LLMのattention層の位置による影響を比較する


論文を読んで気になったのでAttention層の位置による影響を比較する簡単な実験をします。
以下の論文では、学習済みLLama2をベースに、Attention+Dense層を1つの層とし、層をスキップする数を増減させ性能の違いを比較しています。結果は、少数のスキップであれば大きな性能低下は起きず、一方で多数をスキップした場合は大きな性能低下が見られたことが報告されています。
Attention層のみをスキップしDenseは残すようにすれば、性能も落とさず計算コストも下がって良いのでは????
構成
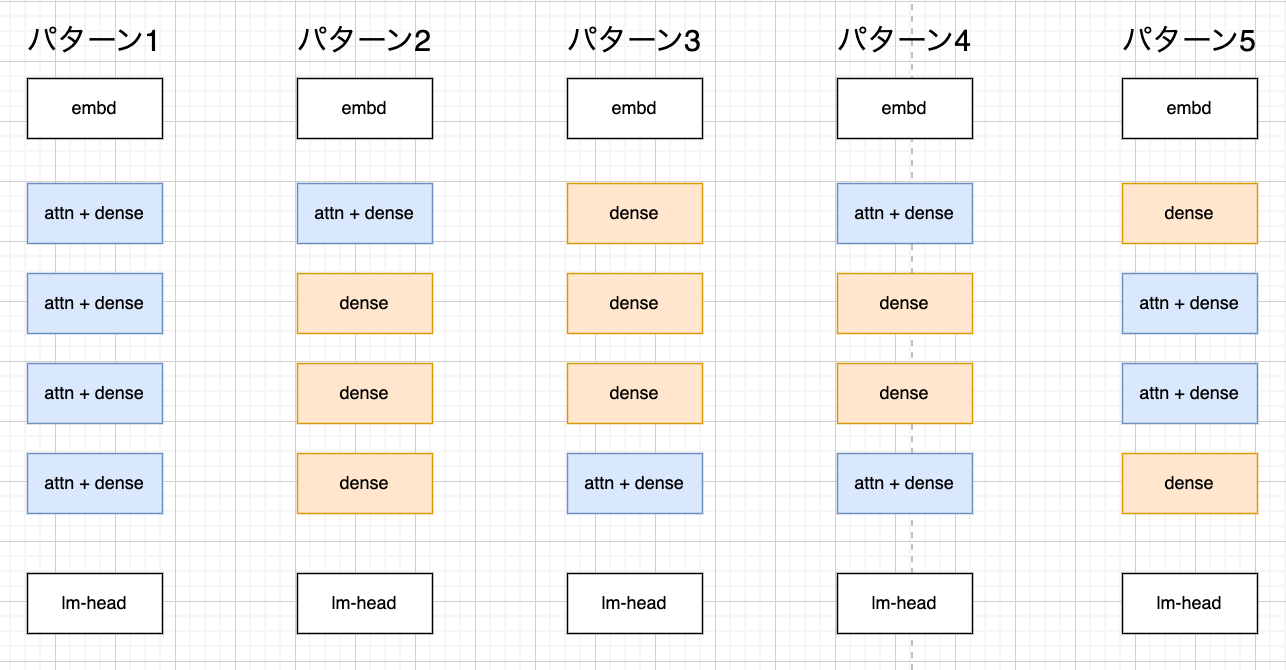
Phi3をベースにAttention層の配置を変更したいくつかのパターンを作成し学習させ、最終的なLossを比較していきます。いずれもlayerは4層で、学習データ(日本語wikipediaの一部)、ハイパーパラメタなどは同じものを利用します。
- パターン1: 比較のベースラインとなる通常のphi3
- パターン2: 1層目のみAttention+Dense
- パターン3: 4層目のみAttention+Dense
- パターン4: 1層目と4層目がAttention+Dense
- パターン5: 2層目と3層目がAttention+Dense
一応コードはここ(huggingface/transformersのphi3を継承してattentionをスキップしたもの)
結果
学習の設定は以下
- 1800step
- learning-rateのwarmupは300step
- モデルのパラメタ数はいずれのパターンも約12million
- 学習データは日本語wikipediaの一部
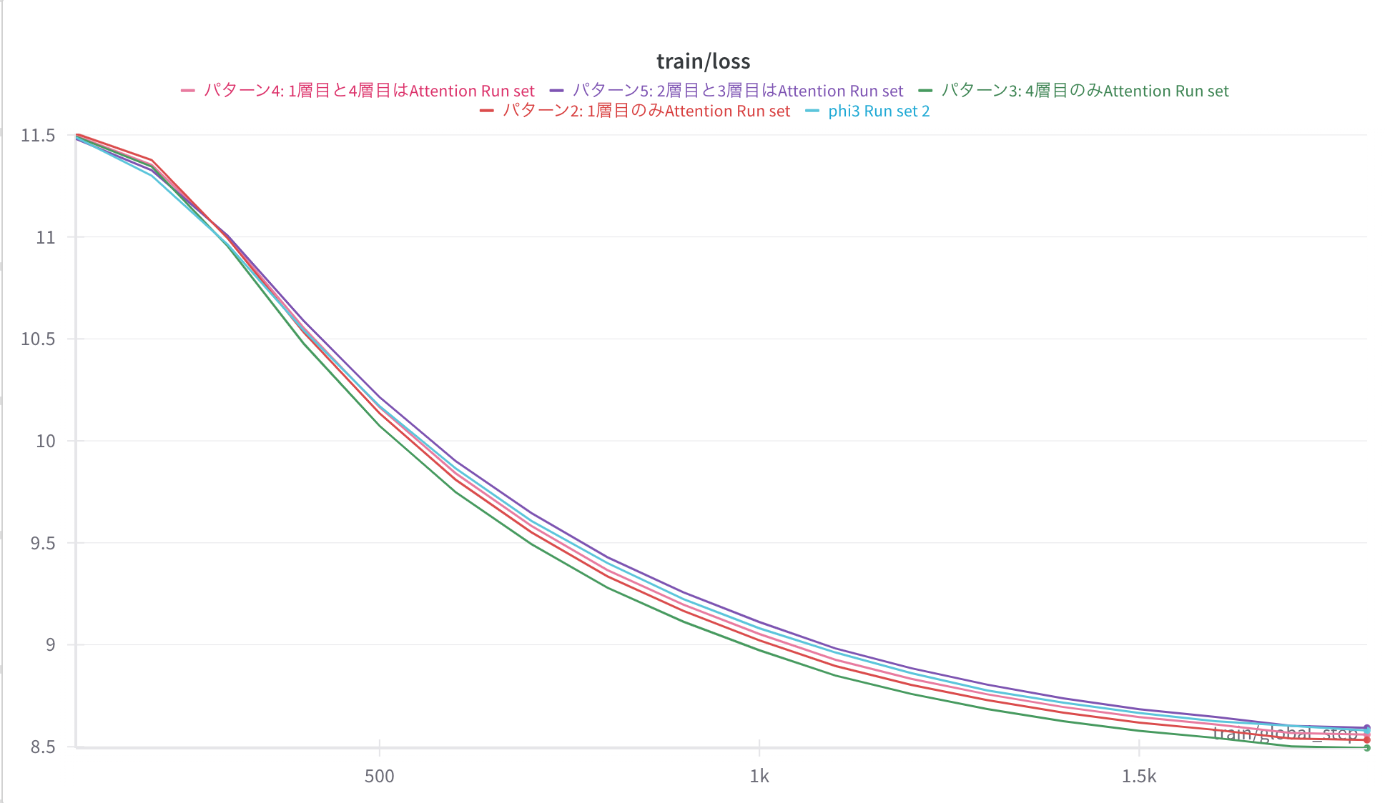
1800stepでのlossを並び替えると以下のようになります。
