やること
Data Factoryで取得したcsvファイルをNotebookを使い、構造化データに変換する
手順
- Microsoft Fabric(https://app.fabric.microsoft.com/home)にアクセス

- 「Synapse Data Engineering」をクリック

- 「ワークスペース」をクリック

4.作業を行うワークスペースをクリック

5.「+新規」をクリック

6.「ノートブック」をクリック

7.ノートブックが開くことを確認

- 「既存のレイクハウス」を選択し、「追加」をクリック
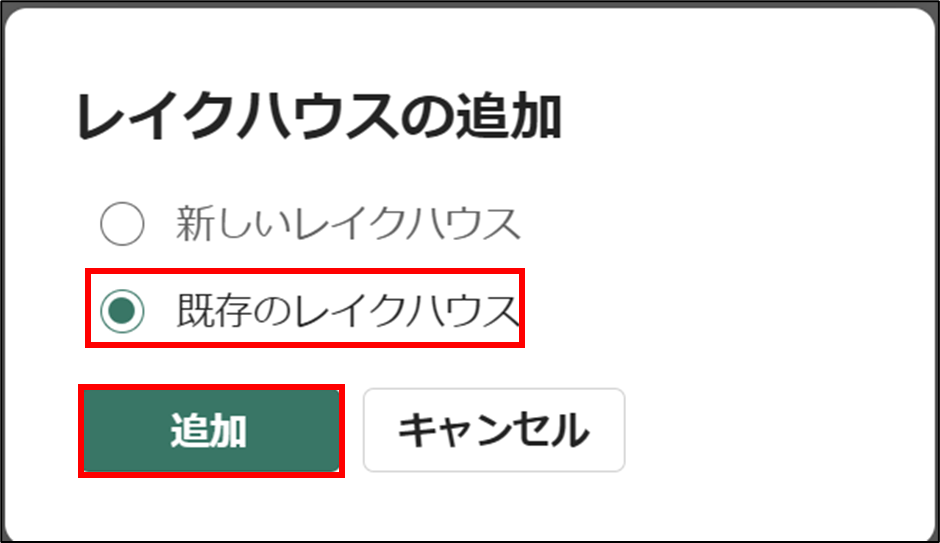
- 「blobtolakehouse」を選択する
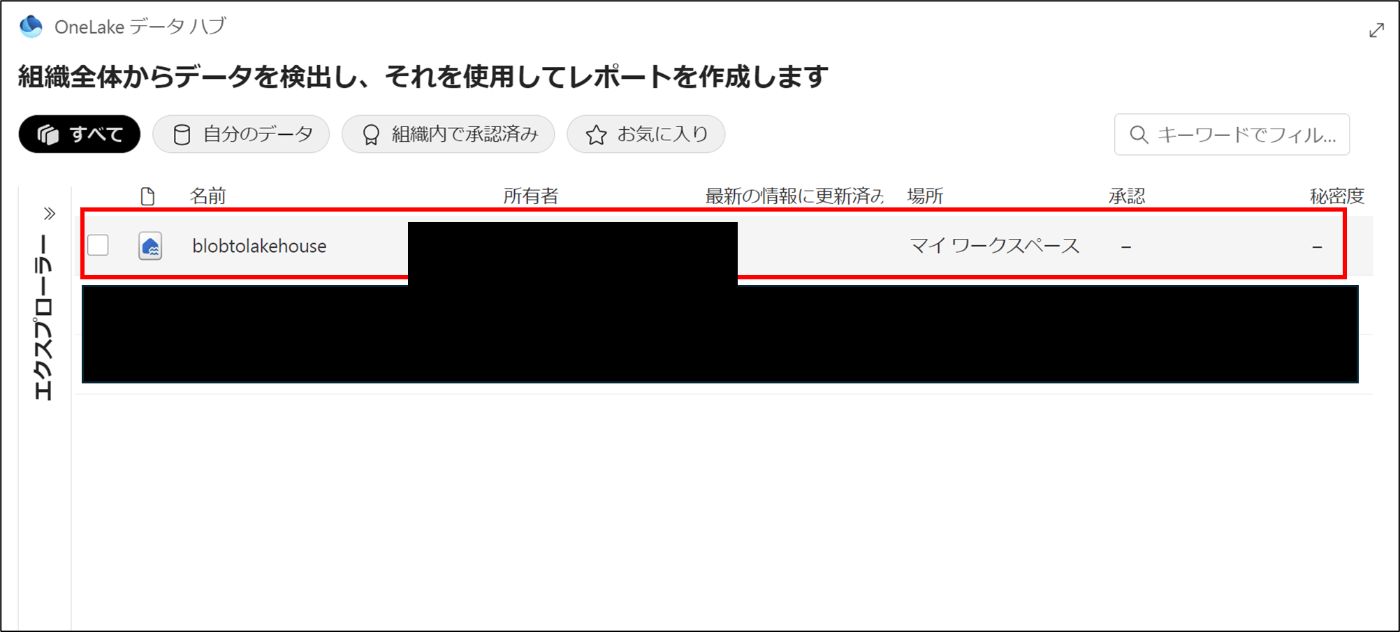
- ノートブックが開くことを確認※pysparkで実装
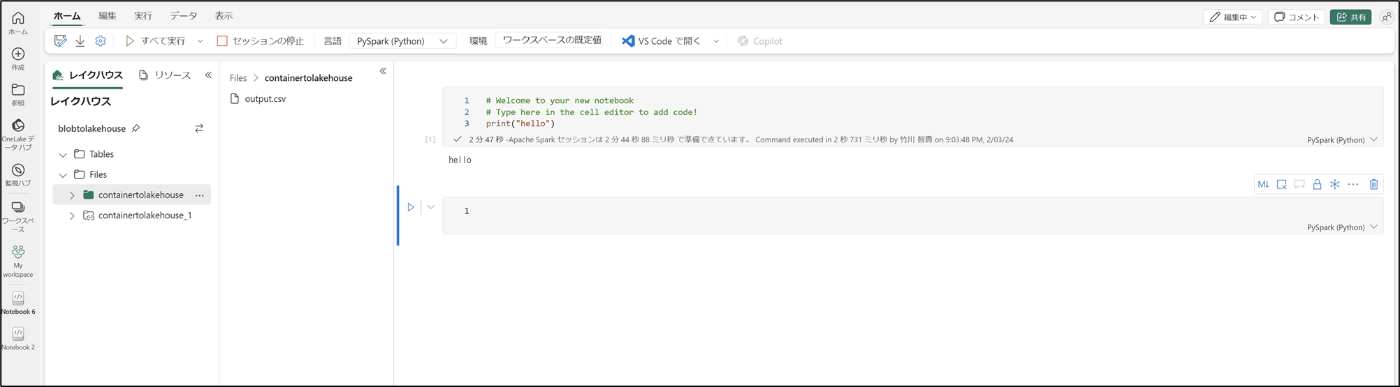
- 該当のcsvファイルを選択し、「・・・」をクリック
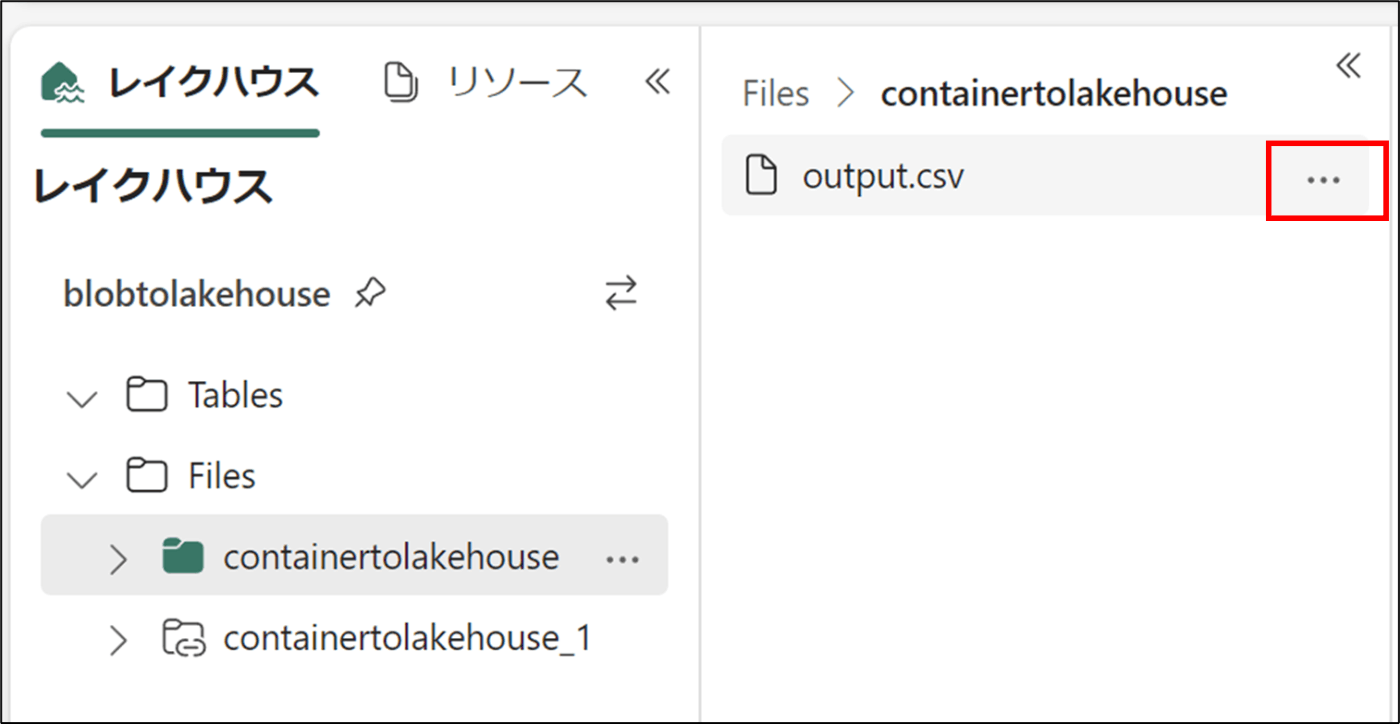
