Closed31
読書メモ: Database Design and Implementation
書籍
配布ソース
取り組み方
- 章ごとの要点をまとめる
- インターフェースとテストコードから実装をイメージする
- 実装を読み解いてコメントを書きながら写経する
-
Suggested Readingは気になる資料のリストアップまで
Exercises はどこまでやるか悩ましい。
割とボリューミーなので、1周目は読むだけに留めて、2周目で取り組むくらいの気持ちで。
全体に対するメモ
- 実装パートは事前に解説した内容まで踏み込まない
- Exerciseパートで、追加で取り組む課題として設定されてたりする
- 扱える値
- string, integer
- buffer replacement
- clock まで解説 & 実装はナイーブなもの
- recovery
- 記録する log の種類は、ファイル末尾への block の追加まで解説 & 実装するのは以下
- CHECKPOINT
- (transactionの) START, COMMIT, ROLLBACK
- SETINT, SETSTRING
- undo-redo まで解説 & 実装は undo-only
- nonquiescent chckpointing まで解説 & 実装は quiescent
- 記録する log の種類は、ファイル末尾への block の追加まで解説 & 実装するのは以下
- transaction
- 4 つの分離レベルやレベルごとの slock の利用方法について解説 & 実装は serializable
- deadlock 検出は解説のみ
- multiversion lock は解説のみ
- lock の粒度の解説 & 実装は block 単位のみ
- record 表現
- spanned/unspanned record を解説 & 実装は unspanned
- homogeneous/nonhomogeneous file を解説 & 実装は homogeneous
- fixed-length/variable-length field を解説 & 実装は fixed-length
- metadata
- 4種類の metadata を解説 & 実装
- table metadata
- view metadata
- index metadata
- statistical metadata
- query processing
- 関係代数はかなりライトに解説
- 演算子は select, project, product のみ
- 実装するのも上記の演算子のみ
- select のための predicate も実装
- 構造
- predicate
- terms
- expression
- constant
- フィールド、定数の等価比較まで
- 構造
- 関係代数はかなりライトに解説
- planning
- 基本的な計画作成プロセスのみ(最適な計画作成は最終章でカバー)
- 単純な SQL のサブセットをサポートするだけなので select, project, product のみを使用したクエリツリーで実装
- 計算、ソート、グループ化、入れ子、名前の変更は含まず
- indexing
- static hashing, extendable hashing, B-trees を解説
- static hashing, B-trees を実装
- B-trees の実装は簡易的なもの
- merge は実装しない
- latch, lock は実装しない
- 実装済の block 単位の lock にて一貫性を担保?
- materialization & sorting
- 一時テーブルを利用して sort, groupby, mergejoin を実装
- 一時テーブルの破棄タイミングは DB 起動時のみ
- sort は素朴な mergesort + α
- 解説では一度に merge する run の数を増やしたり、初期の run の数を減らすような改善を紹介しているが、実装はしない
- groupby の集計式は count, max のみ実装
- mergejoin は sort を利用して効率化 & 駆動表に join 値が重複する際の内部表の読み直しも想定
- 効果的なバッファ使用手法
- 関係演算子によって使用可能なバッファの割り当て方法を変えると、効率化できることを解説
- 例: merge sort は一度に複数の run を merge 出来ると良い(multibuffer sorting)
- SimpleDB では Multibuffer Product のみを実装
- バッファ数の割り当て方法としては、ルート計算、因子計算を実装
- multibuffer sort ではルートを利用(解説のみ)
- multibuffer product では因子を利用(実装まで)
- join アルゴリズムの比較が面白かった
- mergejoin, hashjoin, indexjoin がユースケースによって、効率が変わることが説明されていた
- 関係演算子によって使用可能なバッファの割り当て方法を変えると、効率化できることを解説
- クエリ最適化
- 最適化のための個々の操作を解説
- products の並び替え
- select の分割
- select の移動
- select-product の join への変換
- projection の追加
- クエリ最適化のステップをヒューリスティクなものを中心に解説
- そのうち一部を使ったものを実装
- 最適化のための個々の操作を解説
Chapter 1: Database Systems
Database Systems の概要説明の章。
- Database に求められるもの
- Record Storage
- update / read を効率良くおこなえるような構造で記録
- Multi-user Access
- 複数ユーザーが同時に操作でき、かつ不整合な状態にならないようにする
- Dealing with Catastrophe
- クラッシュからリカバリー可能にする
- Memory Management
- disk/flash の操作は遅いのでメモリーへのキャッシュする
- Usability
- query language をサポートすることで usability を提供
- Record Storage
- Java-based な database system として Derby が参考になる
- 洗練されている代わりに複雑
- この本では Java でシンプルな実装の database system を実装していく
- ソースはここからダウンロード可能
- embedded, server-based のどちらもサポート
- query はかなり制限
- select: フィールド名称のリストのみ
- from: テーブル名称のリストのみ
- where: boolean オペレータと and のみ
- その他には、
*なし、null なし、join なし、union なし、insert は明示的な値のみ、update での set 対象は 1 つのみ
Chapter 2: JDBC
JDBC の説明が主なので省略。
Chapter 3: Disk and File Management - 要点
- Disk ドライブの説明
- 物理的な構造: Platters, Tracks, Spindle, Actuator などなど
- 回転スピード: 5,400 rpm - 15,000 rpm
- 転送速度: 100MB/s など(回転スピードと Track あたりのバイト数による)
- seek time: Actuator が Disk ヘッド を動かす時間(平均 5ms ほど)
- RAID の話
- Flash ドライブの説明
- Disk のブロックレベルのインターフェース
- 割り当て可能なブロックの記録方法のベーシックなストラテジー
- disk map
- ブロックに対応する bit の値で free/allocated を管理
- free list
- チャンクのチェーンの方式で管理
- チャンク: 連続した未割り当てのブロックかたまり
- チャンクの先頭ブロックに自身のチャンクの長さと、次のチャンクの位置が記録
- チャンクのチェーンの方式で管理
- disk map
- Disk のファイルレベルのインターフェース
- OS はファイルシステムと呼ばれる Disk への高レベルなインターフェースも提供
- Database エンジンを実装する際に上記のどちらを選ぶべきか?
- ブロックレベルを使うと
- Disk ブロックを完全にコントロールできる
- 例えば、よく使うブロックをシーク時間が短い位置に配置するなど
- OS の制限を超えるサイズや複数ディスクドライブにまたがるデータをサポートできる
- disadvantage もある
- 実装が複雑になる
- database 管理者もブロックアクセスパターンについての幅広い知識が要求される
- Disk ブロックを完全にコントロールできる
- ファイルシステムをフルに利用すると
- 実装が簡単だが、2 つの理由から受け入れがたい
- database システムはブロックの境界を把握できないとデータを効率良く扱えない
- OS の I/O バッファの管理方法はデータベースクエリに適してない
- 実装が簡単だが、2 つの理由から受け入れがたい
- 妥協案: データを OS ファイルに格納し、そのファイルを raw disk と同じように扱う
- 多くの database システムで採用されている
- Microsoft Access, Oracle, Derby, SimpleDB
- 多くの database システムで採用されている
- ブロックレベルを使うと
- 割り当て可能なブロックの記録方法のベーシックなストラテジー
Chapter 3: Disk and File Management - 実装
実装対象: BlockId, Page, FileMgr
BlockId
- ファイル名と論理的なブロックナンバーから特定のブロックを識別
BlockId blk = new BlockId("student.tbl", 23)
Page
- Disk ブロックの内容を保持
- Buffer Manager, Log Manager から使われるコンストラクタをそれぞれ用意
- ページ内の特定の位置に値を格納したりアクセスするための get/set メソッドを実装
- 例
getString,setString
- 例
- 3 つの値のタイプを保持可能とする
- int, string, blob
- クライアントは任意の場所に値を格納できるが、どこに何の値を格納したか把握しておく必要がある
-
setStringした場所に対してはgetStringで値を取得する必要あり
-
-
setString,getStringはそれぞれ内部でsetBytes,getBytesを呼び出し - setBytes は先頭にバイト配列の長さをセットしつつ、バイト配列自体もセット
private ByteBuffer bb; // Page のコンストラクタで生成
public void setBytes(int offset, byte[] b) {
bb.position(offset);
bb.putInt(b.length);
bb.put(b);
}
FileMgr
- OS ファイルシステムとのインタラクションをハンドリング
- database システムが扱うファイルを格納するディレクトリ名と、ブロックのサイズを保持
- database システム起動時に 1 つの FileMgr オブジェクトを生成して保持
- read, write は synchronized 指定
public synchronized void read(BlockId blk, Page p) {
try {
RandomAccessFile f = getFile(blk.fileName()); // ここで Map<String,RandomAccessFile> openFiles から該当の File を取得
f.seek(blk.number() * blocksize);
f.getChannel().read(p.contents());
} catch (IOException e) {
throw new RuntimeException("cannot read block " + blk); // e を握りつぶしている感
}
}
- synchronized 指定は内部的にオープン済の RandomAccessFile オブジェクトを Map にキャッシュしているため?
Chapter 4: Memory Management
- Two Principles of Database Memory Management
- Principle 1: Minimize Disk Accesses
- RAM は速い
- flash に比べて 1000 倍
- disk に比べて 100,000 倍
- Principle 2: Dont't Rely on Virtual Memory
- OS に Memory Management を委ねると 2 つの問題が発生する
- database engine のクラッシュリカバリー能力が損なわれる(可能性がある)
- ページ更新前にログレコードに書き込むべきだが、その前にページが swap out される可能性がある
- OS が間違った推測をして不必要なディスクアクセスが発生する可能性がある
- database engine がどのページを使っていて、どのページは気にしていないかを知るすべがないため
- database engine のクラッシュリカバリー能力が損なわれる(可能性がある)
- OS に Memory Management を委ねると 2 つの問題が発生する
- Principle 1: Minimize Disk Accesses
Managing Log Information
- database を変更するたびに、その変更を取り消す必要がある場合に備えてログレコードを記録
- Log Manager はログの中身は把握せず、ただログをファイルに書き出す役割
- 素朴に実装するとログを追加するたびに disk read/write が発生して非効率
- disk read は単に current のログのページを保持しておくだけで減らせる
- disk write は、ログのページがいっぱいになるまで遅延させることで減らせる
- が、それでは問題がある
- ログが書き込まれないと、database への変更も disk に書き込むことができないため、「ログのページがいっぱいになるまで」待つ必要があるのは問題
- ログに適したバッファ管理はもうひと工夫必要
- Chap.5 でも取り上げる話
- ログが書き込まれないと、database への変更も disk に書き込むことができないため、「ログのページがいっぱいになるまで」待つ必要があるのは問題
- が、それでは問題がある
Managing User Data
- ログレコードの使われ方は
well-understoodなので、Log Manager は細かくチューニングできる - 一方 JDBC アプリケーションからのアクセスは完全には予期できない
- The Buffer Manager
- バッファープールと呼ばれる固定的なページを保持
- バッファプールはコンピューターの物理メモリーに収める必要あり
- バッファープール内のページは
pinned、もしくはunpinned状態となる- pinned 状態である限りバッファプール内に保持
- クライアントがあるブロックに対応するページに pin する時
- すでにバッファプールに該当ページが存在したら pinned をインクリメント
- バッファプールに存在しない場合
- プールに空きがある、もしくは unpinned 状態のページがあればブロックからページに読み込みを行う
- reuse する対象のページを選択するための主要な Strategies は後述
- プールに空きがなく、unpinned 状態のページもない場合はクライアントを wait list に追加して unpinned 状態のページが出てくるまで待ってもらう
- プールに空きがある、もしくは unpinned 状態のページがあればブロックからページに読み込みを行う
- バッファープールと呼ばれる固定的なページを保持
- Buffer Replacement Strategies
- Buffer Manager はどのページが次にアクセスされるか予期できないが、できるだけ長い時間再度読み込む必要がないものを選択したい
- database のライフタイムを通じて常に使用されるページ(e.g. カタログファイル) などもある
- 主要な 4 つの戦略
- ナイーブ: シンプルにシーケンシャルに unpinned 状態のページを探す
- SimpleDB はこれを実装
- FIFO
- LRU: least recently used
- Clock: バッファプールをリング状にスキャン & スキャン開始場所は前回の置換した場所の後ろから
- ナイーブ: シンプルにシーケンシャルに unpinned 状態のページを探す
- Buffer Manager はどのページが次にアクセスされるか予期できないが、できるだけ長い時間再度読み込む必要がないものを選択したい
メモ
- ここで言うログは WAL と同一なのか?
- おそらく同一
- ↑にも記載があるように、Chap.5 で取り上げられていそうではある
- 参考資料
Chapter 4: Memory Management(Log) - 実装
実装対象: LogMgr, LogIterator
LogMgr
- append: ログレコードをページの先頭に向かって書き込み、そのログシーケンスナンバー(LSN)を返す
- 唯一の制限: ログレコードの配列がページに収まる必要あり
- synchronized 指定
- 追加するログがページに収まりきらない場合は、flush して次のブロックに移動
- ページの先頭に、最後に書き込んだログレコードの pos を記録
public synchronized int append(byte[] logrec) {
int boundary = logpage.getInt(0);
int recsize = logrec.length;
int bytesneeded = recsize + Integer.BYTES;
if (boundary - bytesneeded < Integer.BYTES){// It doesn't fit
flush(); // so move to the next block.
currentblk = appendNewBlock();
boundary = logpage.getInt(0);
}
int recpos = boundary - bytesneeded;
logpage.setBytes(recpos, logrec);
logpage.setInt(0, recpos); // the new boundary latestLSN += 1;
return latestLSN;
}
- flush: ログレコードを確実に disk に書き込む
- iterator: ログレコードを逆順に返す iterator を取得
- constructor
- ログファイルが存在しない場合は1つめのブロックを発行
- ログファイルが存在する場合は、一番最後のブロックを読み込み
LogIterator
- ブロック内のログレコードをブロックの先頭から読み込み
- ログレコードは後ろから先頭に向けて書き込まれるため、先頭から読み込むと書き込みと逆順となる
- ページに読み込んだブロックの先頭まで達したら、次のブロックに移動
Chapter 4: Memory Management(Buffer) - 実装
実装対象: Buffer, BufferMgr
Buffer
- ページを読み込み
- pin 数を保持
- 変更に関わる情報も保持
- トランザクション識別番号と、ページ変更時に生成されたログレコードの LSN を記録
- flush
- disk write を行って、バッファが割り当てられた disk ブロックと、バッファが保持するページの値を一致させる
- 先にページ変更時に生成されたログレコードを flush して disk に記録した上で実施
BufferMgr
- pin: 内部的に tryToPin を呼び出し
- tryToPin
- 2 つのパートがある
- findExistingBuffer: すでに該当のブロックにに割り当てられた buffer を探す
- chooseUnpinnedBuffer: ナイーブな方法で unpinned buffer を探す
- tryToPin が null を返した場合、pin メソッドは wait する
- unpin されたら notifyAll が呼び出される
- タイムアウトも設定
- 2 つのパートがある
- tryToPin
public synchronized Buffer pin(BlockId blk) {
try {
long timestamp = System.currentTimeMillis();
Buffer buff = tryToPin(blk);
while (buff == null && !waitingTooLong(timestamp)) {
wait(MAX_TIME);
buff = tryToPin(blk);
}
if (buff == null)
throw new BufferAbortException();
return buff;
} catch(InterruptedException e) {
throw new BufferAbortException();
}
}
public synchronized void unpin(Buffer buff) {
buff.unpin();
if (!buff.isPinned()) {
numAvailable++;
notifyAll();
}
}
Chapter 5: Transaction Management
- buffer manager は複数のクライアントが同じ buffer に並行アクセスすることを許容
- 結果はカオスになり得る
- concurrency manager
- トランザクションが一貫して動くように実行を制御
- recovery manager
- ログレコードを読み取り/書き込み
- コミットされていないトランザクションを必要に応じて取り消し可能にする
- ログレコードを読み取り/書き込み
Transactions
- 単一の操作として動作する操作のグループ
- ACID 特定によって特徴づけられる
- atomicity and durability
- commited, rollback 操作の適切な動作を記述
- recovery manager の責務
- consistency and isolation
- 並行アクセス時の適切な動作を記述
- conflict する操作を防ぐ
- 典型的な戦略は、conflict を検知したら一方のクライアントを wait させる
- concurrency manager の責務
Chapter 5: Transaction Management - Recovery Manager
- log record の書き込み
- transaction の rollback
- システムクラッシュ後の復旧
Log Records
- loggable activity が発生した際に log record を書き込み
- 基本的な 4 タイプのレコード
- start
- commit
- rollback
- update
- SimpleDB では integer, string の 2 種類に対応
- 潜在的な loggable activity はファイル末尾への block の追加
- transaction が rollback した際、追加された block の割り当て解除
- 簡単のため SimpleDB では対応しない
- record に含む情報
- record のタイプ
- START, SETINT, SETSTRING, COMMIT, ROLLBACK
- transaction の ID
- update の record のみ追加の 5 つの値
- 変更対象のファイルの名称
- ブロックナンバー
- 変更箇所の offset
- 変更箇所の old value
- 変更箇所の new value
- record のタイプ
- 複数の transaction が同時に log に書き込まれるため、log record は散在
Rolback
- 変更を元に戻すことで transaction を rollback
- update の record を追加した逆順で値を古い値に更新していく
Recovery
- リカバリは database engine 起動時に実行
- 目的は database を「合理的な状態」に復元すること
- 「合理的な状態」とは
- すべての未完了のトランザクションは rollback
- すべての commit 済みのトランザクションは変更が disk に書かれている
- 正常なシャットダウン後の起動時にはすでに合理的な状態になっている
- トランザクションの完了とバッファの flush が完了するまで wait するため
- 予期せずクラッシュした場合は処理が必要
- recovery manager はログファイルに記録された情報をもとにリカバリを実行
- コミット操作を完了する前に確実にログレコードをフラッシュする必要がある
- undo-redo algorithm
- undo
- すべてのログを逆順に読む
- committed, rollback のログであればそれぞれのリストに追加
- committed, rollback のリストに含まれないトランザクションの update ログであれば、指定の箇所に古い値を格納
- redo
- 全てのログを先頭から読む
- committed のリスト上のトランザクションの update ログであれば、指定の箇所に新しい値を格納
- undo
Undo-Only and Redo-Only Recovery
- undo もしくは redo のみを実行することでアルゴリズムをシンプルにできる
- undo のみのアルゴリズム
- commit record 書き込み前に disk に書き込むことを保証すれば redo は不要になる
- 良い点: リカバリはログファイルを 1 回読めば終わるので高速 & 更新レコードの new value は不要
- 悪い点: commit 操作は buffer flush を伴うので非常に遅くなる
- クラッシュ頻度が低い場合は、redo した方が効率良くなる
- redo のみのアルゴリズム
- commit されていない buffer が disk に書き込まれないのであれば undo は不要になる
- transaction が完了するまで buffer を pin 留め
- 良い点: リカバリは undo 処理がない分高速
- 悪い点: transaction が変更するブロックをすべて buffer に pin 留めするので buffer の競合を増加させる
Write-Ahead Logging
- リカバリ時に未完了の transaction の undo が必要 -> 未完了の transaction のすべての更新は log ファイル内に対応する log record を持つ必要がある
- 上記を満たす方法
- 更新 log record が書き込まれたらすぐに disk に flush
- が、非常に非効率的
- 未完了 transaction が page を更新した際にシステムクラッシュした場合の 4 パターン
- (a) page と log record が両方 disk に書き込まれた
- (b) page だけが disk に書き込まれた
- (c) log record だけが disk に書き込まれた
- (d) どちらも disk に書き込まれなかった
- ↑のうち (b) が問題となる
- database エンジンは buffer page を flush する際に更新 log record を flush することで回避
- Write Ahead Log と呼ばれる
- database エンジンは buffer page を flush する際に更新 log record を flush することで回避
Quiescent Checkpointing
- log ファイルには database に対する全ての変更の履歴が含まれる
- database ファイルよりも大きくなることもある
- リカバリ作業は労力が必要になるので、 log の一部だけを読み出す手法が考案された
- ある log について、それより前に commit されていない transaction が存在しなければ undo を停止できる
- 完了した transaction の buffer が disk に flush されていれば redo は停止できる
- quiescent checkpoint は log 内の目印として機能
- undo 時に checkpoint log に遭遇 -> redo はその log 以降のみ処理可能
- アルゴリズム
- Stop accepting new transactions.
- Wait for existing transaction to finish.
- Flush all modified buffers.
- Append a quiescent checkpoint record to the log and flush it to disk.
- Start accepting new transactions.
- quiescent checkpoint log record の書き込みに適したタイミングはシステム起動時のリカバリが終わり、新しい transaction が開始される前
Nonquiescent Checkpoiting
- quiescent checkpointing はシンプルで理解しやすい
- が、recovery manager が transaction の完了を待っている間 database が利用できないようにする必要がある
- 許容できないケースも多い
- quiescent(静的)な状態を必要としないアルゴリズムが開発された
- 許容できないケースも多い
- が、recovery manager が transaction の完了を待っている間 database が利用できないようにする必要がある
- アルゴリズム
- Let T1,...,Tk be the currently running transactions.
- Stop accepting new transactions.
- Flush all modified buffers
- Write the record <NQCKPT T1,...,Tk> into the log.
- Start accepting new transactions.
