こんにちは、カスタマーエンジニアの下門 (しもじょう) です。
本記事では、SolrCloud クラスタを Kubernetes 上に簡単に構築できる Solr Operator のご紹介とその利用手順を前編・後編の2回に渡って解説していきたいと思います。
前編では「そもそも Solr / SolrCloud とは?」について概要レベルでご紹介したあと、実際に SolrCloud クラスタをセットアップする手順を解説いたします。
後編では、実際に Solr の基本的な機能 (コレクションの作成、ドキュメントのインデクシング、検索) を試したあと、SolrCloud の可用性を検証していきます。
Solr とは
Apache Solr (アパッチ ソーラー) とは、オープンソースの全文検索サーバーです。
中核部分には Java ベースの全文検索エンジンライブラリである Apache Lucene (アパッチ ルシーン) を利用しています。Lucene は Solr の他に Elasticsearch でも利用されています。
Solr 自体、元々 Lucene のサブプロジェクトとして開始され、2021年に Apache の独立したトップレベルプロジェクトに昇格しています。
Lucene は Java API のみを提供していますが、Solr は JSON や XML を使用して HTTP 経由で利用可能な REST ライクな API を提供しています。また、いくつかの言語向けにはクライアントライブラリも提供しています。
2023年4月時点では 9.2.0 が Solr の最新バージョンとなります。
転置インデックス
Lucene / Solr をはじめとする全文検索エンジンの特徴として、転置インデックス (Inverted Index) と呼ばれる、単語と単語を含むドキュメントのマッピングを保持するインデックス型のデータ構造を採用しており、これにより、例えばリレーショナルデータベースの LIKE 検索のような順次検索方式と比べて、大量のドキュメントがある場合でも高速なキーワード検索が行えます。
例えば、下記3つのドキュメントを例に挙げてみます。
- doc1 :
it is what it is - doc2 :
what is it - doc3 :
it is a banana
転置インデックスは、分割された単語をキーにその単語を含むドキュメント ID のリストが値となるように作成されます。
| 単語 | ドキュメント ID |
|---|---|
| a | doc3 |
| banana | doc3 |
| is | doc1, doc2, doc3 |
| it | doc1, doc2, doc3 |
| what | doc1, doc2 |
単語の重み付けと類似度スコア
Lucene / Solr では、ある検索キーワードに対して特定のドキュメントがどの程度マッチするのかを、類似度スコア (Relevance Score) と呼ばれるアルゴリズムにより計算しています。
Lucene / Solr 5 系までは TF-IDF (Term Frequency-Inverse Document Frequency) というアルゴリズムがデフォルトで使用されていました。
具体的には、TF 値 (単語の出現頻度) と IDF 値 (逆文書頻度) という2つの指標に基づいて計算されます。
- TF 値 : ある文書の中である単語の出現回数が多ければスコアが増加する
- IDF 値 : 検索対象の全文書の中でその単語が出現する文書の数が少なければスコアが増加する
例えば、英単語の the, a, an, and, it などは TF 値は高くなりそうですが、多くの文書に出現する単語のため IDF 値が低くなり、あまり重要でない単語と見なされるため、スコアも相殺されて低くなる、といった仕組みです。
Lucene / Solr 6系からは、TF-IDF の進化系である BM25 というアルゴリズムがデフォルトのアルゴリズムに変更されました。従来の TF-IDF では、文章が相対的に長いとスコアが低くなるという問題があったため、BM25 では TF 値、IDF 値に加えて、文書内の総単語数 (Document Length) を利用して、文章の長さによるスコアへの影響が調整されています。
SolrCloud とは
SolrCloud とは耐障害性と高可用性を兼ね備えた Solr クラスタを構成・運用するモードの一つです。
従来の Solr クラスタにおいても、レプリケーションやシャーディングを実現する仕組みは提供されていましたが、分散インデクシングの機能は限定的で、どのシャードにどのドキュメントを保存するのかを、インデクシング時に指定する必要があり、そのため、更新系 (インデクシング等) を担うノードがダウンしてしまった場合に、一部のシャードにドキュメントが登録できなくなる問題が生じていました。
分散検索においても、参照系 (検索) を担うノードがダウンしてしまった場合に、検索対象から手動で除外するか、事前にクライアントと Solr クラスタの間にロードバランサを挟んでリクエストを正常なノードにルーティングする必要がありました。
加えて、一度ダウンしたノードをクラスタに復帰させる際にも、ノード間でインデックスの同期が必要になったり、オペレーションコストが高くなってしまうことが課題でした。
