Snowflake における CTE のマテリアライズ
この記事は Snowflake Advent Calendar 2023 Series 2 の 1 日目です。
Disclaimer
筆者は Snowflake でパフォーマンスエンジニアをやっている者ですが、この記事はオフィシャルな文書ではなく、また 2023 年 12 月時点での動作となります。
CTE (Common Table Expression) とは
CTEとは何ですか?
CTE(共通テーブル式)は、 WITH 句で定義された名前付きサブクエリです。CTE は、 CTE 定義するステートメントで使用する仮の ビュー と考えることができます。CTE は、仮のビューの名前、オプションの列名のリスト、およびクエリ式(つまり、 SELECT ステートメント)を定義します。クエリ式の結果は事実上テーブルになります。そのテーブルの各列は、列名の(オプションの)リスト内の列に対応しています。
例えば、下記のようなネストしたサブクエリなどがあった場合、
select key, sum(value)
from (
select keys.key, t2.value
from (
select t0.key || t1.key
from t0
join t1 on t0.id = t1.id
) keys
join t2 on keys.key = t2.key
)
group by key
;
CTE を使うと、
with
keys as (
select t0.key || t1.key
from t0
join t1 on t0.id = t1.id
),
pairs as (
select keys.key, t2.value
from keys
join t2 on keys.key = t2.key
)
select key, sum(value)
from pairs
group by key
;
のように書けるのでわかりやすくなる、という機能になります。
Snowflake における CTE のマテリアライズ
