LangGraph : LangMemによる記憶管理の基本
LangMemとは
LangMem は、2025年2月に発表された LangGraph ツールチェーン SDK に含まれるライブラリで、主に LLM エージェントの「長期記憶」を管理するための専用 API を提供します。
LangMem はデータの永続化機能と連携するものの、「永続化するデータ(記憶)の管理(追加・更新・削除)」が目的であり、永続化そのものが主目的ではありません。
LangGraph には、すでに「Checkpointer」と「Store」という永続化の仕組みが存在します。LangMem は、この「Store」と連携することで、エージェントが扱う記憶をより適切に管理できるようになっています。
CheckpointとStoreについては、過去記事にしていますので、こちらもよろしければご参照ください。
環境
この記事を書いた時点では以下のバージョンで確認しています。
出たばかりの機能になるため、動作確認時はバージョン情報を改めて確認ください。
- langmem==0.0.11
- langgraph==0.2.74
- langchain==0.3.19
- langchain-core==0.3.37
LangMemにおける記憶の概要
LangMemが記憶をどのように扱うのかを簡単に説明します。
記憶の保存形式: collectionとprofile
LangMemでは、記憶の保存形式としてcollectionとprofileの2種類を想定しています。
| 保存形式 | 説明 |
|---|---|
| collection | 実際の会話履歴など、個別の記憶内容をドキュメントとして保存し、実行時に検索される。 |
| profile | スキーマに従い、固有の情報として記録される。ユーザーのプロフィールなど常に最新の情報を参照し、既存ドキュメントを更新する形式のデータ。 |
LangMemにおける記憶の種類
LangMemを通じて管理できる記憶は以下のように整理されています。
| メモリタイプ | 目的 | 説明 | 一般的な保存形式 |
|---|---|---|---|
| セマンティック (Semantic) | 事実と知識 | 知識や事実に関する情報を保存し、長期的に保持する。 | Profile または Collection |
| エピソード (Episode) | 過去の経験 | 過去の出来事や対話の要約を記憶し、文脈に基づいた応答を可能にする。 | Collection |
| 手続き的 (Procedural) | システムの動作 | システムの振る舞いや応答パターンを学習し、適切なアクションを実行できるようにする。 | プロンプトルール または Collection |
Semantic memory: 事実と知識

Semantic memoryは、エージェントの応答に使用される。事実や知識を指します。
これには、前述のcollection(チャット履歴など)やprofile(ユーザープロフィール)が該当します。
Episodic memory: 過去の経験
エピソード記憶は、成功した経験を将来の実行の学習例として保存します。Semantic memoryとは異なり、過去の実行(経験)のコンテキスト(どのような思考でどうアクションし、どのような結果を得たか)も一緒に保存されます。
データ保存の形式としては collectionでこれを表現します。
Procedural memory: システム命令
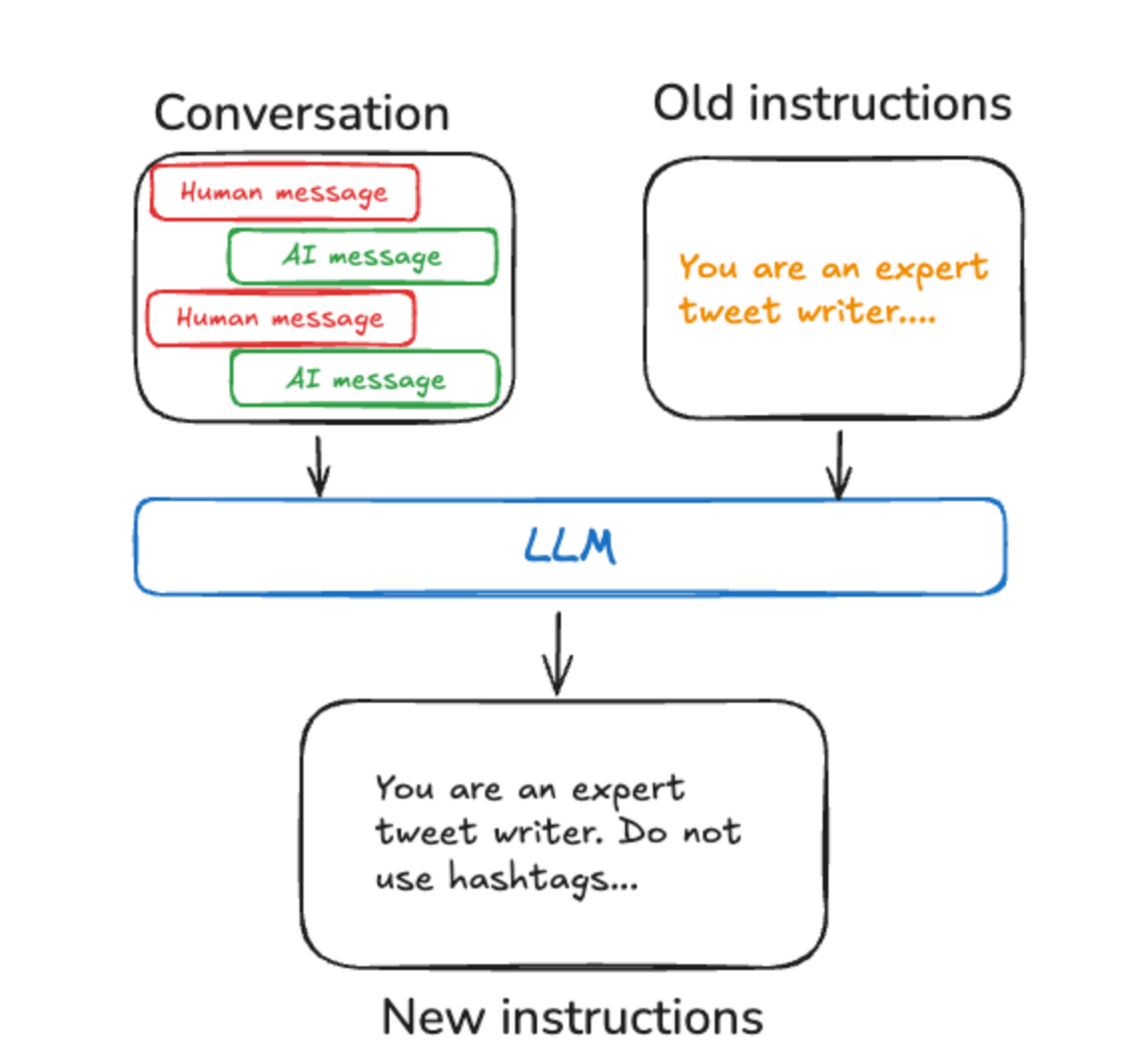
Procedural memory(手続き記憶)は、エージェントがどのように動作し、応答すべきかをコード化する仕組みです。
LangMemでは、「Prompt Optimization」と呼ばれるプロンプトを最適化する機能でこれを表現しています。
LangMemにおける記憶の保存方法
LangMemにおいては、基本の保存方法には以下2つの方法があります。
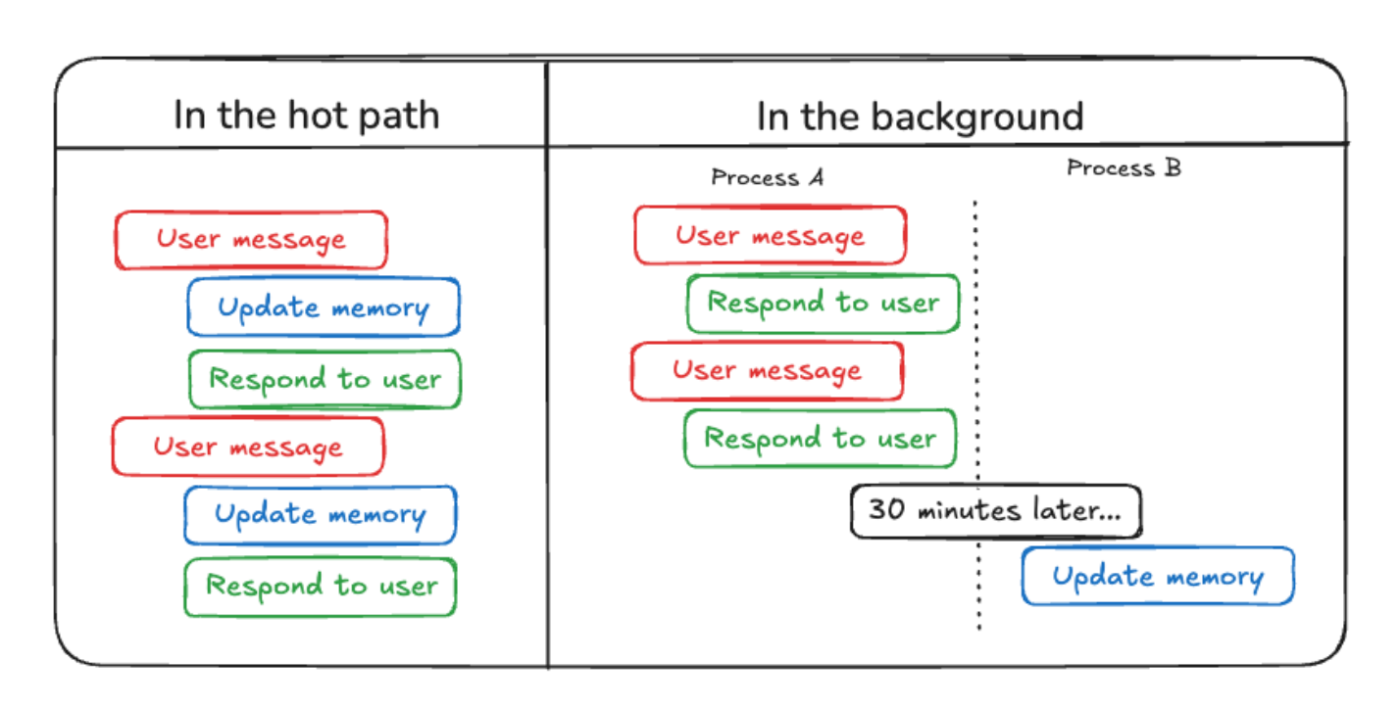
| タイプ | 説明 |
|---|---|
