スプリット統計とは?
Spanner のスプリット統計(Split statistics)という機能が 2024 年 10 月に GA となりました。Spanner にある SPANNER_SYS.SPLIT_STATS_TOP_MINUTE という統計テーブルにクエリ(SELECT)することで、ホットとなっているスプリット、すなわち負荷が高いスプリットが時系列でわかるようになってます。また合わせてこの統計テーブルの情報を Cloud Console から手軽に確認できるホットスポットの分析情報(Hotspot Insights)も登場しました。この情報から、ホットスポットになり続けてるスプリットについて、具体的なテーブル名(インデックス名)とそのキーレンジを特定することができます。どのテーブル(インデックス)を見直せばよいのかがわかるということですね
この統計テーブルは時系列に情報が記録されます。安定運用されている Spanner データベースにおいては、この統計テーブルを見ても空っぽの状態になっていると思います。もしくは、たまにホットスポットの記録が残っているものの、速やかに(10 分程度で)ホットスポットが解消して、このテーブルに記録されなくなる様子が見て取れると思います。
Spanner になじみがある人以外にはスプリットという単語だとイメージわきづらいと思いますが、自動的なシャーディングで負荷分散を行う Spanner にとって、スプリットとはいわゆるシャードのようなものです。負荷が高くなったシャード(スプリット)は、自動的にさらに分割されて、負荷が分散していきます。Spanner の自動シャーディングについてはこちらの記事が詳しいので御覧ください。
スプリット統計にクエリを投げると、例えば以下の表 1 のような結果が返ってきます(ドキュメントから引用)。
表 1. スプリット統計の例
| SPLIT_START | SPLIT_LIMIT | CPU_USAGE_SCORE |
|---|---|---|
| Users(13) | Users(76) | 82 |
| Users(101) | Users(102) | 90 |
| Threads(10, “a”) | Threads(10, “aa”) | 100 |
| Messages(631, “abc”, 1) | Messages(631, “abc”, 2) | 100 |
| Threads(12, “zebra”) | Users(14) | 76 |
| Users(620) | <end> | 100 |
SPLIT_START と SPLIT_LIMIT はそのスプリットにおけるキーの開始と終了の場所を表しています。CPU_USAGE_SCORE は該当キーレンジからなるスプリットが、どの程度 CPU リソースを消費してるかについて抽象化された CPU スコアがパーセンテージで表示されます。つまり最大 100 ということです。ドキュメントによると 50% だとウォームなスプリットで 100% に近づくにつれてホットなスプリットであると書かれてます。Spanner はホットなスプリットを自動的に分割していくので、各スプリットの負荷が高まっていって、スコア 50 - 100 の間で追加の分割が起こって、ホットスポットが解消されて、この統計テーブルから消えていくということが起こるはずです。
SPLIT_START と SPLIT_LIMIT の見方として、START となるキーは該当スプリットに含まれますが、LIMIT となるキーは含まれません。つまり [SPLIT_START, SPLIT_LIMIT) ということです。表 1 の例の 1 行目は、Users テーブルの 13 ≦ PK < 76 が含まれるスプリットということです。5 行目を見るとキーレンジがテーブルをまたがってますね。これはどういう意味でしょうか?イメージとしては Spanner では全部のテーブル(とあとインデックスも)を図 1 のように並べて、一番先頭を <begin> で一番最後を <end> とし、この中で分割線が引かれそこがスプリットの境界になります。 テーブルをまたがったスプリットが出てくるのはこういった背景からです。