いくつかのデータベース製品では CTE はマテリアライズ、つまり CTE の処理結果を一時テーブルのような形で再利用可能な状態に実体化し、クエリ内で参照されることがあります。
Snowflake では、常に CTE 内に記述された処理の結果がそのままマテリアライズされるわけではなく、一部の例外を除いて、一度サブクエリやインラインビューとして解釈・展開され、CTE 外のフィルタや集約とマージした上で適宜マテリアライズされます。
この記事では、どういった条件で CTE のマテリアライズが発生するかを説明していきます。
CTE がマテリアライズされないケース
まず、マテリアライズされるケースの前に、CTE がサブクエリと同様に展開されるケースを説明します。
これ以降の説明では、下記の 0〜999999 の値が格納された 100 万行のテーブル t1 を使用します。
create or replace table t1 (c1 int) as
select seq4()
from table(generator(rowcount => 1000000))
;
CTE が 1 回のみ参照されるケース
下記の 2 つのクエリは、WHERE 句の位置が CTE 内と CTE 外と異なる配置になっていますが、CTE が展開されて解釈されるため、どちらも同じ実行計画となります。
with
cte1 as (
select c1
from t1
)
select c1
from cte1
where c1 > 10000
;
with
cte1 as (
select c1
from t1
where c1 > 10000
)
select c1
from cte1
;

CTE としての処理は残っておらず、TableScan + Filter という形で処理されています。
同様に、CTE がネストしていても、各 CTE が 1 回しか参照されていない場合には、展開されて解釈されます。
下記のクエリでは、CTE1 内で T1 が C1 > 10000 の条件でフィルタされ、CTE2 内でさらに CTE1 の結果が C1 < 100000 の条件でフィルタされているような記述になっています。