| アクティブ(Hot Path) | 会話の途中やユースケースの途中で即時更新する。データ種別によっては実行パフォーマンスに影響がでる。 |
| バックグラウンド | インタラクションの合間に更新され、パターン分析や要約を行う。 |
LangMemにおける記憶の操作
ここでは、LangMemのAPIを使って実際に記憶の追加、更新、削除を管理する方法を紹介します。
LangMemでは、記憶を操作するために主に「create_memory_manager」と「create_memory_store_manager」の2つのAPIが用意されています。
この2つの大きな違いは、「store機能と自動で連携するかどうか」です。
-
create_memory_managerは、store機能とは独立してメモリを管理します。 -
create_memory_store_managerを使用すると、storeに定義されたnamespaceを指定することで、自動的にstoreと連携し、永続化を行うことが可能です。
create_memory_managerを使って、記憶の管理を行う
まずは、create_memory_managerのAPIを使用して、LangMemがどのように記憶の更新を行うのかを見ていきます。
コード例
from langmem import create_memory_manager
from pydantic import BaseModel, Field
# 記憶のスキーマ構造をクラス定義
class UserProfile(BaseModel):
name: str | None = Field(default=None, description='ユーザーの名前')
language: str | None = Field(default=None, description='ユーザーの言語')
hobby: str | None = Field(default=None, description='ユーザーの趣味')
def main():
# マネージャーの生成
manager = create_memory_manager(
'openai:gpt-4o-mini',
schemas=[UserProfile],
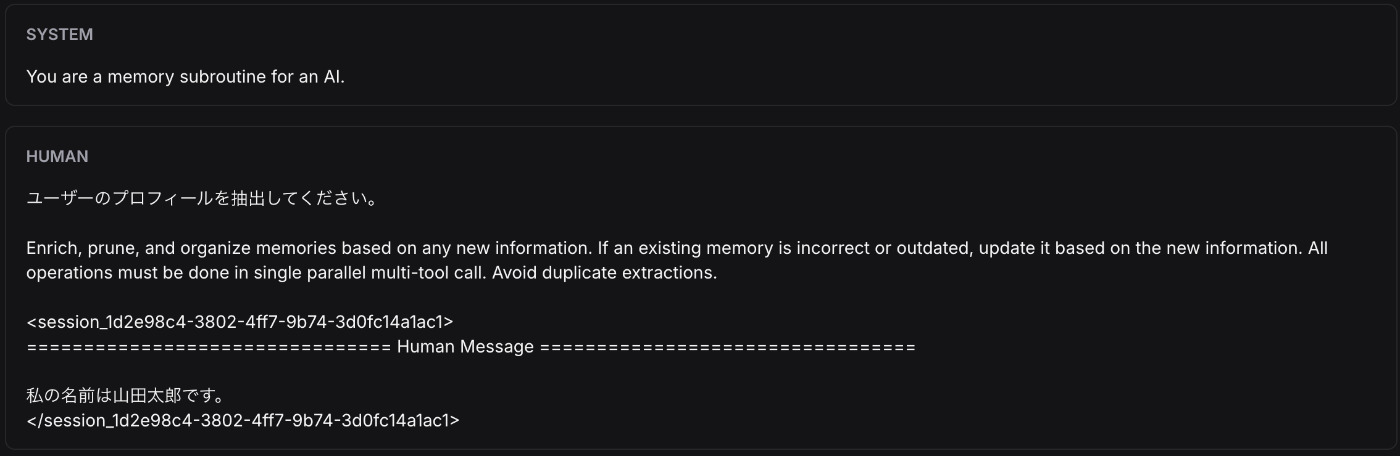
instructions='ユーザーのプロフィールを抽出してください。',
enable_inserts=False,
)
# 最初の会話(名前情報を更新)
conversation1 = [{'role': 'user', 'content': '私の名前は山田太郎です。'}]
# memory_manager.invokeの実行により、メモリの内容を更新する
memories = manager.invoke({'messages': conversation1})
print(memories[0])
# 2回目の会話(趣味情報を更新)
conversation2 = [{'role': 'user', 'content': '私の趣味はサッカーです'}]
update = manager.invoke({'messages': conversation2, 'existing': memories})
print(update[0])
if __name__ == '__main__':
main()
実行結果
ExtractedMemory(id='d5511762-a5e1-4ed3-9f58-aea58e3c118c', content=UserProfile(name='山田太郎', language=None, hobby=None))
ExtractedMemory(id='d5511762-a5e1-4ed3-9f58-aea58e3c118c', content=UserProfile(name='山田太郎', language=None, hobby='サッカー'))
1回目の会話で name が、2回目の会話で hobby が更新されていることがわかります。
このように、memory_manager を使うと、特定の情報から記憶に紐づく内容だけを抽出し、更新することができます。
MemoryManagerの内部では記憶を整理するためのLLMが実行される
