この記事の目的
リレーショナルデータベース(以下、RDBMS)を大規模に利用されるときの構成手法として、データベースシャーディング(Database sharding)という方法があります。オンラインゲームやSaaSなどアクセス頻度が高く、個別のユーザーごとの操作による更新量が大きい用途などでデータベースの書き込み性能の限界に対しての回避策として多くの場面で利用されている手法です。
この手法の実現方法や得失について簡単に解説したあと、この手法の経験者がSpannerを使う場合にシャーディングでの概念をどのようにSpannerに対応できるか解説します。
シャーディングについては十分わかっており、概念の読み替えだけを知りたい方は最後の表をご覧ください。
RDBMSでのシャーディングの構成
シャーディングは通常水平分割で実現されます。つまり1つのテーブルのレコードを複数の異なる物理データベースに配置します。このとき、どのカラムを基準にして分割するかを決めますが、このようなカラムをシャーディングキーと呼びます。よくあるケースではユーザーテーブルをシャーディング対象としたとき、ユーザー IDといったユーザーを一意に特定できるカラムを使って分散させます。マルチテナントのSaaSなどではテナントIDをシャーディングキーに使う場合もあるでしょう。
さらに特定のレコードをどのシャードに格納するかを決める方法として、ハッシュ関数を適用してその結果を使う方式や、ユーザー IDとシャードの対応表を持つ方式などがあります。このドキュメントでは前者をハッシュ方式、後者を対応表方式と呼ぶことにします。
ハッシュ方式は具体的には剰余(割り算の余り)を使ってシャードを決定すると言った方式です。アプリケーションのロジックでシャードが決定できるためシャード決定が高速であるというメリットがありますが、運用開始をしてからのシャード増設やシャーディングのやり直しや、シャーディングキーの範囲を使ってのスキャンが不連続で分散したスキャンになるといった特性があります。
対応表方式は対応表を持つデータベースというコンポーネントが増えるものの、シャード増設が容易であると言ったメリットがあります。

対応表方式では実データへアクセスする前に対応表を一度引いてからアクセス先のシャードを確定し、実際のシャードにアクセスする動きとなります。
シャーディングのメリット
書き込み性能上限の引き上げ
読み込み性能については読み取りレプリカを作ることで性能を引き上げる事が可能ですが、書き込み性能に関してはインスタンスサイズのスケールアップを行う必要がありました。シャーディングは書き込み先を複数の物理データベースに分散させることができるので、書き込み性能に関してもスケールアウトすることが可能です。
対応表方式では各シャードへアクセス毎にこの対応表を引くことになるため、それなりの性能が必要になります。幸い対応表は通常、頻繁に書き換えられることはない(シャード間でのユーザー移動やシャードの増設は稀である)ため、長いTTLで効率よくキャッシュすることが可能です。対応表のデータ構造は単純であるためmemcachedやRedisなどのオンメモリKVSに書いて置くことで高速化が可能です。
シャーディングのデメリット
アプリケーション側の複雑さ
シャーディングされたデータベースへアクセスする部分でシャード決定する機構(シャードリゾルバー)が必要となります。一度書いてしまえばアプリケーション内で流用が可能ですが、バッチなど一部が異なる言語で書かれている場合にはそれらの間で挙動を完全に一致させておくことが重要です。ハッシュ方式などでは細かい挙動も含めて完全に一致しないと障害に繋がりますので注意が必要です。
