browser-useによるブラウザ操作自動化のサンプル集
はじめに
browser-use を使う上で詳しいドキュメントがなかったので、自分で使ってみたことをまとめてみました。
browser-use の基礎的なところは以下にまとめてあります。
ブラウザを起動させず、ヘッドレスモードで実行したい
BrowserConfigのheadlessをTrueにすることで、ブラウザを起動させず、ヘッドレスモードで実行することができます。
from browser_use.browser.browser import Browser, BrowserConfig
browser = Browser(
config=BrowserConfig(
headless=True,
)
)
async def main():
model = ChatOpenAI(model='gpt-4o')
agent = Agent(
task='東京の天気をGoogleで調べてください',
llm=model,
controller=controller,
browser=browser,
)
await agent.run()
input('Press Enter to close...')
if __name__ == '__main__':
asyncio.run(main())
カスタムアクションを作成したい
controller.actionデコレータを使用して、カスタムアクションを作成します。
初期化したcontrollerをAgentの引数に渡してあげることで、カスタムアクションを使用することができます。
import asyncio
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
from browser_use.agent.service import Agent
from browser_use.controller.service import Controller
from browser_use.agent.views import ActionResult
controller = Controller()
class WebpageInfo(BaseModel):
link: str = 'https://github.com/browser-use/browser-use'
@controller.action('Go to the webpage', param_model=WebpageInfo)
def go_to_webpage(webpage_info: WebpageInfo):
return ActionResult(extracted_content=webpage_info.link, include_in_memory=True)
async def main():
task = (
'Go to the browser-use github page via the link I provided you.'
)
model = ChatOpenAI(model='gpt-4o')
agent = Agent(task, model, controller=controller)
result = await agent.run()
print(result)
if __name__ == '__main__':
asyncio.run(main())
ユーザーに入力を求めたい
@controller.actionでユーザーに入力を求めるカスタムアクションを作成します。途中でユーザーの入力が必要な場合に入力されるまでは処理を止めたい場合などで使用できます。
ポイントとしてはカスタムアクションのreturnにActionResultを返すことで、ユーザーの入力をAgentに渡すことができます。
extracted_content={Agentに渡したい情報}とinclude_in_memory=Trueを引数で渡した ActionResultを返さない場合、Agentはユーザーの入力を受け取れません。
from langchain_openai import ChatOpenAI
from browser_use.agent.views import ActionResult
from browser_use import Agent, Controller
import asyncio
controller = Controller()
@controller.action('Ask user for information')
def ask_human(question: str) -> str:
print("Ask human")
user_input = input(f'\n{question}\nInput: ')
# ユーザーの入力をメモリに保存
return ActionResult(extracted_content=user_input, include_in_memory=True)
async def main():
agent = Agent(
task="go to google.com and ask the user for the search query",
llm=ChatOpenAI(model="gpt-4o"),
controller=controller,
)
result = await agent.run()
print(result)
asyncio.run(main())
step のマックスを設定したい
API の料金を抑えたい等の理由で step のマックスを設定したい場合は、agent.run(max_steps=3) のように設定します。
async def main():
agent = Agent(
task="AI関連で勢いのあるプロダクトを10件調べてください",
llm=ChatOpenAI(model="gpt-4o-mini"),
)
result = await agent.run(max_steps=3)
asyncio.run(main())