しかし、実際の処理としてはどちらも展開され、(C1 > 10000) AND (C1 < 100000) というフィルタとして処理されます。
with
cte1 as (
select c1
from t1
where c1 > 10000
),
cte2 as (
select c1
from cte1
where c1 < 100000
)
select c1
from cte2
;

これは下記のように WHERE 句が CTE 内と CTE 外にあるケースでも同じ動作になります。
with
cte1 as (
select c1
from t1
),
cte2 as (
select c1
from cte1
where c1 > 10000
)
select c1
from cte2
where c1 < 100000
;
CTE がマテリアライズされるケース
次に CTE がマテリアライズされるケースですが、これは当該 CTE がクエリ内で複数回参照されているケースになります。
例えば、下記のようなクエリがあるとします。
with
cte1 as (
select c1
from t1
where c1 > 10000
),
cte2 as (
select c1
from t1
where c1 < 100000
)
select *
from cte1
join cte2 using (c1)
;
このクエリは CTE1 と CTE2 それぞれで T1 にアクセスしていますが、それぞれの CTE は 1 回ずつしか参照されていないため、それぞれ展開され、T1 へのテーブルスキャンが 2 回発生する形となります。
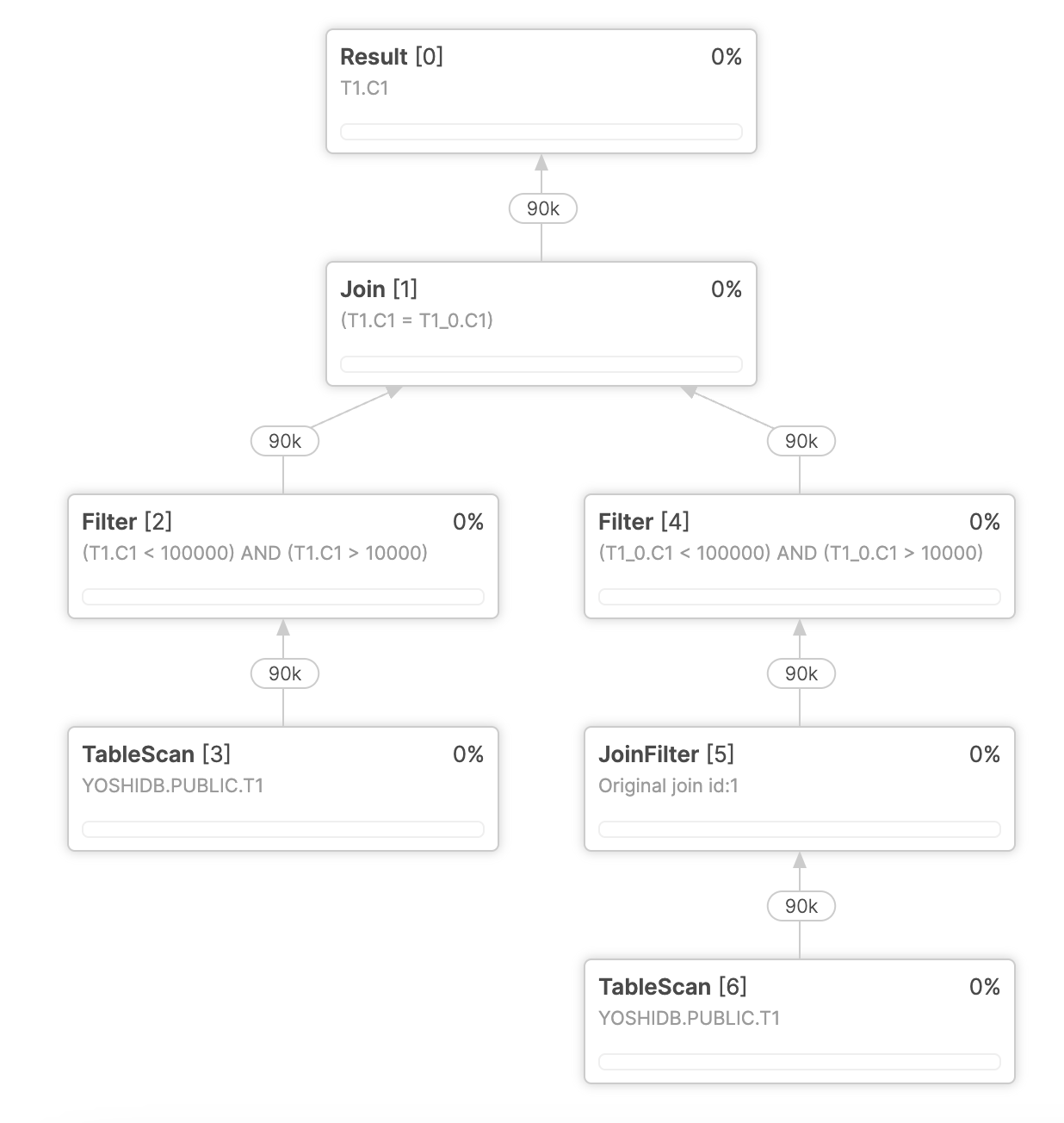
ここで、このクエリに T1 へのテーブルスキャンをラップしただけの CTE0 を追加した、下記のようなクエリについて考えます。
with
cte0 as (
select c1
from t1
),
cte1 as (
select c1
