LLMOpsって何だ?: MLflow LLM Evaluationを読み込む
MLflow LLM Evaluation
LLMの評価について学んでいこうと思います。
また今までの記事はこちらにありますのでよければご覧ください。
MLflowの提供するLLM components
MLflowによるLLMの評価は大きく3つの構成要素からなります。
- 評価対象のモデル
- メトリックス
- 評価データ
それぞれにpyfuncやmlflow.data.dataset.Dataset()などmlflowのinstance等が使える旨が書かれていますが、より深い理解のためにどんどん進んでいこうと思います。
Quick startしてみよう
私はAzure Open AIを利用しているので下記のコードで動作しました。
事前に書かれているようにOPENAI_API_TYPE="azure"等環境変数を用意しないと動かないのでご注意ください。
"""
Set environment variables for Azure OpenAI service
export OPENAI_API_KEY="<AZURE OPENAI KEY>"
# OPENAI_API_BASE should be the endpoint of your Azure OpenAI resource
# e.g. https://<service-name>.openai.azure.com/
export OPENAI_API_BASE="<AZURE OPENAI BASE>"
# OPENAI_API_VERSION e.g. 2023-05-15
export OPENAI_API_VERSION="<AZURE OPENAI API VERSION>"
export OPENAI_API_TYPE="azure"
export OPENAI_DEPLOYMENT_NAME="<AZURE OPENAI DEPLOYMENT ID OR NAME>"
"""
import mlflow
import openai
import pandas as pd
mlflow.set_tracking_uri("http://localhost:8080")
mlflow.set_experiment("LangChain Tracing")
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"ground_truth": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) "
"lifecycle. It was developed by Databricks, a company that specializes in big data and "
"machine learning solutions. MLflow is designed to address the challenges that data "
"scientists and machine learning engineers face when developing, training, and deploying "
"machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data "
"processing and analytics. It was developed in response to limitations of the Hadoop "
"MapReduce computing model, offering improvements in speed and ease of use. Spark "
"provides libraries for various tasks such as data ingestion, processing, and analysis "
"through its components like Spark SQL for structured data, Spark Streaming for "
"real-time data processing, and MLlib for machine learning tasks",
],
}
)
with mlflow.start_run() as run:
system_prompt = "Answer the following question in two sentences"
# Wrap "gpt-4" as an MLflow model.
logged_model_info = mlflow.openai.log_model(
model="gpt-4o-mini",
task=openai.chat.completions,
artifact_path="model",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "{question}"},
],
)
# Use predefined question-answering metrics to evaluate our model.
results = mlflow.evaluate(
logged_model_info.model_uri,
eval_data,
targets="ground_truth",
model_type="question-answering",
)
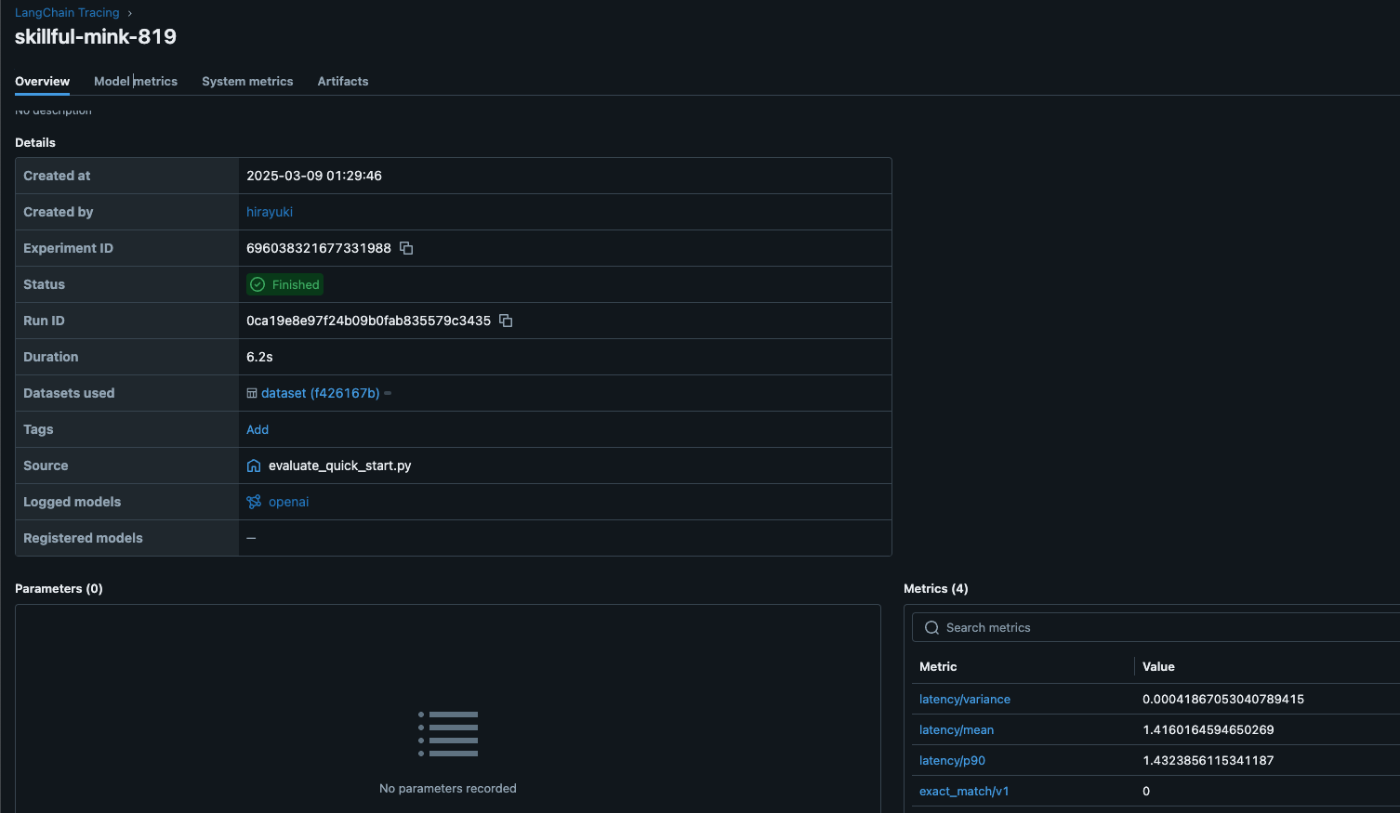
print(f"See aggregated evaluation results below: \n{results.metrics}")
# Evaluation result for each data record is available in `results.tables`.
eval_table = results.tables["eval_results_table"]
print(f"See evaluation table below: \n{eval_table}")
結果は{'exact_match/v1': 0.0}ということで、一致した結果は無しということでした。
LLM Evaluation Metrics
MLflowには2種類の評価指標が用意されています。
- Heuristic-based metrics
- LLM-as-a-Judge metrics
Heuristic-based metrics