CAPTCHA を解きたい
スパム対策でよく実施されている CAPTCHA を解決したい場合は、model にgpt-4oを指定して、taskに指示することで解くことができます。
import os
import sys
import asyncio
from langchain_openai import ChatOpenAI
from browser_use import Agent
# NOTE: captchas are hard. For this example it works. But e.g. for iframes it does not.
# for this example it helps to zoom in.
llm = ChatOpenAI(model='gpt-4o')
agent = Agent(
task='go to https://captcha.com/demos/features/captcha-demo.aspx and solve the captcha',
llm=llm,
)
async def main():
await agent.run()
input('Press Enter to exit')
asyncio.run(main())
モデルによって精度が変わるところもあるとは思いますが、gpt-4oで試したところそこまで回答率は高くない印象です。
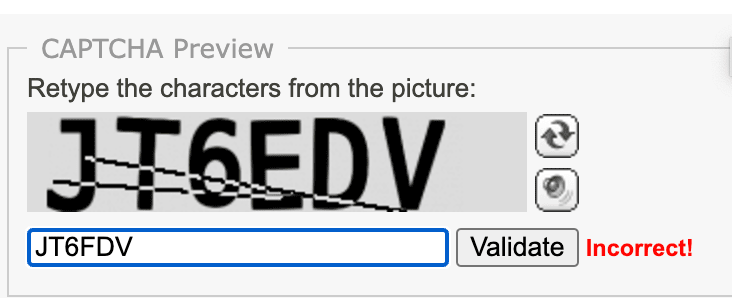
出力をカスタマイズしたい
agent.run()の結果をそのまま出力すると LLM からの出力がそのまま出力されます。
出力をカスタマイズしたい場合は、controller.registry.actionデコレータを使用して、タスク完了時のカスタムアクションを作成します。
import asyncio
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
from browser_use.agent.service import Agent
from browser_use.controller.service import Controller
from browser_use.agent.views import ActionResult
controller = Controller()
class DoneResult(BaseModel):
post_title: str
post_url: str
num_comments: int
hours_since_post: int
@controller.registry.action('Done with task', param_model=DoneResult)
async def done(params: DoneResult):
result = ActionResult(is_done=True, extracted_content=params.model_dump_json())
return result
async def main():
task = 'Go to hackernews show hn and give me the number 1 post in the list'
model = ChatOpenAI(model='gpt-4o')
agent = Agent(task=task, llm=model, controller=controller)
history = await agent.run()
result = history.final_result()
if result:
parsed = DoneResult.model_validate_json(result)
print('--------------------------------')
print(f'Title: {parsed.post_title}')
print(f'URL: {parsed.post_url}')
print(f'Comments: {parsed.num_comments}')
print(f'Hours since post: {parsed.hours_since_post}')
if __name__ == '__main__':
asyncio.run(main())
agent.run()から以下の関数で履歴等の結果を取得することができます。
関数一覧
| 関数名 | 取得・処理できる情報 |
|---|---|
load_from_file |
JSON ファイルから履歴を読み込み、AgentHistoryList を返す |
last_action |
履歴の最後に行われたアクションを取得(存在しない場合は None) |
errors |
履歴内に記録されたすべてのエラー(文字列)のリスト |
final_result |
履歴の最終結果(抽出された内容など)を取得(存在しない場合は None) |
is_done |
エージェントが完了(is_done == True)かどうかを判定 |
has_errors |
エージェントがエラーを含んでいるかどうかを判定 |
urls |
履歴内でアクセスされたユニークな URL のリスト |
screenshots |
履歴内で取得されたスクリーンショットのリスト |
action_names |
履歴内の各アクションの名前(キー)をすべて収集したリスト |
model_thoughts |
履歴内に記録された思考オブジェクト(AgentBrain)のリスト |
model_outputs |
履歴内のモデル出力(AgentOutput)のリスト |
model_actions |
履歴内のすべてのアクション(パラメータ付き)のリスト |
action_results |
履歴内で行われたアクションの結果(ActionResult)のリスト |
extracted_content |
履歴内で抽出されたコンテンツ(文字列)のリスト |
model_actions_filtered |
指定したアクション名のみをフィルタリングして取得したアクションのリスト |
システムプロンプトをカスタマイズしたい
SystemPromptクラスを継承して、important_rulesメソッドをオーバーライドして、Agentのsystem_prompt_classに渡すことで、システムプロンプトをカスタマイズすることができます。
import json
import os
import asyncio
from langchain_openai import ChatOpenAI
from browser_use import Agent, SystemPrompt
class MySystemPrompt(SystemPrompt):
def important_rules(self) -> str:
existing_rules = super().important_rules()
new_rules = 'REMEBER the most importnat RULE: ALWAYS open first a new tab and go first to url wikipedia.com no matter the task!!!'