- 実行中のトランザクションを NQCKPT レコードに記録しておき、リカバリ時の undo をその場所で止めることができる
- NQCKPT ログに到達したら、そこに記録されているトランザクションの状況を確認
- 残っていたトランザクションの開始レコードの開始レコードより前のログは無視できる
Data item Granularity
- granularity(粒度)
- log record に含むデータ項目の大きさ
- ここまでの説明における granularity は変更された値だったが、他にも block またはファイル単位の選択肢もある
- block
- block が変更されるたびに更新 log record 作成
- block の以前の値、新しい値が log record に含まれる
- log record の数は少なくなるが、更新 log record が非常に大きくなってしまう
- ファイル
- 変更したファイルに対して 1 つの更新 log record を生成
- log record にはファイルの元の内容全体が含まれる
- 値がいくつ変更されても、ファイル全体のコピーを作成するため実用的ではない
- ワープロソフトなどは採用している
Chapter 5: Transaction Management - Recovery Manager 実装
実装対象: 各種 LogRecord, RecoveryMgr
LogRecords
- 各 log record は共通のインターフェースを実装
public interface LogRecord {
static final int CHECKPOINT = 0, START = 1, COMMIT = 2,
ROLLBACK = 3, SETINT = 4, SETSTRING = 5;
int op();
int txNumber();
void undo(int txnum);
// ...省略
}
- LogRecord を実装した SetStringRecord
- コンストラクタ: バイト配列から↑の6つの値を抽出
- writeToLog: SETSTRINGログレコードの6つの値をバイト配列にエンコードする静的メソッド
- undo: undo を実行する transaction を受け取り、対象の block を pin し、old value を書き込み、unpin する
- 呼び出し側が disk に flush する責務を持つ
public class SetStringRecord implements LogRecord {
private int txnum, offset;
private String val;
private BlockId blk;
public SetStringRecord(Page p) {
int tpos = Integer.BYTES;
txnum = p.getInt(tpos);
int fpos = tpos + Integer.BYTES;
String filename = p.getString(fpos);
int bpos = fpos + Page.maxLength(filename.length());
int blknum = p.getInt(bpos);
blk = new BlockId(filename, blknum);
int opos = bpos + Integer.BYTES;
offset = p.getInt(opos);
int vpos = opos + Integer.BYTES;
val = p.getString(vpos);
}
// ...省略
@Override
public void undo(Transaction tx) {
tx.pin(blk);
tx.setString(blk, offset, val, false); // don't log the undo!
tx.unpin(blk);
}
public static int writeToLog(LogMgr lm, int txnum, BlockId blk, int offset, String val) {
int tpos = Integer.BYTES;
int fpos = tpos + Integer.BYTES;
int bpos = fpos + Page.maxLength(blk.fileName().length());
int opos = bpos + Integer.BYTES;
int vpos = opos + Integer.BYTES;
int reclen = vpos + Page.maxLength(val.length());
byte[] rec = new byte[reclen];
Page p = new Page(rec);
p.setInt(0, SETSTRING);
p.setInt(tpos, txnum);
p.setString(fpos, blk.fileName());
p.setInt(bpos, blk.number());
p.setInt(opos, offset);
p.setString(vpos, val);
return lm.append(rec);
}
}
RecoveryMgr
- undo-only リカバリーを実装
- commit, rollback は log record 書き込み前に transaction の buffer を flush
- ここでいう log record は commit, rollback のタイプのもの
- 更新 log record はすでに記録されている
- ここでいう log record は commit, rollback のタイプのもの
- (private method) doRecover, doRollback
- ログレコードを後方からたどる
- 該当の transaction の log record を見つけるたびに、undo を呼び出し
- 停止条件
- doRecover: checkpoint log を読む or 終端に達する
- doRollback: 該当 transaction の start log を読んだ時
public class RecoveryMgr {
// ...省略
public void commit() {
bm.flushAll(txnum);
int lsn = CommitRecord.writeToLog(lm, txnum);
lm.flush(lsn);
}
public void rollback() {
doRollback();
bm.flushAll(txnum);
int lsn = RollbackRecord.writeToLog(lm, txnum);
lm.flush(lsn);
}
public void recover() {
doRecover();
bm.flushAll(txnum);
int lsn = CheckpointRecord.writeToLog(lm);
lm.flush(lsn);
}
// ...省略
private void doRollback() {
Iterator<byte[]> iter = lm.iterator();
while (iter.hasNext()) {
byte[] bytes = iter.next();
LogRecord rec = LogRecord.createLogRecord(bytes);
if (rec.txNumber() == txnum) {
if (rec.op() == LogRecord.START)
return;
rec.undo(tx);;
}
}
}
private void doRecover() {
Collection<Integer> finishedTxs = new ArrayList<Integer>();
Iterator<byte[]> iter = lm.iterator();
while (iter.hasNext()) {
byte[] bytes = iter.next();
LogRecord rec = LogRecord.createLogRecord(bytes);
if (rec.op() == LogRecord.CHECKPOINT)
return;
if (rec.op() == LogRecord.COMMIT || rec.op() == LogRecord.ROLLBACK)
finishedTxs.add(rec.txNumber());
else if (!finishedTxs.contains(rec.txNumber()))
rec.undo(tx);
}
}
}
Chapter 5: Transaction Management - Concurrency Manager
- Concurrency Manager は同時実行 transaction の正しい実行に責任を持つ
- このセクションでは
- 「実行が正しい」とはどういうことかを検討
- 正しさを保証するいくつかのアルゴリズムをとりあげる
Serializable Schedules
- transaction の履歴は database ファイルにアクセスするメソッド(get/set など)の呼び出しのシーケンス
- database 操作の粒度はさまざま
- 値単位
- block 単位
- その他もある(後述)
- 複数の transaction が同時実行されている場合
- database エンジンはそれらのスレッドの実行をインターリーブ
- SimpleDB では Java ランタイムが自動的におこなう
- transaction の履歴は予測不可能なインターリブになる
- -> スケジュールと呼ばれる
- database エンジンはそれらのスレッドの実行をインターリーブ
- concurrency control の目的は、正しいスケジュールだけが実行されることを保証
- 正しいとは?を以下で見ていく
- すべての transaction が直列に実行されるスケジュールを考えると
- インターリーブされない
- スケジュールは back-to-back 履歴となる
- このようなスケジュールは
serial scheduleと呼ばれる
- 同一の transaction であっても serial schedule が異なれば異なる結果になり得る
- 以下のような transaction を考える
- T1: W(b1); W(b2)
- T2: W(b1); W(b2)
- どちらも b1 block を書いた後に b2 block を書くため、block 単位の操作については同一の履歴を持つ
- ただ、transaction としては必ずしも同一ではない
- T1 はブロックの先頭に X を書き込み、T2 は Y と書き込む場合など
- T1, T2 の順番が変わると、結果が変わる
- どちらの serial schedule についても database エンジンは正しいものとして扱う
- ただ、transaction としては必ずしも同一ではない
- 以下のような transaction を考える
- non-serial schedule であっても、ある serial schedule と同じ結果を出す場合、
serializableという - non-serial schedule である以下のような transaction を考える
- W1(b1); W2(b1); W1(b2); W2(b2)
- T1 の前半、T2 の前半、T1 の後半、T2 の後半を実行した結果
- このスケジュールは T1 を実行し、T2 を実行することと等価なので
serializable
- W1(b1); W2(b1); W1(b2); W2(b2)
- 以下のようなnon-serial schedule の場合は
non-serializable- W1(b1); W2(b1); W2(b2); W1(b2)
- T1 の前半、T2 の前半、T2 の後半、T1 の後半
- b1 block には T2 の値が書き込まれるが、b2 block には T1 の値が書き込まれる
- W1(b1); W2(b1); W2(b2); W1(b2)
- ACID の isolation の性質
- 各トランザクションがあたかもシステムにおける唯一のトランザクションであるかのように実行されるべき
- non-serializable では↑の性質をもたないので、non-serializable なスケジュールは正しくない
- schedule は serializable である場合のみ「正しい」
The Lock Table
- database エンジンは全てのスケジュールが serializable を保証する責任がある
- 一般的なテクニック: locking を利用して transaction の実行を延期
- このセクションでは lock がどう機能するかを説明
- 各 block に対する lock
- 共有 lock(slock)
- 他の transaction は共有 lock を持つことはできる
- 排他 lock(xlock)
- 他の transaction はいかなる lock も持てない
- 共有 lock(slock)
- 1 つの transaction で 1 つの block に対して共有 lock と排他 lock を持つことはできる
The Lock Protocol
- すべてのスケジュールが serializable であることを保証する
- 以下の transaction を考える
- T1: R(b1); W(b2)
- T2: W(b1); W(b2)
- serial schedule が異なる結果になる原因
- 両方とも同じ b2 block に書き込むため、順序によって値が変わる
- 一般的に、実行順序によって異なる結果を生む可能性がある場合、「競合」する
- 読み書きの衝突もある
- T1 の R(b1) の実行が、T2 の W(b1) の先か後かで結果が変わる
- 両方とも同じ b2 block に書き込むため、順序によって値が変わる
- non-serial schedule で競合する操作が実行される順序は、同等の serial schedule がどうあるべきかを決定
- ↑の例では W2(b1) が R1(b1) より先に実行される場合、同等の serial schedule は T1 より先に T2 が実行されなければならない
- 衝突するすべての操作を考えると、T1 完了後に T2 実行、もしくは T2 完了後に T1 実行のどちらかとなる
- 衝突しない操作は任意の順序で発生させることができる
- lock プロトコル
- ある block を読む前に共有 lock を取得する
- ある block を変更する前に排他 lock を取得する
- commit or rollback 後に全ての lock を開放する
- ↑のプロトコルから 2 つの推論ができる
- ある transaction が block の共有 lock を取得した場合、他の transaction はその block に書き込んでいない
- ある transaction が block の排他 lock を取得した場合、他の transaction はその block にアクセスしていない
- つまり、ある transaction が実行した操作は、他のアクティブな transaction による以前の操作と衝突しないことを意味する
- 結果として、得られるスケジュールは常に serializable となる
- 等価な serial schedule は transaction のコミット順序によって決定される
- lock protocol システムの並行性を大幅に制限する
- transaction が完了するまで lock を保持するため
- 不要になった時点で lock を解放できれば、他の transaction の待ち時間は短くなる
- が、transaction 完了前に lock を解放すると 2 つの深刻な問題が起きる(後述)
Chapter 5: Transaction Management - Concurrency Manager Part2
(Chapter 5 が長いので分割)
Serializability Problems
- transaction が block の lock を解放すると、serializability への影響無しに別の block を lock できなくなる
- 以下の transaction T1 を考える
- T1: ...R(x); UL(x); SL(y); R(y);...
- R: read, UL: unlock, SL: shared lock
- T1: ...R(x); UL(x); SL(y); R(y);...
- x の unlock と y の共有 lock の間において T1 は非常に脆弱となる
- その間に T2 が割り込んで x, y に排他 lock をかけて書き込み、commit & unlock したとする
- T1 は T2 書き込み前の x を読んだので serial order は T2 より前に来る必要がある
- が、T1 はその後 T2 が書き込んだ y を読むので T1 は T2 より後に来なければならない
- 結果、スケジュールは non-serializable となる
- 逆に transaction が unlock する前に全ての lock を取得する場合のスケジュールは serializable となる
- 2 phase lock と呼ばれる
- lock を蓄積するフェーズと、lock を解放するフェーズがあるため
- 2 phase lock は database エンジンで簡単には利用できない
- 通常、最終 block にアクセスし終わる頃には transaction は commit する準備ができている
- (意味が取れてない)
- 通常、最終 block にアクセスし終わる頃には transaction は commit する準備ができている
Reading Uncommitted Data
- lock を早期に解放することのもう一つの問題は、transaction が commit されてないデータを読み取れてしまうこと
- 以下の部分的なスケジュールを考える
- ...W1(b); UL1(b); SL2(b); R2(b);
- T1 が b block に書き込み & unlock、T2 が b block を共有 lock して読み込み、をしたとする
- T1 が rollback すると、 T2 は存在しない変更に基づいた読み込みをしているため rollback が必要になる
- -> rollback の連鎖が起きる(カスケードロールバック)
- transaction に commit されていないデータの読み取りを許可すると
- より多くの同時実行を可能にする
- が、データを書き込んだ transaction が commit されないリスクを負う
- ほとんどの商用 DB は transaction 完了するまで常に排他 lock 解放を待つ
Deadlock
- lock protocol は全ての transaction が commit されることを保証しているわけではない
- 保証するのは、スケジュールが serializable となること
- 特に、deadlock になる可能性がある
- 以下の transaction の履歴を考える
- T1: W(b1); W(b2)
- T2: W(b2); W(b1)
- T1 が先行している状態で、T1 が b2 の lock 取得前に T2 が b2 の lock を取得すると deadlock となる
- concurrency manager は waits-for グラフを保持することで deadlock を検出
- 各 transaction に 1 つのノードを持つ
- T1 が T2 の持つ lock を待っている場合、T1 から T2 へのエッジを持つ
- 各エッジには transaction が待っている block のラベルが貼られる
- lock が要求、または解放されるたびにグラフは更新
- waits-for グラフがサイクルを持つする場合 deadlock が発生
- transaction manager は deadlock を検出するとサイクル内の transaction を 1 つ選択して rollback
- サイクル発生の原因となった lock を要求した transaction を選択
- 選択する戦略は他にもある
- サイクル発生の原因となった lock を要求した transaction を選択
- lock 待ちのスレッドだけでなく buffer 待ちのスレッドも考慮すると、deadlock は複雑になる
- 以下のシナリオを考える
- T1: xlock(b1); pin(b4)
- T2: pin(b2); pin(b3); xlock(b1)
- T1 が b1 の lock を取得したのちに中断し、その間に T2 が b2, b3 を pin し b1 の lock 取得待ちに入る場合
- T1 が b4 の buffer 取得待ちに入り、他に unpin されることがなければ deadlock
- lock manager は waits-for グラフを保持するだけでなく、transaction の buffer 待ちも考慮するのはかなり困難
- waits-for グラフ使用の問題点
- グラフの維持がやや困難
- サイクル検出に時間がかかる
- deadlock 検出を近似的におこなう、より単純な戦略もある
- 常に deadlock を検出 & deadlock ではない状況も deadlock 判定されることがあるもの
- wait-die
- T1 の lock 要求が T2 が保持する lock と競合した時を考える
- T1 が T2 よりも古い transaction であれば wait する
- そうでなければ rollback する
- use time limit
- T1 の lock 要求が T2 が保持する lock と競合した時を考える
- T1 は lock 取得待ちをする
- wait list 上に一定時間以上いたら rollback される
File-Level Conflicts and Phantoms
- これまで block の読み書きに起因する競合を見てみた
- ファイルの終端マーカーの読み書きをする size, append メソッドの衝突もある
- 以下の transaction を考える
- T1: ...; append; ...
- T2: ...; size; ...
- T1 が T2 の size 呼び出し前に append を呼び出すとすると、serial order 上 T1 は T2 より前に来る必要がある
- phantom 問題: ↑の衝突の結果の 1 つ
- T2 がファイルの全内容を繰り返し読み、その度に size を呼び出す場合
- T2 が size を呼び出した後、T1 が append した場合、T2 が次にファイルを読み込むとき、T2 は追加された値を見ることになる
- ACID の分離の性質に違反
- 解決策
- end-of-file マーカーを lock 可能にする
- append するためには xlock、size を呼び出すためには slock を実施
- end-of-file マーカーを lock 可能にする
Multiversion Locking
- 待ち時間を減らすための戦略
- 読み取りと更新 transaction は先にロックを取得した transaction が完了するまで、もう一方は待たされる
The Principle of Multiversion Locking
- 各 block に複数のバージョンを保存
- 基本的なアイデアは以下
- block の各バージョンにはそれを書き込んだ transaction の commit 時刻のタイムスタンプが付けられる
- 読み取り専用の transaction が block から値を要求すると concurrency manager は transaction の開始時に最も最近 commit された block のバージョンを使用する
- 読み取り専用 transaction は transaction の開始時に見えたであろう commit された block のバージョンを使用
- 読み取り専用 transaction は commit されたデータのスナップショットを見ることになる
- それ以降の transaction によって書き込まれたデータを見ることはない
- 次の multiversion lock の例を考える
- T1: W(b1); W(b2)
- T2: W(b1); W(b2)
- T3: R(b1); R(b2)
- T4: W(b2)
- スケジュール

- W1(b1); W1(b2); C1; W2(b1); R3(b1); W4(b2); C4; R3(b2); C3; W2(b1); C2
- Ci: commit タイミングで、i は transaction の番号に対応
- 更新 transaction である T1, T2, T4 は lock protocol に従う
- それぞれの transaction ごとに block のバージョンが保存される
- time は transaction が commit した時間
- 読み取り専用 transaction である T3 は lock protocol に従わない
- R3(b1) で読み取られるのは直前に commit されている T1 が書き込んだ値
- R3(b2) は T4 の transaction が commit された後にスケジュールされているが time=7 のバージョンは表示されない
- multiversion lock の優れた点
- 読み取り専用の transaction が lock を取得する必要がなく、待つ必要がない
- 更新する transaction が比較的少ないと仮定すると、待機の頻度はかなり低くなる
5.4.6.2 Implementing Multiversion Locking
- 各 block のバージョンをどのように管理するか
- バージョンファイルを明示的に保存する方法
- シンプルだけどやや難しい方法
- ログを使用して block の任意の望ましいバージョンを再構築する方法
- バージョンファイルを明示的に保存する方法
- ログを使用して再構築する方法の実装
- 読み取り専用 transaction 開始時にタイムスタンプを付与
- 更新トランザクションは commit する時にタイムスタンプを付与
- commit 方法は以下
- recovery manager は commit log record の一部として transaction のタイムスタンプを書き込む
- transaction が保持する各 xlock について、concurrency manager が block をピン留めし、タイムスタンプを block の先頭に書き込み、buffer を unpin する
- 適切なバージョン再構築のステップ
- block の現在のバージョンを新しいページをコピーする
- 次のように log を3回逆向きに読む
- 読み取り transaction が持つタイムスタンプ t の後に commit された transaction のリストを構築
- t よりも小さいタイムスタンプの commit record まで達したら log 読み込みをストップ
- 未完了の transaction リストを構築
- commit or rollback record がないものは未完了の transaction
- quiescent checkpoint の場合: checkpoint record に達した時点で log 読み込みをストップ
- nonquiescent checkpoint の場合: checkpoint record に含まれる transaction の最も古い開始 record に達した時点で log 読み込みをストップ
- 上記のリストのいずれかにある transaction による更新を巻き戻す
- 更新を巻き戻した block の情報を返す
- 読み取り transaction が持つタイムスタンプ t の後に commit された transaction のリストを構築
- 読み取り専用 transaction は JDBC においては
setReadOnlyというメソッドで指定
Transaction Isolation Levels
- serializabitily を強制することはかなりの待ち時間を発生させる
- multiversion lock は読み取り専用 transaction においては待ち時間が無く魅力的
- 実装はやや複雑
- version を作成するために追加のディスクアクセスが必要
- 更新 transaction には適用できない
- 待ち時間を短縮する方法: 完全な serializability を目指さない
- transaction 分離レベルと共有 lock の使用方法のまとめ
- serializable
- problems: none
- lock usage
- transaction 完了まで共有 lock を保持
- EOF マーカーに対しても共有 lock 取得
- repeatable read
- problems: phantoms
- lock usage
- transaction 完了まで共有 lock を保持
- EOF マーカーに対しては共有 lock はとらない
- read committed
- problems: phantoms, 値が変わりうる
- lock usage
- 共有 lock を早めに解放
- EOF マーカーに対しては共有 lock はとらない
- read uncommitted
- problems: phantoms, 値が変わりうる, ダーティリード
- lock usage
- 共有 lock をとらない
- serializable
- ↑のどの分離レベルでもデータの書き込みに関しては正しく振る舞うべき
- 適切な排他 lock(EOF マーカー含む)を取得し、完了するまで保持
- read uncomitted isolation と multiversion locking の比較
- どちらも読み取り専用の transaction に適用 & lock 無しで動作
- read uncommitted は各 block の現在の値を見れてしまう
- serializable とは程遠い
- multiversion locking は transaction 開始時点で commit されていた値を見るので serializable
Data Item Granularity
- ここまで block 単位で lock することを想定してきたが、他の粒度も可能
- 粒度(=concurrency data item と呼ばれる)
- 値
- ファイル
- database 全体
- concurrency control の原則は粒度に影響されない
- 定義、プロトコル、アルゴリズムはどの粒度にも適用される
- 粒度の選択は実用性をもとに判断
- 粒度選択におけるトレードオフ
- 粒度のサイズを小さい場合
- より多くの同時実行が可能になる
- より多くの lock が必要となる
- 粒度のサイズを大きい場合
- 同時実行性が悪化する
- より少ない lock で扱える
- -> 結果、block 粒度は妥当な選択といえる
- 粒度のサイズを小さい場合
- データレコードの粒度を扱える database もある
- 魅力的だが phantom に関する新たな問題が発生する
- 新しいデータレコードは既存の block に挿入される場合 phantom リードが起こる
- 解決策は block やファイルレベルの粒度もサポート
- 魅力的だが phantom に関する新たな問題が発生する
Chapter 5: Transaction Management - Concurrency Manager 実装
実装対象: LockTable, ConcurrencyMgr
ConcurrencyMgr
- 各 transaction が CocurrencyMgr を持つ
- 各 ConcurrencyMgr は同じ LockTable を使用する必要がある
- CocurrencyMgr はその transaction が保持する lock を追跡
- sLock メソッド
- transaction がすでにblock を lock していたら何もしない
- ロックしていない場合 LockTable の sLock メソッドを呼び出し
- 許可されるのを待つ
public void sLock(BlockId blk) {
if (locks.get(blk) == null) {
locktbl.sLock(blk);
locks.put(blk, "S");
}
}
- xLock メソッド
- すでに block に対する xLock を保持している場合は何もしない
- まず sLock を呼び出して、ロックが許可されるのを待つ
- LockTable の xLock メソッドは transaction が block に対する slock を持っていることを仮定
public void xLock(BlockId blk) {
if (!hasXLock(blk)) {
sLock(blk);
locktbl.xLock(blk);
locks.put(blk, "X");
}
}
LockTable
- locks
- 現在 lock が割り当てられている各 block のエントリーを含む
- エントリ: 排他 lock では -1, 正の値は共有 lock 数
- 現在 lock が割り当てられている各 block のエントリーを含む
- sLock メソッド
- BufferMgr の pin メソッドと似た動作
- xlock がある場合は待ち続ける
- xlock がない場合は locks の該当 block の値をインクリメント
private final Map<BlockId, Integer> locks = new HashMap<>();
public synchronized void sLock(BlockId blk) {
try {
long timestamp = System.currentTimeMillis();
while (hasXlock(blk) && !waitingTooLong(timestamp))
wait(MAX_TIME);
if (hasXlock(blk))
throw new LockAbortException();
int val = getLockVal(blk); // will not be negative
locks.put(blk, val + 1);
} catch (InterruptedException e) {
throw new LockAbortException();
}
}
- xLock メソッド
- BufferMgr の pin メソッドと似た動作
- 該当 block に 2 つ以上の slock がかかっている場合 while ループで待つ
-
hasOtherSLocksはlocks の値 > 1を返す - ConcurrencyMgr は xlock 要求前に slock を取得するため該当 block に対する slock 数は少なくとも 1 ある
-
- 他の transaction の slock がなければ
locksの該当 block の値を-1に上書き - なぜこのような実装になっているか?
