カスタマーエンジニアの下門 (しもじょう) です。
前編では Solr Operator を利用することで、簡単に (コマンド一発で) SolrCloud クラスタが構築でき、Kubernetes の Ingress 経由で、Solr Admin UI にアクセスできることを確認しました。
後編では、Solr の基本的なオペレーションである、コレクションの作成、ドキュメントのインデクシングおよび検索を試したあと、実際にフェイルオーバーの挙動を確認していきます。
SolrCloud on Kubernetes 構成
前回のおさらいとして、Solr Operator を利用すると下記の通り Kubernetes リソースが自動的に作成されました。
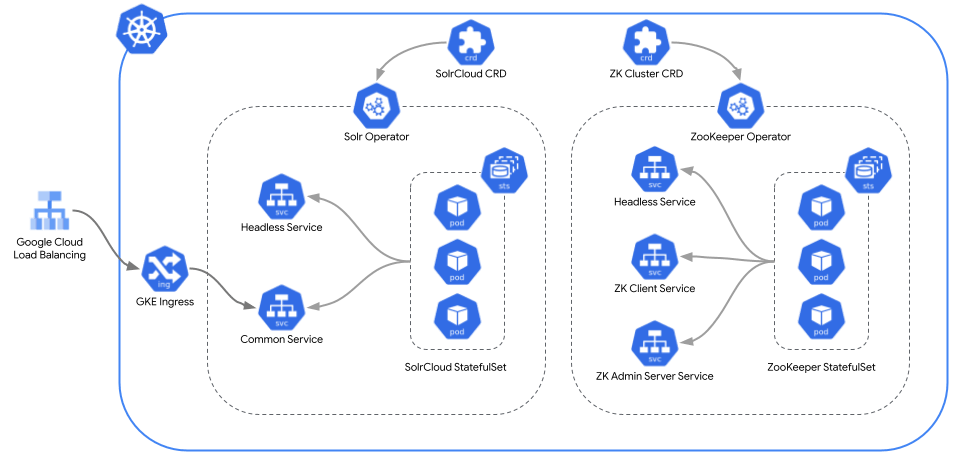
Solr Operator k8s アーキテクチャ
Solr / ZooKeeper は何れもステートフルなワークロードのため、Deployment ではなく StatefulSet として Pod が作成されています。またこれに伴い Headless Service も作成されており、Pod 名での名前解決ができるようになっています。
Solr Operator を利用するメリットの一つとして、例えば Solr のバージョンをアップグレードしたい場合は、独自のローリングアップデート方式がデフォルトで組み込まれているため、既存のシステムへの影響を抑えつつ、ノードの数が多い場合にも一元的にアップデートを適用することが可能になります。Solr Operator で選択できる Update Strategy についてはこちらをご参考ください。
インデックスの作成&検索
ここまででインフラ周りの環境が整ったので、実際に Solr のリソースを作成していきます。
Admin UI 上でも設定・操作できますが、今回はせっかくなので cURL を利用して API 経由でリソースを作成していきます。
コレクションの作成
books という名前のコレクションを作成します。
$ curl "http://${EXTERNAL_IP}/solr/admin/collections?action=CREATE&name=books&numShards=2&replicationFactor=3&maxShardsPerNode=2"
コレクション作成時のパラメータはクエリ文字列として指定します。
| パラメータ | 説明 |
|---|---|
| action | CREATE, LIST, RELOAD, RENAME 等のアクションを指定 |
| name | コレクション名を指定 |
| numShards | シャード数を指定 |
| replicationFactor | シャードあたりのレプリカ数を指定 |
| maxShardsPerNode | ノードあたりの最大シャード数を指定 |
詳しいパラメータの説明は公式ドキュメントをご参照ください。
Solr Admin UI の左側のメニューから Cloud >> Graph を選択すると、各コレクションを構成するシャード並びに各シャードを構成するレプリカの関係がグラフビューで確認できます。