対応表方式では毎回対応表へアクセスを行うとシャード全体と同じぐらいの高頻度のアクセスを受ける事となるため、前述の通りキャッシュすることが有効です。
構成管理の煩雑さ
一般的に各シャードは同一のテーブル構成で運用されます。そのため、シャーディング対象のデータベースに新しいテーブルやインデックスを追加するときに各シャードへDDLを漏れなく実行する必要があります。いずれかのシャードへDDLを実行漏れがあると、特定のシャードだけ追加したカラムやインデックスが存在しないといった状況が発生し即座に障害へと繋がります。
キャパシティ管理
各シャードの負荷が均一になっていると運用管理が楽ですが、現実問題としてはそのシャードに含まれるユーザー数を均一にしたとしてもサービスへのアクティビティが均一にならない(新規と初期ユーザーでアクティビティが異なるなど)こともあり個別で性能のキャパシティ管理が必要となります。各シャードのインスタンスサイズを調整する必要が出てくるかもしれません。
シャードの増設・削除
サービス開始当初のシャード数ではCPU性能やストレージ容量が不足してきた場合には増設が必要になります。対応表方式では新規ユーザーを新シャードに登録するなどの工夫で増設することが可能でしょう。具体的には4つのシャードを使っているサービスで、5つ目を追加する場合には既存のシャードへの新規流入を止めて新規加入ユーザーは5つ目のシャードに登録するといった工夫です。つまり新規加入のロジックもシャーディングを意識している必要があります。
一方でハッシュ方式ではハッシュ関数にもよりますが、既存のユーザーのシャード移動が必要になる場合があります。これはかなり煩雑な対応が必要で、更新が行われないメンテナンス時間を設けてその間に実施するなどの工夫が必要です。先の剰余の例では"4"で剰余を取っているサービスをシャード数が足りないからと5に変更すると、既存のユーザーも移動しなければいけないというのが想像できると思います。4の次は2倍の8で剰余を取ることでユーザーの移動を減らすという方法も可能ですが、そうなるとシャード数が必要以上に増えてしまうという問題があります。
シャードの削除については廃止シャード上のユーザーのシャード間での移動が必要となるため、実際には廃止は行わず各シャードのスケールダウンで済ませる事が多いかもしれません。その場合、サービス全体のアクティビティが落ちてきたとしてもシャード数は維持する必要があります。
シャードをまたいだ処理
シャーディングを導入した場合、複数のシャードが関連する処理は慎重に実装する必要があります。たとえば、ゲームであるユーザー(UserID AAAA、シャード1に所属)から別のユーザー(UserID BBBB、シャード3に所属)へアイテム(ItemId XXXX)を受け渡すような処理を考えます。この場合、元ユーザー(AAAA)のシャード1に対して
DELETE FROM Items WHERE UserID=AAAA AND ItemId=XXXX
贈り先ユーザー(BBBB)のシャード3に対して
INSERT INTO Items (UserID, ItemId, ... ) VALUES (BBBB, XXXX, ...)
というDMLを発行することになるでしょう。
