CopilotにはMetrics APIがある
昨年10月からGitHub Copilotの使用状況を取得できるAPIが提供されました。
組織の管理者権限を持つアカウントのアクセストークンじゃないと取得はできないようになっています。
APIからは以下のデータが取得することができます。
・過去28日間のデータ
・アクティブユーザーとエンゲージメントの高いユーザーの数
・GitHub Copilotのコード提案数、採用数、採用行数
・Copilot Chatの使用回数
・上記内容のIDE別、プログラミング言語別の内訳
やりたいこと
GitHub Copilotが一般リリースされてから全社的に導入を推進しています。
しかしアンケートやヒアリングといった方法でしか導入効果と活用率が見えていませんでした。
APIを使って正確な情報まで取得できるので、Microsoft Fabric(データ分析基盤環境)を使って、社内の利用状況を可視化してみます。
Fabricで構築
前提
自社の環境にFabricのリソースを作っておく必要があります。
※Microsoft Fabricは一番低いプランでも月5万円ほどかかります。
1. Workspaceを作成
今回のデータ分析環境を作成します。
「新しいワークスペース」を選択

ワークスペース名を入力して「適用」を選択

2. Lakehouseを作成
データを保存するストレージを作成します。
左上の「新しい項目」から「レイクハウス」を選択

