


やりたいこと
社内でZennの運営をしています。
メンバーが投稿した記事がトレンドに上がったらTeamsに通知が飛ぶようにしたいと思います。
Zennのトレンド一覧を取得
非公式ですが、TechとIdeaそれぞれのトレンド記事を取得できるAPIがありました。
こちらのAPI(非公式)の上から20個のデータもトレンドと一緒なのでした。
ただ毎回上から20個がトレンドという確証がないので、今回は前者のAPIを使用します。
Data Activatorとは
Microsoft Fabric内にある機能で、設定したデータのパターン・条件が検出された時に自動でアクションを実行します。
検出した後はメール・Teamsにメッセージを飛ばしたり、Power Automateのフローを実行できたりします。
現状はデータの監視先として設定できるのはBIレポートのビジュアルのみです。
まだパブリックプレビュー版なので使える機能は限られてますが、今後の機能追加に期待大です。
実装
前提
こちらで既にFabricの環境を作っているので、これをベースに進めていきます。
1. Notebook上でデータを取得
- 既存CSVファイルを読み込み
- APIを叩いて、既存データ内に同じslugがあったらlast_trend_in_datetimeを更新する
- 新規のデータと既存データを組み合わせてCSVに出力
- CSVファイルからTableを作成
実行は3時間ごとにスケジューリングします。
import requests
import pandas as pd
import datetime
exist_trend_post_all = pd.read_csv("/lakehouse/default/" + "Files/trend_post_all.csv")
df_trend_post_all = pd.DataFrame()
categories = [
{"name": "tech", "url": "https://zenn-api.vercel.app/api/trendTech"},
{"name": "idea", "url": "https://zenn-api.vercel.app/api/trendIdea"},
]
for i in categories:
dt_now = datetime.datetime.now()