各ユーザーは異なるシャード、つまり異なるデータベースに格納されている可能性があります。そのため、これらのDMLは2つの独立したトランザクションで発行されることになります。トランザクションがいずれも成功あるいは失敗した場合は問題ありませんが、一方のみが成功した場合にはアイテムが消失したり増殖してしまいます。本来はこのような事態を避けるために本来は分散トランザクションの仕組みを使ってデータベース間で協調させる必要があります。実際のアプリケーションではここまで厳密な制御を行っていないケースも多いのではないかと想像します。
更新ではない場合でも、たとえばシャードをまたいだ検索処理を行いたい場合には全シャードをくまなく検索する必要があります。先の例のようにゲームのアイテムを想定すると、どのユーザーが所有しているか分からない特定のアイテムを全ユーザーを対象に検索したい場合などです。このようにシャードをまたいだ検索ではデータの一貫性が保証されません。シャード横断でデータの断面について各シャードで完全に同一の断面とならないためです。具体的にはシャードをまたいだアイテム引き渡しが行われているときに検索を行うと、どちらのシャードにも存在しない状態(あるいはその逆に重複して存在する状態)が観測される可能性があります。稼働中のサービスではシャードをまたいで一貫性のある結果を得ることはかなり難しいという状況が発生します。
Spannerの構成
Spannerでの解説に移りますが、これ以降の説明は基本的にリージョナル構成(単一リージョン構成)を前提としています。
Spannerのインスタンスは大きく分けてコンピュートとストレージで構成されています。コンピュートは3つを1つのセットとして1ノードとして扱います。各コンピュートは異なるゾーンに分散して配置されるので、1ノードであっても冗長性があります。
1ノードは1,000 PU(Processing Unitsの略)とも呼びます。1,000 PU未満の場合、3つを1セットという構成はそのままに各コンピュートがより小さい大きさになります。1,000 PU以上では1ノードをワンセットとして、ノード数が増えていきます。
1,000 PUのSpannerは単純な1レコードの読み取りを22,500 QPS処理可能な能力を持っています、更新では3,500 QPSが処理可能です。
インスタンス全体では100 PUから1,000 PUまでは100 PU刻みで、1,000 PU(=1ノード)以上では1,000 PU単位でコンピュートの能力を指定できます。100 PUから1,000 PUではコンピュートの大きさで、1,000 PU以上ではコンピュートの数が増えていくことでスケールしていくわけです。
コンピュートの詳しい説明のマニュアルの該当部分もご参照ください。
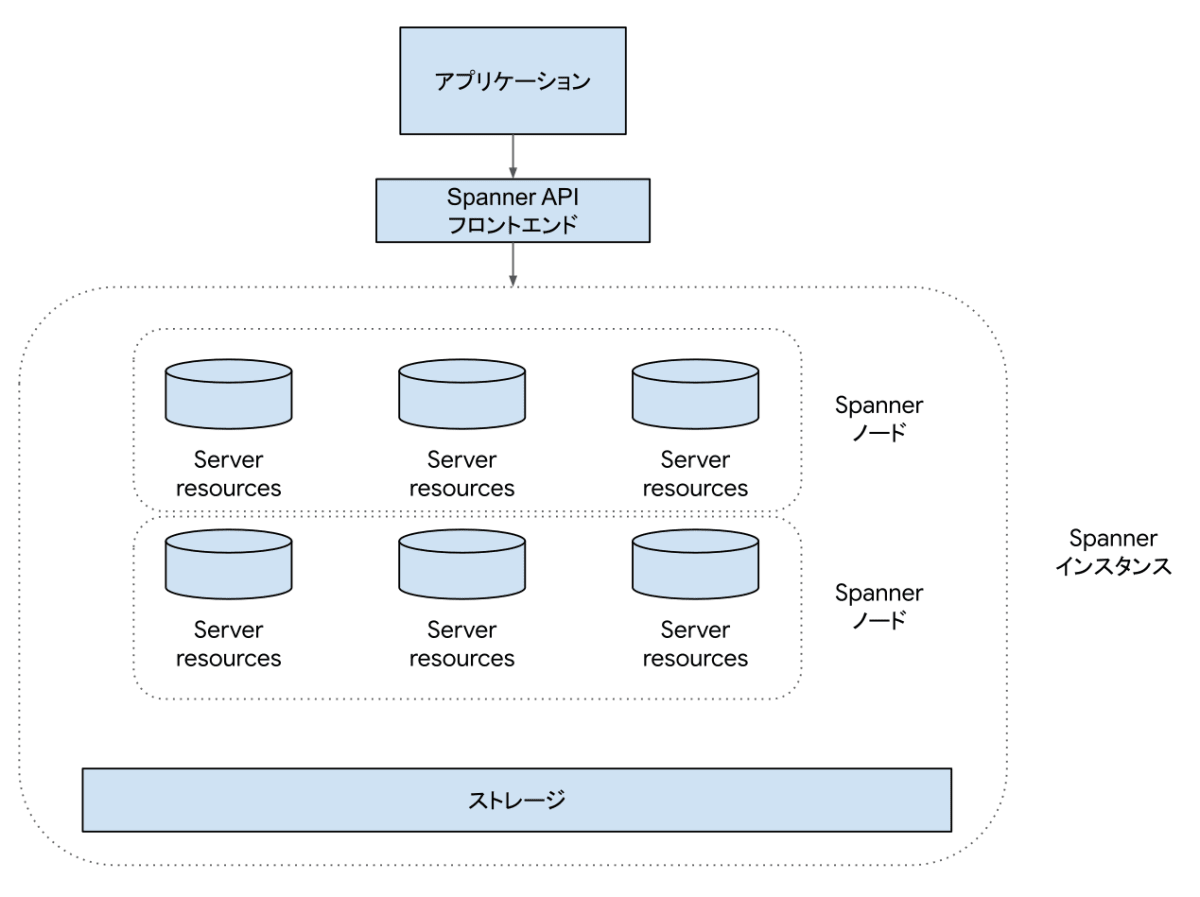
2,000PUのSpannerインスタンスの構成イメージ
図のように2,000 PUのときにはコンピュート(図ではServer resourcesと記載しているコンポーネント)は6個起動することになります。アプリケーションからは常にAPIのエンドポイントへSpannerへのリクエストを送るため、インスタンスが現在幾つのコンピュートで構成されているかは意識する必要はありません。
ストレージはインスタンスを構成する一部ですが、実際にはColossusというGoogleが開発した共有分散ストレージを使っています。構成図ではインスタンスの一部として表現されていますが、実際には共有ストレージであるためリージョン単位に存在する共有のストレージプールを使っています。このためパフォーマンスはインスタンスとは独立してスケールします。サイズも事前に大きさを指定するのではなく、書き込まれたデータサイズに応じて料金が発生するというモデルです。