from cte0
where c1 > 10000
),
cte2 as (
select c1
from cte0
where c1 < 100000
)
select *
from cte1
join cte2 using (c1)
;
このクエリは、セマンティクス的には元のクエリと同じになりますが、CTE0 が複数回参照されているため、CTE0 がマテリアライズされることになり、結果として T1 のテーブルスキャンが 1 回のみとなります。

プロファイル内に WithClause および WithReference というオペレータが出現し、TableScan が 1 つになっていることが確認できます。
ただし、ここで CTE0 は記述そのままの結果がマテリアライズされているわけではないという点に注意してください。
CTE0 は本来 SELECT C1 FROM T1、すなわち T1 から全行読み込むだけの CTE ですが、当該プロファイルを確認すると、TableScan と WithClause の間に Filter がプッシュダウンされています。
したがって、マテリアライズされている結果は、本来の SELECT C1 FROM T1 の結果ではなく、SELECT C1 FROM T1 WHERE (C1 > 10000) AND (C1 < 100000) の結果であるということがわかります。
このように、CTE がマテリアライズされるケースでも、可能な限りフィルタや集約のプッシュダウンは適用されるため、Snowflake における CTE のマテリアライズは、必ずしも CTE そのもののマテリアライズではない、という形となります。
例外: CTE が定数化されるケース
下記のような例外的なケースでは、CTE が記述そのままの結果としてマテリアライズされます。厳密には、これらの最適化は CTE だけでなくサブクエリにも適用されます。
CTE がコンパイル時に定数に置換できるケース
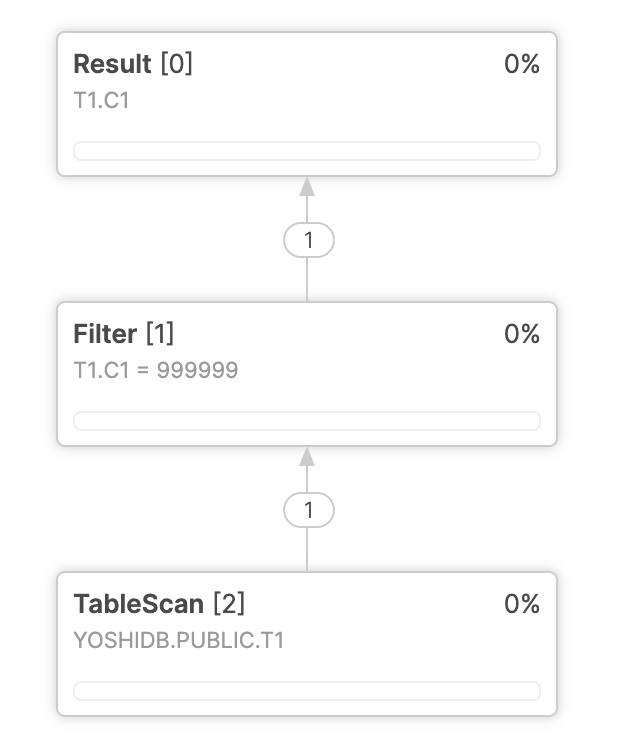