- -> ある block に対して複数の transaction が xlock を取ろうとした場合の制御のため。
- slock は xlock がない場合のみ取得できるので xlock を取る際も事前に slock を取っている
- -> ある block に対して複数の transaction が xlock を取ろうとした場合の制御のため。
public synchronized void xLock(BlockId blk) {
try {
long timestamp = System.currentTimeMillis();
while (hasOtherSLocks(blk) && !waitingTooLong(timestamp))
wait(MAX_TIME);
if (hasOtherSLocks(blk))
throw new LockAbortException();
locks.put(blk, -1);
} catch (InterruptedException e) {
throw new LockAbortException();
}
}
- unlock メソッド
- 指定された lock をコレクションから削除 or decrement
- コレクションから削除された場合、待機中のスレッドに通知
Chapter 5: Transaction Management - Transaction 実装
実装対象: Transaction, BufferList
Transaction
- BufferList を使用して pin 留めした buffer を管理
- 各 Transaction オブジェクトはそれぞれ recovery manager と concurrency manager を生成
- commit, rollback メソッド
- 残りの buffer を unpin
- recovery manager を呼び出して commit/rollback
- concurrency manager を呼び出して lock を解放
public void commit() {
recoveryMgr.commit();
concurMgr.release();
mybuffers.unpinAll();
System.out.println("transaction " + txnum + " committed");
}
public void rollback() {
recoveryMgr.rollback();
concurMgr.release();
mybuffers.unpinAll();
System.out.println("transaction " + txnum + " roll back");
}
- getInt, getString メソッド
- 指定された block の slock を取得
- buffer から値を返す
public int getInt(BlockId blk, int offset) {
concurMgr.sLock(blk);
Buffer buff = mybuffers.getBuffer(blk);
return buff.contents().getInt(offset);
}
public String getString(BlockId blk, int offset) {
concurMgr.sLock(blk);
Buffer buff = mybuffers.getBuffer(blk);
return buff.contents().getString(offset);
}
- setInt, setString メソッド
- concurrencyMgr から xlock 取得
- log record 作成 & lsn 取得
- buffer の setModified に lsn を記録
public void setInt(BlockId blk, int offset, int val, boolean okToLog) {
concurMgr.xLock(blk);
Buffer buff = mybuffers.getBuffer(blk);
int lsn = -1;
if (okToLog)
lsn = recoveryMgr.setInt(buff, offset, val);
Page p = buff.contents();
p.setInt(offset, val);
buff.setModified(txnum, lsn);
}
public void setString(BlockId blk, int offset, String val, boolean okToLog) {
concurMgr.xLock(blk);
Buffer buff = mybuffers.getBuffer(blk);
int lsn = -1;
if (okToLog)
lsn = recoveryMgr.setString(buff, offset, val);
Page p = buff.contents();
p.setString(offset, val);
buff.setModified(txnum, lsn);
}
- size, append メソッド
- EOF マーカーを block number -1 として扱う
- size は↑の block の slock を取得し block 数を返す
- append は ↑の block の xlock を取得し block を追加する
public int size(String filename) {
BlockId dummyblk = new BlockId(filename, END_OF_FILE);
concurMgr.sLock(dummyblk);
return fm.length(filename);
}
public BlockId append(String filename) {
BlockId dummyblk = new BlockId(filename, END_OF_FILE);
concurMgr.xLock(dummyblk);
return fm.append(filename);
}
BufferList
- ある transaction に対して pin 留めされている buffer のリストを管理
- block の buffer 割り当てや pin 留め数を管理
Chapter 6: Record Management
- record manager は block 内の値の配置に責務を持つ
Record Manager の設計
- 以下のような問題に対処する必要がある
- 各レコードは 1 つの block 内に配置する必要があるか
- block 内のレコードはすべて同じテーブルのものか
- 各フィールドはあらかじめ決められたバイト数で表現できるか
- 各フィールドの値はそのレコードのどこに配置すべきか
- 問題点の詳細とトレードオフは後述
Spanned or Unspanned Records
- spanned record: 値が 2 つ以上の block にまたがる record
- unspanned だと
- disk スペースを浪費
- 例: block の 51 % の容量の record を連続して配置すると 49 % 分 が使われない状態になる
- block より大きなサイズの record は記録できない
- spanned だと
- record へのアクセスが複雑になる
- メモリ上での record の再構築も必要
Homogeneous or Nonhomogeneous Files
- homogeneous file: ファイル内の全ての record が同じテーブルのもの
- homogeneous だと
- 単一テーブルに対するクエリは簡単に返せる
- 複数テーブルに対するクエリは効率が悪くなる
- nonhomogeneous file: 同じファイル内にクラスタリングしたレコードを一緒に格納
- nonhomogeneous だと
- クラスタリングされたテーブルを結合するクエリの効率が向上
- 単一テーブルのクエリの効率は低下
- 各テーブルのレコードがより多くのブロックに分散するため
- 単一テーブルのクエリの効率は低下
Fixed-Length Versus Variable-Length Fields
- ほとんどの型は固定長
- 整数、浮動小数点、日付/時刻型、...
- 可変長の表現は複雑
- フィールドの変更時にレコードの大きさが変わると再配置が必要となることもある
- 文字列の3つの表現
- a: 可変長表現
- 文字列が必要とする正確な量のスペースをレコードに割り当て
- b: 固定長表現1
- 文字列をレコードの外部の場所に格納し、レコード内には固定長の参照を保持
- c: 固定長表現2
- 各文字列に対して、長さに関係なく同じ量のスペースを割り当て
- スペースが無駄になりがち
- 上記の表現は SQL 標準の char, varchar, clob に対応
- char: c
- varchar: a
- clob: b
Placing Fields in Records
- 固定長のレコードの場合、最も簡単な位置決め方法: 隣り合わせに格納
- レコードのサイズは各フィールドのサイズの合計
- オフセットは前のフィールドの終端
- 大抵のコンピューターでは整数はメモリ上の4の倍数の位置にある必要がある
- record manager は全ての整数が 4 バイト境界にアラインされていることを確認
- 前のフィールドが 4 の倍数でない場所で終わっている場合パディングする
- 型が異なると必要とするパディングも変わることもある
- 倍精度浮動小数点数は 8 バイト境界にアライン
- 例:
create table T (A smallint, B double precision, C smallint, D int, E int)- B は倍精度浮動小数点数なので A は 6 バイトパディングをして B の開始位置を 8 の倍数に合わせる必要がある
- D は整数なので C は 2 バイトパディングして D の開始位置を 4 の倍数に合わせる必要がある
- -> 合計 28 バイト必要
- パディングが最小になるようにフィールドを並び替える方法もある
- ↑の例だと [B, D, A, C, E] の順で格納すればパディングは不要となる
- -> 合計 20 バイト必要
- フィールドだけでなくレコードのパディングもおこなう
- [A, B, C, D, E] の順で格納する場合、2 レコード目の開始位置は 28 バイト目となるが、2 レコード目の B の開始位置が 36 (=28 + 8) バイト目となり、倍精度浮動小数点の 8 バイト境界に違反
- 1 レコードが 28 バイトの場合、レコードとしては 4 バイトのパディングが必要となる
- Java ではバイト配列内の数値に直接アクセスできないので考慮不要
-
ByteBuffer.getIntは整数取得の機械語は使わないので(非効率だが)アライメント問題を回避できる
レコードファイルの実装についての考察
- 設計上の決定が実装にどのような影響を及ぼすかを考える
A Straightforward Implementation
- homogeneous, unspanned, fixed-length なファイルを作る
- unspanned
- ファイルを block のシーケンスとして扱うことができる
- 各 block はそれ自身のレコードを含んでいる
- homogeneous & fixed-length
- block 内の各レコードに同じ量のスペースを割り当てることができる
- 各 block はレコードの配列として扱うことができる
- -> SimpleDB ではこのような block を record page と呼ぶ
- block 内の各レコードに同じ量のスペースを割り当てることができる
- unspanned
- record page の実装
- block を slot に分割
- slot はレコード + 1 バイトを保持
- 上記の 1 バイトは slot が空か使用中かを示すフラグ
- 0: 空, 1: 使用中
- 例: block サイズが 400, レコードサイズが 26 の場合
- 各 slock は 27 バイトで、block には 14 個の slock があり、22 バイトの無駄なスペースがある
- 上記の 1 バイトは slot が空か使用中かを示すフラグ
- record page 内のレコードを insert, delete, modify するにはレコードに関する以下の情報が必要
- slock のサイズ
- レコードの各フィールドの name, type, length, offset
- -> これらを「レイアウト」と呼ぶ
- レイアウトが与えられれば page 内の各値の位置を決定できる
- 新しいレコードを挿入
- slock の空フラグを探して、使用中に変更
- すべてのフラグが使用中であれば挿入は不可能
- slock の空フラグを探して、使用中に変更
- レコードの削除
- フラグを空に変更
- レコードの値の変更
- 対象のフィールドの場所を特定し、その場所に値を書き込む
- レコードの取り出し
- 使用中フラグを探す
- レコードの識別
-
record pageの場合は slot 番号で識別可能
-
- 新しいレコードを挿入
Implementing Variable-Length Fields
- variable-length フィールドを導入
- 問題1: レコード内のフィールドの offset が固定ではなくなる
- 特に variable-length フィールドに続くすべてのフィールドの offset はレコードごとに異なる
- offset を決定するには、前のフィールドを読み、どこで終わるかを確認する必要がある
- 各レコードの先頭に fixed-length フィールド、末尾に variable-length フィールドを配置すると効率よくアクセスできる
- 問題2: フィールドの値を変更するとレコードの長さが変わる
- 新しい値が大きい場合、変更された値の後ろの block の内容をシフトする必要がある
- 極端なケースではシフトされたレコードが block から溢れる
- overflow block を確保することで対処する
- overflow block は複数になることもある
- 問題3: レコードの識別子に slot 番号を使用できない
- そもそも slot 番号が分かっていても variable-length なので
slot サイズ * slot 番号をしても slot の offset は計算できない- 先頭からレコードを読み込む必要あり
- variable-length なのでレコード削除後に slot のスペースが再利用できない状態(断片化)になる可能性があり、デフラグすると slot 番号が変わってしまう
- 解決方法は ID テーブルを使って ID と slot の位置を管理
- block 内の配置
- block の一方の端に ID テーブル、もう一方の端にレコードを置く
- 互いに向かいあって成長
- block の一方の端に ID テーブル、もう一方の端にレコードを置く
- そもそも slot 番号が分かっていても variable-length なので
Implementing Spanned Records
- unspanned なレコードであれば各 block の最初のレコードは同じ位置から始まる
- spanned なレコードでは状況が違う
- 各 block の先頭に整数を格納して、最初のレコードの offset を保持
- spanned レコードの分割方法 2 パターン
- block を可能な限り埋めて block 境界で分割し、残りのバイトをファイルの次の block に配置
- こちらはスペースを無駄にしないが、block 間で値が分割されるので 2 つの block を連携して値を再構築する必要あり
- レコードを値ごとに書き込み、ページが一杯になったら新しいページに書き込む
- block を可能な限り埋めて block 境界で分割し、残りのバイトをファイルの次の block に配置
Implementing Nonhomogeneous Records
- nonhomogeneous レコードをサポートする場合、variable-length レコードもサポートする必要がある
- 異なるテーブルのレコードはサイズも異なる可能性があるため
- 2 つの問題がある
- block 内の各レコードのレイアウトを知る必要がある
- 各レコードがどのテーブル由来のものであるかを知る必要がある
- 上記の 1 つ目の問題はレイアウトの配列を保持することで対処
- 2 つ目の問題は各レコードの先頭に
タグ値と呼ばれる値を追加することで対処- タグ値: レイアウト配列のインデックス
Chapter 6 Record Management: Record Pages 実装
実装対象: Schema, Layout, RecordPage
Schema
-
[fieldname, type, length]の triple のリストを保持 - フィールド追加や取得のメソッドを実装
Layout
- レコードに関する物理的な情報も含む
- フィールド, slot サイズ, フィールド offset を計算
- コンストラクタは 2 つ
- テーブル作成時に利用し、レイアウト情報を計算
- テーブル作成後に呼び出され、以前計算された値を提供
- slot の先頭には
空/使用フラグのための 4 バイトを確保
RecordPage
- ページ内のレコードを管理
- getInt, getString: 指定された slot 番号のレコードのフィールドの値を返す
public int getInt(int slot, String fldname) { int fldpos = offset(slot) + layout.offset(fldname); return tx.getInt(blk, fldpos); } public String getString(int slot, String fldname) { int fldpos = offset(slot) + layout.offset(fldname); return tx.getString(blk, fldpos); }- slot 自体の offset とレコード内でのフィールドの offset を足して block 内での pos を算出して取得
- nextAfter, insertAfter: ページ内の対象のレコードを検索
- nextAfter: 指定された slot に続く最初の空でない slot を探す
- insertAfter: 指定された slot に続く最初の空である slot を探す
- 空の slot が見つかったらフラグを
使用中に変更して slot 番号を返す - 内部で
searchAfterというメソッドを利用
private int searchAfter(int slot, int used) { slot++; while(isValidSlot(slot)) { if (tx.getInt(blk, offset(slot)) == used) { return slot; } slot++; } return -1; }-
isValidSlotは指定された slot が block サイズ内に収まっている場合 true を返す - used: EMPTY=0, USED=1
Chapter 6 Record Management: Table Scans 実装
実装対象: TableScan
TableScan
- テーブルのレコードを管理するクラス
- beforeFirst: 操作対象のレコードをファイルの最初の block の最初のレコードの 1 つ前へ
- (分かりにくい...)
public void beforeFirst() { moveToBlock(0); } private void moveToBlock(int blknum) { close(); BlockId blk = new BlockId(filename, blknum); rp = new RecordPage(tx, blk, layout); currentslot = -1; } - next: 操作対象のレコードを 1 つ後ろにずらす
public boolean next() { currentslot = rp.nextAfter(currentslot); while (currentslot < 0) { if (atLastBlock()) { return false; } moveToBlock(rp.block().number() + 1); currentslot = rp.nextAfter(currentslot); } return true; }- 現在の block にそれ以上レコードがない場合、後続の block を読み込む
- get/set/delete: 操作対象のレコードに対して実施
- TableScan クラスは block 構造をクライアントから隠す
- insert: 現在の slot より後ろの空 slot の位置に移動
public void insert() { currentslot = rp.insertAfter(currentslot); while (currentslot < 0) { if (atLastBlock()) { moveToNewBlock(); } else { moveToBlock(rp.block().number() + 1); } currentslot = rp.insertAfter(currentslot); } }- 同一 block 内に空きがない場合は後続の block の空きを探す
Chapter 7 Metadata Management
レコードのレイアウトなどメタデータも管理する必要がある
The Metadata Manager
- メタデータの種類
- テーブルのレコードの構造
- View のプロパティ
- その定義や作成者など
- Index の記述
- 統計的な情報
- 各テーブルのサイズとそのフィールド値の分布
- クエリオプティマイザがクエリのコストを推定するのに利用
- database が更新される度に生成
Table Metadata
※SimpleDB の TableMgr クラスを説明しているので、一般的な内容ではない
- テーブル生成時にテーブル名とスキーマの情報と、レコードの offset を計算してカタログに保存
- 一般的なカタログの管理方法は database テーブルに格納
- tableCatalog(tablename varchar, slotsize int)
- テーブルごとに 1 レコード
- filedCatalog(tablename varchar, fieldname varchar, type int, length int, offset int)
- 各テーブルのフィールドごとに 1 レコード
- tableCatalog(tablename varchar, slotsize int)
- TableScan を利用してテーブル情報登録 & 読み込み
View Metadata
- View: クエリから動的に計算されるレコードを持つテーブル
- このクエリ = View の定義
- 定義を保存しておき、リクエスト時に定義を取得して処理
- SimpleDB では ViewMgr が定義の管理をおこなう(情報は database テーブルに格納)
- viewCatalog(viewName, viewDef)
- SimpleDB の制約上、viewDef は 100 文字以内
- viewCatalog(viewName, viewDef)
- TableScan を利用してテーブル情報登録 & 読み込み
Statistical Metadata
- 統計情報: database 内の各テーブルのレコード数やフィールド値の分布など
- クエリプランナーがコストを見積もるために使用
- 優れた統計情報を使うとクエリの実行時間を大幅に改善できる
- SimpleDB では 3 種類をピックアップ
- 各テーブルが使用する block 数
- 各テーブルのレコード数
- テーブルの各フィールドについてのカーディナリティ
- 統計情報の管理方法
- database カタログに情報を格納し、database が変更されるたびに情報を更新
- 統計情報を最新に保つためのコストが問題
- insert, delete, setInt, setString の度にテーブルを更新
- 同時実行性が低下
- 統計情報を更新する際に xlock が取られる
- 同一のテーブルに対する更新だけでなく、読み取り(slock取得)も lock 待ち
- 厳密性は求められないので読み取り時に slock を取らない方法もとれる
- 統計情報を最新に保つためのコストが問題
- 情報をメモリに保持し、エンジンの初期化時に計算する
- 統計情報は比較的小さいのでメモリに収まるはず
- 起動時に統計情報をゼロから計算する必要があるのが問題
- 2 つのオプションがある
- database を更新する度に統計情報を更新
- 定期的にゼロから統計情報を再計算
- SimpleDB ではこちらを採用
- database カタログに情報を格納し、database が変更されるたびに情報を更新
StatMgr 実装
- getStatInfo
- 呼び出される度にカウンターをインクリメント
- カウンターが特定の値に達すると統計情報をリフレッシュ
public synchronized StatInfo getStatInfo(String tableName, Layout layout, Transaction tx) { numCalls++; if (numCalls > 100) refreshStatistics(tx); StatInfo si = tableStats.get(tableName); if (si == null) { si = calcTableStats(tableName, layout, tx); tableStats.put(tableName, si); } return si; } - refreshStatistics
- テーブル情報が記録された tableCatalog テーブルをループ
- テーブルごとにテーブルの統計情報を計算
- 簡略化のためフィールド値はカウントしない
private synchronized void refreshStatistics(Transaction tx) { tableStats = new HashMap<>(); numCalls = 0; Layout tableCatalogLayout = tblMgr.getLayout("tableCatalog", tx); TableScan ts = new TableScan(tx, "tableCatalog", tableCatalogLayout); while (ts.next()) { String tableName = ts.getString("tableName"); Layout layout = tblMgr.getLayout(tableName, tx); StatInfo si = calcTableStats(tableName, layout, tx); tableStats.put(tableName, si); } ts.close(); } private synchronized StatInfo calcTableStats(String tableName, Layout layout, Transaction tx) { int numRecs = 0; int numBlocks = 0; TableScan ts = new TableScan(tx, tableName, layout); while (ts.next()) { numRecs++; numBlocks = ts.getRid().blockNumber() + 1; } ts.close(); return new StatInfo(numBlocks, numRecs); }
Index Metadata
- Index metadata の構成
- Index の名前
- Index 対象のテーブル名
- Index 対象のフィールドのリスト
- Index Manager は上記の metadata を保存したり取得したりするコンポーネント
- metadata をカタログテーブルに格納 & 取得
IndexMgr 実装
- コンストラクタ
- システム起動時に呼び出される
- createIndex
- TableScan を用いて Index metadata をカタログテーブルに格納
- getIndexInfo
- TableScan を用いて指定されたテーブルの Index metadata を取得
- Index の対象フィールドに対する IndexInfo クラス(詳細は後述)の Map を返す
IndexInfo 実装
- コンストラクタ
- Index の名前、Index されたフィールド、関連するテーブルのレイアウト、統計 metadata を受け取る
- 統計 metadata によって Index レコードのスキーマを構築 & Index ファイルのサイズを推定
- open
- HashIndex コンストラクタに Index の名前とスキーマを渡して Index を open
- HashIndex については後の章で説明
- blocksAccessed
- Index を検索するために必要なブロックアクセス数の見積もりを返す
- Index のサイズではない、とのこと
public int blocksAccessed() { int rpb = tx.blockSize() / idxLayout.slotSize(); int numBlocks = si.recordsOutput() / rpb; return HashIndex.searchCost(numBlocks, rpb); }-
rpb: おそらく record per block,si: 前節で実装した StatInfo - Index ファイルのブロック数を算出した上で、HashIndex クラスの searchCost メソッドに渡してコストを返す
- コスト: Indexを探索するためのブロックアクセス数
- Index を検索するために必要なブロックアクセス数の見積もりを返す
- recordsOutput
- 検索キーを持つレコードの推定件数を返す
- テーブル内のレコード数を Index 付きフィールドの異なる値の数で割った値
public int recordsOutput() { return si.recordsOutput() / si.distinctValues(fieldName); } - distinctValues
- 指定されたフィールドの個別値を返す
- また、Index 付きフィールドの場合は 1 を返す
Metadata Manager
- これまで見てきた 4 つのマネージャクラスをラップ
- metadata の種類毎に metadata を生成・保存、取得
- 統計 metadata は例外
Chapter 8 Query Processing
- Database エンジンは SQL を関係代数(relational algebra)クエリに変換し、実行
- この章では関係代数のクエリとその実装を紹介
- 次の 2 つの章では SQL から関係代数への変換を扱う
Relational Algebra
- 関係代数は演算子の集合で構成
- 各演算子は 1 つ以上のテーブルを入力 & 1 つ以上の出力テーブルを生成するという特殊なタスクを実行
- これらの演算子を組み合わせることで複雑なクエリを構築
- SimpleDB 版の SQL は 3 つの演算子を用いて実装
- select
- 出力テーブルが入力テーブルと同じカラムを持ち、いくつかの行が削除されたもの
- project
- 出力テーブルが入力テーブルと同じ行を持ち、いくつかの列が削除されたもの
- product
- 出力テーブルが、2 つの入力テーブルのレコードのすべての可能な組み合わせから構成されるもの
- select
Select
- select 演算子
- 入力テーブルと述語の 2 つの引数を取る
- 例:
select(STUDENT, GradYear=2019)
- 出力テーブル
- 述語を満たす入力レコードで構成される
- 常に入力テーブルと同じスキーマを持つ
- select クエリ
- レコードのサブセットを持つテーブルを返す
- 例
- クエリ Q1:
select(STUDENT, GradYear=2019)- 2019 年に卒業した生徒を見つける
- クエリ Q2:
select(STUDENT, GradYear=2019 and (MajorId=10 or MajorId = 20))- 述語は、任意の真偽値の組み合わせが可能( SQL の where 句に相当)
- 2019 年に卒業し、専攻が学科10または20のどちらかの生徒を見つける
- クエリ Q3:
select(select(STUDENT, GradYear=2019), MajorId=10 or MajorId=20)- あるクエリの出力テーブルを別のクエリの入力にすることができる
- Query2 と同等の結果となる
- クエリ Q4:
select(Q1, MajorId=10 or MajorId=20)- Q3 の一部を Q1 を使用して表現したパターン
- クエリ Q1:
- 関係代数のクエリはクエリツリーとして絵として表現できる
- テーブルはリーフノード、演算子は内部ノード
Project
- project 演算子
- 入力テーブルとフィールド名のセットという 2 つの引数を取る
- 例:
project(STUDENT, {SName, GradYear})
- 出力テーブル
- 入力テーブルと同じレコードを持つが、スキーマには指定されたフィールドのみが含まれる
- 重複したレコードが含まれることがある
- project クエリ
- project 演算子と select 演算子の両方で構成できる
- 例
- クエリ Q5:
project(STUDENT, {SName, GradYear})- すべての学生の名前と卒業年を返す
- クエリ Q6:
project(select(STUDENT, MajorId=10), {SName})- select 演算子も利用したパターン
- 学科10 を先行しているすべての学生の名前をリストしたテーブルを返す
- クエリ Q5:
Product
- product 演算子
- 複数のテーブルから情報を組み合わせて比較できる
- 例:
product(STUDENT, DEPT)
- 出力テーブル
- 入力テーブルのレコードのすべての組み合わせ
- スキーマは入力スキーマのフィールドの和集合
- 同じ名前の2つのフィールドを持たないよう、入力テーブルのフィールド名はバラバラである必要あり
- 例
- クエリ Q8:
product(STUDENT, DEPT)- STUDENTに N レコード、DEPT に M レコードある場合、出力テーブルには NM レコードが含まれる
- クエリ Q9:
select(product(STUDENT, DEPT), MajorId=Did)- DEPT テーブルの id で絞り込み
- クエリ Q8:
Scans
- Scan: 関係代数クエリの出力を表す
- 以下は、SimpleDB における話
- Scan は TableScan のサブセット
- クエリ、テーブルどちらも表せる
- Scan オブジェクトはクエリツリーのノードに対応
- リレーショナル演算子ごとに Scan クラスがある
- SelectScan, ProjectScan, ProductScan
- ツリーのリーフは TableScan となる
- リレーショナル演算子ごとに Scan クラスがある
Update Scans
- クエリは仮想テーブルを定義
- Scan は仮想テーブルからの読み取りはできるるが、更新はできないメソッドを持つ
- すべての Scan が意味のある更新を行えるわけではない
- Scan が更新可能な場合は?
