やること
10月にAzure OpenAI ServiceのGPT-4oモデルの一つであるRealtime Audioが発表されました。
現在JavaScriptとPythonとC#のサンプルコードが提供されています。
Pythonのサンプルコードはバックエンドでの動作確認としてしか使えないので、API化してクライアント側から叩けるようにします。
Voice to Voiceはモバイルアプリでの利用されることが多そうなので、Flutterを使ってiOSアプリを作ります。
前提
以下の記事で実装しているところから開始します。
バックエンド側(Python)はサンプルコードからAPI化。
クライアント側は送信用の音声ファイルの作成処理とAPIから受け取った音声データをもとに音声再生する機能を作っています。
上記の記事では処理が最適化されてないので、ストリーミング形式でのリアルタイムなやり取りを実現させます。
API側の最適化
1. ファイルの形式変換とオーディオデータの取得を最適化
convert_audioという関数を作ってクライアント側から受け取ったファイルを.wavに変換してフォルダ上に保存してましたが、できれば無駄なファイルは保持しておきたくないです。
以下のような処理で音声データを抜き出します。
- pydubの
AudioSegmentクラスを使ってクライアント側から受け取った.m4a形式ファイルを読み取る - 読み取った音声データをnumpy配列に変換
- 読み込んだ音声データのサンプリングレートを取得
- サンプリングレートが24,000Hz以上か判定
- もし24,000Hz以上だったらresample_audio関数を使ってサンプリングレートを変更
from pydub import AudioSegment
import numpy as np
from client_sample import resample_audio, with_azure_openai
@app.post("/realtime_audio/")
async def realtime_audio(audio_file: UploadFile = File(...)):
sample_rate = 24000
audio = AudioSegment.from_file(audio_file.file, format="m4a")
audio_data = np.array(audio.get_array_of_samples())
original_sample_rate = audio.frame_rate
if original_sample_rate != sample_rate:
audio_data = resample_audio(audio_data, original_sample_rate, sample_rate)
resample_audioはサンプルコードに含まれている関数ですのでインポートしてください。
これで無駄にファイルを作成する手間がなくなりました。
2. レスポンスをストリーミング形式にする
前回はバックエンド側で生成AIから返ってきた音声データを一度ファイルに起こして、クライアント側に結果を返すタイミングでファイルの中身を読み取って音声データを一括で返していました。
ここでも無駄にファイルを作成しているので、生成AIから返ってきた音声データをそのままクライアント側に送るようにします。
以下の処理に修正
-
with_azure_openai関数には先ほど作成した音声データを引数に渡す - 非同期ジェネレーターで逐次的にオーディオデータを生成
- レスポンス形式を
StreamingResponseにして、media_typeをaudio/wavにする
from fastapi.responses import StreamingResponse
@app.post("/realtime_audio/")
async def realtime_audio(audio_file: UploadFile = File(...)):
sample_rate = 24000
audio = AudioSegment.from_file(audio_file.file, format="m4a")
audio_data = np.array(audio.get_array_of_samples())
original_sample_rate = audio.frame_rate
if original_sample_rate != sample_rate:
audio_data = resample_audio(audio_data, original_sample_rate, sample_rate)
// ↓修正
async def audio_stream():
async for audio_bytes in with_azure_openai(audio_data):
yield audio_bytes
return StreamingResponse(audio_stream(), media_type="audio/wav")
これでクライアント側にはwav形式の音声データをストリーミングで返すことができるようになります。
次にwith_azure_openai関数含むサンプルコードを修正します。
基本的には全ての関数を非同期ジェネレーターにするだけです。
receive_item関数で生成AIから返ってきたaudio_bytesを呼び出し先の関数にどんどん渡して行ってます。
import asyncio
import base64
import os
import numpy as np
import soundfile as sf
from azure.core.credentials import AzureKeyCredential
from dotenv import load_dotenv
from scipy.signal import resample
from rtclient import InputAudioTranscription, RTClient, RTInputItem, RTOutputItem, RTResponse
from rtclient.models import NoTurnDetection
def resample_audio(audio_data, original_sample_rate, target_sample_rate):
number_of_samples = round(len(audio_data) * float(target_sample_rate) / original_sample_rate)
resampled_audio = resample(audio_data, number_of_samples)
return resampled_audio.astype(np.int16)
async def send_audio(client: RTClient, audio_data):