マイクロパーティションのメタデータなどから、クエリコンパイルの時点で CTE の結果が 1 つの定数に置換できることが確定できる場合、CTE 全体があらかじめ定数に置換されるため、結果としてマテリアライズされる形となります。
例えば、下記のようなクエリがあった場合、MAX(C1) はマイクロパーティションのメタデータから確定できるため、コンパイルの時点で置換されます。
with
cte1 as (
select max(c1) c1
from t1
)
select c1
from t1
where c1 = (select c1 from cte1)
;
下記のプロファイルを見ると、CTE1 に対応する TableScan が存在せず、Filter 内で当該 CTE の結果が 99999 という定数に置換されていることが確認できます。
CTE が実行時に定数に置換できるケース
クエリコンパイル時には何の値になるか確定できず、定数に置換することができないものの、実行時には結果が 1 つの定数になる場合、まず最初にその CTE を処理し、後続の処理中では前段の処理結果を参照する形になります。
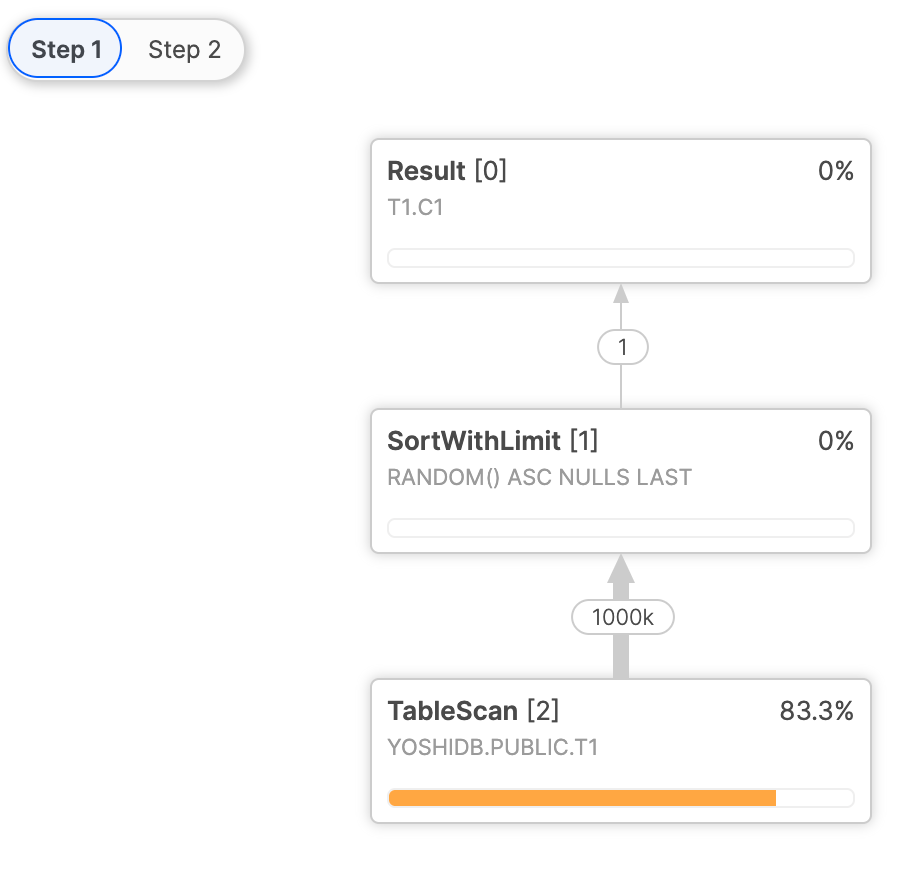
例えば、下記のクエリは ORDER BY RANDOM() LIMIT 1 でランダムな 1 行を抽出しているため、コンパイル時には結果を確定することができませんが、実行時に定数として評価することはできます。
with
cte1 as (
select c1
from t1
order by random()
limit 1
)
select c1
from t1
where c1 = (select c1 from cte1)
;
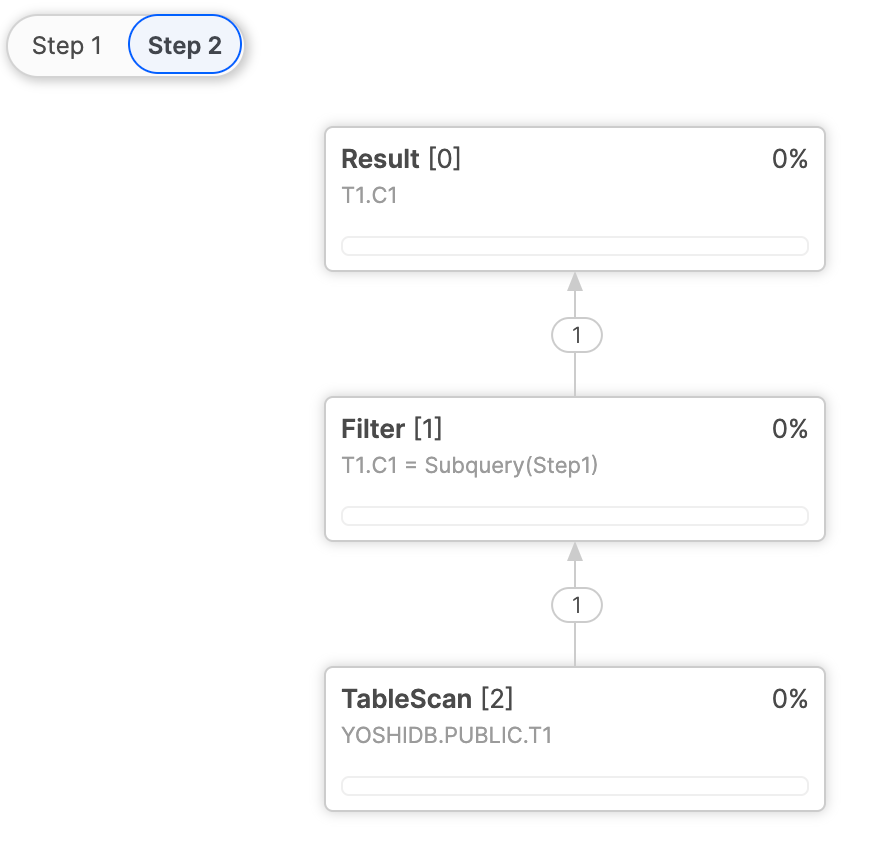
この場合、下記のように Step 1 でまず CTE1 の処理を行い、後続する Step 2 の Filter で Subquery(Step1) として Step 1 の処理結果を参照しています。
CTE のマテリアライズは常に狙うべきか?
