【Cloud Data Fusion】性能チューニングについて
はじめに
この記事は、Google Cloud Platform Advent Calendar 2021の22日目の記事になります。
Cloud Data Fusion (以降、CDF)[1] を本格的に利用し始めて8ヶ月が経ちました。
今回は過去の障害対応で調査した性能に関する内容をお伝えできればと思います。
今回のテーマ
CDFの性能について、以下の観点でまとめてみました。
- アーキテクチャ
- チューニングポイント
【参考】
・ Cloud Data Fusion公式ドキュメント (パイプラインパフォーマンス)
・ CDAP公式ドキュメント (Data Pipeline Performance Tuning Guide)
利用環境
| Product | version |
|---|---|
| CDAP | 6.4.1 (Basic) |
| Region | asia-northeast1 |
1. アーキテクチャ
CDFはオープンソースのCDAPのマネージドサービスになります。
CDAPで設定したパイプラインをHadoopクラスタ上のSparkが処理します。

CDAP公式サイト
1-1. エディションによる違い
2019年にGoogle Cloudに買収され、CDFには現在3つのエディションがあります。
現時点ではエディションによる機能面の違いはなく、以下のような違いがあります。
【エディションによる違い】
| 機能 | Developer | Basic | Enterprise |
|---|---|---|---|
| ユーザー数 | 2 (推奨) | 無制限 | 無制限 |
| 高可用性 | 1つのゾーンのみ | マルチゾーン (リージョン) | マルチゾーン (リージョン) |
| ランタイム | Dataproc (エフェメラル) | Dataproc (エフェメラル) | Dataproc、Hadoop、EMR (エフェメラルor専用) |
私は検証フェーズではDeveloperを利用していました。
本番運用フェーズでは約60本のパイプラインを実行していますが、Basicを利用しています。
【参考】
・ エディションの比較
1-2. システム構成
Dataprocにはクラスタ管理するMasterノードとETL処理を担うWorkerノードが存在します。
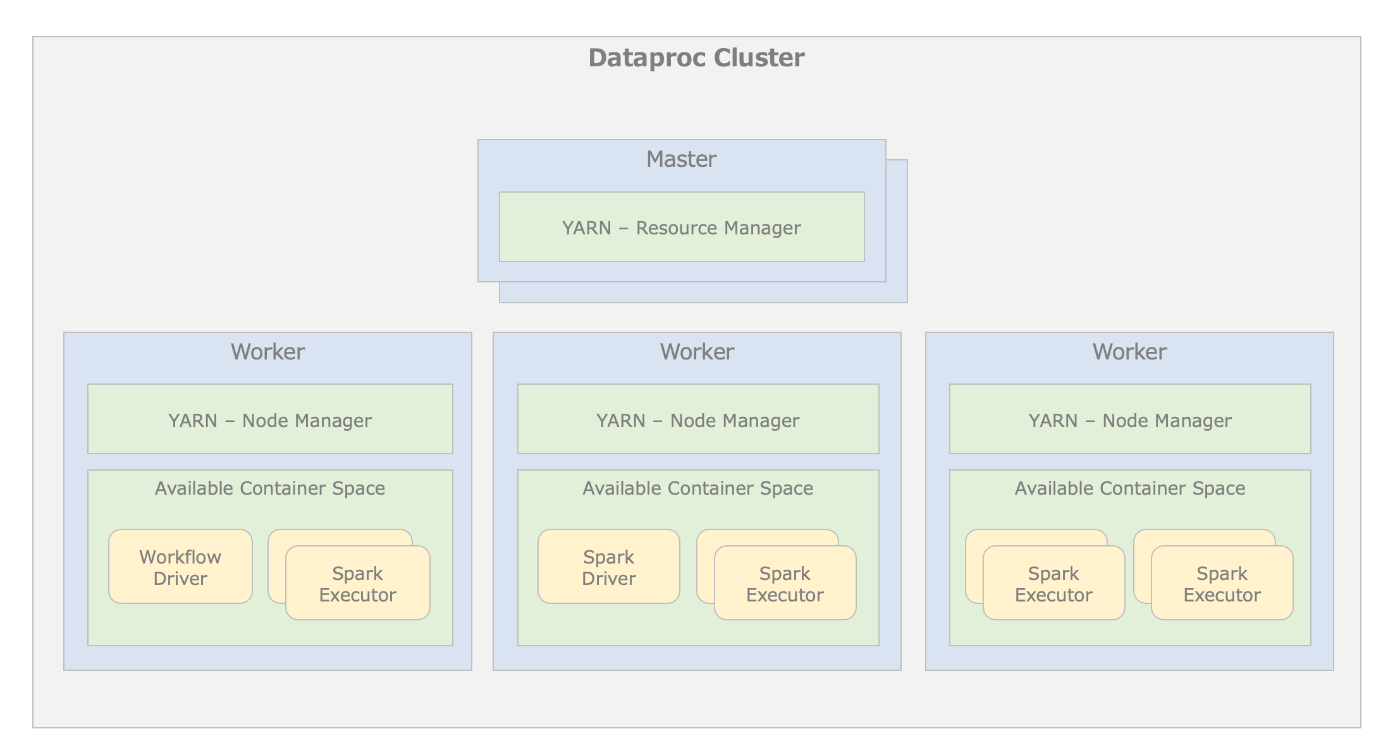
クラスタ構成図
上記図における主要なコンポーネントの役割は以下の表の通りとなります。
【主要なコンポーネント】
| コンポーネント名 | 説明 |
|---|---|
| Resource Manager | クラスター上のWorkerでコンテナを作成および実行場所を決める役割 |
| Node Manager | コンテナを実行するために使用可能なリソースを予約する役割 |
| Workflow Driver | パイプラインを構成する1つ以上のSparkプログラムを起動する役割 |
| Spark Driver | Spark Executor間でETLタスクを調整する役割 |
| Spark Executor | 実際のETLタスクにおいてデータを処理する役割 |
性能チューニングにおいて、Spark Executorは重要なコンポーネントになります。
Workerノードの持つCPUとメモリをSpark Executorに振り分けてETL処理を行います。
他のコンポーネントはなんとなく何をしているものなのか理解しておけば良いと思います。
2. チューニングポイント
主なチューニングポイントは以下の通りとなります。
- Number of Primary Worker
- Worker Cores
- Worker Memory
- Spark Executor CPU
- Spark Executor Memory
Workerノードの台数とCPUやメモリ、Spark ExecutorのCPUとメモリのチューニングになります。
2-1. Masterノード
Masterで設定できるパラメータは以下の通りになります。
【Masterのパラメータ】
