やりたいこと
今年から全社的に取り組んでいるZennでのテック記事投稿の状況を可視化できるようにしたいです。
Microsoft Fabricとは?
データ分析を円滑に行うための統合サービスです。
データ統合やデータエンジニアリング・データサイエンスからビジネスインテリジェンスまで、さまざまな環境が提供されています。
ZennにはAPIがあるっぽい
RSS以外にAPIもあるとのこと。
ユーザー単位以外にもpublication単位での投稿も取得できるようです。(API自体非公式です)
可視化までの流れ

使うサービス
- Python(Notebookで使用)
- Power BI Desktop(Power BI Service内のレポート作成でも問題なし)
- LakeHouse
- Dataflow
- SharePointリスト
環境準備
1. ワークスペースの作成
2. 容量の紐付け
以下の記事にFabric容量と紐づける方法が記載されてますので、参考にしてみてください!
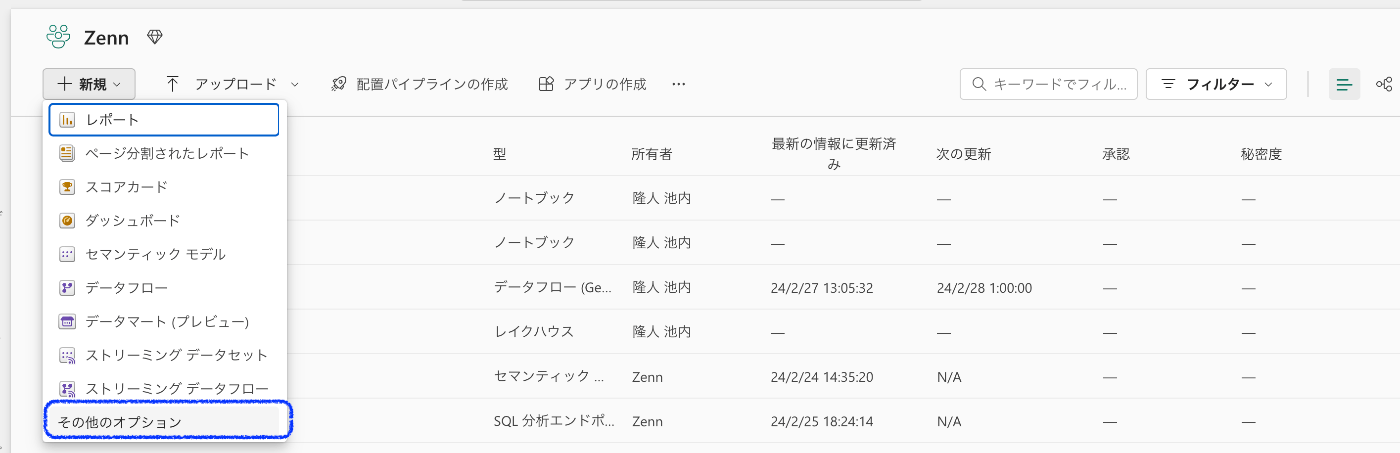
3. レイクハウスの作成
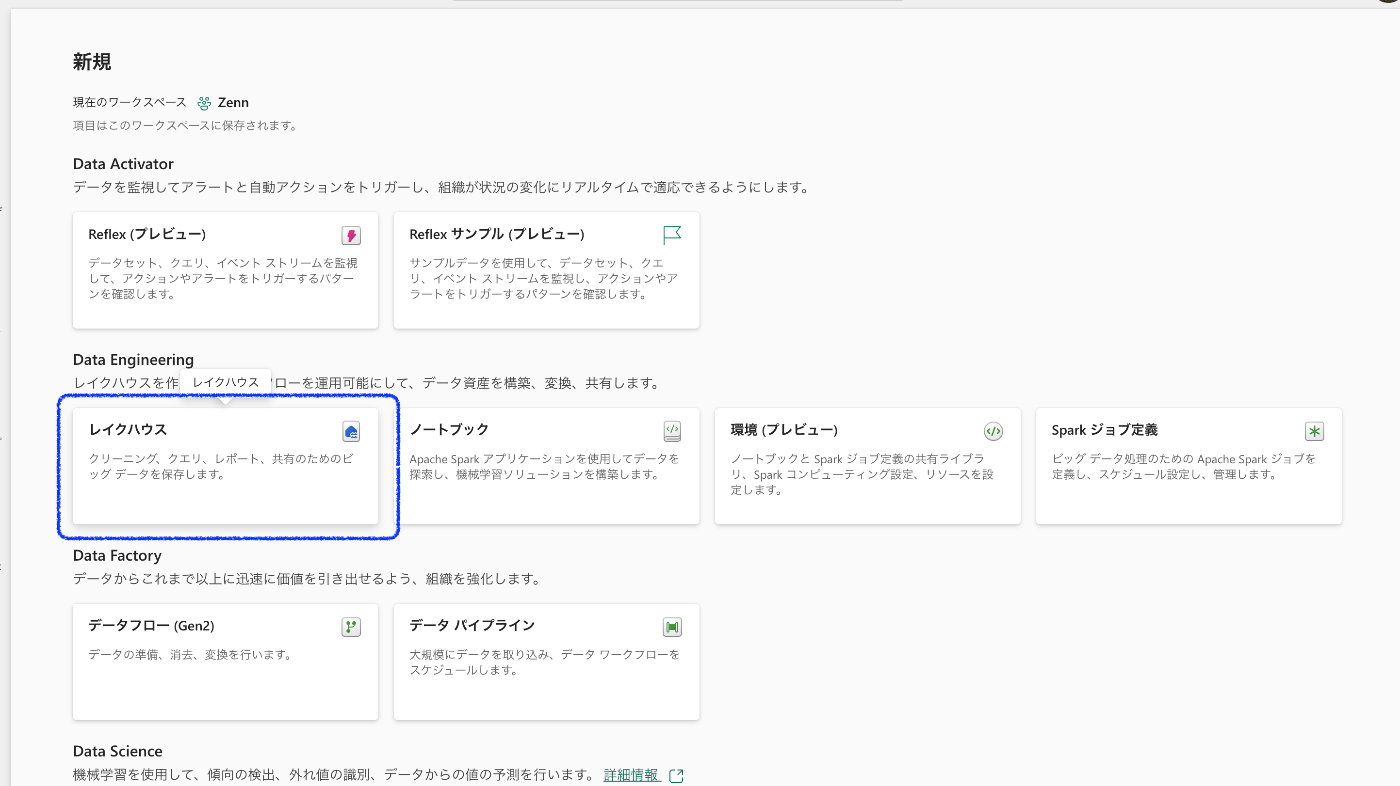
ワークスペース内の新規から「その他オプション」を選択
Data Engineeringの「レイクハウス」を選択
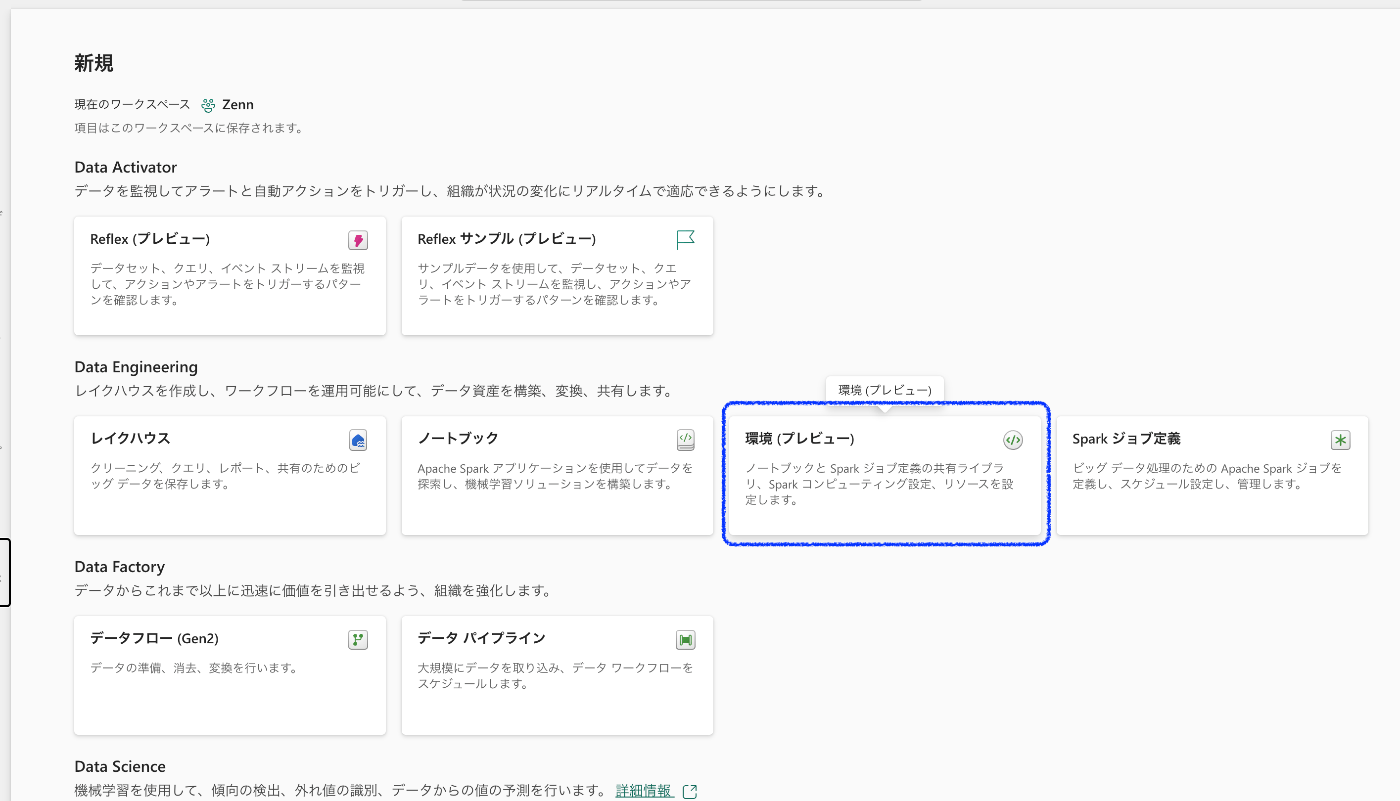
4. 環境の作成
「2.」と同じようにその他オプションで開かれる画面のData Engineeringエリアにある「環境」を選択。
実装:SharePointからデータを取得
1. SharePointリストを作成しておく
予めSharePointリストにフルネームと所属チーム、ZennのユーザーネームとIDを登録しておきます。
新しくヘッドウォータースのPublicationに追加されるときに、ここにも記載してもらうようにします。
こちらは出来れば自動化したいところですが、仕方がないです。
こちらのURLをコピーしておきます。
あとで使用しますので、青枠で囲われているところをコピーしておいてください

