超高速DataFrameライブラリー「Polars」について
はじめに
ここ最近、Polarsについて調べる中で色々と面白そうだと思い現在勉強中です。今回の記事では勉強内容の整理も兼ねて、Polarsの特色を紹介できればと思っています。
Polarsとは
RustとPythonで使える[1]超高速("Blazingly fast")DataFrameライブラリー、つまりデータ解析に使えるライブラリーとなります。pandasに対するPolars(しろくま)であり洒落ているなと思います。
Core部分はRustで実装されており、インターフェースとしてPythonからも呼び出せるようになっています。RustからPythonパッケージへのビルドはmaturin(PyO3)を使っています。
環境
記事作成時のOSや言語、ライブラリーのバージョンは以下になります。関連が強そうなもののみ抜粋しています。
Ubntu 22.04
Python 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] on linux
maturin 0.13.7
pandas 1.5.2
polars 0.15.2
pyarrow 11.0.0.dev141
cargo 1.67.0-nightly (eb5d35917 2022-11-17)
rustc 1.67.0-nightly (ff8c8dfbe 2022-11-22)
なお、Polars自体はまだまだ開発中であり日々更新されています。(この記事を書いている間にもバージョンが0.15.6まで更新されています!)
高速化の背景
データフォーマット
Apache Arrowという列指向のインメモリ型データフォーマットをベースにしてライブラリーが実装されています。より正確に言うと、Arrow2というApach Arrow形式のcrateを使って実装しています。結果、そもそものデータ処理が速いです。実際に定義されているデータ型についてはユーザーガイドに説明があります。
Lazy API
PolarsではDataFrameを操作するクエリーについて、評価するタイミングを"Lazy"(遅延的)か"Eager"(逐次的)か分けることができます。Lazyにした場合、Polarsではクエリー間の並列化と最適化をプランニングするため、さらなる高速化を実現できます。
いくつか例[2]を提示してみます。
>>> import polars as pl
>>> pl.Config.set_tbl_rows(2) # 行の表示省略のため
<class 'polars.cfg.Config'>
>>> pl.read_csv("PS.csv", skip_rows=290)
shape: (33796, 287)
┌───────┬──────────┬──────────┬───────────┬─────┬─────────┬──────────┬───────────┬──────────────┐
│ rowid ┆ pl_name ┆ hostname ┆ pl_letter ┆ ... ┆ st_nrvc ┆ st_nspec ┆ pl_nespec ┆ pl_ntranspec │
│ --- ┆ --- ┆ --- ┆ --- ┆ ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ str ┆ ┆ i64 ┆ i64 ┆ i64 ┆ i64 │
╞═══════╪══════════╪══════════╪═══════════╪═════╪═════════╪══════════╪═══════════╪══════════════╡
│ 1 ┆ 11 Com b ┆ 11 Com ┆ b ┆ ... ┆ 2 ┆ 0 ┆ 0 ┆ 0 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ ... ┆ ... ┆ ... ┆ ... ┆ ... ┆ ... ┆ ... ┆ ... ┆ ... │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 33796 ┆ xi Aql b ┆ xi Aql ┆ b ┆ ... ┆ 1 ┆ 0 ┆ 0 ┆ 0 │
└───────┴──────────┴──────────┴───────────┴─────┴─────────┴──────────┴───────────┴──────────────┘
>>> (df := pl.scan_csv("PS.csv", skip_rows=290))
<polars.LazyFrame object at 0x7F99301331C0>
>>> df.collect()
shape: (33796, 287)
┌───────┬──────────┬──────────┬───────────┬─────┬─────────┬──────────┬───────────┬──────────────┐