return f'{existing_rules}\n{new_rules}'
# important_rules以外のメソッドもオーバーライドできますが、推奨されていません。
async def main():
task = 'do google search to find images of elon musk wife'
model = ChatOpenAI(model='gpt-4o')
agent = Agent(task=task, llm=model, system_prompt_class=MySystemPrompt)
print(
json.dumps(
agent.message_manager.system_prompt.model_dump(exclude_unset=True),
indent=4,
)
)
await agent.run()
if __name__ == '__main__':
asyncio.run(main())
ファイルをアップロードしたい
controller.actionデコレータでrequires_browser=Trueを指定し、BrowserContextとindexを引数に指定したupload_fileアクションを作成します。
indexはBrowserContext内での DOM 要素のインデックスで、Agent がアクションを呼ぶ際に、indexを適宜指定してくれるためファイルアップロードを行うことができる要素をget_dom_element_by_indexで取得することができます。
取得した要素に対してset_input_filesを呼ぶことで、ファイルアップロードを行うことができます。
import os
from pathlib import Path
from browser_use.agent.views import ActionResult
import asyncio
from langchain_openai import ChatOpenAI
from browser_use import Agent, Controller
from browser_use.browser.browser import Browser, BrowserConfig
from browser_use.browser.context import BrowserContext
CV = Path.cwd() / 'examples/test_cv.txt'
import logging
logger = logging.getLogger(__name__)
# ブラウザを初期化
browser = Browser(
config=BrowserConfig(
headless=False,
chrome_instance_path='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome',
)
)
controller = Controller()
@controller.action('Upload file to element ', requires_browser=True)
async def upload_file(index: int, browser: BrowserContext):
"""
ファイルをアップロードするアクション
"""
path = str(CV.absolute())
dom_el = await browser.get_dom_element_by_index(index)
if dom_el is None:
return ActionResult(error=f'No element found at index {index}')
file_upload_dom_el = dom_el.get_file_upload_element()
if file_upload_dom_el is None:
logger.info(f'No file upload element found at index {index}')
return ActionResult(error=f'No file upload element found at index {index}')
file_upload_el = await browser.get_locate_element(file_upload_dom_el)
if file_upload_el is None:
logger.info(f'No file upload element found at index {index}')
return ActionResult(error=f'No file upload element found at index {index}')
try:
await file_upload_el.set_input_files(path)
msg = f'Successfully uploaded file to index {index}'
logger.info(msg)
return ActionResult(extracted_content=msg)
except Exception as e:
logger.debug(f'Error in set_input_files: {str(e)}')
return ActionResult(error=f'Failed to upload file to index {index}')
@controller.action('Close file dialog', requires_browser=True)
async def close_file_dialog(browser: BrowserContext):
page = await browser.get_current_page()
await page.keyboard.press('Escape')
async def main():
task = (
f'go to https://kzmpmkh2zfk1ojnpxfn1.lite.vusercontent.net/'
f' and upload to each upload field my file'
)
model = ChatOpenAI(model='gpt-4o')
agent = Agent(
task=task,
llm=model,
controller=controller,
browser=browser,
)
await agent.run()
await browser.close()
input('Press Enter to close...')
