2023年は「Cloud Run を触って覚える」をテーマとした ひとりアドベントカレンダー を開催しており、Cloud Run のさまざまな機能や Cloud Run でよく使う構成などをご紹介しています。
18日目は Cloud Run ジョブで Gemini Pro Vision の API を使って画像にタグを付ける方法についてご紹介します。Gemini Pro および Gemini Pro Vision は現在、プレビューで提供しています。
Cloud Run の概要は「gihyo.jp」で解説していますので、こちらもぜひご覧ください。
API を有効化する
まずは使用する API を有効化しましょう。コマンドの実行は Cloud Shell で行います。
gcloud services enable \
bigquery.googleapis.com \
storage-api.googleapis.com \
aiplatform.googleapis.com
数秒~数分後、API の有効化が完了します。
画像データを用意する
次に画像データを用意し、GCS バケットにアップロードしておきます。画像データは商品画像データなど、お好きな画像を用意してください。ここでは5枚の画像を用意した前提で進めます。
ここでは Google Merchandise Store の商品画像をいくつか使用しました。
ローカルに images フォルダを作り、その中に入れておきます。

images フォルダ
次のコマンドでバケットを作成します。
gcloud storage buckets create gs://<BUCKET_NAME> \
--location asia-northeast1
Cloud Shell に画像をアップロードするには、オプションメニューから [アップロード] を選びます。
アップロード
[フォルダ] をクリックし images フォルダを選びます。
フォルダの指定
Cloud Shell へのアップロードが完了したら、次のコマンドで GCS バケットに画像ファイルをアップロードします。
gcloud storage cp images/* gs://<BUCKET_NAME>/
以上で GCS の準備は完了です。
BigQuery を用意する
次に BigQuery のデータセット、およびテーブルを用意します。
次のコマンドで BigQuery のバケットを作成します。
bq --location asia-northeast1 \
mk \
--dataset \
<PROJECT_ID>:products
BigQuery テーブルに読み込ませる CSV ファイルを用意します。ここでは GCS バケットにアップロードした画像ファイルをリストし、CSV ファイルに加工します。
gcloud storage ls gs://<BUCKET_NAME>/ > tags.csv
awk '{print $0","}' tags.csv > import.csv
import.csv は次のようなファイルになります。
gs://<BUCKET_NAME>/GGOEGHPB211899.jpg,
gs://<BUCKET_NAME>/GGOEGHPT221410.jpg,
gs://<BUCKET_NAME>/GGOEGXXX2037.jpg,
gs://<BUCKET_NAME>/GGOEGXXX2079.jpg,
gs://<BUCKET_NAME>/GGOEGXXX2217.jpg,
BigQuery のスキーマ定義ファイルを作成します。
[
{
"name": "uri",
"type": "STRING"
},
{
"name": "tags",
"type": "STRING",
"mode": "NULLABLE"
}
]
bq load を実行し、テーブルの作成とインポートを実行します。
bq load \
--source_format=CSV \
<PROJECT_ID>:products.tags \
./import.csv \
./schema.json
BigQuery コンソールを開き、次のクエリを実行しデータが入っていることを確認します。
SELECT uri, tags FROM `<PROJECT_ID>.products.tags`