- 出力レコードのすべてが、基礎となる database テーブルに対応するレコードをもつ場合
- 更新可能 Scan の場合、UpdateScan インターフェースをサポート
- 5 つの変更操作のメソッド
- SimpleDB では TableScan と SelectScan が UpdateScan インターフェースを実装
Scan の実装
Scan (インターフェース)
- 各 Scan クラスが実装するインターフェース
- レコードを読み取るメソッドを定義
- beforeFirst, next, getInt, getString, hasField, close
UpdateScan (インターフェース)
- SelectScan など更新可能な Scan が実装するインターフェース
- Scan インターフェースを拡張して、レコードを更新するメソッドを定義
- setInt, setString, insert, delete, getRid, moveToRid
- レコードを読み取るメソッドを定義
- beforeFirst, next, getInt, getString, hasField, close
SelectScan
- UpdateScan インターフェースを実装
- constructor
- 基礎となる Scan と Predicate (述語) を受け取る
public SelectScan(Scan s, Predicate pred) { this.s = s; this.pred = pred; } - beforeFirst, getInt, getString, hasField
- 基礎となる Scan の対応するメソッドを呼び出すのみ
- next
- Predicate が満足するレコードを探す
public boolean next() { while (s.next()) if (pred.isSatisfied(s)) return true; return false;} - setInt (setString, insert, delete, getRid, moveToRid も同様)
- 基礎となる Scan を UpdateScan にキャストした上で、対応するメソッドを呼び出す
public void setInt(String fieldName, int val) { UpdateScan us = (UpdateScan) s; us.setInt(fieldName, val); }- ClassCastException は起きないようにプランナーが Scan のツリーを作成することを前提とする
ProjectScan
- Scan インターフェースを実装
- projection は更新可能であるにも関わらず、実装する ProjectScan は UpdateScan を実装しない
- Exercise で実装を完成させる
- constructor
- 基礎となる Scan と出力フィールドのリストを受け取る
public ProjectScan(Scan s, List<String> fieldList) { this.s = s; this.fieldList = fieldList; } - beforeFirst, next, getInt, getString,
- 基礎となる Scan の対応するメソッドを呼び出すのみ
- hasField
- 出力フィールドのリストに含まれるフィールドかどうかを判定
public boolean hasField(String fieldName) { return fieldList.contains(fieldName); }
ProductScan
- Scan インターフェースを実装
- コンストラクタで受け取る 2 つの Scan について多重にループしつつ結果を返す
- constructor
- 基礎となる Scan s1, s2 を受け取り、beforeFirst を呼び出し
public ProductScan(Scan s1, Scan s2) { this.s1 = s1; this.s2 = s2; beforeFirst(); } - beforeFirst
- s1 の 1 件目、s2 の 0 件目のレコードに index をセット
public void beforeFirst() { s1.beforeFirst(); s1.next(); s2.beforeFirst(); } - next
- s2 のレコードが尽きたら s1 のレコードを進めて s2 を先頭レコードに戻す
if (s2.next()) return true; s2.beforeFirst(); return s2.next() && s1.next(); - getInt, getString
- 対象のフィールドを持っている Scan を確認して返す
public int getInt(String fieldName) { if (s1.hasField(fieldName)) return s1.getInt(fieldName); return s2.getInt(fieldName); } - hasField
- s1, s2 の hasField を用いて結果を返す
public boolean hasField(String fieldName) { return s1.hasField(fieldName) || s2.hasField(fieldName); } - close
- s1, s2 両方の close を呼び出す
Pipelined Query Processing
- 前項の 3 つの関係代数演算子の実装には 2 つの共通点がある
- 出力レコードは必要に応じて一度に 1 つずつ生成される
- 出力レコードを保存せず、また中間の計算も保存しない
- これらの実装はパイプライン型と呼ばれる
- パイプライン化された実装は効率的
- Project, Select の場合
- 対象のテーブルのスキャンは 1 回だけ
- Product の場合
- 対象のテーブルのスキャンが複数回実行されうるため、出力レコードを一時テーブルに格納する実装などもある(後述されるとのこと)
- Project, Select の場合
Predicates(述語)
- 与えられた Scan の各行に対して、真か偽かを返す条件
- Predicate の構造
- Predicate は Term(項)や Term の boolean 結合
- Term は 2 つの Expression(式)の間の比較
- Expression は Constans(定数)とフィールド名に対する操作で構成
- Constans は整数や文字列などあらかじめ決められた型の値
- SimpleDB では許容する表現を単純化
Constant の実装
public class Constant implements Comparable<Constant> {
private Integer iVal = null;
private String sVal = null;
public Constant(Integer iVal) {
this.iVal = iVal;
}
public Constant(String sVal) {
this.sVal = sVal;
}
// equals, hashCode, compareTo, toString などを実装
}
- Interger か String を持つ
Expression の実装
public class Expression {
private Constant val = null;
private String fieldName = null;
public Expression(Constant val) {
this.val = val;
}
public Expression(String fieldName ) {
this.fieldName = fieldName;
}
}
- 定数かフィールド名を持つ
- evalute
- スキャンの現在の出力レコードに関する式の値を返す
public Constant evaluate(Scan s) { return (val != null) ? val : s.getVal(fieldName); }- 式が定数の場合は Scan は無視
- 式がフィールドである場合 Scan からフィールドの値を返す
- appliesTo
- 式のスコープを決定するために利用
public boolean appliesTo(Schema sch) { return val != null || sch.hasField(fieldName); }
Term の実装
- constructor
- 左辺の式と右辺の式を受け取る
public Term(Expression lhs, Expression rhs) { this.lhs = lhs; this.rhs = rhs; } - isSatisfied
- 与えられた Scan で左辺の式と右辺の式が同じ値に評価された場合に true を返す
public boolean isSatisfied(Scan s) { Constant lhsVal = lhs.evaluate(s); Constant rhsVal = rhs.evaluate(s); return rhsVal.equals(lhsVal); } - 残りのメソッドは query planner 向けのもの
- reductionFactor
- 述語を満たすレコードの予想数を決定
- 後述
- 述語を満たすレコードの予想数を決定
- equatesWithConstant, equatesWithField
- query planner がいつ index を使用するかを決定するのを助ける
- 後述
- query planner がいつ index を使用するかを決定するのを助ける
- reductionFactor
Predicate の実装
- Term のリストを保持
- 各 Term の対応するメソッドを呼び出す
public boolean isSatisfied(Scan s) { for (Term t : terms) if (!t.isSatisfied(s)) return false; return true; } public int reductionFactor(Plan p) { int factor = 1; for (Term t : terms) { factor *= t.reductionFactor(p); } return factor; } // ...
Chapter 9 Parsing
- パーザは言語の構文解析器
- metadata については何も知らないので SQL の意味を評価することはできない
- metadata を調べる責任は planner
- 後述
- metadata を調べる責任は planner
Lexical Analysis
- 入力文字列をトークンに分割
- トークンには型と値がある
- SimpleDB の lexical analyzer は 5 つのトークンタイプをサポート
- カンマなどの1文字の区切り文字
- 整数定数
- 文字列定数
- キーワード(select, from, where, ...)
- 識別子(テーブル名, フィールド名, ...)
Lexer 実装
-
java.io.StreamTokenizerを利用 - delimiter, int, String, keyword, id などを判定したり eat(consume)して返すメソッドを実装
- 一部抜粋
public boolean matchDelim(char d) { return d == (char)tok.ttype; } public void eatDelim(char d) { if (!matchDelim(d)) throw new BadSyntaxException(); nextToken(); } public boolean matchKeyword(String w) { return tok.ttype == StreamTokenizer.TT_WORD && tok.sval.equals(w); } public void eatKeyword(String w) { if (!matchKeyword(w)) throw new BadSyntaxException(); nextToken(); } public boolean matchId() { return tok.ttype == StreamTokenizer.TT_WORD && !keywords.contains(tok.sval); } public String eatId() { if (!matchId()) throw new BadSyntaxException(); String s = tok.sval; nextToken(); return s; } // ... private void initKeywords() { keywords = Arrays.asList( "select", "from", "where", "and", "insert", "into", "values", "delete", "update", "set", "create", "table", "int", "varchar", "view", "as", "index", "on" ); }-
keywordsリストはidに指定された文字が keyword ではないことを確認することにしか使ってないが、matchKeywordでも使った方が良い気がする
Grammer
- トークンをどのように組み合わせることができるかを記述したルールセット
- 文法規則の例
<Field> := IdTok- 左辺は構文カテゴリ:
<Field>はフィールド名という概念を表す - 右辺は構文カテゴリに属する文字列の集合を指定するパターン
- SimpleDB がサポートする文法規則
<Field> := IdTok<Constant> := StrTok | IntTok<Expression> := <Field> | <Constant><Term> := <Expression> = <Expression><Predicate> := <Term> [ AND <Predicate> ]<Query> := SELECT <SelectList> FROM <TableList> [ WHERE <Predicate> ]<SelectList> := <Field> [ , <SelectList> ]<TableList> := IdTok [ , <TableList> ]<UpdateCmd> := <Insert> | <Delete> | <Modify> | <Create><Create> := <CreateTable> | <CreateView> | <CreateIndex><Insert> := INSERT INTO IdTok ( <FieldList> ) VALUES ( <ConstList> )<FieldList> := <Field> [ , <FieldList> ]<ConstList> := <Constant> [ , <ConstList> ]<Delete> := DELETE FROM IdTok [ WHERE <Predicate> ]<Modify> := UPDATE IdTok SET <Field> = <Expression> [ WHERE <Predicate> ]<CreateTable> := CREATE TABLE IdTok ( <FieldDefs> )<FieldDefs> := <FieldDef> [ , <FieldDefs> ]<FieldDef>:= IdTok <TypeDef><TypeDef> := INT | VARCHAR ( IntTok )<CreateView> := CREATE VIEW IdTok AS <Query><CreateIndex> := CREATE INDEX IdTok ON IdTok ( <Field> )
Recursive-Descent Parsers
- SimpleDB の SQL の文法は単純で再帰下降構文解析で解析できる
- 基本的なパーザは解析のみ
- query planner が必要とする情報を返すように変更する必要がある
-
adding actions to the parser
-
- query planner が必要とする情報を返すように変更する必要がある
- SQL パーザは SQL 文から情報を抽出する
- テーブル名、フィールド名、述語、定数など
Parsing Predicate
- SimpleDB がサポートするPredicate の文法に従ってパーズ
- expression までの処理の抜粋
public Expression expression() { if (lex.matchId()) return new Expression(field()); else return new Expression(constant()); } public Term term() { Expression lhs = expression(); lex.eatDelim('='); Expression rhs = expression(); return new Term(lhs, rhs); } public Predicate predicate() { Predicate pred = new Predicate(term()); if (lex.matchKeyword("and")) { lex.eatKeyword("and"); pred.conjoinWith(predicate()); } return pred; }
Parsing Queries
- SimpleDB がサポートする Query の文法に従ってパーズ
public QueryData query() {
lex.eatKeyword("select");
List<String> fields = selectList();
lex.eatKeyword("from");
Collection<String> tables = tableList();
Predicate pred = new Predicate();
if (lex.matchKeyword("where")) {
lex.eatKeyword("where");
pred = predicate();
}
return new QueryData(fields, tables, pred);
}
Parsing Updates
- SimpleDB がサポートする UpdateCmd の文法に従ってパーズ
- 文字列の最初のトークンをもとに各パーズ処理にディスパッチ
public Object updateCmd() {
if (lex.matchKeyword("insert"))
return insert();
else if (lex.matchKeyword("delete"))
return delete();
else if (lex.matchKeyword("update"))
return modify();
else
return create();
}
private InsertData insert() {
lex.eatKeyword("insert");
lex.eatKeyword("into");
String tblName = lex.eatId();
lex.eatDelim('(');
List<String> fields = fieldList();
lex.eatDelim(')');
lex.eatKeyword("values");
lex.eatDelim('(');
List<Constant> vals = constList();
lex.eatDelim(')');
return new InsertData(tblName, fields, vals);
}
// ... delete, update
private Object create() {
lex.eatKeyword("create");
if (lex.matchKeyword("table"))
return createTable();
else if (lex.matchKeyword("view"))
return createView();
else
return createIndex();
}
private CreateTableData createTable() {
lex.eatKeyword("table");
String tblName = lex.eatId();
lex.eatDelim('(');
Schema sch = fieldDefs();
lex.eatDelim(')');
return new CreateTableData(tblName, sch);
}
// .. createView, createIndex
Chapter 10 Planning
- パーズの次のステップは、抽出したデータを関係代数クエリツリーに変換すること
- このステップを計画と呼ぶ
- 等価なクエリツリーは複数あるがコストが異なる
- この章では基本的な計画作成プロセスについて検討
- 15 章で最適な計画を作成するトピックを扱う
Verification
- planner の最初の責務は、SQL 文が意味があるかの判断
- 以下を確認
- 言及されたテーブルとフィールドがカタログに存在
- 言及されたフィールドは曖昧ではない
- フィールドに対するアクションは正しい型である
- すべての定数は、そのフィールドに対して正しいサイズと型である
- SmpleDB の planner は上記の検証はしていない
- Exercise 対象
The Cost of Evaluating a Query Tree
- planner の第2の責務は、関係代数クエリツリーを構築すること
- クエリの実行時間に対する重要な寄与はブロックアクセス数
- 各関係演算子はそれぞれの独自のコスト算出式を持っている
| s | B(s) | R(s) | V(s, F) |
|---|---|---|---|
| TableScan(T) | B(T) | R(T) | V(T, F) |
| SelectScan(s1, A=c) | B(s1) | R(s1)/V(s1, A) | 1 if F = A V(s1, F) if F ≠ A |
| SelectScan(s1, A=B) | B(s1) | R(s1)/max{V(s1, A), V(s1, B)} | min{V(s1, A), V(s1, B)} if F = A,B V(s1, F) if F ≠ A,B |
| ProjectScan(s1, L) | B(s1) | R(s1) | V(s1, F) |
| ProductScan(s1, s2) | B(s1) + R(s1)*B(s2) | R(s1)*R(s2) | V(s1, F) if F is in s1 V(s2, F) if F in s2 |
- B(s): Scan の出力を構成するのに必要なブロックアクセス数
- R(s): Scan の出力に含まれるレコード数
- V(s, F): Scan に出力に含まれる異なる F の値(F-values)の個数
- F の値とは?
- F値 (曖昧さ回避): wikipediaの中の「F検定」...?後で調べる
- 単に
Fというフィールドの値という意味っぽい
- F の値とは?
- planner はそれぞれの値をどのように計算するか?
- product の場合、
B(s)の値は 2 つのテーブルのブロック数とその左側の Scan のレコード数に依存 - select の場合、
R(s)は Predicate で言及されたフィールドの異なる値の数に依存
- product の場合、
Table Scan のコスト
- B(s), R(s), V(s, F) の値は基礎となるテーブルのブロック数、レコード数、個別の値となる
Select Scan のコスト
- B(s) は 基礎となる Scan(s1) と全く同じ数のブロックアクセスが必要なので B(s1) と同様
- R(s), V(s, F) の計算は Predicate に依存
- 定数に対する選択: SelectScan(s1, A=c)
- A の値が等しく分布していると仮定するとマッチするのは R(s1)/V(s1, A) のレコード
- 均等に分布する仮定は、出力において他のフィールドの値も均等に分布していることを意味する
- V(s, A) = 1
- A は定数マッチしているもののみ
- V(s, F) = V(s1, F)
- A のフィールドでマッチさせても分布は変わらない
- V(s, A) = 1
- フィールドに対する選択: SelectScan(s1, A=B)
- このケースでは A と B は何らかの関係があると考えられる
- R(s) = R(s1) / max{V(s1, A), V(s1, B)} となる理由
- もし B の値が A の値よりも多い場合、すべての A の値は B 内にあると仮定する
- もし A の値が B の値よりも多い場合、すべての B の値は A 内にあると仮定する
- (上記の仮定は A と B がキーと外部キーの関係の場合は確実に成り立つ)
- s1 のレコードを考える
- B の値が A の値より多いと仮定すると
- A の値が B の値と一致する確率は 1/V(s1, B)
- A の値が B の値より多いと仮定すると
- B の値が A の値と一致する確率は 1/V(s1, A)
- B の値が A の値より多いと仮定すると
- 上記の確率の大きな方で R(s1) を割ると R(s) となる
- V(s, F) の値は等分布を仮定すると
- min(V(s1, A), V(s1, B)} for F = A or B
- それはそう
- V(s1, F) for all fields F other than A or B
- こちらも等分布なので絞り込んで変わらない
- min(V(s1, A), V(s1, B)} for F = A or B
- 定数に対する選択: SelectScan(s1, A=c)
Project Scan のコスト
- B(s) = B(s1), R(s) = R(s1), V(s, F) = V(s1, F) for all fields F
- 基礎となる Scan(s1) で必要とされる以上の追加のブロックアクセスは必要ではない
- project 操作はレコードの数、値を変更しない
Product Scan のコスト
- 基礎となる Scan は s1, s2 の2つで出力はそれらのすべての組み合わせ
- B(s) = B(s1) + (R(s1) * B(s2))
- ProductScan(s1, s2) と ProductScan(s2, s1) のブロックアクセス数は異なることがある
- 論理的にはどちらも一緒なので、上記の式で算出したブロックアクセス数が少ない方を利用した方がコストが低い
- R(s) = R(s1) * R(s2), V(s, F) = V(s1, F) or V(s2, F), depending on which schema F belongs to
- これらは自明
Plan の実装
Plan インターフェース
public interface Plan {
// Plant に対応する Scan を開く
public Scan open();
// ブロックアクセス数
public int blockAccessed();
// レコード数
public int recordsOutput();
// 値の数
public int distinctValues(String fieldName);
public Schema schema();
}
TablePlan
- 基礎となるテーブルスキャンのプラン
- constructor
public TablePlan(Transaction tx, String tblName, MetadataMgr md) { this.tblName = tblName; this.tx = tx; layout = md.getLayout(tblName, tx); si = md.getStatInfo(tblName, layout, tx); }- metadata マネージャーを受け取って、レイアウトや統計情報を取得して保持
- blockAccessed, recordOutput, distinctValues
- 統計情報
siの対応するメソッドを呼び出して返す
- 統計情報
SelectPlan
- constructor
public SelectPlan(Plan p, Predicate pred) { this.p = p; this.pred = pred; }- 基礎となる Plan と Predicate を受け取る
- blockAccessed
public int blockAccessed() { return p.blockAccessed(); }- 基礎となる Plan と同じ値
- recordsOutput
public int recordsOutput() { return p.recordsOutput() / pred.reductionFactor(p); }- 基礎となる Plan を Predicate で絞り込む
- distinctValues
public int distinctValues(String fieldName) { if (pred.equatesWithConstant(fieldName) != null) return 1; else { String fieldName2 = pred.equatesWithField(fieldName); if (fieldName2 != null) return Math.min( p.distinctValues(fieldName), p.distinctValues(fieldName2) ); else return p.distinctValues(fieldName); } }- 定数によって選択される場合: 1
- 他のフィールドによって選択される場合: 2 つのフィールドのうち値が少ない方の数
- それ以外の場合は基礎となる Plan と同じ値
ProjectPlan
- blockAccessed, recordOutput, distinctValues
- 基礎となる Plan の対応するメソッドを呼び出して返す
ProductPlan
- constructor
public ProductPlan(Plan p1, Plan p2) { this.p1 = p1; this.p2 = p2; schema.addAll(p1.schema()); schema.addAll(p2.schema()); }- 基礎となる 2 つの Plan を受け取る
- blockAccessed
public int blockAccessed() { return p1.blockAccessed() + p1.recordsOutput() * p2.blockAccessed(); }- 前節で検討した通り、基礎となる Plan のブロックアクセス数、レコード数を用いて算出
- recordsOutput
public int recordsOutput() { return p1.recordsOutput() * p2.recordsOutput(); }- 前節で検討した通り、基礎となる Plan のレコード数を用いて算出
- distinctValues
public int distinctValues(String fieldName) { if (p1.schema().hasField(fieldName)) return p1.distinctValues(fieldName); else return p2.distinctValues(fieldName); }- 対象のフィールドを保持する Plan に基づいて返す
Query Planning
- SimpleDB は単純化された SQL のサブセットのみをサポート
- 計算、ソート、グループ化、入れ子、名前の変更を含まない
- select, project, product の 3 つの演算子のみを使用したクエリツリーで実装
- アルゴリズム
- from 句にある各テーブルに対する Plan を構築
- T がテーブルである場合、T に対する Plan
- T が View である場合、Plan は T の定義に対してこのアルゴリズムを再帰的に呼び出した結果
- これらの Plan の product を与えられた順で取る
- where 句にある述語で select する
- select 句のフィールドに project する
- from 句にある各テーブルに対する Plan を構築
BasicQueryPlanner 実装
public Plan createPlan(QueryData data, Transaction tx) {
// Step 1: Create a plan for each mentioned table or view.