if __name__ == '__main__':
asyncio.run(main())
マルチタブを操作したい
open_tabやswitch_tabというアクションが既に用意されているため、taskに全言語で指示を書くことで、マルチタブを操作することができます。
import asyncio
from langchain_openai import ChatOpenAI
from browser_use import Agent
# video: https://preview.screen.studio/share/clenCmS6
llm = ChatOpenAI(model='gpt-4o')
agent = Agent(
# タスク:3つのタブを開き、それぞれにイーロンマスク、トランプ、スティーブジョブズのページを開き、最初のタブに戻って停止する
task='open 3 tabs with elon musk, trump, and steve jobs, then go back to the first and stop',
llm=llm,
)
async def main():
await agent.run()
asyncio.run(main())
同じブラウザで複数の Agent を実行したい
Agentのbrowser_contextに同じBrowserContextを渡すことで、同じブラウザで複数のAgentを実行することができます。
from langchain_openai import ChatOpenAI
import asyncio
from browser_use import Agent, Browser, Controller
async def main():
# ブラウザの状態を複数のAgent間で保持
browser = Browser()
async with await browser.new_context() as context:
model = ChatOpenAI(model='gpt-4o')
# Agent1を初期化
agent1 = Agent(
task='Open 2 tabs with wikipedia articles about the history of the meta and one random wikipedia article.',
llm=model,
browser_context=context,
)
# Agent2を初期化
agent2 = Agent(
task='Considering all open tabs give me the names of the wikipedia article.',
llm=model,
browser_context=context,
)
await agent1.run()
await agent2.run()
asyncio.run(main())
並列実行したい
taskを複数指定したAgentを作成し、asyncio.gatherを使用することで、複数のAgentを並列実行することができます。
import asyncio
from langchain_openai import ChatOpenAI
from browser_use.agent.service import Agent
from browser_use.browser.browser import Browser, BrowserConfig
from browser_use.browser.context import BrowserContextConfig
browser = Browser(
config=BrowserConfig(
disable_security=True,
headless=False,
)
)
llm = ChatOpenAI(model='gpt-4o')
async def main():
agents = [
Agent(task=task, llm=llm, browser=browser)
for task in [
'東京の天気をGoogleで調べてください',
'Redditのトップページのタイトルを調べてください',
'Bitcoinの価格をCoinbaseで調べてください',
'NASAの今日の画像を調べてください',
# 'CNNのトップストーリーを調べてください',
# 'SpaceXの最新の打ち上げ日を調べてください',
# 'パリの人口を調べてください',
# 'シドニーの現在時刻を調べてください',
# '最後のスーパーボウルの勝者を調べてください',
# 'Twitterのトレンドを調べてください',
]
]
await asyncio.gather(*[agent.run() for agent in agents])
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
ファイルに結果を保存したい
controller.actionでparam_modelを指定することで、ファイルに結果を保存することができます。
import asyncio
from typing import List, Optional
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
from browser_use.agent.service import Agent
from browser_use.controller.service import Controller
controller = Controller()
class Model(BaseModel):
title: str
url: str
likes: int
license: str
class Models(BaseModel):
models: List[Model]
@controller.action('Save models', param_model=Models)
def save_models(params: Models):
with open('models.txt', 'a') as f:
for model in params.models:
f.write(f'{model.title} ({model.url}): {model.likes} likes, {model.license}\n')
async def main():
task = f'Look up models with a license of cc-by-sa-4.0 and sort by most likes on Hugging face, save top 5 to file.'
model = ChatOpenAI(model='gpt-4o')
agent = Agent(task=task, llm=model, controller=controller)
await agent.run()
if __name__ == '__main__':
asyncio.run(main())
別のモデルを使用したい
llmに別のモデルを指定することで、別のモデルを使用することができます。
1. Anthropic Claude を使用したい
langchain-anthropicをインストールすることで、Anthropic Claude を使用することができます。
pip install langchain-anthropic
.envファイルにANTHROPIC_API_KEYを設定します。
ANTHROPIC_API_KEY=your_anthropic_api_key
from langchain_anthropic import ChatAnthropic
from browser_use import Agent
import asyncio
async def main():
agent = Agent(
task="Googleで最新の天気予報を調べてください",
llm=ChatAnthropic(model="claude-3-5-sonnet-20240620"),
)
result = await agent.run()
print(result)
asyncio.run(main())
2. Azure OpenAI を使用したい