ストレージの細かい仕組みまで意識する必要はありませんが、ここではストレージとコンピュートが分離されているという点を覚えておいてください。
Spannerの自動シャーディング
Spannerは自動シャーディングという仕組みがあります。これは文字通り水平分割を自動的に行う機能です。シャーディングで使っていた分割の基準となるシャーディングキーとしては、テーブルのプライマリキーを使います。
前提として、Spannerではテーブルをプライマリキーの辞書順で物理的に並べます。このテーブルに対して、Spannerは負荷の状況に応じて自動的にスプリットという単位へと分割を行います。Spannerのシャーディング方式はRDBでのシャーディング方式における、対応表方式をキーの範囲で行っていると言えます。
個々のスプリットを異なるコンピュートへ割り当てることで負荷を平準化と読み書きのスケールを可能としています。コンピュートとストレージが分離されていることで、データの移動なしに各スプリットを担当するコンピュートを変更できます。担当コンピュートの移動は秒単位で行われ、その間にダウンタイムもありません。スプリットが現在何個に分割されているか、どのコンピュートが担当しているかはアプリケーションから意識することなく利用できます。RDBMSでのシャーディング構成における対応表とシャードリゾルバーに相当する機構をSpanner自身が持っているためです。

スプリットは細かくなりすぎても管理とスキャンの効率が良くないため、負荷の低い状態が継続した場合には統合される場合もあります。スプリットはRDBMSの通常のシャーディングよりは少し小さい粒度になりますが、スプリットの分割と統合は自動的に行われますのでシャーディングの増設・削除が自動的に行われるイメージです。
インターリーブテーブル
従来のRDBMSシャーディング構成では分割の基準となるテーブル以外も各シャードに配置することがあります。
引き続きゲームでの例を考えます。ユーザーの基本的なデータを管理するテーブル(Users)が分割の基準になるでしょう。このテーブルは当然各シャードに分散配置します。また、各ユーザーはアイテム(Items)や魔法(Spells)を複数持っている場合、これらのテーブルを各シャードにまったく同じ定義で配置することになります。
これはユーザーの情報とその所有するアイテム情報をJOINするなどして、1回のSELECTでアクセスするときに効率的にアクセスできるようにするためです。もちろんスケーラビリティの観点でもこの構成は重要です。
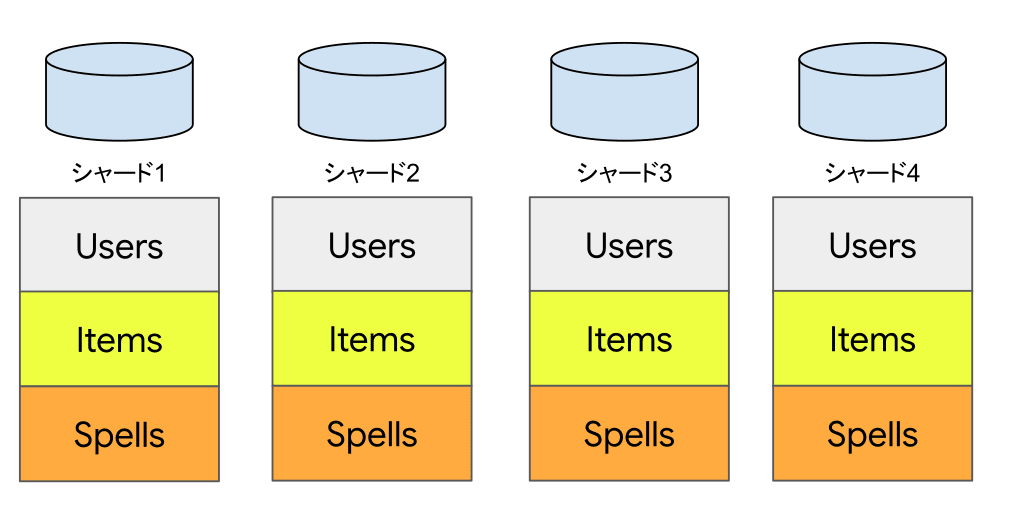
このようなテーブル構成をSpannerで実現する場合、インターリーブされたテーブルを使うと似たような物理レイアウト構成が可能です。DDLは以下のような構成になるでしょう。
CREATE TABLE Users (
UserId INT64 NOT NULL,
UserName STRING(128),
Job INT64,
GuildId INT64,
) PRIMARY KEY(UserId);
CREATE TABLE Items (
UserId INT64 NOT NULL,
ItemId STRING(128),
ItemName STRING(128),
Quantity INT64,