response_post = requests.get(i["url"])
articles = response_post.json()
df_post = pd.DataFrame(articles)
for d in articles:
current_slug_row = exist_trend_post_all[exist_trend_post_all['slug'].isin([d["slug"]])]
if len(current_slug_row) != 0:
df_post = df_post[df_post['slug'] != d["slug"]]
exist_trend_post_all.loc[exist_trend_post_all['slug'] == d["slug"],'last_trend_in_datetime'] = dt_now
df_post["user_id"] = df_post["user"].apply(lambda x: x["id"])
df_post["trend_in_datetime"] = dt_now
df_post = df_post[["id", "title", "slug", "emoji", "commentsCount", "likedCount", "bodyLettersCount", "publishedAt", "bodyUpdatedAt", "trend_in_datetime", "user_id", "articleType"]]
df_post = df_post.rename(columns = {'commentsCount':'comments_count','likedCount': 'liked_count','bodyLettersCount':'body_letters_count','publishedAt':'published_at', 'bodyUpdatedAt':'body_updated_at', 'articleType':'article_type'})
df_trend_post_all = pd.concat([exist_trend_post_all, df_post], ignore_index=True, axis=0)
exist_trend_post_all = df_trend_post_all
df_trend_post_all.to_csv("/lakehouse/default/Files/trend_post_all.csv", index=False)
from pyspark.sql.types import StructType, StructField, IntegerType, StringType, TimestampType, DateType
table_name = "trend_post_all"
file_name = f"Files/{table_name}.csv"
schema = StructType([
StructField("id", IntegerType(), True),
StructField("title", StringType(), True),
StructField("slug", StringType(), True),
StructField("emoji", StringType(), True),
StructField("comments_count", IntegerType(), True),
StructField("liked_count", IntegerType(), True),
