必要なデバイス
- Jetson Orin Nano Developer Kit 8GB
- Ubuntu 20.04 がインストールされているPC
- NVMe SSD
0. 前準備
を読むと
preferably with NVMe SSD
とのことなので、SDK Manager を使用して、NVMe SSD に OS をインストールする
JetPack 6.x の最新版は JetPack 6.0 Developer Preview で、まだ不安定なので、
JetPack 5.1.3 をインストールするものとする
JetPack 5.x をインストールするには Ubuntu 20.04 が必要なので、事前に用意しておくこと

※Ubuntu 22.04 だと JetPack 6.x しかサポートされていないので注意
SDK Manager は意外とスペックを要するので、
もし適当なスペックの PC がない場合は、下記の記事を参考にミニPC等を購入すると良い
格安ミニPCを購入する際の注意点
1. SSD に Jetson OS と Jetson SDK をインストール
- https://developer.nvidia.com/sdk-manager
- https://docs.nvidia.com/sdk-manager/download-run-sdkm/index.html
- https://docs.nvidia.com/sdk-manager/install-with-sdkm-jetson/index.html
-
Jetson Orin Nano に NVMe SSD を取り付ける

使用した NVMe SSD
https://www.amazon.co.jp/gp/product/B0B56X29BK/ref=ppx_yo_dt_b_asin_title_o06_s00?ie=UTF8&psc=1もし別の用途に使用していた NVMe SSD を使用する場合は、nvme-cli で初期化しておく
後述の手順で OS をインストールする際に上手くいかない場合、nvme-cli で初期化しておくことで解決する場合がある# nvme-cli をインストール sudo apt install && sudo apt install -y nvme-cli # 初期化対象のデバイスを確認 sudo fdisk -l # 実行例 nvme format /dev/nvme0 -
Jetson Orin Nano にジャンパピンを接続
Force Recovery Mode にするためにジャンパピンを接続

https://developer.nvidia.com/embedded/learn/jetson-orin-nano-devkit-user-guide/howto.htmlジャンパピン接続前(赤枠のピンにジャンパピンを接続)