ヒューリスティックの元々の言葉の意味は「経験や先入観によって直感的に、ある程度正解に近い答えを得ることができる思考法」という意味らしいです。
ですが具体的には1レコードずつ評価していく指標となり、例として以下の三つが挙げられています。
- ROUGE: こちらはROUGE-N、ROUGE-S、ROUGE-Lなど様々な評価指標がありますが、ROUGE-Nがわかりやすく、こちらはn-gram単位で一致するかどうかを評価します。
- Flesch Kincaid: こちらは読みやすさの指標で一つの文章あたりにどれだけ単語数、音節数が多いかによって評価します。
- Bilingual Evaluation Understudy: こちらは自動翻訳の連続するフレーズと、参考翻訳に含まれる連続するフレーズとが比較され、一致数がカウントされ、重み付けされた形式で表示されます
それぞれ古典的な手法であり、LLMの評価に用いることが可能です。
LLM-as-a-Judge metrics
こちらはLLMのoutputをLLMで評価する手法です。
Heuristic-based Metricsについてさらに
基本の実行方法は以下のようになります。
modelとdataがあり、targetsはそのままですね、最後にmodel_typeとして、どんなタスクを担っているモデルなのかを定義します。
results = mlflow.evaluate(
model,
eval_data,
targets="ground_truth",
model_type="question-answering",
)
eval_dataは一番上のquick startが一例ですが、モデルありきの関数なので、つまりはこの時に推論も一気に行うということなので、API等使っていればお金がかかりそうですね。
model_typeは複数存在し、質疑応答(question-answering)、要約(text-summarization)、文書生成(text models)、文章検索(retrievers)と別れ、それぞれに対して評価指標がいくつか用意されています。
以下のように他の評価指標も使いたい時は、extra_metricsに足せばいいようです。
results = mlflow.evaluate(
model,
eval_data,
targets="ground_truth",
extra_metrics=[mlflow.metrics.toxicity(), mlflow.metrics.latency()],
)
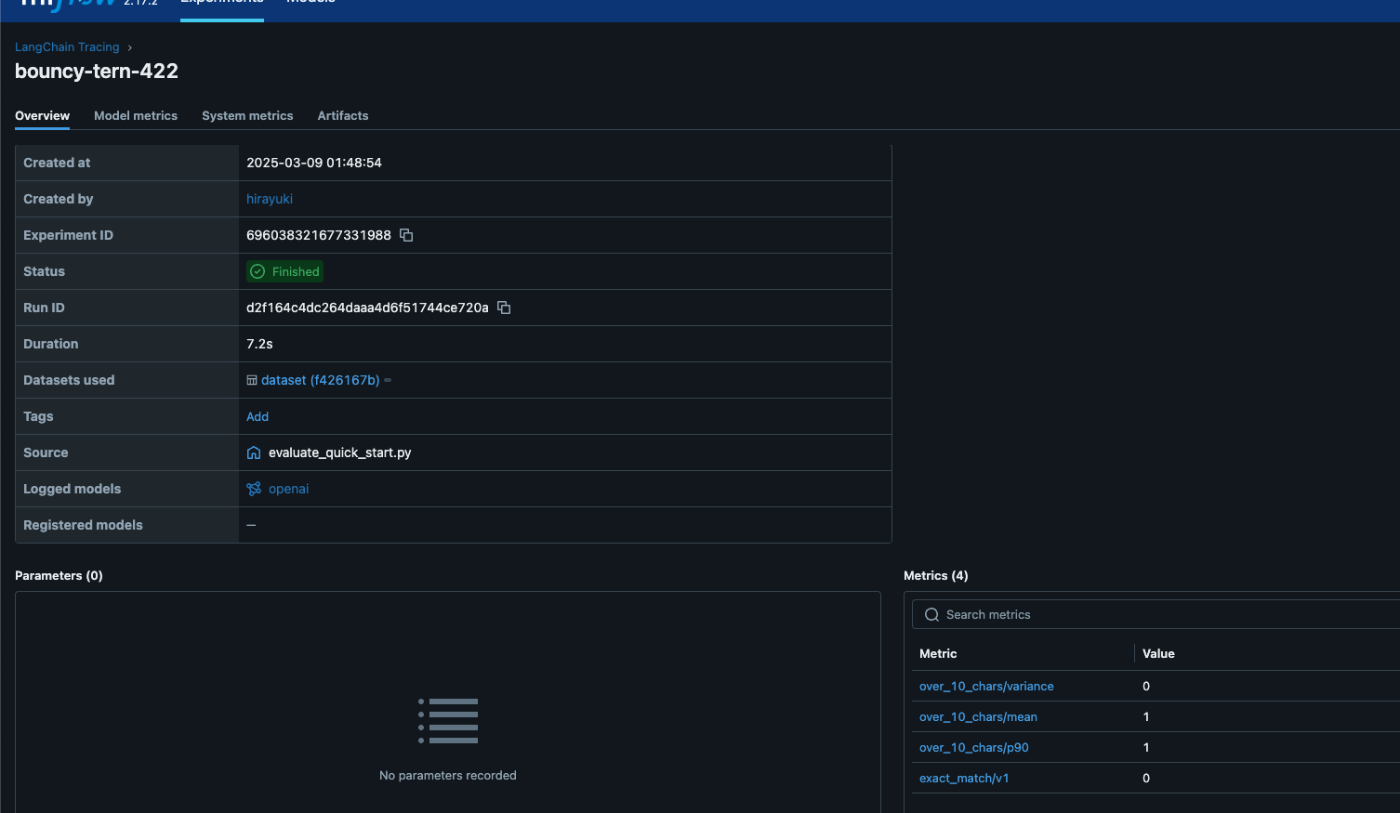
またmlflow.metrics.make_metricという関数を用いると、独自の評価指標を作成することもできます。例えば以下は、回答が10単語以上かどうかを評価するメトリックスです。
def eval_fn(predictions, targets):
scores = ["yes" if len(pred) > 10 else "no" for pred in predictions]
return MetricValue(
scores=scores,
# aggregate_results=standard_aggregations(scores),
)
