1. はじめに
株式会社 Hogetic Labの古畑です。
2022年の年末にChatGPTが公開されてから、空前のLLM(大規模言語モデル)ブームは収まるどころかますます拍車がかかっており、今後もLLMと共生し続ける必要性を感じています。
そんな状況の中、とうとう2024年5月に「LLMで時系列分析ができる」という、データアナリストとしては見逃せないニュースが飛び込んできました。
本記事では馴染みのない方に向け簡単にLLMと時系列分析の解説を行った上で、このニュースの元となった論文を読み解き、内容について解説したいと思います。
筆者経歴
- 経済学部卒、大学では統計学と計量経済学を専攻
- 在学中に暗号資産の時系列分析に関する単著論文を執筆
- みずほ学術振興財団懸賞論文2等・経営管理黒澤賞などを受賞
- 現在はデータアナリスト・データサイエンティストとして勤務
- 時系列データを用いた分析やアルゴリズム開発に従事
想定読者
この記事は、以下のような方を想定して書いています。
- 時系列データの分析に携わっている方
- 今後LLMをさらに活用していきたい方
- 統計学・計量経済学を学んだことがある方
書かないこと
以下のような内容は割愛しています。
- 理論を導出するための数式
- LLMで時系列分析を取り扱う実際のプロンプト
2. LLM(大規模言語モデル)/時系列分析の概略
LLM(大規模言語モデル)
LLM(大規模言語モデル)は、膨大なテキストデータと高度なディープラーニング技術を用いて構築された、NLP(自然言語処理)と呼ばれる分野における革新的な技術です。
一般に機械学習モデルはパラメータ数を増やし続けると、学習データに対する過学習(過剰適合)という現象を起こしてしまい、未知データに対する予測性能がかえって悪化してしまいます。
ところが、LLMでは「計算量」「データ量」「パラメータ数」を大幅に強化することで、あるところから逆に非常に高い未知データに対する汎化性能を示すようになりました。

この現象をGrokkingと呼び、驚異的な自然言語処理性能を発揮する理由の一つとされています。
LLMに対し任意のテキストを入力できるようにインターフェースを整えたものが、昨今話題のChatGPTやGeminiに代表されるLLMチャットボットになります。
時系列分析
時系列分析は、時系列データの分類や将来予測、クラスタリング、異常検知、欠損値の補完などのタスクを解くことを目的とする分析です。
時系列データとは、時間の推移とともに観測されるデータを指しています。
具体的には株価・為替などの金融データや、気温・雨量などの気象データ、脳波・心電図などの医療データなど、様々な実世界の分野で広く利用されています。
時系列分析は、「時間的に連続する」という特性を活かし、将来の値を予測する必要がある分野において幅広く活用されています。
- 商品の需要予測、生産計画
- ビジネスにおける戦略策定や意思決定、業務効率化
- 異常の発見(設備機器の異常検知、システム障害、不正取引の検出など)
時系列分析の歴史を紐解くと、主に以下の4つのフェーズに分かれています。

引用元:Position: What Can Large Language Models Tell Us about Time Series Analysis/ Figure 3
-
Statistical TS Models
- 主に2000年以前
- 統計モデル(ARモデル・MAモデルなど)をタスクごとに設計
- 特徴量の設計は、分析者のドメイン知識・専門知識に強く依存
-
Neural TS Models
- 主に2010年代
- ニューラルネットワークを時系列分析に適用
- 精度は向上したが、モデルの構築難易度やデータの前処理工数が大幅に増加
-
Pre-trained TS Models
- 2020年代前半
- Transformerベースの事前学習モデルを時系列分析に適用
- データ収集やアノテーションの時間とコストを大幅に削減
-
LLM-Centric TS Models
- 最新(当該論文)
- LLMを用いた時系列分析
これ以降は、論文を元に「LLMを用いた時系列分析」について深掘りしていこうと思います。
3. 「LLM × 時系列分析」に言及した論文
当該論文
内容
本論文で、筆者は「SIGLLM」と呼ばれるアプローチを提案しています。
SIGLLMは、以下のようなフレームワークを指します。
- 時系列データをテキスト表現に変換するモジュールを導入
- スケーリング、量子化、ローリングウィンドウ処理、トークン化など
- テキスト表現に変換し、LLMで時系列データを処理できるようにする
- 「PROMPTER」を導入
- LLMに直接異常を検出するようにプロンプトを与える
- 時系列データを入力し、どの部分が異常かを直接的に出力
- 「DETECTOR」を導入
- LLMの時系列予測能力を利用して異常を検出するようにプロンプトを与える
- 時系列データを入力し、未来の値を予測させ、予測値と実際の値の差分から異常を検出
著者はこれらのアプローチを11のデータセットで評価しました。
SIGLLMと他の異常検知モデルのF1スコア性能を比較したものが以下の図です。
この図より、LLMはベースラインとなるMAモデルよりも優れた性能を発揮していると言えます。
一方で、最先端の深層学習(DL)モデルやクラシックなモデルには及ばないこともわかります。
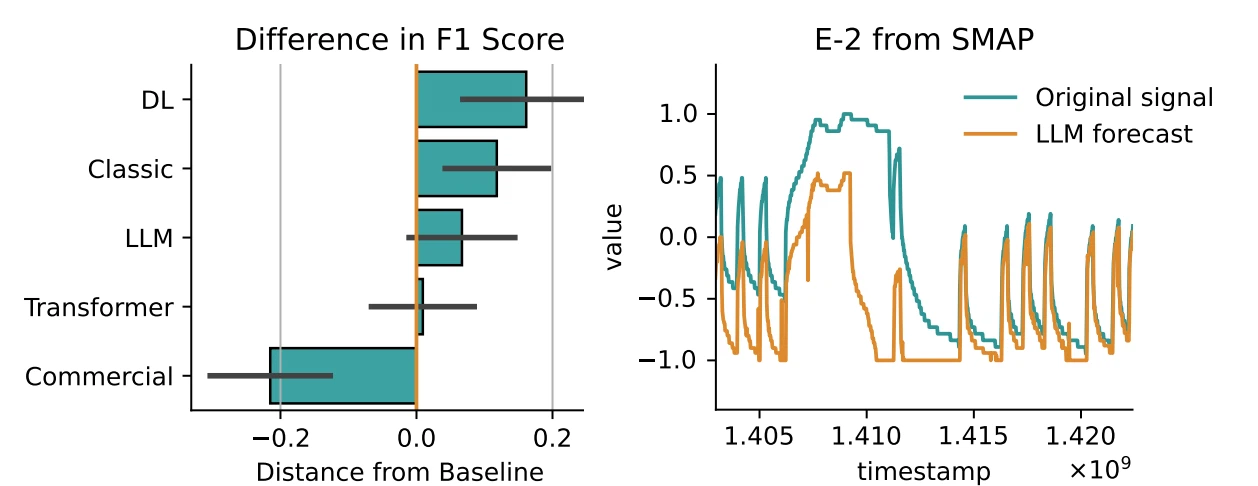
引用元:Large language models can be zero-shot anomaly detectors for time series?
以下の図は、SIGLLMを構成する「PROMPTER」アプローチと「DETECTOR」アプローチのPrecision、Recall、F1スコアを比較したものです。
概してDETECTORアプローチが優れた性能を示していることがわかります。