memory_managerの invokeを実行すると内部では、メモリ抽出の為のLLMが実行されます。
■ 1回目のLLM
■ 2回目のLLM

LangMemのメモリ管理APIを使うとこのように、LLMが適切な形で記憶情報を更新してくれます。
create_memory_store_manager を使って store と連携する
create_memory_store_manager を使用すると、LangGraph で用意されている永続化機構 store と自動的に連携できるようになります。
ここでは、開発用のストア機構である InMemoryStore を使って、会話の中の記憶を操作する処理を見ていきます。
実際のコードは以下のとおりです。
import dotenv
from langchain.chat_models import init_chat_model
from langgraph.func import entrypoint
from langgraph.store.memory import InMemoryStore
from langmem import create_memory_store_manager
# 開発用のInMemoryのStoreに保存
store = InMemoryStore(
index={
'dims': 1536,
'embed': 'openai:text-embedding-3-small',
}
)
llm = init_chat_model('openai:gpt-4o-mini')
# メモリマネージャーの定義
memory_manager = create_memory_store_manager(
'openai:gpt-4o-mini',
# "memories"という名前空間で記憶を保存する
namespace=('memories'),
)
@entrypoint(store=store)
async def chat(message: str):
# LLMを実行
response = llm.invoke(message)
# memory_managerの記憶の更新処理
# OpenAIのメッセージ形式で保存する
to_process = {'messages': [{'role': 'user', 'content': message}] + [response]}
await memory_manager.ainvoke(to_process)
return response.content
create_memory_store_manager を使うことで、LLM の実行を行う「モデル」とストアにデータを保存する単位である「namespace」を指定するだけで、自動的に store と連携できます。
to_process = {'messages': [{'role': 'user', 'content': message}] + [response]}
await memory_manager.ainvoke(to_process)
記憶管理を実行しているのはこの 2 行です。
この処理を次のように実行してみます。
async def main():
response = await chat.ainvoke('私は犬が好きです。')
print(response)
memories = store.search(('memories',))
print(memories)
if __name__ == '__main__':
asyncio.run(main())
結果は以下のとおりです。
犬は本当に素晴らしいペットですよね!犬のどんなところが特に好きですか?例えば、性格や行動、特定の犬種などについてお話ししていただければ嬉しいです。
[Item(namespace=['memories'], key='fb490f33-d472-49b9-8898-11594f2fb0e5', value={'kind': 'Memory', 'content': {'content': 'The user likes dogs.'}}, created_at='2025-02-22T12:14:02.339480+00:00', updated_at='2025-02-22T12:14:02.339484+00:00', score=None)]