2. データフローの作成
ワークスペースに戻って、Data Factoryの「データフロー(Gen2)」を選択
3. SharePointリストを選択
作成したDataflowを開いて、「データを取得」の「詳細」を選択
取得方法がずらっと出るので、「SharePoint Online リスト」を選択
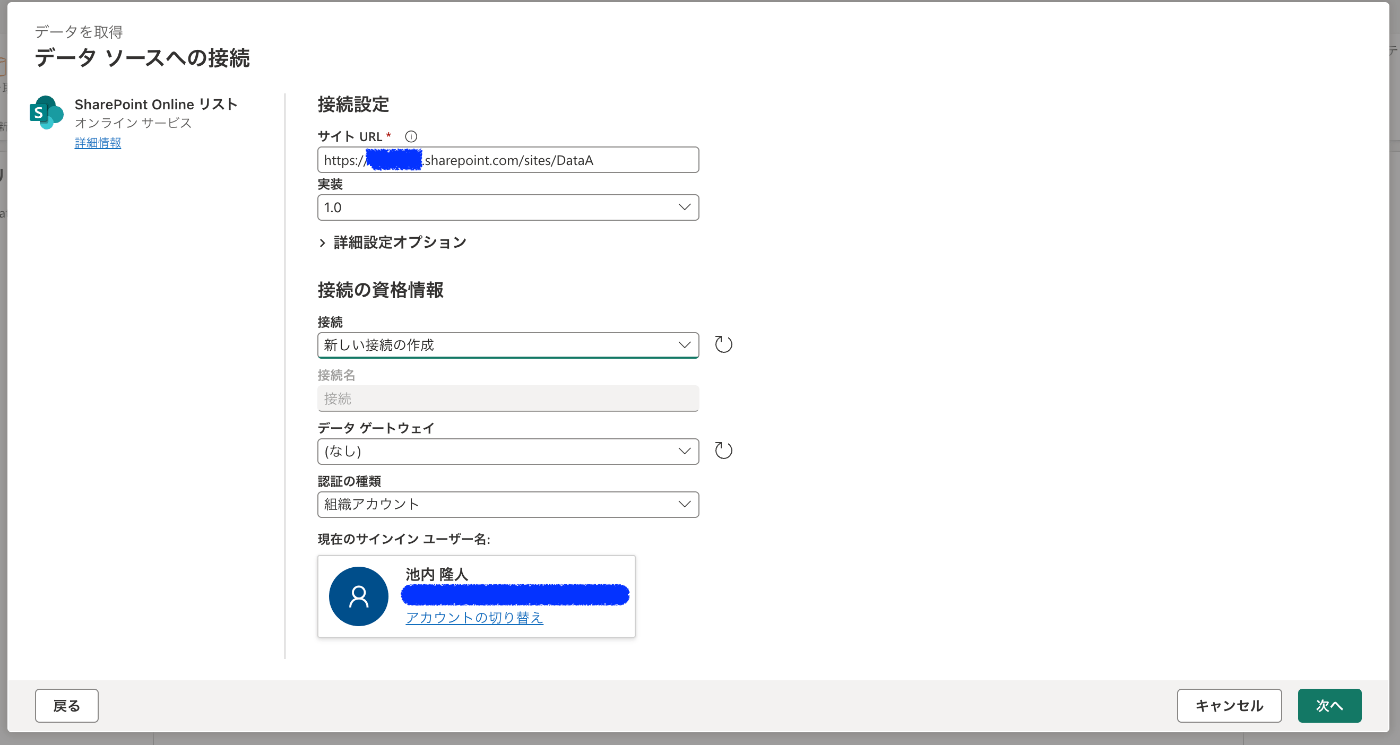
先ほどコピーしたURLを「サイトURL」にペーストします。
初めてのURLは接続の資格情報を登録する必要がありますので、データゲートウェイと認証の種類を選択して、「作成」をクリック
4. データの整形
するとSharePoint上のデータが一覧で出てくるので、Zennのメンバーを管理しているリスト名を選択
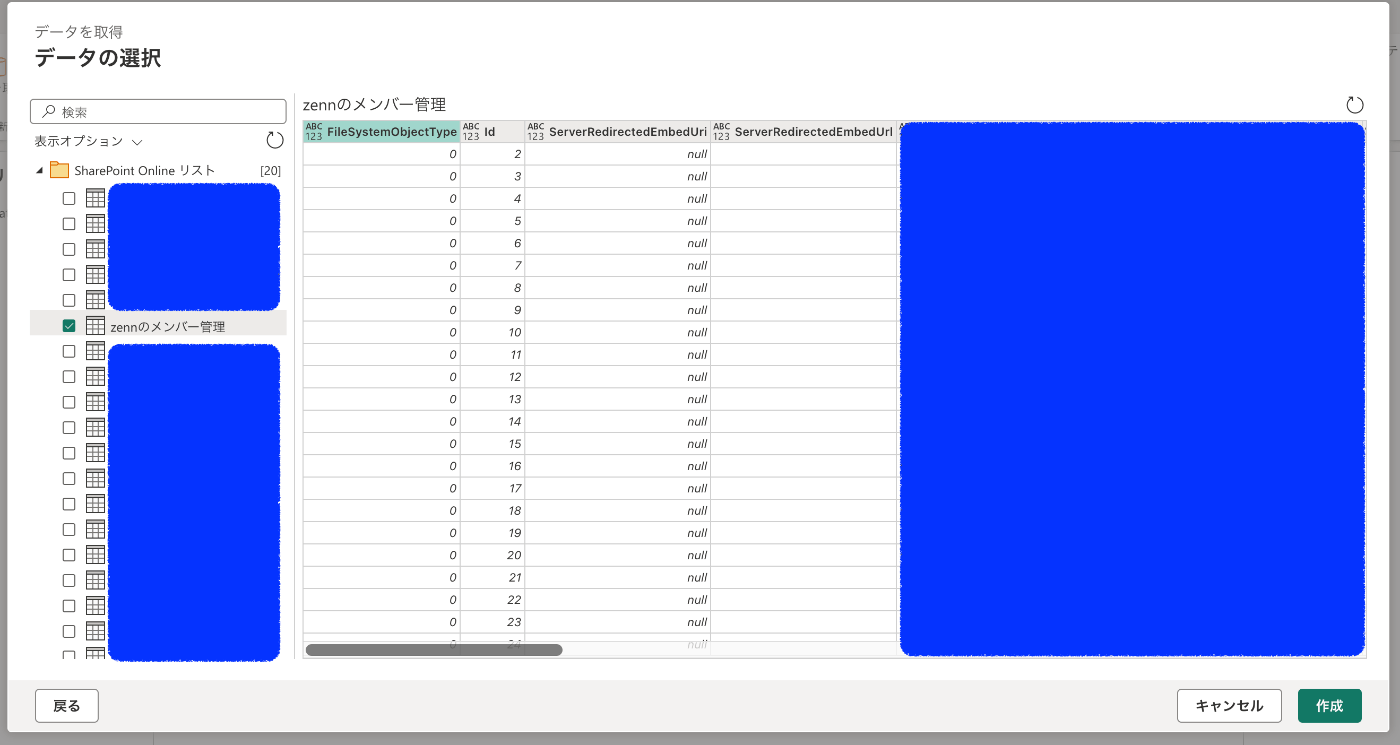
これで一応データの取り込みはできたので、あとはデータの整形をしていきます。
テーブル名は日本語から英語に変更しました。
不要な列が多いので、必要な列だけに絞り込んでます。