langchain-azure-openaiをインストールすることで、Azure OpenAI を使用することができます。
pip install langchain-openai
.envファイルにAZURE_OPENAI_API_KEYとAZURE_OPENAI_ENDPOINTを設定します。
AZURE_OPENAI_KEY=your_azure_openai_key
AZURE_OPENAI_ENDPOINT=your_azure_openai_endpoint
from langchain_openai import AzureChatOpenAI
from browser_use import Agent
import os
import asyncio
async def main():
agent = Agent(
task="Googleで最新の天気予報を調べてください",
llm=AzureChatOpenAI(
model='gpt-4o',
api_version='2024-10-21',
azure_endpoint=os.getenv('AZURE_OPENAI_ENDPOINT', ''),
api_key=SecretStr(os.getenv('AZURE_OPENAI_KEY', '')),
),
)
result = await agent.run()
print(result)
asyncio.run(main())
3. Google Gemini を使用したい
langchain_google_genai をインストール後、.envファイルにGEMINI_API_KEYを設定します。
pip install langchain-google-genai
import asyncio
import os
from dotenv import load_dotenv
from langchain_google_genai import ChatGoogleGenerativeAI
from pydantic import SecretStr
from browser_use import Agent
load_dotenv()
api_key = os.getenv('GEMINI_API_KEY')
if not api_key:
raise ValueError('GEMINI_API_KEY is not set')
llm = ChatGoogleGenerativeAI(model='gemini-2.0-flash-exp', api_key=SecretStr(api_key))
async def run_search():
agent = Agent(
task=(
'Go to url r/LocalLLaMA subreddit and search for "browser use" in the search bar and click on the first post and find the funniest comment'
),
llm=llm,
max_actions_per_step=4,
tool_call_in_content=False,
)
await agent.run(max_steps=25)
if __name__ == '__main__':
asyncio.run(run_search())
本家ではないですが、Gemini と DeepSeek を利用できるように改良したリポジトリがありました。
既存のブラウザを使用したい
BrowserConfigに既存のブラウザのパスを指定することで、既存のブラウザを使用することができます。
以下の例ではあらかじめ Google でログインしたブラウザを用意することと、起動する予定のブラウザをすべて閉じることが前提条件です。
※ ログイン後の操作が何でも可能になるため、自己責任でお願いします。
import os
import sys
from pathlib import Path
from browser_use.agent.views import ActionResult
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import asyncio
from langchain_openai import ChatOpenAI
from browser_use import Agent, Controller
from browser_use.browser.browser import Browser, BrowserConfig
from browser_use.browser.context import BrowserContext
browser = Browser(
config=BrowserConfig(
headless=False,
# 注意:デバッグモードでブラウザを開くためには、既存のブラウザを閉じる必要があります。
chrome_instance_path='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome',
# Edgeでも使用可能です。
# chrome_instance_path='/Applications/Microsoft Edge.app/Contents/MacOS/Microsoft Edge',
)
)
controller = Controller()
async def main():
task = f'In docs.google.com write my Papa a quick thank you for everything letter \n - Magnus'
task += f' and save the document as pdf'
model = ChatOpenAI(model='gpt-4o')
agent = Agent(
task=task,
llm=model,
controller=controller,
browser=browser,
)
await agent.run()
await browser.close()
input('Press Enter to close...')
if __name__ == '__main__':
asyncio.run(main())
既存のアクションを上書きしたい
@controller.registry.actionに既存のアクションを上書きすることができます。
例では既にdoneというアクションが存在していますが、これを上書きしています。
タスクが完了した段階で完了アクションが実行されるため、doneアクションを上書きすることで、タスクが完了した段階でメールを送信することができます。
import asyncio
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
from browser_use import ActionResult, Agent, Controller
controller = Controller()
@controller.registry.action('Done with task ')
async def done(text: str):
import yagmail
# To send emails use
# STEP 1: go to https://support.google.com/accounts/answer/185833
# STEP 2: Create an app password (you cant use here your normal gmail password)
# STEP 3: Use the app password in the code below for the password
yag = yagmail.SMTP('your_email@gmail.com', 'your_app_password')
yag.send(
to='recipient@example.com',
subject='Test Email',
contents=f'result\n: {text}',
)
return ActionResult(is_done=True, extracted_content='Email sent!')