store に「The user likes dogs.」という会話の記憶が保存されていることがわかります。
create_memory_store_managerの記憶管理のLLM
これらがどのように動作しているのか、LangSmith のトレースで確認してみましょう。

先述の create_memory_manager と同様に、記憶管理のための LLM が実装されていることがわかります。(create_memory_store_manager は、内部のプロンプトが少し異なるようです。)
storeへの継続的な記憶の反映
次に、以下のように連続してチャットAPIを実行してみます。
async def main():
await chat.ainvoke('私は犬が好きです。')
memories = store.search(('memories',))
print(memories)
await chat.ainvoke('私は日本に住んでいます。私の犬の名前はポチです')
memories = store.search(('memories',))
print(memories)
await chat.ainvoke('私の趣味は料理です')
memories = store.search(('memories',))
print(memories)
出力結果
[Item(namespace=['memories'], key='2d130122-ab78-42ad-a400-7492610dcbeb', value={'kind': 'Memory', 'content': {'content': 'The user likes dogs.'}}, created_at='2025-02-24T02:39:20.452476+00:00', updated_at='2025-02-24T02:39:20.452483+00:00', score=None), Item(namespace=['memories'], key='b54176b0-327a-4b57-b487-13fb015a2993', value={'kind': 'Memory', 'content': {'content': 'The user has expressed a preference for dogs as pets.'}}, created_at='2025-02-24T02:39:20.697678+00:00', updated_at='2025-02-24T02:39:20.697681+00:00', score=None)]
[Item(namespace=['memories'], key='2d130122-ab78-42ad-a400-7492610dcbeb', value={'kind': 'Memory', 'content': {'content': 'The user likes dogs.'}}, created_at='2025-02-24T02:39:20.452476+00:00', updated_at='2025-02-24T02:39:20.452483+00:00', score=None), Item(namespace=['memories'], key='b54176b0-327a-4b57-b487-13fb015a2993', value={'kind': 'Memory', 'content': {'content': 'The user has expressed a preference for dogs as pets.'}}, created_at='2025-02-24T02:39:20.697678+00:00', updated_at='2025-02-24T02:39:20.697681+00:00', score=None), Item(namespace=['memories'], key='9a948d7a-dbf9-4f78-b568-c6c4ee44970c', value={'kind': 'Memory', 'content': {'content': "The user's dog's name is Pochi."