sample_rate = 24000
duration_ms = 100
samples_per_chunk = sample_rate * (duration_ms / 1000)
bytes_per_sample = 2
bytes_per_chunk = int(samples_per_chunk * bytes_per_sample)
audio_bytes = audio_data.tobytes()
for i in range(0, len(audio_bytes), bytes_per_chunk):
chunk = audio_bytes[i : i + bytes_per_chunk]
await client.send_audio(chunk)
await client.commit_audio()
await client.generate_response()
async def receive_control(client: RTClient):
async for control in client.control_messages():
if control is not None:
print(f"Received a control message: {control.type}")
else:
break
async def receive_item(item: RTOutputItem):
prefix = f"[response={item.response_id}][item={item.id}]"
audio_transcript = None
async for chunk in item:
if chunk.type == "audio_transcript":
print(chunk.data)
audio_transcript = (audio_transcript or "") + chunk.data
elif chunk.type == "audio":
audio_bytes = base64.b64decode(chunk.data)
yield audio_bytes
async def receive_response(client: RTClient, response: RTResponse):
prefix = f"[response={response.id}]"
async for item in response:
print(prefix, f"Received item {item.id}")
async for audio_bytes in receive_item(item):
print(prefix, f"Received audio chunk with length: {len(audio_bytes)}")
yield audio_bytes
print(prefix, "Response completed")
await client.close()
async def receive_input_item(item: RTInputItem):
prefix = f"[input_item={item.id}]"
await item
print(prefix, f"Previous Id: {item.previous_id}")
print(prefix, f"Transcript: {item.transcript}")
print(prefix, f"Audio Start [ms]: {item.audio_start_ms}")
print(prefix, f"Audio End [ms]: {item.audio_end_ms}")
async def receive_items(client: RTClient):
async for item in client.items():
if isinstance(item, RTResponse):
async for audio_bytes in receive_response(client, item):
yield audio_bytes
else:
asyncio.create_task(receive_input_item(item))
async def receive_messages(client: RTClient):
async for audio_bytes in receive_items(client):
yield audio_bytes
await receive_control(client)
async def run(client: RTClient, audio_data):
with open(instructions_file) as f:
print("Configuring Session...", end="", flush=True)
await client.configure(
turn_detection=NoTurnDetection(),
input_audio_transcription=InputAudioTranscription(model="whisper-1"),
)
print("Done")
await send_audio(client, audio_data)
async for audio_bytes in receive_messages(client):
yield audio_bytes
def get_env_var(var_name: str) -> str:
value = os.environ.get(var_name)
if not value:
raise OSError(f"Environment variable '{var_name}' is not set or is empty.")
return value
async def with_azure_openai(audio_data):
endpoint = get_env_var("AZURE_OPENAI_ENDPOINT")
key = get_env_var("AZURE_OPENAI_API_KEY")
deployment = get_env_var("AZURE_OPENAI_DEPLOYMENT")
async with RTClient(url=endpoint, key_credential=AzureKeyCredential(key), azure_deployment=deployment) as client:
async for audio_bytes in run(client, audio_data):
yield audio_bytes
クライアント側の最適化
1. 音声再生ライブラリの再選定
前回はaudioplayersを使っていました。
しかしaudioplayersは音声ファイルを使った再生がメインでオーディオデータから音声再生は難しそうです。(もしかしたら出来るかもです..)