│ rowid ┆ pl_name ┆ hostname ┆ pl_letter ┆ ... ┆ st_nrvc ┆ st_nspec ┆ pl_nespec ┆ pl_ntranspec │
│ --- ┆ --- ┆ --- ┆ --- ┆ ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ str ┆ ┆ i64 ┆ i64 ┆ i64 ┆ i64 │
╞═══════╪══════════╪══════════╪═══════════╪═════╪═════════╪══════════╪═══════════╪══════════════╡
│ 1 ┆ 11 Com b ┆ 11 Com ┆ b ┆ ... ┆ 2 ┆ 0 ┆ 0 ┆ 0 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ ... ┆ ... ┆ ... ┆ ... ┆ ... ┆ ... ┆ ... ┆ ... ┆ ... │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 33796 ┆ xi Aql b ┆ xi Aql ┆ b ┆ ... ┆ 1 ┆ 0 ┆ 0 ┆ 0 │
└───────┴──────────┴──────────┴───────────┴─────┴─────────┴──────────┴───────────┴──────────────┘
read_csvがcsvの読み込み結果を逐次的に返しているのに対し、scan_csvはコール時点ではLazyFrameオブジェクトを返しています。その後のcollectによって読み込み処理が遅延評価されています。
もう少し処理を追加して最適化や並列化の効果について確認します。
import polars as pl
def main() -> None:
radius_by_method = (
pl.scan_csv("PS.csv", skip_rows=290)
.groupby("discoverymethod")
.agg([
pl.count(),
pl.col("pl_rade").mean().alias("Planet Radius [Earth Radius]"),
pl.col("pl_rade").max().alias("Max. Planet Radius"),
pl.col("pl_rade").min().alias("Min. Planet Radius"),
])
.sort("count", reverse=True)
.limit(4)
)
print(radius_by_method.collect())
if __name__ == "__main__":
main()
系外惑星の観測手法ごとにグループ分けし、惑星半径の平均値と最大値、最小値を算出します[3]。
Eagerな場合
scan_csvがread_csvに変わっただけです。
import polars as pl
def main() -> None:
radius_by_method = (
pl.read_csv("PS.csv", skip_rows=290)
.groupby("discoverymethod")
.agg([
pl.count(),
pl.col("pl_rade").mean().alias("Planet Radius [Earth Radius]"),
pl.col("pl_rade").max().alias("Max. Planet Radius"),
pl.col("pl_rade").min().alias("Min. Planet Radius"),
])
.sort("count", reverse=True)
.limit(4)
)
print(radius_by_method)
if __name__ == "__main__":
main()
$ time python lazy_example.py
shape: (4, 5)
┌───────────────────────────┬───────┬──────────────────────────────┬────────────────────┬────────────────────┐
│ discoverymethod ┆ count ┆ Planet Radius [Earth Radius] ┆ Max. Planet Radius ┆ Min. Planet Radius │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ u32 ┆ f64 ┆ f64 ┆ f64 │
╞═══════════════════════════╪═══════╪══════════════════════════════╪════════════════════╪════════════════════╡