図 1. スプリットの分割線のイメージ
スプリット統計の保存期間は 6 時間
スプリットの状態の変化というのは分単位で起こります。SPLIT_STATS_TOP_MINUTE テーブルも名前の通り、1 分ごとの情報となっており、かなり細かい粒度での情報となっています。結果としてこの統計テーブルの情報は 6 時間で揮発していきます。ドキュメントにも以下の通り記載があります。
注: Spanner がホット分割の統計情報を収集するのを防ぐことはできません。これらのテーブルのデータを削除するには、テーブルに関連付けられているデータベースを削除するか、Spanner がデータを自動的に削除するまで待つ必要があります。これらのテーブルの保持期間は固定されています。統計情報を長期間保持する場合は、これらのテーブルから定期的にデータをコピーすることをおすすめします。
負荷試験などリアルタイムにメトリクスを確認できるときはよいのですが、例えば「昨夜 Spanner でレイテンシの悪化が見られたけど、ホットスポットの状態はどうだったのだろうか?」など、6 時間以上経ってからこの情報を見たいと思うときはあると思います。というわけでこれをお手軽に BigQuery に保存してみましょう。ではこれから BigQuery からスプリット統計の情報にアクセスしてみたいと思います。SPLIT_STATS_TOP_MINUTE は SELECT でデータを取れるため、BigQuery から Spanner への連携クエリ(federated query)を使うことで情報を取得できそうです。
リバース ETL 機能を使ってお手軽にホットスポットを発生させてみる
ではさっそく試してみましょう!... といいつつも、スプリット統計はホットスポットがなければそもそも空っぽのテーブルなので、何かしら負荷をかけてホットスポットを生じさせなければなりません、ちょっと手間ですね。何か負荷かけツールを用意してもいいのですが、もっとお手軽に Spanner に負荷をかけられるものがあります。今年登場した新機能の 1 つである BigQuery から Spanner へのリバース ETL です。これは何かというと BigQuery で SELECT した結果を、簡単に Spanner にしかもいい感じに INSERT(EXPORT DATA)してくれるというものです。手頃なデータとして BigQuery のパブリック データセットの、Wiikipedia のページビューのデータを Spanner に大量に書き込んでみました。このリバース ETL の話の詳細は後日別のブログに分けて書きたいと思います。様子だけさっと紹介すると、図 2 のような SQL を書くだけで、Spanner に結果が INSERT されていくというものです。

図 2. BigQuery からのリバース ETL で Spanner に負荷をかける
さて INSERT が始まりました。最後まで INSERT を待つ必要ありませんが、10〜20分程度更新をかけたら、ホットスポットが発生しているか様子を観測してみましょう。まずは手軽に見られるホットスポットの分析情報画面を見てみましょう。図 3 にホットスポットとなっているスプリットが、時系列とともに可視化されていますね。

図 3. ホットスポットの様子
スプリット統計に BigQuery からアクセスしてみる
次に BigQuery から連携クエリ経由で取得してみましょう。事前に外部データソースの接続そして、Spanner の該当 DB への接続設定を作成しておき、それを利用して EXTERNAL_QUERY 経由で SPANNER_SYS.SPLIT_STATS_TOP_MINUTE をクエリしてみます。
SELECT * FROM
EXTERNAL_QUERY(
"<外部データソースとして設定したSpannerの対象DBとの接続>",
"SELECT * FROM SPANNER_SYS.SPLIT_STATS_TOP_MINUTE;"
);
図 4 の通り、BigQuery 上でスプリット統計のテーブルを表示できました。このデータは上に書いた通り 6 時間で消えて行ってしまいますので、せっかくなので BigQuery 側に保存してみましょう。