SolrCloud では、分散コーディネーションサービスの ZooKeeper が各ノードを監視し、ノードのステータス管理、設定ファイルの中央集中管理、分散インデクシング、レプリケーション、自動フェイルオーバー、リーダーの自動選出など、SPOF (Single Point of Failure) を極力無くすための仕組みを提供しています。
分散インデクシングをサポートしており、クラスタ内のどのノードに更新リクエストを送信しても自動的に適切なシャードのリーダーへリクエストが転送されます。
また、新たなレプリカを追加する際にも自動的にインデックスをリカバリするため、従来のクラスタと比べて、耐障害性や拡張性が向上しています。
SolrCloud の構成要素
SolrCloud を構成するコンポーネントについて簡単に説明します。
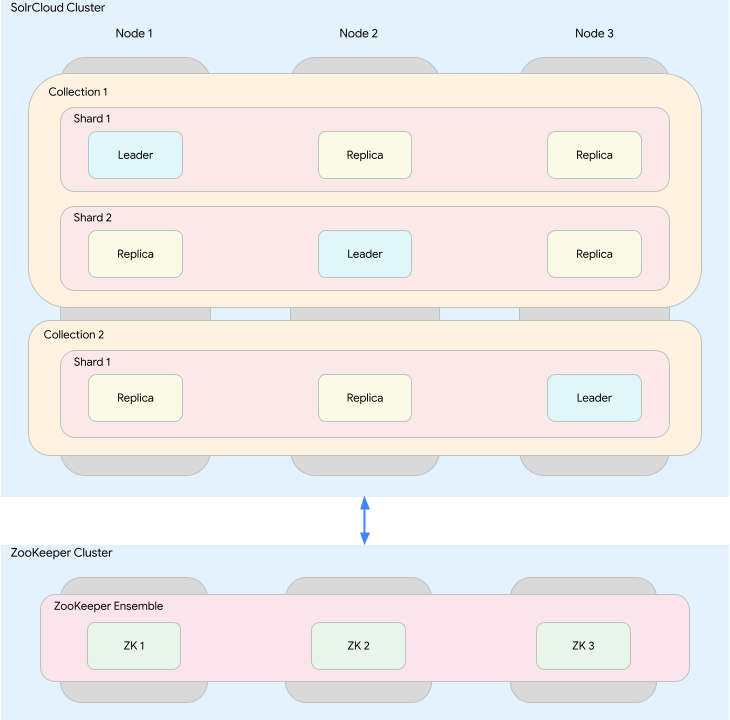
SolrCloud の構成要素
- ノード : 1つの JVM インスタンスで起動する Solr サーバー。今回は GKE Autopilot を利用してクラスタを構築するため、ノード = GKE Pod を意味します。
- クラスタ : 相互に連携して動作する Solr ノードの集合です。
- コレクション : 単一の論理インデックス。単一の設定ファイルとスキーマを保有します。
- シャード : コレクションの論理パーティション。ドキュメント単位でインデックスを分割してシャードに保存することが可能です (単一のドキュメントは必ず単一のシャード内に保存されます)。SolrCloud ではドキュメントのユニークキーから計算したハッシュ値の範囲でどのドキュメントをどのシャードに保存するのかを制御します。
- リーダー / レプリカ : シャードの物理的な複製。シャードは1台以上のレプリカから構成され、その中の1つがリーダーに自動選出されます。
Solr Operator とは
前述の通り、SolrCloud では信頼性の高い検索システムを構築する上で、非常に強力な機能を提供しておりますが、ZooKeeper が必要になったり、従来のクラスタと比べて構成が複雑になってしまう点が導入の敷居を高くしていました。
そこで、Kubernetes の API を拡張するオペレータとして開発・提供されているのが今回ご紹介する Solr Operator です。
Solr Operator を利用すると、SolrCloud クラスタ (Solr + ZooKeeper クラスタ) を Kubernetes 上に簡単に構築することが可能です。
2023年4月時点では v0.6.0 が Solr Operator の最新バージョンとなります。
2023年4月24日に v0.7.0 がリリースされました。
SolrCloud クラスタの構築
前置きが長くなってしまいましたが、Solr Operator を利用して実際に SolrCloud クラスタを構築する流れを解説します。
事前準備
- GKE Autopilot クラスタを作成します (作成手順)。
- Solr Operator は Helm のチャートとして提供されているため、手元の環境に Helm が入っていない場合はこちらを参考にインストールします (今回は Helm がプリインストールされた Cloud Shell を使用しています)。
Helm リポジトリを追加
Solr Operator 用の Helm チャートリポジトリを追加し、リポジトリを最新の状態にアップデートします。
$ helm repo add apache-solr https://solr.apache.org/charts
$ helm repo update
Solr / ZooKeeper Operator をインストール
solr という名前の Namespace を作成して Solr / ZooKeeper Operator をインストールします。
Solr Operator のバージョンは現時点の最新である 0.6.0 を指定します。
$ helm install solr-operator apache-solr/solr-operator --version 0.6.0 \
--create-namespace \
--namespace solr \
--set zookeeper-operator.crd.create=true
Deployment が作成されていることを確認します。
$ kubectl get deploy -n solr
NAME READY UP-TO-DATE AVAILABLE AGE
solr-operator 1/1 1 1 2m30s
solr-operator-zookeeper-operator 1/1 1 1 2m30s
CRDs (Custom Resource Definitions) も作成されていました。
$ kubectl get crds | grep -e solr -e zookeeper
solrbackups.solr.apache.org 2023-04-11T04:09:38Z
solrclouds.solr.apache.org 2023-04-11T04:09:38Z
