2023年は「Cloud Run を触って覚える」をテーマとした一人アドベントカレンダーを一人で開催しており、Cloud Run のさまざまな機能や、Cloud Run でよく使う構成などを実際の使い方と一緒にご紹介しています。
12日目は Cloud Run ジョブと Workflows の組み合わせについてご紹介します。Cloud Run ジョブ、Workflows の概要についてはそれぞれ下記の記事を参照してください。
Cloud Run の概要は技術評論社さまのブログ「gihyo.jp」に寄稿した記事で解説していますのでこちらもぜひご覧ください。
Workflows で BigQuery を参照してから Cloud Run ジョブを実行する
Cloud Run ジョブの今年のアップデートで、ジョブを実行する際に設定を上書きすることができるようになりました。
この機能を使って、BigQuery のテーブルを参照してタスク数を決定し、Cloud Run ジョブの設定を上書きしながらジョブを実行するという一連の流れを構成していきます。全体のパイプラインを Workflows で管理します。
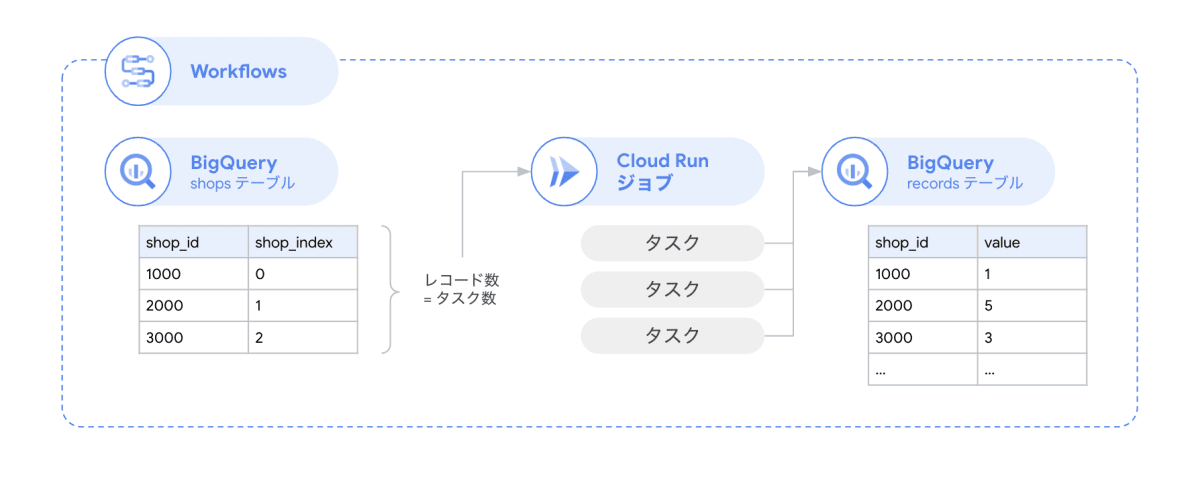
Workflows には各サービスへのコネクターを提供しており、ワークフロー定義上 (YAML) から簡単に呼び出すことができます。今回は Cloud Run ジョブ コネクターと BigQuery コネクターを使います。それぞれのコネクターの使い方は下記も参照してください。
なお Google Cloud プロジェクトは作成済みの前提で進めます。
BigQuery テーブルの準備
まずはデータソースとなる BigQuery テーブルを準備します。BigQuery コンソールを開きます。
クエリ エディタを開きます。

