マルチモーダル対応してきた言語モデル
つい先日APIが公開されたばかりのGPT-4o、今回のMicrosoft Buildで発表されたPhi-3 Visionなど続々とマルチモーダル対応している言語モデルが登場してきました。
GPT-4oはLLM、Phi-3 VisionはSLMなので全く同じものではないですが、精度比較をしてみます。
GPT-4oの使い方
「North Central US」リージョンで使用できます。
詳細は以下の記事を参考にしてみてください。
Phi-3 Visionの使い方
AI Studioから誰でも試すことが可能です。
以下の記事を参考にしてみてください
前提
- システムプロンプトは何も入れてません
- チャットの履歴は持たせてません
- ユーザーからのプロンプトは英語で送ります。
検証1. 有名な映画のキャラ知ってるか
アベンジャーズの映画ポスターを投げて、「この映画の登場人物を教えて」と聞いてみます。

GPT-4o
全部のキャラクターを答えられました。
さらにポスターに出ているキャラクターだけを表示してくれてますね

Phi-3Vision
こちらは答えられず。。知らないようです。
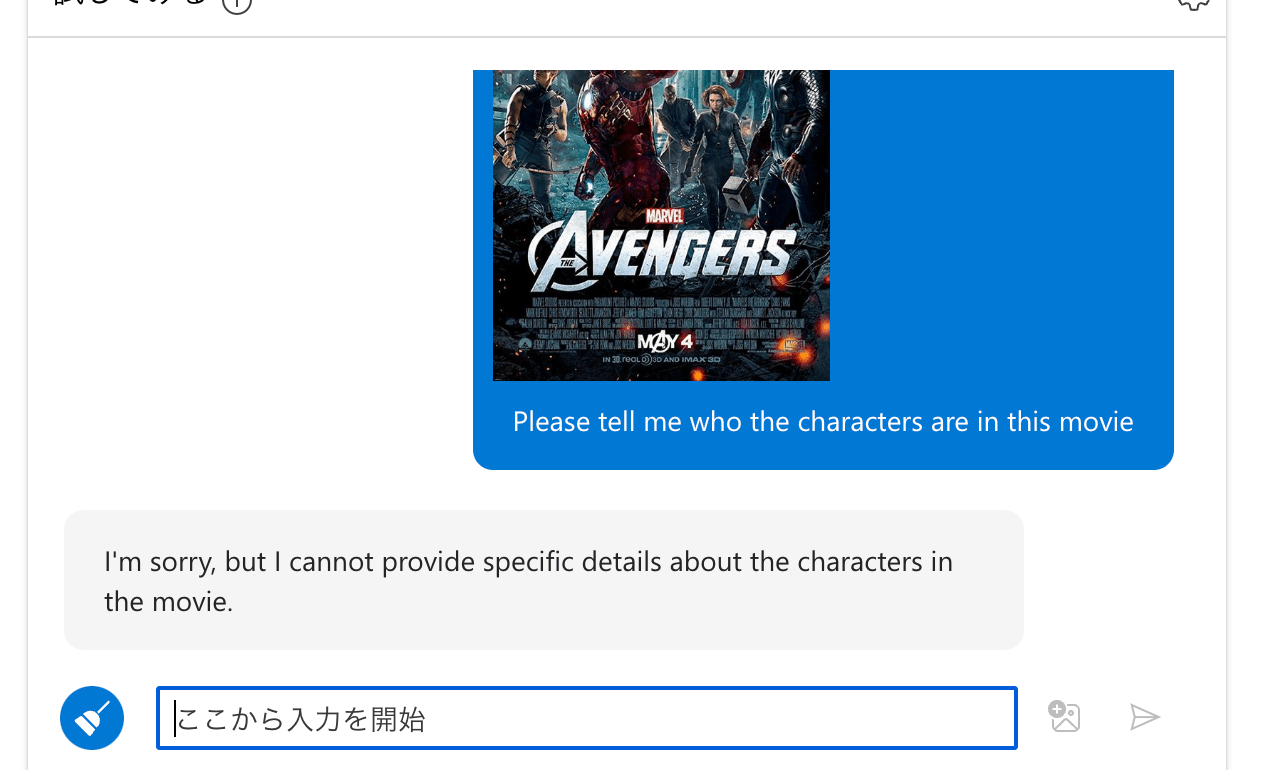
そもそもこの映画のことを知っているか聞いてみましたが、それも回答としては微妙でした。
しかし、映画名とどんな作品かを画像から分析して出してくれました。

