はじめに
今回は、Google Cloud のサービスを用いて、大規模言語モデル(LLM)の基盤モデルにチューニングを実施します。一言でチューニングと言っても、さまざまなアプローチがあります。この記事では、チューニングに期待される効果やビジネスにおける価値、そして、Google Cloud で提供されるチューニング機能の概要を説明します。また、Generative AI Studio のコンソールを用いてチューニングを実施する方法を紹介します。
チューニングに期待される効果
これまで「パート 2:PaLM API の利用例 1 〜 英文を日本語で要約する」や「パート 3:PaLM API の利用例 2 〜 メールを分類する」で見てきたように、大規模言語モデルは汎用的な事柄について、要約、分類、アイディア出しといった様々な用途で利用できます。しかしながら、大規模言語モデルはさまざまなドメインの膨大な情報を保持しているため、特定のユースケースに特化して使用する場合、特定ドメインの知識を用いた回答や業界特有の言い回しを用いた回答を得るのが難しい場合があります。
これに対応する 1 つの方法がプロンプトエンジニアリングです。言語モデルに入力するプロンプトに必要な情報を追加したり、回答のサンプルを与えることで、ユースケースにあった回答を得る方法です。その他には、プロンプト(正確にはプロンプトの埋め込み表現)を機械学習の手法で最適化する、プロンプトチューニングと呼ばれる手法もあります。
一方、ここで説明するチューニングでは、基盤モデルそのものに情報を追加することで、より効果的にユースケースに適合した回答が得られるモデルを作ることを目指します。
推論時の性能を向上するプロンプトエンジニアリングと、基盤モデルそのもののチューニングを組み合わせて総合的なチューニングを実施すれば、少し極端な例ですが、人間で例えると、次の様な違いが期待できます。
-
元の言語モデル:法律の仕事に関わらない一般人
-
チューニング後の言語モデル:法律に関する専門的なアドバイスができる弁護士
PaLM をベースとした総合的なチューニングの成功事例として、Med-PaLM 2 と呼ばれる、医療に関する質問を正確かつ安全に回答できる言語モデルがあり、米国医師国家試験(USMLE)形式の問題で構成される MedQA データセットに対して、「エキスパート」レベルの成績を初めて達成しています。その他には、セキュリティに特化した Sec-PaLM もあります。
Google Cloud が提供するチューニングの機能
このように基盤モデルのチューニングは、特定の目的に適したモデルを構築する上での強力なアプローチとなりますが、そのためには、大量の学習データや多くの計算リソースが必要となり、Med-PaLM 2 や Sec-PaLM レベルのチューニングを行うのは容易ではありません。
Google Cloud では、必要とするデータやコストとカスタマイズ性のバランスを考慮したチューニング方法を提供しています。具体的には、数百例程度の学習データで基盤モデルを追加学習することで、Few-shot プロンプティングでは実現できなかったレベルでモデルをカスタマイズすることが可能となります。
「パート 3:PaLM API の利用例 2 〜 メールを分類する」では、メールの分類処理において、Few-shot プロンプティングで数個の例を示しました。より多くの例を示せば、分類精度がさらに向上すると期待できますが、Google Cloud のチューニング機能を用いれば、数百から数千の例を用いたチューニングが可能です。チューニングに使用するデータを工夫することで、業界特有の知識や社内の情報だけでなく、文章を作成する際のガイドライン(指示代名詞を使いすぎない、句読点の打ち方)のような暗黙的な知識も学習できると期待できます。
チューニングを体験してみる
ここではまず、Generative AI Studio の GUI コンソールからチューニングを試してみます。本記事の執筆時点では、まだ日本語テキストの取り扱いに対応していないため、英語のテキストで例を示します。
事前準備
はじめに、チューニングに使用する学習データを用意します。ここでは、Python に関する技術的な質問と回答が収められた公開データセットを使用します。JSONL 形式にデータを変換する必要がありますが、ここでは、変換済みのものをダウンロードして使用します。ここから ZIP 形式のファイルを手元の PC にダウンロードして、解凍しておきます。
オリジナルの公開データセットを JSONL 形式に変換する方法は、こちらのノートブックを参考にしてください。
次に、「パート 1 : 生成 AI ソリューションを使うための基本的なセットアップ」の手順を参考にして、Google Cloud のプロジェクトを作成した後、Vertex AI API と Compute Engine API を有効化します。(Notebooks API を有効化している場合は、Compute Engine API は自動的に有効化されています。)

続いて、チューニングの実行に必要なサービスアカウントを作成します。クラウドコンソールの右上にある下図のボタンをクリックして、Cloud Shell のコマンドターミナルを開きます。