名前を入力して「作成」を選択

2. Notebookを作成
PythonでMetrics APIを叩いて情報を取得します。
左上の「新しい項目」から「ノートブック」を選択
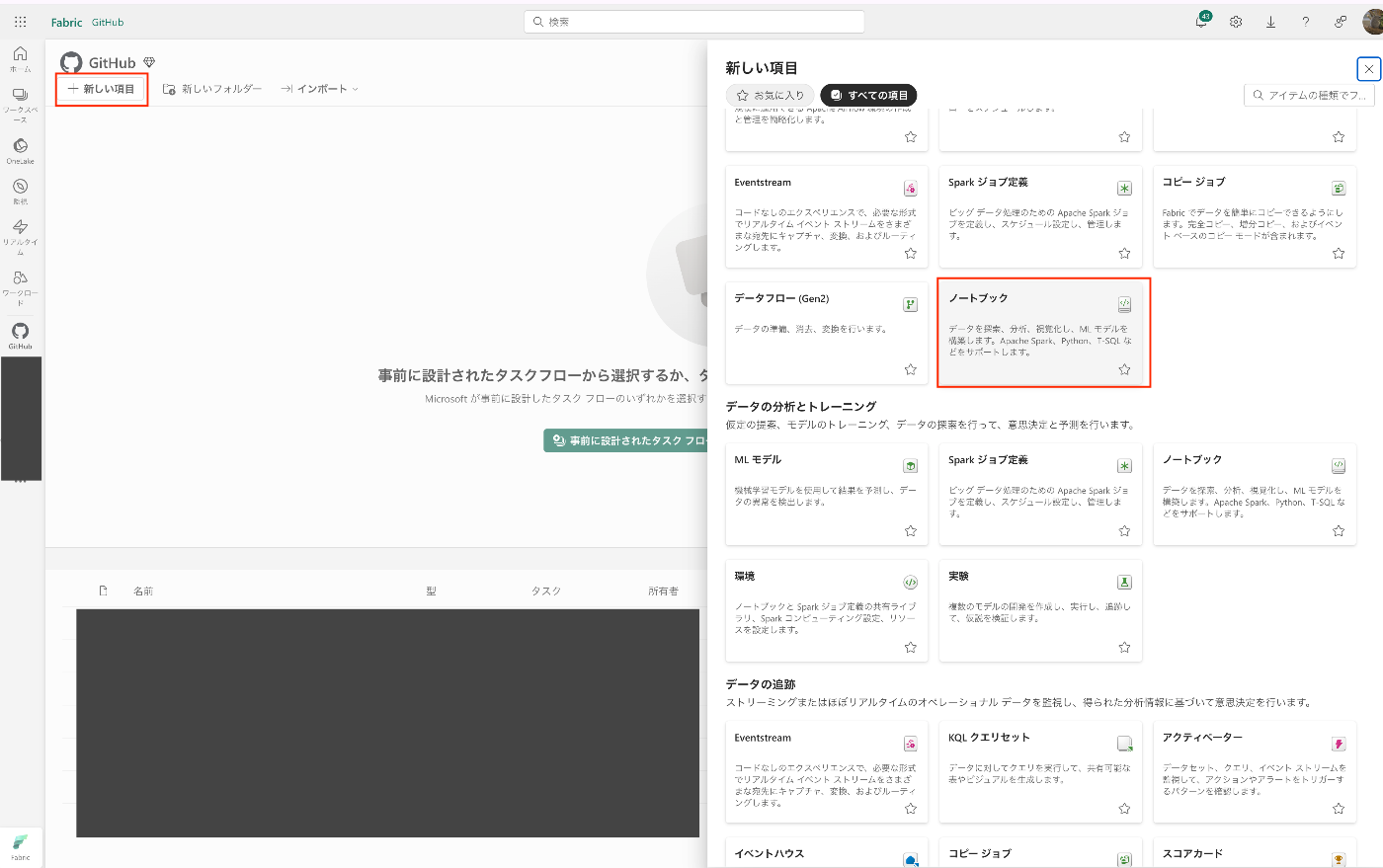
先ほど作成したLakehouseを紐づけます。
「Add data items」から「既存のデータソース」を選択
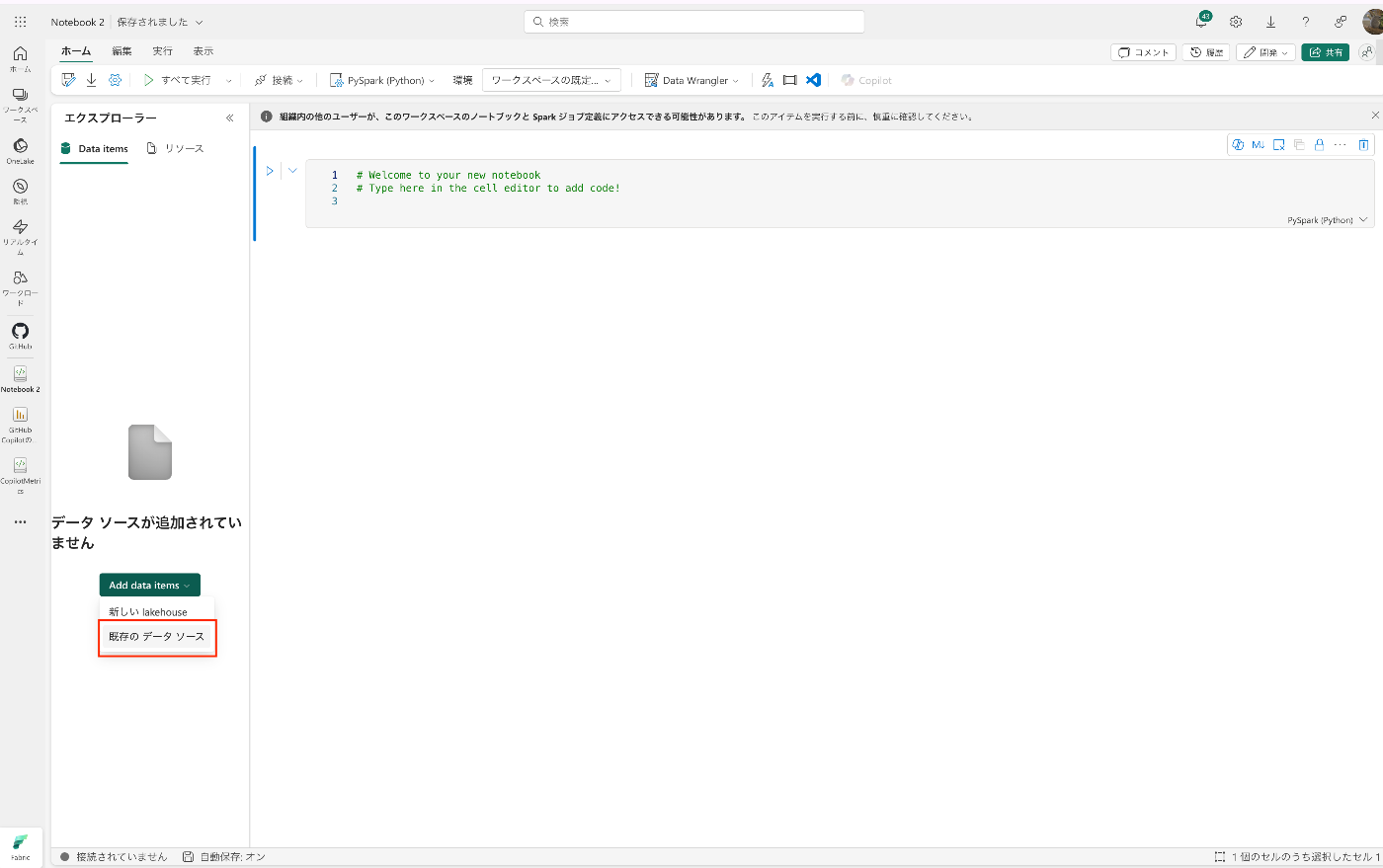
Lakehouseを選択して「接続」を選択

3. Metrics APIからデータ取得
access tokenにはGitHub.comの設定画面からトークンを作成したものを、orgには自分が所属している組織の名前を入れてください。
import requests
headers = {
"Accept": "application/vnd.github+json",
"Authorization": "Bearer <access token>",
"X-GitHub-Api-Version": "2022-11-28",
}
response = requests.get("https://api.github.com/orgs/<org>/copilot/metrics", headers=headers)
response_json = response.json()
情報が取得できました。