solrprometheusexporters.solr.apache.org 2023-04-11T04:09:38Z
zookeeperclusters.zookeeper.pravega.io 2023-04-11T04:10:00Z
SolrCloud クラスタを構築
SolrCloud クラスタの構築も helm install を実行するだけで完了します。
$ helm install example-solr apache-solr/solr --version 0.6.0 -n solr \
--set image.tag=9.1 \
--set solrOptions.javaMemory="-Xms500m -Xmx500m"
コマンド実行時の各オプションについてはこちらをご参考ください。
しばらく経つと、Solr や ZooKeeper に関する様々なリソースが自動的に作成されます。
$ kubectl get svc -n solr
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
example-solrcloud-common ClusterIP 10.113.129.43 <none> 80/TCP 22s
example-solrcloud-headless ClusterIP None <none> 8983/TCP 22s
example-solrcloud-zookeeper-admin-server ClusterIP 10.113.128.89 <none> 8080/TCP 21s
example-solrcloud-zookeeper-client ClusterIP 10.113.129.90 <none> 2181/TCP 22s
example-solrcloud-zookeeper-headless ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP,7000/TCP,8080/TCP 21s
$ kubectl get cm -n solr
NAME DATA AGE
...
example-solrcloud-configmap 1 2m53s
example-solrcloud-zookeeper-configmap 4 2m53s
...
$ kubectl get sts -n solr
NAME READY AGE
example-solrcloud 3/3 8m4s
example-solrcloud-zookeeper 3/3 8m4s
$ kubectl get solrclouds -n solr
NAME VERSION TARGETVERSION DESIREDNODES NODES READYNODES UPTODATENODES AGE
example 9.1 3 3 3 3 8m30s
$ kubectl get zookeepercluster -n solr
NAME REPLICAS READY REPLICAS VERSION DESIRED VERSION INTERNAL ENDPOINT EXTERNAL ENDPOINT AGE
example-solrcloud-zookeeper 3 3 0.2.14 0.2.14 10.113.129.90:2181 N/A 8m34s
外部アクセスの設定
SolrCloud クラスタの構築が完了しましたが、現時点ではまだ外部からはアクセスできません。
Solr の Admin UI (管理画面) や API のエンドポイントに外部からアクセスするために Kubernetes の Ingress リソースを作成していきます。
Ingress を作成
先ほどの SolrCloud クラスタ構築の際に example-solrcloud-common という Service (ClusterIP) が外部からのアクセス用に作成されていますので、そちらをバックエンドに指定して Ingress を作成します。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-solrcloud-ingress
namespace: solr
spec:
defaultBackend:
service:
name: example-solrcloud-common
port:
number: 80
$ kubectl apply -f example-solrcloud-ingress.yaml
GKE の Ingress Controller により、外部 HTTP(S) ロードバランサが立ち上がり、外部 IP アドレスが付与されたことを確認します。
$ kubectl get ing -n solr
Solr Admin UI への接続
先ほど付与された外部 IP を指定して http://xxxxxx/solr/ にブラウザからアクセスすると無事に Solr の Admin UI が表示されました!
Solr Admin UI
後編では、今回構築したクラスタに対して分散検索や分散インデクシングを行った上で、実際にフェイルオーバーの挙動を確認し、SolrCloud の可用性を検証していきたいと思います。

Discussion