│ Transit ┆ 30802 ┆ 5.111434 ┆ 3791.05 ┆ 0.27 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Radial Velocity ┆ 2270 ┆ 7.211939 ┆ 16.264 ┆ 1.211 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Microlensing ┆ 430 ┆ null ┆ null ┆ null │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Transit Timing Variations ┆ 120 ┆ 2.206051 ┆ 3.01 ┆ 0.37 │
└───────────────────────────┴───────┴──────────────────────────────┴────────────────────┴────────────────────┘
real 0m0.793s
user 0m0.784s
sys 0m0.040s
$ time python eager_example.py
shape: (4, 5)
┌───────────────────────────┬───────┬──────────────────────────────┬────────────────────┬────────────────────┐
│ discoverymethod ┆ count ┆ Planet Radius [Earth Radius] ┆ Max. Planet Radius ┆ Min. Planet Radius │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ u32 ┆ f64 ┆ f64 ┆ f64 │
╞═══════════════════════════╪═══════╪══════════════════════════════╪════════════════════╪════════════════════╡
│ Transit ┆ 30802 ┆ 5.111434 ┆ 3791.05 ┆ 0.27 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Radial Velocity ┆ 2270 ┆ 7.211939 ┆ 16.264 ┆ 1.211 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Microlensing ┆ 430 ┆ null ┆ null ┆ null │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Transit Timing Variations ┆ 120 ┆ 2.206051 ┆ 3.01 ┆ 0.37 │
└───────────────────────────┴───────┴──────────────────────────────┴────────────────────┴────────────────────┘
real 0m0.916s
user 0m9.997s
sys 0m0.184s
そもそもの並列化性能が良くて実時間にほぼ差はありませんが、user timeに大きな差が見られます。これはLazy時の最適化による効果だと認識しています。
show_graphメソッドを使うとLazyFrameのクエリープランを可視化することができます。
radius_by_method.show_graph(optimized=True, show=False, output_path="optimized.png")
radius_by_method.show_graph(optimized=False, show=False, output_path="no_optimized.png")
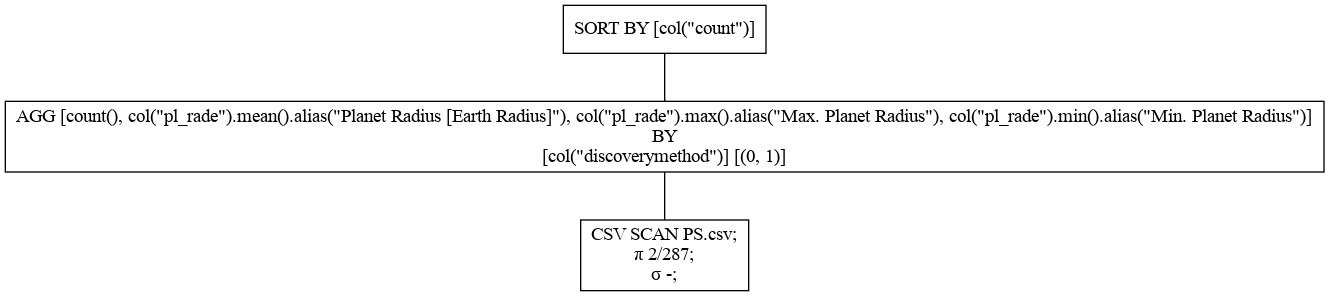
最適化あり
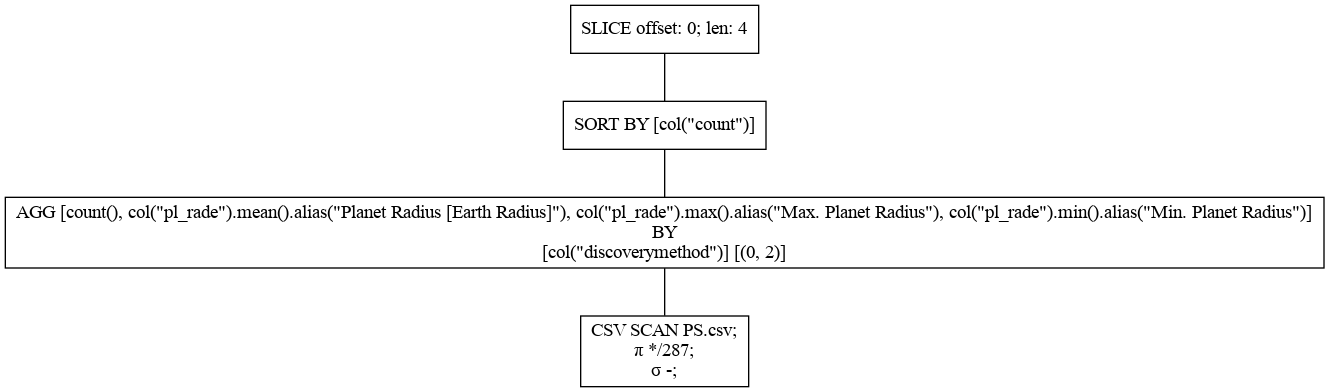
最適化なし
上が最適化あり、下が最適化なしのクエリープランです。CSV SCANの違いはわかりやすいかと思います。最適化ありでは
参考: EagerからLazyへの変換
lazyメソッドを使うことでEagerからLazyへ切り替えることが可能です。
@@ -6,2 +6,3 @@
pl.read_csv("PS.csv", skip_rows=290)
+ .lazy()
.groupby("discoverymethod")
@@ -16,3 +17,3 @@
)
- print(radius_by_method)
+ print(radius_by_method.collect())
最適化について補足
optimize内を見ると、クエリープランに対する各種最適化を追うことができます。各最適化ルールの概要を現在理解できている範囲で記載します。
-
PredicatePushDown
複数のfilter処理があった場合に、それらを結合しデータ読み込み時に合わせて行うようにします。以下に例を示します。