ちなみに普通にリクエストを飛ばすと28日分取得するので、日付を指定したい場合は以下のようにします。
例)前日の1日分だけ取得する場合
import requests
import datetime
from dateutil.relativedelta import relativedelta
today = datetime.date.today()
yesterday = today + relativedelta(days=-1)
headers = {
"Accept": "application/vnd.github+json",
"Authorization": "Bearer <access token>,
"X-GitHub-Api-Version": "2022-11-28",
}
params = {
"since": yesterday
}
response = requests.get("https://api.github.com/orgs/<org>/copilot/metrics", headers=headers, params=params)
response_json = response.json()
ここでAPIから取得できる情報の詳細を解説
日別に配列で情報を取得できます。
[
{
"date": "2024-06-24", # 日付
"total_active_users": 0, # アクティブユーザー数
"total_engaged_users": 0, # 利用ユーザー数
"copilot_ide_code_completions": { # IDE内でのコード提案に関する¥情報
"total_engaged_users": 0, # 利用ユーザー数
"languages": [ # 言語別に配列形式で格納
{
"name": "python", # 言語名
"total_engaged_users": 0 # 利用ユーザー数
}
],
"editors": [ # IDE別に配列型式で格納
{
"name": "vscode", # IDE名
"total_engaged_users": 0, # 利用ユーザー数
"models": [ # モデル別に配列型式で格納
{
"name": "default", # モデル名(defaultは通常のオリジナルモデル)
"is_custom_model": false, # カスタムモデルか
"custom_model_training_date": null, # いつカスタムさせたか
"total_engaged_users": 0, # 利用ユーザー数
"languages": [ # モデル内で言語別に配列型式で格納
{
"name": "python", # 言語名
"total_engaged_users": 0, # 利用ユーザー数
"total_code_suggestions": 0, # その言語で提案した回数
"total_code_acceptances": 0, # その言語で提案したコードが採用された回数
"total_code_lines_suggested": 0, # その言語で提案したコードの行数
"total_code_lines_accepted": 0 # その言語で提案したコードが採用された行数
},
]
}
]
},
]
},
"copilot_ide_chat": { # IDE内でCopilot Chatの情報
"total_engaged_users": 0, # 利用ユーザー数
"editors": [ # IDE別に配列型式で格納
{
"name": "vscode", # IDE名
"total_engaged_users": 0, # そのIDEで利用したユーザー数
"models": [ # モデル別に配列型式で格納
{
"name": "default", # モデル名
"is_custom_model": false, # カスタムモデルか
"custom_model_training_date": null, # いつカスタムしたか
"total_engaged_users": 0, # 利用ユーザー数
"total_chats": 0, # チャット回数
"total_chat_insertion_events": 0, # 提案したコードが挿入された回数
"total_chat_copy_events": 0 # 提案したコードがコピーされた回数
},
]
}
]
},
"copilot_dotcom_chat": { # GitHub.com内でのCopilot Chatの情報
"total_engaged_users": 0, # 利用ユーザー数
"models": [ # モデル別に配列型式で格納
{
"name": "default", # モデル名
"is_custom_model": false, # カスタムモデルか
"custom_model_training_date": null, # いつカスタムしたか
"total_engaged_users": 0, # 利用ユーザー数
"total_chats": 0 # チャット回数
}
]
},
"copilot_dotcom_pull_requests": { # GitHub.com内でCopilotのPull Request機能に関する情報
"total_engaged_users": 0, # 利用ユーザー数
"repositories": [ # リポジトリ別に配列型式で格納
{
"name": "demo/repo1", # リポジトリ名
"total_engaged_users": 8,
"models": [
{
"name": "default", # モデル名
"is_custom_model": false, # カスタムモデルか
"custom_model_training_date": null, # いつカスタムしたか
"total_pr_summaries_created": 0, # 要約機能を何回使用したか
"total_engaged_users": 0 # 利用ユーザー数
}
]
},
]
}
}
]
4. 取得したデータを加工
テーブルは以下の11個に分けて、リレーションシップで相互関係を結ぶようにします。
ですので、テーブルに入れるための11個の配列を用意。
# 全体のデータ
copilot_global_data =[]
# ideでのコード補完の使用状況
copilot_ide_completions = []
copilot_ide_completions_languages = []
copilot_ide_completions_editors = []
copilot_ide_completions_editor_models = []
copilot_ide_completions_editor_model_languages = []
# ideでのcopilot chatの使用状況
copilot_ide_chats = []
copilot_ide_chat_editors = []
copilot_ide_chat_editor_models = []
# githubでのcopilot chatの使用状況
copilot_dotcom_chats = []
copilot_dotcom_chat_models = []
# copilot for pull requestの使用状況
copilot_dotcom_pull_requests = []
copilot_doctcom_pr_repositories = []
APIから取得したレスポンスを上記11個の配列に追加していきます。
またリレーションを結ぶので、各配列ごとにuuidで一意のキーと親テーブルに値する配列のキーを持たせます。
import uuid
for entry in response_json:
global_id = uuid.uuid4()
copilot_global_data.append({
"global_id": global_id,
"date": entry.get("date"),
"total_active_users": entry.get("total_active_users"),
"total_engaged_users": entry.get("total_engaged_users")
})
completions = entry.get("copilot_ide_code_completions", {})
copilot_ide_completion_id = uuid.uuid4()
copilot_ide_completions.append({
"copilot_ide_completion_id":copilot_ide_completion_id,
"global_id": global_id,
"total_engaged_users": completions.get("total_engaged_users")
})
for lang in completions.get("languages", []):
copilot_ide_completions_language_id = uuid.uuid4()
copilot_ide_completions_languages.append({
"copilot_ide_completions_language_id": copilot_ide_completions_language_id,
"copilot_ide_completion_id":copilot_ide_completion_id,
"language": lang.get("name"),
"total_engaged_users": lang.get("total_engaged_users")
})
for editor in completions.get("editors", []):
copilot_ide_completions_editor_id = uuid.uuid4()
copilot_ide_completions_editors.append({
"copilot_ide_completions_editor_id": copilot_ide_completions_editor_id,