| パラメータ | デフォルト値 | 選択肢 | 説明 |
|---|---|---|---|
| Number of masters | 1 | 1 or 3 | Masterノードの数 |
| Master Machine Type | - | n1, n2, n2d, e2 | MasterのVMマシンタイプ |
| Master Cores | 4 | 1, 2, 4, 6, 8, 16, 32, 64, 96 | MasterノードのvCPU数 |
| Master Memory (GB) | 16 | (自由入力) | Masterノードのメモリサイズ |
| Master Disk Size (GB) | 1000 | (自由入力) | Masterノードのディスクサイズ |
| Master Disk Type | - | Standard Persistent Disk, SSD Persistent Disk | Masterノードのディスクタイプ |
Masterはシングル構成またはクォーラムを維持する3ノード構成(冗長)が選べます。
エフェメラルの場合、MasterノードはCPU2個、メモリ8GB程度で良いとされています。
If you are running pipelines on ephemeral clusters, we suggest using 2 CPU and 8gb memory for the master nodes.
2-2. Workerノード
Workerで設定できるパラメータは以下の通りになります。
【Workerのパラメータ】
| パラメータ | デフォルト値 | 選択肢 | 説明 |
|---|---|---|---|
| Number of Primary Workers | 0 | (自由入力) | プライマリWorkerノードの数 |
| Number of Secondary Workers | - | (自由入力) | セカンダリWorkerノードの数 |
| Worker Machine Type | - | n1, n2, n2d, e2 | WorkerのVMマシンタイプ |
| Worker Cores | 2 | 1, 2, 4, 6, 8, 16, 32, 64, 96 | WorkerノードのvCPU数 |
| Worker Memory (GB) | 8 | (自由入力) | Workerノードのメモリサイズ |
| Worker Disk Size (GB) | 1000 | (自由入力) | Workerノードのディスクサイズ |
| Worker Disk Type | - | Standard Persistent Disk, SSD Persistent Disk | Masterノードのディスクタイプ |
Workerノードにはプライマリとセカンダリがあります。
Dataprocでは殆ど違いがないため、基本的にはプライマリのみ利用します。
2-3. Spark DriverとExecutor
Spark DriverとExecutorで設定できるパラメータは以下の通りになります。
【Spark DriverとExecutorのパラメータ】
| パラメータ | デフォルト値 | 選択肢 | 説明 |
|---|---|---|---|
| Driver CPU | 1 | 1〜20 | Spark DriverのvCPU数 |
| Driver Memory | 2048 | (自由入力) | Spark Driverのメモリサイズ |
| Executor CPU | 1 | 1〜20 | Spark ExecutorのvCPU数 |
| Executor Memory | 2048 | (自由入力) | Spark Executorのメモリサイズ |
DriverのCPUとメモリの設定を変えることは殆どありません。
WorkerのCPUとメモリに応じて、Spark Executorをチューニングします。
2-4. チューニングの考え方
繰り返しになりますが、性能を出すにはWorkerとSpark Executorのバランスを考えます。
以下の構成図を例に説明します。