demo データセットを作り、その中に shops テーブルと records テーブルを作ります。shops テーブルには店舗マスタが入るようなイメージで、records テーブルには実績 (POS データ) が入るイメージです。
CREATE SCHEMA `demo`;
CREATE TABLE `demo.shops` (
shop_id INT64 NOT NULL,
shop_index INT64 NOT NULL,
shop_name STRING,
);
CREATE TABLE `demo.records` (
shop_id INT64 NOT NULL,
value INT64 NOT NULL,
);
次に shops テーブルに、店舗マスタデータとして 5 つのレコードを追加します。
INSERT INTO
`demo.shops` (shop_id, shop_index, shop_name)
VALUES
(1000, 0, 'ショップ1号店'),
(2000, 1, 'ショップ2号店'),
(3000, 2, 'ショップ3号店'),
(4000, 3, 'ショップ4号店'),
(5000, 4, 'ショップ5号店');
これで BigQuery の準備は完了です。
records テーブルには Cloud Run ジョブから追加するので、ここではテーブル作成のみ行っておきます。
ジョブの作成
続いて Cloud Run ジョブを作成します。開発環境は Cloud Shell を使います。Google Cloud コンソールであれば、右上のメニューから起動できます。
サンプル ソースコードを GitHub リポジトリに公開しています。こちらをクローンします。
git clone git@github.com:suwa-yuki/cloudrun-jobs-workflows-sample.git
cd cloudrun-jobs-workflows-sample
次のようなソースコードになっています。PROJECT_ID をご自身の Google Cloud プロジェクトに置き換えてください。
'use strict'
const {BigQuery} = require('@google-cloud/bigquery')
const {CLOUD_RUN_TASK_INDEX = 0} = process.env
const projectId = "<PROJECT_ID>"
const client = new BigQuery()
const main = async () => {
const query = `SELECT shop_id FROM ${projectId}.demo.shops WHERE shop_index = ${CLOUD_RUN_TASK_INDEX}`
const data = await client.query(query)
const rows = data[0]
const shopId = rows[0]['shop_id']
const values = [1, 2, 3, 4, 5].map((v) => `(${shopId}, ${v})`)
const insertQuery = `INSERT INTO ${projectId}.demo.records (shop_id, value) VALUES ${values.join(',')};`
await client.query(insertQuery)
}
main().catch(err => {
console.error(err)
process.exit(1)
})
このコードでは店舗ごとに 1 ~ 5 の値を records テーブルに記録する処理を行っています。
CLOUD_RUN_TASK_INDEX から店舗マスタデータを特定するために shops レコードを参照し、店舗マスタデータに入っている shop_id を使って records テーブルに書き込んでいます。records テーブルに書き込む部分を拡張すれば、例えば Cloud Storage (GCS) に入っている店舗ごとの CSV データを BigQuery にインポートするというユースケースなどにも応用できます。
コンテナ イメージを Artifact Registry に登録し gcloud run jobs deploy コマンドで Cloud Run ジョブを作成します(PROJECT_ID はご自身の Google Cloud プロジェクトに置き換えてください)。
gcloud builds submit --region=asia-northeast1 --tag gcr.io/PROJECT_ID/cloudrun-jobs-workflows-sample .
続けてジョブをコンソールから作成します。Cloud Run のコンソールを開きます。
[ジョブを作成] をクリックします。

[コンテナ イメージの URL] は先ほどプッシュしたコンテナ イメージを選択します。

タスク数はわかりやすさのために 1 のままで作成します。

[セキュリティ] タブを開き [サービス アカウント] の [新しいサービス アカウントの作成] をクリックします。
サービス アカウントの名前は、今回はそのまま自動で入力された名前を使います。
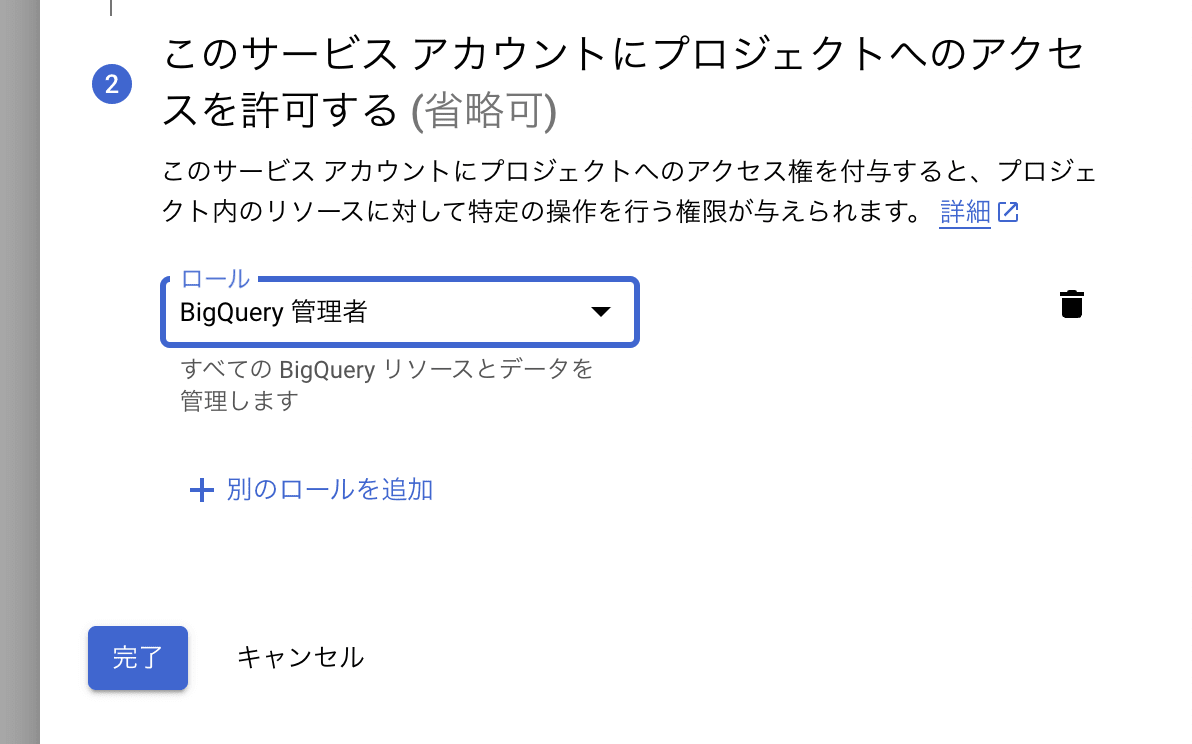
ロールは簡易的に [BigQuery 管理者] を付与します。より細やかな最小限の権限を設定したい場合は こちら を参考にしてください。
ワークフローの作成
Workflows のワークフローを作成します。Workflows のコンソールを開きます。
Workflows の API を有効化していない場合は、有効化します。