}}, created_at='2025-02-24T02:39:24.197649+00:00', updated_at='2025-02-24T02:39:24.197651+00:00', score=None), Item(namespace=['memories'], key='002b46b0-2b63-468c-92ca-23e34c42d1f9', value={'kind': 'Memory', 'content': {'content': 'The user lives in Japan.'}}, created_at='2025-02-24T02:39:24.601405+00:00', updated_at='2025-02-24T02:39:24.601412+00:00', score=None)]
[Item(namespace=['memories'], key='2d130122-ab78-42ad-a400-7492610dcbeb', value={'kind': 'Memory', 'content': {'content': 'The user likes dogs.'}}, created_at='2025-02-24T02:39:20.452476+00:00', updated_at='2025-02-24T02:39:20.452483+00:00', score=None), Item(namespace=['memories'], key='b54176b0-327a-4b57-b487-13fb015a2993', value={'kind': 'Memory', 'content': {'content': 'The user has expressed a preference for dogs as pets.'}}, created_at='2025-02-24T02:39:20.697678+00:00', updated_at='2025-02-24T02:39:20.697681+00:00', score=None), Item(namespace=['memories'], key='9a948d7a-dbf9-4f78-b568-c6c4ee44970c', value={'kind': 'Memory', 'content': {'content': "The user's dog's name is Pochi."}}, created_at='2025-02-24T02:39:24.197649+00:00', updated_at='2025-02-24T02:39:24.197651+00:00', score=None), Item(namespace=['memories'], key='002b46b0-2b63-468c-92ca-23e34c42d1f9', value={'kind': 'Memory', 'content': {'content': 'The user lives in Japan and their hobby is cooking.'}}, created_at='2025-02-24T02:39:29.804990+00:00', updated_at='2025-02-24T02:39:29.804992+00:00', score=None), Item(namespace=['memories'], key='cb233d2e-cc21-4f35-899b-048dd8f44660', value={'kind': 'Memory', 'content': {'content': "User's hobby is cooking."}}, created_at='2025-02-24T02:39:29.734338+00:00', updated_at='2025-02-24T02:39:29.734347+00:00', score=None)]
出力結果から、store に保存されている記憶の部分だけを抜き出すと以下のようになります。
■ 1回目
- The user likes dogs.