List<Plan> plans = new ArrayList<>();
for (String tblName : data.tables()) {
String viewDef = mdm.getViewDef(tblName, tx);
if (viewDef != null) { // Recursively plan the view.
Parser parser = new Parser(viewDef);
QueryData viewData = parser.query();
plans.add(createPlan(viewData, tx));
} else {
plans.add(new TablePlan(tx, tblName, mdm));
}
}
// Step 2: Create the product of all table plans
Plan p = plans.remove(0);
for (Plan nextPlan : plans)
p = new ProductPlan(p, nextPlan);
// Step 3: Add a selection plan for the predicate
p = new SelectPlan(p, data.pred());
// Step 4: Project on the field names
p = new ProjectPlan(p, data.fields());
return p;
}
- 基本的なクエリプランの作成
- QueryData.tables によって返される順序で ProductPlan を作成
- metadata は利用しないので、性能は不安定
- ProductPlan 作成の小さな改良版
// Step 2: Create the product of all table plans Plan p = plans.remove(0); for (Plan nextPlan : plans) { // Try both orderings and choose the one having the lowest cost Plan choice1 = new ProductPlan(nextPlan, p); Plan choice2 = new ProductPlan(p, nextPlan); if (choice1.blockAccessed() < choice2.blockAccessed()) p = choice1; elsep = choice2; }- まだクエリ内のテーブルの順番に依存
- 商用 DB はより洗練したアルゴリズムを使用
- 最適な Plan の選択は後述
BasicUpdatePlanner 実装
- executeDelete, executeModify
- SelectPlan を用いて対象のレコードを特定した上で操作を行う
public int executeDelete(DeleteData data, Transaction tx) { Plan p = new TablePlan(tx, data.tableName(), mdm); p = new SelectPlan(p, data.pred()); UpdateScan us = (UpdateScan) p.open(); int count = 0; while (us.next()) { us.delete(); count++; } us.close(); return count; } - executeInsert
- TablePlan を用いて insert 操作を行う
public int executeInsert(InsertData data, Transaction tx) { Plan p = new TablePlan(tx, data.tableName(), mdm); UpdateScan us = (UpdateScan) p.open(); us.insert(); Iterator<Constant> iter = data.vals().iterator(); for (String fieldName : data.fields()) { Constant val = iter.next(); us.setVal(fieldName, val); } us.close(); return 1; } - executeCreateTable, executeCreateView, executeCreateIndex
- metadata manager の対応するメソッドを呼ぶのみ
public int executeCreateTable(CreateTableData data, Transaction tx) { mdm.createTable(data.tableName(), data.newSchema(), tx); return 0; }
Planner
- SQL 文を Plan に変換するコンポーネント
- Parser を用いて SQL 文を QueryData や ModifyData(, DeleteData, ...) に変換
- QueryPlanner , UpdatePlanner に処理を委譲
- createQueryPlan
- Plan を作成して返す
- executeUpdate
- Plan を作成して実行して影響を受けたレコード数を返す
- 使用感
public static void main(String[] args) { SimpleDB db = new SimpleDB("dbdir/plannertest1"); Transaction tx = db.newTx(); Planner planner = db.planner(); String cmd = "create table T1(A int, B varchar(9))"; planner.executeUpdate(cmd, tx); int n = 200; System.out.println("Inserting " + n + " random records into T1."); for (int i = 0; i < n; i++) { int a = (int) Math.round(Math.random() * 50); String b = "bbb" + a + "(idx=" + i + ")"; cmd = "insert into T1(A, B) values(" + a + ", '" + b + "')"; planner.executeUpdate(cmd, tx); } cmd = "create table T2(C int, D varchar(9))"; planner.executeUpdate(cmd, tx); System.out.println("Inserting " + n + " records into T2."); for (int i = 0; i < n; i++) { int c = n - i -1; String d = "ddd" + c + "(idx=" + i + ")"; cmd = "insert into T2(C,D) values(" + c + ", '" + d + "')"; planner.executeUpdate(cmd, tx); } String query = "select B,D from T1,T2 where A=C"; Plan p = planner.createQueryPlan(query, tx); Scan s = p.open(); while (s.next()) System.out.println(s.getString("b") + " " + s.getString("d")); s.close(); tx.commit(); }- create table, insert, select などの SQL 文を実行できるようになっている
- 2 テーブルのフィールド値の一致条件も使えている
- create table, insert, select などの SQL 文を実行できるようになっている
Chapter 11 JDBC Interfaces
後回し
Chapter 12 Indexing
- static hashing, extendable hashing, B-trees について取り上げる
- index を利用した関係代数演算も開発
Index の価値
- 絞り込み対象のフィールドの値でソートされていれば、バイナリサーチでレコードを特定できる
- テーブルは複数の index を持てる
- index は役に立たないこともある
- フィールド A に対する index の有用性は、テーブル内の異なる A の値の数に比例
- index されたフィールドがテーブルの PrimaryKey である場合、最も有用
- 異なる A の値の数がブロックごとのレコード数より少ない場合、役に立たない
SimpleDB の index
- Index インターフェースにおける宣言メソッドは TableScan のメソッドと似ている
- well-known な特定の方法で使用されるため、より明確
- index を検索する際は常に値(検索キー)を指定
- すべての index レコードは同じ 2 つのフィールドを持つので、汎用の値の Getter が不要になる
- well-known な特定の方法で使用されるため、より明確
Static Hash Indexes
- 最もシンプルな index の実装
- 最も効率的とは言えないが理解しやすく、原理も明確
- 0 から N-1 までの固定数 N のバケットを使用
- 各 index レコードは dataVal を hash 化した結果のバケットに割り当てられる
- index レコードの格納するには
- hash 関数によって割り当てられたバケットに入れる
- index レコードを見つけるには
- 検索キーを hash 化して対応するバケットを調べる
- index レコードを削除するには
- index レコードを見つけてからバケットから削除する
- index レコードの格納するには
- hash index の検索コスト
- バケットの数に反比例
- index が B ブロックを含む & バケットが N 個ある場合
- バケットを検索するには B/N ブロックアクセスが必要
- 例: ブロックサイズが 4k バイト, バケット数が 1024, dataVal が varchar(10) の場合
- index レコードは 23 バイト(dataVal + dataRid + 空/使用フラグ )
- ブロックには 178 の index レコードが収まる
- -> 2 回のブロックアクセスを想定すると 364,544 レコード(=178 * 1024 * 2)を検索できる
Static Hash Indexes 実装
- 各バケットを別々のテーブルに格納
- 名称: index 名 + バケット番号
- beforeFirst
- 検索キーを hash 化し、バケットに対する TableScan を開く
public void beforeFirst(Constant searchKey) { close(); this.searchKey = searchKey; int bucket = searchKey.hashCode() % NUM_BUCKETS; String tblName = idxName + bucket; this.ts = new TableScan(tx, tblName, layout); } - next
- TableScan の現在の位置から開始し、検索キーを持つレコードが見つかるまで読み進める
public boolean next() { while (ts.next()) if (ts.getVal("dataVal").equals(searchKey)) return true; return false; } - searchCost
- IndexInfo.blocksAccessed によって呼び出される
public static int searchCost(int numBlocks, int rpb) { return numBlocks / HashIndex.NUM_BUCKETS; }- 第二引数はブロックごとに index レコード数だが、HashIndex では使われない
Extendable Hash Indexes
- Static Hash Index の検索コストはバケットの数に反比例
- バケットを多く使えば使うほど各バケットのブロック数は少なくなる
- 最も望ましいのは各バケットがちょうど 1 ブロックの長さになること
- 将来の必要性に基づいてバケットを多く用意すると、初期は無駄なスペースとなる
- Extendable hashing(拡張可能ハッシュ)は上記の問題を解決
- 各バケットが 1 ブロックより長くならないことを保証
- 複数のバケットが同じブロックを共有できるようにすることで、無駄なスペースを無くす
- 2 つのファイルによって実現
- バケットファイル
- index ブロックが格納されている
- バケットディレクトリ
- バケットとブロックの対応付けを行う
- 整数の配列と考えることができる
- 検索キーの hash 値とバケットファイル(の番号)のマッピング情報を保持
- index レコードが少ないうちは、異なる hash 値(hash 化 & mod 計算結果) を同一のブロックに割り当てることができる
- (レコードが溢れた場合は再配置が必要になりそう)
- バケットファイル
- バケットファイルの特定方法
- 検索キーを hash 化
- 例: hash 値=12
- 上記の値をバケットディレクトリ(整数配列)の長さで mod 計算
- 例: バケットディレクトリの長さが 8 の場合は 4
- 上記の値を バケットディレクトリの index として値を取得
- 例: バケットディレクトリの index=4 の値が 1
- 上記の値が対応するバケット
- 例: バケットファイルの番号は 1
- 検索キーを hash 化
- 複数のバケットでブロックを共有するためのパケットディレクトリの設定方法はたくさんあるので後述
Sharing Index Blocks
-
2^M - M: 整数 & index の最大深度と呼ばれる
- 整数値は 32 ビットなので M=32 が妥当
-
初期状態はすべてのディレクトリエントリは 1 つのブロックを指す
- 新しい index レコードはすべてのこのブロックに挿入
-
バケットファイル内のすべてのブロックはローカル深度を持つ
- ローカル深度L とは
- ブロック内のすべてのレコードの hash 値が同じ右端の L ビットを持つことを意味する
- ファイルの最初のブロックは任意の hash 値を持つことができるので L = 0 となる
- ローカル深度L とは
-
ある index レコードが割り当てられたブロックに収まらない場合
- ブロックは分割されレコードは分配される
- 再分配のアルゴリズムはブロックのローカル深度に基づく
- ブロック内のすべてのレコードは右端の L ビットが同じ
- L+1 ビットが 0 ならばもとのブロック、1 ならば新しいブロックに移動
- -> ブロックのローカル深度は 1 増加
- 再分配のアルゴリズムはブロックのローカル深度に基づく
- 分配後、バケットディレクトリを調整する
- もとのブロックを指すディレクトリエントリを特定
- 右端から L+1 ビットが1であるものは追加されたブロックを指すように変更
- ブロックは分割されレコードは分配される
-
分割の例:

-
どのような hash 法でもレコードが均等に分散される保証はない
- ブロックが分割される時、該当のブロックが含むレコードは同じブロックに割り当たるかもしれない
- ローカル深度が最大深度に達するとそれ以上の分割は不可能
- オーバーフローブロックを作成する必要がある
Compacting the Bucket Directory
- バケットディレクトリも必要に応じて拡張できる
- ↑の図のバケットディレクトリのエントリーは特定のパターンになっている
- あるブロックのローカル深度が0であれば、すべてのバケットエントリーはそのブロックを指す
- あるブロックのローカル深度が2であれば、バケットは4つごとにそのブロックを指す
- 一般的に、あるブロックのローカル深度が L であれば
2^L - ローカル深度が最も深いものがディレクトリの周期を決定
- ディレクトリのエントリーが繰り返される=ディレクトリ全体を保存する必要はない
- 最も深いローカル深度 d に対して
2^d - d: インデックスのグローバル深度、という
- 最も深いローカル深度 d に対して
- インデックスを検索するアルゴリズムの修正点
- 検索キーをハッシュ化後に右端 d ビットを利用してバケットを特定
- 挿入時、ブロックの分割によってローカル深度がグローバル深度よりも大きくなる場合はグローバル深度をインクリメント
- バケットディレクトのサイズが2倍になる
- エントリは繰り返されるため、前半の情報を後半にコピーするので OK
- バケットディレクトのサイズが2倍になる
- 参考
Chapter 12 Indexing: B-Tree Indexes
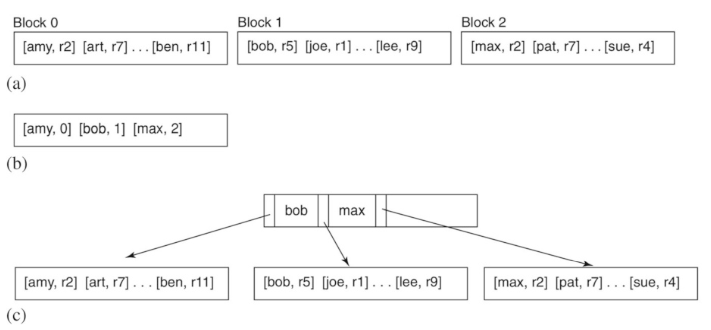
- 図の説明
- (a)ソート済の index のファイル
- (b) index ファイルのレベル 0 のディレクトリ
- ディレクトリ内のレコードを dataVal (amy, bob, max など) 順に並べると隣接するディレクトリのエントリを比較してブロックの値の範囲を決定できる
- (c) ディレクトリと index ブロックをツリーとして表現したもの
- B-tree が大きく成長した際に対処する必要がある 3 つの問題
- ディレクトリが数ブロックになる可能性がある
- 新しく挿入された index レコードはブロックに収まらないかもしれない
- 同じ dataVal を持つ index レコードが複数存在する可能性がある
A Directory Tree
- 図の説明
- ディレクトリブロックは 2 つのレベルに分かれている
- Level 0: index ブロックを指し示すブロックが含まれる
- Level 1: Level 0 のブロックを指し示すブロックが含まれる
- ディレクトリレコードにおける名前の分布の注意
- "eli" は Level1 には現れるが Level 0 には現れない
- 各 index ブロックの dataVal は B-tree のあるレベルのディレクトリブロックに一度だけ現れる
- 検索コストはディレクトリのレベルの数に 1 を加えたものとなる
- 例
- 4K バイトのブロック
- 22 バイトのインデックスレコードだと 178 個収まる
- 18 バイトのディレクトリレコードだと 227 個収まる
- Level 0 の B-tree は 2 回のブロックアクセスで 40,406 index レコードにアクセスできる
- 227 * 178
- Level 1 の B-tree は 3 回のブロックアクセスで 9,172,162 index レコードにアクセスできる
- 227 * 227 * 178
- Level 2 の B-tree は 4 回のブロックアクセスで 2,082,080,774 index レコードにアクセスできる
- 227 * 227 * 227 * 178
- 4K バイトのブロック
Inserting Records
- 挿入時にブロックに空きが無い場合はブロックを分割
- index ファイルに新しいブロックを割り当てる
- index レコードの高い値側の半分を新しいブロックに移動
- 新しいブロックのディレクトリレコードを生成
- 新しいディレクトリレコードをもとの index ブロックを指したのと同じ Level 0 ディレクトリブロックに挿入
- ディレクトリブロックに空きが無い場合は、そのディレクトリブロックも分割
Duplicate Datavals
- 同じ dataVal の index レコードは同じブロックに配置される必要がある
- ディレクトリから辿れなくなるため
- 同じ dataVal が多すぎて 1 つのブロックに収まらない場合はオーバーフローブロックを利用する
Implementing B-Tree
- SimpleDB における主要な 4 つのクラス
- BTreeIndex
- BTreeDir
- BTreeLeaf
- BTPage
BTPage
- B-Tree page のレコード
- レコードはソートされた順序で管理される必要がある
- レコードは永続的な ID を持つ必要はなく、必要に応じてページ内で移動できる
- ページはそのレコードを他のページと分割できる必要がある
- 各ページはフラグとなる整数が必要である
- ディレクトリページはフラグを利用してそのレベルを保持
- リーフページはそのオーバーフローブロックを指し示すためにフラグを使用する
- B-Tree page
- ソートされたレコードのリストを保持
- 新しいレコードがページに挿入されると、そのソート順の位置が決定され、それに続くレコードが 1 つ右に移動して場所を確保
- レコードが削除されると、それに続くレコードは左側に移動して穴を埋める
- findSlotBefore
public int findSlotBefore(Constant searchKey) { int slot = 0; while (slot < getNumRecs() && getDataVal(slot).compareTo(searchKey) < 0) slot++; return slot - 1; }- 検索キーを引数に取り、検索キー <= dataVal(x) となるような最小の slot を見つけて、その前の slot を返す
BTreeLeaf
- constructor
public BTreeLeaf(Transaction tx, BlockId blk, Layout layout, Constant searchKey) { this.tx = tx; this.layout = layout; this.searchKey = searchKey; contents = new BTPage(tx, blk, layout); currentSlot = contents.findSlotBefore(searchKey); fileName = blk.fileName(); }- 指定されたブロックの BTreePage を作成し
findSlotBeforeを呼び出す- 検索キーを含む最初のレコードの直前に自分自身を配置
- 指定されたブロックの BTreePage を作成し
- next
public boolean next() { currentSlot++; if (currentSlot >= contents.getNumRecs()) return tryOverflow(); else if (contents.getDataVal(currentSlot).equals(searchKey)) return true; else return tryOverflow(); }- 次のレコードに移動し、そのレコードが目的の検索キーを持っているかを返す
- overflow ブロックがあれば、それも検索する
- insert
- 指定された dataRID を持つ leaf レコードを挿入する
- レコードがページにフィットしない場合、ページを split してディレクトリエントリーを返す(フィットする場合は null を返す)
- ページが同じ dataVal を保つ場合は overflow block を生成する
public DirEntry insert(RID dataRid) { if (contents.getFlag() >= 0 && contents.getDataVal(0).compareTo(searchKey) > 0) { // overflow ブロックが存在し、searchKey が挿入対象のブロックが持つ最初の dataVal よりも前に配置されるものの場合は split Constant firstVal = contents.getDataVal(0); BlockId newBlk = contents.split(0, contents.getFlag()); currentSlot = 0; contents.setFlag(-1); contents.insertLeaf(currentSlot, searchKey, dataRid); return new DirEntry(firstVal, newBlk.number()); } currentSlot++; contents.insertLeaf(currentSlot, searchKey, dataRid); if (!contents.isFull()) return null; // ページが full の場合、split する Constant firstKey = contents.getDataVal(0); Constant lastKey = contents.getDataVal(contents.getNumRecs()-1); if (lastKey.equals(firstKey)) { // overflow ブロックを生成して、2件目以降のレコードを移す BlockId newBlk = contents.split(1, contents.getFlag()); contents.setFlag(newBlk.number()); return null; } else { int splitPos = contents.getNumRecs() / 2; Constant splitKey = contents.getDataVal(splitPos); if (splitKey.equals(firstKey)) { // next key を探すために右へ移動 while (contents.getDataVal(splitPos).equals(splitKey)) splitPos++; splitKey = contents.getDataVal(splitPos); } else { // key を持つ最初の entry を探すために左へ移動 while (contents.getDataVal(splitPos-1).equals(splitKey)) splitPos--; } BlockId newBlk = contents.split(splitPos, -1); return new DirEntry(splitKey, newBlk.number()); } }
BTreeDir
- ディレクトリブロックを実装
- search
- ルートから検索キーに関連する level 0 のディレクトリブロックが見つかるまでツリーを下っていく
public int search(Constant searchKey) { BlockId childBlk = findChildBlock(searchKey); while (contents.getFlag() > 0) { contents.close(); contents = new BTPage(tx, childBlk, layout); childBlk = findChildBlock(searchKey); } return childBlk.number(); } - insert
- 新しいディレクトリエントリーを挿入
- ブロックが level 0 ならエントリーはそこに挿入
- そうでない場合は適切な子ノードに挿入
- non-null な値を返す場合は子ノードは split され返されたエントリーはそのブロックに挿入されたことを示す
public DirEntry insert(DirEntry e) { if (contents.getFlag() == 0) return insertEntry(e); BlockId childBlk = findChildBlock(e.dataVal()); BTreeDir child = new BTreeDir(tx, childBlk, layout); DirEntry myEntry = child.insert(e); child.close(); return (myEntry != null) ? insertEntry(myEntry) : null; } private DirEntry insertEntry(DirEntry e) { int newSlot = 1 + contents.findSlotBefore(e.dataVal()); contents.insertDir(newSlot, e.dataVal(), e.blockNumber()); if (!contents.isFull()) return null; // ページが full の場合 split する int level = contents.getFlag(); int splitPos = contents.getNumRecs() / 2; Constant splitVal = contents.getDataVal(splitPos); BlockId newBlk = contents.split(splitPos, level); return new DirEntry(splitVal, newBlk.number()); } - makeNewRoot
- ルートページでの挿入の呼び出しが non-null を返すときに呼び出される
- ルートは常にディレクトリファイルのブロック0にある必要がある
- このメソッドは新しいブロックを割り当て、ブロック0の内容を新しいブロックにコピーし、ブロック0を新しいルートとして初期化
- 新しいルートは常に 2 つのエントリを持つ
- 古いルート
- 新しく分割されたブロック
public void makeNewRoot(DirEntry e) {
Constant firstVal = contents.getDataVal(0);
int level = contents.getFlag();
BlockId newBlk = contents.split(0, level);
DirEntry oldRoot = new DirEntry(firstVal, newBlk.number());
insertEntry(oldRoot);
insertEntry(e);
contents.setFlag(level + 1);
}
B-Tree Index
- constructor
- 与えられたスキーマオブジェクトからリーフレコードのレイアウトを構築
- リーフスキーマから対応する情報を抽出することによってディレクトリレコードのスキーマを構築し、レイアウトを構築
- 必要に応じてルートをフォーマットし、リーフファイルのブロック0を指すエントリを挿入
public BTreeIndex(Transaction tx, String idxName, Layout leafLayout) { this.tx = tx; leafTbl = idxName + "leaf"; this.leafLayout = leafLayout; if (tx.size(leafTbl) == 0) { BlockId blk = tx.append(leafTbl); BTPage node = new BTPage(tx, blk, leafLayout); node.format(blk, -1); } Schema dirSch = new Schema(); dirSch.add("block", leafLayout.schema()); dirSch.add("dataVal", leafLayout.schema()); String dirTbl = idxName + "dir"; dirLayout = new Layout(dirSch); rootBlk = new BlockId(dirTbl, 0); if (tx.size(dirTbl) == 0) { // 新しいルートブロックを生成 tx.append(dirTbl); BTPage node = new BTPage(tx, rootBlk, dirLayout); node.format(rootBlk, 0); // 最初のディレクトリエントリーを挿入 int fieldType = dirSch.type("dataVal"); Constant minVal = (fieldType == INTEGER) ? new Constant(Integer.MIN_VALUE) : new Constant(""); node.insertDir(0, minVal, 0); node.close(); } } - beforeFirst
- 指定した検索キーに関連する leaf ブロックを探す
- 探しだした leaf を open して next, getDataRid を実行可能な状態にしておく
public void beforeFirst(Constant searchKey) { close(); BTreeDir root = new BTreeDir(tx, rootBlk, dirLayout); int blkNum = root.search(searchKey); root.close(); BlockId leafBlk = new BlockId(leafTbl, blkNum); leaf = new BTreeLeaf(tx, leafBlk, leafLayout, searchKey); } - insert
- 適切な leaf ページを探して index レコードを挿入
- leaf ページが分割された場合、新しい leaf の index レコードをディレクトリに挿入