| パターン | Loss |
|---|---|
| パターン3: 4層目のみAtt | 8.4939 |
| パターン2: 1層目のみAtt | 8.5334 |
| パターン4: 1層目と4層目がAtt | 8.5594 |
| パターン1: phi3 | 8.5797 |
| パターン5: 2層目と3層目がAtt | 8.5926 |
4層目のみをAttentionとしたモデル(パターン3)のlossが最も低く、ついで1層目のみ(パターン2)となった。2層目と3層目にAttentionを用いたモデル(パターン5)のlossが最も高く、ついでベースのphi3(パターン1)となった。
モデルの最初と最後のAttentionの処理が重要で、中央のAttentionは冗長??
200stepでのlossを見てみると、phi3や2層目と3層目にAttentionを用いたモデルが低いlossとなり、1800stepでの結果とは逆になっている。今回のlearning rateのwarmupは300stepとしたので、200stepはwarmupの途中ということになる。
| パターン | Loss |
|---|---|
| パターン1: phi3 | 11.3002 |
| パターン5: 2層目と3層目がAtt | 11.3269 |
| パターン3: 4層目のみAtt | 11.3449 |
| パターン4: 1層目と4層目がAtt | 11.353 |
| パターン2: 1層目のみAtt | 11.3768 |
モデル中央のAttentionは学習初期の情報の流れを制御するのに役立っている??
所感
モデル前半と後半のAttention層が割と重要そうとなる結果でした。言語が喋れる程度のサイズのモデルで学習を行い、タスクによる違いも調べてみると面白そうです。
こういうの調べた論文ありそうだけど見つからなかったので、知っている方がいれば教えてください。
Discussion