"copilot_ide_completion_id":copilot_ide_completion_id,
"editor": editor.get("name"),
"total_engaged_users": editor.get("total_engaged_users")
})
for model in editor.get("models", []):
copilot_ide_completions_editor_model_id = uuid.uuid4()
copilot_ide_completions_editor_models.append({
"copilot_ide_completions_editor_model_id": copilot_ide_completions_editor_model_id,
"copilot_ide_completions_editor_id":copilot_ide_completions_editor_id,
"model": model.get("name"),
"is_custom_model": model.get("is_custom_model"),
"custom_model_training_date": model.get("custom_model_training_date"),
"total_engaged_users": model.get("total_engaged_users")
})
for model_lang in model.get("languages", []):
copilot_ide_completions_editor_model_language_id = uuid.uuid4()
copilot_ide_completions_editor_model_languages.append({
"copilot_ide_completions_editor_model_language_id": copilot_ide_completions_editor_model_language_id,
"copilot_ide_completions_editor_model_id":copilot_ide_completions_editor_model_id,
"language": model_lang.get("name"),
"total_engaged_users": model_lang.get("total_engaged_users"),
"total_code_suggestions": model_lang.get("total_code_suggestions"),
"total_code_acceptances": model_lang.get("total_code_acceptances"),
"total_code_lines_suggested": model_lang.get("total_code_lines_suggested"),
"total_code_lines_accepted": model_lang.get("total_code_lines_accepted"),
})
ide_chat = entry.get("copilot_ide_chat", {})
ide_chat_id = uuid.uuid4()
copilot_ide_chats.append({
"copilot_ide_chat_id": ide_chat_id,
"global_id": global_id,
"total_engaged_users": ide_chat.get("total_engaged_users")
})
for editor in ide_chat.get("editors", []):
ide_chat_editor_id = uuid.uuid4()
copilot_ide_chat_editors.append({
"copilot_ide_chat_editor_id": ide_chat_editor_id,
"copilot_ide_chat_id": ide_chat_id,
"name": editor.get("name"),
"total_engaged_users": editor.get("total_engaged_users")
})
for model in editor.get("models", []):
ide_chat_editor_model_id = uuid.uuid4()
copilot_ide_chat_editor_models.append({
"copilot_ide_chat_editor_model_id": ide_chat_editor_model_id,
"copilot_ide_chat_editor_id": ide_chat_editor_id,
"name": model.get("name"),
"is_custom_model": model.get("is_custom_model"),
"custom_model_training_date": model.get("custom_model_training_date"),
"total_engaged_users": model.get("total_engaged_users"),
"total_chats": model.get("total_chats"),
"total_chat_insertion_events": model.get("total_chat_insertion_events"),
"total_chat_copy_events": model.get("total_chat_copy_events"),
})
dotcom_chat = entry.get("copilot_dotcom_chat", {})
dotcom_chat_id = uuid.uuid4()
copilot_dotcom_chats.append({
"copilot_dotcom_chat_id": dotcom_chat_id,
"global_id": global_id,
"total_engaged_users": dotcom_chat.get("total_engaged_users")
})
for model in dotcom_chat.get("models", []):
dotcom_chat_model_id = uuid.uuid4()
copilot_dotcom_chat_models.append({
"copilot_dotcom_chat_model_id": dotcom_chat_model_id,
"copilot_dotcom_chat_id": dotcom_chat_id,
"name": model.get("name"),
"is_custom_model": model.get("is_custom_model"),
"custom_model_training_date": model.get("custom_model_training_date"),
"total_engaged_users": model.get("total_engaged_users"),
"total_chats": model.get("total_chats")
})
5. Lakehouseにデータを追加
配列にデータが入ったので、DataFrameを作成して、テーブルに追加させます。
データの型が暗黙値になっているので、明示的に定義することをおすすめします。
copilot_global_data
# copilot_global_data
import pandas as pd
from pyspark.sql.types import StringType, StructField, DateType, IntegerType, StructType, BooleanType
columns = ['global_id', 'date', 'total_active_users', 'total_engaged_users']
df = pd.DataFrame(copilot_global_data, columns=columns)
df["global_id"] = df["global_id"].astype(str)
df["date"] = pd.to_datetime(df['date'])
schema = StructType([
StructField("global_id", StringType(), True),
StructField("date", DateType(), True),
StructField("total_active_users", IntegerType(), True),
StructField("total_engaged_users", IntegerType(), True),
])
spark_df = spark.createDataFrame(df, schema=schema)
spark_df.write.mode("append").format("delta").save("Tables/"+ "copilot_global_data")
copilot_ide_completions
# copilot_ide_completions
columns = ['copilot_ide_completion_id', 'global_id','total_engaged_users']
df = pd.DataFrame(copilot_ide_completions, columns=columns)
df["global_id"] = df["global_id"].astype(str)
df["copilot_ide_completion_id"] = df["copilot_ide_completion_id"].astype(str)
schema = StructType([
StructField("copilot_ide_completion_id", StringType(), True),
StructField("global_id", StringType(), True),
StructField("total_engaged_users", IntegerType(), True),