StructField("body_letters_count", IntegerType(), True),
StructField("published_at", DateType(), True),
StructField("body_updated_at", DateType(), True),
StructField("user_id", IntegerType(), True),
])
df = spark.read.format("csv").option("header","true").schema(schema).load(file_name)
df.write.mode("overwrite").format("delta").save("Tables/"+table_name)
2. セマンティックモデルの設定
レイクハウス内の「SQL分析エンドポイント」を開く。

「報告」タブ内の「既定のセマンティックモデルの管理」を選択
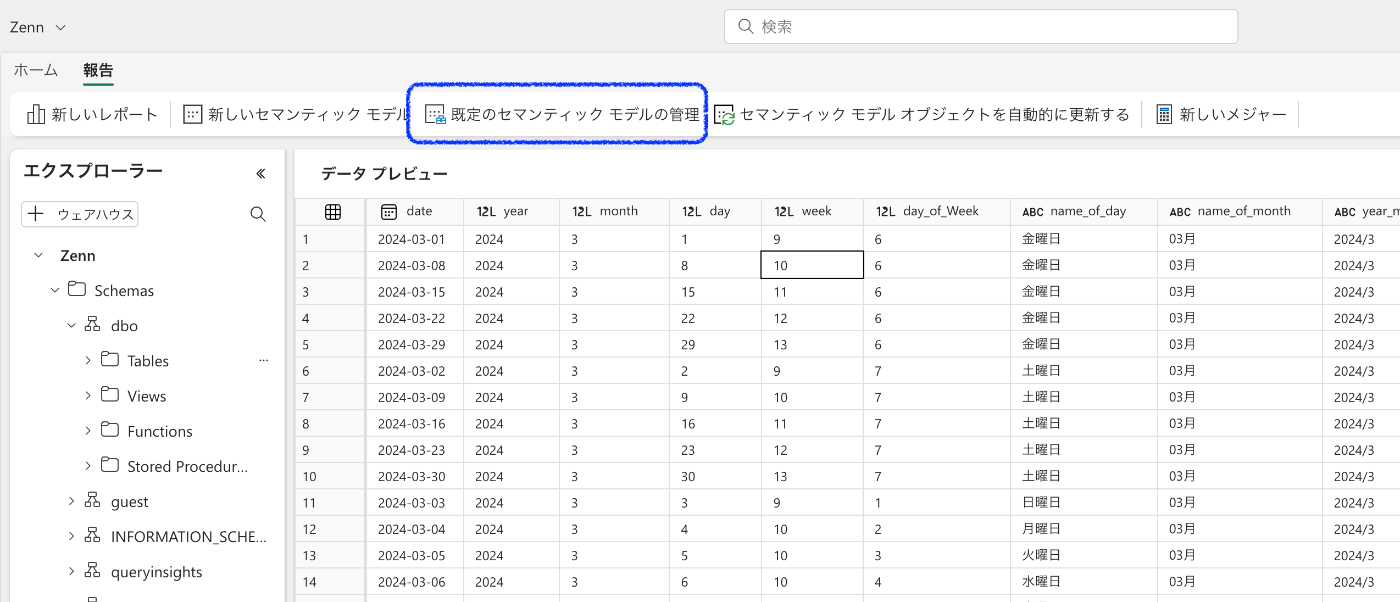
先ほど作成したTableのチェックをつけて、セマンティックモデルに追加
