Snowflakeへの既存環境データ投入時の小TIPS(時系列で並べる)
この記事はSnowflake Advent Calendar 2023のPart2の2日目です。
Part2の1日目はindigo13loveさんの「Snowflake における CTE のマテリアライズ」でした。
Part1の1日目はAkira Sakatokuさんの「Snowflake×Streamlit×PyGWalkerの始め方」でした。
2日目にして一気にハードルを下げていきたいと思います。
はじめに
前段として、(実運用が始まってから)Snowflakeに日々入ってくるデータは、そこまでプルーニング!!!とか気にしなくても大丈夫です… という内容をSnowflake Data Superheroの渋谷さんが2022年のアドベンドカレンダーで書いてくれてます。
つまり、時系列で蓄積されるテーブルにおいて、日付、タイムスタンプ、インクリメンタルな数値などは、何もしなくてもその順番の通りに並んでパーティションが形成されていくため、自然とプルーニングが効くことになります。
プルーニングには設定という概念はなく、自動的に勝手に行ってくれるため、もちろん利用は無料です。一方で、プルーニングが効くかどうかで、性能ひいてはSnowflakeの利用コストも大きく変わってきます。
(もちろん必要に応じて明示的にクラスタリングキーを設定することで、性能を向上させることも出来ます)
わりと忘れがちな気にしないといけない場合
そんなわけで自動でプルーニングが効くシーンが多いのですが、実は導入前の「ちょっと試してみようかな? 既存環境のデータをCOPYして入れて試してみようかな?」のときは、ちょっとだけ気にしてあげてくださいというお話です。もちろん本番運用開始前の「既存環境のデータを一括でCOPYして全部入るぞ」のときも同様です。
参考としてデータロード時の話
ちなみにこれが本日伝えたいことではないのですが… データロードの際は大きなファイル(100GB以上)1をロードするよりも、分割してあげたほうが早くなることがドキュメントに書いてあったりします。これはChatGPTに「Snowflakeにデータを一括投入するときの注意事項はありますか?」って聞いても教えてくれます。GPT-4賢い
ここからもわかるように、データロードは並列処理で実施するので、元データの並んでいる順番は気にしないのです。なので↓が当てはまらなくなります。
つまり、時系列で蓄積されるテーブルにおいて、日付、タイムスタンプ、インクリメンタルな数値などは、何もしなくてもその順番の通りに並んでパーティションが形成されていくため、自然とプルーニングが効くことになります。
一括データ投入時に時系列で並べた方がいい(ことが多い)
データを既存環境からSnowflakeに一括ロードする場合は、COPYで一括投入してそのまま使いがちですが、(時系列で追加されるデータ想定している場合は)明示的に時系列で並べておいたほうが、より効率的にプルーニング効くとかいい場合が多いですよという話。もちろん分析側の要件次第なんでフワッとした表現になっちゃうんですが…
これは2023年12月01日現在GPT-4も教えてくれないかつ、よく説明しているので解説とかいうか、実際に試してみます。
試してみる
SnowflakeのハンズオンでおなじみのCITIBIKEのデータを見てみます。
CSVをS3からCOPYしただけ(よくある状態)
COPYで一括投入してみます。CSVから61,468,359レコード
copy into trips FROM @citibike_trips file_format=CSV ;
2015年のデータだけ見てみる
SELECT * FROM TRIPS
WHERE STARTTIME >= '2015-01-01 00:00:00'
AND STARTTIME < '2016-01-01 00:00:00';
このときのクエリ履歴を見てみます。みんな大好きクエリ履歴
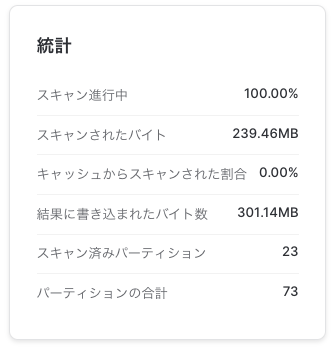
23/73パーティーション見てました。スキャンしたのは239.46MB。2015年のデータが23個のパーティションに分散して格納されてるってことですね。
時系列で並び替えてみる(CTAS + ORDER BY STARTTIME)