ジャンパピン接続後

使用したジャンパピン
https://www.amazon.co.jp/gp/product/B00076YM1K/ref=ppx_yo_dt_b_asin_title_o01_s01?ie=UTF8&psc=1 -
Jetson Orin Nano と PC を USB-C ケーブルで接続
-
Jetson Orin Nano に電源ケーブルを挿して、起動
-
Ubuntu 20.04 が Jetson Orin Nano を認識していることを確認
$ lsusb Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 001 Device 003: ID 25a7:fa61 Compx 2.4G Receiver Bus 001 Device 004: ID 8087:0026 Intel Corp. Bus 001 Device 002: ID 0955:7523 NVIDIA Corp. APX Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub -
SDK Manager をインストールし、JetPack 5.1.3 をインストール
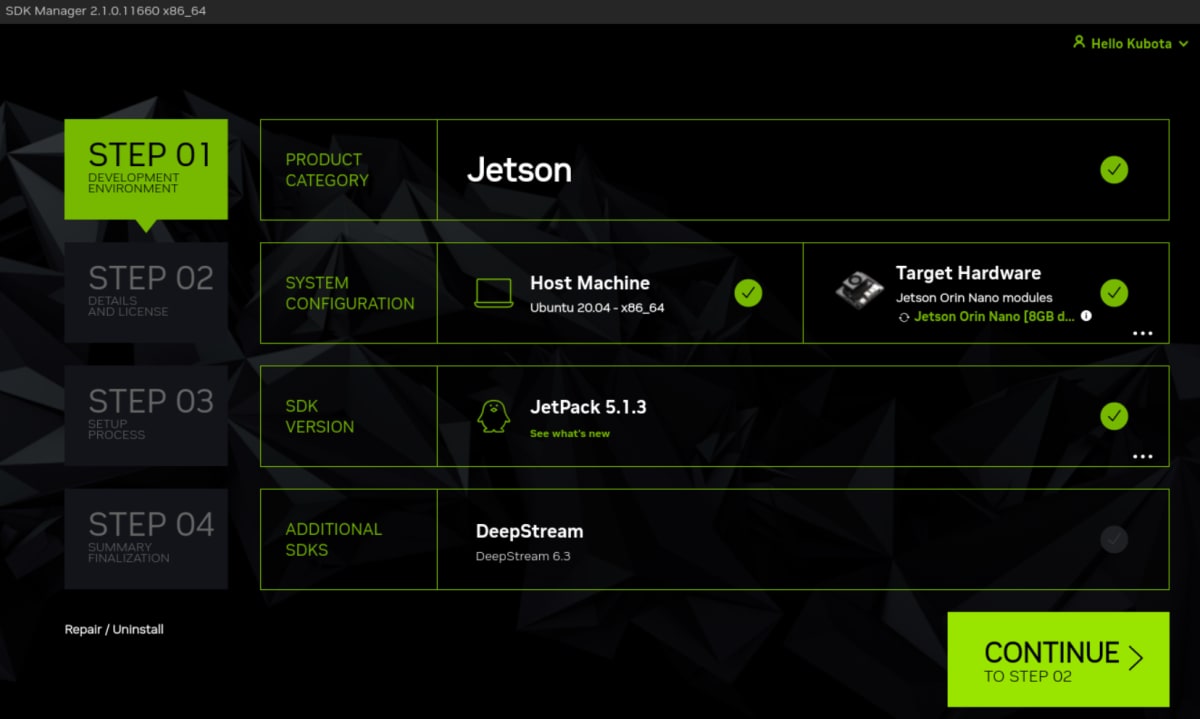
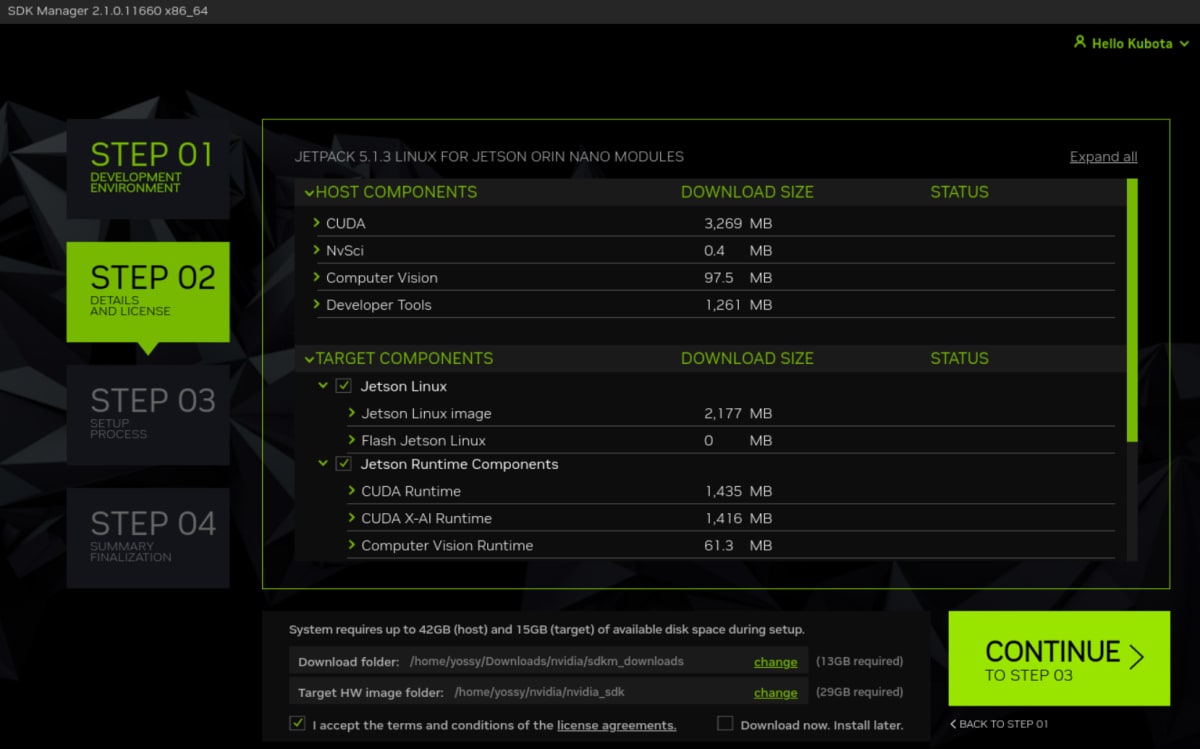
以下のようなダイアログが表示されたら、Jetson Orin Nano は既に起動した状態になっているので、
Jetson Orin Nano にモニターを接続し、
初期セットアップを行った後、LANケーブルを接続した状態で、
hostname -Iをターミナルで実行し、IPアドレスを確認して、こちらのダイアログに入力する※以下はスクショを撮り忘れたため、公式ドキュメントの画像を使用