5. データの同期
最後にデータの同期先を設定します。
既にレイクハウスを作成してる場合は自動でレイクハウスの設定ができていますが、更新方法がデフォルトで「追加」になっているので、どのみち再設定が必要です。。。
画面右下の「データ同期先」内の歯車を選択

「レイクハウス」を選択

僕の場合は同期先のテーブルを既にテーブルを作っちゃってますが、本来はないと思うので、「新しいテーブル」を選択して、テーブル名を入力。(テーブル名は同じでいいかと)

アペンド(追加)か置換か選べるので、置換を選択
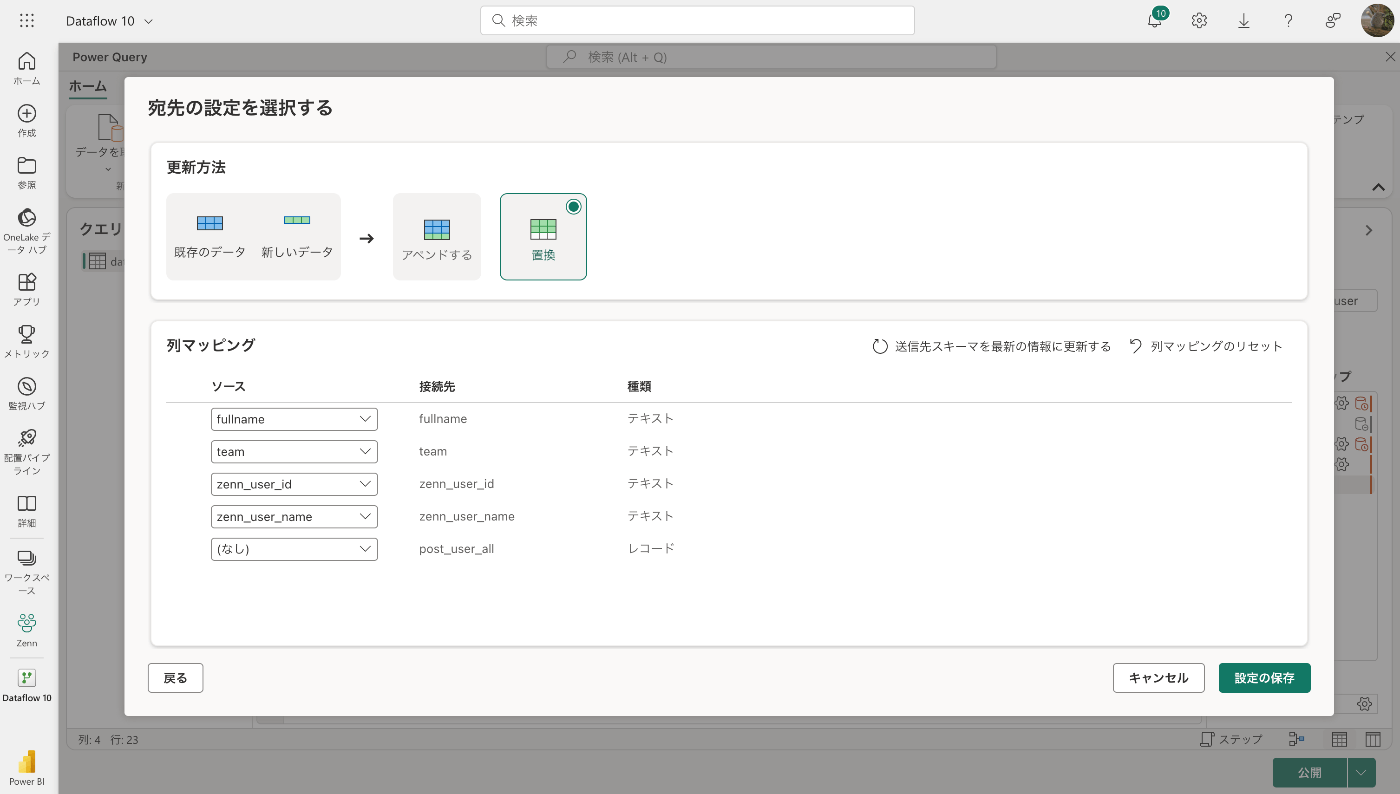
更新方法が「置換」になっていればOK
「公開」をクリック