- The user has expressed a preference for dogs as pets.
■ 2回目
- The user likes dogs.
- The user has expressed a preference for dogs as pets.
- The user's dog's name is Pochi.
- The user lives in Japan.
■ 3回目
- The user likes dogs.
- The user has expressed a preference for dogs as pets.
- The user's dog's name is Pochi.
- The user lives in Japan and their hobby is cooking.
- User's hobby is cooking.
それぞれの会話内容に基づいて、store の内容が更新されていることがわかります。
memory_manager の toolをagentから利用する
LangMem では、記憶の管理や検索を行うための toolを提供しています。
現在提供されているtoolは次のとおりです。
| ツール名 | 説明 |
|---|---|
create_manage_memory_tool |
メモリの作成・更新・削除を管理する永続化メモリ操作ツール |
create_search_memory_tool |
セマンティック検索/完全一致で保存済みメモリを検索する情報検索ツール |
これらを agent と組み合わせることで、簡単に記憶を保持したチャット機能などを作ることができます。
以下にサンプル実装を示します。
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStore
from langmem import (
create_manage_memory_tool,
create_search_memory_tool,
)
store = InMemoryStore(
index={
'dims': 1536,
'embed': 'openai:text-embedding-3-small',
}
)
# agent の実行
agent = create_react_agent(
'openai:gpt-4o-mini',
tools=[
# tool に記憶管理(create_manage_memory_tool)と検索(create_search_memory_tool)を指定
create_manage_memory_tool(namespace=('memories',)),
create_search_memory_tool(namespace=('memories',)),
],
# store と連携
store=store,
)
これらを次のように実行してみます。
def main():
# まだ記憶がない状態
response = agent.invoke(
{'messages': [{'role': 'user', 'content': '私の飼っている犬の名前を覚えていますか?'}]},
)
print(response['messages'][-1].content)
# 記憶を更新する
agent.invoke(
{'messages': [{'role': 'user', 'content': '私は、山田太郎です。私は犬を飼っています。名前はポチです。'}]},
)
# エージェントは manage_memories ツールを使用して明示的に保存した
# 記憶のみを呼び出すことができます
response = agent.invoke(
{
'messages': [
{
'role': 'user',
'content': 'こんにちは。私のことを覚えていますか?私の飼っている犬の名前は何でしたか?',
}
]
},
)
print(response['messages'][-1].content)
if __name__ == '__main__':
main()
出力結果は次のとおりです。
あなたの犬の名前を記憶していないようです。犬の名前を教えていただければ、次回から覚えておくことができますよ。
こんにちは、山田太郎さん!あなたの犬の名前はポチですね。何か他にお話ししたいことはありますか?