図 4. BigQuery からの連携クエリでスプリット統計をみる
スプリット統計を BigQuery に保存してみる
まずは CREATE TABLE AS SELECT で一旦 BigQuery 側にテーブルを作ってみます。これで現在のスプリット統計テーブルの断面はコピーされました。
CREATE TABLE `<BigQuery 側でスプリット統計を保存するテーブル>` AS
SELECT * FROM
EXTERNAL_QUERY(
...,
"SELECT * FROM SPANNER_SYS.SPLIT_STATS_TOP_MINUTE;"
);
Spanner 側の SPLIT_STATS_TOP_MINUTE は、タイムスタンプ列である INTERVAL_END が単調増加する時系列データです。BigQuery 側にコピーした最終タイムスタンプを使って、SPLIT_STATS_TOP_MINUTE に新規に追加したものを定期的に(例えば 1 時間に 1 回など)クエリのスケジューリングあたりで追記していけばよさそうです。例えば以下の様な SQL を保存し、それをスケジュール設定します。図 5 をみてください。ここではすぐに確認できるように最短スケジュール時間の 5 分にしていますが、通常は 1 時間など、揮発する 6 時間以内のスケジュールにしておけば十分でしょう。宛先テーブルの書き込み設定には「テーブルに追記する(WRITE_APPEND)」を選びます。ちなみにテーブルを上書きする(WRITE_TRUNCATE)にすると、スプリット統計が空っぽになるとそれで上書きされて消えてしまうので注意してください。
SELECT * FROM
EXTERNAL_QUERY(
...,
"SELECT * FROM SPANNER_SYS.SPLIT_STATS_TOP_MINUTE;"
)
WHERE
INTERVAL_END > (
SELECT IFNULL(MAX(INTERVAL_END),TIMESTAMP_SECONDS(0))
FROM `<BigQuery 側でスプリット統計を保存するテーブル>`
);

図 5. BigQuery からの連携クエリでスプリット統計
スプリット統計を BigQuery で分析してみる
ここから先はケースバイケースですのであくまで一例です。
高い負荷によってスプリット分割が発生している場合、それらはスプリット統計上では、時系列にそってスプリット(キーレンジ)が、ホットになっては分割されてホット状態が解消していくという様子が見えるはずです。つまりスコアが上がっては消えるという様子が見えていくことになります。逆に何らかの理由でホットスポットが解消できない場合、同じキーレンジが高い CPU スコア(例えば 100 近くなど)を維持している様子が見えるかもしれません。またそもそものリクエストの偏りによって、ホットスポットが数分ごとに変わり続けるような場合もうまくスプリットの分割が進まず、同じテーブルの異なるキーレンジが代わる代わる高い CPU スコアになってしまうかもしれません。
例1) キーレンジごとに集計する
重要なのは単一スプリットの CPU スコアがどういう推移をしているかです。ですので SPLIT_START, SPLIT_LIMIT で GROUP BY をし、スプリットごとのスコアの推移を見れるように少しクエリを変えてみます。後半は idx_title(\316\262) から idx_view(2) の範囲が、ダラダラと同じスプリットに負荷が集まってる様子がみえます。スコア 50 いかないくらいなので、ドキュメントによるとウォームなスプリットというところでしょうか。なお idx_view はこのテーブルの view 列にはったインデックスであり、元データがある日時の Wikipedia のページ閲覧数であるため、ロングテール的に閲覧数 1 などにの数が多いです。テーブル境界もまたぐスプリットのためちょっと分かりづらいですが、この場合は idx_view(1) に対する書き込みが集中するため、該当スプリットの負荷が多めだったということになります。
SELECT
SPLIT_START, SPLIT_LIMIT,
ARRAY_AGG(
STRUCT(INTERVAL_END, CPU_USAGE_SCORE) ORDER BY INTERVAL_END
) AS TREND
FROM
`<BigQuery 側でスプリット統計を保存するテーブル>`
GROUP BY
SPLIT_START, SPLIT_LIMIT
ORDER BY TREND[0].INTERVAL_END