実装:カレンダーテーブルを作成
1. Notebookの作成
ノートブックの作成

言語を「PySpark」、環境を先ほど作成した環境に設定

2. レイクハウスの設定
レイクハウスの追加をします。
既に作成してあるので、「既存のレイクハウス」を選択

対象のレイクハウスを選択

3. カレンダーを作成する処理
以下の記事を参考にさせていただきました。
あとは追加で曜日は日本語 + 語尾に「月」を付けるようにしました。
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit, current_date, datediff, months_between, trunc, floor
from pyspark.sql.functions import year, month, dayofmonth, weekofyear, dayofweek, date_format, expr
import pyspark.sql.functions as F
from datetime import datetime, timedelta
from pyspark.sql.types import DateType, StringType
day_of_week_dict = {
0: '月曜日',
1: '火曜日',
2: '水曜日',
3: '木曜日',
4: '金曜日',
5: '土曜日',
6: '日曜日'
}
def get_day_of_week(date):
return day_of_week_dict[date.weekday()]
get_day_of_week_udf = F.udf(get_day_of_week, StringType())
def create_calendar_table_spark(start_date, end_date, first_fiscal_year=None, start_fiscal_month=None):
# 文字列をdatetimeオブジェクトに変換
start_date = datetime.strptime(start_date, '%Y-%m-%d')
end_date = datetime.strptime(end_date, '%Y-%m-%d')
# 日付の範囲を生成
date_range = [start_date + timedelta(days=x) for x in range((end_date - start_date).days + 1)]
df = spark.createDataFrame(date_range, DateType()).toDF("date")
# 現在日時(タイムゾーンを考慮せず)
today = datetime.now().replace(hour=0, minute=0, second=0, microsecond=0)
# 相対月計算用
first_day_of_current_month = today.replace(day=1)
# 会計年度の計算のための基準
this_fy = today.year if today.month > 3 else today.year - 1
# 各種日付関連のカラムを追加
df = df.withColumn("year", year("Date"))\
.withColumn("month", month("Date"))\
.withColumn("day", dayofmonth("Date"))\
.withColumn("week", weekofyear("Date"))\
.withColumn("day_of_Week", dayofweek("Date"))\
.withColumn("name_of_day", get_day_of_week_udf("Date"))\
.withColumn("name_of_month", date_format("Date", 'MM月'))\
.withColumn("year_month", F.concat_ws("/", col("Year"), col("Month")))\
.withColumn("relative_date", datediff("Date", lit(today)))\
.withColumn("relative_month", floor(months_between("Date", lit(first_day_of_current_month))))\
.withColumn("relative_year", col("Year") - year(lit(today)))
# 会計年度と会計四半期の計算
if start_fiscal_month is not None:
fiscal_year_expr = F.when(month("Date") >= start_fiscal_month, year("Date")).otherwise(year("Date") - 1)
df = df.withColumn("fy", fiscal_year_expr)\
.withColumn("fiscal_quarter", expr(f"floor(((month(Date) - {start_fiscal_month} + 12) % 12) / 3) + 1"))\
.withColumn("fiscal_quarter_str", F.concat(col("fiscal_quarter"), lit("Q")))\
.withColumn("relative_fiscal_year", col("FY") - this_fy)
# 'AccountingPeriod' 列と 'RelativeAccountingPeriod' 列を追加
if first_fiscal_year is not None and start_fiscal_month is not None:
accounting_period_expr = F.when(month("Date") >= start_fiscal_month, year("Date") - first_fiscal_year).otherwise(year("Date") - first_fiscal_year - 1)
df = df.withColumn("accounting_period", accounting_period_expr)
current_accounting_period = today.year - first_fiscal_year if today.month >= start_fiscal_month else today.year - first_fiscal_year - 1
df = df.withColumn("relative_accounting_period", col("accounting_period") - current_accounting_period)
return df
4. 実行して確認してみる
df_calender = create_calendar_table_spark("2024-01-01", "2024-12-31", first_fiscal_year=1940, start_fiscal_month=6)
display(df_calender)
いい感じ

5. テーブルに出力
df_calender.write.mode("overwrite").format("delta").save("Tables/calender_2024")
テーブルが作成されてあることを確認

6. 毎月の目標数を入れるテーブルを作成
一旦は毎月40本が目標なので、for文でサクッと作成
data = [(i + 1, 40) for i in range(12)]
df = spark.createDataFrame(data, ["month", "target_number_of_posts"])
df.write.mode("overwrite").format("delta").save("Tables/target_post")
テーブルが作成されてあることを確認