])
spark_df = spark.createDataFrame(df, schema=schema)
spark_df.write.mode("append").format("delta").save("Tables/"+ "copilot_ide_completions")
copilot_ide_completions_languages
# copilot_ide_completions_languages
columns = ['copilot_ide_completions_language_id', 'copilot_ide_completion_id', 'language', 'total_engaged_users']
df = pd.DataFrame(copilot_ide_completions_languages, columns=columns)
df["copilot_ide_completion_id"] = df["copilot_ide_completion_id"].astype(str)
df["copilot_ide_completions_language_id"] = df["copilot_ide_completions_language_id"].astype(str)
schema = StructType([
StructField("copilot_ide_completions_language_id", StringType(), True),
StructField("copilot_ide_completion_id", StringType(), True),
StructField("language", StringType(), True),
StructField("total_engaged_users", IntegerType(), True),
])
spark_df = spark.createDataFrame(df, schema=schema)
spark_df.write.mode("append").format("delta").save("Tables/"+ "copilot_ide_completions_languages")
copilot_ide_completions_editors
# copilot_ide_completions_editors
columns = ['copilot_ide_completions_editor_id', 'copilot_ide_completion_id', 'editor', 'total_engaged_users']
df = pd.DataFrame(copilot_ide_completions_editors, columns=columns)
df["copilot_ide_completion_id"] = df["copilot_ide_completion_id"].astype(str)
df["copilot_ide_completions_editor_id"] = df["copilot_ide_completions_editor_id"].astype(str)
schema = StructType([
StructField("copilot_ide_completions_editor_id", StringType(), True),
StructField("copilot_ide_completion_id", StringType(), True),
StructField("editor", StringType(), True),
StructField("total_engaged_users", IntegerType(), True),
])
spark_df = spark.createDataFrame(df, schema=schema)
spark_df.write.mode("append").format("delta").save("Tables/"+ "copilot_ide_completions_editors")
copilot_ide_completions_editor_models
# copilot_ide_completions_editor_models
columns = ['copilot_ide_completions_editor_model_id', 'copilot_ide_completions_editor_id', 'model', 'is_custom_model', 'custom_model_training_date', 'total_engaged_users']
df = pd.DataFrame(copilot_ide_completions_editor_models, columns=columns)
df["custom_model_training_date"] = pd.to_datetime(df['custom_model_training_date'])
df["copilot_ide_completions_editor_id"] = df["copilot_ide_completions_editor_id"].astype(str)
df["copilot_ide_completions_editor_model_id"] = df["copilot_ide_completions_editor_model_id"].astype(str)
df["is_custom_model"] = df["is_custom_model"].astype(bool)
schema = StructType([
StructField("copilot_ide_completions_editor_model_id", StringType(), True),
StructField("copilot_ide_completions_editor_id", StringType(), True),
StructField("model", StringType(), True),
StructField("is_custom_model", BooleanType(), True),
StructField("custom_model_training_date", DateType(), True),
StructField("total_engaged_users", IntegerType(), True),
])
spark_df = spark.createDataFrame(df, schema=schema)
spark_df.write.mode("append").format("delta").save("Tables/"+ "copilot_ide_completions_editor_models")
copilot_ide_completions_editor_model_languages
# copilot_ide_completions_editor_model_languages
columns = ['copilot_ide_completions_editor_model_language_id', 'copilot_ide_completions_editor_model_id', 'language', 'total_engaged_users', 'total_code_suggestions', 'total_code_acceptances', 'total_code_lines_suggested', 'total_code_lines_accepted']
df = pd.DataFrame(copilot_ide_completions_editor_model_languages, columns=columns)
df["copilot_ide_completions_editor_model_language_id"] = df["copilot_ide_completions_editor_model_language_id"].astype(str)
df["copilot_ide_completions_editor_model_id"] = df["copilot_ide_completions_editor_model_id"].astype(str)
schema = StructType([
StructField("copilot_ide_completions_editor_model_language_id", StringType(), True),
StructField("copilot_ide_completions_editor_model_id", StringType(), True),
StructField("language", StringType(), True),
StructField("total_engaged_users", IntegerType(), True),
StructField("total_code_suggestions", IntegerType(), True),
StructField("total_code_acceptances", IntegerType(), True),
StructField("total_code_lines_suggested", IntegerType(), True),
StructField("total_code_lines_accepted", IntegerType(), True),
])
spark_df = spark.createDataFrame(df, schema=schema)
spark_df.write.mode("append").format("delta").save("Tables/"+ "copilot_ide_completions_editor_model_languages")
copilot_ide_chats
# copilot_ide_chats
columns = ['copilot_ide_chat_id', 'global_id','total_engaged_users']
df = pd.DataFrame(copilot_ide_chats, columns=columns)