[作成] をクリックします。

[ワークフロー名] は cloudrun-jobs-workflows-sample にしました。リージョンは asia-northeast1 を選びます。

[サービス アカウント] は新規作成します。
ここでは次のロールを付与します。
- [BigQuery 管理者] : BigQuery テーブルの参照に必要
- [Cloud Run 管理者] : Cloud Run ジョブの実行に必要

[次へ] をクリックし、ワークフローの定義を設定します。次の YAML ファイルを設定します(PROJECT_ID はご自身の Google Cloud プロジェクトに置き換えてください)。
main:
steps:
- init:
assign:
- project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- bq_shops_table: <PROJECT_ID>.demo.shops
- job_name: cloudrun-jobs-workflows-sample
- job_location: asia-northeast1
- get_task_count:
call: googleapis.bigquery.v2.jobs.query
args:
projectId: ${project_id}
body:
query: ${"SELECT COUNT(*) as count FROM " + bq_shops_table}
useLegacySql: false
result: query_result
- assign_count:
assign:
- task_count: ${int(query_result.rows[0].f[0].v)}
- run_job:
call: googleapis.run.v1.namespaces.jobs.run
args:
name: ${"namespaces/" + project_id + "/jobs/" + job_name}
location: ${job_location}
body:
overrides:
taskCount: ${task_count}
result: job_execution
- finish:
return: ${job_execution}
この例では get_task_count ステップで BigQuery から shops レコードの総数を取得し、後続の run_job ステップの中でオーバーライドするタスク数に設定しています。
Workflows の BigQuery コネクターのレスポンスのスキーマの詳細は下記を参照してください。
また Cloud Run ジョブ コネクターのパラメータは下記を参照してください。
最後に [デプロイ] をクリックして完了です。