チューニングの考え方
WorkerのCPU数に対して、Spark ExecutorのCPU数で割った数のSpark Executorが稼働します。
上記例では、WorkerのCPU数が8に対して、Spark Executorが2個なので、4台稼働します。
次にメモリですが、YARNコンテナではノードの75%のメモリしか使用できません。
Workerにメモリが32GBあってもYARNでは24GBしか使用できないことになります。
そしてSpark Executorのメモリは10%のオーバーヘッドがかかります。
よって、5GBのメモリを割り当てても512MBのオーバーヘッドが上乗せされます。
あとは、Workerの台数を増やすと上記のセットが指定した台数分、並列稼働します。
CPUあたりのメモリサイズが決まっていることも忘れないようにしましょう!
【補足】
リソース割り当てのバランスを間違えて、Spark Executorにメモリを割り当てすぎると
以下のようなエラーが出力され、パイプラインは失敗します。
2-5. 設定方法
GCP管理コンソールからData Fusionインスタンスを開きます。
Deploy済みのパイプラインを開きます。
[Pipeline Studio]から❶[Configure] > ❷[Compute config]で❸[Customize]をクリックします。

Masterノードの設定を変更する場合は、❹の[Master Nodes]を開きます。

Workerノードの設定を変更する場合は、❺の[Worker Nodes]を開きます。

MasterまたはWorkerの設定変更後は❻[Done]を押します。

Spark Executorの設定変更する場合は❼[Resources]で❽[Executor]の設定を変更します。

全ての設定を保存する場合は❾[Save]ボタンを押します。
【補足】
・ Spark DriverとExecutorはDeploy前に設定可能でコンフィグに保存されます。
・ MasterとWorkerの設定はDeploy後に指定します。(コンフィグに保存されません)
2-6. モニタリング
チューニングした結果、処理性能が発揮出来ているかチェックするには
[Dataproc] > [クラスタ]から稼働しているクラスタを開いてモニタリングを確認します。
特にYARNメモリ、YARN保留中メモリ、CPU使用率に注目してみてください。
YARN保留中メモリが高止まりしている場合はWorker台数を増やすなどの対応が必要になります。
まとめ
さて、いかがでしたでしょうか?
パイプライン実行において、バッチウィンドウ内で処理が終わらないと困ってしまいます。
時間内に終わらせるためにSpark Executorに多くの仕事させる必要があります。
CPUとメモリを増やすためにはWorkerのCPUとメモリを増やす必要があります。
それでも足りない場合は、Workerの数を増やすことでさらに処理性能を上げましょう。
最後はコストとの兼ね合いになりますが...
Discussion