引用元:Large language models can be zero-shot anomaly detectors for time series?
4. LLMの限界と時系列分析の特殊性
本論文では、LLMを用いた時系列分析の性能は深層学習モデルに及ばないことが示されました。
この差分は、入力の長さ制限やGPUメモリの制約に加え、時系列データが持つある種の特殊性に起因するものと思われます。
その特殊性とは、時系列データには「非定常過程」と呼ばれる概念が存在することです。
一般的な時系列分析は、「非定常過程」との戦いであるといっても過言ではありません。
「非定常過程」とは、時系列分析において重要な前提条件となる「定常性(Stationarity)」を満たさない過程のことです。
定常性には、具体的に以下のような特性があります。
-
平均が時間によらず一定
- ある時点での平均値が別の時点での平均値と同じ
-
分散が時間によらず一定
- ある時点での分散が別の時点での分散と同じ
-
自己共分散(または自己相関)が時間によらず一定
- 2つの時点間の関連性がラグにのみ依存し、時間には依存しない
また、定常過程を前提として定常性の前提を満たさない非定常過程のデータを直接分析すると、様々な不都合が生じてしまうことが知られています。
その中で有名なものは、2つの無関係な時系列データに関して回帰分析を行うと有意な相関が表れてしまう「見せかけの回帰」です。
# ランダムなデータを生成
sigma_x, sigma_y = 1, 2
T = 10000
xt = np.cumsum(np.random.randn(T) * sigma_x).reshape(-1, 1)
yt = np.cumsum(np.random.randn(T) * sigma_y).reshape(-1, 1)
# 両者の間の相関係数を算出(理論上はゼロになるはずが…)
from sklearn.linear_model import LinearRegression
reg = LinearRegression().fit(xt,yt)
print('R-squared : ',reg.score(xt,yt))
print('coef : ',reg.coef_, 'intercept', reg.intercept_)
R-squared : 0.5871289027113126
coef : [[2.08553693]] intercept [-54.04780299]
本論文の手法は、基本的に定常過程を前提としています。
非定常過程をはじめ、様々な特殊性を持つ時系列データにLLMをどのように特化させていくかが、精度を向上させる上で今後の課題になると思われます。
5. まとめ
今回はLLM・時系列分析の基本的な概要・特徴に触れた上で、「LLMを用いた時系列分析」の最新論文とその限界について解説しました。
LLMの適用範囲を時系列データにまで拡張するという取り組みはとても挑戦的で、LLMの可能性を大きく広げるものとだと思います。
一方で、時系列データの特殊性を克服するためには、さらなる研究が必要だと思います。
また、この論文では異常検知タスクに焦点が当てられていましたが、LLMの時系列データへの適用可能性は、将来予測や分類など他のタスクにも及びます。
これらのタスクへLLMを適用する研究も、今後の重要な研究課題の1つになると思われます。
今後の「LLM × 時系列分析」の発展に期待しつつ、状況を注視していきたいと思います。
最後に宣伝ですが、弊社はGoogleの生成AIパートナーとして、Google Cloudの活用およびデータ分析の民主化に取り組んでいます。
データアナリスト・データエンジニアをはじめ各ポジションでの採用も行っておりますので、ご興味がある方はチェックしてみてください。

Discussion