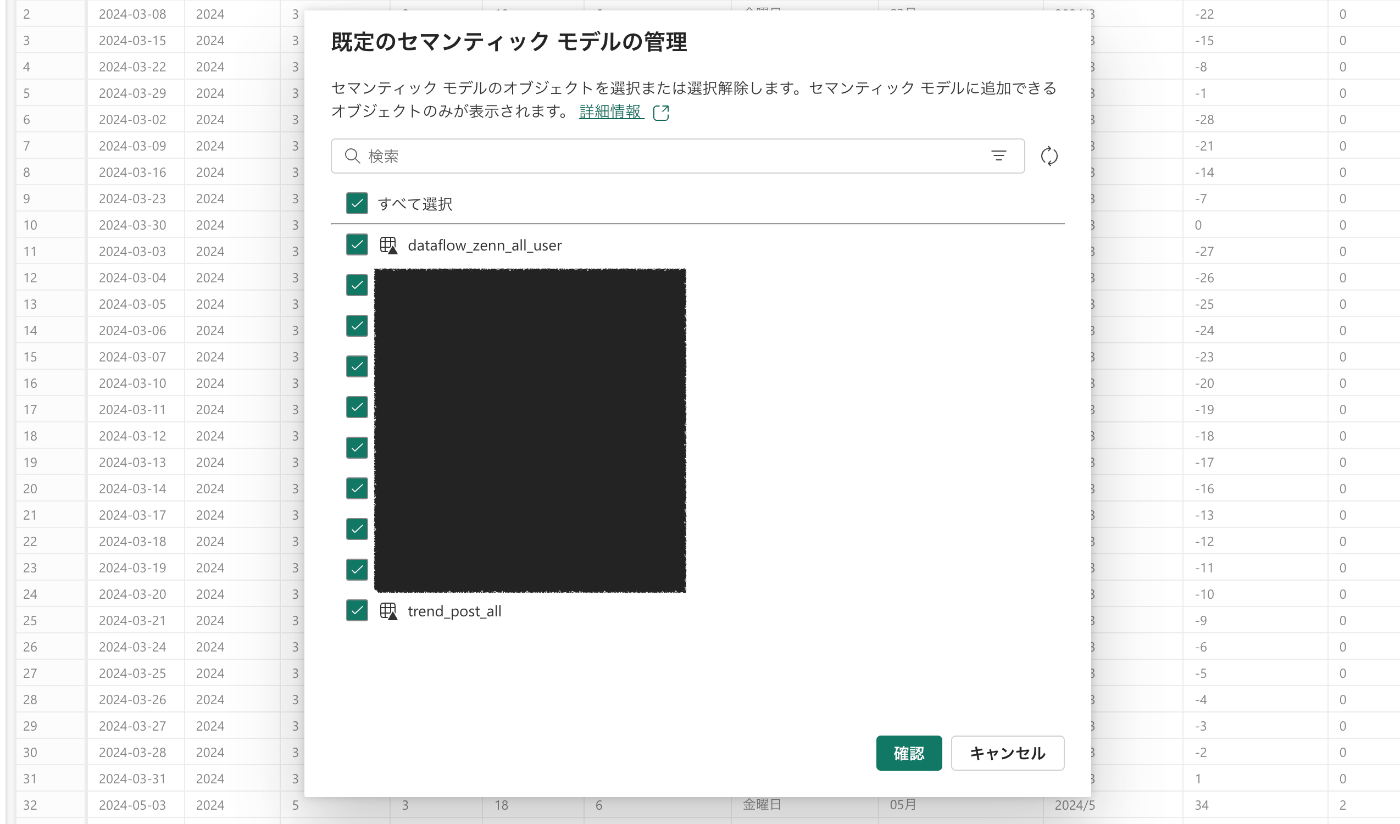
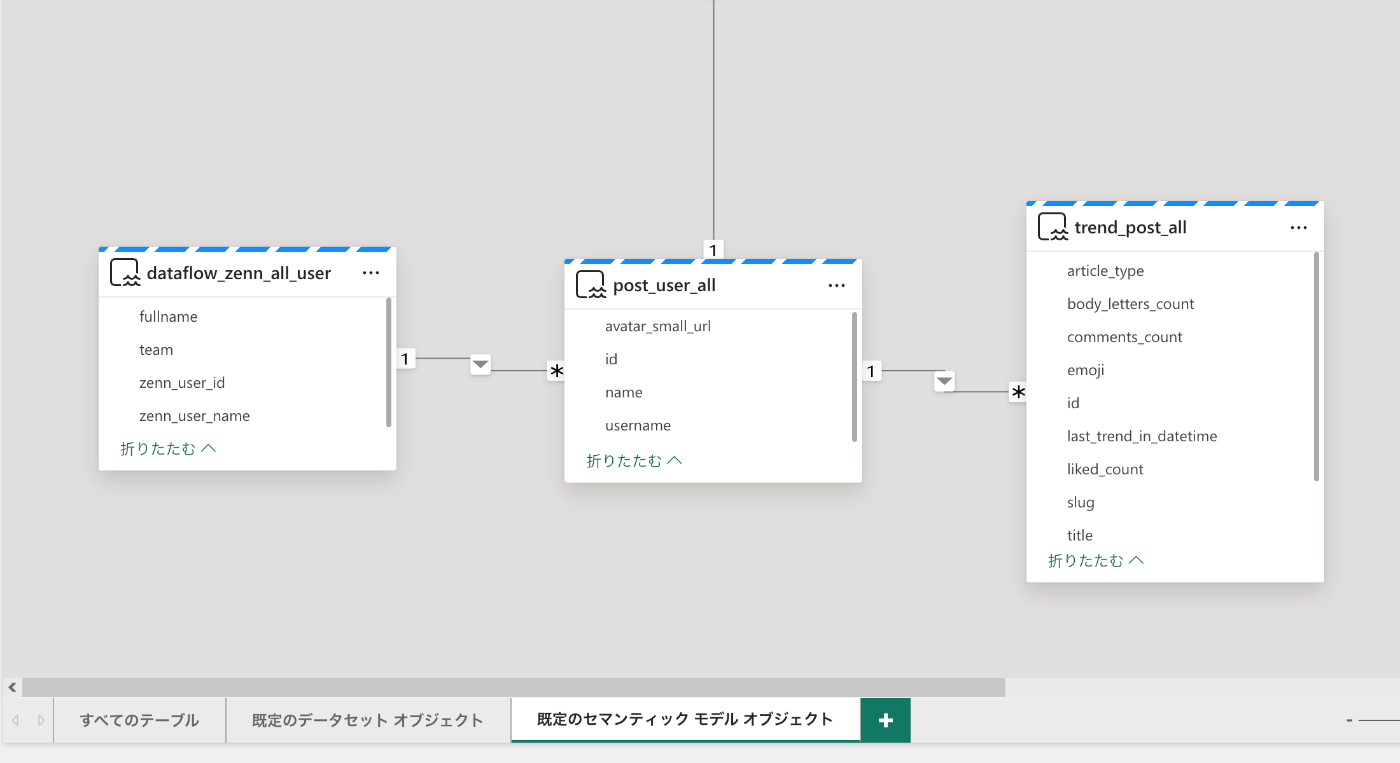
「既定のセマンティックモデルオブジェクト」に移動して、リレーションを設定。
「dataflow_zenn_all_user」と「post_user_all」の二つのテーブルは前の記事で作成しています。
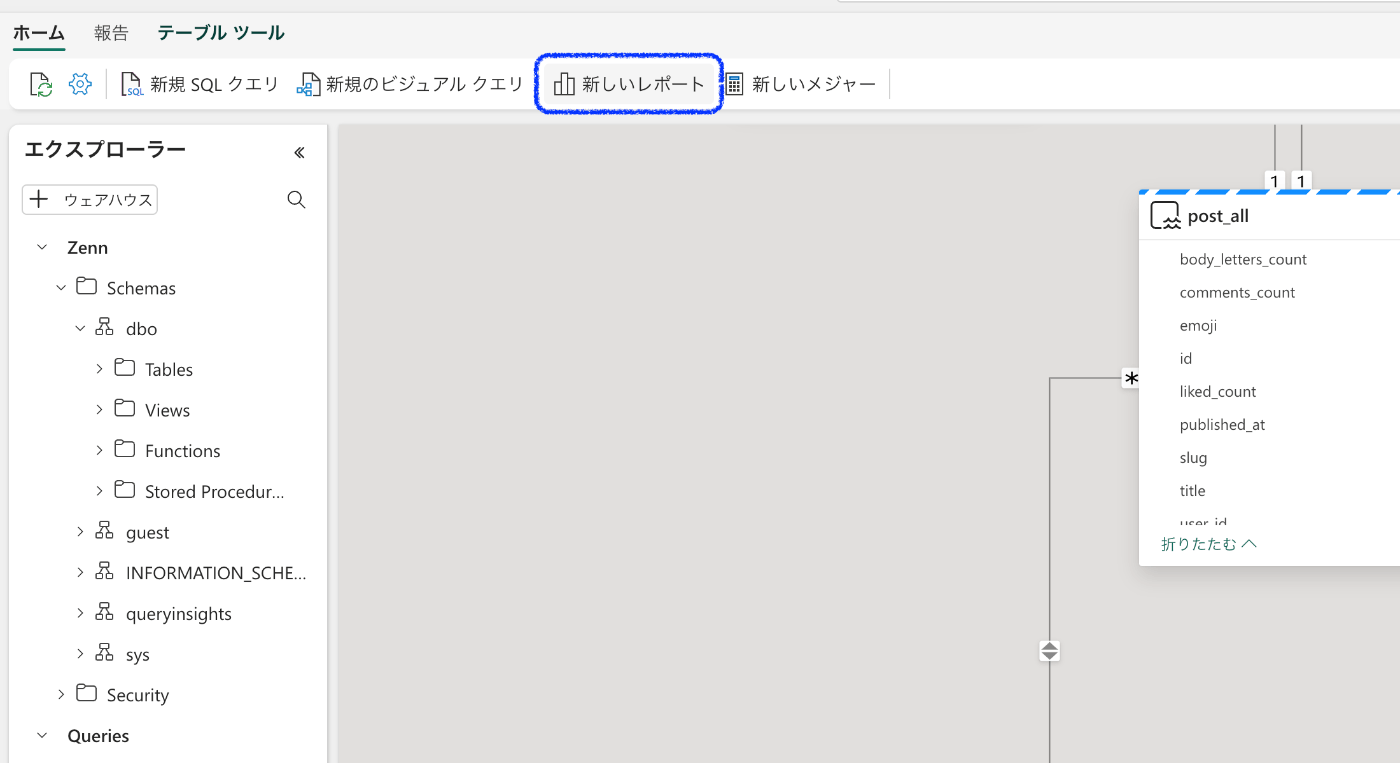
3. BIレポートを作成
ホームタブに移動して、「新しいレポート」を選択
カードビジュアルに、trend_post_allテーブル内のid列の「一意なカウント」を選択

社内のメンバーの記事のみにしたいので、post_user_allテーブル内のid列をビジュアルフィルターに割り当てる。
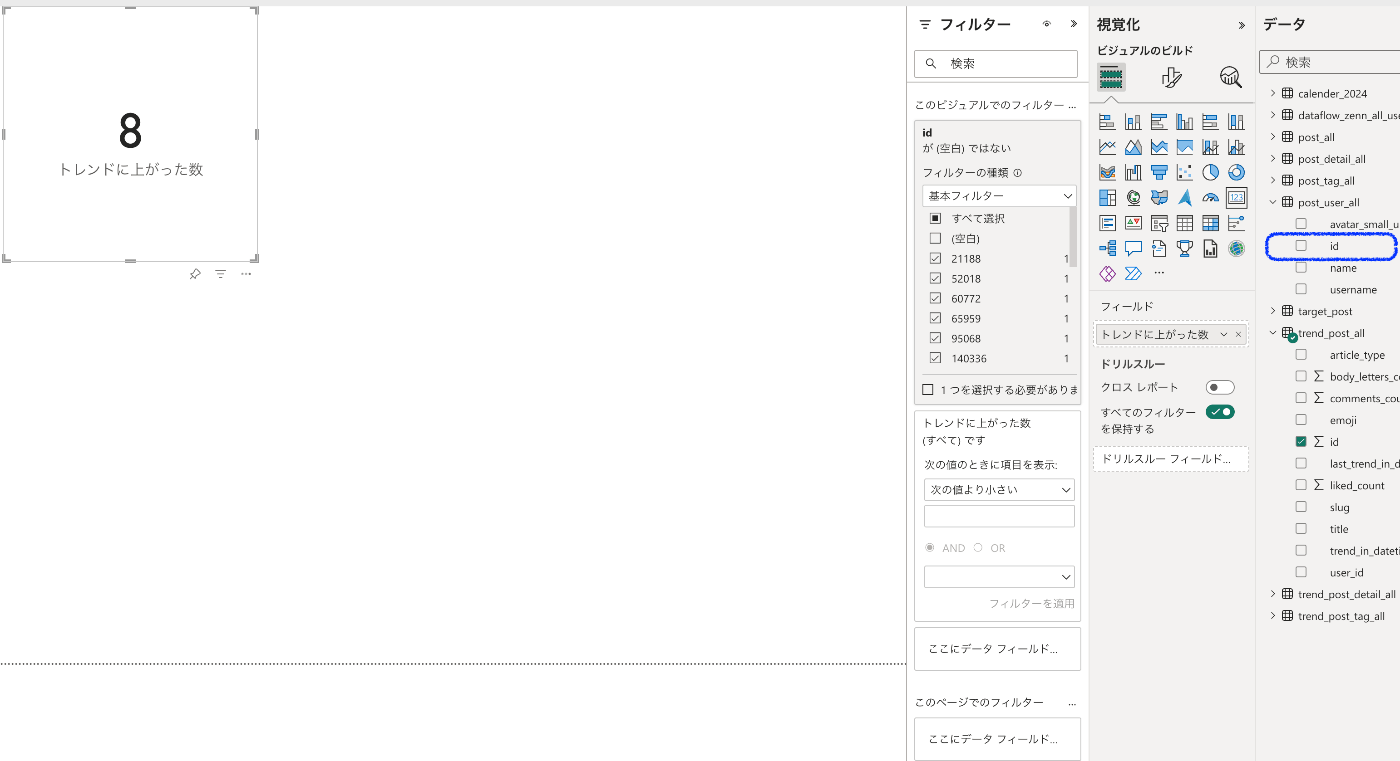
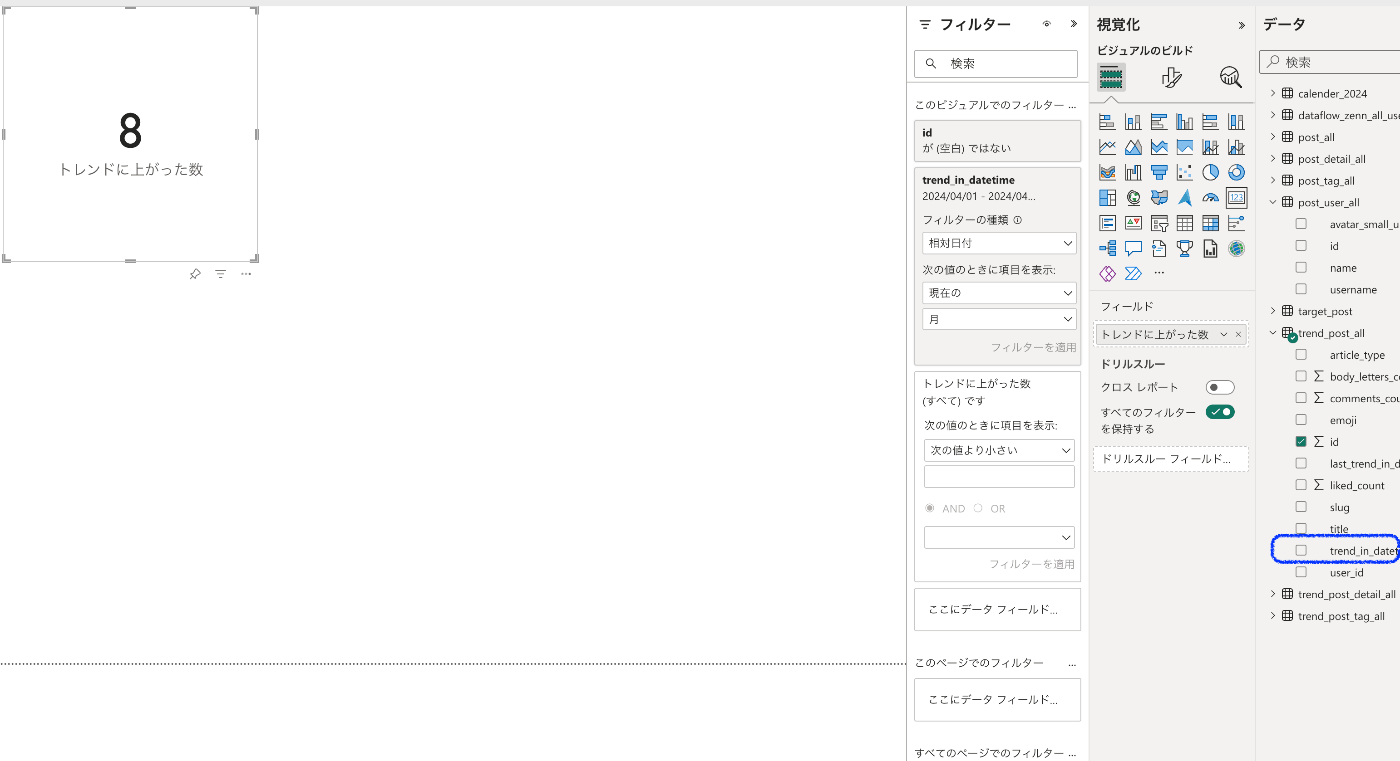
最後に今月の記事の数だけにしたいので、trend_post_allテーブル内のtrend_in_datetime列をビジュアルフィルターに割り当てる。