実装:Zenn APIからデータ取得
1. Notebookの作成
ノートブックの作成

言語を「PySpark」、環境を先ほど作成した環境に設定

レイクハウスの紐づけをする(カレンダーテーブルを作成した時と同様の手順)
2. TablesにあるZennの全てのユーザーを取得
SharePointリストから取得してテーブルにアップしているので、そこのデータを読み込みます。
results = spark.sql("SELECT zenn_user_id FROM dataflow_zenn_all_user")
zenn_all_user_id = [row["zenn_user_id"] for row in results.collect()]
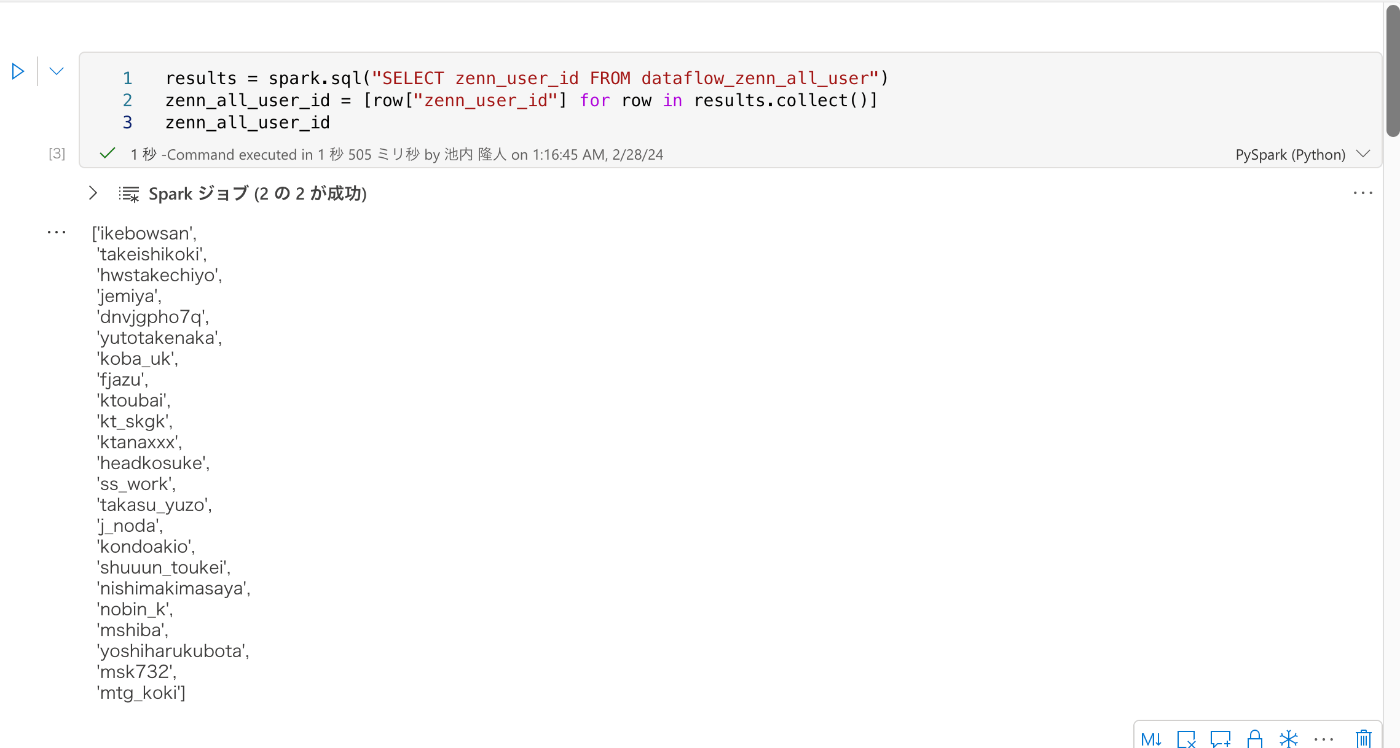
3. Zenn APIから取得したデータでDataFrameを作成
publication単位でも取得できますが、つい最近取得できることに気づいた事もあって、既にユーザー単位で叩くような実装にしてたため、今回はユーザー事にAPIを叩いています。
※今後publication単位の方法に変更する予定です。
ユーザーごとの投稿一覧取得APIは
https://zenn.dev/api/articles?username={ユーザー名}
です。
注意が必要で、usernameをタイポしてミスると全く関係ない投稿一覧が返ってくるのでタイポしないように...
各投稿の詳細取得APIは
https://zenn.dev/api/articles/{slug}
です。
slugは投稿一覧取得APIの各レスポンスに入っているので、そこを引数として活用してください。
最終的にテーブルとして、
・post_all...投稿一覧情報を格納
・post_detail_all...投稿の記事内容(HTML形式)を格納
・post_tags_all...各投稿に紐づくタグ一覧を格納
・user_all...Publicationの全ユーザーの中から1本でも投稿しているユーザーを格納
の4つを作成します。
以下ソースコードです。
カレンダーテーブルみたいにいきなりテーブルを作成した方が早いですが、今後csvファイルとして何か必要になるケースがあるかもなので、一旦csvファイルに落とすことにします。
あとは同じ処理とかは関数で切り分けたほうが絶対いいですが、今回はこのままにしています。
import requests
import pandas as pd
df_post_all = pd.DataFrame()
df_post_detail_all = pd.DataFrame()
df_post_tags_all = pd.DataFrame()
df_user_all = pd.DataFrame()
for i in zenn_all_user_id:
response_post = requests.get(f"https://zenn.dev/api/articles?username={i}")
post_data = response_post.json()
articles = post_data["articles"]
next_page = post_data["next_page"]
if len(articles) != 0 and articles[0]["publication"] != None:
df_post = pd.DataFrame(articles)
df_post["user_id"] = df_post["user"].apply(lambda x: x["id"])
df_post = df_post[["id", "title", "slug", "emoji", "comments_count", "liked_count", "body_letters_count", "published_at", "body_updated_at", "user_id"]]
df_post_all = pd.concat([df_post_all, df_post], ignore_index=True, axis=0)
for j in articles:
slug = j["slug"]
response_detail = requests.get(f"https://zenn.dev/api/articles/{slug}")
post_detail_data = response_detail.json()
articles_detail = [post_detail_data["article"]]
df_post_detail = pd.DataFrame(articles_detail)
tags = post_detail_data["article"]["topics"]
df_post_detail = df_post_detail[["id", "body_html"]]
df_post_detail_all = pd.concat(
[df_post_detail_all, df_post_detail], ignore_index=True, axis=0
)
df_post_tags = pd.DataFrame(tags)
df_post_tags["post_id"] = articles_detail[0]["id"]
df_post_tags = df_post_tags[["id", "name", "display_name", "image_url", "taggings_count", "post_id"]]
df_post_tags_all = pd.concat(
[df_post_tags_all, df_post_tags], ignore_index=True, axis=0
)
user_data = articles[0]["user"]
df_user = pd.DataFrame(user_data, index=[0])
df_user_all = pd.concat([df_user_all, df_user], ignore_index=True, axis=0)
while next_page:
response_post = requests.get(f"https://zenn.dev/api/articles?username={i}&page={next_page}")
post_data = response_post.json()
articles = post_data["articles"]
next_page = post_data["next_page"]
if len(articles) != 0 and articles[0]["publication"] != None:
df_post = pd.DataFrame(articles)
df_post["user_id"] = df_post["user"].apply(lambda x: x["id"])
df_post = df_post[["id", "title", "slug", "emoji", "comments_count", "liked_count", "body_letters_count", "published_at", "body_updated_at", "user_id"]]
df_post_all = pd.concat([df_post_all, df_post], ignore_index=True, axis=0)
for j in articles:
slug = j["slug"]
response_detail = requests.get(f"https://zenn.dev/api/articles/{slug}")
post_detail_data = response_detail.json()
articles_detail = [post_detail_data["article"]]
df_post_detail = pd.DataFrame(articles_detail)
tags = post_detail_data["article"]["topics"]
df_post_detail = df_post_detail[["id", "body_html"]]
df_post_detail_all = pd.concat(
[df_post_detail_all, df_post_detail], ignore_index=True, axis=0
)
df_post_tags = pd.DataFrame(tags)
df_post_tags["post_id"] = articles_detail[0]["id"]
df_post_tags = df_post_tags[["id", "name", "display_name", "image_url", "taggings_count", "post_id"]]
df_post_tags_all = pd.concat(
[df_post_tags_all, df_post_tags], ignore_index=True, axis=0
)
if next_page is None:
break
df_post_all.to_csv("<path>/Files/post_all.csv", index=False)
df_post_detail_all.to_csv("<path>/Files/post_detail_all.csv", index=False)
df_post_tags_all.to_csv("<path>/Files/post_tag_all.csv", index=False)
df_user_all.to_csv("<path>/Files/post_user_all.csv", index=False)
4. 作成されたcsvからテーブルを作成
先ほど作成した4つのcsvファイルをそれぞれテーブルに変えていきます。
post_all
from pyspark.sql.types import StructType, StructField, IntegerType, StringType, TimestampType, DateType
table_name = "post_all"
file_name = f"Files/{table_name}.csv"
schema = StructType([
StructField("id", IntegerType(), True),
StructField("title", StringType(), True),
StructField("slug", StringType(), True),
StructField("emoji", StringType(), True),
StructField("comments_count", IntegerType(), True),
StructField("liked_count", IntegerType(), True),
StructField("body_letters_count", IntegerType(), True),
StructField("published_at", DateType(), True),
StructField("body_updated_at", DateType(), True),
StructField("user_id", IntegerType(), True),
])
df = spark.read.format("csv").option("header","true").schema(schema).load(file_name)
df.write.mode("overwrite").format("delta").save("Tables/"+table_name)
post_detail_all
table_name = "post_detail_all"
file_name = f"Files/{table_name}.csv"
schema = StructType([
StructField("id", IntegerType(), True),
StructField("body_html", StringType(), True)
])
df = spark.read.format("csv").option("header","true").schema(schema).load(file_name)
df.write.mode("overwrite").format("delta").save("Tables/"+table_name)
post_tag_all
table_name = "post_tag_all"
file_name = f"Files/{table_name}.csv"
schema = StructType([
StructField("id", IntegerType(), True),
StructField("name", StringType(), True),
StructField("display_name", StringType(), True),
StructField("image_url", StringType(), True),
StructField("taggings_count", IntegerType(), True),
StructField("post_id", IntegerType(), True),
])
df = spark.read.format("csv").option("header","true").schema(schema).load(file_name)
df.write.mode("overwrite").format("delta").save("Tables/"+table_name)
post_user_all
table_name = "post_user_all"
file_name = f"Files/{table_name}.csv"
schema = StructType([
StructField("id", IntegerType(), True),
StructField("username", StringType(), True),
StructField("name", StringType(), True),
StructField("avatar_small_url", StringType(), True),
])
df = spark.read.format("csv").option("header","true").schema(schema).load(file_name)
df.write.mode("overwrite").format("delta").save("Tables/"+table_name)
全て実行して、Tablesに4つのテーブルが作成されていることを確認
実装:データモデルの作成
1. セマンティックモデルの作成
ワークスペースに作成してあるレイクハウスをクリック