UsageCount INT64,
) PRIMARY KEY(UserId, ItemId),
INTERLEAVE IN PARENT Users ON DELETE CASCADE;
CREATE TABLE Spells (
UserId INT64 NOT NULL,
SpellId STRING(128),
SpellName STRING(128),
) PRIMARY KEY(UserId, SpellId),
INTERLEAVE IN PARENT Users ON DELETE CASCADE;
プライマリキーが通常のシャーディング構成とはちょっと違うかもしれません。ItemIdが単体でNOT NULLかつUNIQUEである場合、これだけをプライマリキーとする場合もあります。しかしインターリーブテーブルではUserIdとItemIdの複合プライマリキーにする必要があります。これは、ちょっと冗長に感じるかもしれません。シャーディング構成ではシャーディングキー(この場合、UserId)が不明だった場合には格納しているシャードが決定できないため、実際のデータへアクセス前にシャードリゾルバーでUserIdをキーにして検索する必要があります。そのため、Spannerではシャードリゾルバーを内部に持っているためインターリーブテーブルでUserIdをプライマリキーの前につけることが必要なこと自体は違和感がないと思います。

この例ではUsersテーブルに対して、ItemsテーブルとSpellsテーブルをインターリーブしています。インターリーブ(Interleave)とは「間に綴じ込む」という意味です。その名前の通り、Usersテーブルのレコードの間に対応する2つのテーブルの関連レコードを配置します。これによって個別ユーザーのデータとその所有アイテムと魔法がまとまっているため、JOINなどで同時にアクセスするときも効率よく行えます。
インターリーブインデックス
RDBMSのシャーディング構成で各シャードに配置しているテーブルへセカンダリインデックスを作ることがあります。その場合、各シャードにインデックスを作ることなります。
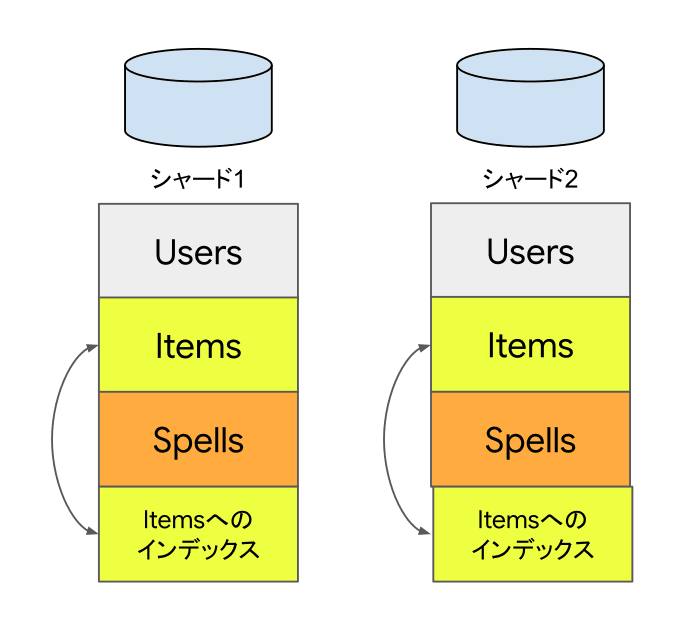
Spannerではこのような各シャードに配置するセカンダリインデックスについて、インターリーブが可能です。
たとえば、ItemsのQuantity(数量)カラムにインデックスを作る場合を考えます。利用場面としてはゲームのルールとしてユーザー毎のアイテムの所持数上限があり、アイテムの総数をカウントしたい、などでしょうか。セカンダリインデックスのDDLとしては以下のようになります。
CREATE INDEX ItemQuantity ON Items(UserId, Quantity), INTERLEAVE IN Users;
インターリーブテーブルと同じく、UserIdが先頭につきますがこれはシャーディング構成でのシャード決定に必要な理由と同様です。Itemsテーブルへのインデックスですがインターリーブ先としてはUsersテーブルであることに注意してください。

セカンダリインデックスをインターリーブで構成するメリットはテーブルと同様に関連するレコードと連続して配置されるので効率よくアクセスできることです。シャーディング構成で各シャードに作成したセカンダリインデックスは多くの場合でインターリーブインデックスに読み替えが可能でしょう。更新に関してもインターリーブされるため親テーブルの分散に従い配置されるので、スケーラビリティの点で有利です。