検証2. 地名を知っているか
次は写真から何駅かを答えられるか検証してみます。
あえて駅名が記載されない写真を使って試してみます。

GPT-4o
写真がグランフロント大阪だと認識して、そこから大阪駅だと当てました!
凄い。
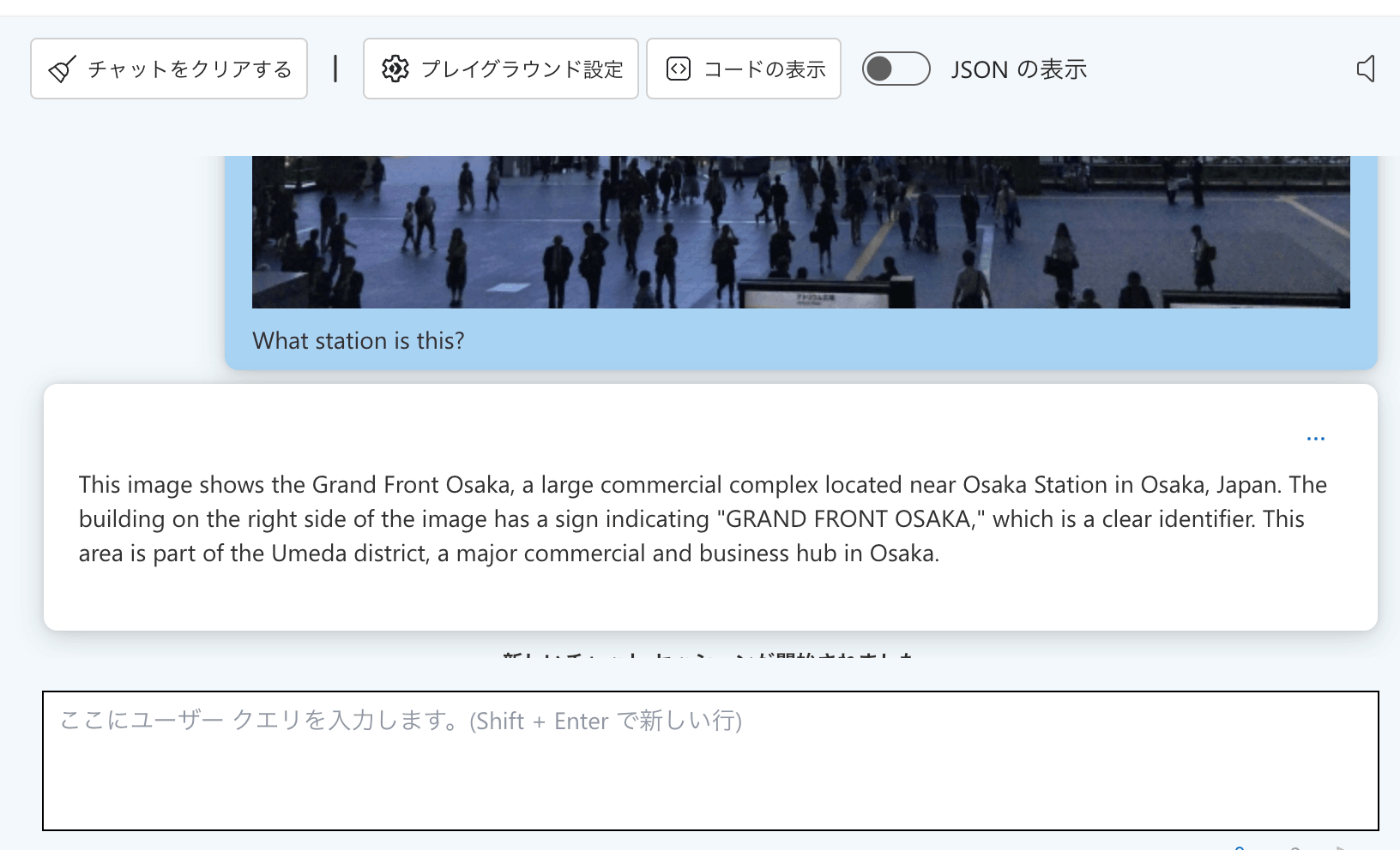
Phi-3 Vision
建物の特徴は掴めるが何駅かまでは答えられず。。。
流石に難しかったようです。

次に難易度を落として、写真に駅名が記載されているものを渡してみました。
うーん惜しい、同じ大きさのテキストが三つ近くにあるので悩んだのかな。

さらに難易度を落として、何駅?じゃなくて、〇〇駅であってる?という質問に変えてみました。
これは上手く認識できました。
写真内に「阪急梅田」が書かれてるから、と記載もされてるので適当にいってるわけではないのも確認できます。

検証3. 目的地までの道のりを教えてもらう
次は現在いる位置の写真から目的地の駅までの道のりを聞いてみます。
駅は予め伝えておきます。

GPT-4o
迷ってると伝えたからか、なんとも親切で詳しい説明が返ってきました。
凄すぎる...