Flutterの音声再生ライブラリだと他にはjust_audioとflutter_soundがあります。
flutter_soundだとオーディオデータからリアルタイムに音声再生する関数があったので、今回はflutter_soundを利用します。
2. 音声再生ライブライの導入と設定
flutter_soundをプロジェクトに導入
flutter pub add flutter_sound
これだけだと起動時にエラーになるので、追加で色々設定が必要です。
<プロジェクト名>/ios配下にある〇〇.xcodeworkspaceファイルをダブルクリックしてXcodeを起動
左上の「Runner」をクリック

①「Build Settings」をクリック
②「All」と「Combined」をクリック
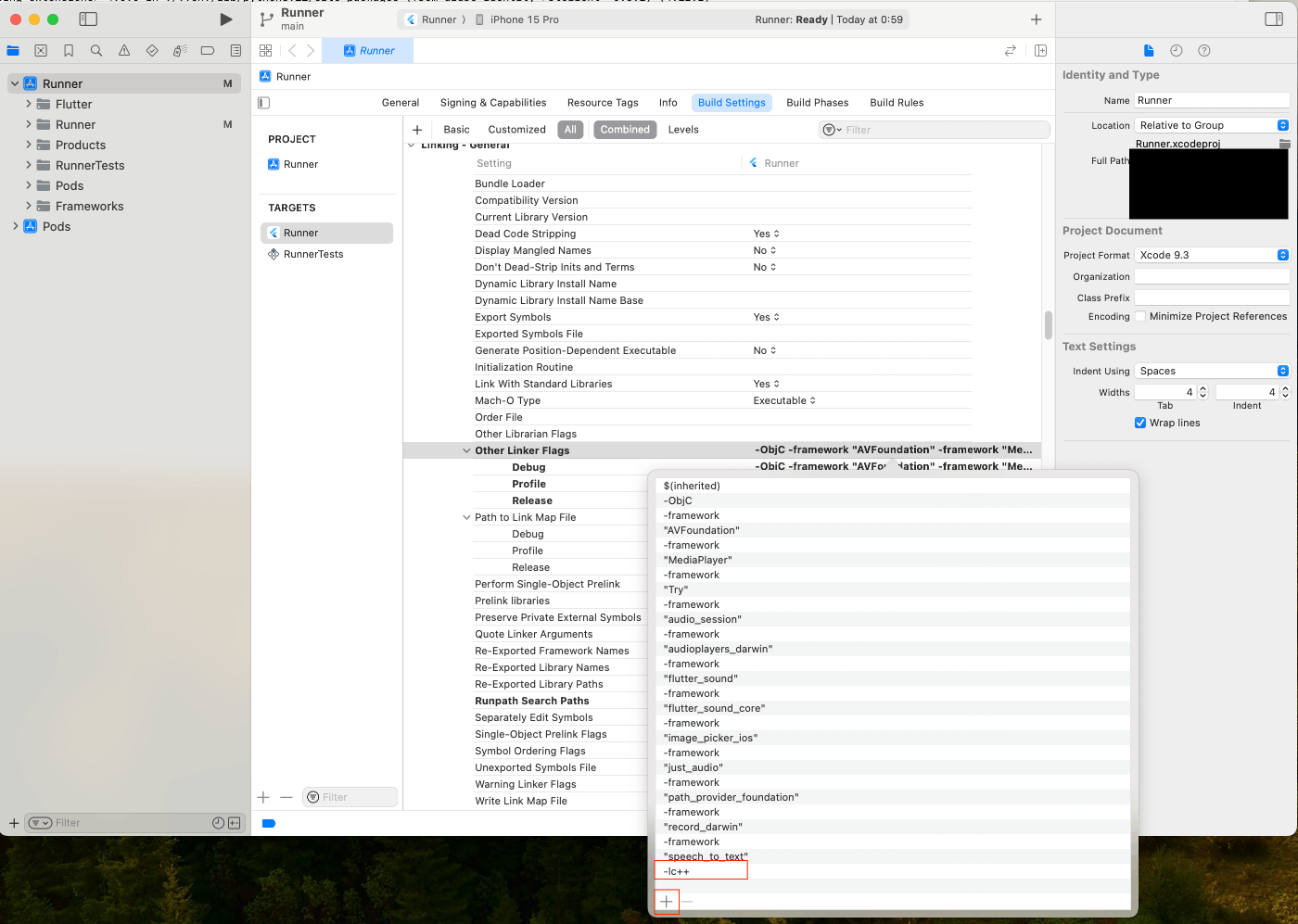
③「Other Linker Flags」を見つけてダブルクリック
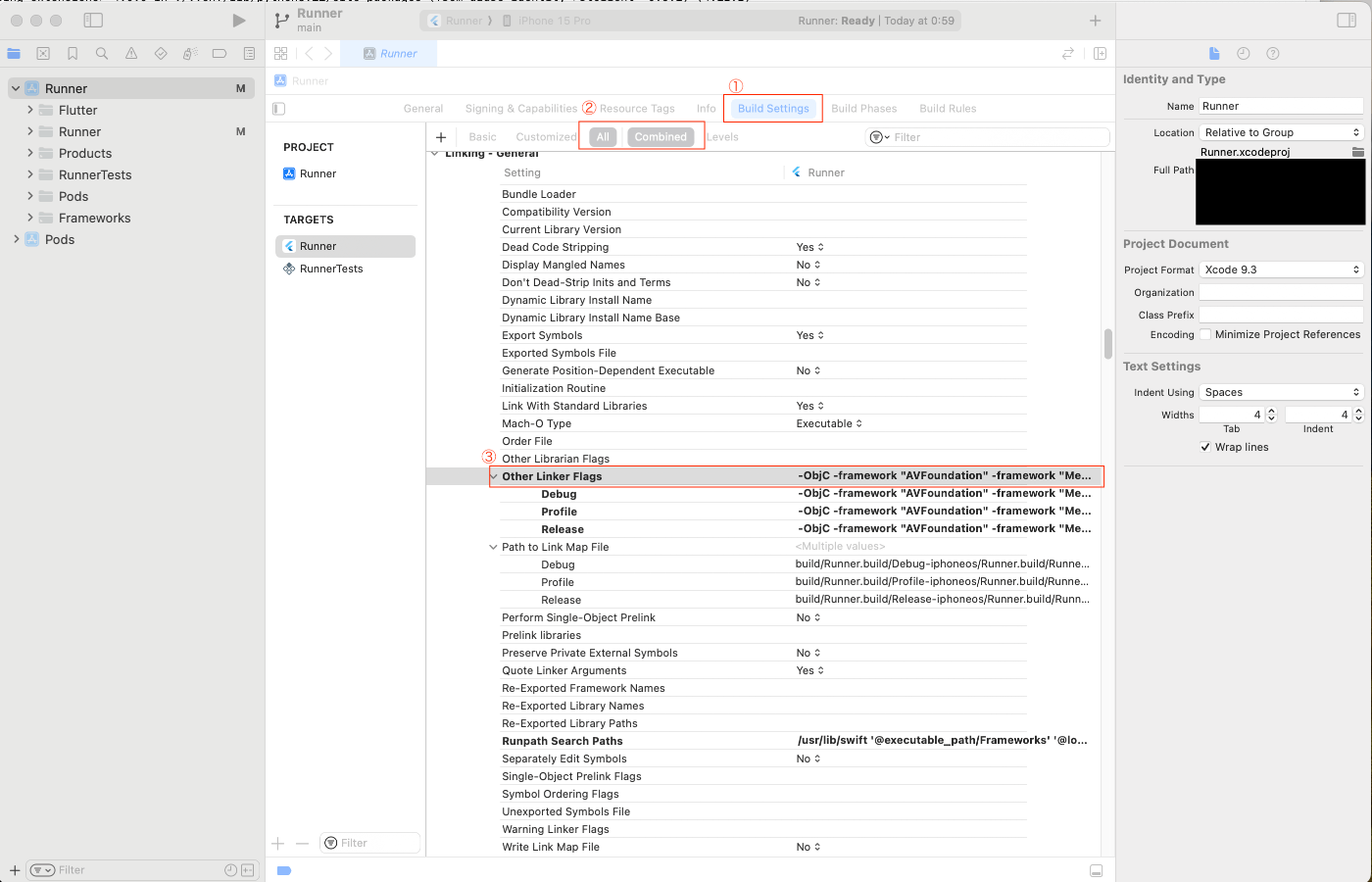
「+」ボタンをクリックして、「-lc++」を入力してエンター
VScodeに戻って、iosフォルダ配下にあるPodfileに以下のコードを追記
post_install do |installer|
installer.pods_project.targets.each do |target|
flutter_additional_ios_build_settings(target)
target.build_configurations.each do |config|
config.build_settings['OTHER_LDFLAGS'] ||= ['$(inherited)', '-ObjC', '-lc++']
end
end
end
最後にpodをインストール
cd ios && pod install
これでflutter_soundを使えるようになりました。
3. データを受け取り次第音声再生させるようにする
sendAudioToAPI関数を修正します。
処理は以下のようにします。
- acceptを
audio/wavに変更 - FlutterSoundPlayerのインスタンス化&初期化
-
startPlayerFromStreamメソッドでストリーミングオーディオ再生を開始 - APIからストリーミングで返ってきたデータをUint8Listに変換して、プレーヤーにフィードする
- プレーヤーが音声を再生し終わったら
closePlayerメソッドで終了
import 'package:flutter_sound/flutter_sound.dart' as fs;
Future<void> sendAudioToAPI(path) async {
final url = Uri.parse("http://127.0.0.1:8000/realtime_audio/");
var request = http.MultipartRequest(
'POST',
url,
);
Map<String, String> header = {
"Content-Type": "application/json",
"accept": "audio/wav",
};
request.headers.addAll(header);
request.files.add(await http.MultipartFile.fromPath('audio_file', path));
final response = await request.send();
if (response.statusCode == 200) {
fs.FlutterSoundPlayer _player =
fs.FlutterSoundPlayer(logLevel: Level.error);
await _player.openPlayer();
await _player.startPlayerFromStream(