(上のTRIPSテーブルを元に)CTAS+ORDER BYで並び替えたテーブル作ってみる。これが実利用開始後のデータに近いイメージ(実際には空の状態から日々入ってくるはずなので)
CREATE TABLE TRIPS_SORTED
AS SELECT * from TRIPS
ORDER BY STARTTIME;
同様に2015年のデータだけ見てみる
SELECT * FROM TRIPS_SORTED
WHERE STARTTIME >= '2015-01-01 00:00:00'
AND STARTTIME < '2016-01-01 00:00:00';
こちらもクエリ履歴を見てみます
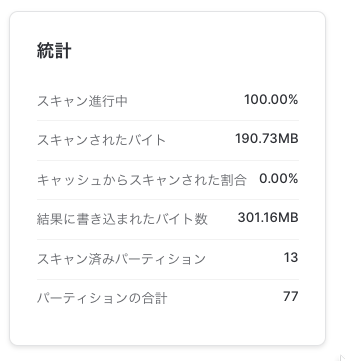
こっちは13/77パーティーション見てました。スキャンしたのは190.73MB。2015年のデータが13個のパーティションに格納されてる。スキャン対象が減った!(13個のパーティションに集めて入ってる感じ)
参考:BIKEIDが15000から20000の利用だけ見てみる
SELECT * FROM TRIPS_SORTED
WHERE BIKEID BETWEEN 15000 AND 20000;
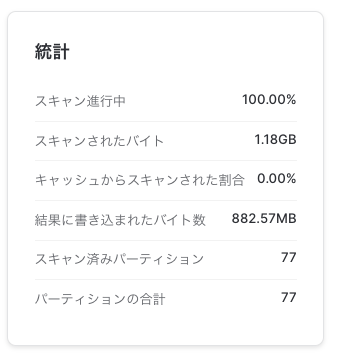
こっちは77/77スキャンしてしまう。
逆に時系列はバラバラにしてみる(CTAS + ORDER BY BIKEID)
ためしに時系列じゃない列でソートしてみる。要件によってはこれが合うこともあるのかもしれない…
CREATE TABLE TRIPS_BIKE_SORTED
AS SELECT * from TRIPS
ORDER BY BIKEID;
SELECT * FROM TRIPS_BIKE_SORTED
WHERE STARTTIME >= '2015-01-01 00:00:00'
AND STARTTIME < '2016-01-01 00:00:00';
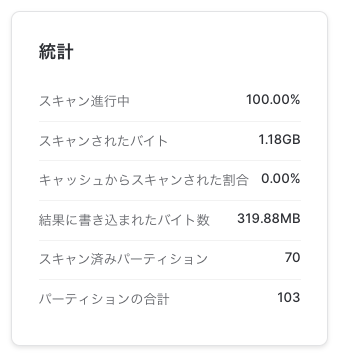
こっちは70/103パーティーション見てました。スキャンしたのは1.18GB。一気に増えた!
参考:BIKEIDが15000から20000の利用だけ見てみる
SELECT * FROM TRIPS_BIKE_SORTED
WHERE BIKEID BETWEEN 15000 AND 20000;
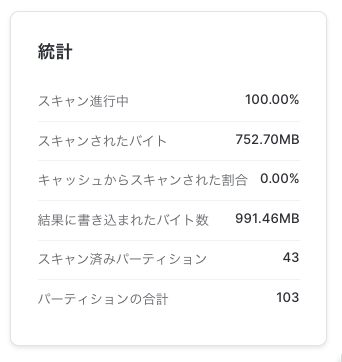
参考:クラスタリングキー設定してみる(CLUSTER BY(STARTTIME))
テーブル作成時にSTARTTIMEでクラスタリングキー設定してみます。既存デーブルに後からも設定できます。
クラスタリングキーを設定すると、自動的にマイクロパーティションが指定されたキーで自動クラスタリングされ続けます(クラスタリングのメンテナンス費用がかかります。詳しくはドキュメントで)
CTASと同時に設定する場合
CREATE TABLE TRIPS_CLUSTERED
CLUSTER BY(STARTTIME)
AS SELECT * from TRIPS;
既存テーブルに適用する場合はこちら
ALTER TABLE TRIPS_CLUSTERED CLUSTER BY(STARTTIME);
で、2015年のデータだけ見てみる
SELECT * FROM TRIPS_CLUSTERED
WHERE STARTTIME >= '2015-01-01 00:00:00'
AND STARTTIME < '2016-01-01 00:00:00';
クエリ履歴

こっちは20/127パーティーション見てました。スキャンしたのは189.41MB。スキャン対象のバイト数はORDER BY STARTTIMEしたときと同じくらい。
まとめ
既存環境のデータをSnowflakeを一括投入する場合は、ただCOPYだけでもいいけど明示的に時系列で並べておくと「より効率的にプルーニング効くことが多い」ですよーというお話でした。想定してたパフォーマンスが出ない場合とか、思い出したり試してみたりしてください。
なるほど、こうゆう場合も
この記事はSnowflake Advent Calendar 2023の2日目でした。3日目はtoru_hiyamaさんの「2023年のSnowpark for Python関連のリリースを振り返る」です。
Discussion