2. Jetson Orin Nano の RAM の最適化
LLM を実行するには大量の RAM を必要とするため、不要なサービス等を無効化しておく
# GUI を無効化
sudo systemctl set-default multi-user.target
# その他のサービスを無効化
sudo systemctl disable nvargus-daemon.service
# swap をマウント
sudo systemctl disable nvzramconfig
sudo fallocate -l 16G /ssd/16GB.swap
sudo mkswap /ssd/16GB.swap
sudo swapon /ssd/16GB.swap
sudo vi /etc/fstab
/etc/fstab の末尾に次の行を追加
/ssd/16GB.swap none swap sw 0 0
再起動させる
sudo reboot
[Optional] 不要なサービスを無効化
以下は公式ドキュメントには記載されていない内容だが、
マシンのリソースを可能な限り空けるために実施した
# 有効なサービス一覧を表示
systemctl list-unit-files --type=service --state=enabled
# 使用しないサービスを無効化
sudo systemctl disable bluetooth.service
sudo systemctl disable snap.cups.cupsd.service
sudo systemctl disable snap.cups.cups-browsed.service
sudo systemctl disable rsync.service
sudo systemctl disable ModemManager.service
sudo systemctl disable pppd-dns.service
sudo systemctl disable dbus-fi.w1.wpa_supplicant1.service
sudo systemctl disable wpa_supplicant.servic
sudo systemctl disable snapd.apparmor.service
sudo systemctl disable snapd.autoimport.service
sudo systemctl disable snapd.core-fixup.service
sudo systemctl disable snapd.recovery-chooser-trigger.service
sudo systemctl disable snapd.seeded.service
sudo systemctl disable snapd.service
sudo systemctl disable snapd.system-shutdown.service
sudo systemctl disable openvpn.service
sudo reboot
# 通常のメモリ使用量
jetson@ubuntu:~$ free -mh
total used free shared buff/cache available
Mem: 7.3Gi 452Mi 5.8Gi 34Mi 1.1Gi 6.6Gi
Swap: 15Gi 0B 15Gi
# 使用しないサービスを無効化した後のメモリ使用量
jetson@ubuntu:~$ free -mh
total used free shared buff/cache available
Mem: 7.3Gi 333Mi 6.5Gi 34Mi 511Mi 6.7Gi
Swap: 15Gi 0B 15Gi
3. text-generation-webui で LLM をロードする
コンテナが用意されているので、以下のコマンドを実行するだけで text-generation-webui が立ち上がる
git clone https://github.com/dusty-nv/jetson-containers
bash jetson-containers/install.sh
jetson-containers run $(autotag text-generation-webui)
https://www.jetson-ai-lab.com/tutorial_text-generation.html#model-size-tested
によると、Jetson Orin Nano では 7B model までは動作するとのことだが、
記載されている手順で llama-2-7b-chat.Q4_K_M.gguf をダウンロード後にロードすると、落ちてしまった
こちらの方も同様の事象が発生した模様
https://qiita.com/vfuji/items/4618d78d2cb6964c67a1#webuiの実行とモデルの設定
※こちらに記載されているコンパクトなモデルtinyllama-2-1b-miniguanaco.Q4_K_M.gguf は動作した
今回は、小型なのに高性能!と話題になっている日本語の LLM
TFMC/Japanese-Starling-ChatV-7B-GGUF
japanese-starling-chatv-7b.Q4_K_M.gguf
を動かしてみる
ダウンロード元
- 饒舌な日本語ローカルLLM【Japanese-Starling-ChatV-7B】を公開しました
- https://huggingface.co/TFMC/Japanese-Starling-ChatV-7B-GGUF
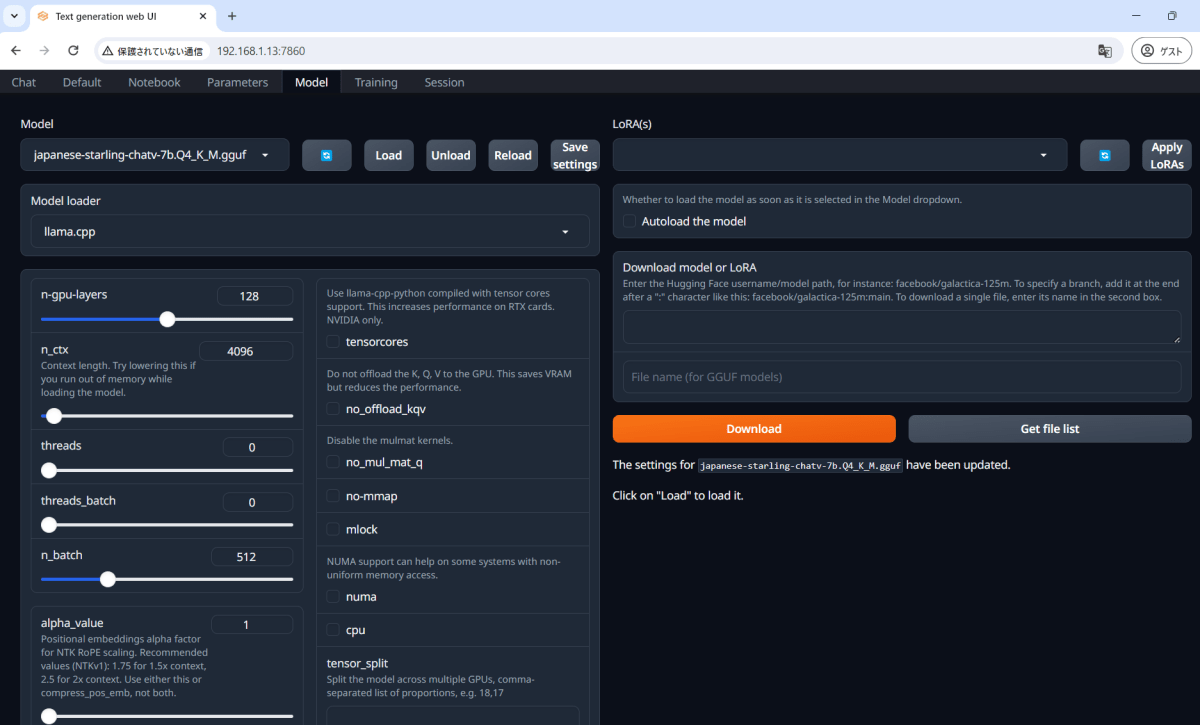
ロードにかかる時間は10秒程度
00:44:55-826326 INFO LOADER: llama.cpp
00:44:55-834338 INFO TRUNCATION LENGTH: 4096
00:44:55-836304 INFO INSTRUCTION TEMPLATE: Alpaca
00:44:55-837977 INFO Loaded the model in 10.86 seconds.
日本語での受け答えができるように、Character を日本語にカスタマイズする