# Create an EvaluationMetric object.
passing_code_metric = make_metric(
eval_fn=eval_fn, greater_is_better=False, name="over_10_chars"
)
LLM-as-a-Judge Metricsについてさらに
一番シンプルなquick startだと以下の関数で動くようです。
from mlflow.metrics import latency
from mlflow.metrics.genai import answer_correctness
results = mlflow.evaluate(
eval_data,
targets="ground_truth",
extra_metrics=[
answer_correctness(),
latency(),
],
)

結果として平均5と表示されています。5? Ragasの例など見ても Answer correctnessはF値で評価されていて0~1の間で評価される気がするのですが、MLflowは違うのだろうか?documentを読み漁っても見えず。。。
あとはArtifactsに残されていたgenai_custom_metrics.jsonを確認するとscoreが2だったり4だったりするのですが、これは大丈夫なのか?・・・
{
"name": "answer_correctness",
"definition": "<長いとこ省略>",
"examples": [
{
"grading_context": {
"targets": ""
},
"input": "How is MLflow related to Databricks?",
"justification": "",
"output": "",
"score": 2
},
{
"grading_context": {
"targets": ""
},
"input": "",
"output": ",
"score": 4
}
],
"version": "v1",
"model": "openai:/gpt-4",
"grading_context_columns": [
"targets"
],
"include_input": true,
"parameters": {
"temperature": 0,
"max_tokens": 200,
"top_p": 1
},
"aggregations": [
"mean",
"variance",
"p90"
],
"greater_is_better": true,
"max_workers": 10,
"metric_metadata": null,
"mlflow_version": "2.17.2",
"fn_name": "make_genai_metric"
}
また評価モデルだけ異なるモデルことを使うこともできます。今までの例は環境変数に設定されたOPENAI_API_KEYなどをもとに標準のモデルを使っていますが、LLM as a Judgeの思想として同じモデル同士で評価するよりは別のモデルを、ということもあると思います。
その場合は以下のように書けます。
answer_similarity = mlflow.metrics.genai.answer_similarity(
model="openai:/gpt-4o",
proxy_url="https://my-proxy-endpoint/chat",
extra_headers={"Group-ID": "my-group-id"},
)
私はDatabricks好きなので、Databricks endpointにも向けられるのは嬉しいです。
from mlflow.deployments import set_deployments_target
set_deployments_target("databricks")
llama3_answer_similarity = mlflow.metrics.genai.answer_similarity(
model="endpoints:/databricks-llama-3-1-405b-instruct"
)
Prepare Your Target Models
こちらはMLflowを使い慣れているとわかる章なので割愛します。
mlflow.pyfunc.PyFuncModel()という型があるのですが、それにしないと自作モデルをそのままmlflow.evaluateにできないよ。という話です。
View Evaluation Results via the MLflow UI
こちらUI上で過去の結果が簡単に可視化可能なEvaluateという機能があるので、少し触ってみた画面を共有したいと思います。
同じ問に対しても何度か試して結果の違いやスコアを確認できます。

最後に(感想)
実は読む前は、実はLLMのevaluationってどうやるのか想像もついていませんでした。
tracingで取得した結果に対する評価もどうやってやるべきか期待していました。
本記事自体はLLMにevaluate関数を実行するたびに推論も行なっているので、それなりのコスト等が必要ですが、こちらも重要ですね。
よくよく考えると当たり前なのですが、groud_truthが必要な評価指標か、そうでないかもtracingを分析する上で重要かと思いました。例えばtoxicityとかはgroud truthなしで動かせるので、簡単にtracingした結果を活かせそうな気がします。なんだかずっと手段と目的が入れ替わったまま物事を考えていますが、まずはフレームワークの理解を進めたかったので満足です。
お読みいただきありがとうございました。
reference
Discussion