df["copilot_ide_chat_id"] = df["copilot_ide_chat_id"].astype(str)
df["global_id"] = df["global_id"].astype(str)
schema = StructType([
StructField("copilot_ide_chat_id", StringType(), True),
StructField("global_id", StringType(), True),
StructField("total_engaged_users", IntegerType(), True),
])
spark_df = spark.createDataFrame(df, schema=schema)
spark_df.write.mode("append").format("delta").save("Tables/"+ "copilot_ide_chats")
copilot_ide_chat_editors
# copilot_ide_chat_editors
columns = ['copilot_ide_chat_editor_id', 'copilot_ide_chat_id', 'name', 'total_engaged_users']
df = pd.DataFrame(copilot_ide_chat_editors, columns=columns)
df["copilot_ide_chat_editor_id"] = df["copilot_ide_chat_editor_id"].astype(str)
df["copilot_ide_chat_id"] = df["copilot_ide_chat_id"].astype(str)
schema = StructType([
StructField("copilot_ide_chat_editor_id", StringType(), True),
StructField("copilot_ide_chat_id", StringType(), True),
StructField("name", StringType(), True),
StructField("total_engaged_users", IntegerType(), True),
])
spark_df = spark.createDataFrame(df, schema=schema)
# spark_df.write.mode("overwrite").format("delta").save("Tables/"+ "copilot_ide_chat_editors")
spark_df.write.mode("append").format("delta").save("Tables/"+ "copilot_ide_chat_editors")
copilot_ide_chat_editor_models
# copilot_ide_chat_editor_models
columns = ['copilot_ide_chat_editor_model_id', 'copilot_ide_chat_editor_id', 'name', 'is_custom_model', 'custom_model_training_date', 'total_engaged_users', 'total_chats', 'total_chat_insertion_events', 'total_chat_copy_events']
df = pd.DataFrame(copilot_ide_chat_editor_models, columns=columns)
df["custom_model_training_date"] = pd.to_datetime(df['custom_model_training_date'])
df["copilot_ide_chat_editor_model_id"] = df["copilot_ide_chat_editor_model_id"].astype(str)
df["copilot_ide_chat_editor_id"] = df["copilot_ide_chat_editor_id"].astype(str)
df["is_custom_model"] = df["is_custom_model"].astype(bool)
schema = StructType([
StructField("copilot_ide_chat_editor_model_id", StringType(), True),
StructField("copilot_ide_chat_editor_id", StringType(), True),
StructField("name", StringType(), True),
StructField("is_custom_model", BooleanType(), True),
StructField("custom_model_training_date", DateType(), True),
StructField("total_engaged_users", IntegerType(), True),
StructField("total_chats", IntegerType(), True),
StructField("total_chat_insertion_events", IntegerType(), True),
StructField("total_chat_copy_events", IntegerType(), True),
])
spark_df = spark.createDataFrame(df, schema=schema)
spark_df.write.mode("append").format("delta").save("Tables/"+ "copilot_ide_chat_editor_models")
copilot_dotcom_chats
# copilot_dotcom_chats
columns = ['copilot_dotcom_chat_id', 'global_id','total_engaged_users']
df = pd.DataFrame(copilot_dotcom_chats, columns=columns)
df["global_id"] = df["global_id"].astype(str)
df["copilot_dotcom_chat_id"] = df["copilot_dotcom_chat_id"].astype(str)
schema = StructType([
StructField("copilot_dotcom_chat_id", StringType(), True),
StructField("global_id", StringType(), True),
StructField("total_engaged_users", IntegerType(), True),
])
spark_df = spark.createDataFrame(df, schema=schema)
# spark_df.write.mode("overwrite").format("delta").save("Tables/"+ "copilot_dotcom_chats")
spark_df.write.mode("overwrite").format("delta").save("Tables/"+ "copilot_dotcom_chats")
copilot_dotcom_chat_models
# copilot_dotcom_chat_models
columns = ['copilot_dotcom_chat_model_id', 'copilot_dotcom_chat_id', 'name', 'is_custom_model', 'custom_model_training_date', 'total_engaged_users', 'total_chats']
df = pd.DataFrame(copilot_dotcom_chat_models, columns=columns)
df["copilot_dotcom_chat_model_id"] = df["copilot_dotcom_chat_model_id"].astype(str)
df["copilot_dotcom_chat_id"] = df["copilot_dotcom_chat_id"].astype(str)
df["custom_model_training_date"] = pd.to_datetime(df['custom_model_training_date'])
df["is_custom_model"] = df["is_custom_model"].astype(bool)
schema = StructType([
StructField("copilot_dotcom_chat_model_id", StringType(), True),
StructField("copilot_dotcom_chat_id", StringType(), True),
StructField("name", StringType(), True),
StructField("is_custom_model", BooleanType(), True),
StructField("custom_model_training_date", DateType(), True),
StructField("total_engaged_users", IntegerType(), True),
StructField("total_chats", IntegerType(), True),
])
spark_df = spark.createDataFrame(df, schema=schema)
spark_df.write.mode("append").format("delta").save("Tables/"+ "copilot_dotcom_chat_models")
6. リレーションシップを作成
レイクハウスを開いて、「新しいセマンティックモデル」を選択