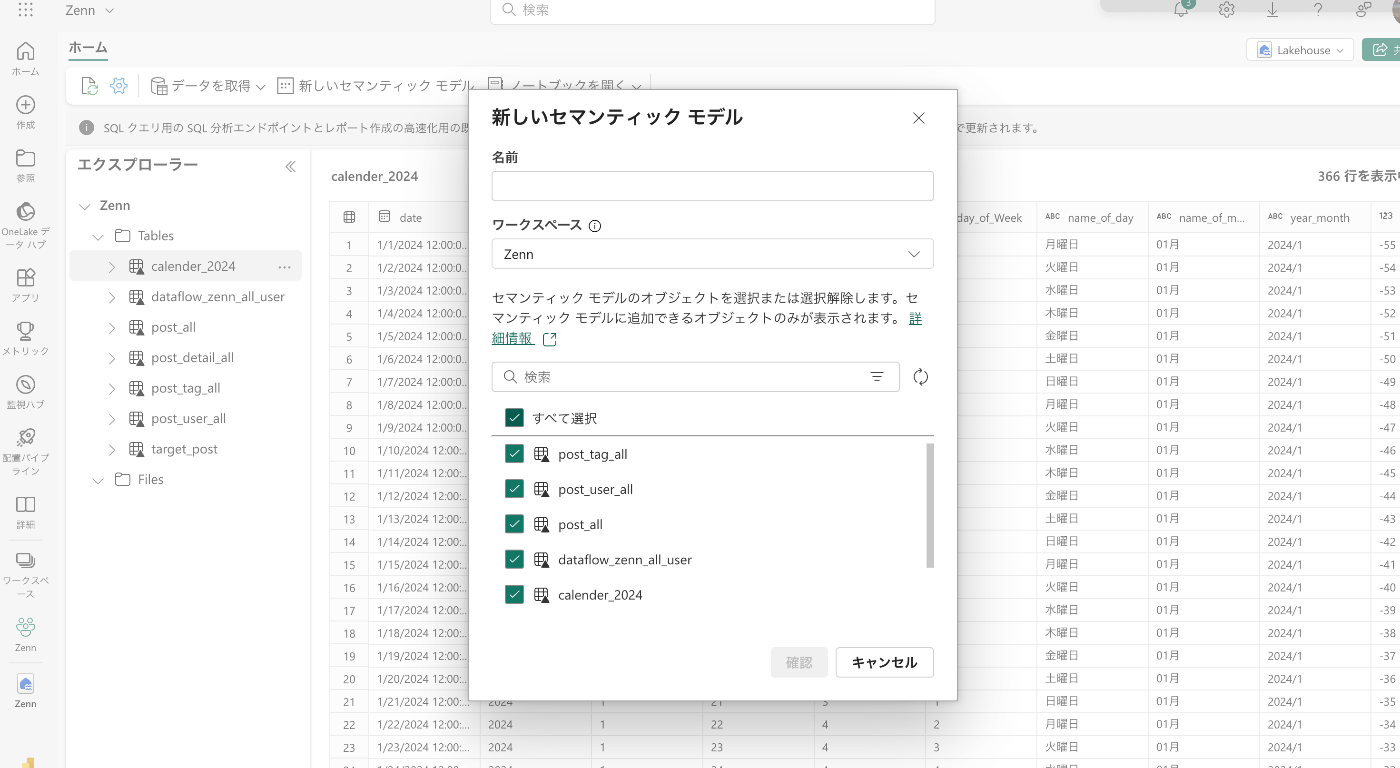
「新しいセマンティックモデル」を選択

名前はなんでもいいです。
今回は全てのテーブルを使用するので、「すべて選択」をクリック
2. リレーションシップの定義
新しいセマンティックモデルを作成すると以下の画面に飛びますので、ここでリレーションシップを作成していきます。
Power BI Desktopでいうモデルビューと同じことをここでします。