- 「Spark」をクリック
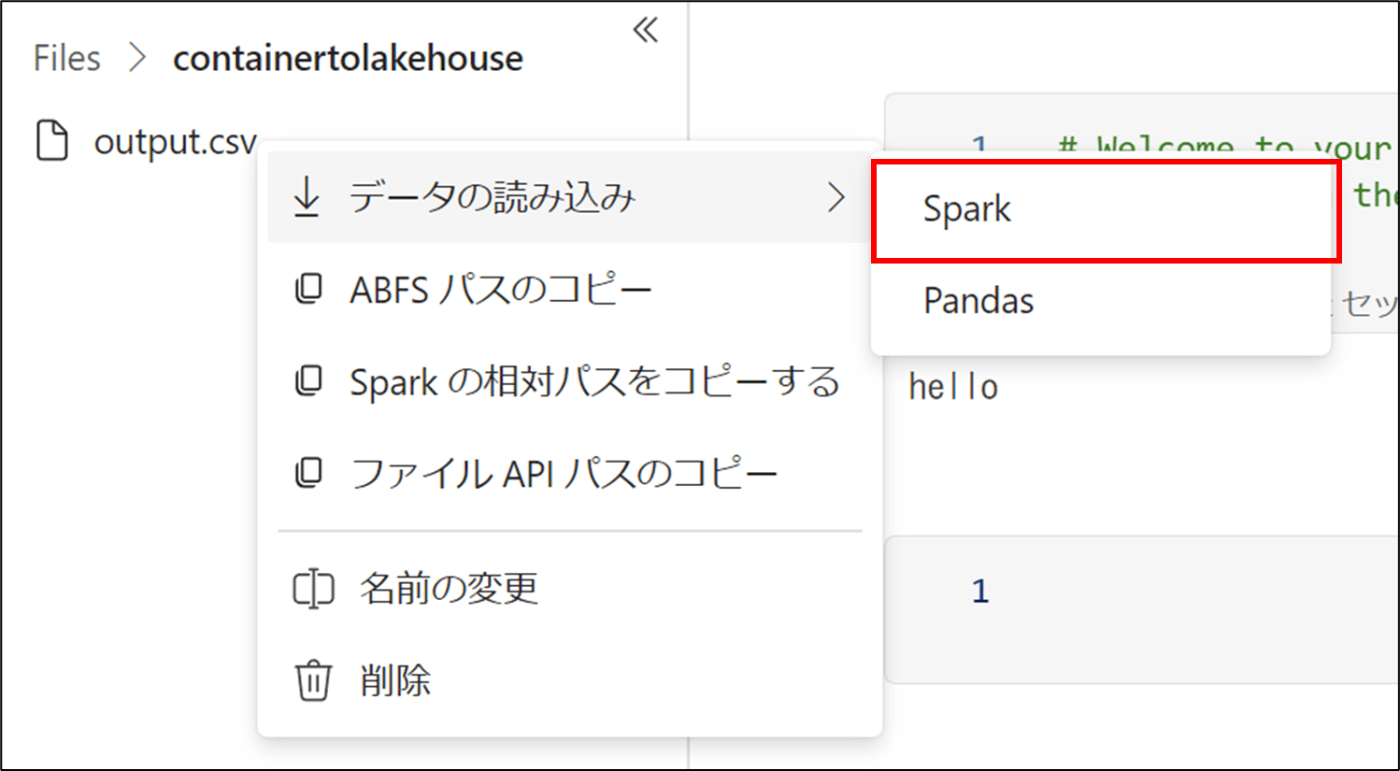
13 . コードが生成されたので、コードを実行
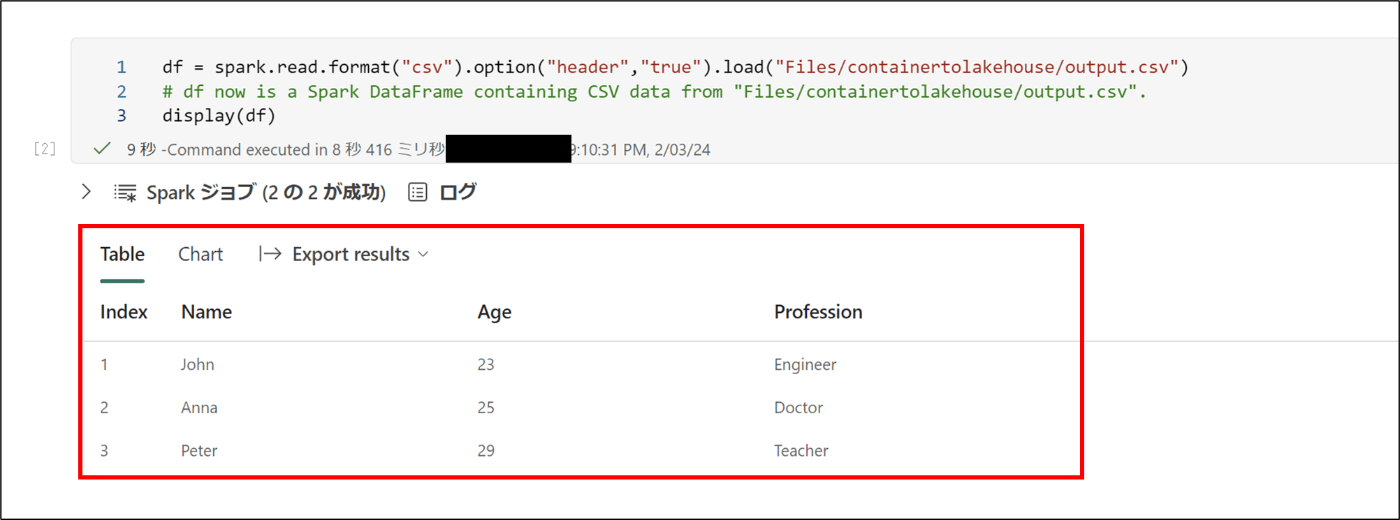
※pandasだと下記のコードが生成される
import pandas as pd
# Load data into pandas DataFrame from "/lakehouse/default/" + "Files/containertolakehouse/output.csv"