>>> import polars as pl
>>> qp = (
... pl.scan_csv("PS.csv", skip_rows=290)
... .filter(pl.col("pl_rade") > 10)
... .filter(pl.col("pl_masse") < 10)
... .select([
... "rowid", "pl_name", "hostname", "discoverymethod", "pl_rade", "pl_masse"
... ])
... )
>>> qp.collect()
shape: (1, 6)
┌───────┬─────────────┬───────────┬─────────────────┬─────────┬──────────┐
│ rowid ┆ pl_name ┆ hostname ┆ discoverymethod ┆ pl_rade ┆ pl_masse │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ str ┆ f64 ┆ f64 │
╞═══════╪═════════════╪═══════════╪═════════════════╪═════════╪══════════╡
│ 25028 ┆ Kepler-51 d ┆ Kepler-51 ┆ Transit ┆ 11.8 ┆ 6.2 │
└───────┴─────────────┴───────────┴─────────────────┴─────────┴──────────┘
>>> qp.show_graph(optimized=False, show=False, output_path="no_optimized.png")
>>> qp.show_graph(optimized=True, show=False, output_path="optimized.png")
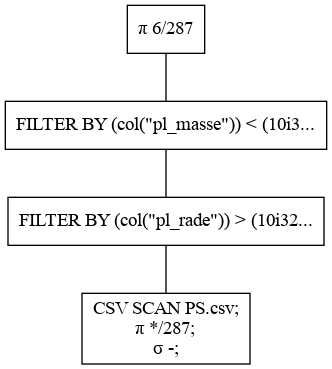
最適化なし
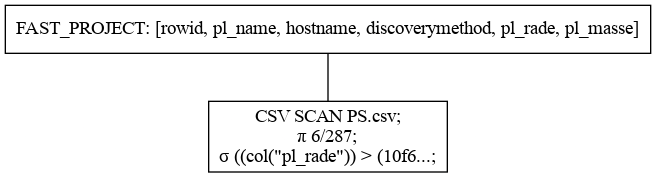
最適化あり
-
ProjectionPushdown
データスキャン時など列の読み込みを最適化、つまりクエリープランで必要となる列のみを読み込みます。Lazy APIで挙げた例もこちらに該当する認識です。 -
TypeCoercionRule
異なるデータ型を持つ列が比較される際の型キャストのルールを定義しています。 -
SimplifyBooleanRule
x and falseやx and trueなど結果が自明なboolean演算を実際の演算前に単純化します。 -
SimplifyExprRule
可換性のある演算やnull演算など実際の演算前にクエリー操作側を単純化します。
Out of Core
最適化によりメモリも節約されるのですが、それでも扱うデータがRAMに収まらない場合はcollect(streaming=True)とstreamingオプションを指定すれば良いとissueにはあります。ただし、こちらはまだアルファ版の機能となるようです。(API referenceより)
その他
並列化やメモリ効率についてはPolarsのAuthorであるRitchie氏が書いた技術記事も参考になります。(証明書の期限切れかもなので閲覧は自己責任でお願いします…)
pandasとの違い
ユーザーガイドにもpandasから来た人向け[4]に違いを記載したページがあるので、ここまでに説明してきた並列化や最適化以外の部分を抜粋して紹介します。
indexについて
PolarsではDataFrameにindexがありません。Lazy APIが基本なので、indexの保持や存在は並列化を阻害する認識です。付随してpandasのilocやlocに相当するメソッドもありません。(正確に言うと、非推奨ですがEagerモードのみに実装はされているようです。参考
→ ユーザーに混乱を与える可能性があるとして、2023年1月末頃にユーザーガイドにあった記載が修正されました。indexについては非推奨でなく、いくつかのケースでは有効な場合があるという記載になっています。参考
ただし、遅延評価の恩恵は受けられないため、最適化や並列化とのトレードオフになります。)
実際のデータ選択にはselectやfilterメソッドを使用します。
>>> df.select(["discoverymethod"]).first().collect()
shape: (1, 1)
┌─────────────────┐
│ discoverymethod │
│ --- │
│ str │
╞═════════════════╡
│ Radial Velocity │
└─────────────────┘
>>> df.filter(pl.col("pl_rade") > 100.0).first().collect()
shape: (1, 287)
┌───────┬───────────────┬─────────────┬───────────┬─────┬─────────┬──────────┬───────────┬──────────────┐