図 6. スプリットごとに集計してみる
例2) データ キャンバスで可視化してみる
キーレンジごとにスコアの推移がさらにグラフで見れるとわかりやすいかもしれません。Google Sheets や Looker Studio でグラフにしてもいいのですが、データ キャンバスを使えば BigQuery で手早く可視化もできてしまったりします。スプリットのキーレンジごとに集計してみたいので、そこだけ 1 つの列につなげ、それを Visualization の自動モードで可視化してみました。すると CPU スコアが高くなっては解消していっているスプリットと、後半のウォームスプリットが可視化されました。わかりやすいですね!
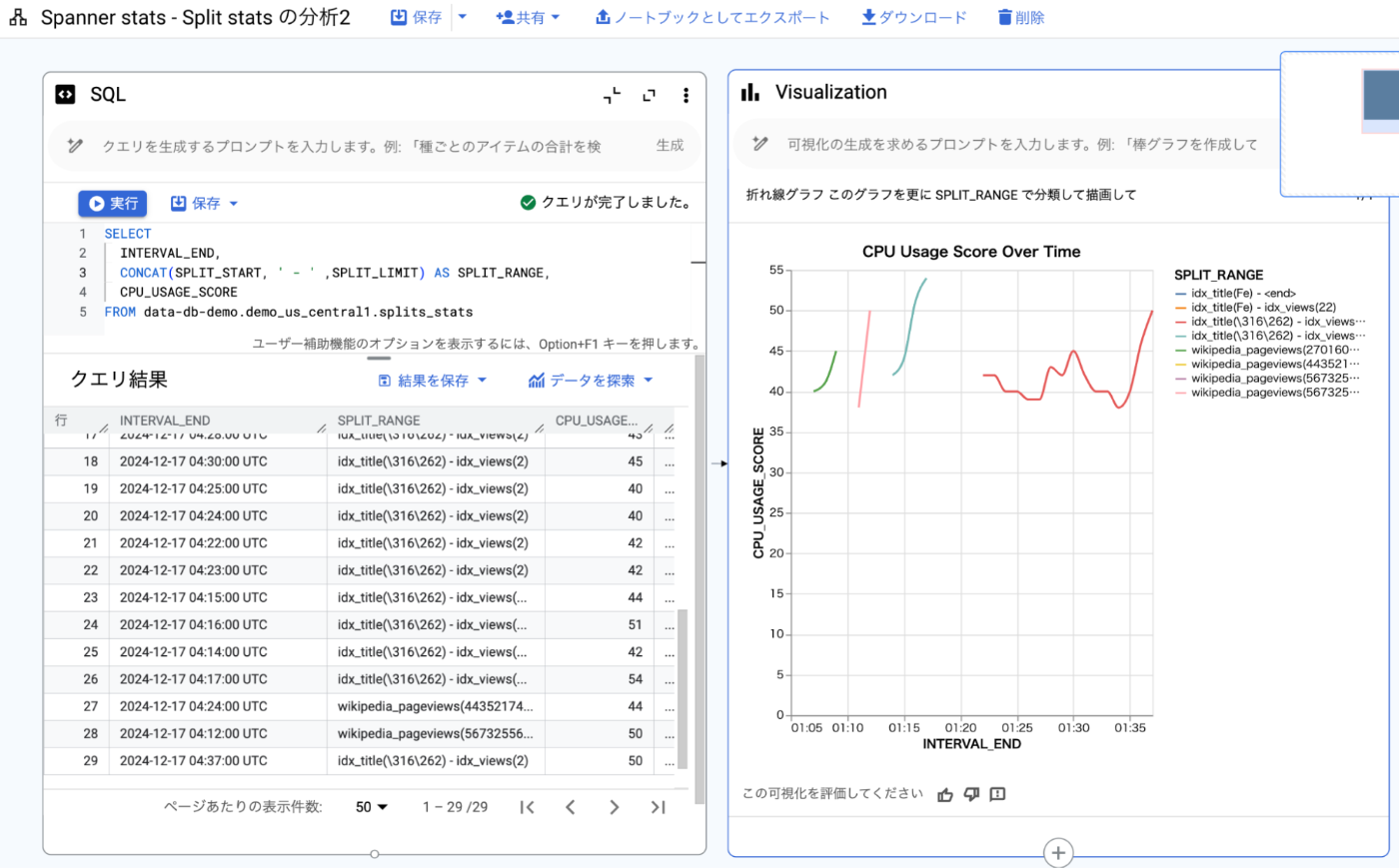
図 7. データ キャンバスを使ってグラフを描画

Discussion