- ルートに挿入した結果、ルートが分割されたら
BTreeDirの makeNewRoot を呼び出す
public void insert(Constant dataVal, RID dataRid) { beforeFirst(dataVal); DirEntry e = leaf.insert(dataRid); leaf.close(); if (e == null) return; BTreeDir root = new BTreeDir(tx, rootBlk, dirLayout); DirEntry e2 = root.insert(e); if (e2 != null) root.makeNewRoot(e2); root.close(); } - delete
- leaf から index レコードを削除
- ディレクトリは変更しない
- ディレクトリブロックが十分に空いた場合 merge させることができるが、SimpleDB では実装しない
- DB が小さくなることはほとんどなく、削除の後に別の挿入が続くのが普通
index を使った Select の実装
- IndexSelectPlan
- select 演算子を実装
- constructor
public IndexSelectPlan(Plan p, IndexInfo ii, Constant val) { this.p = p; this.ii = ii; this.val = val; }- 基礎となる TablePlan, index 情報, 選択定数を受け取る
- open
public Scan open() { TableScan ts = (TableScan) p.open(); Index idx = ii.open(); return new IndexSelectScan(ts, idx, val); }- index を open し、IndexSelectScan のコンストラクタに渡す
- IndexSelectScan
- next
public boolean next() { boolean ok = idx.next(); if (ok) { RID rid = idx.getDataRid(); ts.moveToRid(rid); } return ok; }- IndexSelectPlan から受け取った index を用いて RID を取得
- TableScan を該当の RID まで進める
- next
index を使った Join の実装
- Join の実装では内部テーブルを繰り返しスキャンする必要があったが、IndexJoin では代わりに index を繰り返し検索
- 2 つのテーブルの積を取るよりもかなり効率的
- IndexJoinScan
- constructor
public IndexJoinScan(Scan lhs, Index idx, String joinField, TableScan rhs) { this.lhs = lhs; this.idx = idx; this.joinField = joinField; this.rhs = rhs; beforeFirst(); } public void beforeFirst() { lhs.beforeFirst(); lhs.next(); resetIndex(); } private void resetIndex() { Constant searchKey = lhs.getVal(joinField); idx.beforeFirst(searchKey); }- constructor 内で beforeFirst を呼び出すと lhs の joinField の値 を searchKey として index を検索
- next
public boolean next() { while (true) { if (idx.next()) { rhs.moveToRid(idx.getDataRid()); return true; } if (!lhs.next()) return false; resetIndex(); } }- lhs のレコードがある限り index を繰り返しリセットしつつ rhs のレコードの位置を該当の RID にセット
- index は rhs のテーブルから作成されている前提
- lhs のレコードがある限り index を繰り返しリセットしつつ rhs のレコードの位置を該当の RID にセット
- constructor
Index Update Planning 実装
- database が index 作成をサポートする場合、レコードが更新される度に対応する index レコードの変更も必要
- executeInsert
- テーブルの index 情報を取得し、値をセットしつつ index が存在したら挿入
public int executeInsert(InsertData data, Transaction tx) { String tableName = data.tableName(); Plan p = new TablePlan(tx, tableName, mdm); // 始めにレコードを挿入 UpdateScan s = (UpdateScan) p.open(); s.insert(); RID rid = s.getRid(); // 値をセットしつつ、index が存在したら挿入 Map<String, IndexInfo> indexes = mdm.getIndexInfo(tableName, tx); Iterator<Constant> varIter = data.vals().iterator(); for (String fieldName : data.fields()) { Constant val = varIter.next(); s.setVal(fieldName, val); IndexInfo ii = indexes.get(fieldName); if (ii != null) { Index idx = ii.open(); idx.insert(val, rid); idx.close(); } } s.close(); return 1; } - executeDelete
- レコードを削除する前にレコードのフィールドの値を使って index を削除
public int executeDelete(DeleteData data, Transaction tx) { String tableName = data.tableName(); Plan p = new TablePlan(tx, tableName, mdm); p = new SelectPlan(p, data.pred()); Map<String, IndexInfo> indexes = mdm.getIndexInfo(tableName, tx); UpdateScan s = (UpdateScan) p.open(); int count = 0; while (s.next()) { // 始めにすべての index のレコードが存在したら削除 RID rid = s.getRid(); for (String fieldName : indexes.keySet()) { Constant val = s.getVal(fieldName); Index idx = indexes.get(fieldName).open(); idx.delete(val, rid); idx.close(); } // その後レコード自体を削除 s.delete(); count++; } s.close(); return count; } - executeModify
- レコードを更新しつつ index が存在したら delete & insert する
public int executeModify(ModifyData data, Transaction tx) { String tableName = data.tableName(); String fieldName = data.targetField(); Plan p = new TablePlan(tx, tableName, mdm); p = new SelectPlan(p, data.pred()); IndexInfo ii = mdm.getIndexInfo(tableName, tx).get(fieldName); Index idx = (ii == null) ? null : ii.open(); UpdateScan s = (UpdateScan) p.open(); int count = 0; while (s.next()) { // 始めにレコードを更新 Constant newVal = data.newVal().evaluate(s); Constant oldVal = s.getVal(fieldName); s.setVal(data.targetField(), newVal); // index が存在したら delete & insert if (idx != null) { RID rid = s.getRid(); idx.delete(oldVal, rid); idx.insert(newVal, rid); } count++; } if (idx != null) idx.close(); s.close(); return count; }
Chapter 13: Materialization and Sorting
- materialize, sort, groupby, mergejoin について考察
- 入力レコードを一時テーブルに保存することで実体化
- パイプライン演算子のみを使用した場合もよりはるかに効率の良い問い合わせ実装を実現
Materialization の価値
- これまでに見てきた演算子の実装の特徴
- レコードは必要に応じて計算され、保存されない
- 前のレコードにアクセスするには演算全体を最初から再計算
- この章では入力を実体化する演算子について考える
- 前処理により、出力レコードを一時テーブルに保存
- 例: groupby
- 指定されたグループ化フィールドに従って入力レコードをグループ化 & 各グループに対して集計関数を計算
- グループを決定する最も簡単な方法はレコードをグループ化フィールドでソートすること
- ソートしたレコードは一時テーブルに保存しておく
- 集計関数の計算はこの一時テーブルを一回通過させることで行う
- materialization は両刃の剣
- scan 効率を大幅に向上
- 一時テーブルの書き込みと読み込みでオーバーヘッドが発生
- クライアントが必要とする出力レコードよりも多くのレコードを一時テーブルに書き込む必要がある
- 上記のコストが scan の効率化で相殺される場合のみ有用
一時テーブル
- 一時テーブルと通常のテーブルとの違い
- TableManager の createTable では作成されず、metadata も catalog に表示されない
- SimpleDB では一時テーブルの独自の metadata を管理
- 一時テーブルは不要になった時点で database システムによって自動的に削除
- SimpleDB ではシステムの初期化時に削除
- RecoveryManager は一時テーブルの変更を記録しない
- TableManager の createTable では作成されず、metadata も catalog に表示されない
Materizliation
- materialize 演算子
- サブクエリの出力を一時テーブルに保存
- レコードが何度も計算されないようにする
Materialization の例
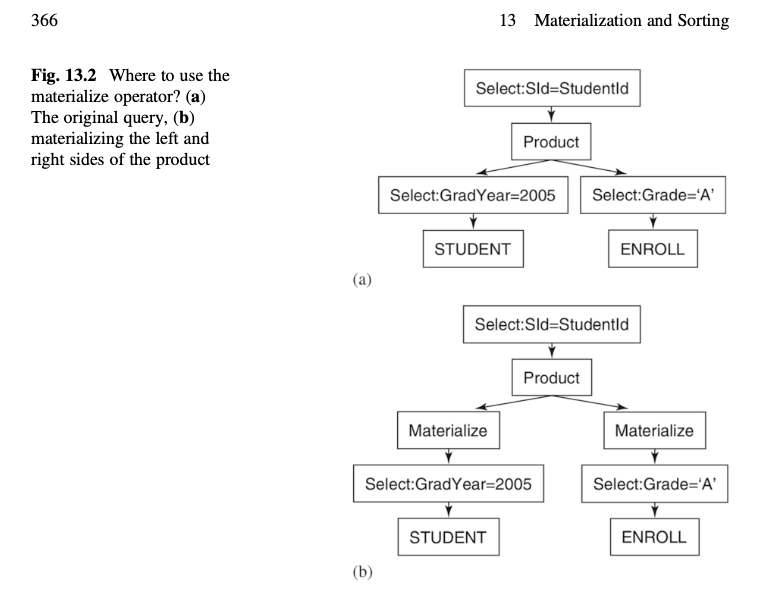
- (a)
- Product では左の部分木の各レコードに対して右の部分木の各レコードを検査
- 右のサブツリーは何度もアクセスされる
- その際に
Grade='A'が何度も計算される - 例
- STUDENT: 900 人
- ENROLL テーブル: 50,000 ブロック
- Product 時のアクセス:
50,000 * 900 = 45,000,000
- Product では左の部分木の各レコードに対して右の部分木の各レコードを検査
- (b)
- 2 つの materialize ノードがある
- 右の Select ノード
-
Grade='A'の ENROLL レコードを含む一時テーブルを作成 - 例
- 一時テーブルは元のテーブルの 1/14 になる場合: 3,572 ブロック
- 一時テーブル作成時のアクセス: 50,000(読み込み) + 3,572(書き込み) ブロック
- Product 時のアクセス:
3,572 * 900 = 3,214,800 - materialization により (a) よりも 80 % 以上削減
-
- 左の Select ノード
- 一時テーブル作成時のブロックアクセス + Product 時の一時テーブルのブロックアクセスが発生
- (a) に比べてコストが増加
- → materialize はそのノードの出力が繰り返し計算される場合にのみ有用
Materialization のコスト
- 入力の前処理コストと scan 実行コストに分けることができる
- 前処理コスト: 対象のテーブルの読み取りコストと一時テーブルへの書き込みコスト
- scan コスト: 一時テーブルからレコードを読み出すコスト
Materialize Operator の実装
- MaterializePlan のみ実装
- Scan は TempTable の TableScan を使う
- open
- ソースから読み取りを行いつつ一時テーブルへの書き込みを行う
- 返り値は一時テーブルに対する Scan
public Scan open() { Schema sch = srcPlan.schema(); TempTable temp = new TempTable(tx, sch); Scan src = srcPlan.open(); UpdateScan dest = temp.open(); while (src.next()) { dest.insert(); for (String fieldName: sch.fields()) { dest.setVal(fieldName, src.getVal(fieldName)); } } src.close(); dest.beforeFirst(); return dest; } - blocksAccessed
- materialized テーブルの推定サイズを返す
- ソースのレコード数をブロック辺りのレコード数で割ることで算出
- 前処理コストは含まれていない
- 一時テーブルの構築は1回で、Scan は複数回されることを想定して無視
public int blockAccessed() { // レコードの長さを計算するためにダミーレイアウトを作成 Layout layout = new Layout(srcPlan.schema()); double rpb = (double) (tx.blockSize() / layout.slotSize()); return (int) Math.ceil(srcPlan.recordsOutput() / rpb); } - recordsOutput, distinctValues の値はソースの値と同じものを返す
Sorting
- sort 演算子
- 関係代数のもう一つの便利な演算子
- 入力テーブルとフィールドのリストという 2 つの引数を取る
- 出力テーブルは入力テーブルと同じレコードを持つ
- フィールドのリストに従って sort されたものになる
- groupBy, mergeJoin という演算子を実装するためにも使用される
なぜ Sort は入力レコードを Materialize する必要があるか
- Materialize を使用にせずに実装することも可能
- next が呼ばれる度に入力レコードを 2 回反復する必要があるので非効率
- 次に大きな値を見つける & その値を持つレコードに移動する
- next が呼ばれる度に入力レコードを 2 回反復する必要があるので非効率
- Materialize 実装
- open メソッドが入力レコードを前処理
- sort された順序で一時テーブルに保存
- next の呼び出しは、単に一時テーブルから次のレコードを取得
- 一時テーブルの作成と sort が比較的効率的に実行できるのであれば Materialize 実装は、コストが低くなる
基本的な Mergesort アルゴリズム
- insertion sort, quick sort などはすべてのレコードがメモリ内に存在する必要がある
- internal sort アルゴリズムと呼ばれる
- DB においてはテーブルがメモリに収まると仮定することはできない
- external sort アルゴリズムを使う必要がある
- 最も単純かつ一般的なアルゴリズムは mergesort
- external sort アルゴリズムを使う必要がある
- run(ソート済みの部分列、連)という概念に基づいていいる
- ソートされてないテーブルは複数の run を持つ
- ソートされたテーブルは 1 つの run を持つ
- 2 つのフェーズ
- split
- 入力レコードを scan
- 各 run を一時テーブルに格納
- merge
- run が一つになるまで merge を繰り返す
- split
- 初期の run の数を
R log_2 R - 参考: wikipedia: マージソート
Mergesort アルゴリズムの改善
- 効率を上げる 3 つの方法
- 一度に merge される run の数を増やす
- 初期の run の数を減らす
- 最終的なソートされたテーブルを write しない
- merge される run の数を増やす
- 一度に 3 つ以上の run をマージすることすることができる
- 一度に
k -
log_k R - 最適な
k
-
- 初期の run の数の削減
- 1 回の実行あたりのレコード数を増やす必要がある
- アルゴリズム 1
- 1 ブロック分の入力レコードを新しい一時テーブルに読み取る
- メモリ上のバッファページに配置されるのでディスク書き込みは発生しない
- 内部ソート(クイックソートなど)を用いてこれらのレコードをソートする
- 1 ブロックの一時テーブルをディスクに保存する
- 1 ブロック分の入力レコードを新しい一時テーブルに読み取る
- アルゴリズム 2
- 1 ブロック分のステージングエリアを入力レコードで埋める
- 新しい run を開始
- ステージングエリアが空になるまで繰り返す
- ステージングエリアのレコードがどれも現在の run に適合しない場合、run を終了し、新しい run を開始
- 現在の run の最後のレコードより高い最小値を持つステージングエリアからレコードを選択
- このレコードを現在の run にコピー
- ステージングエリアからそのレコードを削除
- 次の入力レコードをステージングエリアに追加
- 現在の run を終了する
- (例)
- 入力レコード: 2 6 20 4 1 16 19 3 18, ブロックは 3 レコードまで保持
- 入力レコードをステージングエリアに読み込み
- Staging: 2 6 20
- Run1:
- ステージングエリアの最小値を選択し run に移動 & 入力レコードを 1 つ読み込み
- Staging: 6 20 4
- Run1: 2
- ステージングエリアの最小値を選択し run に移動 & 入力レコードを 1 つ読み込み
- Staging: 6 20 1
- Run1: 2 4
- 最小値は 1 だが現在の run には追加できないので 6 を移動
- Staging: 20 1 16
- Run1: 2 4 6
- 現在の run へ追加できるものを移動し終える
- Staging: 1 3 8
- Run1: 2 4 6 16 19 20
- 新しい run を開始して追加を実施
- Staging:
- Run1: 2 4 6 16 19 20, Run2: 1 3 18
- 最終的なソートされたテーブルを write しない
- 1 つの一時テーブルにマージする前段階で前処理を終了
- 一時テーブルは
k
- 一時テーブルは
- scan 時に
k
- 1 つの一時テーブルにマージする前段階で前処理を終了
Mergesort のコスト
- 前処理コストと scan コストに分けることができる
- 前処理コスト
- 対象のテーブルスキャンのコスト
- レコードを run に分割するコスト
- マージコスト
- scan コスト
- 一時テーブルのレコードから最終的なマージを実行するためのコスト
- 以下を仮定して説明
- 一度にk
-R
- materialized な入力レコードは B ブロックを必要とする- 前処理コスト
-
2B log_k R - B + inputのコスト - 分割には B ブロックのアクセスに加えて入力のコストが必要
- レコードのソートは
log_k R - 繰り返しのうち 1 回は scan 段階で実施
- 各繰り返しの間、各 run のレコードは 1 回読み・書きされる
-
2B
-
- 最終的なマージは scan 時に行えば良いので
-B
-
- scan コスト
-
B - 各 run のレコードが 1 回ずつ読まれ、
B
- 各 run のレコードが 1 回ずつ読まれ、
-
- 前処理コスト
- 例
- 1000 ブロックのテーブルに
1000 - 一度に
2 コスト \risingdotseq 21,000 - 前処理コスト
- 10 回のマージの繰り返しが必要
-
log_2 1000 \leq 10
-
-
20,000 = 2 * 1000 * 10
- 10 回のマージの繰り返しが必要
- scan のコスト
-
1000
-
- 前処理コスト
- 一度に
10 コスト \risingdotseq 7,000 - 前処理コスト
- 3 回のマージの繰り返しが必要
-
log_{10} 1000 = 3
-
-
6,000 = 2 * 1000 * 3
- 3 回のマージの繰り返しが必要
- scan のコスト
-
1000
-
- 前処理コスト
- 一度に
1000 コスト \risingdotseq 3,000 - 前処理コスト
- 1 回のマージの繰り返しが必要
-
log_{1000} 1000 = 1
-
-
2,000 = 2 * 1000
- 1 回のマージの繰り返しが必要
- scan のコスト
-
1000
-
- 前処理コスト
- 1000 ブロックのテーブルに
Mergesort の実装
- SortPlan
- open
- mergesort を実行する
- 一度に 2 個の run をマージ
- 初期実行回数は減らさない
public Scan open() { Scan src = p.open(); List<TempTable> runs = splintIntoRuns(src); src.close(); while (runs.size() > 2) runs = doAMergeIteration(runs); return new SortScan(runs, comp); } - splitIntRuns
- src を run に分割して、それぞれを一時テーブルに格納
private List<TempTable> splintIntoRuns(Scan src) { List<TempTable> temps = new ArrayList<>(); src.beforeFirst(); if (!src.next()) return temps; TempTable currentTemp = new TempTable(tx, sch); temps.add(currentTemp); UpdateScan currentScan = currentTemp.open(); while (copy(src, currentScan)) if (comp.compare(src, currentScan) < 0) { // start a new run currentScan.close(); currentTemp = new TempTable(tx, sch); temps.add(currentTemp); currentScan = (UpdateScan) currentTemp.open(); } currentScan.close(); return temps; } - doMergeIteration
- 2 つずつ run をマージしていき、sort 結果の一時テーブルを含むリストを返す
- 初期 run が 2 つ以上ある場合、返り値のリストのサイズは 2 になる
private List<TempTable> doAMergeIteration(List<TempTable> runs) { List<TempTable> result = new ArrayList<>(); while (runs.size() > 1) { TempTable p1 = runs.remove(0); TempTable p2 = runs.remove(0); result.add(mergeTwoRuns(p1, p2)); } if (runs.size() == 1) result.add(runs.get(0)); return result; } - 2 つずつ run をマージしていき、sort 結果の一時テーブルを含むリストを返す
- mergeTwoRuns
- 2 つの run の一時テーブルを open し、比較しつつマージ
- recordsOutput, distinctValues
- 入力テーブルと同じ値を返す
- blocksAccessed
- Materialized されたテーブルのブロック数を返す
- Mergesort の前処理コストは含まない
- open
- RecordComparator
- 上記のコードで
compとして記載されているもの - 各 scan の現在のレコードの値をソート対象のフィールドで比較
- 上記のコードで
- SortScan
- constructor
- 1 つまたは 2 つの run のリストを受け取り、それぞれの scan を open する
- next
- 2 つの scan の現在のレコードを比較して currentScan を設定する
- get 系メソッド
- currentScan の値を返す
- savePosition
- 2 つの scan の現在のレコードの RID を保存
- 後述の mergejoin で利用
public void savePosition() { RID rid1 = s1.getRid(); RID rid2 = (s2 == null) ? null : s2.getRid(); savedPosition = Arrays.asList(rid1, rid2); }
- constructor
Grouping and Aggregation
- groupby 演算子
- 入力テーブル、グループ化フィールドの集合、集計式の集合の 3 つ引数を取る
- グループ化フィールドに同じ値を持つレコードを同じグループにまとめる
- 出力テーブルにはグループごとに 1 つの行がある
- グループ化フィールドと集計式ごとに 1 つの列がある
- レコードのグループをどのように作成するか
- 最適な方法は、グループ化フィールドでレコードをソートした一時テーブルを作成
- 各グループのレコードは隣り合うのでソートされたテーブルを一回通過するだけでグループの情報を計算可能
- アルゴリズム
-
- グループ化フィールドでソートされた入力レコードを含む一時テーブルを作成
-
- テーブルの最初のレコードに移動
-
- 以下を一時テーブルがなくなるまで繰り返し
- 現在のレコードのグループ化フィールドの値を "グループ値" とする
- "グループ値" と同じグループ化フィールドを持つレコードをグループリストに読み込む
- グループリストのレコードに対して指定された集計式を計算する
-
- コスト
- 前処理コスト
- ソートのコスト
- scan コスト
- ソートされた一時テーブルのレコードを 1 回反復するコスト
- 前処理コスト
GroupByPlan
- constructor
- 基礎となる plan とグループ化フィールドのリストと集計式のリストを受け取る
- グループ化フィールドと集計式の名称からスキーマを構築
public GroupByPlan(Transaction tx, Plan p, List<String> groupFields, List<AggregateFn> aggFns) { this.p = new SortPlan(tx, p, groupFields); this.groupFields = groupFields; this.aggFns = aggFns; for (String fieldName : groupFields) schema.add(fieldName, p.schema()); for (AggregateFn fn: aggFns) { schema.addIntField(fn.fieldName()); } } - open
- GroupByScan を生成して返す
- recordsOutput
- グループの数を返す
- 均等に分布していることを仮定して、グループ化フィールドごとの distinct values の数の積を返す
public int recordsOutput() { int numGroups = 1; for (String fieldName : groupFields) numGroups *= p.distinctValues(fieldName); return numGroups; }
GroupByScan
- constructor
- 基礎となる scan とグループ化フィールドのリストと集計式のリストを受け取る
- next
- 異なる "グループ値" が現れるまでレコードを読みつつ集計
public boolean next() { if (!moreGroups) { return false; } for (AggregateFn fn : aggFns) { fn.processFirst(s); } groupVal = new GroupValue(s, groupFields); while (moreGroups = s.next()) { GroupValue gv = new GroupValue(s, groupFields); if (!groupVal.equals(gv)) { break; } for (AggregateFn fn : aggFns) fn.processNext(s); } return true; } - getVal
- 指定されたフィールドがグループ化フィールドであればその値を返す
- 集計式の名称と一致する場合は集計値を返す
public Constant getVal(String fieldName) { if (groupFields.contains(fieldName)) { return groupVal.getVal(fieldName); } for (AggregateFn fn : aggFns) { if (fn.fieldName().equals(fieldName)) { return fn.value(); } } throw new RuntimeException("field " + fieldName + " not found."); }
AggregateFn
- MaxFn
- processFirst, processNext
- 前者で初期化、後者で比較しつつ大きければ差し替え
public void processFirst(Scan s) { val = s.getVal(fieldName); } public void processNext(Scan s) { Constant newVal = s.getVal(fieldName); if (newVal.compareTo(val) > 0) { val = newVal; } } - processFirst, processNext
- CountFn
- processFirst, processNext
- 前者で counter を 1 にセット、後者でインクリメント
- processFirst, processNext
Merge Joins
- 効率的な join 演算子
- アルゴリズム
-
- それぞれの input テーブルをソート
- join フィールドを sort フィールドとして用いる
-
- sort したテーブルを並列に scan し、join フィールドのマッチングを探す
-
- 結合の左側にあるテーブルのレコードごとに右側のテーブルのレコードを探す際、sort されていると検索は単純化する
- ポイント
- 一致する右側のレコードは、直前の左側のレコードの後に開始しなければならない
- 一致するレコードはテーブル内で隣り合っている
- 右側のテーブルの scan は一度だけでよい
- 新しい左側のレコードが考慮されるたびに、右側テーブルの中断したところから scan
- 左側の join 値より大きい join 値に達した時点で停止
- 左側のテーブルに重複する join 値がある場合
- アルゴリズムは対象の join 値にマッチした右側の最初のレコードに戻る必要がある
- 一致するレコードを含む全ての右側ブロックを再読み込みする必要があり、コストが増加
- 幸い、左側の値が重複することはほとんどない
- (そんなこと無い気がするが...)