codec: fs.Codec.pcm16, numChannels: 1, sampleRate: 20000);
await for (var chunk in response.stream) {
await _player.feedFromStream(Uint8List.fromList(chunk));
}
if (_player.playerState == fs.PlayerState.isStopped) {
await _player.closePlayer();
}
} else {
print('Failed to fetch audio stream: ${response.statusCode}');
}
}
4. UIをリッチにする
どうせなのでUIもちょっと頑張る
音声のレコーディングが終わって音声再生中のUIを変更します。
AnimatedContainerを使用します。
home: Scaffold(
resizeToAvoidBottomInset: true,
body: Center(
child: showPlayer
? AnimatedContainer(
duration: const Duration(milliseconds: 500),
width: _animation.value,
height: _animation.value,
decoration: BoxDecoration(
shape: BoxShape.circle,
color: Colors.blue,
),
)
: Recorder(
onStop: (path) {
if (kDebugMode) print('Recorded file path: $path');
setState(() {
audioPath = path;
showPlayer = true;
});
sendAudioToAPI(path);
},
),
),
),
クラスにTickerProviderStateMixinを追加とanimationの変数を二つ追加
class _VoiceApp extends ConsumerState<VoiceApp>
with TickerProviderStateMixin {
final GlobalKey _inputFormContainer = GlobalKey();
Size _inputFormContainerSize = Size.zero;
FocusNode inputNode = FocusNode();
bool showPlayer = false;
// ↓追加
late AnimationController _animationController;
late Animation<double> _animation;
追加した二つの変数をインスタンス化
void initState() {
super.initState();
showPlayer = false;
_animationController = AnimationController(
vsync: this,
duration: const Duration(milliseconds: 500),
);
_animation =
Tween<double>(begin: 50.0, end: 100.0).animate(_animationController)
..addListener(() {
setState(() {});
});
WidgetsBinding.instance.addPostFrameCallback((_) => getWidgetSize());
}
音声データから振り幅のサイズを計算する関数を作成
double calculateAmplitude(Uint8List chunk) {
Int16List pcmData = Int16List.view(chunk.buffer);
int maxAmplitude =