条件は「相対日付」で「現在」の「月」に設定
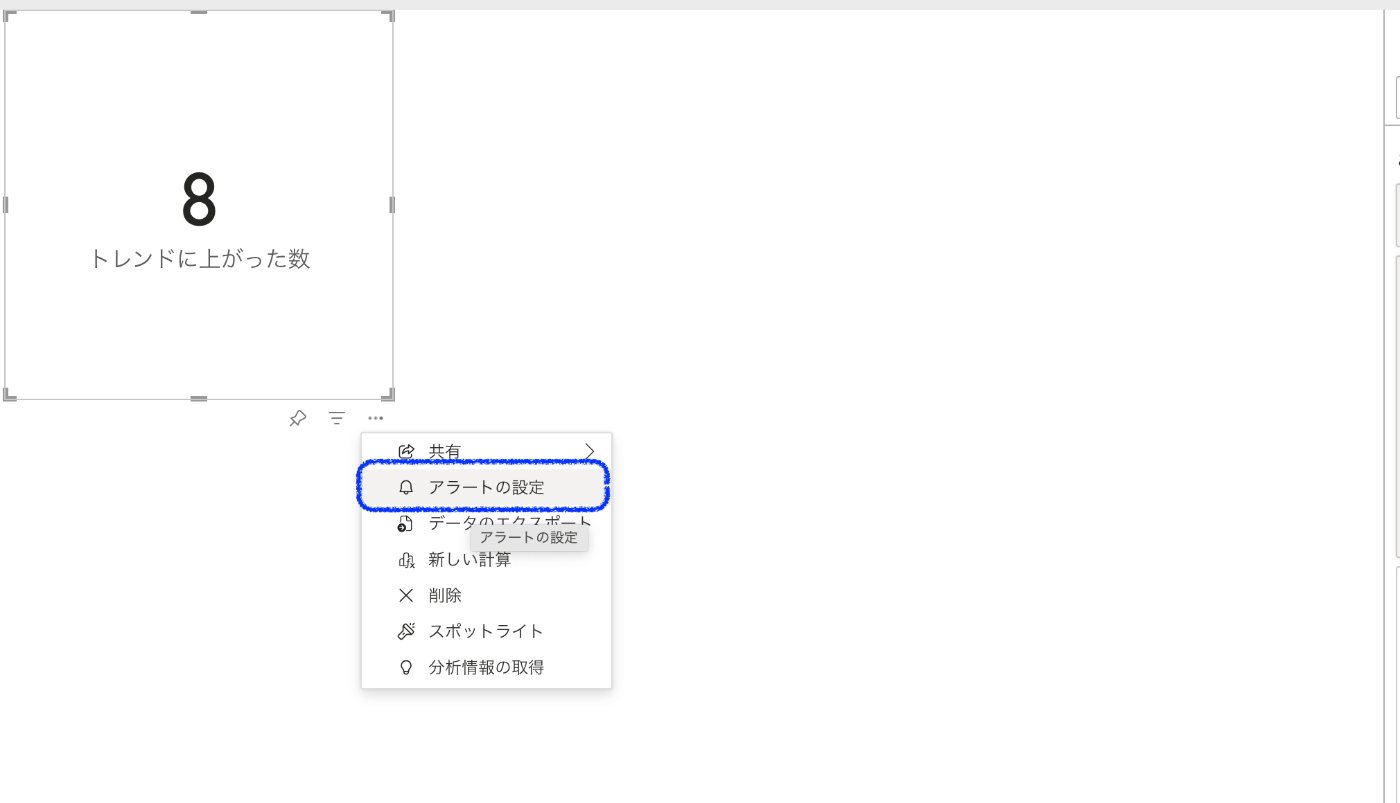
3. アラートの設定
ビジュアルの「...」をクリックして、「アラートの設定」を選択
条件はあとで変更できるので適当に設定します。
DataActivatorは既に作ってるので、作成済みのものを設定。
「アラートの作成」を選択

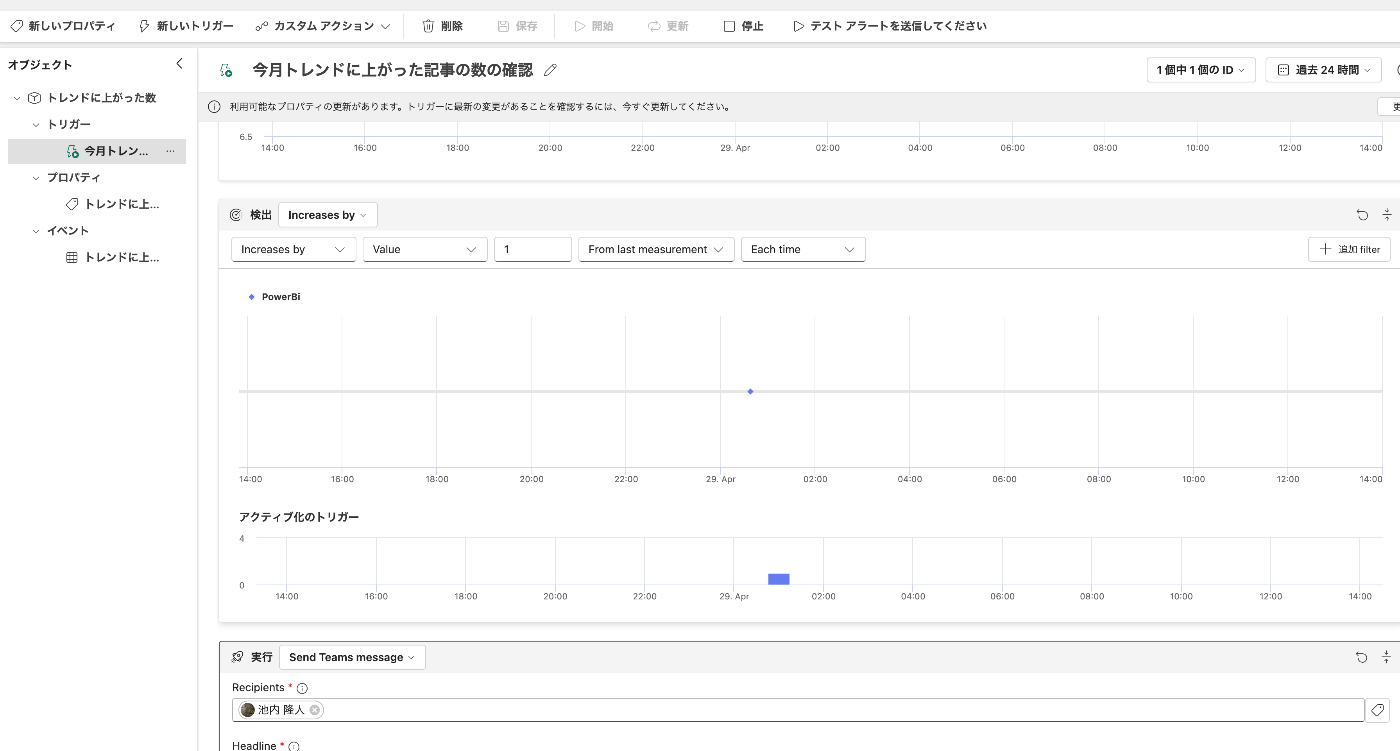
DataActivatorに移動して、トリガーの検出条件を変更します。
条件を「increases by」にして、「Value」を「1」、「From last measurement」にして「Each time」に設定します。
こうすることで、前回検出時から値が増えたらトリガーを実行されるようになります。
トレンドの情報は3時間に1回取得するので、トリガーの検出も3時間に1回のペースで行われます。
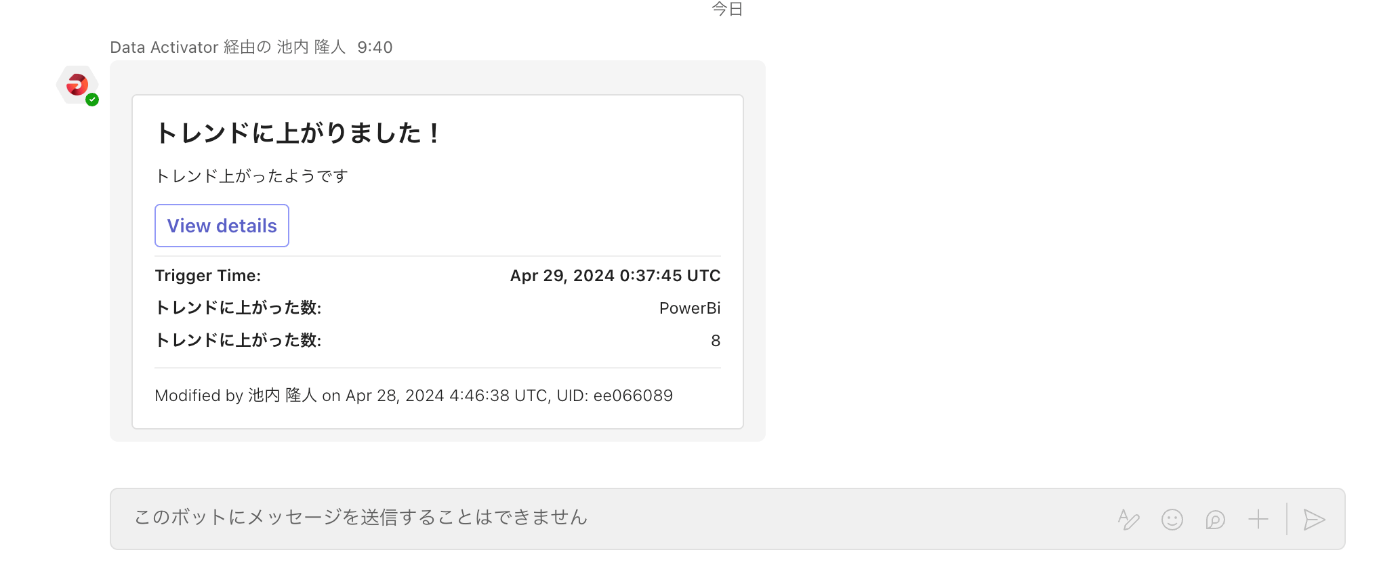
検証
今日の朝、新しく記事がトレンドに上がったようでTeamsに通知が飛んできました。

Discussion