インデックスの作成
続いてドキュメントのインデックスを作成していきます。
サンプルドキュメントをダウンロード
今回は books.json というサンプルをダウンロードして利用します。
$ wget https://raw.githubusercontent.com/apache/solr/main/solr/example/exampledocs/books.json
ドキュメントをインデクシング
先ほどダウンロードしたファイルをリクエストボディに指定して Solr のエンドポイントに対して POST リクエストを送信し、ドキュメントをインデクシングします。
$ curl -X POST -H "Content-Type: application/json" \
-d @books.json \
"http://${EXTERNAL_IP}/solr/books/update/?commit=true"
検索
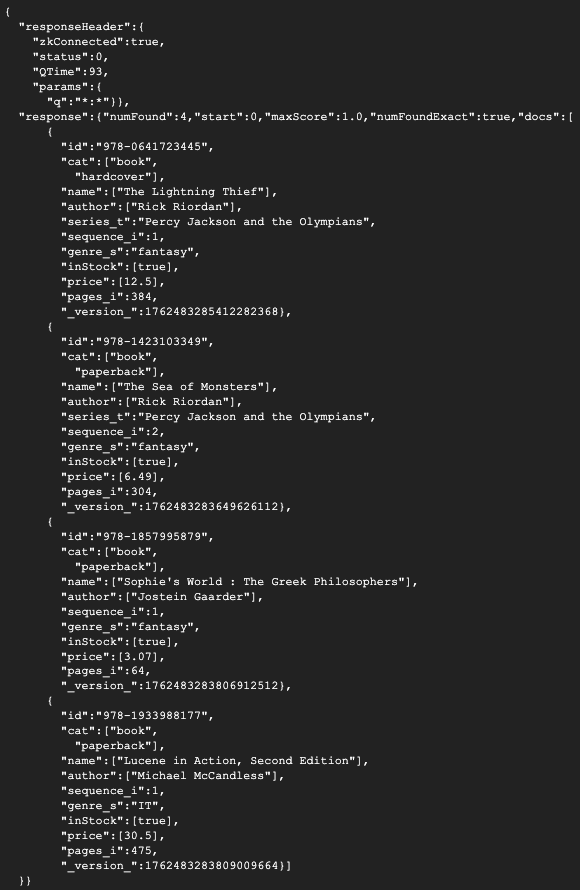
ドキュメントを検索します。今回は検索クエリに全件検索を意味する *:* を指定しています。
$ curl "http://${EXTERNAL_IP}/solr/books/select?q=*:*"
検索結果が返ってきました!
ちなみに、コレクション全体ではなくshards パラメータにシャード名を指定して特定のシャードを対象に検索することもできます。
$ curl "http://${EXTERNAL_IP}/solr/books/select?q=*:*&shards=shard1"
今回は4つのドキュメントの内 shard1 に1つ、shard2 に3つのドキュメントが分割保存されていました。
可用性の確認
意図的にレプリカやノードを手動で削除して、フェイルオーバーの挙動を確認していきます。
フェイルオーバーの確認
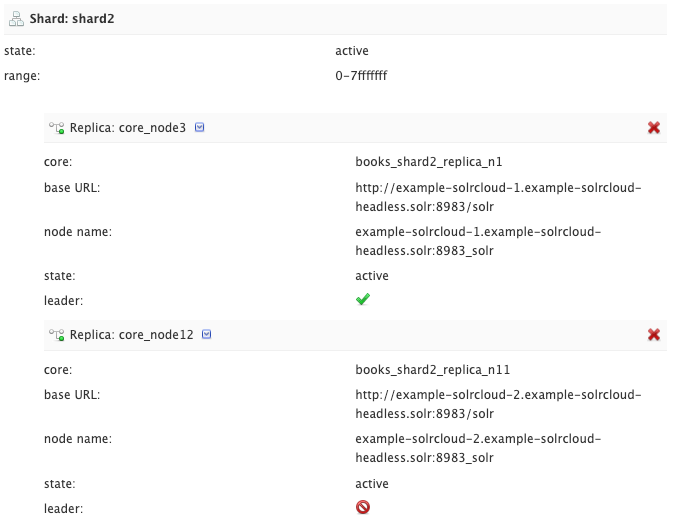
shard2 のリーダーレプリカを削除してフェイルオーバーするか確認してみます。
Solr Admin UI のメニューから Collections を選択すると、各シャードに関する情報が確認でき、shard2 のリーダーレプリカが core_node7 という名前であることが分かります。
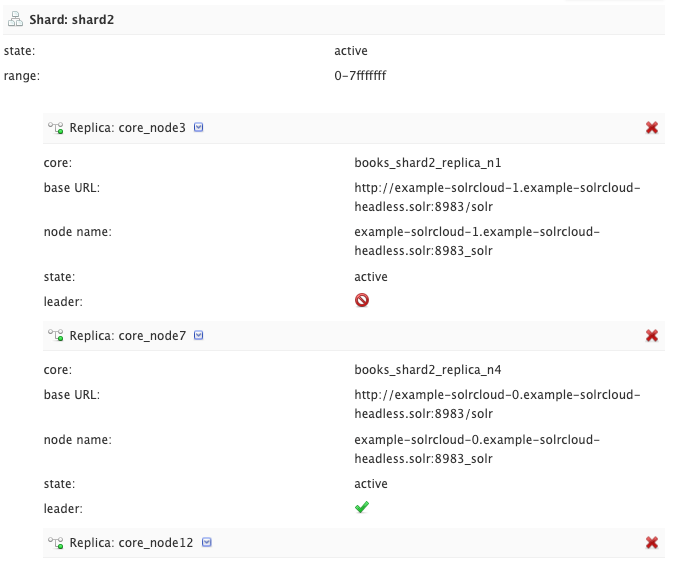
API 経由で core_node7を削除します。
$ curl "http://${EXTERNAL_IP}/solr/admin/collections?action=DELETEREPLICA&collection=books&shard=shard2&replica=core_node7"
shard2 のレプリカ数が3つ→2つになりました。
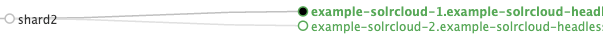
core_node3 が新たなリーダーに選出されています。
続いて shard2 に新たなレプリカを追加します。
$ curl "http://${EXTERNAL_IP}/solr/admin/collections?action=ADDREPLICA&collection=books&shard=shard2"
追加されたレプリカにはインデックスが自動的に同期され、インデックスのリカバリが完了するとノードのステータスが Active に戻ります。