コマンドターミナルが開いたら、次のコマンドを実行します。
UUID=$(cat /proc/sys/kernel/random/uuid)
gcloud ai custom-jobs create \
--display-name $UUID \
--region europe-west4 \
--worker-pool-spec=replica-count=1,machine-type=n1-highmem-2,container-image-uri=gcr.io/google-appengine/python
JOB_ID=$(gcloud ai custom-jobs list \
--region europe-west4 \
--filter="displayName:$UUID" \
--format='value(name)' | rev | cut -d"/" -f1 | rev)
sleep 10 \
&& gcloud ai custom-jobs cancel $JOB_ID --region europe-west4 \
&& echo Done
最後に Done と表示されるまで、少し待ちます。
チューニングの実施
クラウドコンソールのナビゲーションメニューから[Vertex AI]-[GENERATIVE AI STUDIO]-[言語]を選択します。
次の画面が表示されるので、[調整]をクリックします。

[調整済みモデルを作成]をクリックすると、チューニングを開始するためのウィザード画面が開きます。

ウィザードでは「モデルの詳細」と「データセット」を設定します。まず、「モデルの詳細」では以下の項目を設定します。
-
モデル名 : チューニング後のモデルの名前です。学習させたドメイン知識やバージョンを付与しておくとよいでしょう。
-
ベースモデル : 学習の元となる言語モデルです。現在、利用できるモデルは text-bision@001 のみです。
-
ステップをトレーニング : 学習に用いるエポック数です。(この値を大きくすると学習時間が長くなります。)
-
Learning rate multiplier : デフォルトの学習率に掛け合わせる数値です。詳細な調節を行いたい場合以外は、1 のままにします。
-
作業ディレクトリ: 言語モデルの学習に必要なメタデータや作業ファイルを保存するストレージです。モデルの学習を行うリージョンの Cloud Storage バケットを指定します。
-
リージョン : モデルのチューニングを行うリージョンを指定します。現在は、us-central1 と europe-west4 での学習が可能です。チューニング後のモデルは、us-central1 にデプロイされます。

作業ディレクトリについては、[参照]をクリックした後、下図のボタンをクリックして、新しいバケットを作成して使用します。

「バケットに名前を付ける」の画面では、任意のバケット名を指定して、[続行]をクリックします。グローバルで一意な名前が必要なので、先頭部分をプロジェクト ID にするとよいでしょう。
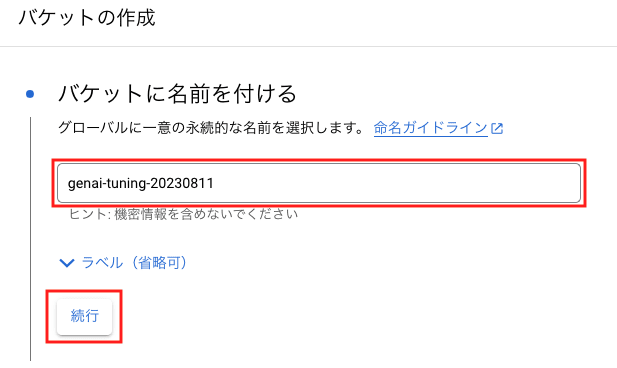
「データの保存場所の選択」では、ロケーションタイプに Region を選択して、モデルのチューニングを行うリージョンを指定します。[作成]をクリックすると、「公開アクセスの防止」のポップアップが表示されるので、[確認]をクリックします。
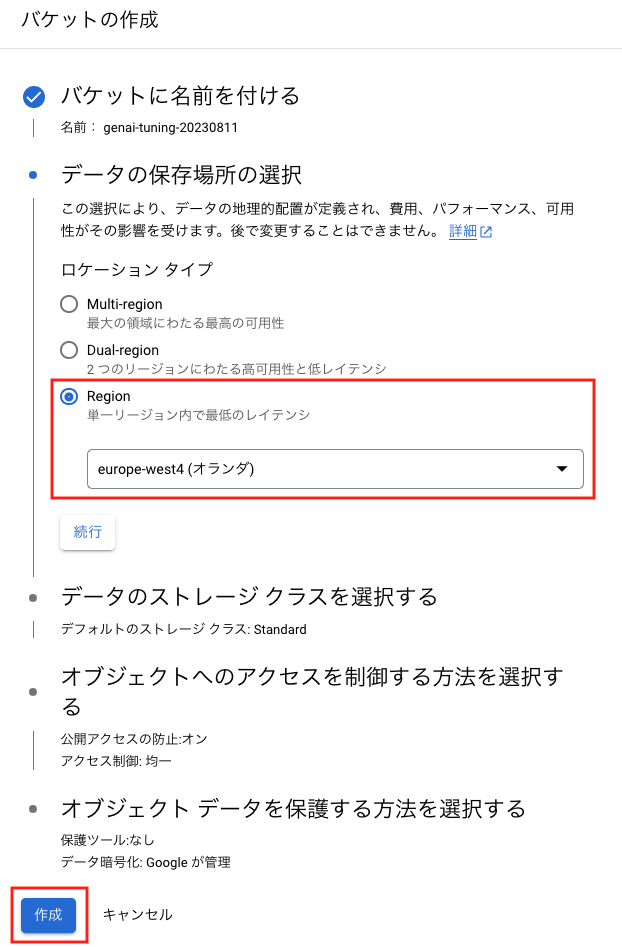
バケットが作成されるので、[選択]をクリックします。