df = pd.read_csv("/lakehouse/default/" + "Files/containertolakehouse/output.csv")
display(df)
- 下記のコードを実行し、csvを構造化データに変換
from pyspark.sql.types import StructType, StructField, StringType
from pyspark.sql.types import IntegerType
schema = StructType([
StructField("Name", StringType(), True),
StructField("Age", IntegerType(), True),
StructField("Profession", StringType(), True)
])
df = spark.read.format("csv").schema(schema).option("header","true").load("Files/containertolakehouse/output.csv")
display(df)
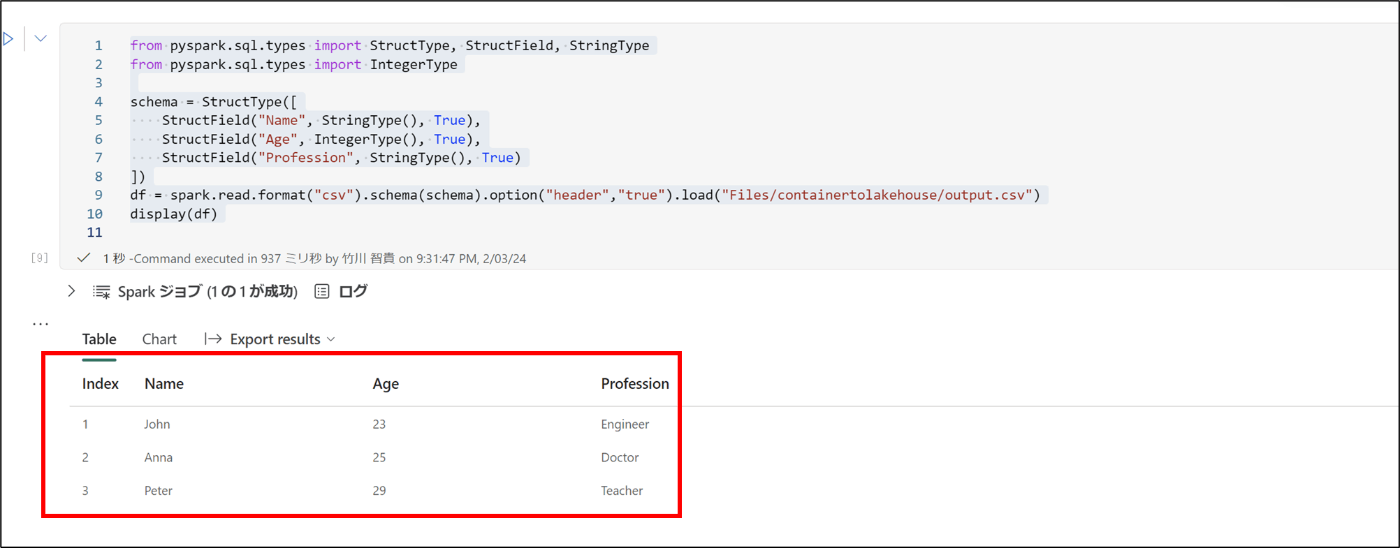
15. 下記のコードを実行し、一時ビューを作成
df.createOrReplaceTempView("test")
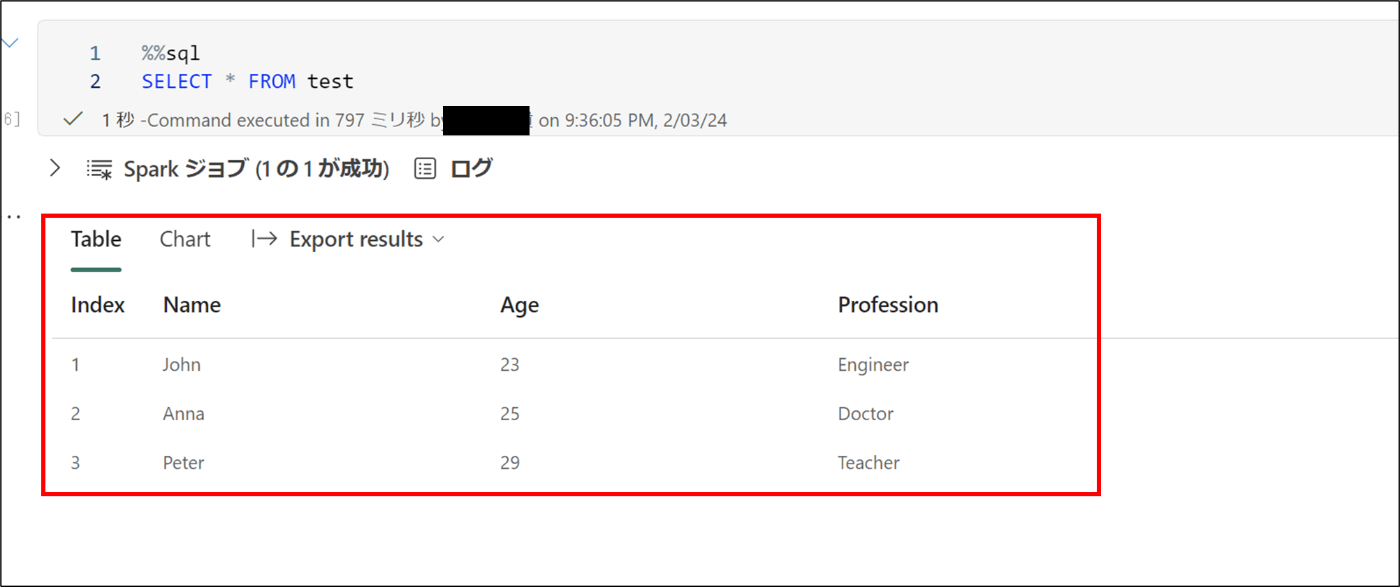
- 下記のコードを実行し、構造化データを確認
%%sql
SELECT * FROM test
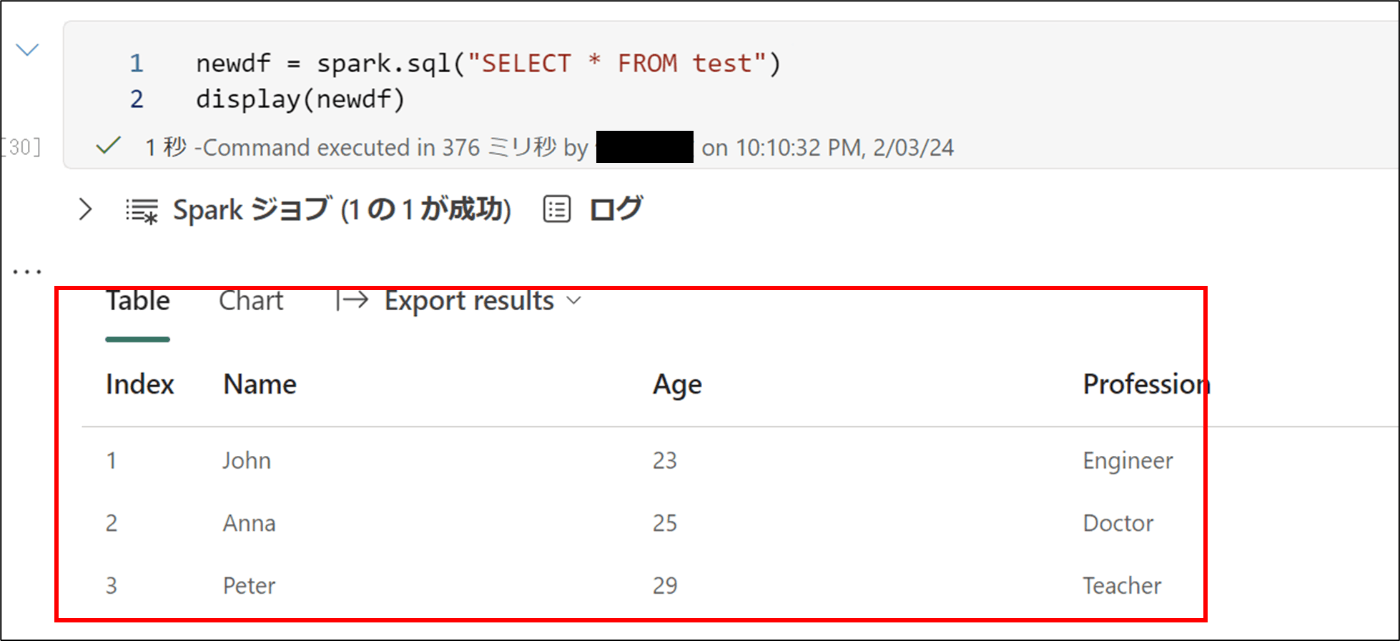
17. 下記のコードを実行し、保存