ワークフローを実行する
それでは実行してみましょう。ワークフローの [実行] をクリックします。

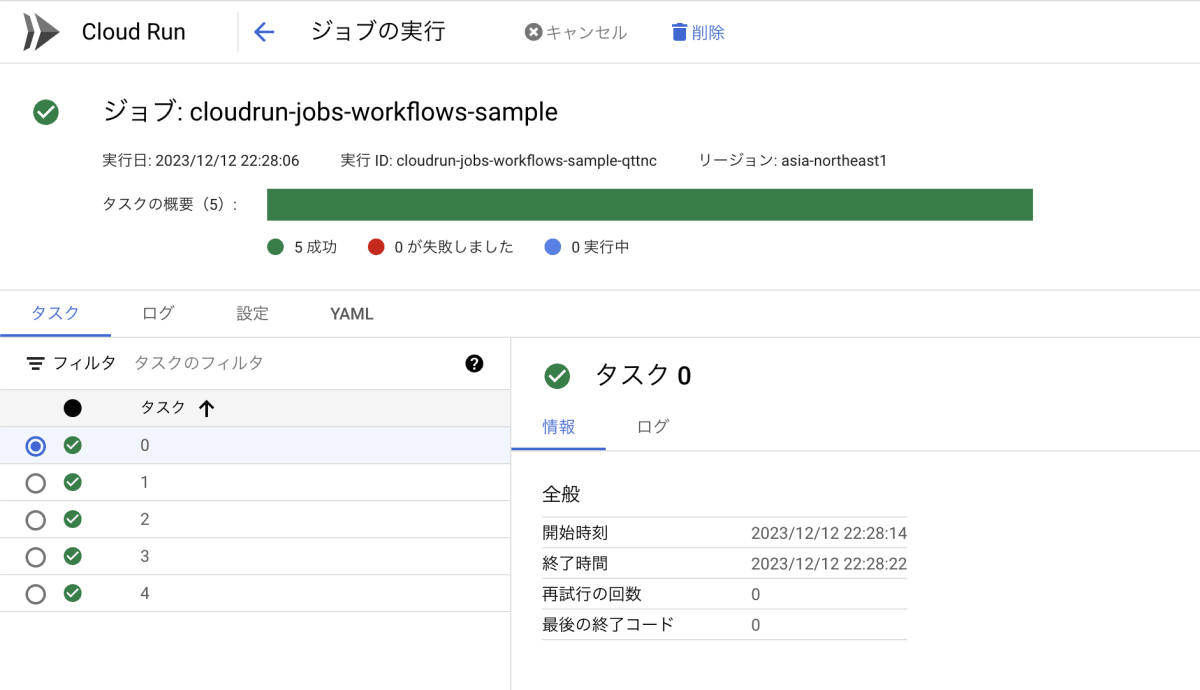
ジョブを確認してみると、5 つのタスクが実行されていることが確認できます。
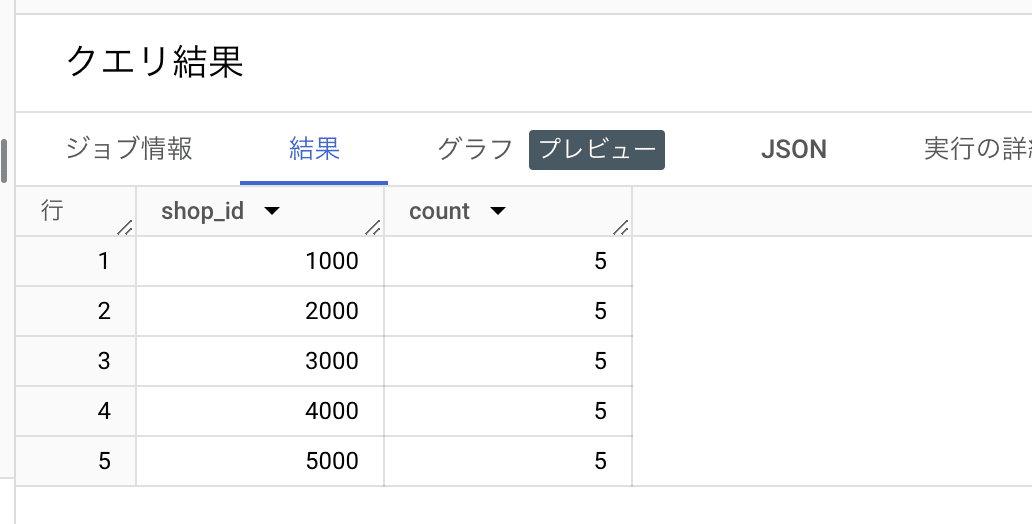
BigQuery テーブルのデータを確認してみましょう。例えば次のようなクエリをかけます(PROJECT_ID はご自身の Google Cloud プロジェクトに置き換えてください)。
SELECT
shop_id,
COUNT(*) AS count
FROM
<PROJECT_ID>.demo.records
GROUP BY
shop_id
ORDER BY
shop_id
想定通りのデータが取得できました。
まとめ
Cloud Run ジョブは並列処理をスケールさせることが可能な点が特長です。実際のユースケースを考えるとタスクの単位がデータベースのレコード単位になるケースも多いですが、この記事と同様な構成を取ることで動的にタスク数を決めて実行することができます。

Discussion