チューニングに使用するデータ数とエポック数の推奨値は、次のようになります。詳しくは公式ドキュメントを参照してください。
| 用途 | データセットのデータ数 | エポック数 |
|---|---|---|
| 分類 | 100+ | 100-500 |
| 要約 | 100-500+ | 200-1000 |
| ドキュメント検索(Extractive QA) | 100+ | 100-500 |
[続行]ボタンを押すと、学習に用いるデータセットを指定するページに飛びます。ここでは、次の項目を指定します。
-
学習に使用するデータ
-
学習データを置く Cloud Storage のバケット
ここでは、「JSONL ファイルを Cloud Storage にアップロードする」を選択して、「JSONL ファイルの選択」に先ほどダウンロードして解凍したファイルを指定します。「データセットの場所」は、[参照]をクリックして、先ほど作成したバケットを指定します。

学習に使用するファイルの中身を見ると、次のように、質問 input_text と回答 output_text のペアが含まれています。input_text は言語モデルに入力するテキストで、output_text はそれに対して期待される回答と見なされます。このため、回答の内容そのものだけではなく、専門用語の使い方や言い回しも学習されることになります。
{
"input_text":"Solving non linear equations where equations are equals in python...",
"output_text":"<p>Looks like you have a system of <strong>non-linear<\/strong> equations...."
}
{
"input_text":"How should I convert numbers in a column to the same format style in Python?"
"output_text":"<p>Suppose you have this DataFrame:..."
}
この後は、[調整を開始]をクリックするとチューニングのパイプラインが実行されます。1 〜 2時間程度で実行が完了して、チューニング済みのモデルが利用可能になります。下図の[テスト]をクリックすると、モデルを使用する画面が開きます。使用するモデルとして、チューニング後のモデルが選択されており、ここからチューニング後のモデルを試すことができます。

Google Cloud で利用可能な大規模言語モデル(PaLM 2)は、もともとプログラミングに関する知識を十分に持っているので、Python に関する一般的な QA データを用いた今回のチューニングでは、はっきりと分かる変化はありませんが、チューニングの処理そのものは簡単に実行できることがわかりました。
チューニング後のモデルを Python SDK から利用する際は、デプロイされたモデルのエンドポイントを projects/[Project ID]/locations/[Region]/models/[Model ID] という形式で指定する必要があります。チューニング後のモデルに付けた名前を text-bison-python-qa とした場合、次のコードが利用できます。チューニングを実施したプロジェクトでノートブックを起動して、試してください。
はじめに、次のコードでエンドポイント名を取得します。(text-bison-python-qa の部分は、実際のモデルの名前に置き換えてください。)
PROJECT_ID = !gcloud config get project
MODEL_ID = !gcloud ai models list --region=us-central1 \
--format="value(MODEL_ID)" \
--filter="DISPLAY_NAME=text-bison-python-qa" 2>/dev/null
ENDPOINT = 'projects/{}/locations/us-central1/models/{}'.format(
PROJECT_ID[0], MODEL_ID[0])
エンドポイント名を用いて、モデルのクライアントオブジェクトを取得します。
from vertexai.preview.language_models import TextGenerationModel
model = TextGenerationModel.from_pretrained('text-bison@001')
generation_model = model.get_tuned_model(ENDPOINT)
取得したオブジェクトは、これまでと同様に使用できます。日付を表示する Python のコードを教えてもらいましょう。
response = generation_model.predict('show python code to print current date')
print(response.text)
結果は次のようになります。
```python
import datetime
# Get current date and time
now = datetime.datetime.now()
# Print current date
print(now.strftime("%Y-%m-%d"))
```
まとめ
今回は、Google Cloud で大規模言語モデルをチューニングする機能を紹介しました。まだプレビュー段階の機能ですが、チューニングの雰囲気はつかめたと思います。簡単のために既存のサンプルデータを用いましたが、実用レベルでのチューニングを行う際は、チューニングに使用するデータの品質が重要になるのは言うまでもありません。

Discussion