結論としては、常に有効なわけではありません。
例えば、下記のようなクエリを考えます。
create or replace table t_big (c1 int) as
select seq4()
from table(generator(rowcount => 1000000000))
;
with
cte1 as (
select c1
from t_big
where c1 < 5
),
cte2 as (
select c1
from t_big
where c1 < 500000000
)
select *
from cte1
join cte2 using (c1)
;
このクエリでは、10 億行のテーブル T_BIG から、CTE1 は C1 < 5 である 5 行を、CTE2 は C1 < 500000000 である 5 億行を読み込み、C1 で結合しています。
これを素直にこのまま実行すると、CTE2 に結合フィルタが適用され、実行時プルーニングで 5 行のみが読み込まれるため、テーブルスキャン量を抑えることができます。

実際、このクエリは XSMALL 仮想ウェアハウスで 200-250 ミリ秒程度で完了します。
一方で、これに CTE0 を追加して、CTE のマテリアライズが適用されるような書き換えを考えます。
with
cte0 as (
select c1
from t_big
),
cte1 as (
select c1
from cte0
where c1 < 5
),
cte2 as (
select c1
from cte0
where c1 < 500000000
)
select *
from cte1
join cte2 using (c1)
;
このとき、CTE1 と CTE2 のフィルタは範囲が重複しているため、C1 < 5 は実質的に無視され、C1 < 500000000 がテーブルスキャンにプッシュダウンされることとなります。
すなわち、このクエリは
-
T_BIGからC1 < 500000000の条件で 5 億行スキャンする - WithClause/WithReference が 5 億行の中間結果を複製する
- 複製した中間結果を結合する (このときに初めて結合フィルタが適用される)
という形で処理されます。
結果として、元のクエリは計 10 行のスキャンで処理できていたクエリが、5 億行のスキャンと 5 億行の複製を必要とするクエリとして処理されてしまう形となります。

実際に、このクエリは同じ XSMALL 仮想ウェアハウスで 5-6 秒程度 (約 20-30 倍) かかるクエリとなってしまいます。
また、下記のように、外部結合で結合フィルタの影響を排除した場合についても考えてみます。
with
cte1 as (
select c1
from t_big
where c1 < 5
),
cte2 as (
select c1
from t_big
where c1 < 500000000
)
select count(*)
from cte1
right join cte2 using (c1)
;
このクエリは 5 億行側が外部結合の外側になっているため、結合フィルタによるプルーニングが適用できないため、下記のような素朴な手順で処理されます。
-
CTE1がC1 < 5の条件で 5 行スキャン -
CTE2がC1 < 500000000の条件で 5 億行スキャン - 結合して集約
結果、このクエリは XSMALL 仮想ウェアハウスで 1.5-2 秒程度で完了します。
一方で、このクエリに CTE0 を導入し、CTE がマテリアライズされるようにした下記のクエリについても考えます。
with
cte0 as (
select c1
from t_big
),
cte1 as (
select c1
from cte0
where c1 < 5
),
cte2 as (
select c1
from cte0
where c1 < 500000000
)
select count(*)
from cte1
right join cte2 using (c1)
;
このクエリでは C1 < 5 の条件は C1 < 500000000 に包含されているため、
-
CTE0がC1 < 500000000の条件で 5 億行スキャン -
CTE0の 5 億行の結果を複製 - 結合して集約
という手順で処理されることになります。
この手順を CTE 再利用がないクエリの手順と比較すると、これらのクエリの実行時間の差は
-
CTE1がC1 < 5の条件で 5 行スキャン -
CTE0の 5 億行の結果を複製
の差になり、明らかに 5 行のスキャンのほうが高速に処理することができそうです。
実際、このクエリを実行すると XSMALL 仮想ウェアハウスで 6-7 秒程度かかるため、CTE がマテリアライズされるケースのほうが遅い形となります。
したがって、
- 対象のテーブルが大きい
- 複製される CTE の中間結果が大きい
- 特に、各参照箇所のフィルタの選択性に大きな差があり、また包含関係がある
といったケースでは、CTE のマテリアライズが逆効果となる場合があります。
そのため、もしプロファイル中で WithClause や WithReference が占める実行時間の割合が大きいことが確認された場合、むしろマテリアライズされている CTE を削除して、それぞれの利用箇所で元テーブルを参照するように書き換えることで、パフォーマンスが改善する場合もあります。
まとめ
CTE がマテリアライズされるケースは、単純に「CTE が複数回参照された場合」のみなので、知識として持ってしまえば仕組み自体はとても簡単です。
しかし、常に再利用されたほうがいいわけでもないところが難しい部分となるので、状況に応じて使い分けられるように、仕組みを理解しておくことが重要になるかなと思います。
とはいえ、実際バッドノウハウ感はあるので、最終的には「どっちで書いてもコンパイラがインテリジェントに使い分けられるようになる」というのを目指したいなあとは思っております。
Discussion