newdf = spark.sql("SELECT * FROM test")
display(newdf)
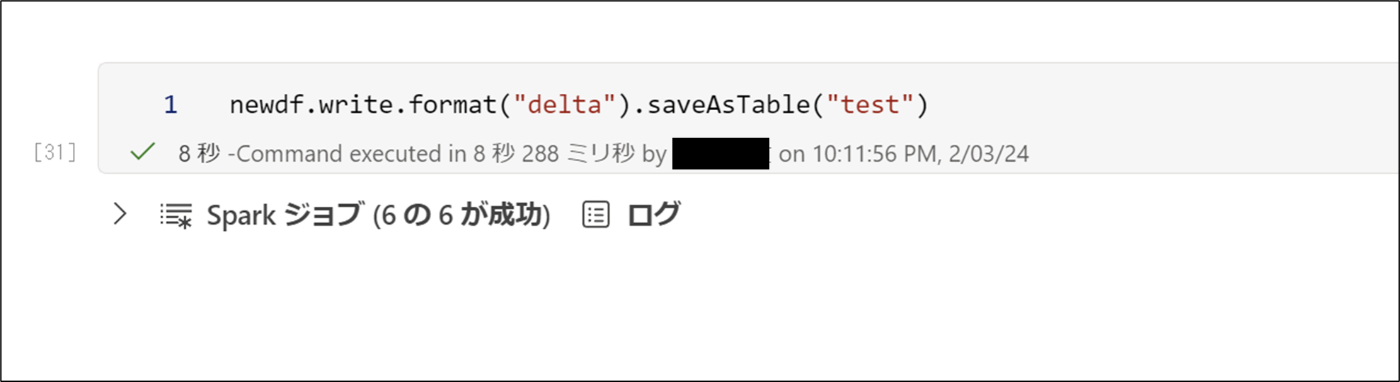
18. 下記のコードを実行し、testテーブルを作成
19.Tables配下に、作成されていることを確認

20. 下記のコードを実行し、テーブルを確認
df = spark.sql("SELECT * FROM blobtolakehouse.test LIMIT 1000")
display(df)


Discussion