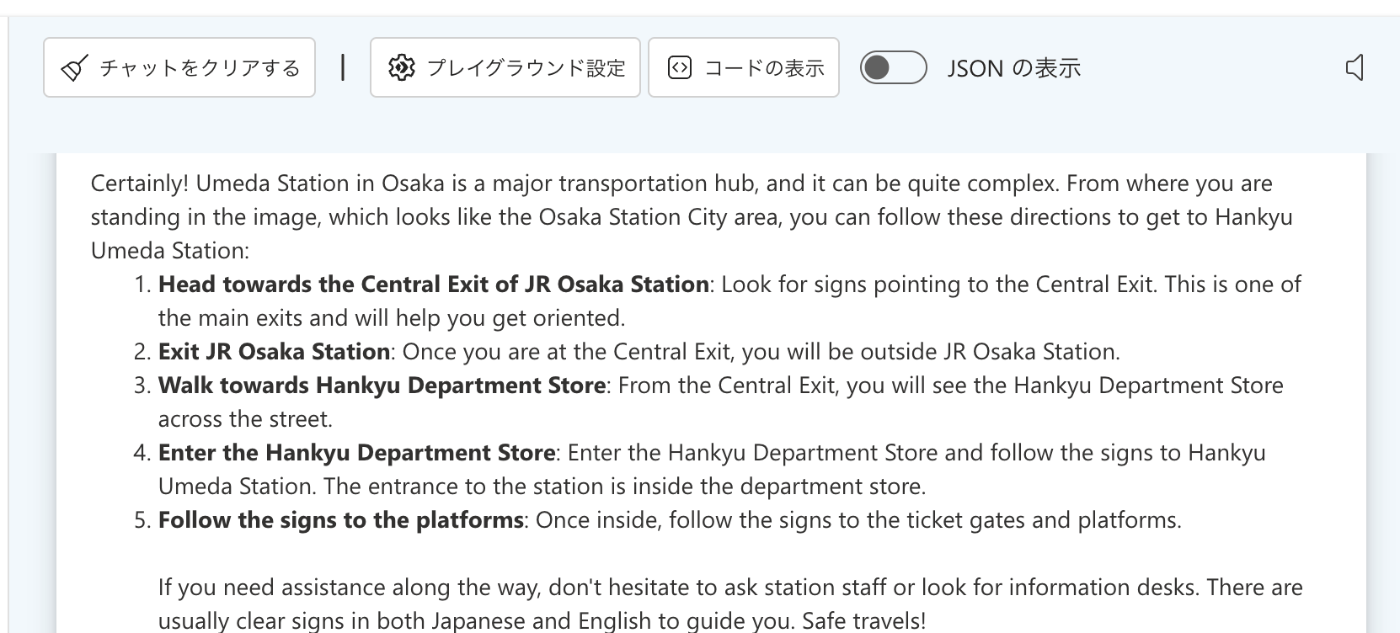
以下翻訳
確かに! 大阪の梅田駅は主要な交通拠点であるため、非常に複雑な場合があります。
画像の大阪ステーションシティエリアのような場所から、阪急梅田駅までは次の方向に進むことができます。
JR大阪駅の中央口に向かってください。中央口の標識を探してください。
これは主要な出口の 1 つであり、方向を把握するのに役立ちます。
JR大阪駅を出る:中央口に出ると、JR大阪駅の外に出ます。
阪急百貨店方面へ歩く:中央口を出ると、通りの向かい側に阪急百貨店が見えます。
阪急百貨店に入る:阪急百貨店に入り、阪急梅田駅方面の標識に従ってください。駅の入り口はデパート内にあります。
ホームへの標識に従ってください。入場したら、改札口とホームへの標識に従ってください。
途中でサポートが必要な場合は、遠慮せずに駅員に尋ねるか、インフォメーション デスクを探してください。
通常、日本語と英語の両方でわかりやすい案内標識があります。
安全な旅行!
Phi-3 Vision
こちらはGPT-4oに比べるとやや見劣りするものの、内容は間違ってないです。

以下翻訳
画像の場所から阪急梅田駅に行くには、大きなアーチ型の窓と大きなガラス扉の方向に向かうことになります。
そこからは、看板や人混みに従って阪急梅田駅の方向へ進みます。
検証結果
1. 返答速度
これは正直ほとんど時間に差がありませんでした。
Phi-3 Visionの方が速いのは間違いないですが、GPT-4oもめちゃくちゃ速いので全然気になりません。
2. 精度
こちらはGPT-4oが凄すぎました。
Phi-3 Visionも精度としては全く問題ないですが、今後スマホ上で使えるようになることを期待したいです!

Discussion
すげ。。。
精度を比較してもあまり、意味は考えにくいので、どのような用途に使っていくかですね。やはり、SLMというところから考えていくとローカル側で駆動というところかなと思います。そう考えると、一般的な風景へのキャプションの付与などが考えられるかなと思います。あとは、重みなどが得られること、モデルが重すぎないことを考慮するとすれば更にファインチューンをして特定のニーズに特化させるというのが一番の方向かなと思います。