Context
以下はAIの大規模言語モデルとの会話です。
このAIは、質問に答えたり、推奨事項を提供したり、意思決定を支援したりするように訓練されています。
AIはユーザーの要求に従います。
AI は既成概念にとらわれずに考えます。
Greeting
何か御用でしょうか
4. 日本語の LLM とチャットしてみる
日本語でちゃんと受け答えができる!

レスポンスの速度は ChatGPT と同程度
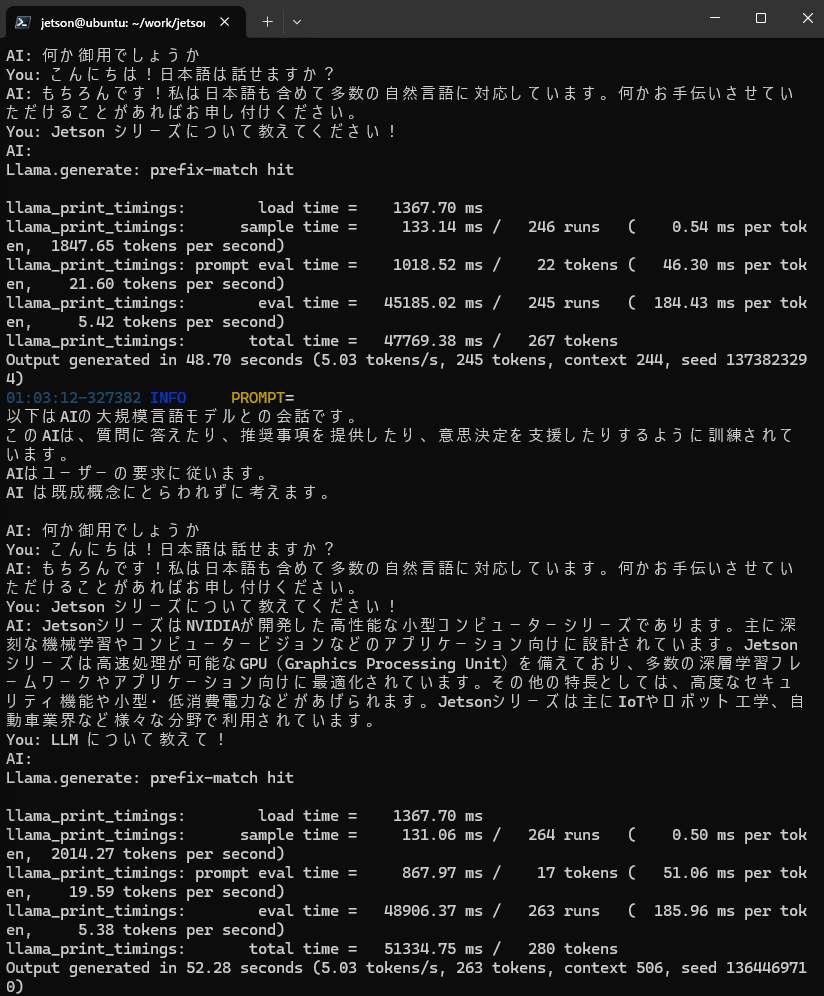
お勧めのアニメを聞いてみたが、
進撃の巨人とゆるキャンはジャンルがかなり違う気もする

競技プログラミングの問題を解かせてみる


少し惜しいが、それなりに動作するコードを生成できている

[おまけ] Llama 3 を Jetson Orin Nano で動かしてみる
2024年4月18日 に Meta社が Llama 3 を公開したのに合わせて、
NVIDIA Jetson AI Lab のドキュメントにも Llama 3 の実行例のページが追加されていたので、早速試してみる
Hugging Face にて、リポジトリへのアクセス要求を送る
(自分の場合、数分程度で承認された)
エッジデバイスにLLMを組み込んで業務で活用する事例を尋ねてみる
jetson-containers run \
--env HUGGINGFACE_TOKEN=hf_abc123def \
$(autotag nano_llm) \
python3 -m nano_llm.chat --api mlc \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--prompt "Please tell me an example of incorporating LLM into an edge device and utilizing it in business."

レスポンスの速度も、回答の内容も、なかなか良さそう
おわりに
LLMは日進月歩で新しいモデルが次々とリリースされている
従来のLLMは高性能なGPUと大量のRAMが必要だったが、
今では Jetson Orin Nano のようなエッジデバイスでも高速に動作する日本語LLMも出てくるようになった
スマホやスマートスピーカーにLLMが標準で搭載される未来もそう遠くはないのかもしれない

Discussion