- Mergejoin のコスト
- 前処理: 2 つのテーブルのソートコスト
- scan: ソートされたテーブルサイズの合計
Mergejoin の実装
- MergeJoinPlan
- constructor
- 指定された 2 つの Plan をそれぞれ sort
public MergeJoinPlan(Transaction tx, Plan p1, Plan p2, String fieldName1, String fieldName2) { this.fieldName1 = fieldName1; List<String> sortList1 = Arrays.asList(fieldName1); this.p1 = new SortPlan(tx, p1, sortList1); this.fieldName2 = fieldName2; List<String> sortList2 = Arrays.asList(fieldName2); this.p2 = new SortPlan(tx, p2, sortList2); sch.addAll(p1.schema()); sch.addAll(p2.schema()); } - recordsOutput
- 一様分布を仮定して
R(join(p1, p2)) = R(p1)*R(p2)/max{V(p1, F1), V(p2, F2)}
public int recordsOutput() { int maxVals = Math.max(p1.distinctValues(fieldName1), p2.distinctValues(fieldName2)); return (p1.recordsOutput() * p2.recordsOutput()) / maxVals; } - 一様分布を仮定して
- constructor
- MergeJoinScan
- next
- 1 つ前の next 呼び出し時に決まった join 値を利用
- 右側の scan が join 値と一致する間、そちらの next を呼び出して true を返す
- 右側の scan が join 値と一致しない場合で、左側の scan が join 値と一致する場合、右側の scan の位置を戻して true を返す
- 左側の scan に join 値が重複するケース
- 右側を読み直す必要がある
- SortScan は読み直しのための位置を記録する機能を実装している前提
- どちらの scan も join 値と一致しない場合は左右の scan を進めて、次に一致する値を探す
- 一致する値が見つかったら、右側の位置を記録
- 左側に join 値が重複するケースに備える
- join 値を上書き
- 一致する値が見つかったら、右側の位置を記録
public boolean next() { boolean hasMore2 = s2.next(); if (hasMore2 && s2.getVal(fieldName2).equals(joinVal)) { return true; } boolean hasMore1 = s1.next(); if (hasMore1 && s1.getVal(fieldName1).equals(joinVal)) { s2.restorePosition(); return true; } while (hasMore1 && hasMore2) { Constant v1 = s1.getVal(fieldName1); Constant v2 = s2.getVal(fieldName2); if (v1.compareTo(v2) < 0) { hasMore1 = s1.next(); } else if (v1.compareTo(v2) > 0) { hasMore2 = s2.next(); } else { s2.savePosition(); joinVal = s2.getVal(fieldName2); return true; } } return false; }
- next
Chapter 14 Effective Buffer Utilization
- 演算子の実装が異なると必要なバッファも異なる
- select は単一のバッファを効率的に使用でき、追加のバッファは必要ない
- sort の materialize 実装は一度に複数の run を merge し、それぞれにバッファが必要
- 演算子の実装が追加のバッファを使用できる方法を検討
- sort, product, join の効率的なバッファアルゴリズムを提供
Query プランにおけるバッファの使用
- select, project, product の各 scan では対象のテーブルのブロック分のバッファしか固定されない
- index 実装においても同様
- static hash index では各バケットを順次 scan して 1 ブロックずつ固定
- B-tree index ではルートから始まり、ディレクトリブロックや子ブロックを順次 scan して 1 ブロックずつ固定
- materialize 実装は異なる
- materialize
- 入力 query に必要なバッファに加えて、一時テーブル用のバッファが 1 つ必要
- sort
- 1 つまたは 2 つのバッファが必要(staging エリアを使うかどうかによって変わる)
- merge フェーズでは
k+1
- groupby, mergejoin
- sort に使用するものを除いて、追加のバッファはない
- materialize
- 利用可能なバッファの数
- 400 MB をバッファに使用する場合、バッファの数は 10 万個の
4k - query プランがこれらを効率的に使うことができれば、数千の同時接続をサポートしても十分なサイズ
- 400 MB をバッファに使用する場合、バッファの数は 10 万個の
Multibuffer Sorting
- Mergesort の 2 つの段階を復習
- 最初のフェーズ: レコードを run に split
- 2 番目のフェーズ: テーブルが sort されるまで run を merge
- k 個のバッファが利用可能な場合を考える
- split フェーズでは
- テーブルの k ブロックを一度に k 個のバッファに読み込み
- それぞれを内部ソートして k ブロックの run を生成
- run を一時テーブルに書き込み
- → k が十分に大きい場合、split フェーズでは k 個以上の初期 run は生成しないので、分割以外には何もしなくても良い
- 例: テーブルが B ブロックの場合
- split フェーズで
B/k - (一時テーブル書き出し時に merge もする?)
- その後の merge フェーズは
log_k (B/k) - 基本的な mergesort に比べてイテレーションが 1 回少なくなる
- 基本的な mergesort
2Blog_k R -
2B
- 基本的な mergesort
- 基本的な mergesort に比べてイテレーションが 1 回少なくなる
- コスト
- 前処理:
2Blog_k B - 3B - scan:
B
- 前処理:
- split フェーズで
- k の最適値の選び方
-
k = \sqrt{B} - split フェーズでサイズが k の k 個の run を生成するためマージは scan フェーズで実施すればよい
-
k = \sqrt[3]{B} - split フェーズでサイズが k の
k^2 - 1 イテレーション実行後にサイズが
k^2 - k 個の run は scan フェーズでマージ
- split フェーズでサイズが k の
-
k = \sqrt[4]{B} - 例
- 4GB のテーブルを sort
- ブロックは 4KB
- テーブルは 1000,000 ブロックとなる
- buffer 数 : iteration 数
- 1000 : 0
- 100 : 1
- 32 : 2
- 16 : 3
- 10 : 4
- ...
- 2 : 18
- 上記の例で、あるテーブルのサイズ B に対し、multibuffer mergesort では buffer 数が
\sqrt{B}, \sqrt[3]{B}, \sqrt[4]{B}, ... - buffer 数が 100 の場合は 1 イテレーションだったが、500 の場合は?
- split フェーズで 500 ブロックの 2000 個の run が生成される
- 最初のイテレーションでは 500 個の run を 4 個の run にマージ
- scan フェーズで 4 個の run をマージする必要があるので、buffer 数 100 だった時とイテレーション数が変わっていない
- 結論
- B ブロックのテーブルを sort するために k 個の buffer を使用する場合、k は B のルートでなければならない
-
Multibuffer Product
- SimpleDB の product(T1, T2) の実装では単一の buffer を使用している
- 場合によっては T2 の各ブロックは T1 のレコード数と同じ回数読み込まれる可能性がある
- T1, T2 がともに 1000 ブロックのテーブルだった場合
- 1 ブロックに 20 レコードがあると 20,001,000 回のブロックアクセスが必要
- 仮に T2 のブロックの pin を解除しないと?
- T1 の各ブロックを 1 回、 T2 の各ブロックを 1 回読み取るだけで良いので非常に効率的
- T2 が大きすぎる場合は?
- T2 が 1000 ブロックで buffer が 500 個のケースで考える
- T2 を 2 段階で処理
- 最初の 500 ブロックを buffer に読み込んで T1 との product を計算
- 次に残りの 500 ブロックを buffer に読み込んで T1 との product を計算
- T1 は 2 回、T2 は 1 回読まれるだけなので 3000 回のブロックアクセスで済む
- multibuffer product は上記の考えを一般化
- T1 のブロックを B1, T2 のブロックを B2 とする
- T2 のブロック B2 をチャンクに分ける
- チャンク内のブロック数 = buffer 数 k となるようにする
- →チャンク数は B2/k 個となる
- product には
B2 + (B1B2/k) - 8 章の実装では T1 の scan は 1 回だったが multibuffer product だと複数回になる
- 例
- T1, T2 がともに 1000 ブロック
- buffer 数 : チャンク数 : ブロックアクセス数
- 1000 : 1 : 2000
- 500 : 2 : 4000
- 334 : 3 : 5000
- 250 : 4 : 6000
- T2 を 250 ブロックの 4 つのチャンクに分割
-
1000 + (1000 * 4)
- ...
- 100 : 10 : 11000
- これらの値はすべて基本的な product 実装が必要とするブロックアクセス数よりもはるかに小さい
- sort と同様に k のすべての値が有用ではない
- 300 個の buffer が利用可能でも multibuffer product では 250 個しか利用できない
Determining Buffer Allocation
- multibuffer アルゴリズムのための buffer 数 k の適切な値は以下の要素で決定される
- 利用可能な buffer の数
- 入力テーブルのサイズ
- 関係演算子
- sort の場合は入力テーブルのサイズのルート
- product の場合はテーブルのサイズのファクタ
- バッファー数を計算する BufferNeeds の実装
- bestRoot
- 利用可能な buffer 数と入力テーブルのサイズを受け取って取りうる root を返す
public static int bestRoot(int available, int size) { int avail = available - 2; //reserve a couple if (avail <= 1) return 1; int k = Integer.MAX_VALUE; double i = 1.0; while (k > avail) { i++; k = (int)Math.ceil(Math.pow(size, 1/i)); } return k; } - bestFactor
- 利用可能な buffer 数と入力テーブルのサイズを受け取って取りうる factor を返す
public static int bestFactor(int available, int size) { int avail = available - 2; //reserve a couple if (avail <= 1) return 1; int k = size; double i = 1.0; while (k > avail) { i++; k = (int)Math.ceil(size / i); } return k; }
- bestRoot
- 上記の実装は実際には buffer manager から buffer を予約することはない
- 単に数を返すだけ
- multibuffer アルゴリズムが返された数の buffer を pin しようとしても利用できない可能性がある
- その場合は wait
Multibuffer Sorting の実装
-
SimpleDB の配布ソースには実装は含まれていない
-
以下は実装済の SortPlan の変更方針を記載
-
splitIntoRuns
- テーブルがまだ作成されていないのでサイズが分からない
- blocksAccessed を用いて推定することはできる
- 以下のようなコードを利用
int size = blocksAccessed(); int available = tx.availableBuffs(); int numbuffs = BufferNeeds.bestRoot(available, size);- numbuffs を pin して入力レコードで満たして内部ソートして一時テーブルに書き込めばよい
-
doAMergeIteration
- 最適な戦略はこのメソッドが run リストから k 個の一時テーブルを削除すること
int available = tx.availableBuffs(); int numbuffs = BufferNeeds.bestRoot(available, runs.size()); List<TempTable> runsToMerge = new ArrayList<>(); for (int i=0; i<numbuffs; i++) runsToMerge.add(runs.remove(0));- runsToMerge リストを mergeTwoRuns (mergeSeveralRuns にリネーム)に渡して 1 つの run にマージすればよい
-
GroupByPlan, MergeJoinPlan は内部で使用する SortPlan が通常のアルゴリズムと mulitibuffer のアルゴリズムのどちらをつかっているかは見分けられない
-
ChunkScan
- チャンク実装
- すべてのブロックが利用可能な buffer に収まる特性を持つ
- constructor
- チャンクの最初と最後のブロックのブロック番号が与えられる
- チャンク内の各ブロックのレコードページを開き、リストに格納
public ChunkScan(Transaction tx, String fileName, Layout layout, int startBNum, int endBNum) { this.tx = tx; this.fileName = fileName; this.layout = layout; this.startBNum = startBNum; this.endBNum = endBNum; for (int i = startBNum; i<= endBNum; i++) { BlockId blk= new BlockId(fileName, i); buffs.add(new RecordPage(tx, blk, layout)); } moveToBlock(startBNum); } - next
- 現在のページにレコードが無い場合、リストの次のページがカレントとなる
- TableScan と異なり、ブロック間を移動しても前のページを close しない(unpin しない)
public boolean next() { currentSlot = rp.nextAfter(currentSlot); while (currentSlot < 0) { if (currentBNum == endBNum) { return false; } moveToBlock(rp.block().number()+1); currentSlot = rp.nextAfter(currentSlot); } return true; }
-
MultiBufferProductPlan
- open
- LHS は MaterializeScan として、RHS は一時テーブルとして実体化する
public Scan open() { Scan leftScan = lhs.open(); TempTable tt = copyRecordsFrom(rhs); return new MultiBufferProductScan(tx, leftScan, tt.tableName(), tt.getLayout()); } private TempTable copyRecordsFrom(Plan p) { Scan src = p.open(); Schema sch = p.schema(); TempTable t = new TempTable(tx, sch); UpdateScan dest = (UpdateScan) t.open(); while (src.next()) { dest.insert(); for (String fieldName : sch.fields()) { dest.setVal(fieldName, src.getVal(fieldName)); } } src.close(); dest.close(); return t; } - blocksAccessed
- チャンクのサイズを計算するために RHS のテーブルのサイズを知る必要があるため MaterializePlan を用いて推定
public int blockAccessed() { int avail = this.tx.availableBuffs(); int size = new MaterializePlan(tx, rhs).blockAccessed(); int numChunks = size / avail; return rhs.blockAccessed() + (lhs.blockAccessed() * numChunks); }
- open
-
MultiBufferProductScan
- constructor
- BufferNeed.bestFactor を呼び出してチャンクサイズを決定
- RHS の ChunkScan を open し、LHS との ProductScan を作成
public MultiBufferProductScan(Transaction tx, Scan lhsScan, String tblName, Layout layout) { this.tx = tx; this.lhsScan = lhsScan; this.fileName = tblName + ".tbl"; this.layout = layout; fileSize = tx.size(fileName); int available = tx.availableBuffs(); chunkSize = BufferNeeds.bestFactor(available, fileSize); beforeFirst(); } - next
- ProductScan にレコードが無い場合、新しい ProductScan を作成しする
public boolean next() { while (!prodScan.next()) { if (!useNextScan()) { return false; } } return true; } private boolean useNextScan() { if (nextBlkNum >= fileSize) { return false; } if (rhsScan != null) { rhsScan.close(); } int end = nextBlkNum + chunkSize - 1; if (end >= fileSize) { end = fileSize - 1; } rhsScan = new ChunkScan(tx, fileName, layout, nextBlkNum, end); lhsScan.beforeFirst(); prodScan = new ProductScan(lhsScan, rhsScan); nextBlkNum = end + 1; return true; }
- constructor
Hash Joins
- mergejoin アルゴリズムは両方の入力テーブルを sort
- コストは大きい方の入力テーブルのサイズで決まる
- hashjoin アルゴリズムではコストは小さい方の入力テーブルのサイズで決まる
- 入力テーブルのサイズが非常に異なる場合、mergejoin よりも好ましい
Hashjoin アルゴリズム
- T2 のサイズに基づいて再帰的に実行
- T2のサイズが利用可能な buffer に収まる場合は multibuffer product を使って T1, T2 を結合
- T2 のサイズが大きい場合は T2 のサイズを小さくするために hash を使用

- アルゴリズム
- 利用可能な buffer 数以下の値 k を選択
- T2 が k ブロックに収まる場合
- multibuffer product を使用して T1, T2 を結合 して返す
- 0 から k-1 の間の値を返す hash 関数を選択する
- T1 の各レコードを join field で hash 化し、hash 値に関連する一時テーブルにレコードをコピーする
- T1 を hash 値で分類した一時テーブルの集合ができる
- T2 も同様に hash 化する
- T2 を hash 値で分類した一時テーブルの集合ができる
- 0 から k-1 の間の値 i に対して
- T1 の i 番目の一時テーブルと、T2 の i 番目の一時テーブルに対して hashjoin を再帰的に実行
コスト分析
- 前提
- テーブル T1 のブロック数を B1、テーブル T2 のブロック数を B2 とする
-
B2 = k^n - レコードが均等に hash 化されると仮定
- コストを計算するための整理
- 最初の hash ラウンドでは k 個の一時テーブルが作成される
- それぞれの一時テーブルは
k^{n-1}
- それぞれの一時テーブルは
- 上記を再帰的に hash 化すると
k^2 - それぞれの一時テーブルは
k^{n-2}
- それぞれの一時テーブルは
- 最終的に T2 は k ブロックをもつ
k^{n-1} - これらは multibuffer product を用いて T1 の対応するテーブルと結合
- 最初の hash ラウンドでは k 個の一時テーブルが作成される
- コスト内訳
- 最初のラウンドのコストは B1 + B2 + 入力の読み込みコスト
- その後のラウンドでも 2(B1 + B2) のコストが必要
- 各一時テーブルの各ブロックが 1 回ずつ読み込みされ書き込まれる
- scan 時の multibuffer product によって B1 + B2 のコストが必要
- コスト
- 前処理:
(2B_1log_k B_2 - 3B_1) + (2B_2log_k B_1 - 3B_2) + 入力コスト - 1 つ目の対数の引数は
B_2
- 1 つ目の対数の引数は
- scan:
B_1 + B_2
- 前処理:
- 上記は multibuffer mergejoin のコストとほぼ同じ
- 違いは mergejoin の場合は 1 つ目の対数の引数が
B_1 - hashjoin では hash ラウンド数が T2 によってのみ決まる
- mergejoin は T1, T2 それぞれを sort するため
- 違いは mergejoin の場合は 1 つ目の対数の引数が
- T1, T2 のサイズが近い場合は mergejoin を使用したほうが良い
- hashjoin はレコードを均等に hash するという仮定に依存しているため
- 均等にならない場合、より多くのラウンドが必要になる可能性がある
- hashjoin はレコードを均等に hash するという仮定に依存しているため
- メモ
- 分割は T2 だけ実施して、その過程で使用した hash 方式を記録しておけば T1 を分割する必要はないのでは?
- join 時に T2 のレコードにランダムアクセスすることになるのでダメ
- 分割は T2 だけ実施して、その過程で使用した hash 方式を記録しておけば T1 を分割する必要はないのでは?