先ほど作成したテーブルを全て選択します。
ここで作成したセマンティックモデルはDirectLake方式でデータの取り込みがされます。

以下のようにリレーションシップを作成しました。

7. Power BI Desktopでレポート作成
Power BI Service(Web)でもいいのですが、テーマカラー設定ができないのでDesktopでやります。
「OneLakeカタログ」内の「Power BIのセマンティックモデル」を選択
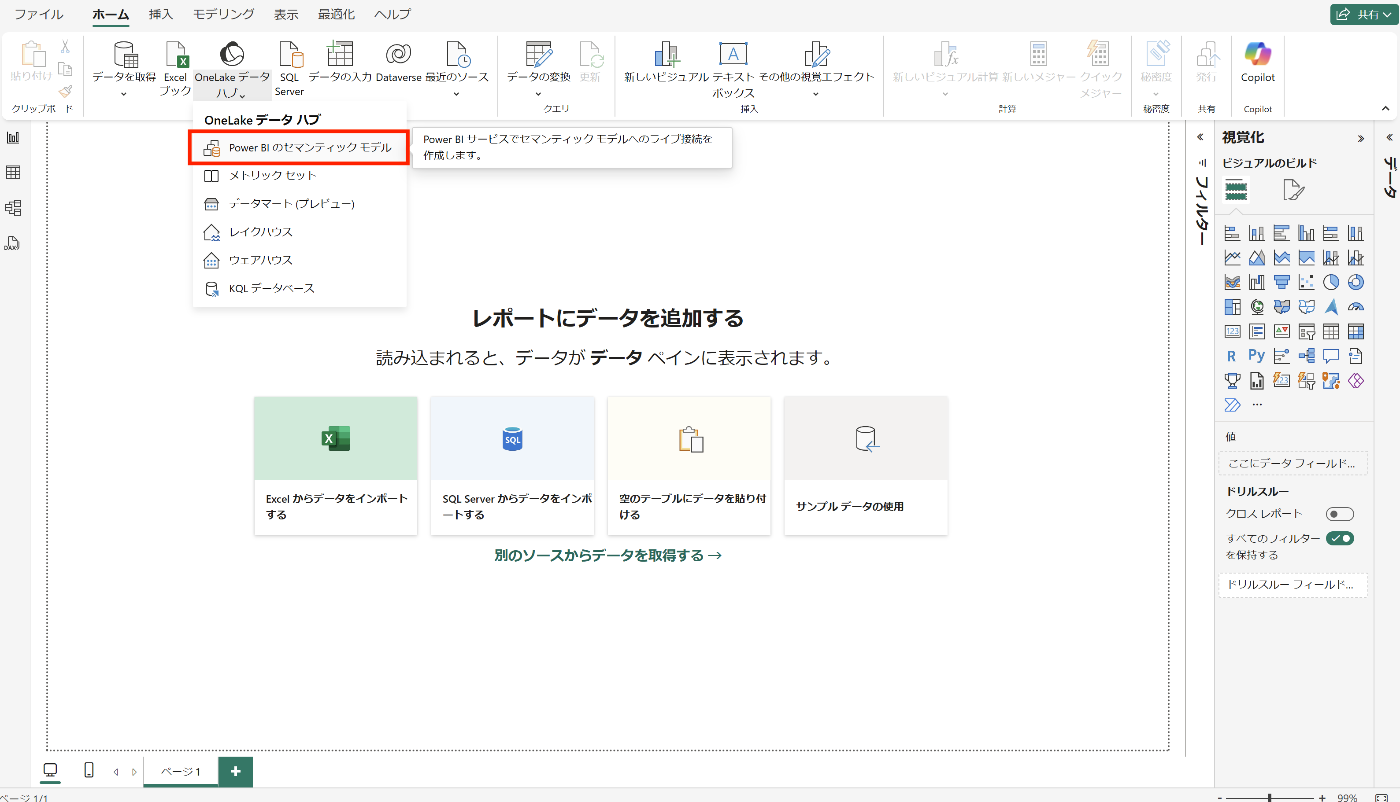
先ほど作成したセマンティックモデルが出てくると思うので選択して接続