ノード障害時のフェイルオーバー
先ほどはレプリカを API 経由で削除&追加しましたが、今度は Solr ノード (= GKE Pod) 自体が削除された場合にきちんとフェイルオーバーするか検証します。
今回はリーダーが何れも example-solrcloud-2 というノード (GKE Pod) 上に配置されている状況でこの Pod を削除してみます。

SolrCloud リソースの scale コマンドを利用して、レプリカ数を3つ→2つに減らします。
$ kubectl scale --replicas=2 solrclouds/example -n solr
Solr が起動している Pod は StatefulSet として管理されているため、ナンバリングが大きい Pod から、すなわちリーダーレプリカが配置されている example-solrcloud-2 というノード (Pod) が削除されます。
Admin UI の Cloud >> Nodes を選択すると、当該ノードのステータスが DEAD になっています。
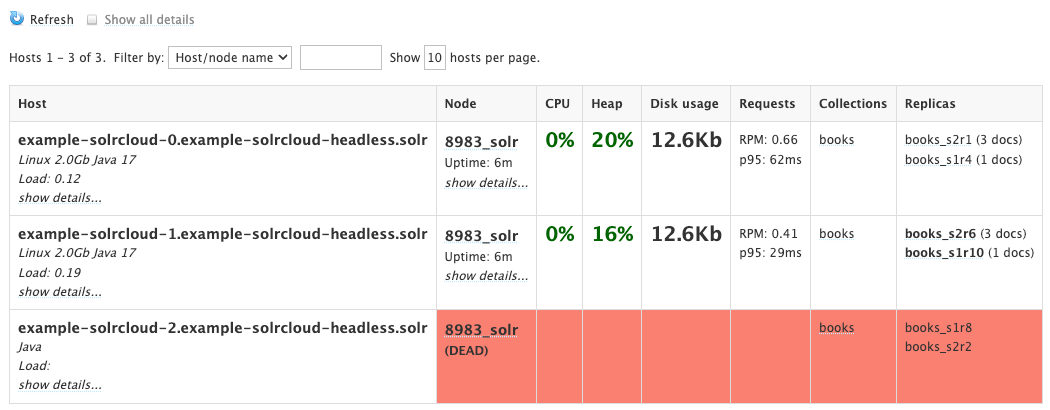
Graph ビューを確認すると、リーダーが配置されているノードがダウンしたため、新たにリーダーが再選出されていることが分かります。
-
shard1shard2のリーダーレプリカがInactiveに

-
新たなリーダーの選出中

-
example-solrcloud-1というノード上のレプリカが新たなリーダーに選出

ノードの障害時にもフェイルオーバーおよびリーダーの再選出が問題なく行われていることが確認できました!
まとめ
前編・後編の2回に渡って、SolrCloud クラスタの概要と Solr Operator を利用して GKE Autopilot 上に構築する手順をご紹介しました。
まとめると SolrCloud on GKE Autopilot with Solr Operator を採用した場合に下記のメリットがあるかと考えています。
- SolrCloud で耐障害性・可用性の高い Solr クラスタが構築できる
- Solr Operator を活用することで SolrCloud クラスタの構築がコマンド一発で完了できる
- 運用面でも Kubernetes の恩恵が受けられるためノードの追加・削除やアップデート作業のオペレーションコストを低減できる
- GKE Autopilot を利用することでサーバーレスで運用できる
- 開発者は検索アプリケーション自体の改善や向上に集中することができる
これから Solr を構築される方や既存の Solr 環境を SolrCloud へ移行検討されている方は、ぜひ Solr Operator も試してみてください!

Discussion