インターリーブの見逃されがちなメリット
これまでの説明でインターリーブテーブルやインデックスはデータの局所性があがることで効率的なアクセスができることは理解できたかと思います。あまり注目されないもう1つのメリットとして、子テーブルが親テーブルの分散にしたがって配置されるため追加直後から十分に分散することがあげられます。
Spannerではテーブルやインデックスは負荷に応じて内部的に自動シャーディングを行います。初期状態では単一のシャードに格納されていたとしても運用していくうちに多数のスプリットに分割されて最適な状態へと自動的に分散されます。この状態で新たな子テーブルを追加すると、親テーブルの分散状態に従い配置されるため追加直後から最適なパフォーマンスが期待できます。サービスの運用後にテーブルを追加する場合などでも、十分に分散して配置されることは運用上のメリットが大きいです。
セカンダリインデックス
Spannerはインターリーブではないインデックスを作ることも可能です。このようなセカンダリインデックスにとくに名前はついていませんがテーブル全体へのインデックスですので、ここではグローバルインデックスと呼ぶことにします。グローバルインデックスがあればシャード構成でのシャードをまたぐようなテーブル全体への検索も効率的に可能です。
一方で、テーブル全体へのインデックスであるためインデックスの対象カラムへの更新があったときはグローバルインデックスも同時に更新が発生します。インデックス対象カラムが単調増加・減少する内容だった場合には特定の部分に更新が集中することになります。このようなグローバルインデックスを作る場合、インターリーブにできないか、できない場合は何らかの方法で書き込みを分散できないか検討ください。インターリーブインデックスであれば書き込みも分散するため、この問題は起こりにくいです。インターリーブインデックスの場合はプライマリキーで分散するのでこの問題はほぼ発生しません。
グローバルインデックスに書き込み集中することがボトルネックとなる場合について、具体的な例を考えます。たとえばGmailのようなマルチテナントのメールサービスを提供しているとします。各ユーザー毎のメールはタイムスタンプの降順、つまり最新のメールを中心に読むことが多いでしょう。そのような場合、グローバルインデックスでサービス全体のメールに対してタイムスタンプの降順でグローバルインデックスを作成すると、サービスに対してメールが到着するたびにシステム全体で1つのインデックスの末端部分に更新を行うことになります。サービス全体の規模にもよりますが、これはSpannerを使っていてもサービスの成長のボトルネックになる可能性が高いでしょう。
一方で、マルチテナントのメールサービスであるため各ユーザーは自分のメールを読むというユースケースが一般的です。SQLレベルではクエリーにユーザーIDが常に条件句を含むため、ユーザーのテーブルに対してインターリーブを行ったセカンダリインデックスで事足りるはずです。インターリーブインデックスにしておけば、更新箇所はシステム全体で一箇所からユーザー毎のメールボックス単位で分散されるため、サービス全体で一箇所に書き込みが集中するということが避けられます。
グローバルインデックスに関連する話題はSpanner特有の考慮事項となります。これは、RDBでのシャーディング構成ではこのようなグローバルインデックスに該当する概念がなく、シャードをまたいだ検索は自前で実装する必要があるためです。