データが取り込めれました。

取得できる情報をもとにビジュアルが作れたので、Fabric環境にアップします。
右上の「発行」を選択

ワークスペースを選択して、アップロードが完了すると以下のようになります。
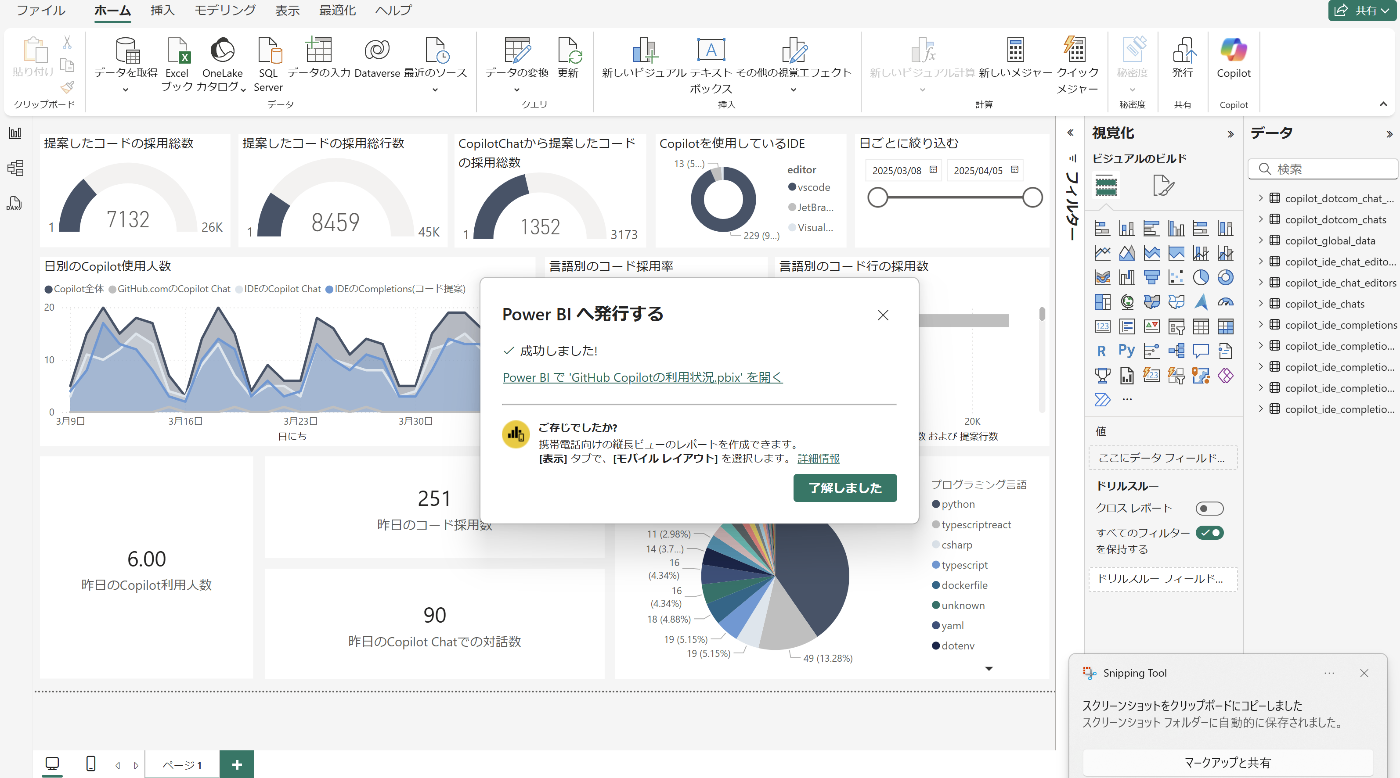
Power BIレポートがワークスペース内に追加されました。
これで一通り完了です。

確認
以下のように可視化してみました。
弊社ではVScodeでPythonの利用が圧倒的に多いようです。
営業日(平日)は大体15~20人が使ってるのですが、まだまだ少ない気がするのでもっと増やしていきたいです。

最後に
ちょうど1年前にZennの取り組み状況を可視化するためにFabricを使い始めました。
↓これ
以前から大きく仕様が変わったことはないのですが以下は改善してくれるとより使いやすくなるなーと思いました。
Power BI Services(Web)でもレポートのテーマカラーを設定できるようにしてほしい
これ何でできないんだ..
結構需要あると思うんだけどなー
現状はDesktop版じゃないとできません。
Dataflow Gen2を使わなくてもImport方式でデータを取り込めれるようにしてほしい
今回のケースは1日に1回データ更新すればいいので、ベストはImport方式です。
DirectLake方式が推奨されてるので今回も採用していますが、Import方式の方がレポートの読み込みが速くなるので、方式を選択できるようになるといいなーと。
ちなみにDataflow Gen2を使えばImport方式で取り込めれるのですが、Dataflow Gen2自体がものすごい容量を使ってしまうので中々手出しづらいです...
Notebookで環境変数の定義できるようにしてほしい
もしかしたら方法があるのかもですが、調べてみた限り分かりませんでした。
Notebook内のロジックは見えるけど、Access Tokenは他の社員に見えないようにしたいのですが、方法があるのかな?

Discussion
これめっちゃ面白いですね!
ちなみに、GitHub Copilot の使用回数が多いユーザーとかって取得できたりするんですかね?
ユーザーまでは取得ができませんでしたねー
僕的には
・既存コードの改修に使っているのか
・テストコード生成に使っているのか
・0からベースとなるコードの生成に使っているのか
も知りたかったのですが、ここら辺はおいおいAPIがアップデートして盛り込まれることに期待です!