、前副市長のアナ・バイラオ氏、3位に元トロント警察署長のマーク・サンダース氏が続いた。なお、愛犬と二人三脚で挑んだトビー・ヒープス氏は593票、高校生のメイヤー・ストラウスは129票であった。
Residual -> layer2 -> layer2 -> layer3
例2
岩波書店は約10年ぶりの大改訂となる「広辞苑 第六版」を1月11日に発売した。
J-CASTによると広辞苑は1955年に発売された初版も含めると累計1100万部を誇り、ベストセラーとなっている辞典で、今回発売する第六版は1998年発売の第五版以来10年ぶりの改訂となる。この間には、インターネットで利用できる無料の「ネット辞書」が普及し、時事用語辞典は「紙」からの撤退を余儀なくされてきた。紙の辞書の売り上げは10年前の1,200万部から2006年には700万冊を下回るまで減少したと推測されており、一方で電子辞書が売り上げを伸ばした。そんな中でも、広辞苑はあくまで「紙」の辞典にこだわり、「紙で引く」ことの効用を説く。
スポーツ報知によると新たに約1万語の新語を掲載し、収録項目は全部で約24万になった。「癒やし系」「うざい」などのこの10年の間に一般に定着し広く使用されている用語を反映した内容になっているという。項目数が増えたためページも158ページ増加したが、厚さを第5版と同等の8センチ程度に抑えた。
また、シブヤ経済新聞によると2007年12月24日から翌1月6日まで東横線・渋谷駅のホームに広辞苑の広告が掲載され、話題を呼んだという。広辞苑 第5版に収録されている全23万語を言葉とその定義をすべて全面コピーした18枚のポスターが張り出された。
※スポーツ報知より
layer3 -> layer4 -> layer4 -> layer1
1つ目の例ではlayer3が最終層になっていましたが、2つ目の例ではlayer1が1層目となっています。layerが動的に選択されていることが確認できます。
まとめと所感
動的transfomerを作ってみました。動的にlayerが選択されることは確認できました。どのようなデータで層が選択されているかや層の特徴を更に調査してみると面白そうです。
今回はwikipediaをデータセットとして用いましたが、カリキュラム学習のように、簡単なデータからはじめ、wikipediaのような幅広い知識を持つデータセットで学習し、より専門的なデータの学習を行うなどの学習を行うと簡単な処理を行うlayerや幅広い知識を持つlayerなどが形成されると想像できます。
層の順番の選択も同時に学習していくので、学習後に層を追加したりなどの拡張が行いづらいのはデメリットのように思えます。
Discussion