Join アルゴリズムの比較
- mergejoin, hashjoin, indexjoin を比較
比較1
- 検討対象
- クエリ:
select SName, Grade from STUDENT, ENROLL where SId=StudentId - STUDENT
- 4500 ブロック
- ENROLL
- 50000 ブロック
- StudentId に対する index を持っている
- 利用可能な buffer: 200
- クエリ:
- mergejoin
- ENROLL の sort
- 平方根は 224 なので buffer 数よりも大きい & 立方根は 37 を使う
- イテレーションは 2 回でそれぞれ読み込みと書き込みが発生
- 200,000 ブロックアクセスが必要
- STUDENT の sort
- 平方根は 68 なので buffer 数に収まる
- イテレーションは 1 回
- 9,000 ブロックアクセスが必要
- merge
- 読み込みのために 54,500 ブロックのアクセスが必要
- 合計 263,500 ブロックアクセス
- ENROLL の sort
- hashjoin
- 最小のテーブルが右側にある場合に効率的なので STUDENT を右側のテーブルとする
- STUDENT の hash
- 68 個の buffer を使用して 68 個のバケットに hash
- それぞれのバケットは 68 個のブロックを持つ
- 上記の処理はブロックの読み込みと書き込みが発生
- 9,000 ブロックアクセスが必要
- 68 個の buffer を使用して 68 個のバケットに hash
- ENROLL の hash
- 68 個の buffer を使用して 68 個のバケットに hash
- それぞれのバケットは 736 個のブロックを持つ
- 上記の処理はブロックの読み込みと書き込みが発生
- 100,000 ブロックアクセスが必要
- 68 個の buffer を使用して 68 個のバケットに hash
- バケットを multibuffer product で結合
- 各バケットは 1 回ずつ読み込まれる
- 54,500 ブロックアクセスが必要
- 合計 163,500 ブロックアクセス
- indexjoin
- STUDENT テーブルの各レコードに対してそのレコードの SID を使って ENROLL インデックスを検索し一致する ENROLL レコードを探す
- STUDENT の scan は 1 回
- 4,500 ブロックアクセスが必要 - ENROLL の scan は最大 1,500,000 (STUDENT レコード数)
- 合計 1504,500 ブロックアクセス
- インデックス検査時のブロックアクセスは省略
- join アルゴリズムの比較
- hashjoin が効率的な理由
- 利用可能な buffer の数に比べて小さい方のテーブルが適度に小さく、もう一方が遥かに大きいため
- mergejoin はもっと buffer 数が多ければ hashjoin と同等になる
- 1000 個の buffer が利用可能場合、イテレーションなしで ENROLL を sort ができる
- indexjoin は圧倒的に効率が悪いのは、ENROLL の全レコードが処理対象だから
- hashjoin が効率的な理由
比較2
- クエリを変更して STUDENT レコードが絞り込まれる場合で再検討
select SName, Grade from STUDENT, ENROLL where SId=StudentId and GradYear=2020- STUDENT レコードは 90 ブロックに収まるまで絞られるとする
- mergejoin
- STUDENT を 90 個の buffer に読み込んで内部 sort ができる
- 必要なブロックアクセスは 4,500
- ENROLL を処理するコストは変わらない
- 200,000 ブロックアクセスが必要
- 合計 204,500 ブロックアクセス
- わずかに改善
- STUDENT を 90 個の buffer に読み込んで内部 sort ができる
- hashjoin
- STUDENT テーブルは 90 個の buffer に収まるのでバケット分割は不要
- 必要なブロックアクセスは 4,500
- ENROLL テーブルも分割不要で 1 回読めば良い
- 必要なブロックアクセスは 50,000
- 合計 54,500 ブロックアクセス
- STUDENT テーブルは 90 個の buffer に収まるのでバケット分割は不要
- indexjoin
- STUDENT テーブルは 1 回読む
- 必要なブロックアクセスは 4,500
- ENROLL テーブルは絞られた STUDENT レコードに一致する分アクセスされる
- 900 人の STUDENT に対応する ENROLL レコードが 50,000 件とする
- 必要なブロックアクセスは 50,000
- 合計 54,500 ブロックアクセス
- インデックス検査時のブロックアクセスは省略
- STUDENT テーブルは 1 回読む
- join アルゴリズムの比較
- hashjoin, indexjoin は同等、mergejoin は劣っている
- 片方のテーブルがかなり小さい場合に mergejoin は不利
比較3
- クエリを変更して STUDENT レコードが 1 件に絞り込まれる場合で再検討
select SName, Grade from STUDENT, ENROLL where SId=StudentId and SId=3
- indexjoin
- STUDENT テーブルは 1 回読む
- 必要なブロックアクセスは 4,500
- ENROLL テーブルは絞られた STUDENT レコードに一致する分アクセスされる
- 1 人の STUDENT に対応する ENROLL レコードが 34 件とする
- 必要なブロックアクセスは 34
- 合計 4,534 ブロックアクセス
- インデックス検査時のブロックアクセスは省略
- STUDENT テーブルは 1 回読む
- hashjoin, mergejoin は 比較2 の場合と変わらない
分析結果
- mergejoin は両方の入力テーブルが比較的同じサイズの時に最も効率的
- hashjoin は入力テーブルのサイズが異なる場合に有効
- indexjoin は出力レコードの数が少ない場合に有効
Chapter 15 Query Optimization
- 効率的な計画を生成するとナイーブな計画に比べて数桁速くなることもある
関係代数 query の等価性
- 関係代数の query は木として表現される
- 等価性はその木の間の変換と考えることができる
- 以下、変換を考察
Products の並び替え
- product 操作はどのような順序でも実行可能
- product 演算は可換性を持つ
product(T1, T2) = product(T2, T1)
- product 演算は結合性を持つ
product(product(T1, T2), T3) = product(T1, product(T2, T3))
- product 演算は可換性を持つ
Splitting Selections
- select は predicate の接続語で分割できる
select(T, p1, p2) = select(select(T, p1), p2)
- select ノードを分割するとクエリツリー内の最適な位置に独立して配置可能
- クエリオプティマイザはできるだけ多くの接続語に分割
- 各 predicate を CNF (Conjunctive Normal Form: 連言標準形)に変換することで実現
- AND 演算子を含まない部分述語の組み合わせであれば CFN になる
- AND 演算子は常に一番外側に置く
-
select SName from STUDENT where (MajorId=10 and SId=3) or (GradYear=2018)- AND が OR の中にあるので CNF ではない
-
select SName from STUDENT where (MajorId=10 or GradYear=2018) and (SId=3 or GradYear=2018)- このように変換すると CNF となる
- 各 predicate を CNF (Conjunctive Normal Form: 連言標準形)に変換することで実現
- 参考
ツリー内での Selections の移動
- クエリツリーにおいて select ノードを移動させることができる
- predicate は select 対象のサブツリーのフィールドのみに言及している前提で
- 例
select(product(T1, T2), p) = product(select(T1, p), T2)
Join 演算子の特定
- select-product ノードのペアを単一の join に変換可能
join(T1, T2, p) = select(product(T1, T2), p)
Projection の追加
- project ノードは祖先ノードに project 対象のフィールドが含まれている限り、ツリー内で移動できる
- materialize を行う際に入力サイズを小さくするために使用できる
クエリ最適化の必要性
- プランナーがクエリに対する計画作成ステップ
- クエリに対応する関係代数クエリツリーを選択
- クエリツリーの各ノードに対する実装を選択
- SQL クエリは多くの等価なクエリツリーに変換可能
- 最適な計画を選択したいが、そのためには多くの作業を伴う可能性があるが労力に見合うのか?
- 同じ結果を返す計画であっても、ブロックアクセス数が極端に異なる可能性がある
- 例としては以下のようなケースがある
- 対象テーブルをすべて product した後に select で絞り込み
- 56兆回のアクセス
- 1 ブロックアクセス 1ms とすると 1780 年かかる
- 56兆回のアクセス
- select や join による絞り込みを先に実施
- 139,500 回のアクセス
- 1 ブロックアクセス 1ms とすると 2.3 分かかる
- 更に工夫すると 7134 回のアクセス
- 7 秒
- 139,500 回のアクセス
- 対象テーブルをすべて product した後に select で絞り込み
クエリオプティマイザの構造
- すべての計画を網羅的に列挙するのは大変
-
n 個の積演算がある場合、配置方法は
(2n)!/n! - n 個のノードの木構造の作り方は
\frac{(2n)}{(n+1)!n!}
- n 個のノードの木構造の作り方は
-
他の演算子を配置したり、各演算ノードに実装を割り当てる必要もある
-
- 最適化は 2 つの独立したステージで実施
- ステージ1: 問い合わせに対して最も有望なクエリツリーを見つける
- この時点では実際のコスト情報は考慮しない
- コスト情報はステージ2のプランに関連付く
- ステージ2: ツリー内の各ノードに対して最適なプランを選択する
- ステージ1: 問い合わせに対して最も有望なクエリツリーを見つける
- 考慮するツリーとプランのセットを制限するためにヒューリスティックを使用できる
- 例: select は可能な限り早期に実行する
- データ数が削減されるため
- 例: select は可能な限り早期に実行する
最も有望なクエリツリーの発見
ツリーのコスト
- 最適化の最初の段階は、プランナが最も低コストな計画を持つと考えるツリーを見つけること
- プランナは最良のツリーを決定することはできないのがポイント
- ブロックアクセスを計算することなくツリーを比較する必要がある
- コスト情報はこの段階では利用できないため
- ブロックアクセスはプランに関連付けられる
- 洞察
- クエリにおけるブロックアクセスはほぼ product, join 操作によるもの
- 上記の演算が必要とするブロックアクセスは入力サイズに関係
- プランナはクエリツリーのコストを
ツリーにある各 product, join ノードへの入力サイズの合計と定義- 実際の実行時間の "quick and dirty" な近似値となる
- ブロックアクセスの見積もりには役立たないが、ツリー間の相対見積もりに役立つ
- 経験上、だいたい正しい
Select ノードをツリーの下に押し出す
- プランナは有望なクエリツリーを探索するためにヒューリスティクスを使用
- select ノードは述語が許す限りはツリー内のどこにでも配置できる
- product, join の内部に配置すれば入力サイズが減り、コストが削減される
- ヒューリスティック1: プランナは select が可能な限り押し下げられたクエリツリーだけを考慮
JoinによるSelect-Productノードの置き換え
- ヒューリスティック2: プランナはクエリツリー内の各 select-product ノードを 1 つの join ノードに置き換える
- 上記はクエリツリーのコストを変えるものではないが、最適なプランを見つけるために重要なステップ
Left-Deep なクエリツリーを使用
- left-deep
- 各 product, join ノードの右側に他の product, join ノードがない状態
- right-deep
- 各 product, join ノードの左側に他の product, join ノードがない状態
- bushy
- left-deep, right-deep でないもの
- ヒューリスティック3: プランナは left-deep なクエリツリーだけを考慮
- ↑の理由は明白ではない
- コストでは bushy なものが低い場合もある
- 1 つ目の理由: left-deep なツリーはコストが最も低くなくても、最も効率的なプランを立てる傾向がある
- join アルゴリズムは右側が stored テーブルである場合にうまく機能
- multi-buffer product では右側のテーブルが materialized なものである必要がある
- join アルゴリズムは右側が stored テーブルである場合にうまく機能
- 2つ目の理由: 利便性
- クエリに n 個の product/join ノードがある場合、left-deep ツリーだけであれば
n!
- クエリに n 個の product/join ノードがある場合、left-deep ツリーだけであれば
ヒューリスティックに Join 順を選択
- 最適な join 順を見つける作業は最も重要なプロセス
- 結果として得られるクエリツリーのコストに劇的に影響
- 選択可能な join 順は非常に多く全てを検証することは不可能なためスマートである必要がある
- 2 つのアプローチ
- 1: ヒューリスティクスを使用
- 2: すべての join 順を考慮
- この節ではヒューリスティクスを検討
-
ヒューリスティック4: join 順の各テーブルは、可能な限り前に選んだテーブルと結合すべき
- product は述語がないため出力レコードがフィルタリングされない
- join の述語に出会うまで無意味なレコードが伝搬されることになる
- 次はどのテーブルを最初に選ぶかを考える
- DB 業界では多くのヒューリスティクスが提案されているが、どれが最も適切かについてのコンセンサスはほとんどない
- 以下、2 つを取り上げる
-
ヒューリスティック5a: 最小の出力をするテーブルを選択
- 最も直感的
-
ヒューリスティック5b: 最も限定的な select の述語を持つテーブルを選ぶ
- クエリツリーの下位にある select の述語はコストに最も大きな影響を与える
- 5a は直感的だが 5b によるものよりもコストが高くなる傾向がある
網羅的な列挙による Join 順の選択
- 確実に最適な join 順を見つけたい場合の戦略
- n 個の join 順は
n! O(2^n) - n が 20 以下など適度に小さい場合は実用的
- lowest という配列変数を使用
- S を テーブルのセットとする
- lowest[S] には 3 つの値を含む
- S のテーブルを含む最もコストの低い結合順
- その結合順に対応するクエリツリーのコスト
- そのクエリツリーが出力するレコードの数
- アルゴリズム
- まず 2 個のテーブルの集合ごとに lowest[S] を計算
- 次に 3 個のテーブルの集合ごとに計算
- テーブルの数を増やしていってクエリ内の全テーブルの集合に到達するまで続ける
- 例
- 2 個のテーブルの lowest[S] の計算
- {T1, T2} の集合を考える
- どちらのテーブルが先であってもコストは同じ
- 最初のテーブルはヒューリスティック 5a または 5b で決定
- 3 個のテーブルの lowest[S] の計算
- {T1, T2, T3} の集合を考える
- 最もコストが低い join 順は以下を考慮することで計算できる
- lowest [{T2, T3}] joined with T1
- lowest [{T1, T3}] joined with T2
- lowest [{T1, T2}] joined with T3
- 結果は lowest[{T1, T2, T3}] として保存
- n 個のテーブルの lowest[S] の計算
- {T1, T2, ..., Tn} の集合を考える
- 最もコストが低い join 順は以下を考慮することで計算できる
- lowest [{T2, T3, ..., Tn}] joined with T1
- lowest [{T1, T3, ..., Tn}] joined with T2
- ...
- lowest [{T2, T3, ..., Tn-1}] joined with Tn
- 結果は与えられたクエリに最適な join 順となる
- 2 個のテーブルの lowest[S] の計算
最も効率的なプランの発見
- クエリ最適化の第2段階はクエリツリーを効率的なプランに変換
- プランナは leaf から順にボトムアップでプランを選択していく
- あるノードを考慮する時、そのサブツリーのブロックアクセス数がわかっている状態になる
- プランナは各ノードの実装を他のノードとは無関係に選択
- サブツリーがどのように実装されているかを気にせず、実装のコストだけを知れればよい
- ノード間の相互作用がないので、プラン生成の複雑度が低減される
- プラン生成を高速化するためのヒューリスティックもある
- ヒューリスティック6: 可能であれば select ノードの実装として IndexSelect を使用
-
ヒューリスティック7: 以下の優先順位に従って join ノードを実装する
- 可能であれば IndexJoin を使用
- 入力テーブルの 1 つが小さい場合 HashJoin を使用
- それ以外の場合は MergeJoin を使用
-
ヒューリスティック8: プランナは各 materialized ノードの子として project ノードを追加して不要なフィールドを削除
- 一時テーブルを可能な限り小さくすることで、create/scan 時のブロックアクセスを削減
- プランナは materialized ノードとその祖先が必要とするフィールドを決定し、それ以外を削除する project ノードを挿入
最適化の2つのステージの組み合わせ
- クエリツリーの構築ステージと、クエリツリーからのプラン構築ステージは、実際にはしばしば組み合わされる
- 利点
- 利便性: 直接計画を作成できる
- 正確さ: 実際のブロックアクセスを元にツリーのコストを計算できる
- 複合最適化の 2 つの例
- ヒューリスティックベース
- SimpleDB ではこちらを実装
- 列挙ベース("Selinger-style" など)
- ヒューリスティックベース
ヒューリスティックベースの SimpleDB Optimizer
- HeuristicQueryPlanner
- join 順を決定するためにヒューリスティック 5a を使用
- 最初のテーブルを決める(H1: 最も小さいものを選択)
- join 順を決める(H2: 最も小さい出力となるものを選択)
public Plan createPlan(QueryData data, Transaction tx) { // Step 1: それぞれのテーブルの TablePlanner を生成 for (String tblName : data.tables()) { TablePlanner tp = new TablePlanner(tblName, data.pred(), tx, mdm); tablePlanners.add(tp); } // Step 2: lowest-size プランを選択 Plan currentPlan = getLowestSelectPlan(); // Step 3: join order に繰り返しプランを追加 while (!tablePlanners.isEmpty()) { Plan p = getLowestJoinPlan(currentPlan); if (p != null) { currentPlan = p; } else { currentPlan = getLowestProductPlan(currentPlan); } } // Step 4: Project on the field names and return return new ProjectPlan(currentPlan, data.fields()); } - TablePlanner
- 1 つのテーブルに対する計画を作成
- constructor
- 指定されたテーブルの TablePlan を作成、index に関する情報を取得、predicate を保存
- makeSelectPlan
- そのテーブルの SelectPlan を作成
- index が使用可能な場合は IndexSelect を作成
- 最後に
addSelectPredを呼び出してテーブルに適用される predicate を決定し、SelectPlan を作成- IndexSelect は index が使われるだけなので predicate は改めて適用する必要がある
public Plan makeSelectPlan() { Plan p = makeIndexSelect(); if (p == null) { p = myPlan; } return addSelectPred(p); } - makeProductPlan
- MultiBufferProductPlan を生成
- makeJoinPlan
- IndexJoin が生成できればそれを返す
- そうでなければ ProductJoin を返す
Selinger-Style 最適化
- Pat Selinger さんが主導して考案
- 動的計画法とプラン生成を組み合わせたもの
- lowest[S] に結合順を保存するのではなく、最もコストの低いプランを保存
- アルゴリズム
- テーブルの各ペアについて最低コストのプランを計算
- 上記のプランを使用して 3 つのテーブルの各組の最低コストのプランを計算
- 全体の最低コストのプランが計算されるまで繰り返す
- コスト計算時にブロックアクセスを考慮するのがポイント
- 出力レコードが最も少ないプランではない
- なぜブロックアクセスが使えるのか?
- ヒューリスティックな最適化と異なり、部分的な結合順序を捨てないため
- より詳細なコスト分析ができる
- 例えばソートのコストを考慮することができる
- ソート済みであれば hashjoin よりも mergejoin が低コスト、といったケースにも対応できる
Merging Query Blocks
- view に言及するクエリの最適化について検討
- 基本的なクエリプランナは、view の定義とクエリを別々に計画してから結合する
- view の定義、クエリそれぞれに関するプランをクエリブロックと呼ぶ
- 個別に最適化すると、必ずしも良いものとはならない
- クエリブロックをマージして1つのクエリとして計画することで、効率の良い計画になる可能性がある
- view が複雑な場合マージが不可能になることもある
Chapter 11 JDBC Interfaces
- 組み込みインターフェースの作成は比較的簡単
- サーバーベースのインターフェースを書くにはサーバーを実行し、JDBC 要求を処理するための追加コードが必要
- Java RMI を使う方法説明
Emmbedded JDBC
- JDBC Driver のインターフェースを実装
- 合わせて
java.sql系のインターフェースも実装- Connection
- Statement
- MetaData,
- ResultSet
- 上記は基本空実装で、SimpleDB で対応している箇所だけ追加実装
- 合わせて
- SimpleIJ の実装
- Derby の ij というクライアントツールの簡易版
public class SimpleIJ { public static void main(String[] args) { Scanner sc = new Scanner(System.in); System.out.println("Connect> "); String s = sc.nextLine(); Driver d = new EmbeddedDriver(); try (Connection conn = d.connect(s, null); Statement stmt = conn.createStatement()) { System.out.print("\nSQL> "); while (sc.hasNextLine()) { // process one line of input String cmd = sc.nextLine().trim(); if (cmd.startsWith("exit")) break; else if (cmd.startsWith("select")) doQuery(stmt, cmd); else doUpdate(stmt, cmd); System.out.print("\nSQL> "); } } catch (SQLException e) { e.printStackTrace(); } sc.close(); } private static void doQuery(Statement stmt, String cmd) { try (ResultSet rs = stmt.executeQuery(cmd)) { ResultSetMetaData md = rs.getMetaData(); int numcols = md.getColumnCount(); int totalwidth = 0; // print header for (int i = 1; i <= numcols; i++) { String fldname = md.getColumnName(i); int width = md.getColumnDisplaySize(i); totalwidth += width; String fmt = "%" + width + "s"; System.out.format(fmt, fldname); } System.out.println(); for (int i = 0; i < totalwidth; i++) System.out.print("-"); System.out.println(); // print records while (rs.next()) { for (int i = 1; i <= numcols; i++) { String fldname = md.getColumnName(i); int fldtype = md.getColumnType(i); String fmt = "%" + md.getColumnDisplaySize(i); if (fldtype == Types.INTEGER) { int ival = rs.getInt(fldname); System.out.format(fmt + "d", ival); } else { String sval = rs.getString(fldname); System.out.format(fmt + "s", sval); } } System.out.println(); } } catch (SQLException e) { System.out.println("SQL Exception: " + e.getMessage()); } } private static void doUpdate(Statement stmt, String cmd) { try { int howmany = stmt.executeUpdate(cmd); System.out.println(howmany + " records processed"); } catch (SQLException e) { System.out.println("SQL Exception: " + e.getMessage()); } } }- 使用感
Connect> foodb new transaction: 1 creating new database transaction 1 committed new transaction: 2 SQL> create table T1(A int, B varchar(9)); transaction 2 committed new transaction: 3 0 records processed SQL> insert into T1(A, B) values(1, 'b'); transaction 3 committed new transaction: 4 1 records processed SQL> select A, B from T1; a b ----------------- 1 b transaction 4 committed new transaction: 5
Remote Method Invocation
- SimpleDB は Java RMI を使って DB サーバーを実装
- クライアント、サーバーがそれぞれ異なるスレッドで動作することを意識する必要がある
- (実装予定の)RemoteDriver オブジェクトはクライアントから呼び出されるまで休止
Remote Interface の実装
- RemoteDriverImpl
- SimpleDB サーバーへのエントリポイント
- DB サーバーによって生成され RMI レジストリで公開される
- 接続メソッドが呼ばれるたびに、RemoteConnectionImpl を生成し、新しいスレッドで実行
- RMI は透過的に RemoteConnection スタブオブジェクトを生成をクライントに返す
- 上記のタスクは UnicastRemoteObject が実施(実装には表れない)
- 合わせて以下も実装
- RemoteConnection
- RemoteStatement
- executeUpdate を実装するたびにトランザクションは commit する実装
- RemoteMetaData
- RemoteResultSet
- 上記は
java.sqlの対応インターフェースは実装しておらず、あくまで RMI に対応するためのもの- それぞれの実装クラスは
UnicastRemoteObjectを継承
- それぞれの実装クラスは
- 例: RemoteConnectionImpl
public class RemoteConnectionImpl extends UnicastRemoteObject implements RemoteConnection { private SimpleDB db; private Transaction currentTx; private Planner planner; public RemoteConnectionImpl(SimpleDB db) throws RemoteException { this.db = db; currentTx = db.newTx(); planner = db.planner(); } // 省略 }- java.sql.Connection は実装していない
-
RemoteConnectionは自分で定義したインターフェース
-
- java.sql.Connection は実装していない
JDBC Interface の実装
- RMI のリモートクラスの実装は java.sql の JDBC インターフェースを満たせていない
- SQLException を投げることや、java.sql の Driver, Connection インターフェースを実装する必要がある
- Remote*** に対する JDBC インターフェースを満たすラッパークラスを実装
- NetworkConnection
- NetworkStatement
- NetworkMetaData
- NetworkResultSet
- 例: NetworkConnection
public class NetworkConnection extends ConnectionAdapter { private RemoteConnection rConn; public NetworkConnection(RemoteConnection rConn) { this.rConn = rConn; } @Override public Statement createStatement() throws SQLException { try { RemoteStatement rStmt = rConn.createStatement(); return new NetworkStatement(rStmt); } catch (Exception e) { throw new SQLException(e); } } // 省略 }- ConnectionAdaptor は java.sql.Connection を実装した抽象クラス
- 実装はほぼ空でインターフェースを満たすためだけに配置
- ConnectionAdaptor は java.sql.Connection を実装した抽象クラス
- NetworkDriver の実装
- SimpleIJ で利用するドライバー
- RMI の registry を用いて RemoteDriver を取得して java.sql.Connection を実装した NetworkConnection を生成して返す
public class NetworkDriver extends DriverAdapter { public Connection connect(String url, Properties prop) throws SQLException { try { String host = url.replace("jdbc:simpledb://", ""); Registry reg = LocateRegistry.getRegistry(host, 1099); RemoteDriver rDrv = (RemoteDriver) reg.lookup("simpledb"); RemoteConnection rConn = rDrv.connect(); return new NetworkConnection(rConn); } catch (Exception e) { throw new SQLException(e); } } } - 使用感
- サーバー起動
- クライアント起動
- サーバー起動

このスクラップは2023/09/02にクローズされました