負荷の管理
Spannerでは負荷の状況に応じてテーブルをスプリットに分割します。また分割したスプリットの担当ノードも動的に変更することで全体の負荷を平準化しようとします。
一時的に負荷のアンバランスが生じた場合も、自動的に負荷は平準化されます。
構成の節で触れた通りストレージとコンピュートが分離されているため、スプリットの担当ノードの変更時にデータの移動の必要はありません。そのため、平準化は秒単位で行われます。
どのような不均一が発生したかはKey Visualizerのヒートマップを見ることで確認が可能です。スプリット統計からも、どの範囲のデータに負荷が集中しているかを確認可能です。
運用時には自動調整機能に任せつつ全体で性能が不足した場合には、ノードを追加することが負荷管理の基本となります。もちろん、ノードの追加・削除は無停止で行えます。利用できるエディションが限定されますがノード数のオートスケールも可能です。
ただし、先の項目で既出ですが単調に増加・減少するキーについてはスキーマ設計での対応が必要となることもあります。
シャード(スプリット)をまたいだ処理
Spannerではシャード(スプリット)をまたいだトランザクションも実行可能です。同一テーブルの異なるスプリットでも異なるテーブル間でアトミック(原子的)なトランザクション操作が可能です。アプリケーションからはシャードをまたいだ処理であるか否かによらず、通常のトランザクションとして実行すれば整合性のある結果が得られます。
ゲームの例ではユーザー間でのアイテムの交換やユーザー同士で対戦を行った結果の反映などが考えられます。
このような操作をどうやって実現しているかについてはかなり詳しい動作の解説があります。分散トランザクションとなるため、2フェーズCommitを行っておりシャーディングで本来求められるシャーディング間の協調動作が行われています。利用者の視点ではここまで詳しい仕組みの理解は必要ありません。
細かい仕組みを理解をしていなくとも、複数のスプリットへの更新も一貫性を持った処理が可能であること、単純な単一のスプリットへの更新よりはやや高コストな処理であることを理解していればアプリケーションからは問題なく利用可能です。
概念の対応
ここでシャーディング構成に出てくる概念とSpannerでの概念を簡単に表にまとめます。各項目の詳細はこれまでの説明も合わせてご参照ください。
| シャーディングでの概念 | Spannerでの概念 |
|---|---|
| シャーディングキー | プライマリキー |
| 各シャードへ配置したテーブル | インターリーブテーブル |
| 各シャードへ配置したテーブルへのインデックス | インターリーブインデックス |
| 全シャードへの網羅的な探索 | 全表探索か非インターリーブインデックスでの検索 |
| 各シャードのスケールアップ・ダウンによる性能管理 | (無停止での)ノード追加・削除 |
まとめ
RDBMSでのシャーディングで使う基本的な概念は、Spannerの概念に対応できることを解説しました。
個人的にはSpannerのインターリーブの概念が非常にスマートだと感じています。インターリーブが提供している機能はシャーディングを構築したり利用したことがある人ほど、理解しやすくそのメリットを感じられると考えたのがこの記事のスタート地点でした。
シャーディングにまつわる複雑性や運用上での困難に悩んでいる方にこそ、Spannerを体験いただきたいです。

Discussion