│ rowid ┆ pl_name ┆ hostname ┆ pl_letter ┆ ... ┆ st_nrvc ┆ st_nspec ┆ pl_nespec ┆ pl_ntranspec │
│ --- ┆ --- ┆ --- ┆ --- ┆ ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ str ┆ ┆ i64 ┆ i64 ┆ i64 ┆ i64 │
╞═══════╪═══════════════╪═════════════╪═══════════╪═════╪═════════╪══════════╪═══════════╪══════════════╡
│ 14325 ┆ Kepler-1698 b ┆ Kepler-1698 ┆ b ┆ ... ┆ 0 ┆ 0 ┆ 0 ┆ 0 │
└───────┴───────────────┴─────────────┴───────────┴─────┴─────────┴──────────┴───────────┴──────────────┘
※rowidは元のcsvに含まれるデータ列になります。
欠損値について
Polarsではデータ型がApach Arrow形式に基づくため欠損値はnull値で表現されます。
>>> df = pl.DataFrame({"value": [1, None, 3]})
>>> df
shape: (3, 1)
┌───────┐
│ value │
│ --- │
│ i64 │
╞═══════╡
│ 1 │
├╌╌╌╌╌╌╌┤
│ null │
├╌╌╌╌╌╌╌┤
│ 3 │
└───────┘
>>> df.mean()
shape: (1, 1)
┌───────┐
│ value │
│ --- │
│ f64 │
╞═══════╡
│ 2.0 │
└───────┘
意図的にNaNを使うこともできますが、NaNは欠損値とみなされないため平均値を取る際など注意が必要です。(np.nanはfloat型であることも注意すべき点です)
>>> import numpy as np
>>> df = pl.DataFrame({"value": [1, np.nan, 3]})
>>> df
shape: (3, 1)
┌───────┐
│ value │
│ --- │
│ f64 │
╞═══════╡
│ 1.0 │
├╌╌╌╌╌╌╌┤
│ NaN │
├╌╌╌╌╌╌╌┤
│ 3.0 │
└───────┘
>>> df.mean()
shape: (1, 1)
┌───────┐
│ value │
│ --- │
│ f64 │
╞═══════╡
│ NaN │
└───────┘
>>> df.fill_nan(None).mean()
shape: (1, 1)
┌───────┐
│ value │
│ --- │
│ f64 │
╞═══════╡
│ 2.0 │
└───────┘
付録: ライブラリーの構成
改めてpolarsリポジトリについてですが、Rustで実装されたCore部分とPythonで実装されたインターフェース部分に大別することが可能です。前者はpolarsディレクトリ以下、後者はpy-polarsディレクトリ以下にコードが存在しています。各ディレクトリ直下にMakefileがあるのでmake testでも実行すれば、ビルドからテストまで通しで実行してくれます。Python関連はvenvで環境構築しているので、ビルド後はpy-polarsディレクトリでsource venv/bin/activateを実行すれば簡単にデバッグなどができます。
ソースコードのトレース例
show_graph()内で呼んでいるto_dot()を例にソースコードをトレースすると以下流れになります。
Python側のLazyFrameクラスとRust側のLazyFrameクラスを結ぶPyLazyFrameクラスが存在することに注意してください。
実際にコミットを目指す場合はCONTRIBUTING.mdにも目を通してください。
-
Node.jsでも一応使えるみたいなのですが、リポジトリの更新頻度やissueを見る限り、メインのメンテナーはTS/JSが専門外であり、この領域はコミュニティからのコントリビュートに委ねている印象が強いです。 ↩︎
-
例で使用しているcsvデータはNASA Exoplanet Archiveが提供している系外惑星のデータカタログです。(61.3MB) ↩︎
-
カタログでは論文ごとの測定データを1行としているため、同じ惑星に対するデータが複数行存在したり、一部列がnullな場合があります。従って、ここでは結果の物理的な正しさは保証しません。Polarsの操作例として提示しています。 ↩︎
-
個人的にはpandasとPolarsで使用ケースが競合するとはそんなに思っていません。公式のユーザーガイドもpandasの知名度にあやかって、間口を広げる意図でページを作成している認識です。 ↩︎
Discussion