LangSmithでtoolの呼び出しを確認
この結果を LangSmith で確認してみましょう。
■ 1 回目「私の飼っている犬の名前を覚えていますか?」

- search_memory が呼び出されますが、まだ何も記憶していないため結果は返ってきません。
■ 2 回目「私は、山田太郎です。私は犬を飼っています。名前はポチです。」

- manage_memory が呼び出され、ユーザー名が「山田太郎」であること、犬の名前が「ポチ」であること、「山田太郎が犬を飼っていること」が記憶として保存されます。
■ 3 回目「こんにちは。私のことを覚えていますか? 私の飼っている犬の名前は何でしたか?」

- search_memory が呼び出され、その結果をもとに回答が生成されます。
LangMem で提供される tool API を使うと、保存済みの記憶を簡単に検索・管理できるようになります。
この機能をエージェントと組み合わせれば、継続的な会話コンテキストを保持しながら応答を生成することが可能です。
プロンプトオプティマイザによるプロンプトの改善
LangMemは記憶管理のAPI以外に、プロンプト最適化の為のAPIを提供しています。
プロンプトの最適化には create_prompt_optimizer というAPIを使います。
実際にコードを見てみましょう。
from langmem import create_prompt_optimizer
# プロンプト改善の元となる会話情報
trajectories = [
(
[
{'role': 'user', 'content': 'ふわふわのスクランブルエッグの作り方を教えて'},
{'role': 'assistant', 'content': '弱火でじっくり加熱しながら...'},
{'role': 'user', 'content': '卵がパサつかないコツは?'},
],
None,
),
(
[
{'role': 'user', 'content': '包丁の正しい扱い方を教えてください'},
{
'role': 'assistant',
'content': '包丁は食材に合わせて切り方を変えると良いです...',
},
],
{
'score': 0.85,
'comment': '安全な持ち方と手の位置についての説明を追加すべき',
},
),
(
[
{'role': 'user', 'content': 'パスタの種類と特徴を教えて'},
{'role': 'assistant', 'content': 'ロングパスタとショートパスタがあります...'},
],
{'revised': 'ロングパスタ(スパゲッティなど)はクリーム系ソースと相性が良く...'},
),
]
optimizer = create_prompt_optimizer(
'openai:gpt-4o-mini',
kind='gradient',
config={'max_reflection_steps': 3, 'min_reflection_steps': 0},
)
# promptには初期のプロンプトを指定する
updated = optimizer.invoke({'trajectories': trajectories, 'prompt': 'あなたはプロのシェフです'})
print(updated)
create_prompt_optimizerには、改善の元となる会話情報、LLMのモデル、最適化のプロトコル(kind)、各種設定(何回リフレクションするか?)などを渡します。
実行結果は次のとおりです。
■ 初期プロンプト
あなたはプロのシェフです
■ 最適化の結果
あなたはプロのシェフです。料理技術や調理に関する問題を含め、ユーザーの質問に対して詳細で段階的なガイダンスを提供してください。
最適化のアルゴリズム
create_prompt_optimizerには、kindというパラメタが存在しており、最適化の方法を複数指定することができます。
| 戦略名 | 説明 |
|---|---|
| gradient | リフレクション(内省)を用いて、プロンプトとフィードバックを分析し、改善点を提案します。各ステップで「考察」と「批評」を行い、具体的な改善を適用してプロンプトを更新します。 |
| metaprompt | メタラーニングを活用し、例を分析して直接プロンプトの更新を提案します。各ステップは単一のLLMコールで行われ、効率的にプロンプトを強化します。 |
| prompt_memory | 過去の対話履歴から成功パターンを抽出し、フィードバックを基に改善点を特定、新しいプロンプトに学習したパターンを適用します。シンプルなシングルショットのメタプロンプトとして機能します。 |
詳細はAPIリファレンスも参照ください。
gradientのフロー
metapromptのフロー
prompt_memoryのフロー
LangSmith
先ほどの、gradientのサンプルコードをLangSmithで確認すると3回リフレクションされていることがわかります。

まとめ
ここまでのポイントを簡単に整理すると、以下のとおりです。
-
LangMemの目的
LangMem は、LLM エージェントの「長期記憶」を管理するために開発されたライブラリで、LangGraph の永続化機能(Store)と連携して記憶の追加・更新・削除を行います。 -
記憶管理のAPI
-
create_memory_manager: Store に依存しないメモリ管理 -
create_memory_store_manager: Store と連携し、自動的に永続化
-
-
ツールとの連携
-
create_manage_memory_toolやcreate_search_memory_toolをエージェントに組み込むことで、簡単に記憶の管理・検索が可能
-
-
プロンプト最適化
-
create_prompt_optimizerを使い、過去の会話やフィードバックからプロンプトを改善できる
-
LLM を高い精度で動かすためには、どのような情報を記憶として持たせるかが非常に重要です。LangMem は、この「記憶」を最適化するために特化したライブラリと言えます。個人的には、プロンプトの最適化も「記憶」として捉えられているコンセプトがとても面白いと感じました。
Discussion