async def main():
task = 'go to brower-use.com and then done'
model = ChatOpenAI(model='gpt-4o')
agent = Agent(task=task, llm=model, controller=controller)
await agent.run()
if __name__ == '__main__':
asyncio.run(main())
既存のアクションとして現在以下のアクションが存在しています。
登録関数一覧表
| 関数名 | 役割 | 備考 |
|---|---|---|
search_google |
Google 検索を実行し、結果を現在のタブに表示する。 |
param_model に SearchGoogleAction を指定 |
go_to_url |
指定された URL に現在のタブを遷移させる。 |
param_model に GoToUrlAction を指定 |
go_back |
ブラウザの「戻る」操作を行う。 | |
click_element |
指定されたインデックスの要素をクリックする。 |
param_model に ClickElementAction を指定 |
input_text |
指定されたインデックスの入力要素にテキストを入力する。 |
param_model に InputTextAction を指定 |
switch_tab |
指定された ID のタブに切り替える。 |
param_model に SwitchTabAction を指定 |
open_tab |
指定された URL を新しいタブで開く。 |
param_model に OpenTabAction を指定 |
extract_content |
現在のページのコンテンツをテキストまたはマークダウン形式で抽出する。 |
param_model に ExtractPageContentAction を指定 |
done |
タスクを完了としてマークする。 |
param_model に DoneAction を指定 |
scroll_down |
ページを下にスクロールする。ピクセル数を指定可能。 |
param_model に ScrollAction を指定 |
scroll_up |
ページを上にスクロールする。ピクセル数を指定可能。 |
param_model に ScrollAction を指定 |
send_keys |
キーボード入力をシミュレートする。 |
param_model に SendKeysAction を指定 |
scroll_to_text |
指定されたテキストを含む要素までスクロールする | |
get_dropdown_options |
ネイティブなドロップダウンメニューの選択肢を取得する |
indexパラメータで対象要素のインデックスを指定 |
select_dropdown_option |
ネイティブなドロップダウンメニューから指定されたテキストの選択肢を選択する。 |
indexパラメータで対象要素のインデックスを指定, textパラメータで選択肢を指定 |
ブラウザ上のデータをコピペしたい
copy_to_clipboardとpaste_from_clipboardというカスタムアクションを作成することで、ブラウザ上のデータをコピペすることができます。
例では、Wikipedia のメインページからテキストをコピーし、Google Translate に貼り付けて翻訳するというタスクを実行しています。
from browser_use.agent.views import ActionResult
import asyncio
import pyperclip
from langchain_openai import ChatOpenAI
from browser_use import Agent, Controller
from browser_use.browser.browser import Browser, BrowserConfig
from browser_use.browser.context import BrowserContext
controller = Controller()
@controller.registry.action('Copy text to clipboard')
def copy_to_clipboard(text: str):
"""クリップボードにテキストをコピーする"""
pyperclip.copy(text)
return ActionResult(extracted_content=text)
@controller.registry.action('Paste text from clipboard', requires_browser=True)
async def paste_from_clipboard(browser: BrowserContext):
"""クリップボードからテキストを貼り付ける"""
text = pyperclip.paste()
# send text to browser
page = await browser.get_current_page()
await page.keyboard.type(text)
return ActionResult(extracted_content=text)
async def main():
task = (
'Go to wikipedia.org and copy the first paragraph of text from the main page. '
'Then go to translate.google.com and paste the text to translate it.'
)
model = ChatOpenAI(model='gpt-4o')
agent = Agent(
task=task,
llm=model,
controller=controller
)
await agent.run()
input('Press Enter to close...')
if __name__ == '__main__':
asyncio.run(main())
画面操作の録画を保存したい
BrowserConfigのnew_context_configにsave_recording_pathを指定することで、画面操作の録画を保存することができます。
Agentの初期化時にbrowserを指定することで、任意のパス(今回は./tmp/recordings)に画面操作の録画を保存することができます。
browser = Browser(
config=BrowserConfig(
headless=False,
new_context_config=BrowserContextConfig(save_recording_path='./tmp/recordings'),
)
)
Discussion