pcmData.reduce((a, b) => a.abs() > b.abs() ? a : b).abs();
return maxAmplitude.toDouble() / 32768.0 * 100.0;
}
最後にsendAudioToAPI関数に_animation.value更新処理を追加
Future<void> sendAudioToAPI(path) async {
final url = Uri.parse("http://127.0.0.1:8000/realtime_audio/");
var request = http.MultipartRequest(
'POST',
url,
);
Map<String, String> header = {
"Content-Type": "application/json",
"accept": "audio/wav",
};
request.headers.addAll(header);
request.files.add(await http.MultipartFile.fromPath('audio_file', path));
final response = await request.send();
if (response.statusCode == 200) {
fs.FlutterSoundPlayer _player =
fs.FlutterSoundPlayer(logLevel: Level.error);
await _player.openPlayer();
await _player.startPlayerFromStream(
codec: fs.Codec.pcm16, numChannels: 1, sampleRate: 20000);
await for (var chunk in response.stream) {
await _player.feedFromStream(Uint8List.fromList(chunk));
// ↓追加
double amplitude = calculateAmplitude(Uint8List.fromList(chunk));
_animation = Tween<double>(begin: 50.0, end: 50.0 + amplitude)
.animate(_animationController);
_animationController.forward(from: 0.0);
print(_animation.value);
}
if (_player.playerState == fs.PlayerState.isStopped) {
await _player.closePlayer();
}
print('Audio saved to ');
} else {
print('Failed to fetch audio stream: ${response.statusCode}');
}
}
動作
レスポンスがかなり早くなりました!
全然ストレスを感じないほど。
若干感情もこもった喋り方になってる気がしますね。

Discussion
駆け出しエンジニアで、初めてのflutter&RT通信で分からない箇所があるので教えてもらえると助かります
こちらの記事を読みながら私側で進めていたのですが2点躓いてます
■1点目
client_sample.pyで以下の関数のclient.items()のitemsが存在しないと言われます。
エラー内容: AttributeError: 'RTClient' object has no attribute 'items'
こちら同じようなエラーはでましたか?また、解決策を知っていたら教えてほしいです!
■2点目
client_sample.pyで以下の関数でwith open(instructions_file) as f:のinstructions_fileが未定義になります。
こちらはどんなファイルを開いているのでしょうか?