BigQuery テーブルのクエリ結果
Cloud Run ジョブをデプロイする
次に Cloud Run ジョブをデプロイしましょう。Git リポジトリからジョブに使用するサンプルコードをクローンします。
git clone https://github.com/suwa-yuki/gemini-jobs-sample.git
cd gemini-jobs-sample
main.js では BigQuery のレコードごとに Gemini Pro Vision の API を呼び出すような実装をしています。
'use strict'
const {BigQuery} = require('@google-cloud/bigquery')
const {VertexAI} = require('@google-cloud/vertexai')
const {Storage} = require("@google-cloud/storage")
const {CLOUD_RUN_TASK_INDEX = 0} = process.env
const projectId = process.env.PROJECT_ID
const bq = new BigQuery()
const gcs = new Storage()
const vertexAI = new VertexAI({project: projectId, location: 'asia-northeast1'});
const model = vertexAI.preview.getGenerativeModel({
model: "gemini-pro-vision",
generation_config: {
"max_output_tokens": 2048,
"temperature": 0.4,
"top_p": 1,
"top_k": 32
}
})
const prompt = "あなたはECサイトのコンテンツ管理者です。添付した商品画像に相応しいタグを生成してください。カンマ区切りで出力してください。"
const main = async () => {
const query = `SELECT uri FROM \`${projectId}.products.tags\` LIMIT 1 OFFSET ${CLOUD_RUN_TASK_INDEX}`
const data = await bq.query(query)
const row = data[0][0]
const uri = row.uri
console.log(`execute : ${uri}`)
const [bucket, object] = uri.replace('gs://', '').split('/')
const blob = await gcs.bucket(bucket).file(object).download()
const base64 = Buffer.from(blob[0]).toString('base64')
const request = {
"contents": [{
"role": "user",
"parts": [
{
"text": prompt
},
{
"inlineData": {
"mimeType": "image/jpeg",
"data": base64
}
}
]
}
]
}
const stream = await model.generateContentStream(request)
const response = await stream.response
const tags = JSON.stringify(response.candidates[0].content.parts[0].text)
const insert = `UPDATE \`${projectId}.products.tags\` SET tags = ${tags} WHERE uri = "${uri}"`
await bq.query(insert)
}
main().catch(err => {
console.error(err)
process.exit(1)
})
Cloud Run ジョブをデプロイします。ここではコマンドラインからビルド・デプロイします。
gcloud run jobs deploy gemini-jobs-sample \
--region asia-northeast1 \
--source . \
--tasks 5 \
--set-env-vars "PROJECT_ID=<PROJECT_ID>" \
--execute-now
ここでは画像が5つなので --tasks も 5 を指定していますが、BigQuery テーブルのレコード数によって可変させたい場合は Workflows と組み合わせてタスクを動的に実行する形が良いと思います。詳しくは次の記事で解説しています。
デプロイ時にジョブを実行するオプションを設定したので、デプロイ後実行されています。Cloud Run ジョブのコンソールでは、すべてのタスクの実行が成功していることが確認できました。
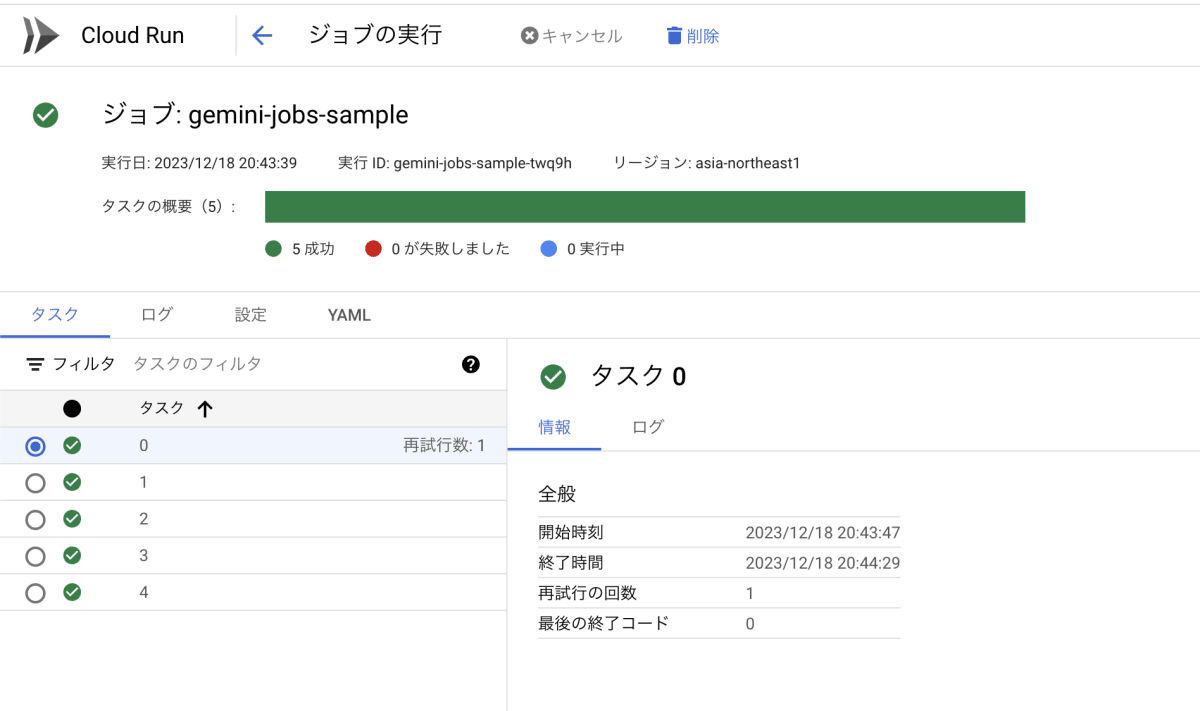
ジョブの実行結果の確認
BigQuery テーブルをクエリしてみます。
SELECT uri, tags FROM `<PROJECT_ID>.products.tags`
Gemini Pro Vision で生成したタグが、各画像単位でセットされていることが確認できました。

BigQuery テーブルのクエリ結果
まとめ
Gemini Pro Vision のマルチモーダル機能はとても面白いので、まずはコンソールからでも良いのでぜひ試してみてください。今回は一例として紹介しましたが、Cloud Run ジョブと組み合わせると Gemini Pro Vision の呼び出しをスケールさせながら並列処理することができます。今後様々なユースケースで活用できると思います。
Gemini Pro Vision については下記のドキュメントが参考になりますので、あわせてご確認ください!

Discussion