リレーションは今回以下のようにしています。
パフォーマンスを考えると双方向リレーションは本来好ましくないですが、データ数も多くないのでこれでいきます。
あとは、1対1のリレーションの箇所があって普通に冗長になってますが、今後やりたいことがあるのでpost_allとpost_detail_allで切り分けています。
本来は一緒のテーブルにまとめた方がベストです。

リレーションが出来たらいよいよレポートを作成します。
「新しいレポート」を選択

実装:BIの作成
BIレポートはPower BI Service(Web)でもPower BI Desktopでもどちらでも作成できます。
今回は既にPower BI Desktopの方で作っていたレポートがあり、そこにデータを当てこんでいくので、Desktopの方を使用しています。
本来はBI Serviceがいいかなと思います。Macでも作成ができるので。
Power BI Serviceでレポートを作成する場合
セマンティックモデルの「新しいレポート」をクリックすると、レポート作成画面に遷移します。
ここでビジュアルを使って、データの可視化を行なっていきます。
Power BI Desktopでレポートを作成する場合
「Power BIセマンティックモデル」を選択
先ほど作成したセマンティックモデルを選択。
Direct Queryモードでの取り込みなので、BI Desktop上ではデータの整形とかリレーションの変更などはできないので注意。

取り込んだデータを割り当てたら、無事表示ができました。
レポートは以下のようにしてみました。
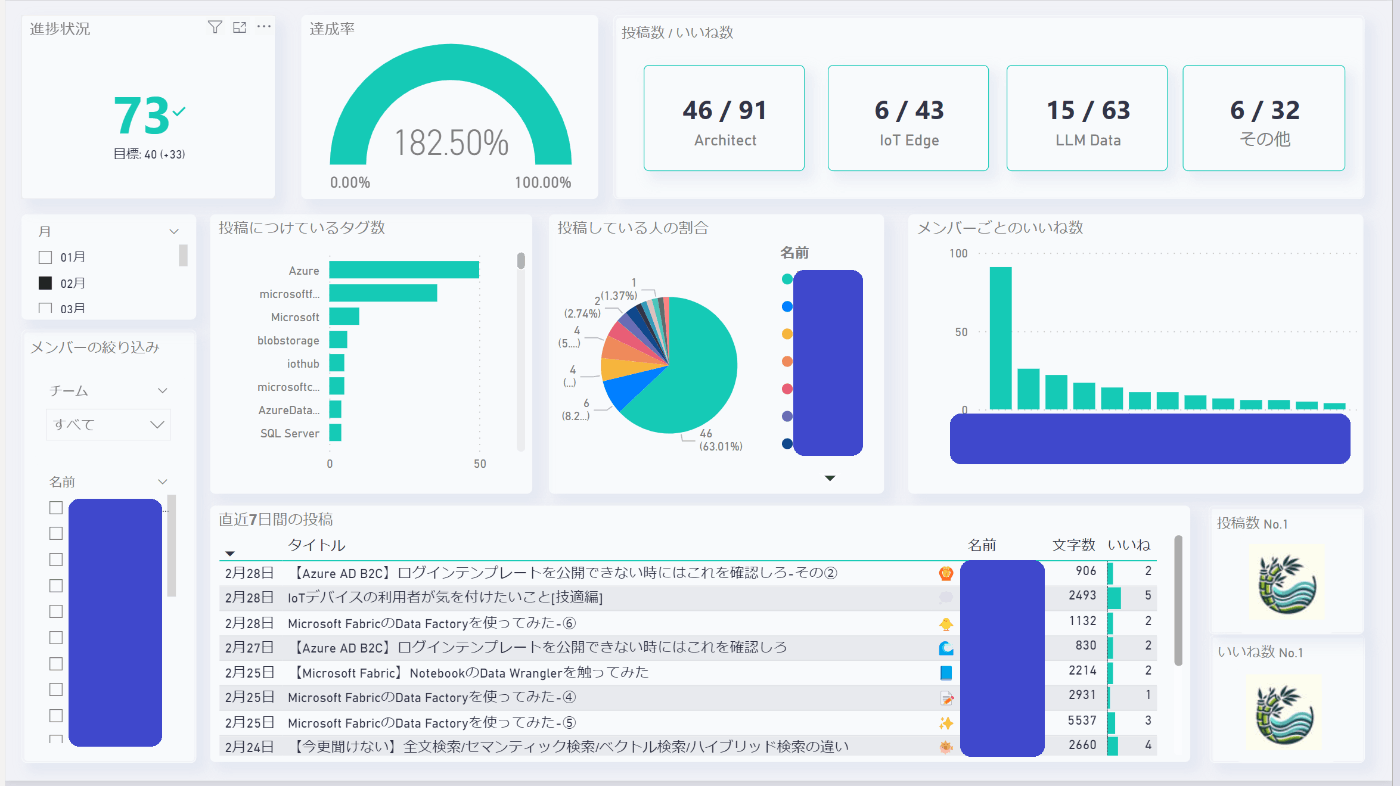
今後アップデートを加えていく予定です。
最後に
今後はZenn APIから取得したデータを使った分析(いいねが多い記事と少ない記事の違いなど)や、
会社としてもっと投稿して欲しいけど投稿数が少ない分野を出したり、いいね数が一定以上を上回ったらTeamsに通知するなど、機能を拡張していく予定です。

Discussion
さすがです!
fabric の使い方も分かりやすく理解出来た!